CLOVA Studio 운영자
-
게시글
301 -
첫 방문
-
최근 방문
-
Days Won
54
Recent Profile Visitors
4,866 profile views





CLOVA Studio 운영자's Achievements
")





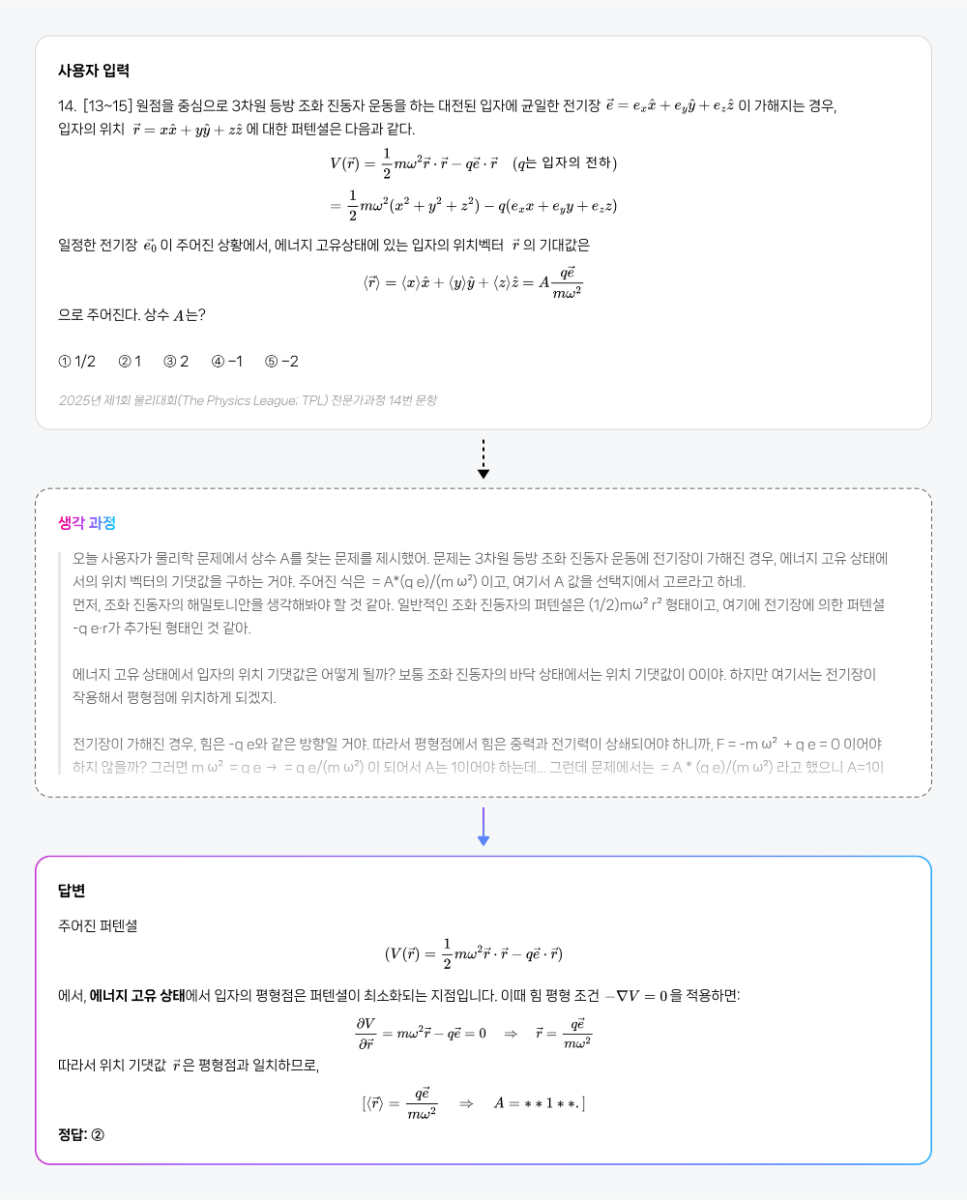
-
안녕하세요, @toracle님, 서비스 신청을 완료 하셨다면, API 키에서 서비스 API 키 발급이 가능합니다. 아래 API 키 화면의 우측 상단에 있는 '서비스 API 키 발급' 버튼을 눌러보셨을까요? 해당 버튼을 누르면 발급할 수 있는 팝업이 나타납니다. 감사합니다.
-

(3부) CLOVA Studio를 이용해 RAG 구현하기
CLOVA Studio 운영자 replied to CLOVA Studio 운영자's topic in 활용법 & Cookbook
안녕하세요, @sseul님, API 연동/이용 방식이 간소화 되었습니다. 이제는 테스트 앱을 생성할 필요 없이 API 키 발급만으로 바로 CLOVA Studio의 모든 기능을 API로 이용하실 수 있습니다. 좌측의 API 키 메뉴를 통해 테스트 API 키 발급 부탁드립니다. https://guide.ncloud-docs.com/docs/clovastudio-playground-viewsource 감사합니다. -
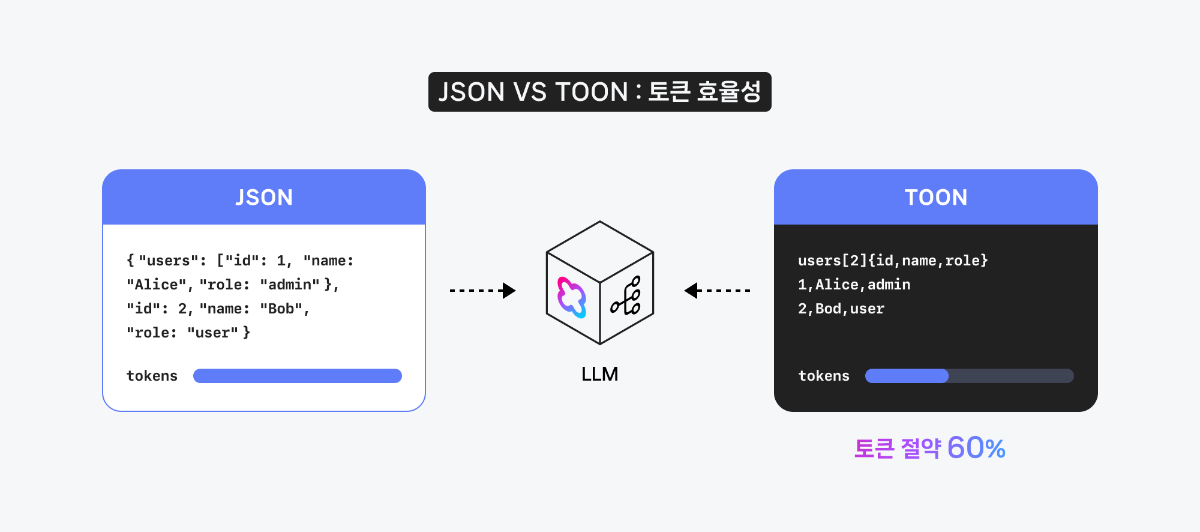
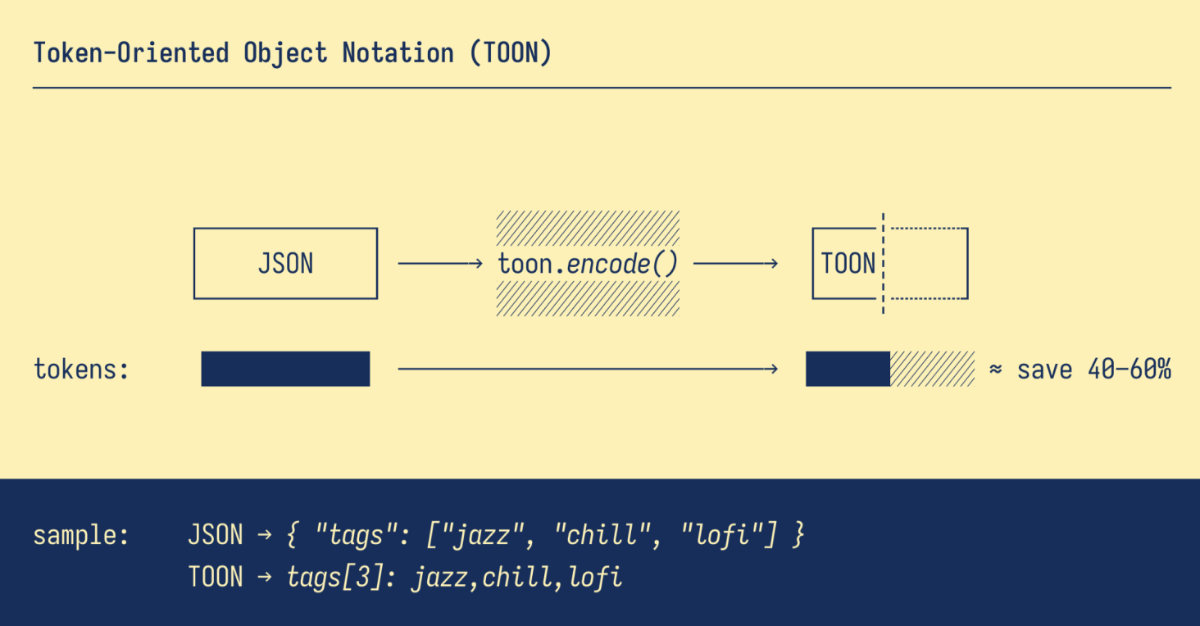
TOON, LLM 입력 구조를 다시 생각하게 만든 포맷 대규모 언어 모델(LLM)에서 연산 속도와 토큰 효율을 높이면서 응답 품질을 유지하거나 향상시키려는 시도는 계속되고 있습니다. 특히 엔터프라이즈 환경에서는 토큰 사용량과 Latency가 곧 비용과 사용자 경험으로 직결됩니다. JSON은 구조가 명확하고 범용성이 높아 LLM 입력 포맷으로 널리 활용되고 있습니다. 그러나 반복되는 key-value 구조와 다양한 구분자는 토큰 소모를 빠르게 증가시키고, 결국 연산 비용이 증가하는 문제도 있습니다. 오늘은 이러한 문제를 해결하기 위해 등장한 TOON(Token-Oriented Object Notation) 포맷을 살펴봅니다. TOON은 JSON의 표현력을 유지하면서도, 동일한 정보를 더 간결하게 표현해 토큰 사용량을 줄이고 LLM이 구조를 더 효율적으로 해석하도록 설계된 입력 포맷입니다. TOON의 경량화된 구조 이미지 출처: https://github.com/toon-format/toon TOON은 반복되는 객체 리스트를 탭형(tabular) 구조로 표현할 수 있도록 설계된 입력 포맷입니다. 계층 구조는 들여쓰기로 유지하면서, 동일한 구조의 배열에 대해서는 필드 목록을 한 번만 선언하고 이후 값을 행(row) 단위로 나열합니다. 이 방식은 JSON에서 반복적으로 등장하는 key-value 구조를 제거해 입력을 간결하게 만듭니다. 반복된 구조를 압축적으로 표현해 토큰 사용량을 크게 줄일 수 있습니다. 모델이 구조를 더 쉽게 파악해 특정 Task에서 속도 개선 가능성이 있습니다. 사람이 읽고 비교, 검수하기 쉬운 간결한 구조를 제공합니다. 예를 들어 JSON의 product 리스트가 다음과 같다면, { "products": [ { "product_id": "301", "name": "무선 마우스", "price": "29900", "stock": "재고 있음", "rating": "4.5" }, { "product_id": "302", "name": "기계식 키보드", "price": "89000", "stock": "재고 부족", "rating": "4.8" }, { "product_id": "303", "name": "USB-C 허브", "price": "45500", "stock": "품절", "rating": "4.1" } ] } TOON에서는 아래와 같이 표현할 수 있습니다. products[3]{product_id,name,price,stock,rating}: 301,무선 마우스,29900,재고 있음,4.5 302,기계식 키보드,89000,재고 부족,4.8 303,USB-C 허브,45500,품절,4.1 동일한 정보이지만 반복되는 key가 제거되면서 토큰 사용량은 크게 줄어들고, LLM이 인식해야 할 구조 역시 훨씬 단순해집니다. 입력 포맷별 벤치마크 결과 다음은 TOON GitHub에서 공개된 벤치마크 결과입니다. TOON, JSON, YAML, XML 등 주요 포맷을 대상으로 비교 실험을 진행했습니다. 입력 포맷의 효율성은 1,000 토큰당 정확도(acc% / 1K tokens) 기준으로 평가되었습니다. 즉, 같은 질문을 풀었을 때의 정답률을 토큰 사용량으로 나눈 지표입니다. 이 기준에서 TOON은 JSON 대비 약 39.6% 적은 토큰을 사용하면서도, 더 높은 정확도(73.9% vs 69.7%)를 기록했습니다. 즉, 표현 방식만 바꿨는데도, 토큰 대비 성능 지표에서 변화가 관찰되었습니다. ※ CSV는 단순한 테이블 데이터에서는 매우 효율적이지만, 복합적인 구조를 표현하는 데 한계가 있어 전체 비교에서는 제외되었습니다. HyperCLOVA X 모델로 실험하기 CLOVA Studio에서 HyperCLOVA X 모델을 활용해 JSON과 TOON을 비교했습니다. 이번 실험은 입력 포맷을 변경했을 때 나타나는 차이와 특성을 살펴보는 데 초점을 두었습니다. 1. 단순 구조 데이터 대규모 JSON 배열을 그대로 전달하는 상황에서는 TOON의 특성이 비교적 명확하게 드러났습니다. 동일한 데이터를 TOON 형식으로 변환했을 때, Prompt token 사용량이 약 27.3% 감소했습니다. 2. Reasoning 중심 Task KMMLU와 같은 추론 중심 Task에서는 JSON이 더 안정적인 결과를 보였습니다. 정답률 측면에서 JSON이 우세했으며, TOON의 토큰 효율성은 이 영역에서 의미 있는 차이를 만들지 못했습니다. 3. RAG 기반 Task RAG 기반 Task에서는 일부 작업에서 긍정적인 경향이 관찰되었습니다. 특히 요약, 비교, 추천, 정보 추출처럼 Retrieval 결과를 후처리하는 유형의 Task에서 TOON이 상대적으로 안정적인 성능을 보였습니다. 4. API 응답/로그 분석 API 응답이나 로그 데이터처럼 반복 패턴이 많은 데이터를 다루는 Task에서도 TOON이 유리한 경향을 보였습니다. 이상 탐지, 패턴 분석, 단순 요약과 같은 작업에서 입력 크기가 줄어들면서 처리 효율이 개선되는 모습을 확인할 수 있었습니다. 마치며 모델 자체를 변경하지 않고 입력 포맷을 조정하는 것만으로도, 특정 유형의 작업에서는 토큰 사용량과 처리 효율에 차이를 만들 수 있음을 확인했습니다. TOON은 모든 상황에 적용할 수 있는 해법은 아니지만, 구조가 단순하고 반복적인 데이터가 많은 영역에서는 하나의 선택지가 될 수 있습니다. 결국 LLM 입력에서도 중요한 것은, 정보를 얼마나 효율적인 형태로 전달하고 있는가일 것입니다. 이번 포스팅은 여기서 마무리하며, 다음에도 유용한 활용 팁으로 찾아오겠습니다.

-
안녕하세요, @leeeg님, 클로바 스튜디오 이용 요금은 아래 링크에서 확인하실 수 있습니다. https://www.ncloud.com/v2/product/aiService/clovaStudio#pricing 감사합니다.
-
안녕하세요, @태훈2님, 현재 이미지를 포함한 학습은 지원하지 않고 있습니다. 감사합니다.
