
CLOVA Studio 운영자
-
게시글
276 -
첫 방문
-
최근 방문
-
Days Won
51
Content Type
Profiles
Forums
Events
Articles
Posts posted by CLOVA Studio 운영자
-
-
서비스 api키 문의
in 이용 문의
안녕하세요, @insighter님,
CLOVA Studio의 Chat Completions API는 Stateless (무상태) 특성을 갖고 있으며, 따라서 테스트 앱 등록 시 입력된 프롬프트는 따로 저장되거나 특정 테스트/서비스 앱에 자동으로 입력되지 않습니다 (시스템 프롬프트 포함).
특정 프롬프트를 기준으로 테스트/서비스 앱을 발급하는 이유는 서비스 앱 신청 시 이용 목적 등의 서비스 관련 정보를 확인하기 위함이며, 매 요청을 보낼 때 data > messages에 작성한 프롬프트만을 대상으로 처리됩니다.
따라서 다른 모델을 이용하지 않는 경우 신규 API 키를 발급받을 필요는 없습니다.
참고로 HCX-003 모델은 출시 이후 별도의 변경 사항이 없습니다. 언어 모델은 특성상 외부 데이터를 알 수 없기 때문에, 관련 질의에 대해 할루시네이션이 발생할 수 있습니다.이를 보완하려면 Function calling 등을 활용해 외부 API를 호출하는 방법을 검토해 보시기 바랍니다.
감사합니다.
-

1. 임베딩이란 무엇인가요?
임베딩은 자연어 처리(NLP)와 기계학습의 핵심 개념으로, 텍스트 데이터를 인공지능이 이해할 수 있는 숫자 벡터로 변환합니다. 의미적으로 유사한 "멍멍이"와 "강아지" 같은 단어들은 벡터 공간에서도 가까운 위치에 배치됩니다.
임베딩의 가장 큰 특징은 단어나 문장의 의미적 관계를 수학적으로 표현할 수 있다는 점입니다. "왕 - 남자 + 여자 = 여왕"과 같은 벡터 연산이 가능하여 자연어의 의미 관계를 수치적으로 포착합니다. 단순한 단어 수준을 넘어 문장과 문단 전체의 의미까지 포착할 수 있는 임베딩은 검색 시스템, 추천 시스템, 감정 분석 등 다양한 자연어 처리 작업에서 핵심적인 역할을 합니다. 특히 최근 transformer 기반 사전학습 모델의 등장으로 더욱 정교한 임베딩이 가능해졌으며, 이는 기계 번역과 질의응답 시스템 같은 고도화된 AI 서비스의 성능 향상에 크게 기여하고 있습니다.
CLOVA Studio의 임베딩 API(v2 포함)를 통해 텍스트 데이터를 1,024차원의 벡터로 변환할 수 있습니다. 이제 화장품 리뷰 데이터를 예시로 활용하여, CLOVA Studio 임베딩v2 API로 텍스트의 의미를 벡터 공간에 표현하고 분석하는 과정을 진행해보겠습니다.
분석 데이터 : review-cosmetic_raw.csv (데이터 출처 : AI Hub 속성기반 감정분석 데이터)
2. 임베딩 시각화를 통한 데이터 분포 확인
리뷰 텍스트 데이터 시각화는 다음 네 단계로 진행됩니다.
- 화장품 리뷰 텍스트 데이터를 수집하고 전처리합니다. 리뷰의 감정은 긍정(Positive), 중립(Neutral), 부정(Negative)으로 분류되어 있습니다.
- CLOVA Studio의 임베딩v2 API를 활용하여 각 리뷰 텍스트의 1,024차원 임베딩 벡터를 생성합니다.
- 고차원의 임베딩 벡터를 t-SNE 알고리즘을 통해 2차원으로 차원 축소합니다.
- 감정 분류에 따라 색상을 다르게 적용하여 시각화함으로써, 감정별 군집화 패턴을 확인할 수 있습니다.
이러한 과정을 통해 화장품에 대한 고객들의 감정적 반응이 벡터 공간에서 어떻게 분포하는지 파악할 수 있습니다.
① 필요한 모듈 import
import timefrom tqdm import tqdmimport pandas as pdfrom sklearn.manifold import TSNEimport numpy as npimport matplotlib.pyplot as pltfrom matplotlib import rcParamsfrom sklearn.utils import resample② 데이터 불러오기
df = pd.read_csv('review-cosmetic_raw.csv', encoding = 'utf-8-sig') # 같은 디렉토리 상의 데이터 불러오기df.info() # 데이터 정보 확인print(df.head()) # 데이터 상단 부분 출력<class 'pandas.core.frame.DataFrame'> RangeIndex: 14835 entries, 0 to 14834 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Index 14835 non-null int64 1 Aspects 14835 non-null object 2 Domain 14835 non-null object 3 GeneralPolarity 14835 non-null int64 4 Text 14835 non-null object dtypes: int64(2), object(3) memory usage: 579.6+ KB
Index Aspects Domain \ 0 1 [{'Aspect': '기능/효과', 'SentimentText': ' 거품이 풍부... 화장품 1 2 [{'Aspect': '기능/효과', 'SentimentText': '여드름 피부에... 화장품 2 3 [{'Aspect': '보습력/수분감', 'SentimentText': '유분기도 ... 화장품 3 4 [{'Aspect': '기능/효과', 'SentimentText': '이 제품 쓴다... 화장품 4 5 [{'Aspect': '향', 'SentimentText': '박하향이 처음에는 자... 화장품 GeneralPolarity Text 0 1 거품이 풍부해서 사용하기 편하고, 사용하기 편하고, 세정력도 좋습니다. 피부에 ... 1 0 여드름 피부에 잘 맞는 듯합니다. 좁쌀 여드름이 많이 좋아졌어요. 용량이 작고 사... 2 1 유분기도 여드름도 많이 좋아졌어요. 여드름도 많이 좋아졌어요. 세일할 때 구매하니 ... 3 1 이 제품 쓴다고 여드름이 안 생기는 건 아니지만 자극적이지 않아서 촉촉하지도 않지만... 4 1 박하향이 처음에는 자극적이라 생각했는데 풍부한 거품으로 부드럽게 잘 세정되는것 같아...
