LLM의 발전은 다양한 산업 분야에서 변화를 가져오고 있지만, LLM 단독으로는 최신 정보에 대한 접근성이나 답변의 신뢰성 측면에서 한계를 지니고 있습니다. 이러한 한계를 극복하기 위해 RAG 시스템이 등장하였고, 이와 관련하여 리랭커 활용법 : CS 문의에 답변하는 RAG 시스템 구현하기 CookBook에서는 RAG 시스템을 구성할 수 있는 도구 중 하나인 리랭커에 대한 내용을 소개했습니다.
이번 쿡북에서는 RAG 시스템의 핵심 구성 요소로 사용될 수 있는 리랭커와 RAG Reasoning 이 둘을 체이닝하여 더욱 강력한 성능을 발휘하는 방법에 대해 다룹니다. 특히, 멀티 턴, 멀티 쿼리 등을 포함하는 복잡한 시나리오에서 정확하고 신뢰할 수 있는 RAG 시스템을 구축하는데 필요한 가이드를 제공하고자 합니다.
1.리랭커, RAG Reasoning API 소개
리랭커 API에 대한 내용은 이전 쿡북에서도 담고 있기 때문에 해당 섹션에서는 리랭커에 대한 간단한 설명와 RAG Reasoning 모델의 역할과 작동 원리, 그리고 이 둘을 효과적으로 결합했을 때 얻을 수 있는 시너지 효과에 대해 알아보겠습니다.
1.1 리랭커
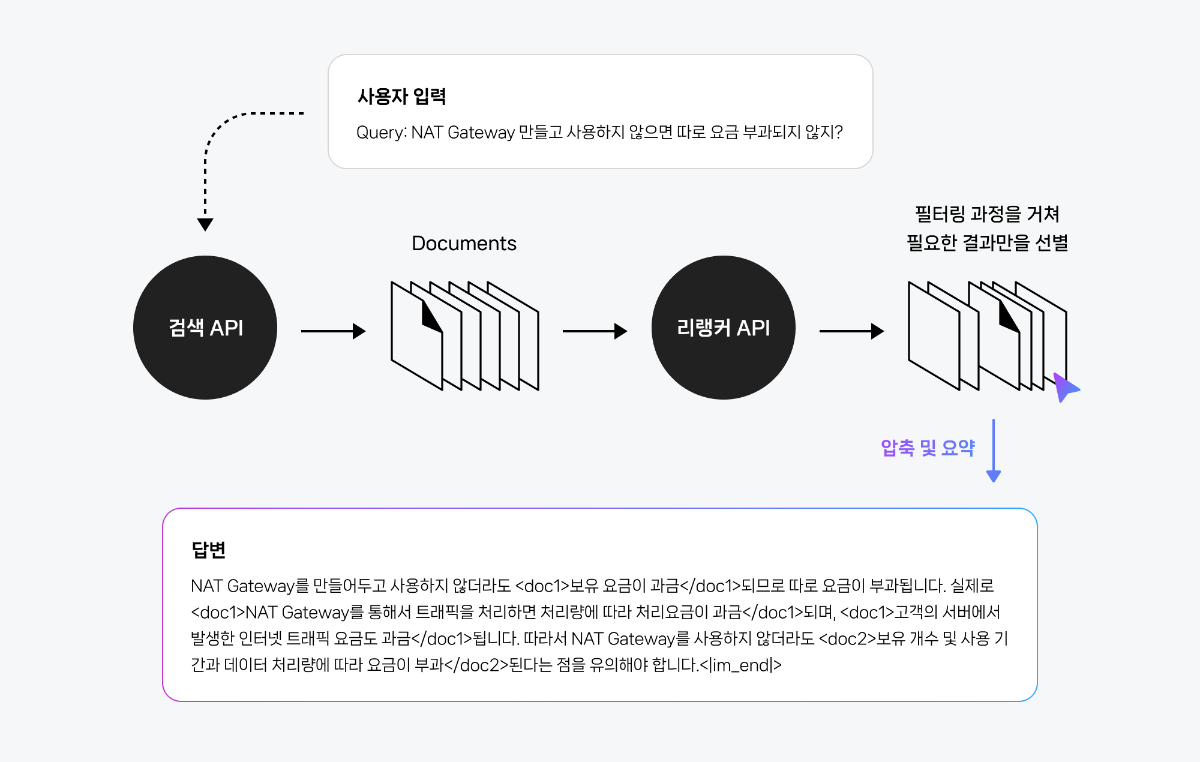
리랭커는 검색 API로 불러온 결과값을 보정합니다. 입력된 쿼리와 가장 관련성 높은 정보(문서)만을 선별하고 압축 요약하여 이를 바탕으로 RAG 답변을 만들어 낼 수 있습니다.