-
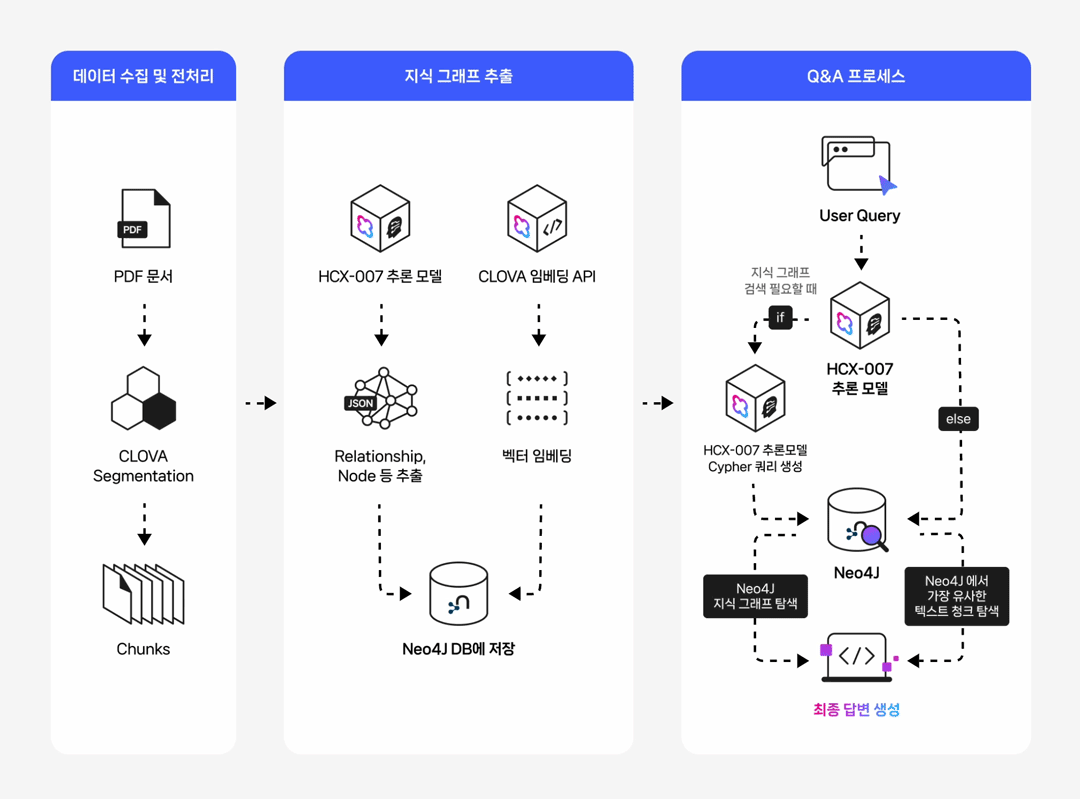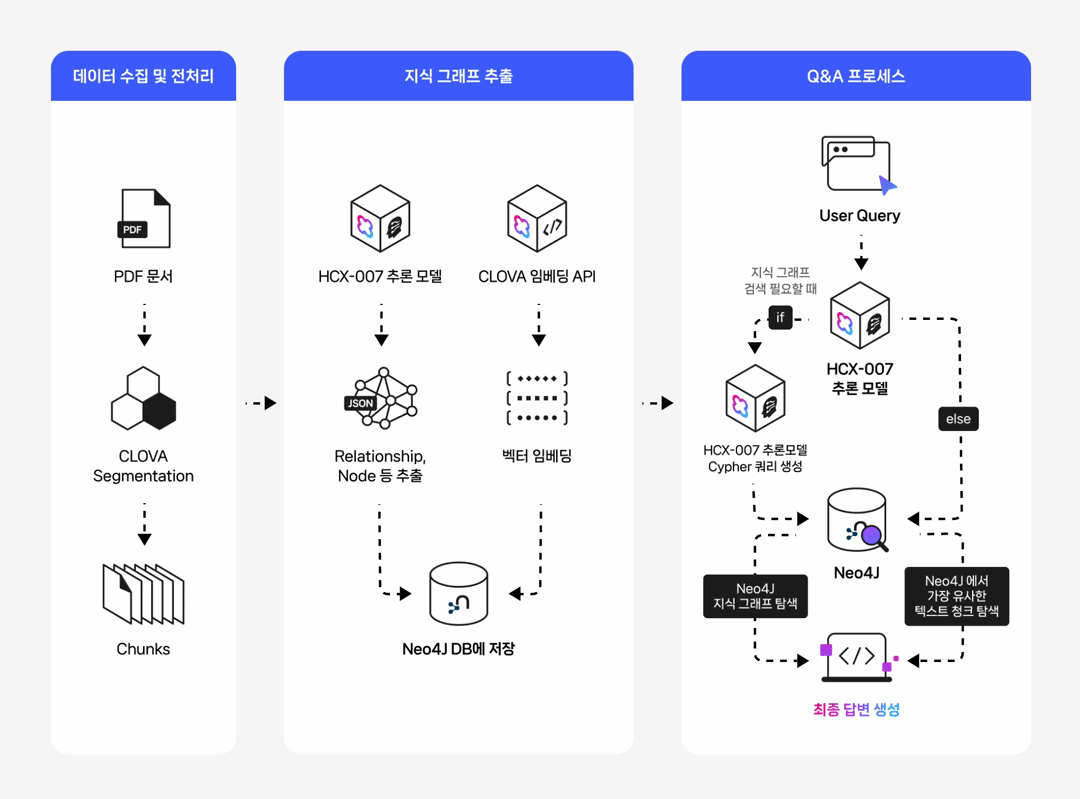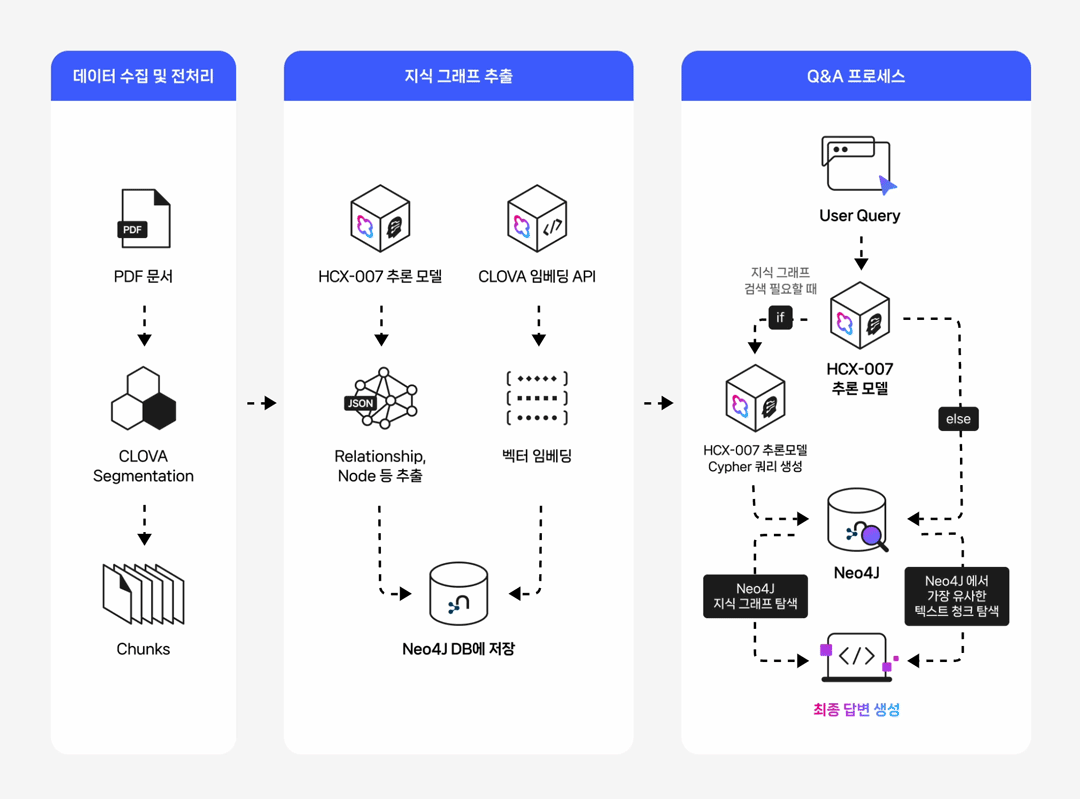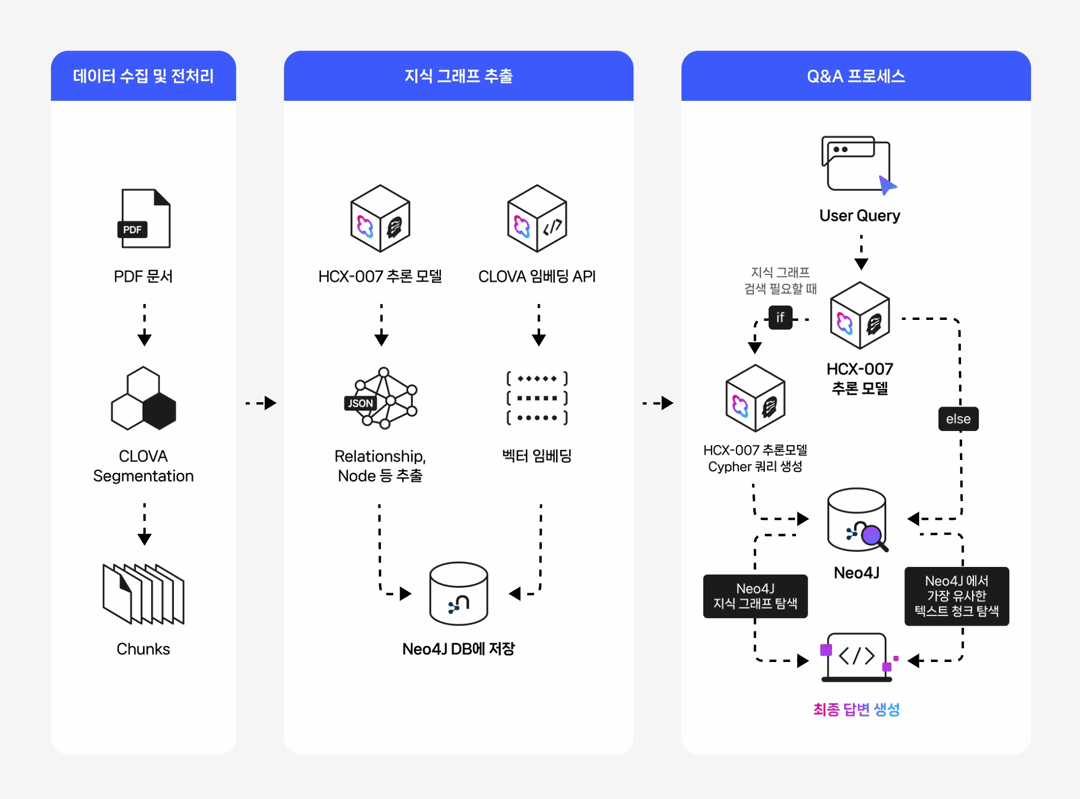
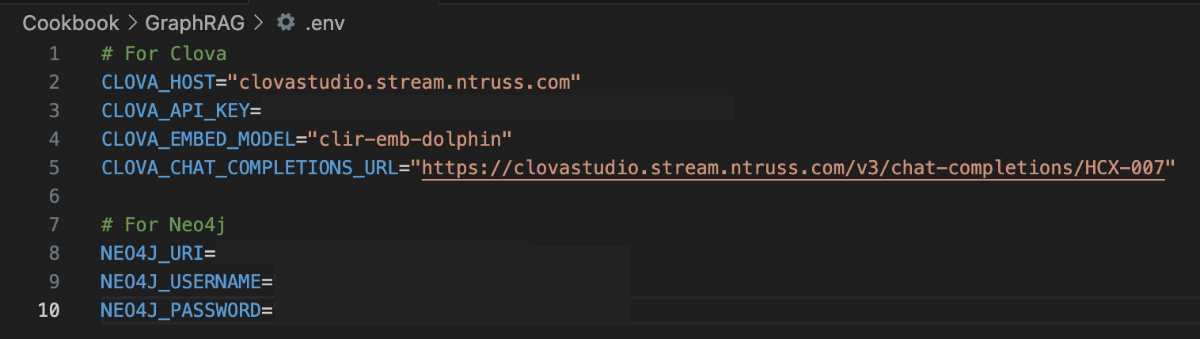
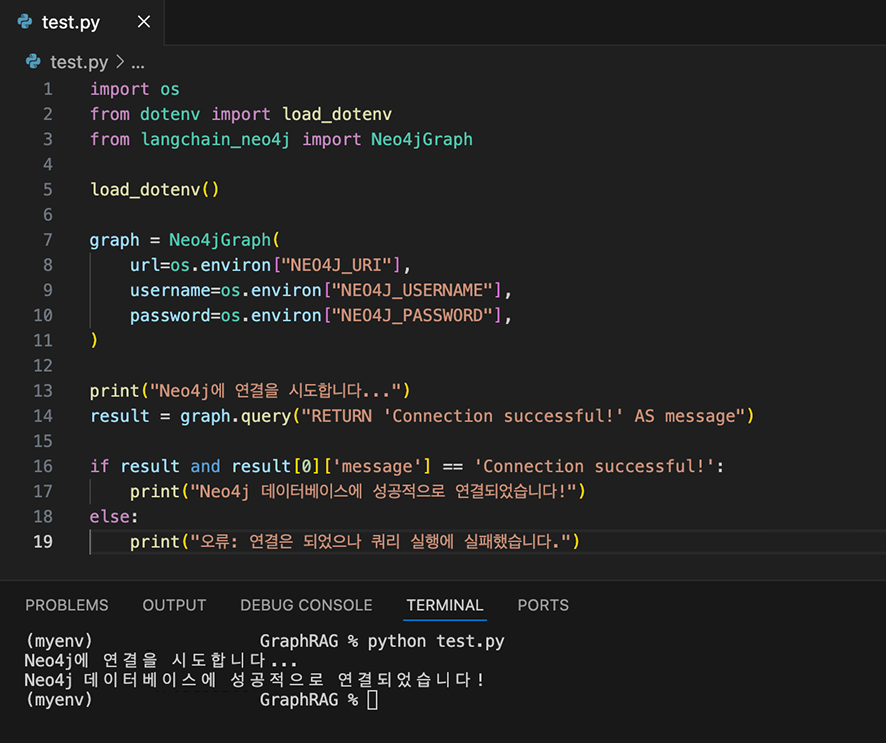
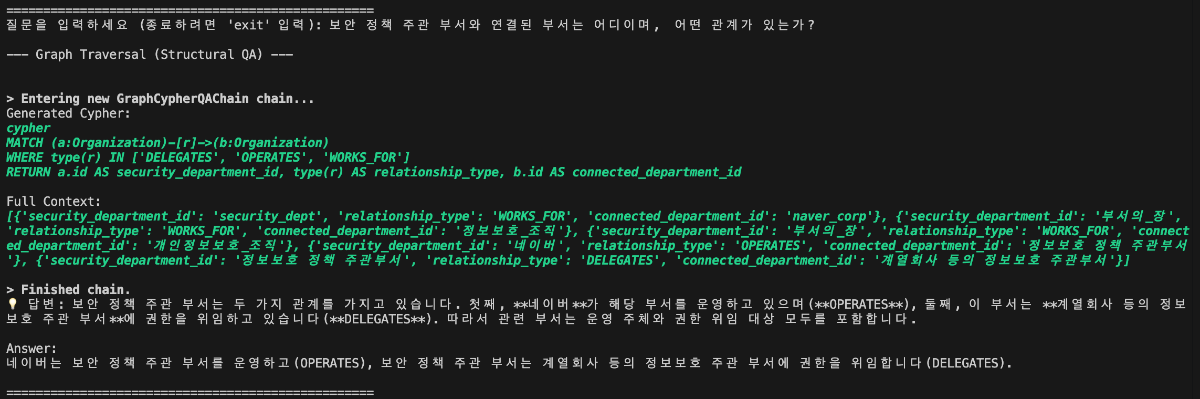
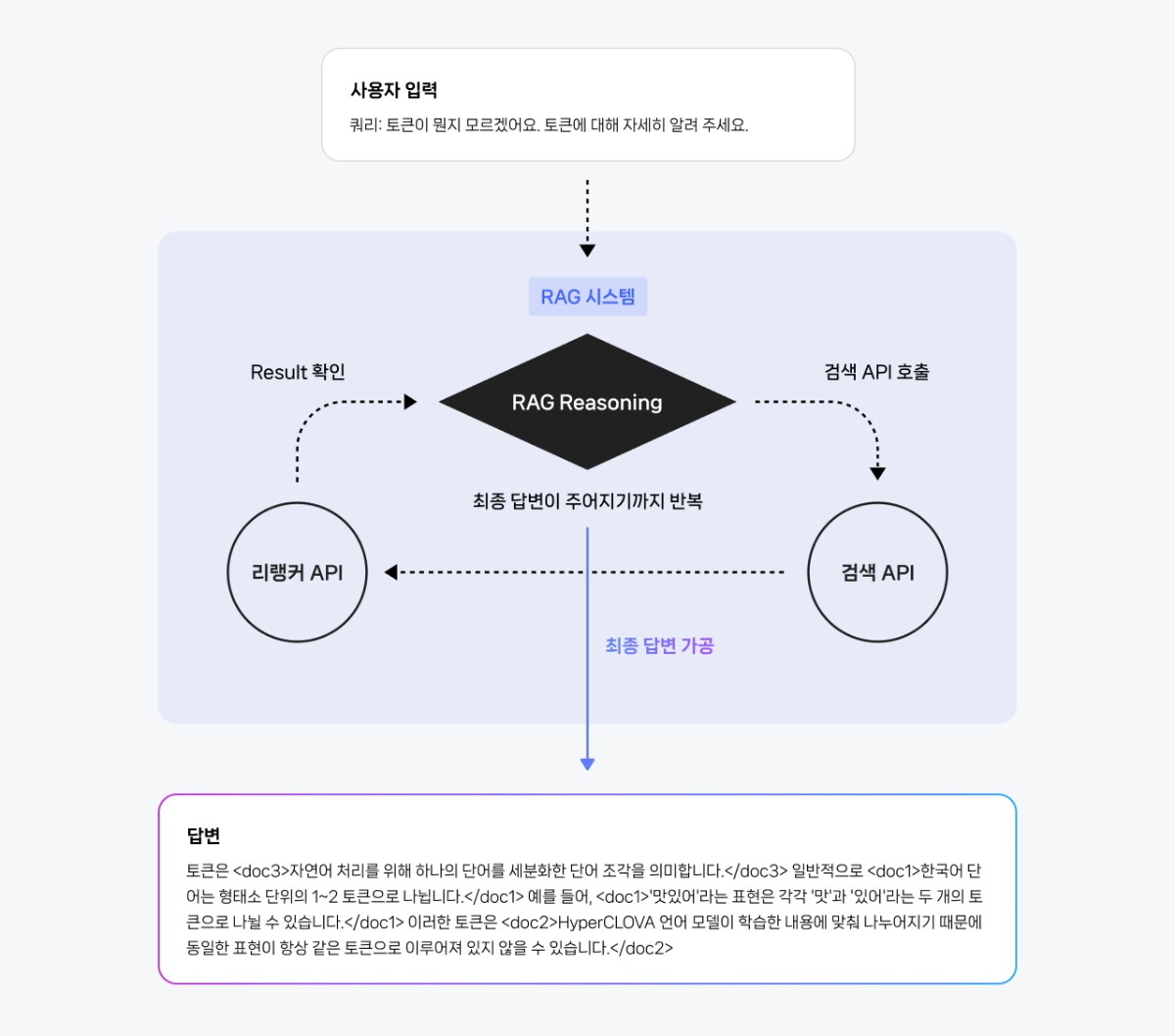
들어가며 작성 배경 및 목적 실무 환경에서는 데이터 간의 복잡한 관계를 탐색하거나, 결과에 대한 명확한 근거 제시가 필요하거나, 여러 단계를 거친 추론이 요구되는 질의가 자주 발생합니다. 본 문서는 이러한 복합 질의 상황에서 전통적인 벡터 기반 RAG(Retrieval-Augmented Generation)의 한계를 보완하기 위해, 데이터의 구조적 관계를 활용한 GraphRAG 파이프라인 구축 방법을 제시합니다. 이를 위해 클로바 스튜디오의 HCX-007 추론 모델과 그래프 데이터베이스 Neo4j를 활용하여 PDF 데이터로부터 지식 그래프를 구축하고, 이를 기반으로 한 Structured Q&A와 기존 Vector Q&A 방식을 결합한 하이브리드 질의응답 시스템의 구현 과정을 다룹니다. GraphRAG와 Neo4j는 무엇인가? ① GraphRAG: '관계 지도'를 활용하는 차세대 AI 검색 기존 RAG는 사용자의 질문과 의미가 비슷한 텍스트를 찾아 LLM이 참고하도록 하는 방식입니다. 이 방식은 해당 페이지 내의 정보에는 강점을 보이지만, 여러 문서에 흩어져 있는 개념 간 관계를 종합적으로 추론하는 데에는 한계가 있습니다. GraphRAG는 이러한 한계를 넘어, Neo4j에 구축된 지식 그래프(relationship graph)를 함께 활용합니다. 즉, 모델이 참고하는 것은 단순한 텍스트 조각이 아니라 데이터 간의 연결 구조 전체입니다. 이를 통해 개별 정보의 의미뿐 아니라 엔터티 간의 관계를 함께 이해하고, 여러 출처의 데이터를 맥락적으로 통합하며, 보다 정확하고 신뢰할 수 있는 답변을 생성할 수 있습니다. ② Neo4j: 데이터의 관계를 저장하는 데이터베이스 데이터베이스는 대개 정보를 엑셀 시트와 같은 표 형태로 저장합니다. 이 방식은 단순한 데이터를 다룰 때는 효율적이지만, 데이터가 복잡해질수록 구조가 복잡해지고 처리 속도가 떨어집니다. Neo4j는 이러한 한계를 보완하기 위해, 데이터를 관계 중심으로 표현하는 그래프 데이터베이스(Graph Database)입니다. Neo4j는 이러한 접근 방식 대신 데이터를 관계 중심으로 모델링하는 그래프 데이터베이스(Graph Database)로, 복잡한 개체 간의 연결을 노드(Node)와 관계(Relationship) 형태로 자연스럽게 모델링하고 저장합니다. Neo4j는 데이터를 노드와 관계로 표현해 복잡한 연결 구조를 직관적으로 다룰 수 있습니다. 이런 그래프 기반 구조는 데이터를 빠르고 효율적으로 탐색할 수 있게 해주며, 스키마가 고정돼 있지 않아 새로운 속성이나 관계도 쉽게 추가할 수 있습니다. 또, 그래프 구조에 최적화된 Cypher 쿼리 언어를 지원해 복잡한 질의도 간결하게 작성할 수 있습니다. ③ 온톨로지: 지식 그래프의 설계도 GraphRAG의 성능을 높이기 위해서는 온톨로지(Ontology) 개념이 중요합니다. 온톨로지는 특정 도메인(예: 금융, 의료, 제조 등)의 지식을 체계적으로 표현하기 위한 규칙과 어휘의 집합으로, 지식 그래프의 설계도이자 스키마 역할을 합니다. 온톨로지에서는 어떤 종류의 개체가 존재하는지, 각 개체가 어떤 속성을 가지는지, 그리고 개체 간에 어떤 관계가 가능한지를 미리 정의합니다. 예를 들어 ‘인물’, ‘회사’, ‘프로젝트’ 같은 개체가 있고, 인물은 이름과 직책이라는 속성을 가지며, 회사에 소속되거나(WORKS_FOR) 프로젝트를 관리하는(MANAGES) 관계를 맺을 수 있습니다. Neo4j가 흩어진 정보를 연결해 ‘관계 지도’를 만든다면, 온톨로지는 그 지도에 쓰인 기호의 의미와 규칙을 정의하는 범례 역할을 합니다. GraphRAG은 이 지도와 범례를 함께 활용해 복잡한 질문에 대해 신뢰도 높은 경로를 찾아냅니다. GraphRAG은 복잡한 관계를 기반으로 한 질의나 설명 가능한 추론이 필요한 환경에서 특히 유용합니다. 예를 들어 기업 조직도나 공급망처럼 개체 간 연결이 많은 구조를 분석하거나, 금융·의료·법률 분야처럼 근거 자료의 추적이 필요한 경우에 적합합니다. 또한 여러 단계의 논리적 연결을 따라가야 하는 복합 질의나, 이미 도메인 지식이 체계화된 산업군에서도 효과적으로 활용할 수 있습니다. 대표적인 활용 분야 금융/리스크/사기 탐지 : 거래 기록, 구성원, 회사 네트워크의 연관성을 분석한 위험 탐지 및 의사결정 법률/규제 : 조문·판례 간의 연결 관계를 활용한 사례 연구 및 근거 탐색 기업 내부 지식/연구 : 다양한 문서·연구자·프로젝트 간 연계를 통한 인사이트 도출 및 지능형 Q&A 고객 서비스 : 복잡한 문의에 대해 근거 기반의 신뢰성 높은 답변 제공 GraphRAG에 HCX-007 추론 모델을 사용해야 하는 이유 GraphRAG에 추론 모델을 사용하는 이유는 그래프 구조 속 관계적 의미를 정확히 이해하고 해석할 수 있기 때문입니다. 1. 뛰어난 추론 및 지시 이행 GraphRAG은 문서에서 엔터티와 관계를 추출해 그래프 형태로 저장합니다. 하지만 단순히 텍스트 유사도를 계산하는 방식만으로는 노드 간의 복잡한 연결이나 간접적인 의미 관계를 충분히 드러내기 어렵습니다. HCX-007 추론 모델은 이러한 한계를 넘어, 여러 노드 사이의 맥락적 연결을 이해하고 문장에 드러나지 않은 논리적 관계를 찾아낼 수 있기 때문에 더 풍부하고 정교한 응답을 제공합니다. 2. 신뢰성 있는 답변 생성 HCX-007 추론 모델은 단순히 답변을 제시하는 데 그치지 않고, 답이 도출된 과정을 함께 보여줄 수 있습니다. 사용자는 이 과정을 통해 결과의 근거를 확인할 수 있으며, 단순한 검색 기반 응답보다 논리적이고 신뢰도 높은 답변을 얻을 수 있습니다. 3. 고품질의 한국어 처리 능력 HCX-007추론 모델은 방대한 한국어 데이터를 기반으로 학습되어, 문맥의 미묘한 차이와 표현을 잘 이해합니다. 이를 통해 한국어로 작성된 전문 문서를 정확히 분석하고, 사용자의 질문 의도에 맞는 답변을 제공합니다. Reasoning 모델 + GraphRAG 구축 시나리오 전체 프로세스 개요 이 시스템은 PDF 문서에서 정보를 추출해 벡터와 그래프 두 형태로 Neo4j 데이터베이스에 저장합니다. 이후 사용자의 질문 의도에 따라 가장 적합한 검색 방식을 자동으로 선택해, 보다 정확한 답변을 생성합니다. 프로세스는 다음과 같은 흐름으로 구성됩니다. [데이터 입력] → 전처리 (PDF 추출 및 분할) → 임베딩 → 지식 그래프 추출 (LLM) / Vector Index 추출 → [Neo4j 저장] → 벡터 인덱스 구축 → 하이브리드 Q&A 파이프라인 → [답변 생성] 0. 라이브러리 세팅 GraphRAG 파이프라인을 구축하기 위해 필요한 필수 라이브러리를 먼저 설치합니다. 아래와 같이 requirements.txt 파일을 생성한 뒤, 필요한 패키지를 한 번에 설치할 수 있습니다. requests dotenv networkx ## numpy langchain langchain-community langchain-naver langchain-neo4j faiss-cpu ## neo4j pypdf 이 명령어를 실행하면, requirements.txt에 정의된 모든 라이브러리가 자동으로 설치됩니다. pip install -r requirements.txt 그 다음 Neo4j를 사용할 수 있는 환경 설정이 필요합니다. 빠르고 간단하게 진행하기 위해, Neo4j Sandbox에서 무료 인스턴스를 생성해 지식 그래프를 구축하겠습니다. 환경 구성이 완료되면, 본격적인 데이터 준비와 전처리 과정을 시작할 수 있습니다. 1. HCX-007 모델, 데이터 준비와 전처리 다음 단계에서는 PDF 파일에서 텍스트를 추출하고, LLM이 효율적으로 이해할 수 있도록 의미 단위(semantic chunk)로 분할합니다. PDF 텍스트 추출 pypdf 라이브러리를 활용해 PDF 문서의 모든 페이지에서 텍스트를 읽어옵니다. 의미 기반 분할 클로바 스튜디오의 문단 나누기 API (가이드 보기)를 사용해 문장 간 의미 유사도를 계산하고, 주제 단위로 문단을 자동 분리합니다. # --- PDF 처리 및 CLOVA Studio Segmentation 로직 --- def read_pdf_text(pdf_path: str) -> str: reader = PdfReader(pdf_path) texts = [p.extract_text() or "" for p in reader.pages] return "\n\n".join(texts).strip() def chunk_by_limit(text: str, limit: int) -> List[str]: parts = text.split("\n\n") batches, cur = [], "" for p in parts: add = p if not cur else ("\n\n" + p) if len(cur) + len(add) <= limit: cur += add else: if cur: batches.append(cur) cur = p if len(p) <= limit else "" if len(p) > limit: print(f"[WARN] A single paragraph of {len(p)} chars is longer than the limit {limit}, it will be chunked bluntly.") for i in range(0, len(p), limit): batches.append(p[i:i+limit]) if cur: batches.append(cur) return batches def clova_segment(text: str, **kwargs) -> List[str]: payload = { "text": text, "alpha": kwargs.get("alpha", -100), "segCnt": kwargs.get("segCnt", -1), "postProcess": kwargs.get("postProcess", True), "postProcessMaxSize": kwargs.get("postProcessMaxSize", 1000), "postProcessMinSize": kwargs.get("postProcessMinSize", 200), } retry, backoff_sec = 3, 1.5 for attempt in range(1, retry + 1): try: r = requests.post(SEG_ENDPOINT, headers=_auth_headers(), json=payload, timeout=TIMEOUT) data = r.json() if r.status_code == 200 and data.get("status", {}).get("code") == "20000": # API 응답에서 텍스트 리스트만 추출하여 반환 return ["\n".join(sents).strip() for sents in data["result"].get("topicSeg", []) if sents] raise RuntimeError(f"Segmentation API error: HTTP {r.status_code}, body={data}") except Exception as e: if attempt == retry: raise e time.sleep(backoff_sec * attempt) return [] def get_chunks_from_pdf(pdf_path: str) -> List[str]: """PDF 파일에서 텍스트를 읽고 CLOVA Studio Segmentation API로 의미 단위 청크를 생성합니다.""" print(f"Reading PDF: {pdf_path}") full_text = read_pdf_text(pdf_path) if not full_text: raise RuntimeError("Failed to extract text from PDF.") batches = chunk_by_limit(full_text, MAX_CHARS_FOR_SEGMENT) print(f"Total length={len(full_text):,} -> {len(batches)} batch(es) for segmentation.") all_chunks = [] for i, text_batch in enumerate(batches, 1): print(f"Segmenting batch {i}/{len(batches)} (length={len(text_batch):,})...") chunks_from_batch = clova_segment(text=text_batch) all_chunks.extend(chunks_from_batch) print(f" -> Got {len(chunks_from_batch)} chunks.") return all_chunks 2. 임베딩 및 벡터화 분할된 텍스트 청크를 벡터로 변환해 의미 기반 검색이 가능하도록 준비합니다. 이때 ClovaXEmbeddings를 사용해 각 청크의 의미를 고차원 벡터로 표현합니다. clova_embedder = ClovaXEmbeddings( model=“clir-emb-dolphin”, api_key=os.getenv("CLOVA_API_KEY") ) 3. (Neo4j 활용) 데이터 추출 및 지식 그래프 생성 LLM을 활용해 각 텍스트 청크에서 노드와 관계(Relationship를 추출하고, 이를 Neo4j에 저장하여 지식 그래프를 구축합니다. 이때 Pydantic으로 LLM의 출력 스키마를 미리 정의해 결과를 일관된 구조(JSON)로 받도록 하고, LangChain 체인을 통해 텍스트에서 구조화된 그래프 데이터를 추출하는 체인을 구성합니다. class Node(BaseModel): id: str = Field(description="노드(엔티티)의 이름 또는 ID") type: str = Field(description="엔티티의 타입 (예: Person, Organization, Concept)") class Relationship(BaseModel): source: Node = Field(description="관계의 시작 노드") target: Node = Field(description="관계의 끝 노드") type: str = Field(description="관계의 타입 (예: IS_A, WORKS_FOR, CONTAINS)") class KnowledgeGraph(BaseModel): nodes: List[Node] = Field(description="그래프의 모든 노드 리스트") relationships: List[Relationship] = Field(description="그래프의 모든 관계 리스트") def get_graph_extraction_chain(llm): parser = JsonOutputParser(pydantic_object=KnowledgeGraph) prompt = ChatPromptTemplate.from_messages([ ("system", """ 주어진 텍스트에서 핵심 엔티티(노드)와 그들 사이의 관계(엣지)를 식별해야 합니다. 