Quote데이터 구조확인
데이터셋은 화장품 리뷰 데이터로, 총 14,835개의 행과 5개의 열로 구성되어 있습니다. 데이터셋의 열에 대한 설명은 다음과 같습니다.- Index : number of data , 정수형 데이터로 1 ~ 14835까지 데이터포인트 ID를 부여한 값입니다.
- Aspects : 리뷰 속성어(감정 분류 대상 텍스트별 점수 부여 내역), 텍스트 데이터를 쪼개서 감정 분석 점수를 부여한 정보 입니다. 본 데이터의 텍스트 부분만 합쳐서 사용했습니다.
- Domain : 리뷰 상품 , 화장품 리뷰 데이터이므로 "화장품"
- GeneralPolarity : 상품평 전체 감정 분류 정수형 데이터 (부정 -1, 중립 0, 긍정 1)
- Text : 리뷰 텍스트 데이터 (본 분석에서 임베딩을 구하는 타겟 데이터)
본 데이터는 화장품에 대한 텍스트 리뷰 데이터로 이미 감정분류(부정, 중립, 긍정), 리뷰 텍스트 데이터에 대한 분류가 완료된 데이터입니다.
③ 임베딩 구하기
본 분석에서는 빠르게 임베딩 값을 구하고 시각화하기 위해 240개의 데이터 포인트 (부정 -1, 중립 0, 긍정 1 : 각 80개씩)를 샘플링하여 사용합니다.
def process_batch(batch, executor, max_retries, retry_delay_seconds):
results = []
for text in tqdm(batch, desc="Processing Requests"😞
retries = 0
while retries <= max_retries:
try:
response = executor.execute({"text": text})
if isinstance(response, list😞
results.append(response)
break
raise ValueError(f"Unexpected response format: {response}")
except Exception as e:
retries += 1
if retries > max_retries:
print(f"Skipping text: {text} due to repeated errors.")
results.append(None)
else:
time.sleep(retry_delay_seconds)
return resultsdef main():
executor = CompletionExecutor(
host='clovastudio.apigw.ntruss.com',
api_key='****', # 올바른 값으로 변경해줘야합니다
api_key_primary_val='***', # 올바른 값으로 변경해줘야합니다
request_id='****' # 올바른 값으로 변경해줘야합니다.
)# 데이터 포인트 240개 샘플링
data = pd.concat([
resample(df[df['GeneralPolarity'] == 1], n_samples=80, random_state=0),
resample(df[df['GeneralPolarity'] == 0], n_samples=80, random_state=0),
resample(df[df['GeneralPolarity'] == -1], n_samples=80, random_state=0)
]).reset_index(drop=True)batches = [data['Text'][i:i + 60] for i in range(0, len(data), 60)]
embeddings = []for i, batch in enumerate(batches, start=1😞
print(f"Processing batch {i}/{len(batches)}")
embeddings.extend(process_batch(batch, executor, max_retries=5, retry_delay_seconds=10))
if i < len(batches):
time.sleep(30) # 429에러 발생 방지를 위한 딜레이, 필요시 조정data['Embedding'] = embeddings
print(data)if __name__ == '__main__':
main()Processing batch 1/4 Processing Requests: 100%|██████████| 60/60 [00:08<00:00, 7.36it/s] Processing batch 2/4 Processing Requests: 100%|██████████| 60/60 [00:39<00:00, 1.52it/s] Processing batch 3/4 Processing Requests: 100%|██████████| 60/60 [00:44<00:00, 1.35it/s] Processing batch 4/4 Processing Requests: 100%|██████████| 60/60 [00:30<00:00, 1.95it/s] Index Aspects \ 0 3905 [{'Aspect': '자극성', 'SentimentText': '순하고 ', 'S... 1 13891 [{'Aspect': '기능/효과', 'SentimentText': '잡티, 멜라닌... 2 4789 [{'Aspect': '기능/효과', 'SentimentText': '세정력이 뛰어... 3 7049 [{'Aspect': '보습력/수분감', 'SentimentText': '얼굴에 너... 4 13036 [{'Aspect': '제형', 'SentimentText': '제형이 생크림 입자... .. ... ... 235 4639 [{'Aspect': '흡수력', 'SentimentText': '너무 무거운 느낌... 236 5757 [{'Aspect': '편의성/활용성', 'SentimentText': '사용하기 ... 237 9963 [{'Aspect': '기능/효과', 'SentimentText': '주름이 옅어지... 238 5514 [{'Aspect': '피부타입', 'SentimentText': '이 제품은 건성... 239 7696 [{'Aspect': '보습력/수분감', 'SentimentText': '촉촉함이 ... GeneralPolarity Text \ 0 1 순하고 저렴하고 양이 많아요. 촉촉함도 오래가고, 오래가고, 끈적이지 않아요. ... 1 1 잡티, 멜라닌 색소 억제 및 잡티 제거와 커버에도 도움이 되는 것 같아요. 