전체 활동내역
- Yesterday
-
 anywherim joined the community
anywherim joined the community -
 pjm0778 joined the community
pjm0778 joined the community - Last week
-
 김경태 joined the community
김경태 joined the community -
 winnersjm joined the community
winnersjm joined the community -
 gotech joined the community
gotech joined the community -
https://navermaps.github.io/maps.js.ncp/docs/tutorial-2-Getting-Started.html script안에 url다시 확인해보세용
-
 웅웅웅 joined the community
웅웅웅 joined the community -
 JHAK joined the community
JHAK joined the community -
<div id="map" style="width:90%;height:360px;margin:0 auto 100px;"></div> <script src="https://oapi.map.naver.com/openapi/v3/maps.js?ncpClientId=ssirtbhxv8"></script> <script> var position = new naver.maps.LatLng(37.5665,126.9780); var map = new naver.maps.Map('map',{ center: position, zoom:15 }); var marker = new naver.maps.Marker({ position: position, map: map }); var infoWindow = new naver.maps.InfoWindow({ content: '<div style="padding:10px;font-size:14px;">(주)원테크엔지니어링</div>' }); infoWindow.open(map, marker); </script> 예를들어 등록 사이트 : https://sample.com/ https://sample.com 코드 구동 디렉토리 https://sample.com/map01

-
 Steven Hong joined the community
Steven Hong joined the community -
 wskim joined the community
wskim joined the community -
 kangsoo joined the community
kangsoo joined the community - Earlier
-
안녕하세요. 아래 "순차적으로 로드하기" 가이드대로 스크립트 호출 부탁드립니다. - https://navermaps.github.io/maps.js.ncp/docs/tutorial-4-Submodules.html 렌더링 성능 저하가 발생하면 아래 경고가 뜨게 됩니다. 클라이언트 기기 스펙에 따라 fps drop 이 발생할 수도 있습니다. > 'requestAnimationFrame' handler took 59ms -maps-gl.js1 경고가 계속 뜨는데요.
-
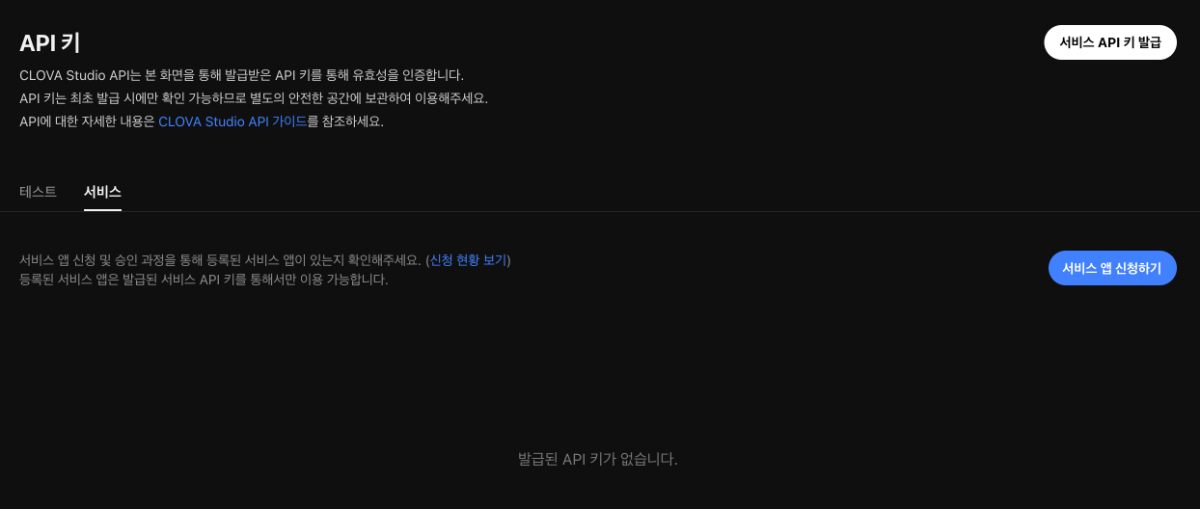
아, 하단에 시선이 먼저 가서, 위에 '서비스 API 키 발급' 버튼을 누를 수 있다는 것을 미처 알아차리지 못했네요. 감사합니다.
-
안녕하세요, @toracle님, 서비스 신청을 완료 하셨다면, API 키에서 서비스 API 키 발급이 가능합니다. 아래 API 키 화면의 우측 상단에 있는 '서비스 API 키 발급' 버튼을 눌러보셨을까요? 해당 버튼을 누르면 발급할 수 있는 팝업이 나타납니다. 감사합니다.
-
안녕하세요. 지도 API 사용하여 웹페이지를 운영 중입니다. 오늘 오후부터 A parser-blocking, cross site (i.e. different eTLD+1) script, https://oapi.map.naver.com/openapi/v3/maps-gl.js, is invoked via document.write. The network request for this script MAY be blocked by the browser in this or a future page load due to poor network connectivity. If blocked in this page load, it will be confirmed in a subsequent console message. 경고와 함께 지도 내에서 zoomLevel 변경 시마다 'requestAnimationFrame' handler took 59ms -maps-gl.js1 경고가 계속 뜨는데요. 이유를 알 수 있을까요?
-
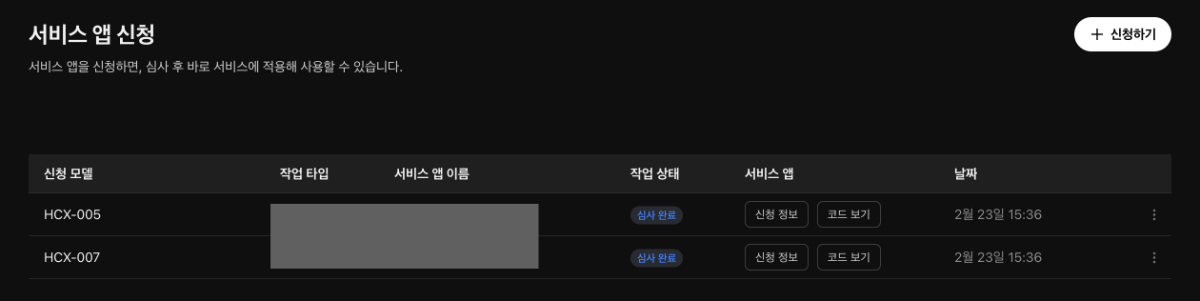
안녕하세요. 서비스 앱을 신청한 후에, 서비스용 API 키를 발급받으려 하니, '서비스 앱 신청하기'를 하라고 나옵니다. 신청한 서비스 앱들은 '심사 완료' 상태로 되어있는데, 현재 어떤 상태인 것인가요? 그리고 서비스용 API 키를 발급받으려면 추가로 어떤 작업이 필요한가요?