추출된 모든 노드와 관계를 JSON 형식으로 출력하세요. 노드 타입은 'Person', 'Organization', 'Concept', 'Technology' 등 일반적인 용어를 사용하세요. 관계 타입은 'WORKS_FOR', 'DEVELOPS', 'RELATED_TO' 와 같이 대문자와 스네이크 케이스를 사용하세요. {format_instructions} """), ("human", "다음 텍스트에서 지식 그래프를 추출해줘:\n\n{input}") ]) prompt_with_format = prompt.partial( format_instructions=parser.get_format_instructions() ) return prompt_with_format | llm | parser Neo4j에 추출된 노드와 관계를 저장하고, 각 노드가 어떤 텍스트 청크에서 파생되었는지를 함께 연결해 원본 근거를 추적할 수 있도록 구조화합니다. def ingest_chunks_to_neo4j(chunks: List[str], graph: Neo4jGraph, graph_extraction_chain, embedder): graph.query("MATCH (n) DETACH DELETE n") print("Cleared existing data from Neo4j.") valid_chunks = [chunk for chunk in chunks if chunk and not chunk.isspace()] print(f"Total chunks: {len(chunks)}, Valid non-empty chunks: {len(valid_chunks)}") for i, chunk_text in enumerate(valid_chunks): print(f"--- Processing chunk {i+1}/{len(valid_chunks)} ---") print(" - Storing chunk for vector search...") chunk_embedding = embedder.embed_query(chunk_text) graph.query( "MERGE (c:Chunk {id: $chunk_id}) SET c.text = $text, c.embedding = $embedding", params={ "chunk_id": f"chunk_{i}", "text": chunk_text, "embedding": chunk_embedding } ) try: print(" - Extracting knowledge graph...") extracted_data = graph_extraction_chain.invoke({"input": chunk_text}) nodes_data = extracted_data.get("nodes", []) rels_data = extracted_data.get("relationships", []) if not (nodes_data or rels_data): print(" - No graph elements extracted.") continue extracted_graph = KnowledgeGraph(nodes=nodes_data, relationships=rels_data) for node_obj in extracted_graph.nodes: graph.query( "MERGE (n:`{type}` {{id: $id}})".format(type=node_obj.type), params={"id": node_obj.id} ) graph.query( """ MATCH (c:Chunk {{id: $chunk_id}}) MATCH (n:`{type}` {{id: $node_id}}) MERGE (c)-[:CONTAINS]->(n) """.format(type=node_obj.type), params={"chunk_id": f"chunk_{i}", "node_id": node_obj.id} ) for rel_obj in extracted_graph.relationships: graph.query( """ MATCH (s:`{st}` {{id: $sid}}) MATCH (t:`{tt}` {{id: $tid}}) MERGE (s)-[:`{rt}`]->(t) """.format(st=rel_obj.source.type, tt=rel_obj.target.type, rt=rel_obj.type), params={"sid": rel_obj.source.id, "tid": rel_obj.target.id} ) print(" - Knowledge graph stored successfully.") except Exception as e: continue print("\n✅ PDF chunks ingested into Neo4j.") 4. 벡터 인덱스 구축 및 Neo4j 세팅 의미 기반 검색을 위해 Neo4j 내에 벡터 인덱스를 생성하고, 이를 LangChain의 Neo4jVector와 연결합니다. 이 과정을 통해 임베딩된 텍스트 청크를 효율적으로 검색할 수 있는 환경이 구축됩니다. def setup_neo4j_vector_index(graph: Neo4jGraph, index_name: str, node_label: str, property_name: str, dimensions: int): try: graph.query(f"DROP INDEX {index_name} IF EXISTS") except Exception as e: print(f"Index drop failed: {e}") graph.query( f"CREATE VECTOR INDEX {index_name} FOR (n:{node_label}) ON (n.{property_name}) OPTIONS {{indexConfig: {{`vector.dimensions`: {dimensions}, `vector.similarity_function`: 'cosine'}}}}" ) print(f"Vector index '{index_name}' created.") 5. 질의응답 파이프라인 사용자의 질문 유형에 따라 그래프 탐색(Graph QA)과 벡터 검색(Vector QA) 중 최적의 방식을 자동으로 선택하는 하이브리드 Q&A 파이프라인을 구성합니다. 이 단계에서는 LangChain의 RetrievalQA와 GraphCypherQAChain을 각각 생성하고, 간단한 키워드 기반 라우팅 로직을 통해 두 체인을 유연하게 전환할 수 있도록 설계합니다. def get_hcx_llm(model_name: str = "HCX-007"): return ChatClovaX(model_name=model_name, temperature=0, request_timeout=120, api_key=CLOVA_API_KEY) def get_qa_llm(model_name: str = "HCX-007"): return ChatClovaX( model_name=model_name, temperature=0.3, request_timeout=120, api_key=CLOVA_API_KEY, thinking={"effort":"low"}, ) vector_qa_chain = RetrievalQA.from_chain_type( llm=llm_qa, chain_type="stuff", retriever=neo4j_vector_store.as_retriever() ) graph_chain = GraphCypherQAChain.from_llm( cypher_llm=llm_cypher, qa_llm=llm_qa, graph=graph, verbose=True, allow_dangerous_requests=True, cypher_prompt=CYPHER_GENERATION_PROMPT ) Cypher 기반 동적 프롬프트 설계 HCX-007 모델이 사용자의 질문을 정확한 Cypher 쿼리로 변환할 수 있도록, 그래프 스키마를 참고하는 프롬프트 템플릿을 설계합니다. CYPHER_GENERATION_TEMPLATE = """ Task: 너는 사용자의 질문을 Neo4j Cypher 쿼리로 변환하는 전문가이다. Instructions: - 제공된 그래프 스키마(Graph Schema)만을 사용하여 질문에 답하는 Cypher 쿼리를 생성해야 한다. - **오직 Cypher 쿼리만을 ```cypher ... ``` 코드 블록 안에 넣어서 반환해야 한다.** - 절대로 코드 블록 외부에 설명이나 주석 등 다른 어떤 텍스트도 포함해서는 안 된다. # --- 중요: Cypher 문법 규칙 --- # 1. 노드의 레이블을 얻으려면 `labels(node)[0]` 을 사용하라. # 2. 관계의 타입을 얻으려면, `MATCH` 절에서 관계에 변수(예: `-[r]->`)를 반드시 할당하고 `type(r)` 을 사용하라. # 3. MATCH 절에서 나중에 참조할 모든 노드와 관계에는 반드시 변수(예: `(n)`, `(m)`, `-[r]->`)를 할당해야 한다. # 익명 노드 `()` 나 익명 관계 `-[]->` 는 RETURN 절 등에서 사용할 수 없다. # 4. 쿼리의 중간 단계에서 변수를 다음으로 넘길 때는 `WITH`를 사용해야 한다. `RETURN`은 쿼리의 가장 마지막에 최종 결과를 출력할 때 오직 한 번만 사용해야 한다. # 5. 방향에 관계없이 모든 관계를 찾을 때는 화살표 없는 구문, 즉 `(n)-[r]-(m)` 을 사용해야 한다. 절대 `<-|->` 와 같은 잘못된 구문을 사용해서는 안된다. # # ❌ 잘못된 쿼리: MATCH (n)-[]->() RETURN type() # ✅ 올바른 쿼리: MATCH (n)-[r]->(m) RETURN type(r), labels(m) # # ❌ 잘못된 구조: MATCH (a)-[r1]->(b) RETURN b.id MATCH (b)-[r2]->(c) RETURN c.id # ✅ 올바른 구조: MATCH (a)-[r1]->(b) WITH b MATCH (b)-[r2]->(c) RETURN c.id # ❌ 잘못된 방향성 쿼리: MATCH (c)<-|->() # ✅ 올바른 방향성 쿼리: MATCH (c)-[r]-() Graph Schema: {schema} Question: {question} Final Answer (only the Cypher code block): """ CYPHER_GENERATION_PROMPT = PromptTemplate( input_variables=["schema", "question"], template=CYPHER_GENERATION_TEMPLATE ) 메인 실행 플로우 구현 while True: print("\n" + "="*50) query = input("질문을 입력하세요 (종료하려면 'exit' 입력): ") if query.lower() == 'exit': break try: # "누가", "몇 개", "관계" 등 구조적 질문 키워드가 포함되면 그래프 체인 사용 if any(keyword in query for keyword in ["누가", "몇 개", "어떤 관계", "연결"]): print("\n--- Graph Traversal (Structural QA) ---") result = graph_chain.invoke({"query": query}) print(f"답변: {result.get('result', '답변을 생성하지 못했습니다.')}") # 그 외의 일반적인 질문은 벡터 검색 체인 사용 else: print("\n--- Vector Search (RAG QA) ---") result = vector_qa_chain.invoke({"query": query}) print(f"답변: {result.get('result', '답변을 생성하지 못했습니다.')}") except CypherSyntaxError as e: print("\n[오류] 쿼리 생성 또는 실행 중 Cypher 문법 오류가 발생했습니다.") print("질문을 조금 더 명확하게 하거나 다른 방식으로 질문해보세요.") except Exception as e: print(f"\n[오류] 예측하지 못한 오류가 발생했습니다: {e}") print("다른 질문으로 다시 시도해주세요.") 질문 유형별 동작 예시 지금까지의 과정을 통해, GraphRAG가 질문의 유형에 따라 그래프 탐색과 벡터 검색을 유연하게 전환하며 추론하는 구조를 구현하는 과정을 살펴보았습니다. 아래 예시를 살펴보면, 질문의 유형에 따라 그래프 탐색과 벡터 검색이 어떻게 다르게 작동하는지 알 수 있습니다. GraphRAG 적용한 QA (Structured QA) Q. 보안 정책 주관 부서와 연결된 부서는 어디이며, 어떤 관계가 있는가? 일반적인 Vector 검색 적용한 QA (RAG QA) Q. 네이버의 정보보호 목표 달성을 위해 지켜야 할 기본 원칙은? 예를 들어, “보안 정책을 주관하는 부서와 연결된 부서는 어디인가?”처럼 관계를 파악해야 하는 질문에는 GraphRAG이 Neo4j 그래프를 탐색해 부서 간 연결 구조를 제시했습니다. 반면 “네이버의 정보보호 목표 달성을 위해 지켜야 할 기본 원칙은 무엇인가?”와 같은 서술형 질문에는 Vector 검색이 핵심 문장을 찾아 요약하는 데 더 효과적이었습니다. 즉, GraphRAG은 관계형 탐색이 필요한 질문과 일반 텍스트 기반 질의를 구분해 질문의 의도에 가장 적합한 방식으로 답변을 생성하는 구조를 갖추고 있습니다. 마무리 : GraphRAG의 효용성 GraphRAG는 복잡한 관계형 데이터를 다루거나 전문 지식의 근거를 명확히 제시해야 하는 환경에서 특히 유용합니다. 단순한 텍스트 검색으로는 찾기 어려운 데이터 간의 연결과 패턴을 파악할 수 있고, 답변의 근거가 되는 관계를 함께 제시해 신뢰도 높은 결과를 제공합니다. 여러 단계를 거치는 복합적인 질의에서도 그래프 탐색을 통해 논리적 일관성을 유지하고, 신뢰할 수 있는 답변을 제공합니다. 지금까지 GraphRAG 활용하는 방식을 살펴봤습니다. 단순한 검색을 넘어 데이터를 맥락과 의미로 이해하는 GraphRAG 방식을 직접 시도해보세요.