1.2 RAG Reasoning
RAG Reasoning은 RAG 용도로 튜닝된 추론 모델로, 검색 API를 호출하여 DB 내 문서들을 검색하고 그 결과를 바탕으로 적절한 답변을 생성합니다. RAG Reasoning은 인용 출처, 인덱싱 표기 등 신뢰성 있는 답변 표기가 가능하도록 튜닝된 모델을 기반으로 합니다. 또한, Function calling 형식을 갖추고 있기 때문에, 단일 또는 여러 개의 (검색) 함수를 정의해두고, 모델이 상황에 맞게 최적의 함수를 자율적으로 선택하여 호출하게 할 수 있습니다. 이처럼 RAG Reasoning은 유연하고 지능적인 함수 호출 능력과 더불어, 다양한 정보를 통합한 고품질의 LLM 답변 생성을 가능하게 합니다.
1.3 리랭커와 RAG Reasoning을 체이닝할 때 얻을 수 있는 장점
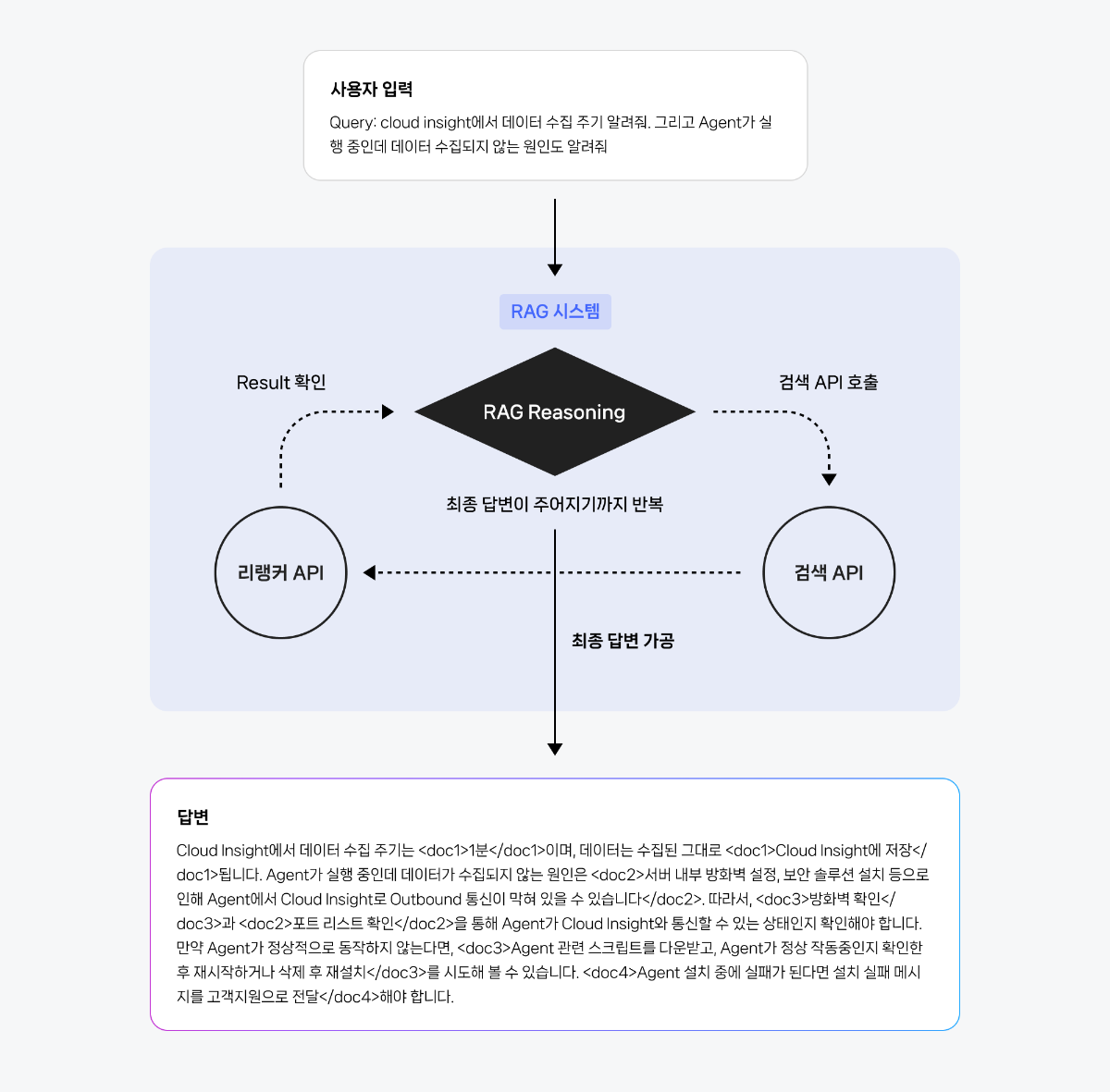
리랭커 기반 RAG 시스템은 간편한 구현과 싱글 쿼리에 대한 높은 검색 정확도를 제공하지만, 일상에서 흔히 발생하는 멀티 쿼리나 멀티 턴 대화를 처리하기는 어렵습니다. RAG Reasoning만으로 RAG 시스템을 구현하는 경우에도, 검색 API로부터 받은 결과를 통으로 추론 과정에 활용하게 될 가능성이 높기 때문에 토큰 효율적으로 모델을 이용하기에 불리할 수 있습니다. 이러한 한계를 극복하기 위해, 본 쿡북에서는 리랭커와 RAG Reasoning 체이닝 전략을 활용합니다. 리랭커와 RAG Reasoning을 결합한 Advanced RAG 시스템은 복합적인 요청의 유저 쿼리와, 멀티 턴 대화에서의 대응력을 높이고, RAG 답변의 품질을 향상 시키는 데 강점이 있습니다.