-
https://www.ncloud.com/v2/support/notice/all/1930?page=10 공지 사항이 있는데 기존 제공되던 AI Naver API는 종료되었습니다. Application Services > Maps에 있는 지도 API를 사용하면 될 겁니다.
-
저도 같은 문제를 겪고 있습니다... 혹시 해결하셨을까요?
-
안녕하세요 naver map api키를 넣어서 홈페이지를 만드려다가 겨우 겨우 https://console.ncloud.com/maps/application 이 주소를 넣어서 map api키를 설정하긴 했는데요 원래는 저기에 map 부분에 하이퍼링크가 있어야 되는거 아닌가요?
-
 안녕하세요. 수고 많으십니다 Direction 5 API 호출 시 간헐적으로 Connect Timeout 에러가 발생합니다. 확인해주시면 감사하겠습니다. --------- 요청 이력 ----------- 2026-02-09 10:21 GET https://maps.apigw.ntruss.com/map-direction/v1/driving?start=126.9615290394227%2C37.59494258107993&goal=126.989775723896%2C37.5734371942191&waypoints=126.989775723896%2C37.5734371942191&option=traavoidcaronly&cartype=1&fueltype=gasoline&mileage=14.0&lang=ko 2026-02-09 10:31 GET https://maps.apigw.ntruss.com/map-direction/v1/driving?start=126.9632162240255%2C37.59492059415746&goal=123.45678%2C34.56789%3A124.56789%2C35.67890&waypoints=126.989775723896%2C37.5734371942191&option=traavoidcaronly&cartype=1&fueltype=gasoline&mileage=14.0&lang=ko 2026-02-11 13:49 GET https://maps.apigw.ntruss.com/map-direction/v1/driving?start=127.06239026406428%2C37.56637536733353&goal=128.36167328636162%2C36.977313922732726&option=traavoidcaronly&lang=ko -----------에러 메시지 ----------------- java.net.SocketTimeoutException: Connect timed out 감사합니다
안녕하세요. 수고 많으십니다 Direction 5 API 호출 시 간헐적으로 Connect Timeout 에러가 발생합니다. 확인해주시면 감사하겠습니다. --------- 요청 이력 ----------- 2026-02-09 10:21 GET https://maps.apigw.ntruss.com/map-direction/v1/driving?start=126.9615290394227%2C37.59494258107993&goal=126.989775723896%2C37.5734371942191&waypoints=126.989775723896%2C37.5734371942191&option=traavoidcaronly&cartype=1&fueltype=gasoline&mileage=14.0&lang=ko 2026-02-09 10:31 GET https://maps.apigw.ntruss.com/map-direction/v1/driving?start=126.9632162240255%2C37.59492059415746&goal=123.45678%2C34.56789%3A124.56789%2C35.67890&waypoints=126.989775723896%2C37.5734371942191&option=traavoidcaronly&cartype=1&fueltype=gasoline&mileage=14.0&lang=ko 2026-02-11 13:49 GET https://maps.apigw.ntruss.com/map-direction/v1/driving?start=127.06239026406428%2C37.56637536733353&goal=128.36167328636162%2C36.977313922732726&option=traavoidcaronly&lang=ko -----------에러 메시지 ----------------- java.net.SocketTimeoutException: Connect timed out 감사합니다 -
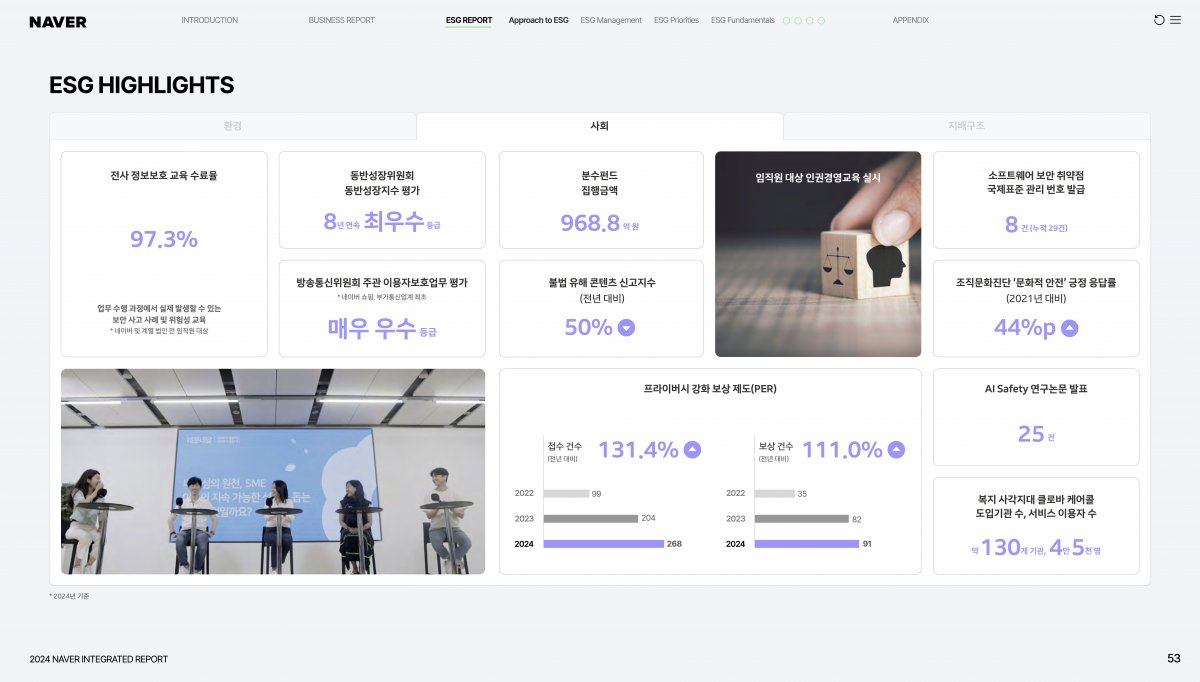
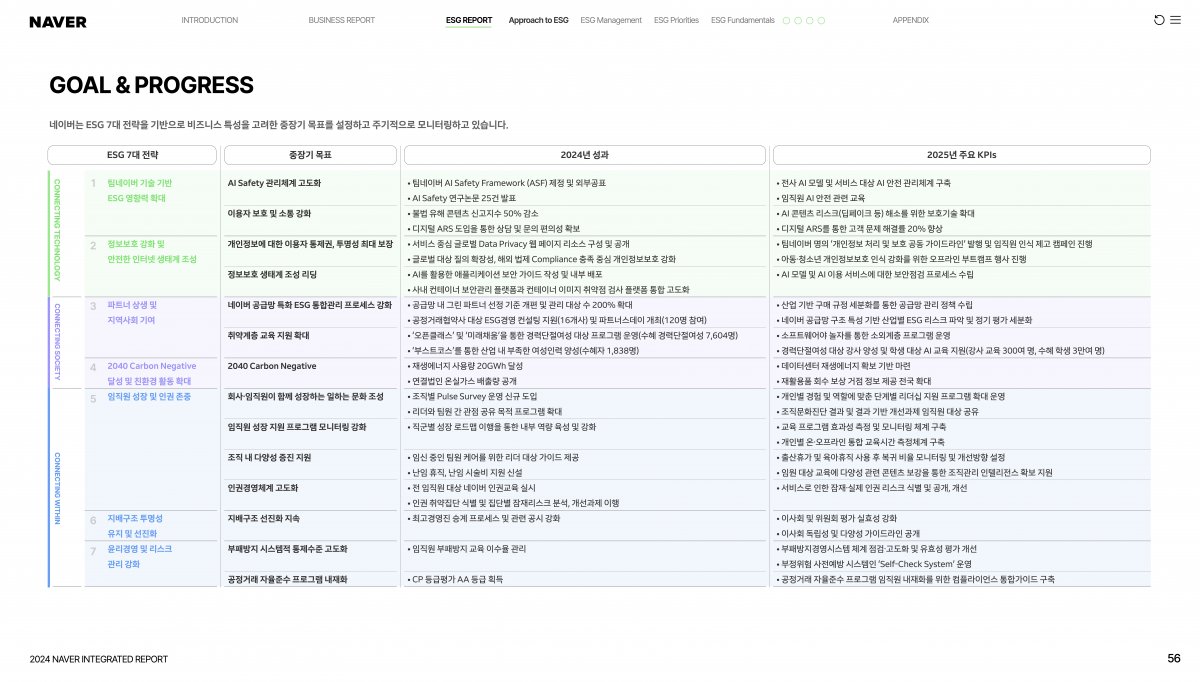
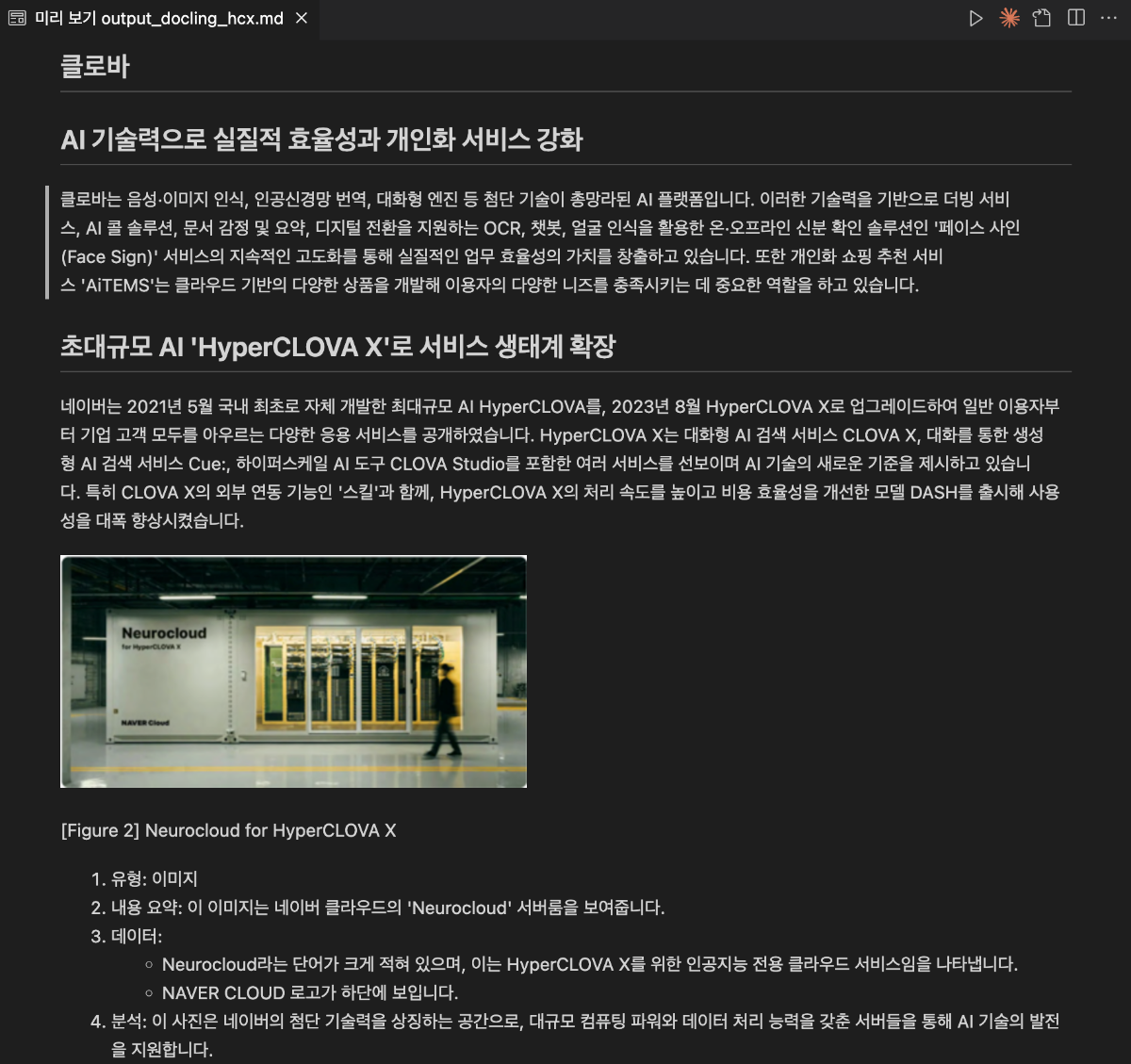