잡티 ... 2 1 세정력이 뛰어난 것 같습니다. 세안하고 나면 뽀득거리면서도 자극적이지 않고 깨끗한 ... 3 1 얼굴에 너무 촉촉하고 ~~ 와~얼굴에 윤기가 광이 나요~~굿 4 1 제형이 생크림 입자 느낌으로 쫀쫀하게 피부에 문지르면 깨끗하게 잘 지워져요. .. ... ... 235 -1 너무 무거운 느낌이라 자주 손이 안가네요. 피부에 팩한 것 처럼 한꺼풀 덮여 있는 ... 236 -1 사용하기 불편합니다. 리프팅 효과도 없는 것 같고 피부에 트러블이 생깁니다. 237 -1 주름이 옅어지는 느낌 안 드네요. 피부는 약간 간질거리고, 붉은 트러블도 생겼어... 238 -1 이 제품은 건성인 분들에게는 뻑뻑하게 발리고 건조한 것 같습니다. 뻑뻑하게 발리고... 239 -1 촉촉함이 덜하고 끈적임이 있어 건조할때 OOO 바르고 건조함이 완화가 되기를 기대했... Embedding 0 [-1.0322266, 1.0615234, -1.0039062, 0.02919006... 1 [-0.70654297, 0.68603516, -1.1757812, -0.28100... 2 [-0.7182617, 1.0566406, -1.0390625, -0.2807617... 3 [0.38183594, 1.3720703, -1.1142578, -0.8857422... 4 [-0.5258789, 0.52441406, -1.1601562, -1.410156... .. ... 235 [0.22509766, 1.0605469, -1.3222656, -0.7373047... 236 [-0.87353516, 1.6015625, -1.5839844, -0.878417... 237 [-1.1142578, 0.8383789, -1.4892578, -0.6748047... 238 [-0.049591064, 1.4492188, -0.671875, -1.814453... 239 [-0.41479492, 1.0751953, -1.3623047, -0.305419... [240 rows x 5 columns]
# 임베딩값을 포함한 데이터프레임 저장 data.to_csv('review-cosmetic_emb.csv', index=False, encoding='utf-8-sig')
리뷰데이터에 대해 임베딩 값을 추가하여 저장한 결과 파일은 다음과 같습니다. review-cosmetic_emb.csv
matplot, t-SNE 차원 축소를 통해 임베딩 시각화하기
t-SNE(t-Distributed Stochastic Neighbor Embedding)는 고차원 데이터를 저차원으로 변환하여 시각화하는 데 매우 효과적인 비선형 차원 축소 기법입니다. 1024차원의 데이터 포인트의 임베딩값 간의 유사도 관계를 최대한 보존하여 2차원 공간으로 차원 축소하면 데이터 포인트들을 시각화할 수 있습니다. 비슷한 의미를 가진 데이터 포인트들은 2차원 평면상에서 서로 가깝게 위치하게 되어, 임베딩 공간의 구조를 직관적으로 이해할 수 있게 됩니다.
본 분석에서는 빠르게 임베딩 값을 구하고 시각화하기 위해 240개의 데이터 포인트 (부정 -1, 중립 0, 긍정 1 : 각 80개씩)를 샘플링하여 사용합니다.
rcParams['font.family'] = 'AppleGothic'
plt.rcParams['axes.unicode_minus'] = Falseembeddings = np.array(data['Embedding'].tolist())
tsne = TSNE(n_components=2, random_state=0, perplexity=30)
# 2차원으로 시각화, perplexity는 데이터의 고차원 공간에서 가까운 이웃을 선택하는 방법과 관련이 있으며, 이 값이 크면 더 넓은 범위의 이웃을 고려한다는 의미이고, 작으면 더 국소적인 관계를 이웃으로 고려한다는 의미입니다
# 데이터포인트의 개수가 많을수록 큰 값을 사용하는 것이 일반적이며, 보통 5~50 사이의 값을 선택합니다.
tsne_results = tsne.fit_transform(embeddings)data['t-SNE Dimension 1'] = tsne_results[:, 0]
data['t-SNE Dimension 2'] = tsne_results[:, 1]
polarity_to_color = {1: 'green', 0: 'blue', -1: 'red'} # 1: 긍정, 0: 중립, -1: 부정
colors = data['GeneralPolarity'].map(polarity_to_color)
plt.figure(figsize=(10, 10))
plt.scatter(
data['t-SNE Dimension 1'],
data['t-SNE Dimension 2'],
c=colors,
alpha=0.5
)
plt.title('t-SNE 시각화: 임베딩 감성 분석')
plt.xlabel('t-SNE 차원 1')
plt.ylabel('t-SNE 차원 2')
plt.legend(handles=[
plt.Line2D([0], [0], marker='o', color='w', markerfacecolor='green', markersize=10, label='긍정 (1)'),
plt.Line2D([0], [0], marker='o', color='w', markerfacecolor='blue', markersize=10, label='중립 (0)'),
plt.Line2D([0], [0], marker='o', color='w', markerfacecolor='red', markersize=10, label='부정 (-1)')
])
plt.show()
감정 별(긍정, 중립, 부정)로 t-SNE 시각화한 결과입니다. 긍정(1, 초록색)은 주로 하단부에 군집화되었고 부정(-1, 빨간색)은 상단부에 주로 분포한 것으로 확인할 수 있습니다. 또한 중립(0, 파란색)은 중앙에 넓게 분포하여 다른 감정들과 일부 겹치는 영역이 있습니다. 리뷰 텍스트가 감정 별로 구분이 되는 군집으로 형성되어 있고 CLOVA Studio의 임베딩 모델이 감정의 의미적 차이를 잘 포착했다는 것을 확인할 수 있습니다. 일부 영역에서 감정 간 겹칩이 발생하는 것은 리뷰 텍스트의 미묘한 감정표현이나 복잡한 표현이 포함된 경우로 해석할 수 있습니다.