체이닝 구조에서는 유저의 쿼리가 들어오면, 먼저 RAG Reasoning이 쿼리에 맞는 검색 함수를 호출합니다. 함수(검색 API와 대응)로 부터 검색된 문서들은 리랭커로 전달됩니다. 리랭커는 검색 결과를 필터링하고 관련성 높은 정보를 선별하여 RAG Reasoning으로 보내줍니다. RAG Reasoning은 이 고품질의 정보를 바탕으로 최종 답변을 생성합니다.
이러한 체이닝 구조를 통해, 다음과 같은 이점들을 얻을 수 있습니다:
멀티 쿼리 지원: 사용자의 멀티 쿼리에 대해 각 질문의 의도를 정확히 파악하고 필요한 정보를 검색하여 통합적인 답변을 제공할 수 있습니다.
멀티 턴 대화 지원: RAG Reasoning이 대화의 맥락과 이전 질문-답변 이력을 관리하여 정보를 재구성할 수 있습니다. 이를 통해 멀티 턴 속에서도 일관성 있고 정확한 답변을 제공합니다.
답변 신뢰도 및 정확성 향상: 리랭커의 필터링 및 보정 기능이 더해진 RAG Reasoning은 더욱 정확하고 신뢰할 수 있는 출처 기반으로 답변을 생성할수 있게 됩니다. 이는 LLM의 환각 현상을 줄이는 데 효과적입니다.
2. 리랭커, RAG Reasoning 체이닝 시나리오
2.1 네이버 클라우드 플랫폼 CS 대응을 위한 RAG 시스템 구현
지금부터는 네이버 클라우드 플랫폼 서비스 CS 대응에 활용될 수 있는 RAG 시스템을 구축해보고자 합니다. 먼저, 네이버 클라우드 플랫폼의 다양한 CS용 데이터를 토대로 검색 가능한 형태의 API를 만든 뒤, 해당 API와 리랭커 그리고 RAG Reasoning 을 체이닝하여 구성할 계획입니다. CS 분야는 상품에 관련된 다양한 종류의 방대한 문서를 다루는 특성상, 고객 대응 담당자가 모든 정보를 완벽하게 숙지하기 어려운 현실적인 한계가 있습니다. 그렇기에 RAG 기술을 통해 대규모 데이터를 효율적으로 검색하고, 고객 문의에 대한 정확하고 일관된 답변을 신속하게 제공함으로써 관리자의 업무 효율성을 향상시킬 수 있습니다.
이번에 구축해 볼 CS 문의 대응을 위한 RAG 시스템은 사용 가이드 데이터와 FAQ 데이터를 검색가능한 형태로 전처리하여 구상한 뒤, 리랭커와 RAG Reasoning을 체이닝한 RAG 시스템을 적용하여 고객 문의에 대한 정확하고 근거있는 답변을 제공하는 것을 목표로 합니다. 체이닝 구조는 싱글 쿼리뿐만 아니라, 멀티 쿼리 대응에도 용이합니다. 참고로, 멀티 쿼리 시나리오는 유저가 "A에 대해 알려줘. 그리고 B에 대한 내용도 궁금해."와 같이 하나의 문장 안에 여러 개의 독립적이거나 상호 연관된 질문을 포함하는 경우를 의미합니다. 우리가 구현할 RAG 시스템은 다음과 같은 워크플로우로 실행됩니다.
자세한 전체 파이프라인에 대한 코드 구현은 '2.2 코드 구성' 파트에서 서술하겠습니다.