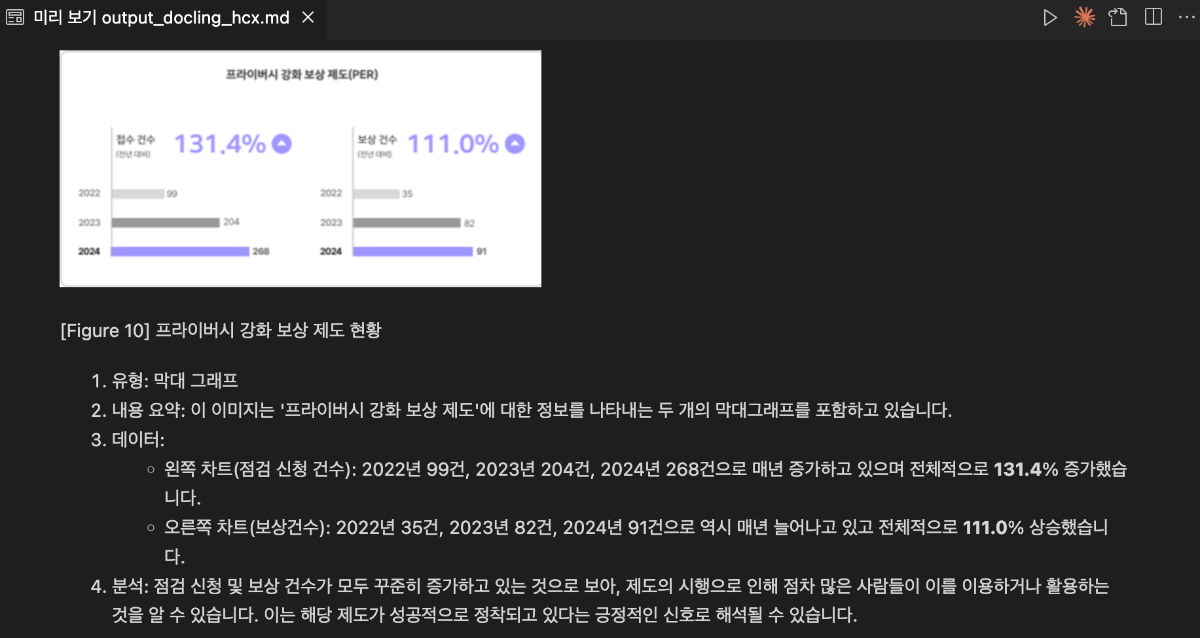
LLM 애플리케이션의 성능은 모델의 크키뿐만 아니라 주입되는 데이터의 품질, 즉 전처리에도 큰 영향을 받습니다. 특히 문서를 참고하여 답변을 생성해야 하는 RAG(검색 증강 생성) 시스템에서 데이터 전처리는 선택이 아닌 필수이며, 비정형 데이터를 얼마나 잘 정제하느냐가 최종 응답의 품질을 결정합니다. 복잡한 표나 불규칙한 레이아웃을 가진 문서를 그대로 입력하면 모델이 구조 파악에 리소스를 낭비하게 되므로, 이를 기계가 읽기 쉬운 형식으로 변환하는 작업이 핵심입니다. 이때 Markdown 변환이 효과적인 이유는 텍스트의 구조와 위계를 명확히 표현하면서도 토큰 효율이 높아, LLM이 문서의 논리적 흐름을 가장 정확하게 이해할 수 있기 때문입니다. 이처럼 잘 정제된 데이터는 할루시네이션을 줄이고 서비스의 신뢰도를 높이는 강력한 기반이 됩니다. 이번 쿡북에서는 CLOVA Studio의 HyperCLOVA X 비전 모델과 Docling을 활용해, PDF 문서를 분석하고 완성도 높은 Markdown으로 변환하는 실전 가이드를 소개합니다. Docling Docling은 IBM Research에서 개발한 오픈소스 Python 라이브러리로, PDF, DOCX, PPTX, XLSX부터 HTML, Markdown, 그리고 이미지(PNG, JPEG, TIFF)와 오디오(MP3, WAV)까지 다양한 형식의 문서를 구조화된 데이터로 변환해주는 도구입니다. 일반적인 변환 도구와 달리 Docling은 내부적으로 시각적 레이아웃 분석 모델, TableFormer와 같은 전용 모델을 활용하여 문서의 레이아웃을 분석하고, 제목, 표, 이미지, 수식, 코드 블록의 위치와 구조를 파악합니다. 예를 들어 복잡한 표가 포함된 PDF 보고서를 처리하면 표의 행과 열 구조를 정확히 인식하고, 텍스트의 읽기 순서를 파악하며, 이 모든 정보를 Markdown, HTML, JSON 같은 형식으로 깔끔하게 내보낼 수 있습니다. 유사한 도구로는 빠른 문서 변환에 특화된 경량 라이브러리 Markitdown과 책이나 기술 문서 처리에 최적화된 Marker 등이 있습니다. 예제 데이터 소개 다음은 전처리 과정에 사용할 PDF 예제입니다. 네이버 통합 보고서 2024에서 다음 세 페이지를 발췌해 예제로 활용합니다. 해당 예제에는 텍스트, 이미지, 표가 적절히 섞여있고 각기 다른 레이아웃을 가지고 있어 예제로 선정하였습니다. 전처리 과정 구현 전처리 전략 문서에는 텍스트 외에도 표, 차트, 다이어그램 같은 시각적 요소가 포함되어 있으며, 이들은 별도의 해석이 필요합니다. 이번 가이드는 Docling과 HyperCLOVA X를 단계적으로 활용하는 전처리 전략을 다룹니다. Docling은 문서 구조를 파악하고 이미지를 추출하는 역할을 합니다. 이미지 위치를 식별하고 내부 텍스트를 OCR로 읽을 수 있지만, "이 차트가 무엇을 의미하는가"와 같은 해석은 수행하지 않습니다. 따라서 역할을 분리합니다. Docling은 문서 구조 정리와 텍스트 및 이미지 추출을, HyperCLOVA X 비전 모델(HCX-005)은 이미지 해석을 담당합니다. 각 도구의 강점을 활용하여 효율적인 문서 전처리 파이프라인을 구성할 수 있습니다. 사전 준비 전처리 구현을 진행하기 전에 가상환경, 라이브러리 설치 등 사전 준비 과정을 안내합니다. 루트 디렉토리의 터미널에서 다음 명령어를 통해 필요한 라이브러리 설치합니다. 가상환경 설치를 권장합니다. # 가상환경 설정 python -m venv .venv # 가상환경 활성화(mac) source .venv/bin/activate # 가상환경 활성화(window,cmd) # .venv\Scripts\activate.bat # 라이브러리 설치 pip install docling pdf2image easyocr openai python-dotenv ipywidgets 루트 디렉토리에 .env 파일을 만들고, 필요한 환경변수를 설정합니다. CLOVA Studio API 키 발급 방법은 CLOVA Studio API 가이드에서 확인할 수 있습니다. 이번 실습에서는 CLOVA Studio의 OpenAI 호환 API를 사용합니다. BASE_URL에 대한 자세한 내용은 CLOVA Studio OpenAI 호환 API 가이드를 확인해 주세요. 코드 구현 이번 실습은 IPython Notebook(.ipynb)으로 진행됩니다. 실습에 사용할 디렉토리에 예제 데이터를 넣어주세요. Step 1. 본격적으로 실행에 앞서 환경 변수를 불러옵니다. from dotenv import load_dotenv load_dotenv() True Step 2.다음으로 필요한 라이브러리를 불러옵니다. 이번 실습에서는 GPU 설정을 따로 하지 않습니다. 