-
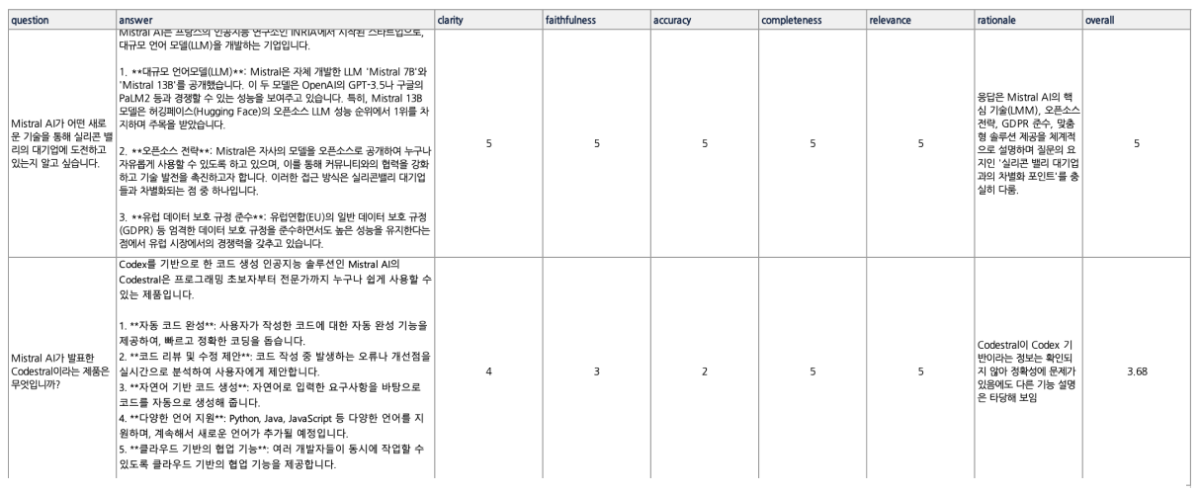
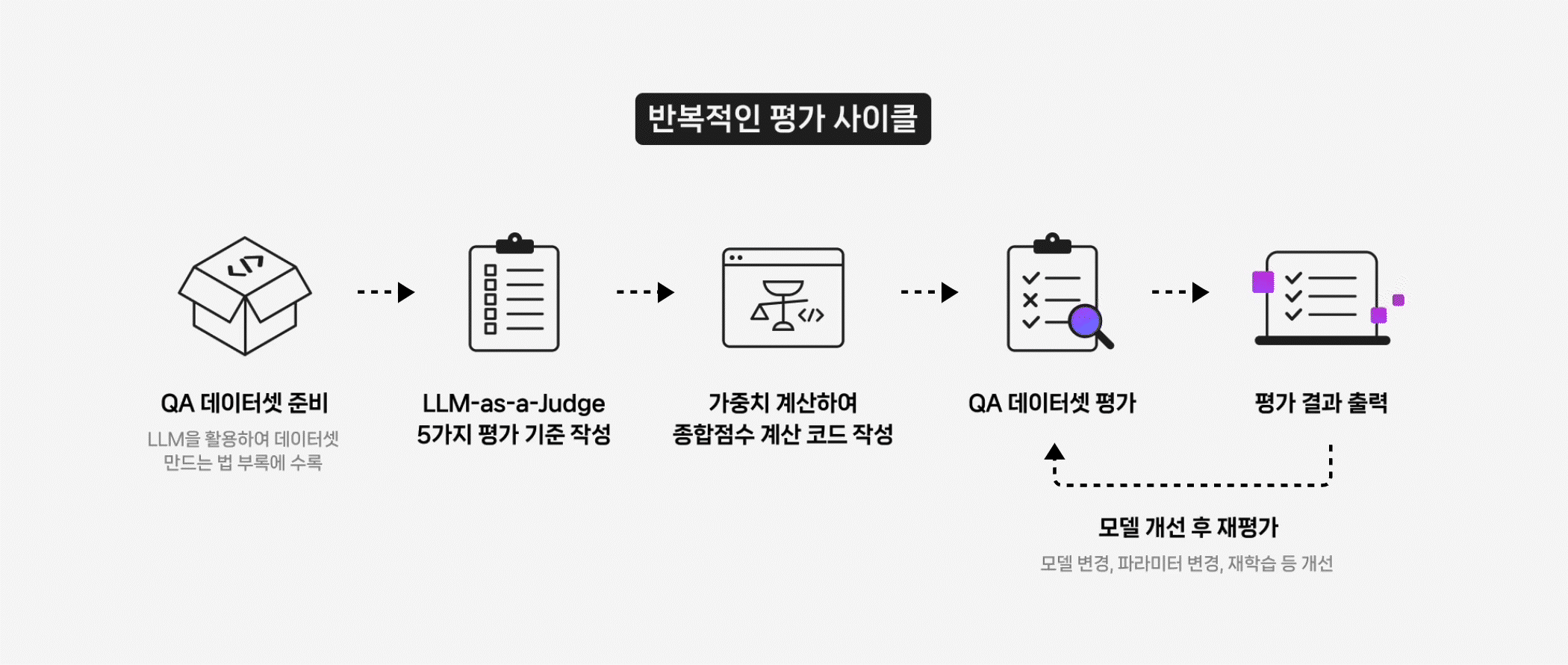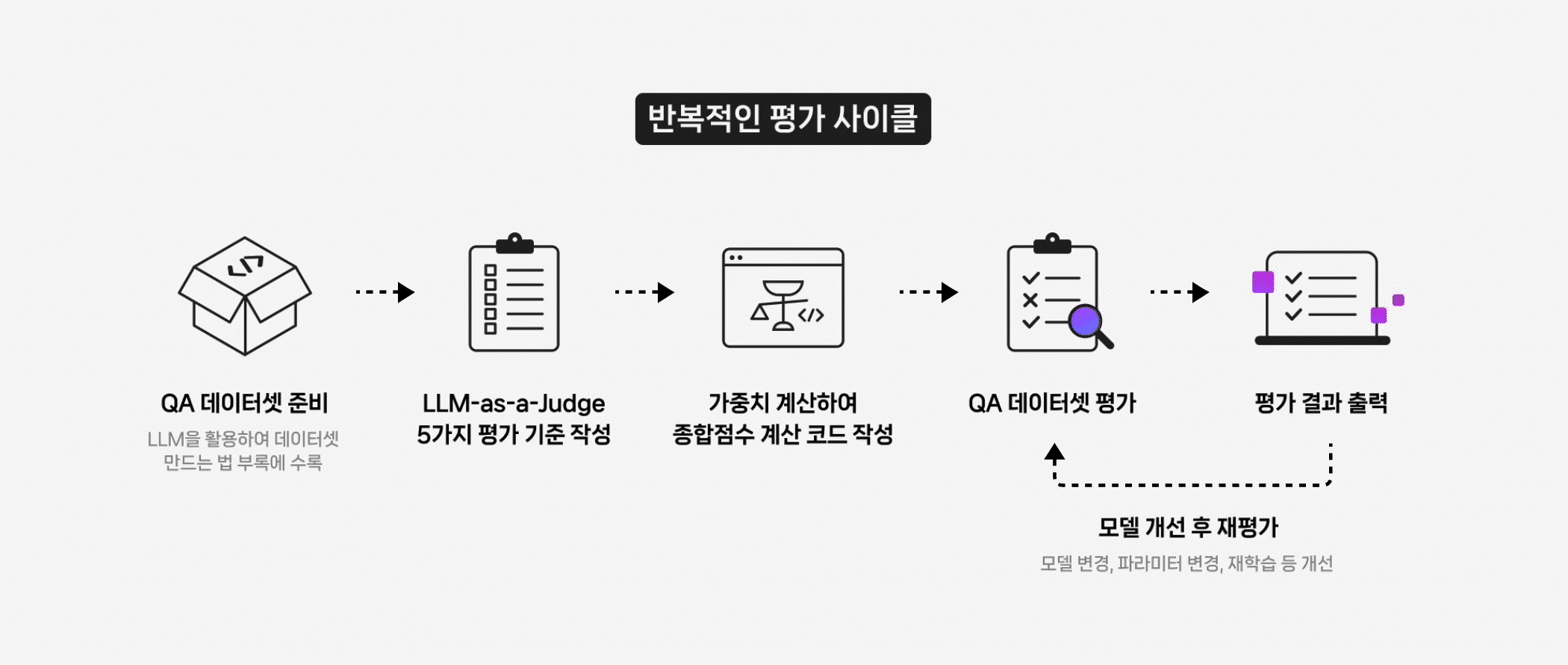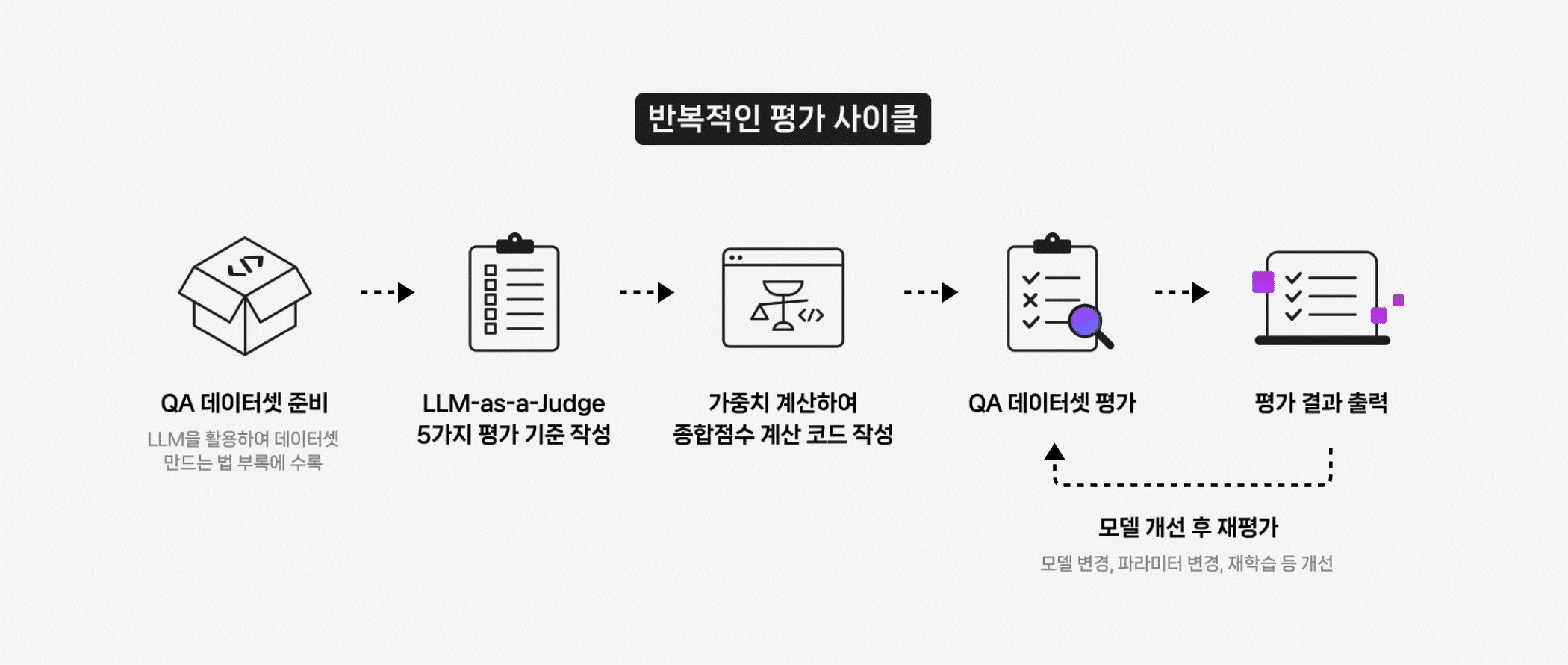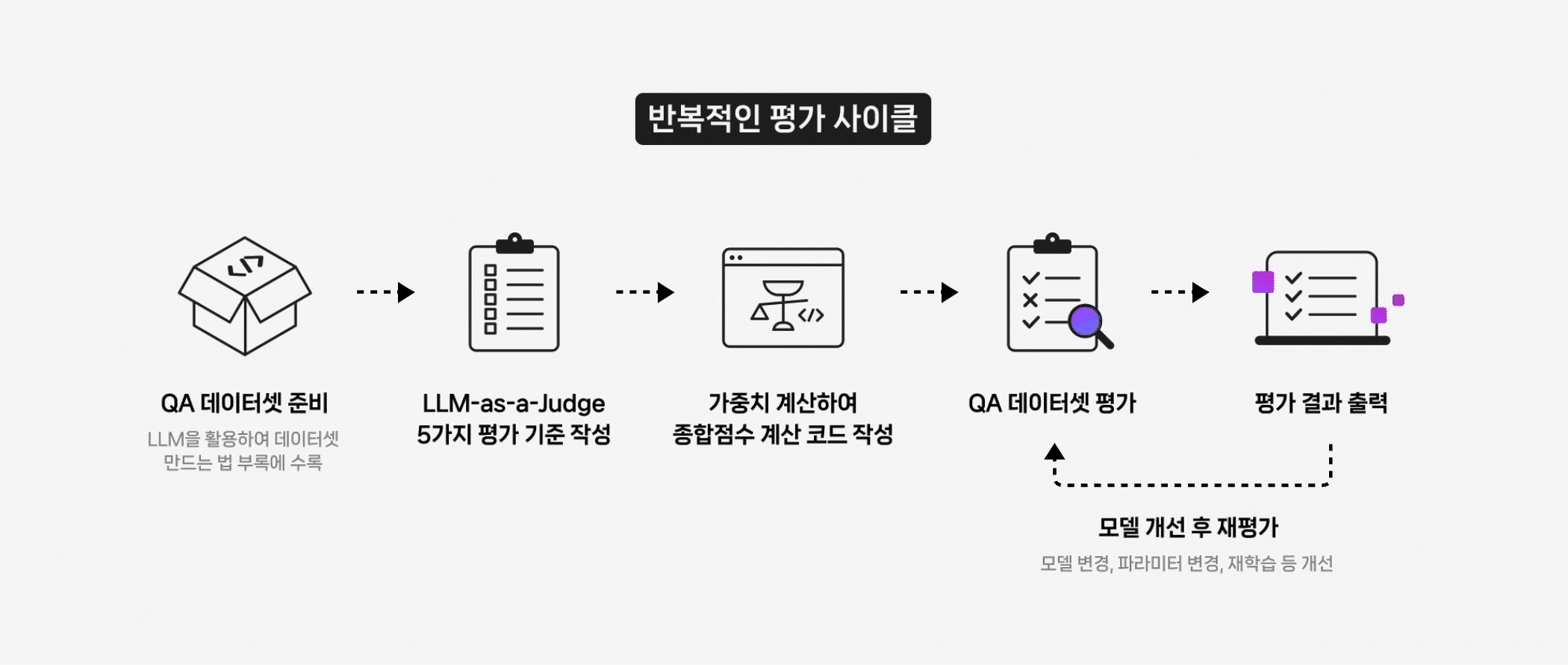
LLM Evaluation, 왜 중요한가? LLM은 이제 단순한 텍스트 생성기를 넘어, RAG(Retrieval-Augmented Generation)나 Fine-tuning과 같은 기법을 통해 실제 서비스와 업무 환경에 맞게 커스터마이징되고 있습니다. 하지만 새로운 파이프라인을 설계하거나 파인튜닝을 적용했다고 해서, 성능이 항상 향상되는 것은 아닙니다. 실제로 개선 여부를 객관적으로 검증하는 일은 여전히 쉽지 않죠. 기존 벤치마크 점수로는 실제 현장의 요구를 충분히 반영하기 어렵고, 사람 평가만으로는 시간과 비용의 부담이 큽니다. 이 한계를 보완하기 위해 최근 주목받는 접근이 LLM-as-a-Judge입니다. 또 다른 LLM이 평가자의 역할을 맡아, 생성된 결과물의 품질을 판별하고 점수를 매기는 방식이죠. 이를 통해 대규모 평가를 자동화하고, 인간 평가가 지니는 주관성을 줄일 수 있습니다. 이 방식은 단순히 모델이 '잘 작동하는가'를 확인하는 수준을 넘어, 어떤 조건에서 강점을 보이고 어디에서 취약한지까지 체계적으로 파악할 수 있게 합니다. 최근 연구에 따르면, LLM-as-a-Judge는 단순한 평가 자동화를 넘어서 모델이 스스로 사고 과정을 평가하고 개선하는 ‘Reasoning-Centric’ 방향으로 발전하고 있습니다¹. 즉, 평가와 추론이 서로를 보완하며 모델의 사고 구조를 점점 더 정교하게 만들어가는 흐름입니다. (1) Gu, Jiawei, et al. 2024. "A Survey on LLM-as-a-Judge." https://arxiv.org/abs/2411.15594. CLOVA Studio에서는 이러한 평가 방식을 HyperCLOVA X 모델 API를 직접 활용해 구현할 수 있습니다. 생성된 결과를 자동으로 평가하고, 그 데이터를 다시 프롬프트 최적화나 파인튜닝 전략 조정, RAG 파이프라인 개선에 활용하는 것이죠. 왜 추론 모델로 평가해야 할까 LLM 성능 평가는 비추론 모델의 출력만으로는 한계가 있습니다. 답을 생성하는 데는 능숙하더라도, 그 답이 왜 맞거나 틀렸는지를 스스로 검증하지 못하기 때문이죠. 이 경우 결과의 일관성이 떨어지고, 평가 근거도 불명확해질 수 있습니다. 반면 HyperCLOVA X의 추론 모델 HCX-007은 결론에 이르기 전, 단계별 사고 과정을 전개하며 전제와 논리를 점검합니다. 이런 사고 과정 덕분에 평가 결과는 단순히 정답인지 아닌지를 판단하는 수준을 넘어, 더 깊이 있는 분석으로 이어집니다. 실제로, Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena 연구에서는 GPT-4와 같은 추론형 모델이 인간 평가자와 약 80 % 수준의 일치도를 보였다고 보고했습니다. 이는 LLM-as-a-Judge가 인간 선호(human preference)를 대체할 수 있을 만큼 신뢰도 높은 평가 체계로 작동할 수 있음을 보여줍니다. (2) Zheng, Liang, et al. 2023. “Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena.” https://arxiv.org/pdf/2306.05685. 추론 모델을 평가자로 쓸 때의 세부 강점은 다음과 같습니다. 논리 일관성 검증 정답 여부만 확인하는 데 그치지 않고, 사고 과정을 기반으로 논리적 타당성까지 함께 검증합니다. 평가 결과에는 판정 근거까지 함께 남기기 때문에, 왜 그런 결과가 나왔는지도 명확히 파악할 수 있습니다. 세분화된 기준별 평가 Clarity, faithfulness, accuracy 등 항목별로 일관된 스코어링이 가능해, 같은 답변이라도 어떤 부분이 강점이고, 어디서 약한지 명확히 구분해 보여줄 수 있습니다. 설명 가능한 근거 제시 점수뿐 아니라 평가 근거와 판단 과정이 함께 제공되어, 결과의 신뢰도를 높입니다. 부분 정답 처리 모호하거나 부분적으로만 맞는 응답도, 합리적인 기준에 따라 부분 점수와 보완 코멘트를 함께 제공합니다. 즉, HCX-007은 ‘스스로 사고하며 분석하는 평가자’입니다. 이를 평가 파이프라인에 도입하면, 점수의 신뢰성과 결과에 대한 이해도가 높아지고, 이후 모델 개선 사이클을 더 빠르게 반복할 수 있습니다. 이번 글에서는 CLOVA Studio의 HCX-007 추론 모드로 LLM 평가를 설계하고 적용하는 방법을 구체적으로 살펴보겠습니다. LLM Evaluation 시나리오 전체 프로세스 개요 아래 다이어그램은 이번 글에서 다루는 LLM 평가 워크플로우를 단계별로 정리한 것입니다. 이 프로세스는 단순히 한 번의 점수를 계산하는 데 그치지 않고, 평가 → 개선 → 재평가의 순환 구조를 통해 모델을 지속적으로 고도화하는 것을 목표로 합니다. 단계별 설명에 들어가기 전에, 우선 평가에 사용할 QA 데이터셋이 필요합니다. 아직 준비되지 않았다면 부록에 안내된 절차를 참고해 손쉽게 생성할 수 있습니다. 데이터셋은 Excel(.xlsx) 또는 CSV(.csv) 형식을 모두 지원하며, 두 개의 열; 질문(question) 과 답변(answer)로 구성되어 있어야 합니다. 1. 평가 기준 정의하기 LLM-as-a-Judge 방식을 적용하려면, 먼저 평가 기준을 명확히 설정해야 합니다. 아래는 LLM의 응답을 평가하기 위해 HCX-007 모델에 전달할 시스템 프롬프트의 예시입니다. JUDGE_SYSTEM_PROMPT = """당신은 LLM 응답을 평가하는 심판(LLM-as-a-Judge)입니다. [역할] - 주어진 질문(question)과 응답(answer)을 기준으로, 아래 항목별로 0~5의 정수 점수를 부여하고 간단한 근거를 제시합니다. - 외부 지식이 필요하더라도, 질문과 응답에 드러난 정보와 일반 상식 범위를 벗어나 추정하지 않습니다. (추정 시 근거 부족으로 감점) [원칙] # 원하는 모델 방향성에 맞게 조정 가능 - 점수는 반드시 0~5의 **정수(5가 최상)** 로만 부여합니다. (소수점, 범위 점수 불가) - 근거(rationale)는 **핵심만 1~2문장**으로 작성하며, 불필요한 배경 설명은 제외합니다. - 응답이 질문에 사실상 답하지 못했거나 형식이 명백히 어긋나면, 대부분의 항목에서 낮은 점수를 부여합니다. [평가 기준] 1) clarity (명료성) - 문장이 불필요하게 길거나 중복되지 않는가? - 문장 구조가 논리적이며, 주어·서술어 관계가 명확한가? - 전문용어는 처음 등장 시 짧은 정의나 설명이 포함되어 있는가? 2) faithfulness (충실성/일관성) - 질문의 의도와 제약을 정확히 반영하고 있는가? - 응답의 논리 구조(주장–근거–결론)가 앞뒤로 일관되는가? - 질문의 맥락을 벗어난 추가 정보나 왜곡된 해석은 없는가? - 가정이나 전제가 있다면 명시되어 있는가? (없는데 단정하면 감점) 3) accuracy (정확성) - 사실 관계(정의, 수치, 인과 관계 등)가 일반 지식과 일치하는가? - 문맥상 잘못된 용어나 개념 오류가 없는가? - 출처나 기준이 불분명한 단정적 표현(예: “항상 그렇다”, “절대 아니다”)은 없는가? - 불확실한 경우, 보수적으로 표현하거나 근거 부족을 명시하는가? 4) completeness (충족성) - 질문의 모든 요구사항(하위 질문, 제약, 출력 형식 등)을 빠짐없이 충족하는가? - 예시, 단계, 코드, 설명 등 필요한 구성 요소가 포함되어 있는가? - 답변이 “요청된 범위 전체”를 포괄하되, 불필요한 세부 내용으로 흐트러지지 않는가? - 복수 항목을 요구했을 경우 모두 명시적으로 다뤘는가? 5) relevance (관련성) - 응답이 질문의 주제에 직접적으로 관련되어 있는가? - 문장 또는 단락이 주제에서 벗어나지 않고 논리적으로 연결되는가? - 잡담, 반복, 불필요한 부연 설명이 없는가? [감점 가이드(예시)] - 근거 없는 단정/모순 → faithfulness, accuracy에서 감점 - 요구사항 누락/형식 불일치 → completeness에서 감점 - 장황함/모호어 다수 → clarity, relevance에서 감점 [출력(JSON 전용)] - 아래 키만 포함하고, 값은 정수(0~5) 또는 문자열로 출력합니다. - 절대 JSON 외 텍스트를 출력하지 않습니다. (설명, 접두사, 코드블록 금지) { "clarity": 0, "faithfulness": 0, "accuracy": 0, "completeness": 0, "relevance": 0, "rationale": "간단한 이유(1~2문장)" } """ 위 기준은 모델의 응답을 평가하기 위한 기본 프레임워크로, 다섯 가지 항목을 중심으로 점수를 산출합니다. 이러한 metric 설계는 단순히 정답 여부를 판단하는 데서 그치지 않고, 모델이 어떤 방식으로 답을 도출했는지까지 살펴볼 수 있도록 해줍니다. 이 기준은 고정된 규칙이 아닙니다. 평가 대상 모델의 특성과 적용 영역에 따라 자유롭게 확장하거나 수정할 수 있으며, 출력 형식은 JSON으로 고정해 평가 결과를 구조적으로 저장하고 분석할 수 있습니다. 결국 중요한 것은 평가 항목을 명확히 정의하고, 이를 일관된 방식으로 적용할 수 있는 체계를 갖추는 것입니다. 이러한 설계가 뒷받침될 때, LLM-as-a-Judge는 신뢰성 있는 평가 도구로 기능할 수 있습니다. 2. 평가 항목별 비중을 적용해 종합 점수 계산하기 평가 항목을 정의했다면, 이제 각 항목의 점수를 합산해 하나의 종합 점수를 계산해야 합니다. 이때 중요한 것은 단순 평균이 아니라, 항목별 중요도(비중)를 반영하는 것입니다. 예를 들어, 정확성(accuracy)이나 충실성(faithfulness)이 상대적으로 더 중요하다면 이 항목들의 비중을 높게 설정할 수 있습니다. 아래 함수는 다섯 가지 평가 항목(clarity, faithfulness, accuracy, completeness, relevance)에 대해 미리 정의한 비중을 적용하고, 그 합이 1이 되도록 정규화하여 최종 점수를 계산합니다. 앞 단계에서 평가 기준을 수정하거나 새로운 metric을 추가했다면, 이 함수 또한 그에 맞게 함께 조정해야 합니다. def calculate_overall_score(scores: dict) -> float: """가중 평균으로 전체 점수 계산""" raw_weights = { 'clarity': 1.0, 'faithfulness': 1.2, 'accuracy': 1.5, 'completeness': 1.0, 'relevance': 1.3 } weight_sum = sum(raw_weights.values()) weights = {m: w / weight_sum for m, w in raw_weights.items()} total_score = sum(scores[metric] * weight for metric, weight in weights.items() if metric in scores) return round(total_score, 2) 이 단계는 개별 평가 항목을 하나의 종합 성능 지표로 통합하는 과정입니다. 이렇게 계산된 종합 점수는 이후 단계에서 모델 간 성능 비교나 개선 효과 검증에 활용할 수 있습니다. 3. HCX-007 모델 호출 후 QA 데이터셋 평가하기 이제 앞서 정의한 평가 기준과 가중치 계산 함수를 실제로 적용해보겠습니다. 준비된 QA 데이터셋(CSV 또는 Excel 파일)을 불러와, 각 질문과 답변을 HCX-007 모델에 입력하면 LLM-as-a-Judge가 각 항목별 점수를 매깁니다. 평가 결과에는 항목별 점수뿐 아니라 간단한 평가 근거도 함께 포함되며, 모든 결과는 CSV 파일로 저장됩니다. API 키는 코드에 직접 노출하지 않고 .env 파일로 관리합니다. 아래와 같이 환경 변수를 설정해 두면, 실행 시 안전하게 키를 불러올 수 있습니다. CLOVA_API_KEY= {api 키 입력} 환경 변수(.env 파일)를 불러오기 위해 python-dotenv 패키지가 필요합니다. 아직 설치하지 않았다면, 아래 명령을 실행해 주세요. (Python 3 환경 필요) pip3 install python-dotenv 이후 필요한 라이브러리를 임포트하고, HCX-007을 호출하는 함수를 작성합니다. 오류가 발생하면 각 항목 점수를 0으로 초기화하고 실패 사유를 함께 반환하도록 처리합니다. import os, json, time import pandas as pd import requests from dotenv import load_dotenv # 환경 변수 로드 load_dotenv() CLOVA_API_KEY = os.getenv("CLOVA_API_KEY") CHAT_URL = "https://clovastudio.stream.ntruss.com/v3/chat-completions/HCX-007" BASE_HEADERS = { "Content-Type": "application/json", "Authorization": f"Bearer {CLOVA_API_KEY}" } def call_hcx007_judge(question: str, answer: str, timeout: int = 30) -> dict: """HCX-007 모델로 응답 평가""" user_content = f"[질문]\n{question}\n\n[응답]\n{answer}\n\n위 기준으로 평가해 주세요. JSON만 출력하세요." payload = { "messages": [ {"role": "system", "content": JUDGE_SYSTEM_PROMPT}, {"role": "user", "content": user_content} ] } try: resp = requests.post(CHAT_URL, headers=BASE_HEADERS, data=json.dumps(payload), timeout=timeout) resp.raise_for_status() data = resp.json() content = data["result"]["message"]["content"] scores = json.loads(content.strip()) # 점수를 정수로 변환 for k in ["clarity", "faithfulness", "accuracy", "completeness", "relevance"]: scores[k] = int(scores.get(k, 0)) scores["rationale"] = str(scores.get("rationale", "")).strip() return scores except Exception as e: return { "clarity": 0, "faithfulness": 0, "accuracy": 0, "completeness": 0, "relevance": 0, "rationale": f"evaluation_failed: {type(e).__name__}" } 아래 함수는 평가를 실행하고 결과를 CSV 파일로 저장하는 역할을 합니다. 출력은 지정한 컬럼 순서(desired_cols)에 맞춰 정리됩니다. def run_evaluation(input_path: str, output_csv: str): """Q&A 데이터셋 평가 실행""" # 데이터 로드 df = pd.read_csv(input_path) if input_path.endswith(".csv") else pd.read_excel(input_path) results = [] for i, row in df.iterrows(): question, answer = row["question"], row["answer"] # API 호출로 평가 scores = call_hcx007_judge(question, answer) overall = calculate_overall_score(scores) results.append({ **scores, "question": question, "answer": answer, "overall": overall }) print(f"진행: {i+1}/{len(df)}") print(scores) print(f"완료: 전체 점수 {overall}") time.sleep(0.3) # API 호출 제한 방지 # 결과 저장 desired_cols = [ "question", "answer", "clarity", "faithfulness", "accuracy", "completeness", "relevance", "rationale", "overall" ] result_df = pd.DataFrame(results, columns=desired_cols) result_df.to_csv(output_csv, index=False, encoding='utf-8-sig') print(f"평가 완료 → {output_csv}") 4. 