2.1.1 사용 데이터
사용 가이드 : 네이버 클라우드 플랫폼의 가이드 센터에서 제공하는 '사용 가이드' 를 활용합니다.
유저 가이드에 대한 자세한 정보는 NCloud 가이드에서 확인할 수 있습니다.
FAQ 데이터: 네이버 클라우드 '자주 묻는 질문'을 가공한 데이터셋 입니다.
2.1.2 검색 API 구현
네이버 클라우드 플랫폼의 가이드 문서와 자주 묻는 질문(FAQ) 데이터를 기반으로, 유저 쿼리에 가장 적합한 문서를 찾아 제공하는 검색 API를 구성합니다. 검색 API는 사용자가 가지고 있는 데이터(혹은 데이터베이스)를 검색 가능한 형태로 만들어 RAG Reasoning에 제공하는 역할을 합니다. Function Calling 형식의 RAG Reasoning 내부에 함수를 정의하고 해당 함수에 맞는 검색 API를 1대1로 매핑함으로써, 유저 쿼리에 맞는 함수와 검색 API를 호출할 수 있습니다. 사용자는 데이터 구조별로 검색 API를 분리 구성하고, 이를 각각 독립적인 함수로 RAG Reasoning 내부에 정의함으로써 보다 정교한 RAG 시스템을 구현할 수 있습니다.
데이터 준비 : 사용 가이드와 FAQ 데이터를 결합하고 중복 제거, 이미지 제거 등 전처리 작업을 수행하고 csv 형태로 통합합니다.
임베딩 생성 : CLOVA Studio의 embedding 모델 API를 호출하여 각 텍스트 데이터에 대해 벡터 임베딩을 생성하고, 이를 새로운 컬럼으로 추가합니다.
CLOVA Studio의 embedding에 대한 자세한 정보는 embedding 가이드에서 확인할 수 있습니다.
구현의 편의를 위해 임베딩 파일을 첨부해 두었습니다. (파일: CLOVA_Studio.csv)
검색 API 구성 : 유저 쿼리를 임베딩한 뒤 기존에 생성한 문서 임베딩 간의 코사인 유사도를 계산하여 가장 관련성 높은 상위 문서들을 반환하는 검색 API를 구성합니다. FastAPI 기반으로 활용할 수 있도록 설정해주었습니다.
쿡북 코드 예시는 아래와 같은 로컬 환경 경로에 검색 API를 구현하는 것을 전제로 합니다
http://127.0.0.1:8000/
다음 명령어를 터미널에 입력하면 FastAPI 서버를 실행할 수 있습니다.
uvicorn filename:app --reload
2.2 코드 구성
먼저 필수 라이브러리를 임포트 합니다.
import requests
import json
예제 코드는 Python 3.11.1에서 실행 확인하였으며, 최소 Python3.7 이상을 필요로 합니다.
간단한 예시를 위해 tqdm 라이브러리는 포함하지 않았지만, 실제 문서의 양이 많아질 경우 진행 상황을 시각적으로 확인할 수 있어 활용하기를 권장합니다.
2.2.1 RAG Reasoning 정의
RAG Reasoning은 Function Calling 형식의 엔진 호출을 제공하기 때문에 해당 형식에 따라 목적에 맞는 검색 함수들을 정의하여 작성합니다. 실제 서비스에서는 다양한 검색 목적에 맞춰 여러 개의 검색 함수를 정의하거나 검색이 아닌 다양한 목적의 함수들을 정의할 수 있지만, 본 예시에서는 시나리오의 이해를 돕기 위해 하나의 검색 함수만을 정의하였습니다.
RAG Reasoning은 Function calling 형식으로 정의된 함수들의 설명(function의 description)을 참고하고 스스로 판단하여 입력된 쿼리(query)에 필요한 (검색) 함수를 호출합니다. 호출된 검색 함수('ncloud_cs_retrieval')는 2.1.2에서 구현한 검색 API를 통해 입력 쿼리와 관련된 문서 검색을 실행합니다. 그 결과는 리랭커에 의해 정제되어 'document_list'에 저장됩니다. RAG Reasoning은 'document_list'를 확인한 후, 검색 함수 호출 대신 'document_list'를 'search_result' 형태로 변환하여 최종 답변 생성에 활용합니다.