환경에 따라서 추가 설정이 가능합니다. import time from docling.document_converter import DocumentConverter, PdfFormatOption from docling.datamodel.base_models import InputFormat from docling.datamodel.pipeline_options import PdfPipelineOptions import easyocr import os import base64 import io from openai import OpenAI from dotenv import load_dotenv from docling_core.types.doc import PictureItem import warnings warnings.filterwarnings('ignore', category=UserWarning, module='torch.utils.data.dataloader') # 환경 변수 로드 load_dotenv() # EasyOCR 리더 초기화 (한국어, 영어 지원) reader = easyocr.Reader(['ko', 'en'], gpu=False) print("✓ 라이브러리 로드 완료") 2026-01-21 16:02:39,723 - WARNING - Using CPU. Note: This module is much faster with a GPU. ✓ 라이브러리 로드 완료 Step 3. Docling으로 PDF를 변환합니다. 먼저 export_to_markdown()으로 디지털 텍스트를 추출한 다음 저장합니다. Docling의 do_ocr=True 설정은 디지털 텍스트가 있는 페이지는 직접 추출하고, 텍스트 정보가 없는 스캔 페이지만 선택적으로 OCR을 수행하여 변환 효율을 극대화합니다. # 예제 데이터 pdf_path = "preprocessing_cookbook_example.pdf" print(f"\nDocling 변환 시작: {pdf_path}") start_time = time.time() # Docling 파이프라인 설정 pipeline_options = PdfPipelineOptions() pipeline_options.do_ocr = True # Docling이 알아서 필요한 곳만 OCR pipeline_options.do_table_structure = True pipeline_options.generate_picture_images = True pipeline_options.generate_page_images = False # DocumentConverter 초기화 docling_converter = DocumentConverter( format_options={ InputFormat.PDF: PdfFormatOption(pipeline_options=pipeline_options) } ) # PDF 변환 실행 docling_result = docling_converter.convert(pdf_path) markdown = docling_result.document.export_to_markdown() # 깨지는 문자열 전처리 markdown = markdown.replace('뭃', '•') elapsed = time.time() - start_time print(f"✓ Docling 변환 완료: {elapsed:.1f}초 소요") # 이미지 저장 디렉토리 생성 os.makedirs("figure", exist_ok=True) 2026-01-21 16:02:41,654 - INFO - detected formats: [<InputFormat.PDF: 'pdf'>] 2026-01-21 16:02:41,705 - INFO - Going to convert document batch... 2026-01-21 16:02:41,705 - INFO - Initializing pipeline for StandardPdfPipeline with options hash 8e7b949cc226caef8aab3aadca70e8e7 2026-01-21 16:02:41,715 - INFO - Loading plugin 'docling_defaults' 2026-01-21 16:02:41,717 - INFO - Registered picture descriptions: ['vlm', 'api'] 2026-01-21 16:02:41,721 - INFO - Loading plugin 'docling_defaults' 2026-01-21 16:02:41,724 - INFO - Registered ocr engines: ['auto', 'easyocr', 'ocrmac', 'rapidocr', 'tesserocr', 'tesseract'] Docling 변환 시작: preprocessing_cookbook_example.pdf 2026-01-21 16:02:42,248 - INFO - Auto OCR model selected ocrmac. 