plotly, t-SNE 차원 축소를 통해 임베딩 시각화하기: 데이터포인트 내용 확인하기
import plotly.express as px
import pandas as pddata['Text'] = data['Text']
df_tsne = pd.DataFrame({
't-SNE Dimension 1': data['t-SNE Dimension 1'],
't-SNE Dimension 2': data['t-SNE Dimension 2'],
'GeneralPolarity': data['GeneralPolarity'],
'Text': data['Text']
})df_tsne['GeneralPolarity'] = df_tsne['GeneralPolarity'].astype(str)
fig = px.scatter(
df_tsne,
x='t-SNE Dimension 1',
y='t-SNE Dimension 2',
color='GeneralPolarity',
hover_data=['Text'],
color_discrete_map={
"-1": "red", # 부정
"0": "blue", # 중립
"1": "green" # 긍정
},
title='t-SNE 시각화: 감성 분석',
width=1200, # 그래프 가로 길이, 필요시 조정
height=800 # 그래프 세로 길이, 필요시 조정
)fig.update_layout(
font=dict(
family="AppleGothic",
size=16
),
title=dict(
font=dict(size=16)
),
xaxis_title="t-SNE 차원 1",
yaxis_title="t-SNE 차원 2"
)fig.show()
plot에 표시된 데이터 포인트의 내용을 인터랙티브하게 바로 확인할 수 있도록 'plotly'를 이용하여 시각화하였습니다. 이를 통해 개별 데이터 포인트에 대한 자세한 정보 확인이 가능하여 실제 리뷰 텍스트의 내용이 어떤지 확인할 수 있습니다. 왼쪽 영역에 위치한 초록색 데이터 포인트를 확인해보니 "제품이 셋 세트라 완전 풍성합니다. 제형이 쫀쫀하게 성분이 콜라겐으로 더 행복한 시간 될 것 같아요"라는 내용의 긍정적인 리뷰 내용을 확인할 수 있습니다. 반면, 오른쪽 영역에 위치한 빨간색 데이터포인트를 확인해보면 "눈시림이 너무 심해서 얼굴에 바를 수가 없네요 자극이 너무 심하네요"라는 내용의 부정적인 리뷰 내용을 확인할 수 있습니다.
3. 임베딩 값을 활용한 분류기 구축과 성능평가
지금까지 우리는 이미 감정 분류가 되어있는, 즉 분류 레이블이 있는 데이터의 임베딩을 구하고 시각화를 해보았습니다. 하지만 실제 대부분의 데이터는 레이블이 없는 데이터를 다루게 되는데요, 이런 상황에서 텍스트 임베딩은 분석에 유용한 도구로 활용될 수 있습니다. 임베딩은 텍스트의 의미적 유사성을 수치화하여 표현된 값이기 때문에, 이를 기반으로 비슷한 의미를 가진 데이터들을 그룹화할 수 있습니다. 유사한 텍스트는 다차원의 임베딩 공간에서 가까운 거리에 위치하게 되기 때문입니다. 이러한 임베딩의 특성을 활용하여, K-means 클러스터링을 통해 비슷한 의미를 가진 텍스트 데이터들을 레이블 없이도 분류가 가능합니다. K-means 클러스터링은 다음과 같은 상황에서 특히 유용합니다.
- 텍스트로 이루어진 대량의 문서(ex. 고객 cs/리뷰 데이터)를 주제 별로 분류할 때
- 텍스트 데이터의 의미있는 패턴을 찾고 싶을 때
화장품 리뷰 데이터는 이미 분류 레이블(감정), 즉 분류에 대한 정답을 가지고 있지만 클러스터링 분석의 결과를 실제와 비교해보면서 임베딩 기반 클러스터링의 활용은 어떻게 할 수 있는지 알아보겠습니다.
임베딩 값을 활용한 분류기 구축/성능 평가 과정은 다음과 같습니다.
- K-means 클러스터링
- 클러스터링 성능평가하기
① 필요한 모듈 import
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.feature_extraction.text import TfidfVectorizer
import matplotlib.pyplot as plt
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
from scipy.stats import entropy
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from xgboost import XGBClassifier
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
from sklearn.model_selection import GridSearchCVK-Means 클러스터링이란?
텍스트 데이터의 t-SNE 차원 축소 결과를 활용하여 K-Means 클러스터링을 수행하고, 클러스터별 카테고리(ex. 감정) 분포와 주요 키워드를 분석하겠습니다. 이를 통해 데이터의 특성별로 데이터를 나눠서 군집화하고 군집화된 데이터들의 내용으로 데이터의 특징을 파악할 수 있습니다. 코드 설명에 앞서, K-Means 클러스터링 알고리즘에 대해 알아봅시다. K-means는 데이터의 특징을 기반으로 하여 k개의 그룹으로 나누는 비지도 학습 알고리즘입니다. K-means 클러스터링 알고리즘을 도식화 하면 다음과 같습니다.
각 클러스터는 하나의 중심점을 가져야 합니다.
1. 초반에는 데이터 포인트 중 무작위로 k개의 중심점이 정해집니다. 이 초기 중심점들이 각 클러스터의 시작점이 됩니다.
2. 각 데이터 포인트들은 초반에 정해진 시작점을 기준으로 가장 가까운 클러스터에 할당됩니다.
3. 정해진 각 클러스터 내 평균을 계산하여 평균값이 새로운 중심값으로 설정됩니다.
4. 더이상 평균값에 변경이 없이 수렴할 때가지 클러스터를 재할당하는 과정을 거칩니다.② K-Means 클러스터링 실행하기
앞서 t-SNE로 차원 축소한 데이터를 기준으로 3개의 클러스터를 생성합니다. 각 클러스터에서 부정(-1), 중립(0), 긍정(1) 감정이 얼마나 분포하는 확인해보고, 클러스터 별로 데이터의 특징이 어떻게 나타나는지 확인해보겠습니다.