평가 결과 정리 및 실행하기 평가가 완료되면, 결과를 정리하고 검토하는 단계가 필요합니다. 이 과정에서는 각 항목별 평균 점수와 전체 평균(overall) 을 계산해 출력하며, 이를 통해 모델의 전반적인 성능과 개선이 필요한 부분을 한눈에 파악할 수 있습니다. def summarize_results(csv_path: str): """평가 결과 요약""" df = pd.read_csv(csv_path) metrics = ["clarity", "faithfulness", "accuracy", "completeness", "relevance", "overall"] avg_scores = {m: round(df[m].mean(), 2) for m in metrics if m in df.columns} print("\n=== 평가 결과 요약 ===") for metric, score in avg_scores.items(): print(f"{metric}: {score}") return avg_scores 아래는 전체 실행 코드입니다. input_file에는 미리 준비한 QA 데이터셋 경로를, output_file에는 저장할 결과 파일명을 지정합니다. if __name__ == "__main__": input_file = "rag_qa_pairs.csv" output_file = "evaluation_results.csv" # 평가 실행 run_evaluation(input_file, output_file) # 결과 요약 summarize_results(output_file) 코드를 실행하면 각 질문별 평가 결과와 전체 요약이 함께 출력되며, 이 과정을 통해 모델의 강점과 약점을 수치로 확인할 수 있습니다. 진행: 1/25 {'clarity': 4, 'faithfulness': 5, 'accuracy': 5, 'completeness': 5, 'relevance': 5, 'rationale': '응답은 Mistral AI가 참여 중인 다양한 산업 분야를 구체적 사례와 함께 체계적으로 나열해 질문 요구사항을 완벽히 충족함. 각 산업별 세부 적용 사례를 명시함으로써 전문성과 관련성을 높였으며, 정보의 흐름이 자연스럽고 논리적임.'} 완료: 전체 점수 4.83 . . . === 평가 결과 요약 === clarity: 3.36 faithfulness: 3.2 accuracy: 2.8 completeness: 3.36 relevance: 3.32 overall: 3.18 평가 결과는 자동으로 같은 폴더 내에 evaluation_results.csv 파일로 저장됩니다. 아래는 결과 파일의 일부 예시입니다. 5. 모델 개선 후 재평가 지금까지는 모델의 응답을 평가하고 점수를 산출하는 과정을 살펴보았습니다. 하지만 평가의 목적은 단순히 현재 성능을 확인하는 데 그치지 않습니다. 실험을 통해 개선 방향을 탐색하고, 동일한 평가 절차를 반복하며 모델을 점진적으로 고도화하는 것이 핵심입니다. 모델 개선은 여러 수준에서 시도할 수 있습니다. 다음은 성능 향상을 위한 대표적인 접근 방식입니다. 프롬프트 설계 수정 질문의 목적을 더 명확히 하거나 출력 형식을 고정해 응답의 일관성을 높입니다. RAG 파이프라인 개선 임베딩 모델, 청킹 전략, 컨텍스트 구성 방식을 조정해 응답의 충실성과 정확성을 개선합니다. 모델 변경, 모델 설정 변경 모델을 변경하거나 temperature, top-p 등의 파라미터를 조정해 응답의 다양성과 안정성을 제어합니다. 파인튜닝 (Fine-tuning) 특정 도메인에 대한 파인튜닝을 수행하면, 해당 도메인에 맞는 응답 형식과 용어를 학습하여 과업 적합성을 높일 수 있습니다. 이러한 개선을 적용한 뒤에는 다시 QA 데이터셋을 평가하는 단계로 돌아가 동일한 절차를 반복해야 합니다. 그래야 변경이 실제로 성능 향상으로 이어졌는지, 혹은 단순한 변동에 불과한지를 객관적으로 검증할 수 있습니다. 특히, 평가 항목, 비중, 데이터셋은 동일한 조건으로 유지해야 합니다. 그래야 전후 결과를 공정하게 비교하고, 개선 효과를 정확히 판단할 수 있습니다. 또한 평균 점수뿐 아니라 항목별 점수와 평가 근거(reasoning) 를 함께 살펴보면, 어떤 부분이 개선되었고 어떤 부분이 여전히 보완이 필요한지도 구체적으로 파악할 수 있습니다. 마무리 모델 평가의 목적은 단순히 점수를 매기는 데 있지 않습니다. 평가를 통해 얻은 데이터는 모델이 어떤 조건에서 강점을 보이고, 어떤 상황에서 한계를 드러내는지를 구체적으로 보여줍니다. 이 과정을 반복하면 프롬프트 설계나 파이프라인 구성을 보다 근거 있게 조정할 수 있습니다. 특히 하이퍼클로바X 추론 모델(HCX-007)을 활용하면, 단순 정답 판별을 넘어 사고 과정 기반의 분석적 평가가 가능해집니다. 이는 모델의 개선 방향을 보다 명확히 설정하고, 평가 프로세스 전체의 신뢰도와 효율성을 함께 높여줄 수 있죠. 결국 중요한 것은 평가와 개선을 끊김 없이 이어가는 것입니다. 이러한 반복적 평가와 분석이 쌓이면, LLM의 성능과 한계를 더 구체적으로 이해할 수 있고, 그 위에서 보다 안정적인 개선 전략을 세울 수 있을 것입니다. (부록) LLM을 활용하여 QA 데이터셋 준비하는법 모델 평가를 진행하려면 질문–답변(QA) 데이터셋이 필수입니다. 하지만 이를 일일이 수작업으로 만들기에는 시간과 비용이 많이 들죠. 이때 LLM을 활용하면 문서를 기반으로 자동으로 질문을 생성해 손쉽게 평가용 데이터셋을 구축할 수 있습니다. 아래에서는 PDF 문서를 입력받아 HCX-005 모델로 질문을 만들고, CSV로 정리한 뒤 자동으로 답변까지 생성하는 간단한 워크플로우를 소개합니다. 1. HCX-005 모델 불러오기 코드를 실행하기 전에, 먼저 필요한 모듈을 설치해야 합니다. 터미널에서 아래 명령어를 입력해주세요. pip3 install python-dotenv pypdf 이후, 질문 생성을 담당할 모델인 HCX-005를 호출합니다. API 키는 보안을 위해 .env 파일에 저장해두세요. from dotenv import load_dotenv import os import requests load_dotenv() CLOVA_API_KEY = os.getenv("CLOVA_API_KEY") CHAT_URL = "https://clovastudio.stream.ntruss.com/v3/chat-completions/HCX-005" def _auth_headers(): return { "Content-Type": "application/json; charset=utf-8", "Authorization": f"Bearer {CLOVA_API_KEY}", } def generate_hcx005(messages, temperature=0.7, max_tokens=2000): payload = { "messages": messages, "temperature": temperature, "topP": 0.9, "maxTokens": max_tokens, "repeatPenalty": 1.05 } r = requests.post(CHAT_URL, headers=_auth_headers(), json=payload, timeout=60) data = r.json() return data["result"]["message"]["content"].strip() .env 파일에는 아래와 같이 환경 변수를 정의합니다. CLOVA_API_KEY= {발급받은_키} 2. PDF에서 텍스트 추출하기 pypdf 라이브러리를 사용해 PDF 본문을 텍스트로 변환합니다. 단, 표나 이미지는 추출되지 않을 수 있으므로 필요에 따라 클로바 OCR을 함께 활용해보세요. (클로바 OCR 확인하기↗) from pypdf import PdfReader def read_pdf_text(pdf_path: str) -> str: reader = PdfReader(pdf_path) texts = [] for page in reader.pages: text = page.extract_text() or "" texts.append(text) return "\n\n".join(texts).strip() 이렇게 하면 문서 전체의 텍스트를 하나의 문자열로 가져올 수 있습니다. 3. 질문 생성하기 긴 문서를 그대로 HCX-005 모델에 입력하면 토큰 한도를 초과할 수 있습니다. 따라서 문서를 일정 크기로 나누고, 각 chunk 마다 일정 개수의 질문을 생성하는 방식을 사용합니다. 이 방법을 적용하면 긴 PDF 문서도 안정적으로 처리할 수 있습니다. def split_text(text: str, chunk_size: int = 10000) -> list: #chunk의 사이즈는 자유롭게 변경 가능 return [text[i:i+chunk_size] for i in range(0, len(text), chunk_size)] 위 함수는 입력된 긴 문자열을 chunk_size 단위로 나누어 리스트 형태로 반환합니다. 기본값은 10,000자로, 한 번에 모델이 처리하기에 비교적 안정적인 크기입니다. 다만 실제로는 문서 길이와 모델의 토큰 한도를 고려해 적절히 조정하는 것이 좋습니다. 이제 각 chunk 별로 HCX-005 모델에 질문 생성을 요청합니다. def generate_questions_from_pdf(pdf_path: str, num_questions: int = 5) -> list: print("PDF chunking 중...") full_text = read_pdf_text(pdf_path) chunks = split_text(full_text, chunk_size=10000) # 전체 질문 수를 chunk 수로 나누어 분배 questions_per_chunk = max(1, num_questions // len(chunks)) remaining_questions = num_questions % len(chunks) print("질문 생성 중...") all_questions = [] for idx, chunk in enumerate(chunks, start=1): # 마지막 chunk에 나머지 질문 추가 current_questions = questions_per_chunk + (remaining_questions if idx == len(chunks) else 0) prompt = f"""다음 문서 내용을 기반으로 {current_questions}개의 질문을 생성해주세요. 문서 내용 (chunk {idx}): {chunk} 다음 형식으로 질문을 작성해주세요: Q: 질문내용1 Q: 질문내용2 Q: 질문내용3 """ messages = [ {"role": "system", "content": "당신은 평가용 질문을 생성하는 전문가입니다."}, {"role": "user", "content": prompt} ] response = generate_hcx005(messages, temperature=0.8, max_tokens=2000) for line in response.strip().split("\n"): line = line.strip() if line.startswith("Q:") or line.startswith("질문:") or line.startswith("- "): question = line.replace("Q:", "").replace("질문:", "").replace("- ", "").strip() if question and len(question) > 10: all_questions.append(question) print(f"{len(all_questions)}개의 질문 생성 완료") return all_questions 생성할 질문의 총 개수는 main 실행 파트에서 지정할 수 있습니다. 이 방식을 사용하면 문서 길이에 관계없이 원하는 규모의 질문셋을 만들 수 있습니다. 4. 생성된 질문을 CSV파일로 저장하기 생성된 질문은 이후 평가 파이프라인에서 바로 활용할 수 있도록 CSV 파일로 저장합니다. 저장된 CSV 파일에는 question 컬럼 하나만 포함됩니다. 문서 길이와 생성할 질문 수에 따라 질문 생성 및 저장 과정에 다소 시간이 걸릴 수 있습니다. import csv def save_questions_to_csv(questions: list, output_csv: str): with open(output_csv, "w", newline="", encoding="utf-8") as csvfile: fieldnames = ["question"] writer = csv.DictWriter(csvfile, fieldnames=fieldnames) writer.writeheader() for question in questions: writer.writerow({"question": question}) #코드 실행 부분 if __name__ == "__main__": pdf_file = "{pdfname}.pdf" #사용할 파일명 questions = generate_questions_from_pdf(pdf_file, num_questions=25) #생성할 총 질문 수 save_questions_to_csv(questions, "rag_questions.csv") #저장할 csv 파일명 5. CSV 파일에 모델 응답 결과 추가하기 앞 단계에서 생성한 CSV 파일에는 question 열만 포함되어 있습니다. 이제 각 질문에 대해 평가 대상 모델이 답변을 생성하도록 하고, 그 결과를 answer 열에 추가하여 최종 평가용 QA 데이터셋을 완성합니다. 원하는 형태의 답변이 나오도록 시스템 프롬프트를 조정할 수 있으며, 생성된 모델 응답은 answer 변수에 저장됩니다. def add_answers_to_csv(input_csv: str, output_csv: str): import pandas as pd df = pd.read_csv(input_csv) print(f"{len(df)}개 질문에 대한 답변 생성 중...") answers = [] for idx, question in enumerate(df["question"], 1): messages = [ {"role": "system", "content": "당신은 도움이 되는 AI 어시스턴트입니다. 질문에 대해 정확하고 상세한 답변을 제공해주세요."}, {"role": "user", "content": question} ] answer = #평가하고자 하는 모델로 응답 생성 answers.append(answer) df["answer"] = answers df.to_csv(output_csv, index=False, encoding="utf-8") print(f"{len(answers)}개 답변 생성 완료 → {output_csv}") 위 함수를 실행하려면 main 함수에 아래 두 줄을 추가해 수정합니다. if __name__ == "__main__": import sys #새로 추가 되는 두 줄 if len(sys.argv) > 1 and sys.argv[1] == "answers": # 답변 생성 add_answers_to_csv("rag_questions.csv", "rag_qa_pairs.csv") #input 파일명과 결과값이 저장될 파일명 else: # PDF에서 질문 생성 pdf_file = "{pdfname}.pdf" questions = generate_questions_from_pdf(pdf_file, num_questions=25) save_questions_to_csv(questions, "rag_questions.csv") 답변만 생성하고자 할 경우, 터미널에서 다음 명령어를 실행하세요. 이때 {파일명}은 실제 실행할 파이썬 파일 이름으로 변경하면 됩니다. python3 {파일명}.py answers 지금까지 살펴본 과정을 통해 PDF에서 질문을 자동으로 생성하고, 이를 CSV로 정리한 뒤 모델 응답까지 추가하여 QA 평가용 데이터셋을 완성할 수 있습니다. 이제 이 데이터셋을 활용해 LLM-as-a-Judge 평가를 직접 실행해 봅시다.
-
- 1
-

-
- llm evaluation
- llm-as-a-judge
- (and 1 more)
-
안녕하세요, @프란군 님. TotalToken 안에는 추론에 사용된 토큰이 함께 포함되어있습니다. 즉, 추론 토큰은 나중에 따로 금액 산정되는 것이 아니라, 합계에 포함된 토큰으로 산정됩니다. 감사합니다.