2026-01-21 16:02:42,258 - INFO - Loading plugin 'docling_defaults' 2026-01-21 16:02:42,261 - INFO - Registered layout engines: ['docling_layout_default', 'docling_experimental_table_crops_layout'] 2026-01-21 16:02:42,704 - INFO - Accelerator device: 'mps' 2026-01-21 16:02:43,983 - INFO - Loading plugin 'docling_defaults' 2026-01-21 16:02:43,984 - INFO - Registered table structure engines: ['docling_tableformer'] 2026-01-21 16:02:44,238 - INFO - Accelerator device: 'mps' 2026-01-21 16:02:44,803 - INFO - Processing document preprocessing_cookbook_example.pdf 2026-01-21 16:02:48,571 - INFO - Finished converting document preprocessing_cookbook_example.pdf in 6.92 sec. ✓ Docling 변환 완료: 6.9초 소요 다음은 export_to_markdown()으로 pdf에서 텍스트만 추출한 결과입니다. 이후 과정에서 <!-- image -->가 이미지에 대한 설명으로 대체됩니다. Step 4. PDF 내부 이미지를 저장할 디렉토리를 생성합니다. # 이미지 저장 디렉토리 생성 os.makedirs("figure", exist_ok=True) # HCX 클라이언트 초기화 hcx_client = OpenAI( api_key=os.getenv("CLOVA_STUDIO_API_KEY"), base_url=os.getenv("CLOVA_STUDIO_BASE_URL") ) # 이미지 처리를 위한 변수 초기화 image_counter = 0 image_refs = [] image_analyses = [] print("✓ 이미지 추출 및 분석 준비 완료") ✓ 이미지 추출 및 분석 준비 완료 Step 5. 문서에서 이미지를 추출한 다음 HCX-005 모델로 분석합니다. PDF의 각 페이지를 PNG로 저장한 뒤 HCX-005 모델로 내용을 분석합니다. 이때 이미지 크기는 HCX-005 모델 규격에 따라야하며, 원활한 처리를 위한 리사이징이 필요할 수 있습니다. 분석된 시각적 정보는 추출된 텍스트와 결합하여 최종적인 마크다운 문서로 완성됩니다. print(f"\n이미지 추출 및 분석 시작...") for element, _level in docling_result.document.iterate_items(): if isinstance(element, PictureItem): image_counter += 1 pil_image = element.get_image(docling_result.document) # 이미지 파일로 저장 image_filename = f"extracted_image_{image_counter}.png" image_path = os.path.join("figure", image_filename) pil_image.save(image_path, format="PNG") # 마크다운 이미지 참조 생성 image_ref = f"" image_refs.append(image_ref) print(f" [{image_counter}] {image_filename} ({pil_image.size[0]}×{pil_image.size[1]}px)") # HCX Vision API로 이미지 분석 try: # 이미지를 base64로 인코딩 buffer = io.BytesIO() pil_image.save(buffer, format="PNG", optimize=True) base64_image = base64.b64encode(buffer.getvalue()).decode() print(f" → HCX 분석 중...", end=" ") # HCX API 호출 response = hcx_client.chat.completions.create( model="hcx-005", messages=[{ "role": "user", "content": [ { "type": "text", "text": f""" # 이미지를 분석하여 다음 양식으로 추출하세요: [Figure {image_counter}] (간단한 제목) 1. **유형**: (차트/표/다이어그램 등) 2. **내용 요약**: 핵심 정보 2-3줄 3. **데이터**: - 차트: 주요 트렌드와 수치 (중요 수치 **굵게**) - 표: 마크다운 테이블로 변환 4. **분석**: 데이터에서 발견되는 