def build_reasoning(query=None, document_list=None, sugquery_list=None, messages=None, tool_calls=None):
# 1단계: 메시지 리스트 초기화
msg_list = []
if messages:
msg_list = messages
# 2단계: 현재 사용자 질문 추가
if query:
msg_list.append({"role": "user", "content": query})
# 3단계: 도구 호출 또는 검색 결과가 있다면 추가
if tool_calls:
# tool_calls는 assistant role 메시지에 포함
msg_list.append({"role": "assistant", "content": "", "toolCalls": tool_calls})
# 검색 결과는 tool role 메시지로 추가
if document_list:
formatted_documents = [{"id": f"doc-{doc['id']}", "doc": doc["doc"]} for doc in document_list]
tool_content = json.dumps({"search_result": formatted_documents}, ensure_ascii=False)
# 모든 tool_call에 대해 동일한 검색 결과를 반환
for tool_call in tool_calls:
msg_list.append({
"role": "tool",
"name": tool_call['function']['name'],
"content": tool_content,
"toolCallId": tool_call['id']
})
# 4단계: 최종 페이로드 구성
payload = {
"messages": msg_list,
"maxTokens": 4000, # maxTokens 파라미터 추가
"tools": [
{
"function": {
"description": "NCloud 관련 검색을 할 때 사용하는 도구입니다.\n나누어 질문해야 하는 경우 쿼리를 쪼개 나누어서 도구를 사용합니다.\n정보를 찾을 수 없었던 경우, 최종 답을 하지 않고 sugquery_list를 참고하여 도구를 다시 사용할 수 있습니다.",
"name": "ncloud_cs_retrieval",
"parameters": {
"properties": {
"query": {
"description": "사용자의 검색어를 정제해서 넣으세요.",
"type": "string"
},
"url": {
"description": "검색 API 서버의 엔드포인트 URL을 입력하세요.",
"type": "string"
}
},
"required": [
"query",
"url"
],
"type": "object"
}
},
"type": "function"
}
],
"toolChoice": "auto"
}
# 추천 검색어가 있다면 페이로드에 추가
if sugquery_list:
payload['suggestedQueries'] = sugquery_list
return payload
build_reasoning 함수는 RAG Reasoning에 전달할 payload를 생성하는 함수입니다. 'query'는 단일 유저 쿼리이고, 'messages'는 멀티 턴 대화 히스토리입니다.
'document_list'가 있는 경우 리랭커에서 선별된 'citedDocuments'를 'search_result'로 구성하여 모델이 답변 생성 시 직접 참고할 수 있도록 제공합니다.
'sugquery_list'가 있는 경우 리랭커에서 적절한 문서를 찾지 못했을 때 제공되는 'suggestedQueries'를 참고하여 재검색 가이드를 제공합니다.
'toolChoice'는 auto로 설정하여 모델이 도구 호출 여부를 자율적으로 결정하게 합니다.
요청과 응답을 포함한 RAG Reasoning API에 대한 자세한 가이드는 [API 가이드] RAG Reasoning를 참고해 주세요.
RAG Reasoning 코드의 요청(Request) 예시는 다음과 같습니다.
위 코드에 대한 RAG Reasoning의 응답(Response) 예시는 다음과 같습니다.
2.2.2 검색 API 호출
검색 함수는 2.1.2에서 구현한 검색 API를 통해 유저 쿼리와 관련된 상위 문서들을 검색하여 반환합니다.
def ncloud_cs_retrieval(query, search_api_url):
headers = {
'accept': 'application/json',
'Content-Type': 'application/json',
}
json_data = {
'query': query,
'top_k': 5,
}
response = requests.post(search_api_url, headers=headers, json=json_data)
response.raise_for_status()
return response.json()['result']
'query'는 처음 RAG Reasoning에 인풋으로 넣은 유저의 쿼리 전문이 아닌 ncloud_cs_retrieval 함수가 정제한 검색어 입니다.
'top_k'는 출력할 검색 결과 상위 문서 설정 개수를 의미합니다. 본 코드에서는 편의상 5로 설정하였으나, 필요에 따라 자유롭게 조정이 가능합니다.
검색 API 요청(Request) 예시는 다음과 같습니다.
위 코드에 대한 검색 API 응답(Response) 예시는 다음과 같습니다.
2.2.3 리랭커 API 호출
검색 단계에서 가져온 문서들은 관련성이 떨어지는 내용이 포함될 수 있습니다. 리랭커 API는 이러한 문서들 중에서 유저 쿼리와 가장 적합한 핵심적인 문서를 선별하여 RAG Reasoning이 최종 답변을 생성할 때 참조할 수 있도록 돕습니다.
def reranker_function(query, documents, api_url, api_key):
headers = {
'Authorization': f'Bearer {api_key}',
'Content-Type': 'application/json',
}
# 유효한 문서만 필터링 (빈 내용, None, NaN 제외)
indexed_documents = [
{"id": str(doc["id"]), "doc": doc["content"]}
for doc in documents
if doc.get("content") not in [None, "", "None", "nan", "NaN"]
]
json_data = {
"query": query,
"documents": indexed_documents,
"maxTokens": 4000 # 응답 토큰 수 범위 설정
}
response = requests.post(api_url, headers=headers, json=json_data)
response.raise_for_status()
result = response.json()
# 리랭커 결과에서 관련 문서와 추천 검색어만 추출하여 document_list와 sugquery_list에 저장
document_list = result.get('result', {}).get('citedDocuments', [])
sugquery_list = result.get('result', {}).get('suggestedQueries', [])
return document_list, sugquery_list
검색 API의 결과값인 문서와 고유 id를 입력받습니다. 리랭커 함수는 RAG Reasoning에 전달하기 위해 응답 파라미터로 'citedDocuments' 값을 반환합니다.