클러스터링 실행
#1. t-SNE 결과 기반으로 클러스터링
kmeans = KMeans(n_clusters=3, random_state=42)
data['Cluster'] = kmeans.fit_predict(data[['t-SNE Dimension 1', 't-SNE Dimension 2']])# 2. 클러스터별 감성 비율 분석
sentiment_distribution = data.groupby('Cluster')['GeneralPolarity'].value_counts(normalize=True).unstack().fillna(0)print("클러스터별 감성 분포:")
print(sentiment_distribution)# 3. 주요 키워드 분석
vectorizer = TfidfVectorizer(max_features=15) # 상위 15개 확인, 필요시 변경 가능
cluster_keywords = {}for cluster_id in data['Cluster'].unique():
cluster_texts = data[data['Cluster'] == cluster_id]['Text']
tfidf_matrix = vectorizer.fit_transform(cluster_texts)
keywords = vectorizer.get_feature_names_out()
cluster_keywords[cluster_id] = keywordsprint("클러스터별 주요 키워드:")
for cluster_id, keywords in cluster_keywords.items():
print(f"Cluster {cluster_id}: {keywords}")Quote다음은 KMeans()의 파라미터에 대한 설명입니다.
- n_clusters :군집화할 클러스터의 개수를 지정합니다. default = 8
- random_state : 재현성을 위해 초기 중심점을 무작위로 선택할 때 사용되는 난수 생성을 위한 시드값을 설정합니다.
③ 결과 확인하기
클러스터별 감성 분포: GeneralPolarity -1 0 1 Cluster 0 0.076923 0.646154 0.276923 1 0.707547 0.283019 0.009434 2 0.000000 0.115942 0.884058 클러스터별 주요 키워드: Cluster 2: ['꾸준히' '너무' '만족합니다' '많이' '바르고' '얼굴에' '오래지속되어' '정말''좋네요' '좋습니다' '좋아요' '촉촉하고' '피부가' '피부에' '효과가'] Cluster 0: ['같습니다' '같아요' '느낌이' '들어요' '발림성' '발림성이' '않고' '오래' '좋고' '좋네요' '좋습니다' '좋아요' '향은' '향이' '효과는'] Cluster 1: ['가격대비' '가격도' '같아요' '구성이' '너무' '아쉽네요' '아직' '않네요' '않아요' '용량이' '촉촉하지' '피부가' '효과' '효과가' '효과는']
클러스터 별 감성 분포 결과를 확인해보니, 각 Cluster 0,1,2마다 부정(-1), 중립(0), 긍정(1) 리뷰 내용이 모여있는 것을 확인할 수 있습니다.
Cluster부정(-1)중립(0)긍정(1)0 7.7% 64.6% 27.7% 1
70.8% 28.3% 0.9% 2 0.0% 11.6% 88.4% Cluster 0는 중립, Cluster 1은 부정, Cluster 2는 긍정적인 리뷰가 다수로 차지하고 있습니다. 각 클러스터의 감정 비율을 통해, 화장품에 대한 리뷰가 부정, 중립, 긍정적으로 잘 나뉘는지를 알 수 있습니다.
클러스터 별 주요 키워드를 확인해보면, 긍정적인 리뷰가 많이 포함된 Cluster 2에서는 "좋아요", "촉촉하고"와 같은 단어가 많이 포함되었습니다. 반면, 부정적인 리뷰가 많이 포함된 Cluster 1에서는 "가격대비", "아쉽네요"와 같은 단어의 빈도가 많습니다.
이러한 결과를 확인해서 긍정적인 클러스터에 자주 언급되는 장점은 이를 강조한 마케팅과 같은 비즈니스 인사이트로 활용하거나 부정적인 클러스터에서 나타난 문제점은 개선점으로 인사이트를 얻을 수 있습니다.④ 클러스터링 품질 평가하기
클러스터의 품질과 데이터 분포를 다양한 지표를 통해 평가하는 방법에 대해 설명하겠습니다. 먼저 데이터의 클러스터링이 잘 되었는지를 알 수 있는 양적 평가 지표에 대해 알아봅시다.
Quote지표 설명
-
Silhouette 점수 (-1~1)
각 데이터 포인트가 속한 클러스터와 다른 클러스터 간의 거리를 비교하는 지표, 값이 1에 가까울수록 클러스터링 간의 경계가 명확한 것을 의미합니다. -
Calinski-Harabasz 점수
클러스터 내 응집도와 클러스터 간 분산을 비교하는 지표, 값이 클수록 클러스터 간 거리가 크고, 클러스터 내 데이터가 밀집되어 있음을 의미합니다. -
Davies-Bouldin 점수
클러스터 간 거리와 클러스터 내부 분산의 비율을 평가하는 지표, 값이 낮을수록 좋은 클러스터링을 의미합니다.
정리하면 Silhouette 점수는 1에 가깝고, Calinski-Harabasz 점수는 높을수록 좋으며 Davies-Bouldin 점수는 낮을수록 좋은 클러스터를 의미합니다. Calinski-Harabasz 점수와 Davies-Bouldin 점수는 제한 범위가 없기 때문에 상대적 클러스터링 비교에 사용하기 적절합니다.
# 지표 함수 정의
def evaluate_clustering(data):
# 1. Silhouette
silhouette_avg = silhouette_score(data[['t-SNE Dimension 1', 't-SNE Dimension 2']], data['Cluster'])
print(f"Silhouette Score: {silhouette_avg}")
# 2. Calinski-Harabasz
ch_score = calinski_harabasz_score(data[['t-SNE Dimension 1', 't-SNE Dimension 2']], data['Cluster'])
print(f"Calinski-Harabasz Score: {ch_score}")
# 3. Davies-Bouldin
db_score = davies_bouldin_score(data[['t-SNE Dimension 1', 't-SNE Dimension 2']], data['Cluster'])
print(f"Davies-Bouldin Score: {db_score}")# 평가 실행
print("### Clustering Quality Evaluation ###")
evaluate_clustering(data)### Clustering Quality Evaluation ### Silhouette Score: 0.3865170180797577 Calinski-Harabasz Score: 262.519196880911 Davies-Bouldin Score: 0.9567987699215011
Silhouette 점수는 0.38로 클러스터링 품질이 양호한 수준입니다. 클러스터 내 데이터 포인트가 서로 밀접하게 모여있으면서 다른 클러스터와 적당히 분리된 상태를 의미하며, 점수가 0.5 이상일 경우 클러스터링 품질이 높다고 평가할 수 있습니다. Calinski-Harabasz 점수와 Davies-Bouldin 점수는 상대적 클러스터링 비교에 사용하기 적절하기 때문에 K값을 적절하게 바꿔가면서 비교하며 더 좋은 클러스터링을 찾는데 적절합니다.