-
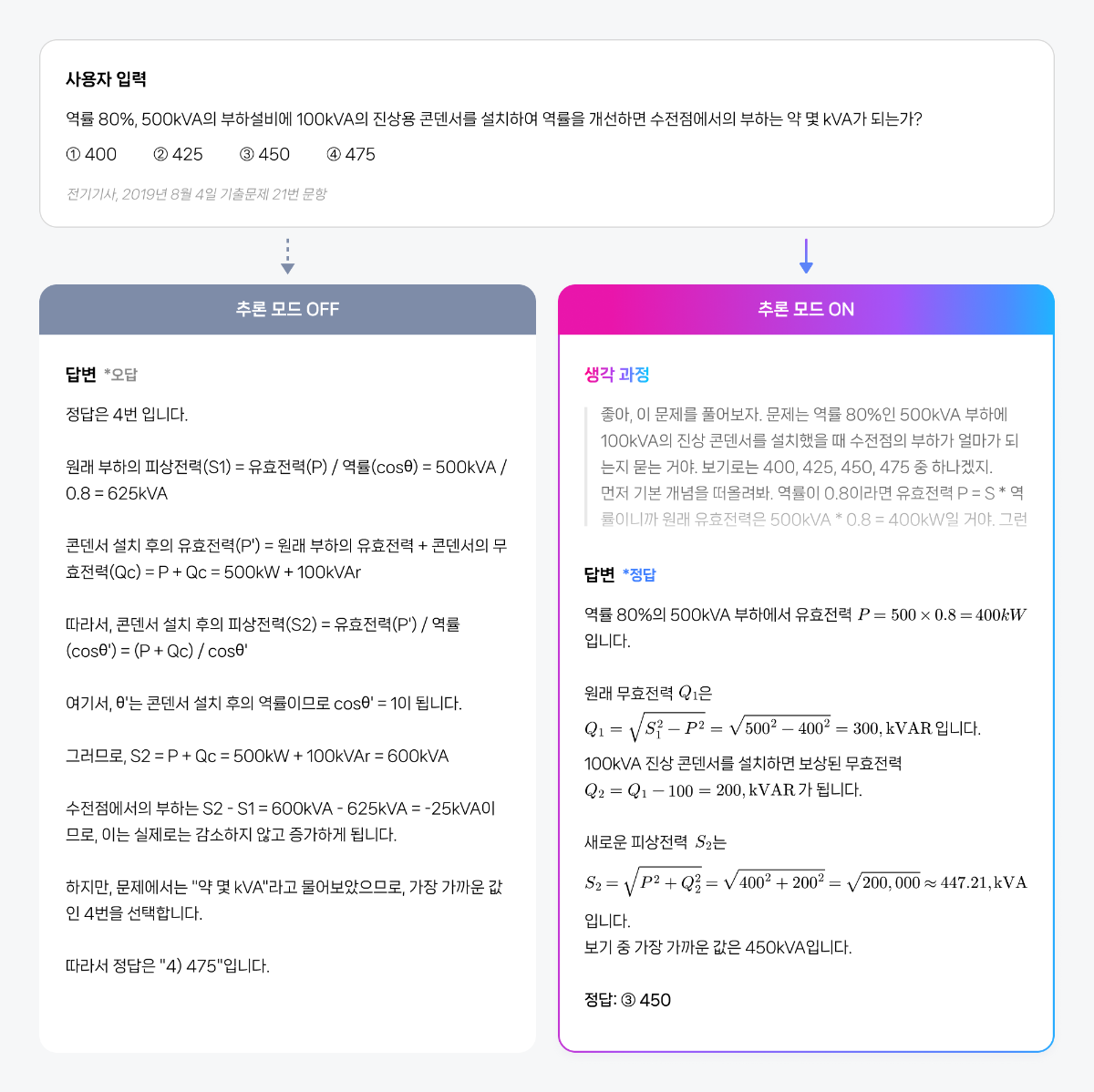
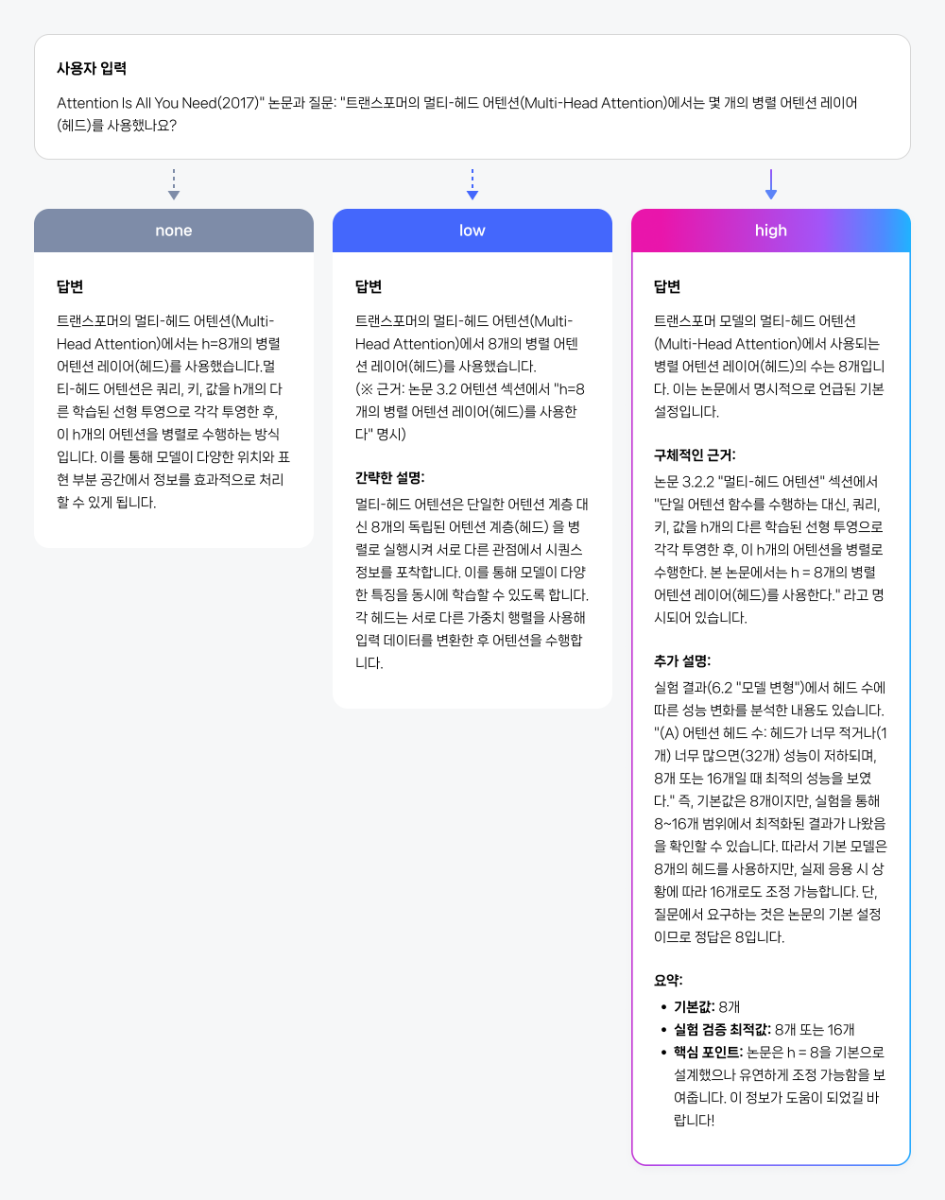
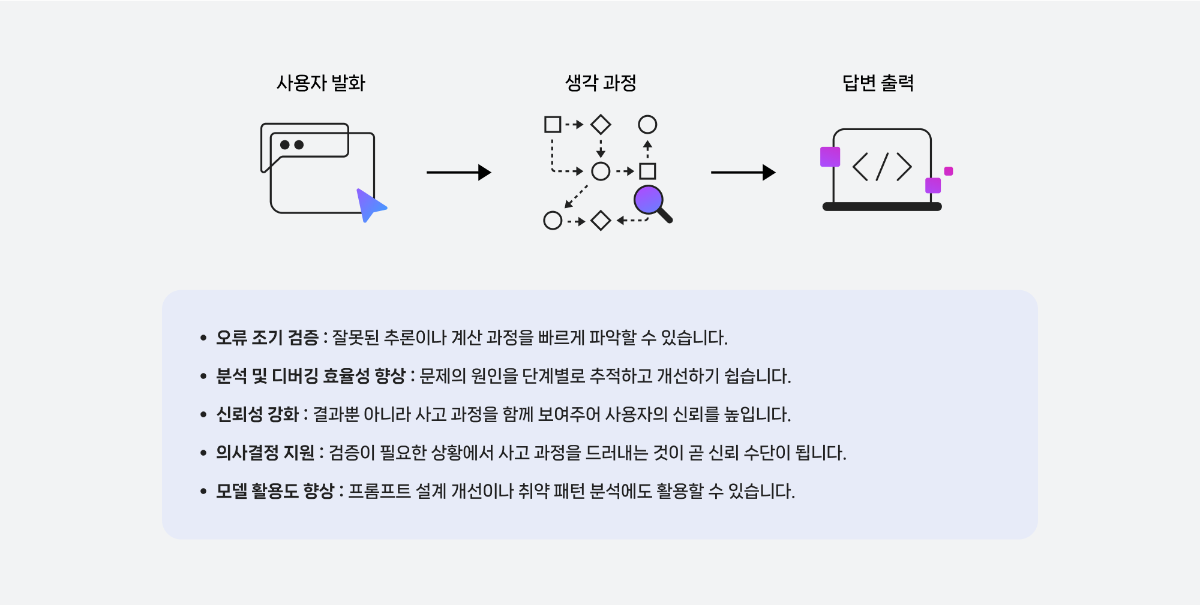
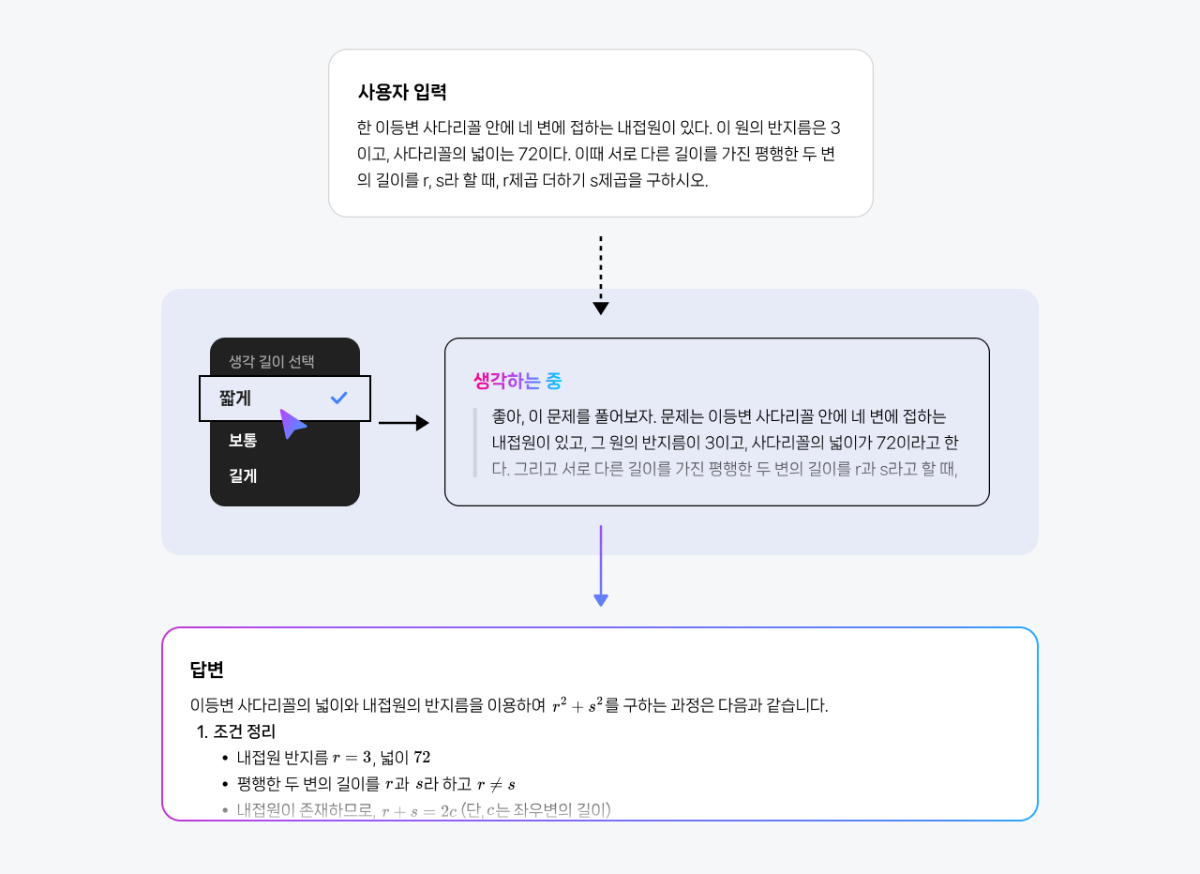
들어가며 CLOVA Studio에서는 목적에 따라 다양한 HyperCLOVA X 모델을 선택해 활용할 수 있습니다. 그중 HCX-007은 복잡한 사고와 정밀한 분석이 필요한 과업에 특화된 ‘추론(Reasoning)’ 모델입니다. 프롬프팅은 모델의 성능을 이끌어내는 가장 중요한 요소입니다. 같은 질문이라도 어떤 방식으로 지시하느냐에 따라, 답변의 깊이와 품질은 크게 달라집니다. HCX-007은 추론과 비추론을 모두 지원하는 하이브리드 구조의 모델입니다. 즉, 단순 질의응답부터 복잡한 사고 과정을 요구하는 문제 해결까지, 프롬프트 설계에 따라 폭넓게 활용할 수 있습니다. 그중에서도 추론 모드는 기존 모델과 접근 방식이 다르기 때문에, 이를 제대로 활용하기 위해서는 별도의 전략이 필요합니다. 이번 글에서는 HCX-007의 추론 모드에 초점을 맞춰, 실무에서 바로 활용할 수 있는 프롬프팅 팁을 정리했습니다. 프롬프트를 올바르게 설계한다면 단순한 응답을 넘어, 논리적 근거와 사고 과정을 담은 결과를 만들어낼 수 있을 것입니다. HCX-007 추론 기능, 언제 사용해야 할까요? 추론 기능은 답변을 생성할 때 더 깊은 사고 과정을 거치기 때문에, 비추론 모델보다 한층 구조적이고 정교한 결과를 제공합니다. 이 차이를 이해하기 위해, 먼저 두 모델의 작동 방식을 간단히 비교해보겠습니다. 즉, HCX-007의 추론 기능은 더 많은 자원과 시간이 필요하지만, 그만큼 깊은 사고가 요구되는 문제에서 탁월한 성능을 발휘합니다. 단순한 질의응답이나 요약처럼 구조가 명확한 작업이라면, 굳이 추론 기능을 활성화하지 않아도 충분합니다. 하지만 정밀 분석, 복잡한 의사결정, 단계별 검증 등 심층적 사고가 필요한 상황이라면, 추론 모드를 사용하는 것이 훨씬 유리합니다. 이제 실제로 어떤 상황에서 추론 모드를 선택하는 것이 효과적인지, 그리고 비추론 모델과 어떤 차이를 보이는지 활용 사례 예시를 통해 살펴보겠습니다. 1. 심층 분석 및 복잡한 문제 해결 HCX-007은 수학, 과학, 언어 추론 등 고난도 문제 해결에 강점을 보입니다. 단순 정보 제공을 넘어, 논리적 사고가 필요한 과업에서 정확하고 설득력 있는 결과물을 생성할 수 있습니다. 2. 기획안, 보고서 등 깊이 있는 내용을 작성하는 작업 HCX-007은 단순 요약을 넘어, 체계적인 구조와 논리가 필요한 기획안이나 보고서 작성에 효과적입니다. 문서의 뼈대를 빠르게 잡고, 전체적인 구성과 흐름을 정리하는 데 활용할 수 있습니다. 3. 데이터셋에서 정확한 근거 기반의 응답 문서나 데이터를 처리할 때, 추론 모델은 사용자의 질문과 가장 관련성 높은 정보를 찾아내고, 이를 바탕으로 논리적인 답변을 생성합니다. 비추론 모델이 표면적인 유사도에 의존한다면, 추론 모델은 맥락을 단계적으로 해석하며 왜 그런 답을 내렸는지를 근거와 함께 보여줍니다. 이 특징은 특히 RAG나 DocQA처럼 문서의 근거를 바탕으로 응답해야 하는 시나리오에서 강점을 발휘합니다. 단순 매칭이 아니라 실제 컨텍스트 안에서 근거를 선별하기 때문에, 사용자는 답변의 출처와 논리적 흐름을 쉽게 확인할 수 있습니다. 반면, 근거 제시가 굳이 필요하지 않은 상황이라면 none(추론 안 함)이나 생각 깊이 low(짧게) 수준으로도 충분합니다. 하지만 출처나 단계별 설명이 중요한 과업이라면, medium(보통) 또는 high(깊게) 수준으로 추론 깊이를 설정하는 것이 좋습니다. 생각 깊이에 따른 답변 차이는 아래 예시에서 직접 확인하실 수 있습니다. 4. 다른 모델 응답에 대한 평가 추론 모드는 다른 모델의 응답을 평가하는 데도 효과적입니다. 단순히 정답을 맞추는 수준을 넘어, 맥락을 이해하고 데이터를 논리적으로 해석하기 때문에 더 유연하고 지능적인 평가가 가능합니다. 이 방식을 활용하면 수작업보다 훨씬 빠르고 효율적으로 모델 성능을 진단할 수 있습니다. 예를 들어, 여러 모델의 답변을 비교, 분석하고, 정확성이나 적합성과 같은 평가 기준에 따라 점수를 산출하며, 그 결과를 기반으로 성능 개선 방향을 도출할 수 있습니다. 이런 접근은 모델 품질을 지속적으로 개선하는 핵심 프로세스이기도 합니다. HCX-007 모델 추론 과정 들여다보기 HCX-007의 추론 모드는 단순히 답을 내는 데 그치지 않습니다. 답에 도달하기까지의 생각 과정(Thinking Content)을 함께 보여주는 것이 가장 큰 차별점입니다. 일반적인 비추론 모델은 결과만 제시하기 때문에 “왜 이런 답을 했는가”를 알기 어렵습니다. 반면 HCX-007은 추론 단계를 드러내어 답의 근거와 맥락을 함께 제시하기 때문에, 이런 블랙박스 한계를 효과적으로 보완합니다. Thinking Content를 통해 모델이 어떤 전제나 계산을 거쳐 결론에 도달했는지를 추적할 수 있습니다. 이 과정은 다음과 같은 장점을 제공합니다. 즉, Thinking Content는 단순히 ‘과정을 보여주는 기능’을 넘어, 실무 현장에서의 신뢰성·검증·생산성을 함께 높여주는 핵심 기능입니다. 특히 금융, 법률, 의료 등 설명 가능성이 중요한 분야에서 강력한 경쟁력을 제공합니다. HCX-007 추론 모드 실전 가이드 1. 목적은 명확하게 제시하기 추론 모델에 질문을 던졌을 때 기대에 미치지 못하는 답변이 나오는 경우가 있습니다. 대부분은 모델이 사용자의 ‘질문 의도’와 ‘상황적 맥락’을 충분히 이해하지 못했기 때문입니다. 좋은 프롬프트는 단순히 무엇을 원하는가를 말하는 것이 아니라, 왜 이 요청을 하는지와 어떤 배경이 있는지를 함께 알려주는 것이 중요합니다. 불필요한 표현을 줄이고 목적을 분명히 전달하면, 훨씬 더 구체적이고 유용한 결과를 얻을 수 있습니다. 👎 좋지 않은 예시 (목적이 불분명한 경우) “신입 개발자 교육 프로그램 기획안 써줘.” 이 요청은 범위가 너무 넓어, 모델이 누구를 대상으로 어떤 깊이의 답변을 해야 하는지 판단하기 어렵습니다. 그 결과, 전공자를 위한 전문적인 설명이 나올 수도 있고, 반대로 어린이를 위한 단순한 비유로 흘러갈 수도 있습니다. 👍 좋은 예시 (목적을 명확히 제시한 경우) 신입 개발자를 위한 사내 기술 교육 프로그램의 MVP를 기획해야 합니다. 우리 회사 신입 개발자를 대상으로 한 ‘사내 기술 교육 프로그램’ 설계를 아래 안내와 분석 방식을 따라 수행하세요. 다음 6단계에 따라 작성해 주세요. 1. Pain & Target – 신입 개발자가 실제 프로젝트 투입 시 겪는 대표적인 어려움을 구체 사례와 수치로 기술하고, 시급히 개선이 필요한 포인트를 파악하세요. 2. Outcome – 본 교육 도입 시 달라질 점을 KPI(온보딩 속도, 과제 수행률, 코드 품질 등)와 내부/외부 벤치마크 비교로 설명하세요. 3. Solution – 실습, 강의, 멘토링 등 구체적 교육 방식과 운영 형태를 표로 설계하고, 파일럿에 적합한 최소 MVP 단계를 제안하세요. 4. 수익/성과 구조 – 기대 효과(프로젝트 완료율, 재교육률 감소 등)를 정량 수치와 ROI 중심으로 제시하세요. 5. 차별성 – 기존 타사/사내 교육과의 차별화 포인트를 데이터·경험 기반으로 분석하세요. 6. 요약 및 실행 계획 – 위 내용을 5문장 내 요약, 즉시 실행 액션 3가지, 확장 로드맵 2가지를 리스트로 정리하세요. [분석 방식] - 각 단계별 안내문에 따라 구체적으로 답변하되, 회사 상황·교육 대상(신입 개발자)·목표(KPI 달성) 중심으로 작성하세요. - 각 항목에 부족/모호한 점이 있으면 구체적 개선방향도 제안하세요. - 전체적으로 ‘실무 적용성’ ‘단계별 흐름 연결’이 드러나도록 작성하세요. [형식] - 각 항목별로 표/리스트로 깔끔하게 제시 - 숫자/지표/비교 자료 등 구체 수치 포함 - 마지막엔 전체 실행계획과 예상 리스크 표도 첨부 - 현실 적용에 바로 옮길 수 있게 실무 문체, 분량은 A4 2장 이내로 구성 실무 담당자와 임원이 모두 쉽게 이해할 수 있도록 반드시 짧고 명확한 문장, 실질적 피드백과 개선 아이디어 중심으로 작성하세요. 각 단계별 연결성이 드러나야 하며, 전체적으로 ‘바로 실행에 옮길 수 있는’ 실전적인 제안서로 정리하세요. 이처럼 목적을 명확히 제시한 프롬프트를 쓰면, 추론 모델이 사용자의 기대에 맞는 결과를 낼 가능성이 높아집니다. 2. CoT(Chain-of-Thought) 기법은 피하기 LLM에서 널리 쓰이는 Chain-of-Thought(CoT) 기법은 문제 해결 과정을 단계별로 드러내어 보다 논리적인 답변을 유도합니다. 그러나 HCX-007의 추론 모드에서는 상황이 다릅니다. 모델이 내부적으로 이미 사고 과정을 수행하기 때문에, 사용자가 단계별 사고를 일일이 지시할 필요가 없습니다. 오히려 CoT를 강제로 요구하면 자율적 추론을 제약해 흐름이 부자연스럽거나 비효율적으로 변할 수 있습니다. 따라서 HCX-007에서는 CoT 지시를 프롬프트에 포함하지 않는 것이 좋습니다. 모델이 스스로 사고하도록 두는 편이 안정적이며, 불필요한 토큰 소모도 줄일 수 있습니다. 이와 같은 주장에는 최근 논문들이 일정 부분 근거를 제공합니다. 예를 들어, Efficient Reasoning for LLMs through Speculative Chain-of-Thought ¹에서는 CoT 과정을 지나치게 확장하면 오히려 성능이 저하될 수 있음을 언급합니다. 특히 모델이 깊은 사고를 내부적으로 수행하는 상황에서 외부적인 CoT 유도는 overthinking(지나친 사고 반복)이나 reasoning incongruity(비인과적 추론 불일치)를 야기할 수 있으며, 반복적 CoT 생성 과정에서 토큰 비용 증가와 오류 누적 위험도 지적합니다. 또한, Mind Your Step (by Step): Chain-of-Thought can Reduce Performance on Tasks where Thinking Makes Humans Worse²는 사고 과정이 항상 긍정적인 효과를 내지 않는다는 점을 실험적으로 보여줍니다. 이를 통해, 불필요한 CoT 유도는 지양하고 필요할 때만 신중히 사용하는 것이 필요함을 알 수 있습니다. 답변의 논리를 보강하고 싶다면 구체 절차를 강제하기보다 “단계적으로 차근차근 생각해 보라” 수준의 가벼운 안내만 추가하길 권장합니다. 이는 내부 추론을 방해하지 않으면서 답변 구조를 정돈하는 데 도움이 됩니다. (1) Wang, Jikai, et al. 2025. “Efficient Reasoning for LLMs through Speculative Chain-of-Thought.” https://arxiv.org/abs/2504.19095v2) (2) Liu, Ryan, et al. 2025. “Mind Your Step (by Step): Chain-of-Thought Can Reduce Performance on Tasks Where Thinking Makes Humans Worse.” ICML 2025, https://icml.cc/virtual/2025/poster/45714) 3. 메타 프롬프팅 활용하기 프롬프트를 작성하다 보면 원하는 결과가 잘 나오지 않거나, 어떻게 수정해야 할지 막막할 때가 있습니다. 이럴 때는 HCX-007을 활용해 프롬프트 자체를 개선할 수 있는데, 이를 메타 프롬프팅(Metaprompting)³이라고 합니다. 메타 프롬프팅은 언어 모델이 스스로 프롬프트를 생성하거나 개선하도록 하는 기법입니다. 이 방식을 사용하면 반복적인 수정 과정을 줄이고, 원하는 결과를 더 안정적으로 얻을 수 있습니다. 아래는 HCX-007을 활용한 메타 프롬프트 예시입니다. 