리랭커의 답변인 'result'가 아닌 'citedDocuments'만을 RAG Reasoning에 전달하는 이유는 불필요한 부가 정보를 제외하고 실제 답변 생성에 필요한 문서 원문만을 전달함으로써 토큰 낭비를 줄이며, 리랭커가 선별한 문서를 기반으로 RAG Reasoning 이 한번 더 생각/처리하여 최종 답변을 생성내도록 하기 위함입니다.
요청과 응답을 포함한 리랭커 API에 대한 더욱 자세한 가이드는 [API 가이드] 리랭커를 참고해 주세요.
리랭커 API 요청(Request) 예시는 다음과 같습니다.
위 코드에 대한 리랭커 API 응답(Response) 예시는 다음과 같습니다.
2.2.4 전체 워크 플로우 실행
앞서 정의한 펑션 콜링, 검색 함수, 리랭커 함수들을 통합하고 최종 답변을 생성하는 전체 RAG 체이닝 워크플로우를 구현합니다. RAG Reasoning이 유저 쿼리를 분석하고, 필요시 검색 함수를 호출하여 관련 문서를 수집한 후 리랭커로 문서를 선별하는 과정을 반복하여, 최종적으로 핵심 문서 기반 정확한 답변 생성을 목적으로 합니다.
def run_reasoning(user_query_or_messages, search_api_url, reranker_api_url, api_key, reasoning_endpoint):
all_document_list = []
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
# 멀티턴일 경우, 현재 질문과 대화 히스토리를 분리
current_query = user_query_or_messages
message_history = None
if isinstance(user_query_or_messages, list) and user_query_or_messages:
current_query = user_query_or_messages[-1]['content']
message_history = user_query_or_messages[:-1] if len(user_query_or_messages) > 1 else None
# 최대 3번까지 반복 (무한 루프 방지)
for iteration in range(3):
# Step 1: 페이로드 생성
if iteration == 0:
# 첫 번째 호출: 검색 (문서 없음)
payload = build_reasoning(query=current_query, messages=message_history)
else:
# 두 번째 이후 호출: 답변 생성 (문서 있음)
payload = build_reasoning(query=current_query, messages=message_history, document_list=all_document_list)
# Step 2: RAG Reasoning API 호출
response = requests.post(reasoning_endpoint, headers=headers, json=payload)
response.raise_for_status()
reasoning_result = response.json()
# Step 3: 응답 분석
message = reasoning_result.get("result", {}).get("message", {})
tool_calls = message.get("toolCalls", []) # 검색 도구 호출 여부
content = message.get("content", "") # 최종 답변 내용
# Case A: tool_calls가 없음 → 모델이 더 이상 검색할 필요가 없다고 판단
# 검색 함수 호출 X
if not tool_calls:
return content if content else "답변을 생성할 수 없습니다."
# Case B: tool_calls가 있음 → Step 4로 이동하여 검색 실행
all_sugquery_list = [] # 검색 실패 시 추천 검색어 수집
# Step 4: 검색 함수 호출에 대해 검색-리랭커 실행
for i, tool_call in enumerate(tool_calls):
search_query = tool_call['function']['arguments']['query']
# Step 4-1: 검색 실행
search_results = ncloud_cs_retrieval(search_query, search_api_url) # search_results는 검색 함수의 결과 값으로 RAG Reasoning의 입력 파라미터인 'search_result'와는 다른 값입니다.