인사이트나 특징 2-3줄 한국어로 간결하게 작성하고, 제목도 간단 명료하게 작성하세요.""" }, { "type": "image_url", "image_url": {"url": f"data:image/png;base64,{base64_image}"} } ] }], max_tokens=1500 ) analysis = response.choices[0].message.content image_analyses.append(f"\n\n{analysis}") print("✓") except Exception as e: print(f"✗ 오류: {str(e)}") image_analyses.append(f"\n\n**[Figure {image_counter}]**\n\n오류: {str(e)}") print(f"\n✓ {image_counter}개 이미지 처리 완료") 이미지 추출 및 분석 시작... [1] extracted_image_1.png (53×51px) → HCX 분석 중... 2026-01-21 16:02:51,940 - INFO - HTTP Request: POST https://clovastudio.stream.ntruss.com/v1/openai/chat/completions "HTTP/1.1 200 OK" ✓ . . . [13] extracted_image_13.png (42×10px) → HCX 분석 중... 2026-01-21 16:03:54,139 - INFO - HTTP Request: POST https://clovastudio.stream.ntruss.com/v1/openai/chat/completions "HTTP/1.1 200 OK" ✓ ✓ 13개 이미지 처리 완료 Step 6. 이미지 분석 결과를 마크다운에 통합하고 최종 파일에 저장합니다. 이전에 추출한 디지털 텍스트에서 <!-- image --> 부분을 실제 이미지 및 분석으로 교체합니다. 그리고 최종 결과를 마크다운 파일로 저장합니다. print(f"\n마크다운 통합 중...") # 이미지 참조와 분석 결과를 마크다운에 삽입 for image_ref, analysis in zip(image_refs, image_analyses): markdown = markdown.replace("<!-- image -->", f"{image_ref}{analysis}", 1) # 최종 파일 저장 output_md = "output_docling_hcx.md" with open(output_md, 'w', encoding='utf-8') as f: f.write(markdown) print(f"✓ 최종 마크다운 저장 완료: {output_md}") print(f"\n=== 처리 요약 ===") print(f" 추출 이미지: {image_counter}개") print(f" 출력 파일: {output_md}") 마크다운 통합 중... ✓ 최종 마크다운 저장 완료: output_docling_hcx.md === 처리 요약 === 추출 이미지: 13개 출력 파일: output_docling_hcx.md 전처리 결과 최종적으로 예제 데이터를 전처리한 결과입니다. 마크다운 렌더링 예시는 다음과 같습니다. 맺음말 이번 쿡북에서는 Docling과 HyperCLOVA X 모델을 도입하여 PDF 문서를 Markdown으로 변환하는 방법에 대해 알아보았습니다. 단순히 글자를 읽어오는 것을 넘어, Docling으로 문서의 전체적인 구조를 잡고 HyperCLOVA X의 비전 기능을 통해 문서 속 이미지와 차트의 의미까지 정확하게 추출하는 과정이 핵심이었습니다. 이처럼 텍스트와 시각 정보를 함께 정제하는 전처리 방식은 이후 모델이 데이터의 맥락을 깊이 있게 이해하도록 돕는 필수적인 단계입니다. 데이터 전처리는 정교한 LLM 서비스를 완성하기 위한 시작점이자 가장 중요한 기반입니다. 이번에 소개해 드린 가이드가 여러분의 프로젝트에서 고품질의 데이터를 확보하고, 더 나아가 사용자에게 신뢰받는 AI 서비스를 구축하는 데 유용한 밑거름이 되기를 바랍니다.
-
네이버 지도 서비스에서 사용하는 거리뷰 뷰어는 NCP 서비스로 따로 제공하지 않습니다. 감사합니다.
-

(3부) CLOVA Studio를 이용해 RAG 구현하기
CLOVA Studio 운영자 replied to CLOVA Studio 운영자's topic in 활용법 & Cookbook
안녕하세요, @sseul님, API 연동/이용 방식이 간소화 되었습니다. 이제는 테스트 앱을 생성할 필요 없이 API 키 발급만으로 바로 CLOVA Studio의 모든 기능을 API로 이용하실 수 있습니다. 좌측의 API 키 메뉴를 통해 테스트 API 키 발급 부탁드립니다. https://guide.ncloud-docs.com/docs/clovastudio-playground-viewsource 감사합니다. -
안녕하세요. 혹시 지금은 테스트앱 생성이 불가능한가요?