3. 맺음말
1024차원의 임베딩 벡터를 2차원으로 시각화하면 리뷰 텍스트 간의 의미적 관계를 시각적으로 이해할 수 있습니다. 이를 통해 데이터 포인트들이 임베딩 벡터 공간에서 어떻게 분포하는지 파악할 수 있으며, 특정 라벨(긍정, 중립, 부정 등)로 분류된 데이터들이 서로 가깝게 위치하는 경향을 확인할 수 있습니다. 이 과정은 데이터의 라벨링 품질과 임베딩 모델의 성능을 확인하는 데 유용합니다.
예를 들어, 데이터 군집 간의 경계가 명확하지 않다면 임베딩 모델이 텍스트 간의 차이를 충분히 학습하지 못했거나, 라벨링된 데이터에 오류가 있을 가능성을 의미합니다. 이를 통해 오분류된 데이터 포인트를 탐지할 수 있으며, 잘못된 라벨링을 수정하거나 모델 성능을 개선하는 데 활용할 수 있습니다.
또한, K-Means 클러스터링과 XGBoost 모델을 활용하여 데이터를 정량적으로 분석했습니다.
K-Means는 임베딩 벡터를 군집화하여 데이터 포인트 간의 유사성을 기준으로 각 클러스터의 특성을 파악하는 데 사용할 수 있습니다. 이 분석 방법은 감정 분석뿐만 아니라 다양한 도메인에서 분류 태스크를 정의하거나 데이터의 라벨링 품질을 확인하는 작업에도 활용될 수 있습니다. 예를 들어, 의료 데이터에서 질병 분류를 하거나 고객 리뷰 데이터를 기반으로 제품 추천을 할 때에도 데이터의 의미적 관계를 확인하고 모델 성능을 개선하는 데 기여할 수 있습니다. 따라서 도메인에 따라 임베딩 모델과 시각화 및 분류 방법을 적절히 조정하여 유용하게 활용할 수 있습니다.
지금까지 우리는 임베딩을 활용한 시각화와, 레이블이 없는 데이터를 가정하고 어떻게 분석하고 군집화할 수 있는지 K-means 클러스터링을 통해 알아봤습니다. 그러나, K-means 클러스터링말고도 더 정교한 분류가 필요할 수 있습니다.
Quote- 기존 레이블된 데이터를 학습하여 새로운 데이터를 더 정확하게 분류하고 싶을 때
- 클러스터링보다 더 세밀한 분류 경계가 필요할 때
- 분류 결과에 대한 확률값이나 신뢰도 점수가 필요할 때
이러한 요구사항을 충족하기 위해, 우리는 XGBoost와 같은 고급 머신러닝 알고리즘을 활용할 수 있습니다. 관련 내용은 "임베딩을 활용한 고급 분류 기법: XGBoost" 문서에서 자세히 다루도록 하겠습니다.
-
안녕하세요, @박태호님,
비전 모델을 활용하면 제품의 형태를 파악할 수는 있지만,
LLM 특성상 최신 정보나 특정 제품에 대한 전문성은 보장되지 않기 때문에, 단독 구성보다는 이미지 임베딩 등과 결합한 방식으로 구현을 고려하시는 것이 좋습니다.모델 요금은 아래 링크에서 확인하실 수 있습니다. 비전 모델을 사용하시는 경우에는 HCX-005 모델을 참고해 주세요.
클로바 스튜디오 이용을 참고하실 수 있는 가이드 링크를 함께 전달드립니다.
- 사용 가이드 : https://guide.ncloud-docs.com/docs/clovastudio-overview
- API 가이드 : https://api.ncloud-docs.com/docs/ai-naver-clovastudio-summary
감사합니다.
-
-
안녕하세요, 네이버 클라우드 플랫폼입니다.
AI 기반의 특화된 서비스를 손쉽게 만들 수 있는 개발 도구, CLOVA Studio의 새로운 모델을 소개합니다.
이미지를 이해하는 HCX-005 비전 모델을 제공합니다 ✨
HCX-005 비전 모델의 도입으로 서비스 활용 가능성이 크게 확장되었습니다. 텍스트, 이미지, 표 등 다양한 형태의 데이터를 처리하고 이해할 수 있게 되어, 서비스 영역을 크게 확장하고 더욱 지능적이고 유용한 서비스 제공이 가능해졌습니다.
더욱 강력하고 효율적인 HCX-DASH-002 모델을 만나보세요 ⚡️
다양한 영역에서 성능이 강화된 HCX-DASH-002 모델은, 비즈니스 로직에 최적화된 모델을 더욱 유연하게 선택할 수 있도록 지원합니다.
긴 길이의 문서도 활용 가능합니다 📚
HCX-005 모델은 128k, HCX-DASH-002 모델은 32k로 context length가 확장되어, 더 긴 문서를 활용할 수 있습니다.
-
비전 모델을 활용한 비정형 업무 자동화
“이건 사람이 해야만 했잖아요?”