# Step 4-2: 리랭커 실행
document_list, sugquery_list = reranker_function(search_query, search_results, reranker_api_url, api_key)
# Step 4-3: 결과 처리
if document_list:
# 리랭커의 결과물인 document_list가 있는 경우: 중복 제거하여 누적
for doc in document_list:
# 중복 문서 체크
if not any(existing_doc['id'] == doc['id'] for existing_doc in all_document_list):
all_document_list.append(doc)
elif sugquery_list:
# 관련 문서를 찾지 못하여 document_list가 없는 경우: 추천 검색어를 재검색용으로 수집
all_sugquery_list.extend(sugquery_list)
# Step 5: 수집된 문서로 최종 답변 생성 시도
if all_document_list:
# 문서가 있으므로 최종 답변 생성 (모든 tool_calls 정보 사용)
payload = build_reasoning(query=current_query, messages=message_history, document_list=all_document_list, tool_calls=tool_calls)
final_response = requests.post(reasoning_endpoint, headers=headers, json=payload)
final_response.raise_for_status()
final_result = final_response.json()
final_content = final_result.get("result", {}).get("message", {}).get("content", "")
return final_content if final_content else "답변을 생성할 수 없습니다."
# Step 6: 재검색 실행 (document_list가 없지만 추천 검색어가 있는 경우)
if all_sugquery_list:
# 추천 검색어를 사용하여 다음 iteration에서 재검색
payload = build_reasoning(query=current_query, messages=message_history, sugquery_list=all_sugquery_list)
continue # 다음 반복으로 이동
# 문서도 없고 추천 검색어도 없는 경우 → 검색 중단
break
# 3번 반복 후에도 결과가 없는 경우
return "검색된 문서가 없어 답변을 생성할 수 없습니다."
여러 번의 검색 및 리랭커 API 활용 과정에서 선별된 모든 문서를 누적하여, 최종 답변 생성 시 RAG Reasoning이 더 광범위한 정보를 참조할 수 있도록 설계합니다.
RAG Reasoning이 도구 호출을 무한 반복하지 않도록, 'max_iterations'=3으로 제한합니다.
전체 체이닝 코드의 실행을 위한 요청(Request) 예시는 다음과 같습니다.
위 코드를 실행한 응답 (Request) 예시는 다음과 같습니다.
3. 유저 쿼리 실행 예시
3.1 멀티 쿼리 실행 예시
실제 RAG 시스템을 실행하고 동작을 확인하는 부분입니다. 멀티 쿼리에 대해 RAG Reasoning, 리랭커 활용 체이닝 파이프라인이 어떻게 작동하여 최종 답변을 생성하는지 예시로 소개해 보고자 합니다.
if __name__ == "__main__":
search_api_url = "http://127.0.0.1:8000/search/"
reranker_api_url = "https://clovastudio.stream.ntruss.com/v1/api-tools/reranker"
reasoning_endpoint = "https://clovastudio.stream.ntruss.com/v1/api-tools/rag-reasoning"
api_key = "API_KEY"
user_query = "스킬 트레이너가 제공하는 스킬셋을 삭제하는 방법은 뭐야? 그리고 하나의 스킬셋에 몇 개의 스킬을 생성할 수 있는지 알려줘" #멀티 쿼리 예시
print(f"질문: {user_query}")
result = run_reasoning(user_query, search_api_url, reranker_api_url, api_key, reasoning_endpoint)
print(f"최종 답변: {result}")
실제 실행시에는 발급받은 api_key와 목적에 맞는 유저 쿼리를 입력합니다.
입력된 유저 쿼리(스킬 트레이너가 제공하는 스킬셋을 삭제하는 방법은 뭐야? 그리고 하나의 스킬셋에 몇 개의 스킬을 생성할 수 있는지 알려줘)에 대한 출력 결과는 다음과 같습니다.
스킬 트레이너가 제공하는 스킬셋을 삭제하는 방법은 <doc-76>네이버 클라우드 플랫폼 콘솔에서 Services > AI Services > CLOVA Studio 메뉴를 차례대로 클릭한 후, My Product 메뉴에서 [CLOVA Studio 바로가기] 버튼을 클릭하고, CLOVA Studio에서 스킬 트레이너 메뉴를 클릭하여 스킬셋의 삭제 메뉴를 클릭하고, 스킬셋 삭제 창이 나타나면 [삭제] 버튼을 클릭하는 것입니다.</doc-76> 단, <doc-76>서비스 앱 발급 이력이 있는 스킬셋은 삭제할 수 없습니다.</doc-76> 하나의 스킬셋에 생성 가능한 스킬의 개수는 <doc-100>최대 10개까지 생성할 수 있습니다.</doc-100>
3.2 멀티 턴 실행 예시
앞서 다룬 예시는 멀티 쿼리 시나리오의 전체 프로세스를 보여주었습니다. 이 체이닝 시스템은 싱글 쿼리에도 효과적으로 작동할 수 있습니다. 지금부터는 RAG 시스템이 이전 대화의 맥락을 이해하고 후속 질문에 답변하는 '멀티 턴' 시나리오를 어떻게 처리하는지 보여주는 예시를 실행해보고자 합니다. 첫 번째 질문에 대한 답변 후, 사용자가 그 답변과 관련된 추가 질문을 했을 때, 시스템이 이전 대화 기록을 참고하여 자연스럽고 정확한 응답을 생성하는 과정을 보여줍니다.