-
api를 이용하여 파노라마 뷰를 불러올 경우 촬영용 차량이 함께 나오는데 네이버 지도에서 거리뷰 열람하는 것처럼 촬영용 차량이 블리인드 된 버전으로 받는 것은 불가능할까요?
-
 혹시 maps style edtitor에서 스타일 등록 하셨는지 확인해보시길 바랍니당
혹시 maps style edtitor에서 스타일 등록 하셨는지 확인해보시길 바랍니당 -
혹시 maps style editor 설정하셨는지 확인해보시기 바랍니다
-
네이버 포럼에 뭐 질문 올려도 관리를 안하는건지 그냥 방치하는건지... 이런 문제를 겪고 있는 사람들이 많은거 같더라구요
-
 저는 React-Native 개발인데.. 저도 그렇습니다. NMFClientId, NMFNcpKeyId 둘다 안먹네요
저는 React-Native 개발인데.. 저도 그렇습니다. NMFClientId, NMFNcpKeyId 둘다 안먹네요 -
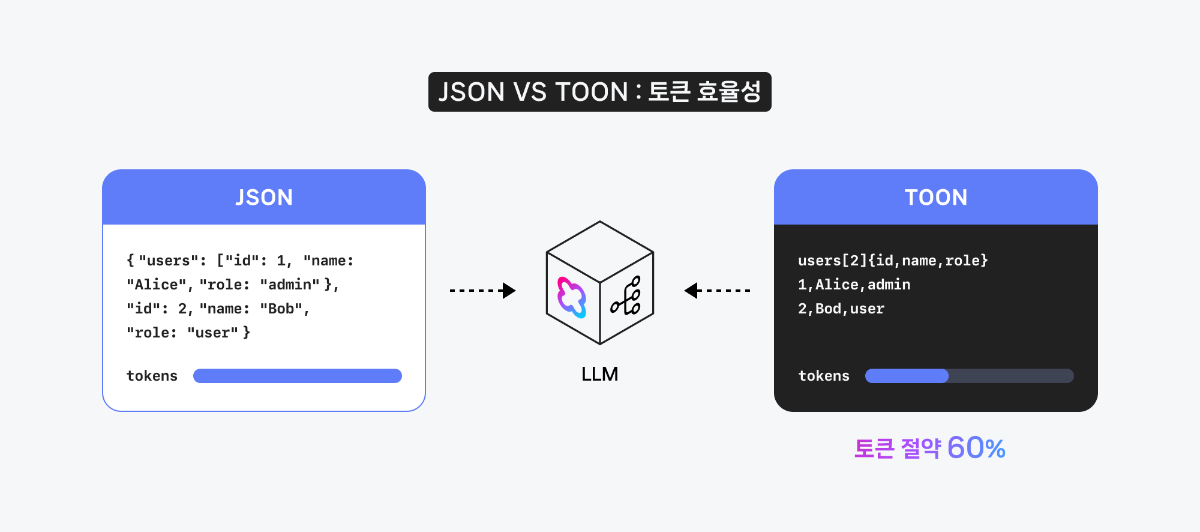
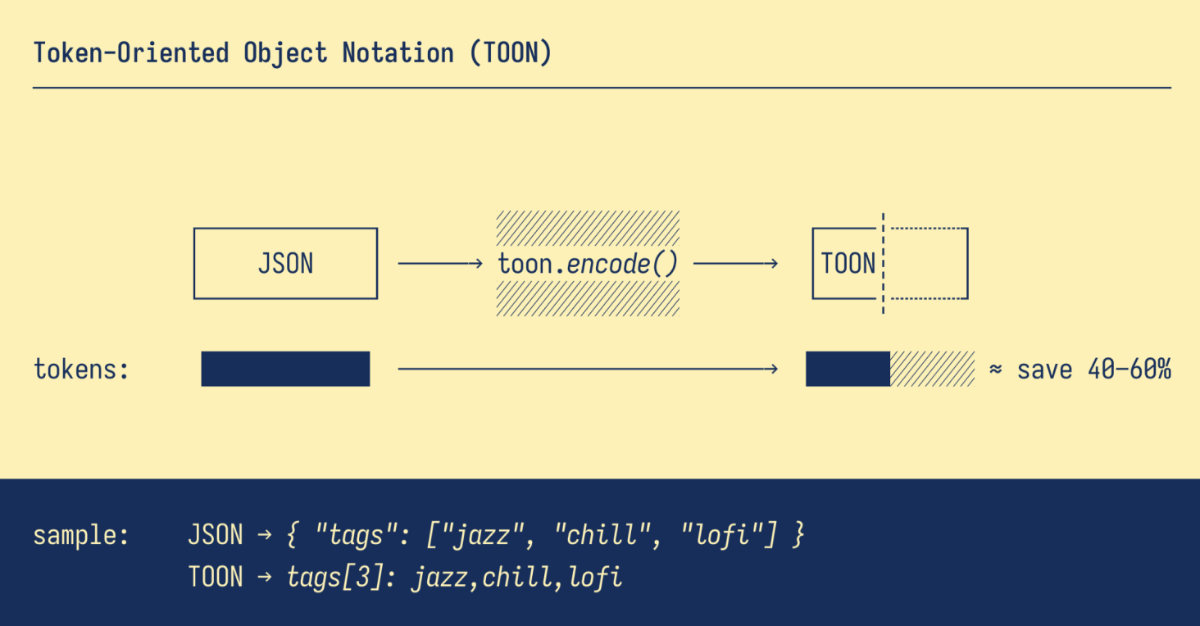
TOON, LLM 입력 구조를 다시 생각하게 만든 포맷 대규모 언어 모델(LLM)에서 연산 속도와 토큰 효율을 높이면서 응답 품질을 유지하거나 향상시키려는 시도는 계속되고 있습니다. 특히 엔터프라이즈 환경에서는 토큰 사용량과 Latency가 곧 비용과 사용자 경험으로 직결됩니다. JSON은 구조가 명확하고 범용성이 높아 LLM 입력 포맷으로 널리 활용되고 있습니다. 그러나 반복되는 key-value 구조와 다양한 구분자는 토큰 소모를 빠르게 증가시키고, 결국 연산 비용이 증가하는 문제도 있습니다. 오늘은 이러한 문제를 해결하기 위해 등장한 TOON(Token-Oriented Object Notation) 포맷을 살펴봅니다. TOON은 JSON의 표현력을 유지하면서도, 동일한 정보를 더 간결하게 표현해 토큰 사용량을 줄이고 LLM이 구조를 더 효율적으로 해석하도록 설계된 입력 포맷입니다. TOON의 경량화된 구조 이미지 출처: https://github.com/toon-format/toon TOON은 반복되는 객체 리스트를 탭형(tabular) 구조로 표현할 수 있도록 설계된 입력 포맷입니다. 계층 구조는 들여쓰기로 유지하면서, 동일한 구조의 배열에 대해서는 필드 목록을 한 번만 선언하고 이후 값을 행(row) 단위로 나열합니다. 이 방식은 JSON에서 반복적으로 등장하는 key-value 구조를 제거해 입력을 간결하게 만듭니다. 반복된 구조를 압축적으로 표현해 토큰 사용량을 크게 줄일 수 있습니다. 모델이 구조를 더 쉽게 파악해 특정 Task에서 속도 개선 가능성이 있습니다. 사람이 읽고 비교, 검수하기 쉬운 간결한 구조를 제공합니다. 예를 들어 JSON의 product 리스트가 다음과 같다면, { "products": [ { "product_id": "301", "name": "무선 마우스", "price": "29900", "stock": "재고 있음", "rating": "4.5" }, { "product_id": "302", "name": "기계식 키보드", "price": "89000", "stock": "재고 부족", "rating": "4.8" }, { "product_id": "303", "name": "USB-C 허브", "price": "45500", "stock": "품절", "rating": "4.1" } ] } TOON에서는 아래와 같이 표현할 수 있습니다. products[3]{product_id,name,price,stock,rating}: 301,무선 마우스,29900,재고 있음,4.5 302,기계식 키보드,89000,재고 부족,4.8 303,USB-C 허브,45500,품절,4.1 동일한 정보이지만 반복되는 key가 제거되면서 토큰 사용량은 크게 줄어들고, LLM이 인식해야 할 구조 역시 훨씬 단순해집니다. 