지난 10년간 기업 환경에서는 RPA와 문서 자동화 도구를 통해 정형화된 업무 프로세스의 자동화가 상당한 성과를 거두었습니다. 정해진 화면을 클릭하고, 엑셀에서 데이터를 복사하고, 반복되는 문서 양식을 채우는 일은 이제 대부분 자동화됐습니다. 그러나 주목할 점은 여전히 많은 업무 환경에서 직원들이 이미지, 문서, 그래프 등을 직접 검토하고 분석하여 보고서를 작성하는 데 상당한 시간을 소비하고 있다는 것입니다. 이러한 현상은 주로 '비정형 정보'라는 장벽 때문입니다. 복잡한 문서 구조, 다양한 형태의 시각 자료, 손글씨 메모, 다국어 혼합 콘텐츠 등은 전통적인 자동화 도구로는 처리하기 어려워 여전히 인간의 개입이 필수적이었습니다. 해당 업무들은 자동화의 마지막 난제로 남아 있었습니다.
비전 모델(Vision-Language Model)은 바로 이 지점에서 중요한 돌파구가 될 것입니다. HCX-005와 같은 모델은 이미지와 텍스트를 동시에 이해하며, 인간 수준의 문서 인식, 차트 해석, UI 분석, 손글씨 판별 능력을 갖추고 있습니다. 비전 모델의 도입으로 기존에 자동화되지 못했던 영역에서도 혁신적인 변화가 가능해졌습니다. 이러한 작업들은 기존에는 "사람이 직접 해야 한다"고 여겨졌던 분야들이지만, 비전 모델의 적용으로 효율적인 자동화가 실현됩니다. 사례 검토를 통해 많은 이들이 "이 업무도 자동화가 가능하구나!"라는 새로운 관점을 발견하게 될 것입니다. 본문에서는 익숙한 일상 업무가 혁신적으로 처리되는 실제 사례들을 함께 살펴보며, 자동화의 새로운 가능성을 탐구해보겠습니다.
1. RPA의 새로운 파트너, 비전 모델
RPA(Robotic Process Automation)는 기업 업무 자동화의 강력한 기반이며, 정형화된 입력과 고정된 UI 흐름, 반복 가능한 규칙에서는 여전히 가장 효과적입니다. 하지만 실제 현업의 복잡한 업무는 RPA만으로 처리하기에는 한계가 있습니다. 예를 들어, 양식이 조금만 변경되어도 RPA 시스템이 작동하지 않거나, 스캔 문서나 이미지에서 정보를 추출하는 데 어려움을 겪으며, UI 화면이 업데이트될 때마다 수동으로 재설계해야 합니다.
이러한 문제로 인해 RPA 시스템은 안정적일지라도 예외 상황에서 효율성이 떨어집니다. 여기서 비전 모델이 중요한 역할을 할 수 있습니다. 비전 모델은 RPA가 처리하기 어려운 비정형 정보 해석, 문맥 이해, 예외 상황 대응 등을 담당하여 자동화 프로세스를 더욱 유연하고 실제 업무 환경에 적합하게 만듭니다.
▼ RPA는 정형 업무의 속도를, VLM은 비정형 데이터의 유연성을 제공하며, 두 기술의 결합으로 완전한 자동화 워크플로우가 구축됩니다.
▼ 아래는 '다양한 형식의 인보이스 자동화'의 구체적 사례입니다. 기업에서 자주 다루는 문서들의 형식이 조금씩 다르거나, 다양한 레이아웃을 가진 경우에도 비전 모델이 정확하게 정보를 추출할 수 있는지 테스트해보았습니다.
2. 복잡한 회의 메모 자동 정리
회의 후의 번거로운 과정들
회의 후 화이트보드를 가득 채운 복잡한 그림과 메모. 사진으로는 찍었지만, 막상 다시 보면 어디서부터 정리해야 할지 막막해집니다. 손글씨 메모, 복잡한 도식, 흩어진 키워드들은 일일이 사람이 해석하고 정리해야 했습니다. 회의 자료는 비정형적이고, 흐름을 파악하기 어렵습니다. 기존의 자동화 기술은 화이트보드에 적힌 글자를 단순히 텍스트로 변환할 뿐, 그 안의 맥락을 이해하지 못했습니다. 하지만 이제는 비전 모델을 통해 이러한 비정형적인 회의 이미지 자료를 단순히 ‘읽어내는 것’이 아니라, ‘이해하고 판단해 정리하는 것’까지 가능합니다.
이제 비전 모델은 회의 이미지의 시각적 요소를 분석하고 자연스러운 문서와 행동을 계획하는 전 과정을 지원합니다. 이러한 과정을 자세히 살펴보겠습니다.
화이트보드에 남은 도식과 키워드를 사람이 해석해 작성하던 회의록은 비전 모델을 통해 자동으로 구성되어, 사람의 개입 없이도 완성도 높은 회의록 확보가 가능합니다. 또는 회의 메모에서 액션 아이템을 수동으로 정리하던 과정을 자동화하여, 회의 직후 바로 협업 도구와 연동 가능한 할 일 리스트를 확보할 수 있을 것입니다.
▼ 아래는 회의 중 작성된 복잡한 화이트보드의 예시 입니다.
회의가 끝난 후, 복잡한 화이트보드와 손글씨 메모는 더 이상 정리의 부담이 아닙니다. 대신, 비전 모델이 이러한 시각 자료에서 구조, 흐름 및 맥락을 지능적으로 인식하여 핵심 정보를 체계적으로 정리합니다. 이로써 팀원들은 반복적인 정리 작업에서 벗어나 보다 중요한 논의와 의사결정에 집중할 수 있는 환경을 마련하게 됩니다.