if __name__ == "__main__":
search_api_url = "http://127.0.0.1:8000/search/" # 앞서 구현한 검색 API 기본 주소
reranker_api_url = "https://clovastudio.stream.ntruss.com/v1/api-tools/reranker"
reasoning_endpoint = "https://clovastudio.stream.ntruss.com/v1/api-tools/rag-reasoning"
api_key = "API_KEY"
# 첫 번째 질문
user_query = "플레이그라운드가 뭐야?"
answer1 = run_reasoning(user_query, search_api_url, reranker_api_url, api_key, reasoning_endpoint)
print("[답변 1]", answer1)
# 두 번째 질문
user_query2 = "챗 모드 사용하는 방법을 알려줘"
messages = [ # 메세지 리스트 형태로 제공
{"role": "user", "content": user_query},
{"role": "assistant", "content": answer1},
{"role": "user", "content": user_query2}
]
answer2 = run_reasoning(messages, search_api_url, reranker_api_url, api_key, reasoning_endpoint)
print("\n[답변 2]", answer2)
멀티 턴 예시의 핵심은 두 번째 질문에서 전달되는 'messages' 리스트 입니다. 리스트에는 해당 시점의 유저 쿼리와 함께 이전 대화 기록(앞선 유저 쿼리와 그에 대한 답변을 의미)을 순서대로 담아 전달합니다.
해당 과정을 통해 RAG Reasoning은 이전 대화 내용을 기반으로 현재 질문의 맥락과 자연스러운 답변 생성을 할 수 있게 됩니다.
예시 코드에서 입력한 값을 바탕으로 출력한 결과는 다음과 같습니다.
[답변 1] 플레이그라운드는 <doc-22>프롬프트 입력과 파라미터 설정을 이용해 HyperCLOVA X 모델을 활용할 수 있는 공간</doc-22>으로, <doc-22>챗 모드와 일반 모드를 제공하여 원하는 결과를 생성할 수 있으며, 다양한 기능을 통해 작업 관리와 결과물을 저장하고 공유할 수 있는 환경을 제공합니다.</doc-22> 또한, <doc-31>네이버 AI 윤리 준칙 준수의 관점에서 사용자는 AI Filter 기능을 설정할 수 있으며, 이 기능은 플레이그라운드에서 생성된 테스트 앱으로부터 부적절한 결과물이 출력되는 것을 감지하여 사용자에게 알려주는 역할을 합니다.</doc-31>
[답변 2] 챗 모드를 사용하는 방법은 <doc-23>네이버 클라우드 플랫폼 콘솔에서 Services > AI Services > CLOVA Studio 메뉴를 차례대로 클릭한 후, My Product 메뉴를 클릭하고 [CLOVA Studio 바로가기] 버튼을 클릭하여 플레이그라운드 메뉴를 클릭하는 것으로 시작합니다.</doc-23> 이후에는 <doc-23>파라미터를 설정하고, 작업 제목을 입력한 다음, 시스템 영역에 모델이 수행할 작업에 대한 구체적인 지시문 또는 예제를 입력합니다.</doc-23> 또한, <doc-23>사용자와 어시스턴트의 대화 내용을 입력한 후, 필요한 경우 [대화 턴 추가] 버튼을 클릭하여 질문과 답변을 추가하고, [실행] 버튼을 클릭하여 작업을 실행합니다.</doc-23> 만약 실행 결과가 만족스럽지 않다면, 내용을 지운 후 다시 실행하거나 예제를 수정한 후 다시 실행할 수 있습니다. <doc-23>작업 실행, 작업 저장, 작업 공유, 테스트 앱 생성, 서비스 앱 신청 등의 추가 절차를 진행할 수 있습니다.</doc-23>
4. 결론
이번 쿡북을 통해 CLOVA Studio의 리랭커 API와 RAG 리즈닝 API를 연동하여 복잡한 CS 문의에 대응하는 RAG 시스템을 구축하는 과정을 살펴보았습니다. 이러한 리랭커 - RAG Reasoning 체이닝 구조는 CS 문의 대응 뿐 만 아니라, 다양한 산업 영역의 복합적인 문제 해결에 폭넓게 활용될 수 있습니다. 실제 서비스 환경에 최적화된 RAG 시스템을 구축하는 데 Clova Studio의 기능과 본 쿡북이 실질적인 지침이 될 수 있기를 바라면서, 여러분의 창의성을 맘껏 발휘하여 업무 환경에 맞는 강력한 RAG 시스템을 자유롭게 설계하고 확장해 나가시길 바랍니다!

")