입력 포맷별 벤치마크 결과 다음은 TOON GitHub에서 공개된 벤치마크 결과입니다. TOON, JSON, YAML, XML 등 주요 포맷을 대상으로 비교 실험을 진행했습니다. 입력 포맷의 효율성은 1,000 토큰당 정확도(acc% / 1K tokens) 기준으로 평가되었습니다. 즉, 같은 질문을 풀었을 때의 정답률을 토큰 사용량으로 나눈 지표입니다. 이 기준에서 TOON은 JSON 대비 약 39.6% 적은 토큰을 사용하면서도, 더 높은 정확도(73.9% vs 69.7%)를 기록했습니다. 즉, 표현 방식만 바꿨는데도, 토큰 대비 성능 지표에서 변화가 관찰되었습니다. ※ CSV는 단순한 테이블 데이터에서는 매우 효율적이지만, 복합적인 구조를 표현하는 데 한계가 있어 전체 비교에서는 제외되었습니다. HyperCLOVA X 모델로 실험하기 CLOVA Studio에서 HyperCLOVA X 모델을 활용해 JSON과 TOON을 비교했습니다. 이번 실험은 입력 포맷을 변경했을 때 나타나는 차이와 특성을 살펴보는 데 초점을 두었습니다. 1. 단순 구조 데이터 대규모 JSON 배열을 그대로 전달하는 상황에서는 TOON의 특성이 비교적 명확하게 드러났습니다. 동일한 데이터를 TOON 형식으로 변환했을 때, Prompt token 사용량이 약 27.3% 감소했습니다. 2. Reasoning 중심 Task KMMLU와 같은 추론 중심 Task에서는 JSON이 더 안정적인 결과를 보였습니다. 정답률 측면에서 JSON이 우세했으며, TOON의 토큰 효율성은 이 영역에서 의미 있는 차이를 만들지 못했습니다. 3. RAG 기반 Task RAG 기반 Task에서는 일부 작업에서 긍정적인 경향이 관찰되었습니다. 특히 요약, 비교, 추천, 정보 추출처럼 Retrieval 결과를 후처리하는 유형의 Task에서 TOON이 상대적으로 안정적인 성능을 보였습니다. 4. API 응답/로그 분석 API 응답이나 로그 데이터처럼 반복 패턴이 많은 데이터를 다루는 Task에서도 TOON이 유리한 경향을 보였습니다. 이상 탐지, 패턴 분석, 단순 요약과 같은 작업에서 입력 크기가 줄어들면서 처리 효율이 개선되는 모습을 확인할 수 있었습니다. 마치며 모델 자체를 변경하지 않고 입력 포맷을 조정하는 것만으로도, 특정 유형의 작업에서는 토큰 사용량과 처리 효율에 차이를 만들 수 있음을 확인했습니다. TOON은 모든 상황에 적용할 수 있는 해법은 아니지만, 구조가 단순하고 반복적인 데이터가 많은 영역에서는 하나의 선택지가 될 수 있습니다. 결국 LLM 입력에서도 중요한 것은, 정보를 얼마나 효율적인 형태로 전달하고 있는가일 것입니다. 이번 포스팅은 여기서 마무리하며, 다음에도 유용한 활용 팁으로 찾아오겠습니다.
-
안녕하세요, @leeeg님, 클로바 스튜디오 이용 요금은 아래 링크에서 확인하실 수 있습니다. https://www.ncloud.com/v2/product/aiService/clovaStudio#pricing 감사합니다.
-
안녕하세요 @jwpark님, CLOVA Studio를 이용해주셔서 감사합니다. 리랭커 API는 llm 모델을 기반으로 하고 있기 때문에 동일한 데이터를 input으로 사용하더라도 호출에 따라 최종 문서 기반 생성 결과인 'result'가 조금씩 상이하게 나타날 수 있으며, 이에 따라 result 생성에 사용된 연관 문서들도 조금씩 달라질 수 있습니다. 그 외 추가로 궁금한 점이 있으시면 편히 말씀주세요. 고맙습니다.
-
안녕하세요 rerank api 관련하여 문의드립니다. rerank api를 사용하여 동일한 쿼리와 그에 해당하는 동일한 검색된 문서 간의 연관도를 평가할 때, 그 결과가 간헐적으로 달라질 수도 있나요? 감사합니다.