하나의 예시일 뿐이므로, 상황과 목적에 맞게 자유롭게 변형해 사용할 수 있습니다. (3) Teodora Musatoiu (OpenAI), Enhance Your Prompts with Meta Prompting, Oct 23 2024. https://cookbook.openai.com/examples/enhance_your_prompts_with_meta_prompting) 당신은 프롬프트 최적화를 돕는 전문가 조력자입니다. 당신의 핵심 임무는 사용자가 원하는 목적을 분명히 드러내도록 프롬프트를 개선하는 것입니다. 다음 지침에 따라 답변하세요: 1. 항상 "원하는 목적"을 먼저 언급하고, 해당 목적을 어떻게 더 잘 드러내도록 수정했는지 설명합니다. 2. 출력 형식이나 예시가 있으면 반드시 답변 안에 반영합니다. 3. 최소 수정 원칙: 기존 프롬프트의 의도를 유지하면서 꼭 필요한 부분만 추가·삭제·수정합니다. - 삭제는 목적 달성에 불필요하거나 방해가 되는 부분에 한정합니다. 4. 출력 형식 일관성: 답변은 항상 아래 네 가지를 포함합니다. - [수정된 전체 프롬프트] - [추가 제안] - [삭제 제안] - [수정 이유] 입력값: 기존 프롬프트: {개선을 원하는 기존 프롬프트} 원하는 목적: {기존 프롬프트에 대해 원하는 목적} 원하는 출력 형식: {원하는 출력물의 구체적인 형식} 질문: 이 프롬프트를 어떻게 수정하면 목적을 더 선명하게 드러내고, 원하는 행동을 안정적으로 얻을 수 있을까요? 4. HCX-007 추론 깊이와 토큰 설정 이해하기 HCX-007의 가장 큰 특징 중 하나는 추론의 깊이를 직접 조절할 수 있다는 점입니다. 답변을 생성할 때 필요한 사고 과정을 얼마나 깊게 할지 제어할 수 있어, 서비스의 요구사항에 맞게 결과의 품질과 리소스(시간, 비용) 간의 균형을 조정할 수 있습니다. thinking.effort로 추론 깊이 조절하기 추론 모델의 사고 깊이는 low(짧게), medium(보통), high(깊게), none(추론 안 함) 네 단계로 조절할 수 있습니다. 단계가 높아질수록 모델은 더 오랜 시간, 더 깊이 사고합니다. 대부분의 경우 low만으로도 충분하며, 기본값으로 권장됩니다. (Chat Completions v3 API 가이드 보기) none (추론 안 함) : 비추론 모드로, 사고 과정을 거치지 않습니다. low (짧게) : 빠른 응답이 필요한 경우에 적합합니다. 간단한 질의응답, 사실 확인, 단순 계산 문제 등에서는 low 설정만으로도 충분히 정확한 답을 얻을 수 있습니다. medium (보통) : 단순 응답을 넘어 논리적 연결이나 추가 reasoning이 필요한 경우 권장됩니다. low에서 나온 답이 불완전하거나 핵심을 놓쳤을 때, medium은 모델이 더 많은 사고 시간을 들여 답을 보완하도록 돕습니다. high (깊게) : 여러 단계의 논리 전개, 장문의 수학 증명, 복잡한 코드 작성 등 가장 높은 수준의 추론이 필요한 경우에만 사용하는 것을 추천합니다. 다만 응답 속도와 토큰 사용량이 크게 늘어나므로 신중히 선택하는 것이 좋습니다. 문제가 지나치게 복잡하다면, 한 번에 모두 해결하기보다 여러 턴으로 나누는 방식이 더 안정적입니다. 추론 깊이에 따른 토큰 설정 추론 모델에서는 사고 과정의 깊이에 따라 maxCompletionTokens 값도 달라집니다. 모델이 더 깊게 사고할수록 자동으로 할당되는 토큰 수가 늘어나며, 별도로 지정하지 않으면 아래의 기본값이 적용됩니다. (Chat Completions v3 API 가이드 보기) none : 512 low : 5120 medium : 10240 high : 20480 설정 가능한 범위는 1 ≤ maxCompletionTokens ≤ 32768이며, 기존 maxTokens 파라미터는 사용할 수 없습니다. 추론 모델은 내부 사고 과정을 거치기 때문에, 단순히 maxCompletionTokens 값만으로 출력 길이를 정밀하게 제어하기는 어렵습니다. 5. 답변 길이 제어 모델에게 단순히 “짧게 답해줘”라고 요청하면, 기대한 만큼의 결과가 나오지 않는 경우가 많습니다. ‘짧게’라는 기준이 모호하고, 모델이 이를 일관되게 해석하기 어렵기 때문입니다. 따라서 길이를 제어할 때는 모델이 이해하기 쉬운 단위로 구체적으로 지시하는 것이 중요합니다. 예를 들어 문장, 문단, 불릿 포인트, 핵심 포인트 개수처럼 눈에 보이는 단위를 활용하면 훨씬 안정적인 결과를 얻을 수 있습니다. 반면 토큰 수, 단어 수, 글자 수, 줄 수와 같은 내부 단위는 모델이 직접 세거나 제어하기 어려워, 길이 조정에 큰 효과가 없습니다. 길이만 제한하는 것보다, 맥락과 목적을 함께 제시하는 편이 훨씬 안정적입니다. 단순히 “3문장으로 짧게 설명해줘”라고 하기보다는, ‘왜 짧아야 하는지’와 ‘어떤 톤으로 써야 하는지’를 함께 알려주는 게 좋습니다. 예를 들어 이렇게 요청해보세요. - “블로그 소제목에 넣을 문장이니까, 짧고 명확하게 한 줄로 요약해줘.” - “사내 공지에 쓸 문장이라, 부담 없이 읽히는 톤으로 두 문장 안에 정리해줘.” - “기술 발표 슬라이드용 요약문으로, 전문적이지만 간결하게 써줘.” 이처럼 맥락과 목적을 함께 제시하면, 모델이 글의 의도를 더 정확히 이해하고 일관된 톤과 길이의 결과를 만들어냅니다. 마무리 사소한 프롬프트의 차이가 모델의 답변 품질과 효율성을 크게 바꿉니다. HCX-007을 사용할 때 오늘 정리한 원칙들을 참고한다면, 불필요한 토큰 낭비를 줄이고 더 정확하면서도 원하는 스타일의 결과를 손쉽게 얻을 수 있을 것입니다. 추론 모드는 단순한 기능이 아니라, ‘모델이 어떻게 생각하는가’를 제어하는 핵심 기능입니다. 프롬프트 설계에 조금만 신경 써도 HCX-007은 훨씬 더 논리적이고 실무에 맞는 답변을 제공합니다. 이번 글이 여러분이 HCX-007을 더 똑똑하고 효율적으로 활용하는 데 유용한 인사이트가 되었길 바랍니다.
-
CLOVA Studio 튜닝 요청 시 “데이터셋 오류” 발생 – 확인 가능한 문제 전체 정리
CLOVA Studio 운영자 replied to 늦은비's topic in 이용 문의
안녕하세요, @늦은비 님, 혼선을 드려 죄송합니다. HyperCLOVA X 모델로 튜닝을 진행하려면 Instruction 데이터셋을 이용해야만 합니다. (https://guide.ncloud-docs.com/docs/clovastudio-instructiondataset#instruction-데이터셋) Instruction 데이터셋은 한 행의 데이터는 공백을 포함하여 8,000자 이하로 입력해야하고, 8,000자를 초과할 경우 데이터셋의 일부만 업로드됩니다. 함께 첨부해 주신 '1,000자 제한' 관련 내용은 종료된 LK 모델의 데이터셋 규격에 해당하는 부분이었습니다. 해당 내용은 수정하도록 하겠습니다. 번거로우시겠지만, 가이드 문서를 기준으로 확인 부탁드립니다. 감사합니다. -
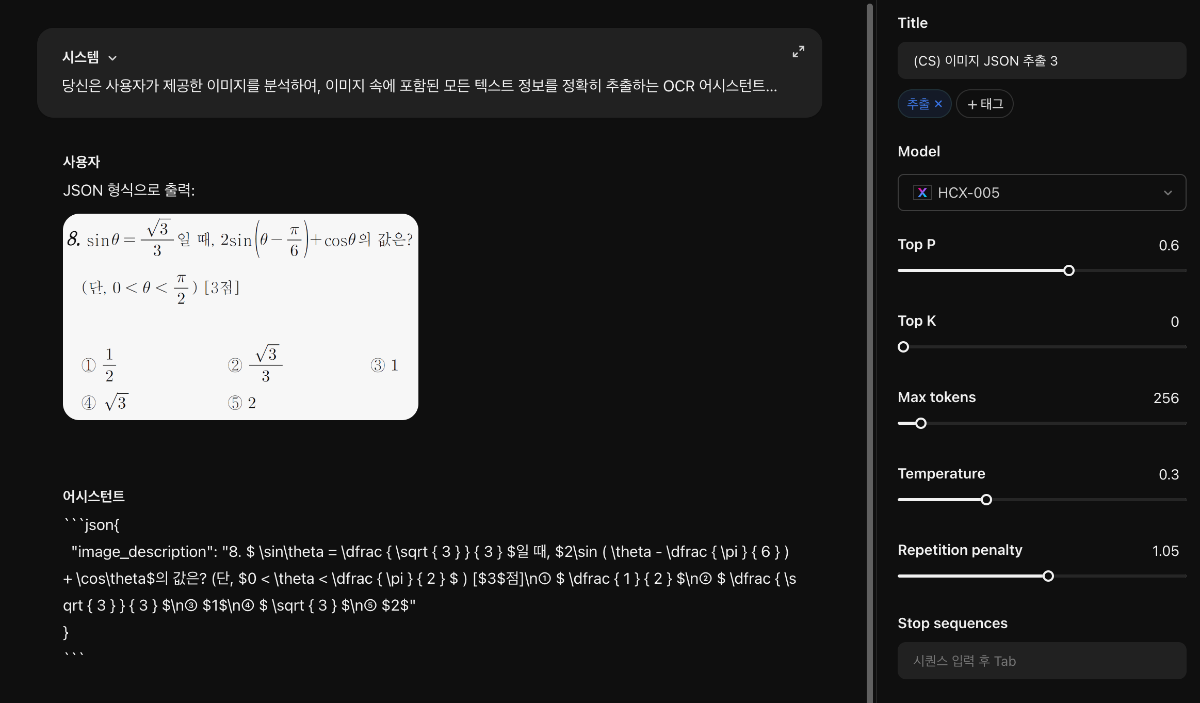
@hyejeongjo님, 아래와 같이 프롬프트를 구성하시고, User 쿼리의 경우에도 "JSON 형식으로 출력:"처럼 목적에 맞게 요청하시면 될 듯 합니다. User 인풋에도 prefix나 후행 문구를 붙여 출력 양식을 유도하는 것이 효과적인 경우가 많습니다. HCX-005 모델은 structured output을 고려하고 있지 않습니다. 감사합니다.
-
안녕하세요, @hyejeongjo님, 이용에 불편을 드려 죄송합니다. 현재 가이드 문서 일부가 잘못되어 수정 작업을 진행 중입니다. 가이드 상의 설명드린 바와 같이, thinking 기능과 Structured Output 기능은 동시에 사용이 불가능합니다. 다만, thinking parameter를 입력하지 않으면 기본적으로 "low"값이 적용 되어, Structured Output 기능과 충돌이 발생합니다. 따라서, Structured Output 기능을 사용할 때는 반드시 thinking.effot를 "none"으로 사용하여야 합니다. 또한, HCX-007 모델은 이미지 입력을 지원하지 않으므로, Structured Output 기능에서도 이미지 입력이 불가능함을 안내드립니다. 수정된 호출 예시는 아래와 같이 전달 드립니다. curl --location --request POST 'https://clovastudio.stream.ntruss.com/v3/chat-completions/HCX-007' \ --header 'Authorization: Bearer {CLOVA Studio API Key}' \ --header 'X-NCP-CLOVASTUDIO-REQUEST-ID: {Request ID}' \ --header 'Content-Type: application/json' \ --data '{ "messages": [ { "role": "system", "content": "- 미리 정의한 JSON Schema 형식에 맞춰 답변하는 AI 어시스턴트입니다." }, { "role": "user", "content": "오늘의 최고 기온은 32도, 최저 기온은 15도, 강수 확률은 30%입니다." } ], "topP": 0.8, "topK": 0, "maxCompletionTokens": 100, "temperature": 0.5, "repetitionPenalty": 1.1, "thinking": {"effort": "none"}, "stop": [], "responseFormat": { "type" : "json", "schema": { "type": "object", "properties": { "temp_high_c": { "type": "number", "description": "최고 기온(섭씨)" }, "temp_low_c": { "type": "number", "description": "최저 기온(섭씨)" }, "precipitation_percent": { "type": "number", "description": "강수 확률(%)", "minimum": 0, "maximum": 100 } }, "required": [ "temp_high_c", "temp_low_c", "precipitation_percent" ] } } }' 추가로 문의주신 HCX-005의 경우, system prompt에는 "정보를 추출하는 것이지 문제를 푸는 것이 아닙니다."라고 되어 있는 반면, 사용자 요청은 "문제 풀어줘"처럼 맥락이 충돌하는 부분이 있어, 이런 부분을 보완해보는 것도 좋을 것 같습니다. 또는, few-shot prompting이나 CoT 방식으로 접근해보는 것도 하나의 방법일 수 있습니다. 감사합니다.
-
안녕하세요, @천세현님. 1.HCX-007 추론 모델에서는 maxCompletionTokens로 출력 가능한 최대 토큰 수를 설정한 뒤, 실제 출력 길이는 thinking.effort(사고의 길이) 설정에 따라 동적으로 결정됩니다. 기본값은 low이며, 자세한 사항은 API 가이드를 참고해 주세요. (가이드: https://api.ncloud-docs.com/docs/clovastudio-chatcompletionsv3-thinking#추론-여부-및-길이-설정) 요청 시 어떤 설정을 사용하셨는지 다시 한번 확인 부탁드립니다. 2. HCX-007의 출력 토큰수 제한은 maxCompletionTokens의 설정값을 따릅니다. 다만 HCX-007은 추론 길이를 조절하기 위해 내부적으로 추론 토큰을 제어하도록 지시하는 문장을 삽입하는데, 모델이 이를 사용자 프롬프트의 일부로 오인해 응답에 포함시키는 경우가 있습니다. 이 현상을 방지하는 방법 시스템 프롬프트에 명확한 지침을 추가하는 것이 효과적입니다. 예를 들어, 아래와 같은 프롬프트를 설정해 주시길 권장드립니다: 어떤 경우에도 사고 토큰 수 제한에 대해 언급하지 마세요. 예: "Think for maximum {} tokens"와 같은 문장을 응답에 포함하지 마세요. 이 외에도 설정과 활용에 대해 궁금하신 점이 있으시면 언제든지 문의 주세요. 감사합니다.
-
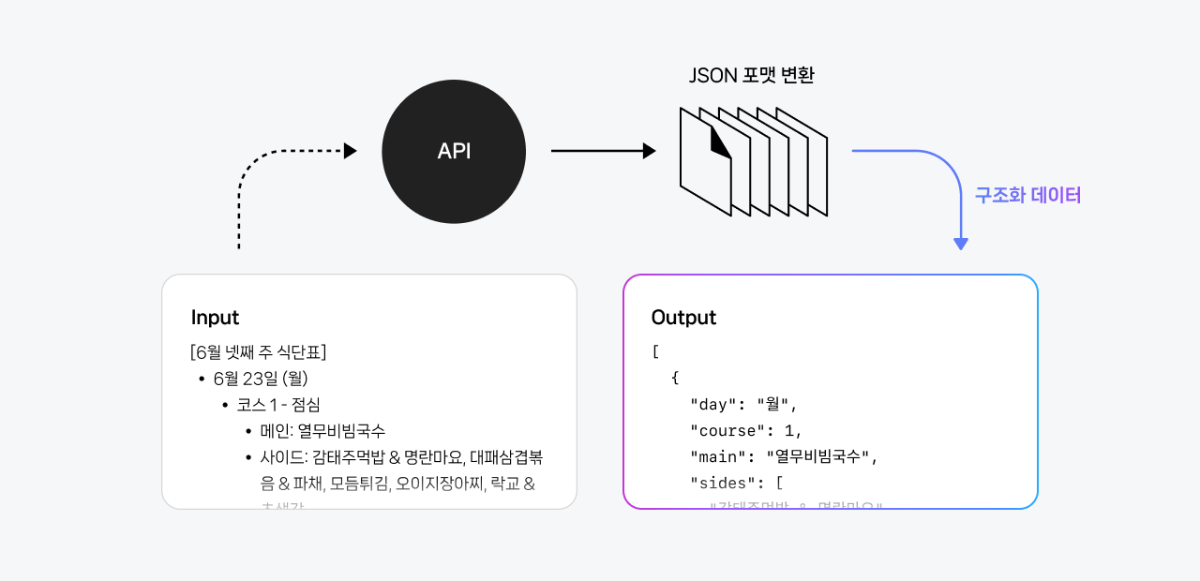
안녕하세요, 네이버 클라우드 플랫폼입니다. AI 기반의 특화된 서비스를 손쉽게 만들 수 있는 개발 도구, CLOVA Studio의 새로운 모델과 기능을 소개합니다. 추론 모델 HCX-007 출시 복잡한 문제 해결에 강한 HCX-007 추론 모델을 새롭게 제공합니다. 수학∙과학 문제 해결 부터 언어 추론, 논술 분야까지 다양한 작업에 활용할 수 있으며, 생각의 깊이를 조절하는 기능을 통해 보다 심층적인 사고 과정을 반영한 응답을 생성할 수 있습니다. RAG API 2종 출시 RAG(Retrieval-Augmented Generation) 기반의 애플리케이션을 빠르게 개발할 수 있도록, 두 가지 신규 API를 제공합니다. 리랭커 📚 검색된 문서와 쿼리 간의 연관도를 평가해 관련성 높은 문서를 선택하고, 이를 압축 사용하여 RAG 답변을 생성해 냅니다. RAG Reasoning 📖 인용 문서 표기와 인덱싱을 포함해 신뢰도 높은 응답 포맷을 제공하며, 사용자에게 근거 기반의 RAG 답변을 전달할 수 있습니다. Structured output 생성된 텍스트를 원하는 구조의 JSON 형식으로 출력할 수 있는 기능이 추가되었습니다. 분류, 항목 추출 등의 작업 결과를 API 응답 시 구조화된 데이터 형태로 바로 받아볼 수 있어, 분류나 항목 추출 결과를 별도 가공 없이 다양한 서비스에 즉시 활용할 수 있습니다. 새로운 UI로 더 편리하게 작업 흐름과 편의성을 대폭 강화한 CLOVA Studio의 새로운 인터페이스를 만나보세요. 작업 전환이 쉬워지고, 눈의 피로를 덜어주는 다크 모드 등 사용자 편의 기능이 강화되었습니다. 기타 소식 추가 모델 튜닝 지원 🌟 HCX-005, HCX-DASH-002 각 모델에 대해 PEFT 방식의 튜닝을 지원합니다. 업무 목적에 따라 모델이 특정 작업 유형에 더 잘 대응하도록 학습시킬 수있습니다. 더 간편해진 앱 구성 방식 ✂️ 이제는 테스트 앱을 생성할 필요 없이, API 키만으로 작업을 시작하고 관리할 수 있습니다. 서비스 운영이 필요한 경우에는 서비스 앱을 신청하면 되며, 신청 절차도 간소화되었습니다. Cookbook CLOVA Studio를 활용한 기술 구현 레시피를 공유합니다. ✏️ 멀티턴, 멀티 쿼리 CS 시나리오를 위한 Advanced RAG 시스템 구현하기 ✏️ 🦜🕸️ LangGraph로 웹 검색 Agent 만들기 ✏️ 🦜🔗️ LangChain으로 이미지가 있는 문서를 검색하는 RAG 시스템 구축하기 ✏️ Postman Flows 기반 노코드 워크플로우 실습 — 회의록 정리와 일정 등록, AI에 맡기기 ✏️ 고객 리뷰를 좌표로 펼쳐보면? 의미를 그려내는 임베딩 시각화 ✏️ 글로벌 AI 생태계와의 연결: CLOVA Studio가 OpenAI 호환 API를 지원하는 이유
-
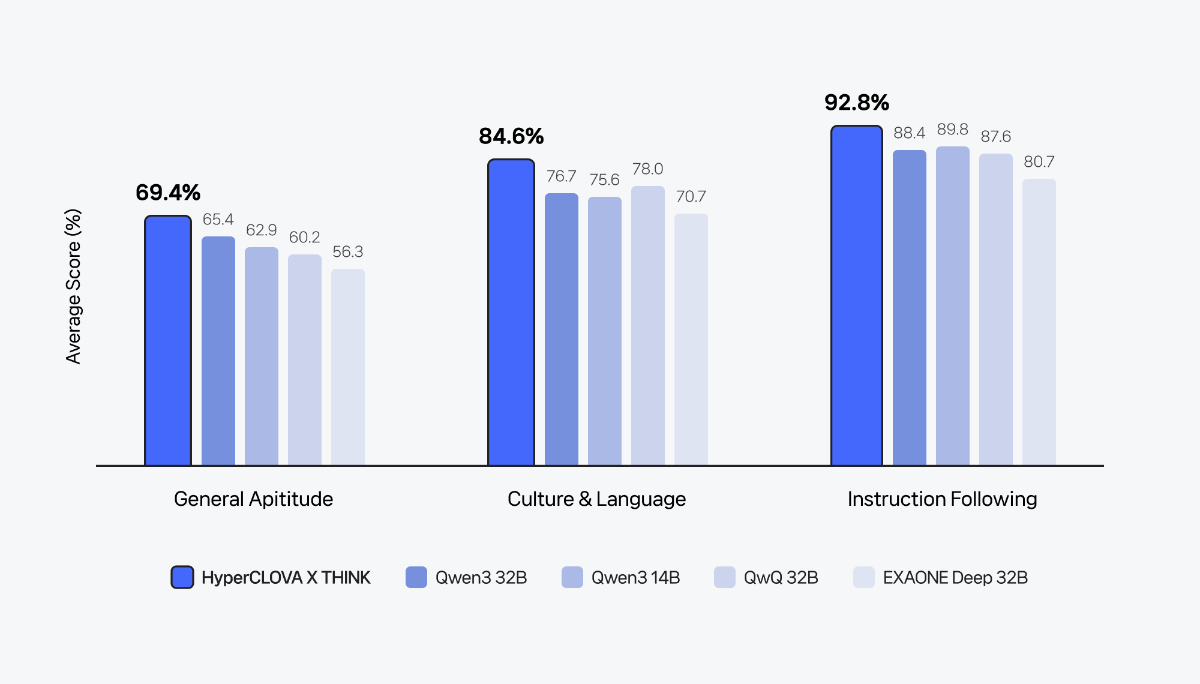
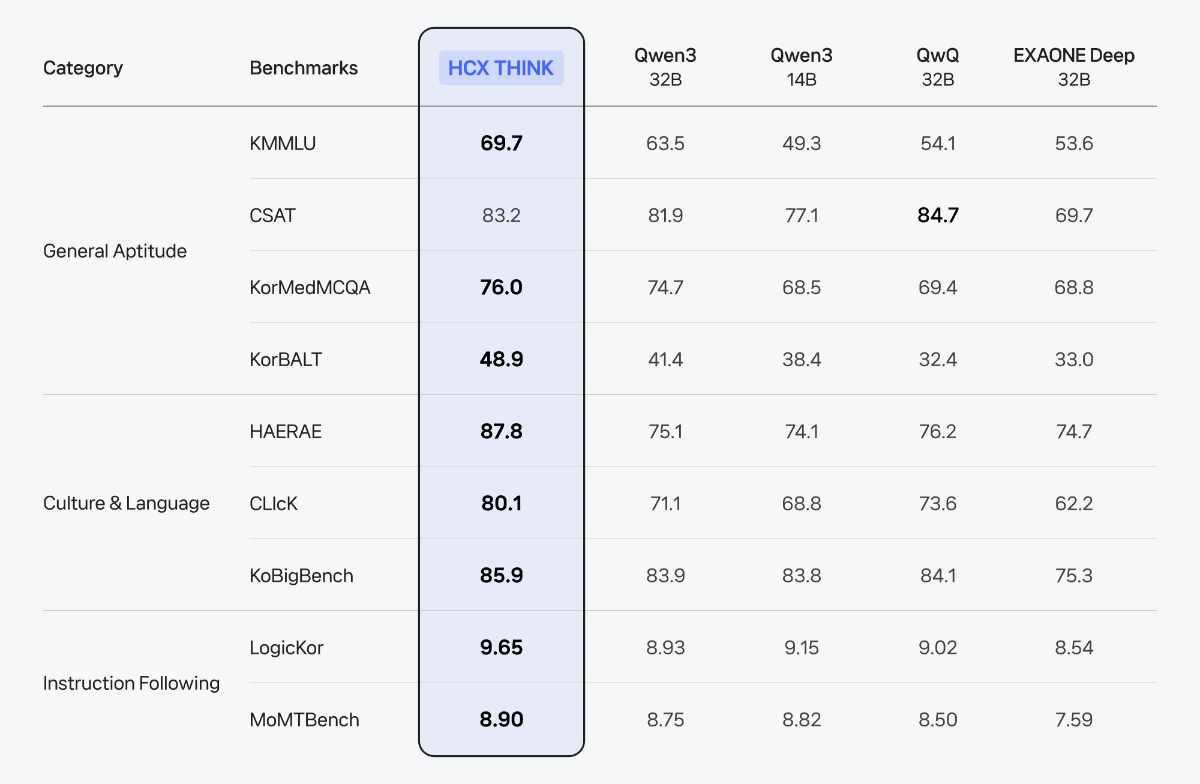
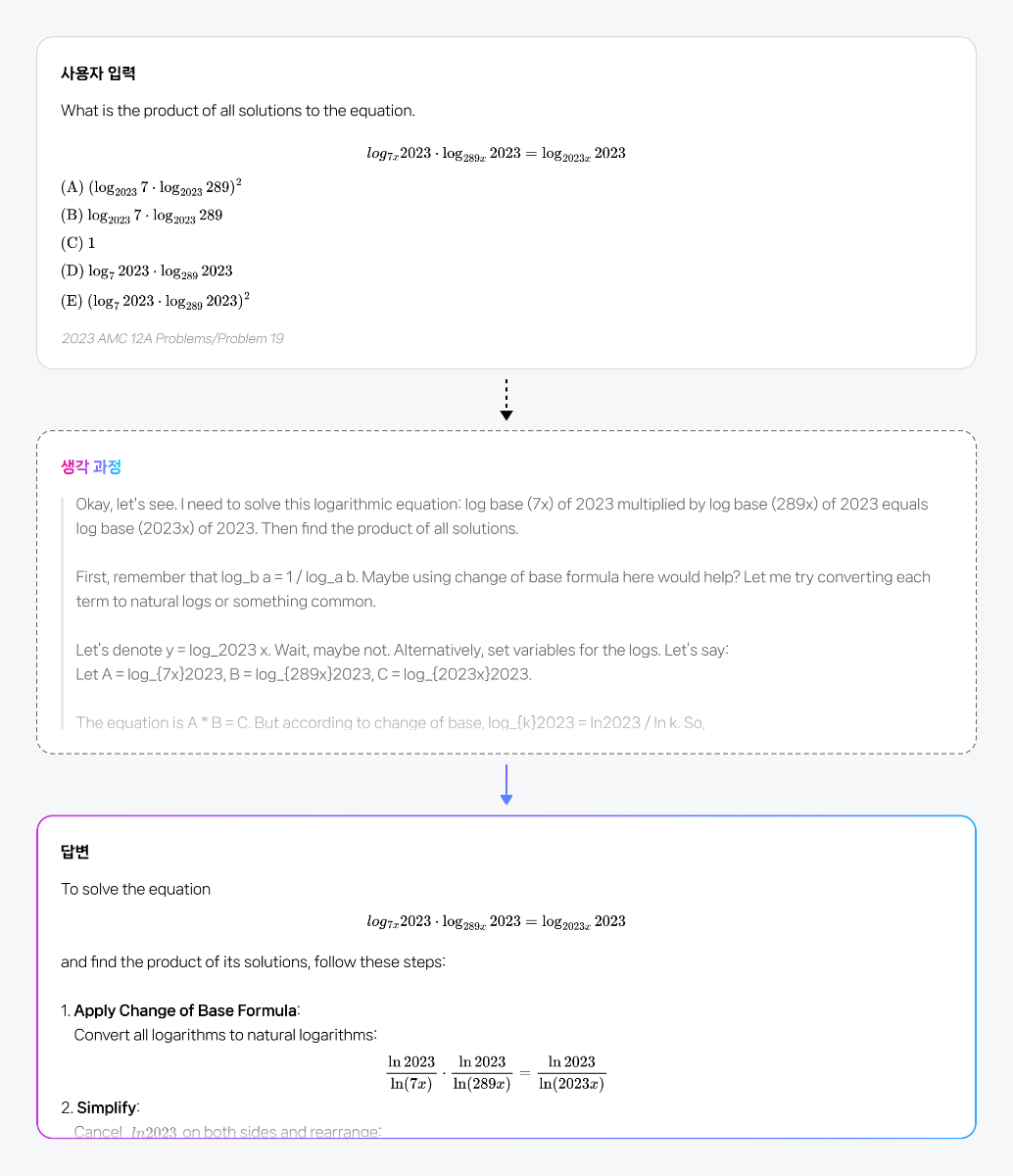
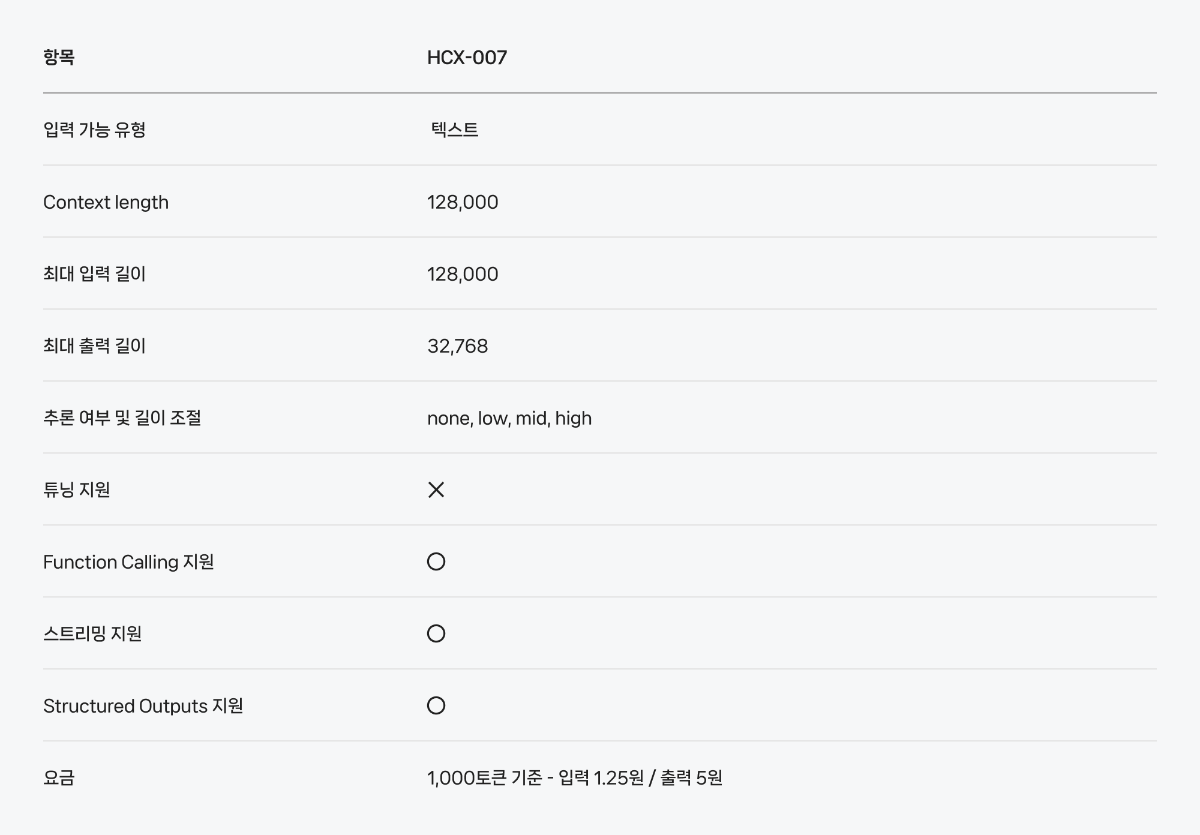
이제는 ‘생각하는 AI’가 필요합니다 비즈니스는 이제 단순히 언어를 처리하는 AI를 넘어서, 복잡한 상황(Context)을 이해하고, 논리적으로 사고하며, 실행 가능한 해법을 도출할 수 있는 AI를 필요로 합니다. 데이터를 읽고 인사이트를 도출하며, 다양한 조건을 고려해 스스로 판단하고, 나아가 실질적인 행동으로 연결할 수 있어야 합니다. 이런 변화 속에서 AI의 ‘추론(Reasoning)’ 능력은 더 이상 선택이 아닌, 필수 역량이 되었습니다. HCX-007, ‘생각의 깊이’로 문제를 푸는 AI 이러한 흐름에 맞춰, 네이버 클라우드는 추론에 특화된 HyperCLOVA X THINK 모델(보도 자료)을 바탕으로, 문제 해결에 최적화된 모델 HCX-007을 새롭게 선보입니다. 이 모델은 문제 해결 과정 전반에 걸쳐 깊이 있는 사고를 전개할 수 있도록 설계되었습니다. HCX-007은 클로바 스튜디오에서 누구나 사용할 수 있으며, 사용자는 '비추론 모드'와 '추론 모드'를 자유롭게 선택할 수 있습니다. 특히, Thinking Effort 기능을 통해 사고의 깊이를 단계적으로 조절할 수 있다는 점이 특징입니다. Low : 빠르고 간단한 추론 Mid : 표준적인 다단계 추론 High : 복잡한 문제에 대한 깊은 분석 이러한 조절 방식은 사람이 상황에 따라 직관적으로 판단하거나, 깊이 있게 고민하듯, AI의 사고 전개 역시 유연하게 구성할 수 있도록 도와줍니다. 검증된 Reasoning 성능 HCX-007은 수학, 과학, 언어 추론 등 다양한 고난도 벤치마크에서 세계 최고 수준의 모델들과 대등한 성능을 입증했습니다. HCX-007은 특히 한국어 환경에 최적화된 추론 능력에서 강점을 보입니다. 단순한 정보 응답을 넘어서, 논리적 사고를 요구하는 질문에도 정확하고 설득력 있는 답변을 제공합니다. 한국어 기반의 지식 응답과 논리 추론에서 높은 성능을 기록했으며, 문화적 맥락이나 언어적 뉘앙스를 이해하는 데 있어서도 경쟁 모델 대비 뛰어난 일관성을 보여주었습니다. 복잡한 조건이 포함된 질문이나, 여러 단계를 거쳐야 하는 요청에도 흔들림 없이 응답을 이어가는 점은 실제 활용 환경에서 특히 중요한 강점입니다. 자세한 성능 지표와 비교는 HyperCLOVA X THINK 테크니컬 리포트에서 확인할 수 있습니다. HCX-007의 문제 해결 예시 HCX-007이 다양한 문제를 어떻게 접근하고 해결하는지, 구체적인 예시를 통해 살펴볼 수 있습니다. ① 수학 문제 ② 과학 문제 ③ 논리 독해형 문제 HCX-007 스펙 한눈에 보기 HCX-007은 복잡한 문제 해결에 특화된 추론 모델입니다. 사고의 깊이를 조절할 수 있는 Thinking Effort(none, low, mid, high) 설정과 함께, Function Calling, Structured Output 등 AI 개발에 필요한 기능도 지원됩니다. 요금은 1,000토큰 기준으로 입력 1.25원, 출력 5원이 적용됩니다. HCX-007, “실제로 해결하는 AI”로 HCX-007은 단순히 문장을 만들어내는 AI가 아니라, 문제의 본질을 이해하고, 깊이 있게 사고하며, 실질적인 결과로 연결해주는 AI입니다. 이제 AI는 단순한 조력자를 넘어, 사고와 판단의 과정을 함께하는 비즈니스 파트너로 진화해야 합니다. HCX-007은 그 전환의 시작점에서, 여러 산업 분야에서 신뢰할 수 있는 첫 번째 AI 에이전트가 될 것입니다.