3. 발표 대본 자동 생성하기
슬라이드 작성을 마쳤지만, 발표할 내용을 어떻게 구성해야 할지 막막해지는 순간이 있습니다. 이미지와 도표, 키워드 등을 잘 정리했음에도 불구하고, 발표를 앞두고 나면 어디서부터 시작해야 할지, 어떤 말투로 전달해야 할지에 대한 고민이 깊어지기 마련입니다. 결국 발표 전날 밤, 슬라이드를 한 장씩 넘기며 문장을 하나씩 구상하게 되죠. "이 부분은 이렇게 표현할까?", "여기는 좀 더 설득력 있게 말해야 하는데...", "이 슬라이드는 별도의 설명 없이 넘어가도 괜찮을까?" 슬라이드는 일정한 형식을 따르지만, 발표 대본 작성은 매우 비정형적인 작업입니다. 정해진 형식이나 정답이 없으며, 각 문장은 적절한 톤과 맥락을 고려하여 작성되어야 합니다. 지금까지의 기술로는 이러한 비정형적인 영역에 효과적으로 접근하기 어려웠습니다.
기존 기술은 이미지를 인식할 수 있었지만, 슬라이드가 왜 필요한지, 어떤 내용을 강조해야 하는지, 그리고 청중에게 어떤 흐름으로 설명해야 하는지까지 판단하는 데에는 한계가 있었습니다. 이런 문제를 해결하기 위해 비전 모델을 활용할 수 있습니다. 슬라이드 내용을 가지고 자동으로 발표 대본을 생성하는 기술이 되는거죠.
▼ 발표자료 화면(예: PPT)을 입력으로 받아 비전 모델이 시각적 요소를 분석하고, 언어 모델이 자연어로 대본을 완성하는 전 과정을 보여줍니다.
▼ 아래는 슬라이드(제목, 본문, 그래프 포함)를 비전 모델에 입력하여 자동 발표 대본 생성 성능을 테스트했습니다.
비전 모델의 성능은 매우 인상적이었습니다. 슬라이드의 주제와 배경 맥락을 정확히 이해하고, 본문 핵심 내용을 발표에 적합한 언어로 재구성했을 뿐 아니라, 그래프 요소를 인식하여 자연스럽게 포함시키고 다음 슬라이드와의 연결성까지 고려해 전체 흐름을 매끄럽게 만들었습니다. 이제 대본을 처음부터 작성할 필요 없이 하이퍼클로바X가 제공하는 기본 대본을 활용하여 톤과 길이를 쉽게 조정할 수 있습니다. 백지 상태에서 시작하는 부담을 덜고, 대본 작성부터 예상 질문 준비, 톤 조절까지 효율적인 프레젠테이션 준비가 가능해졌습니다.
4. 외국어 문서의 텍스트 추출/번역/요약을 한 번에
해외 출장 중 현지 파트너로부터 받은 외국어로 된 계약서 부록을 급히 검토해야 하는 상황을 상상해보세요. 수십 페이지에 이르는 법률 용어와 기술 명세로 가득 찬 문서를 마감 시간 내에 이해하고 중요한 변경 사항을 파악해야 합니다. 과거에는 이러한 상황에서 여러 단계의 작업이 필요했습니다. 문서를 스캔하거나 사진으로 찍은 뒤, 텍스트 추출 도구를 사용하고, 번역 프로그램을 통해 번역한 다음, 중요한 내용을 직접 찾아 요약해야 했습니다. 이러한 '문서 획득 → 텍스트 추출 → 번역 → 내용 분석'의 복잡한 과정은 많은 시간을 소모할 뿐만 아니라, 각 단계마다 정보의 정확성이 떨어질 위험이 있었습니다.
그러나 이제 비전 모델 덕분에 이 과정이 획기적으로 간소화되었습니다. 계약서 이미지를 업로드 하면 HCX-005 모델이 텍스트를 정확하게 인식하고, 맥락을 고려하여 번역하며, 중요한 조항과 변경 사항을 효과적으로 요약해 한 번에 제공할 수 있을 것입니다. 시간에 쫓기는 상황에서도 언어 장벽 없이 복잡한 문서의 핵심을 신속하고 정확하게 파악할 수 있게 되었습니다.
숙소 안내문 이미지와 함께 "내용을 정리해줘"라고 요청하면 비전 모델이 정보를 인식하여 체계적으로 구조화된 요약을 제공합니다. 이 기술은 여행 중 마주치는 다양한 공지사항, 음식점 메뉴판, 공공시설 안내문 등을 실시간으로 해석하여 언어 장벽을 효과적으로 해소합니다. 이를 통해 사용자는 낯선 환경에서도 핵심 정보를 신속하게 파악하고 더 나은 여행 경험을 누릴 수 있습니다.
5. 복잡한 표/차트/그래프 분석은 더이상 그만!
이동평균선, 저항선, 추세선, 거래량…
주가 차트를 이해하는 일이 어렵게 느껴지신 적 있으신가요? 각 용어의 정의는 익혔지만, 차트가 전달하는 전체 흐름과 의미를 읽어내는 것은 또 다른 과제였습니다. 특히 여러 보조지표가 한 화면에 겹쳐져 있을 때, 시장이 보내는 신호를 정확히 읽고 해석하는 일은 쉽지 않았을 것입니다. 이제는 비전 모델을 통해 이미지 기반 주식 차트에서도 유의미한 인사이트를 얻을 수 있습니다. 단순한 숫자의 나열을 넘어, 시장 흐름의 핵심 메시지와 변곡점, 그리고 기술적 분석에 기반한 해석까지 도출할 수 있습니다.
이 기술은 주가 차트 분석을 비롯해 논문 내 실험 그래프 자동 요약, 매출/비용 차트의 자동 분석 및 이상 탐지, 그리고 회사 KPI 기반의 대시보드 자동 리포트 생성 등 여러 분야로 확장 가능합니다. 비전 모델을 활용한 분석은 단순한 데이터 인식을 넘어, 다양한 산업에서 의미 있는 의사결정을 자동으로 지원하는 인사이트 도구로 자리잡을 수 있을 것입니다.
6. 학생의 손글씨 시험지 채점, 이제는 비전모델로
학생보다 교사가 더 오래 붙잡고 있어야 했던 시험지, 이제는 AI가 채점합니다
시험이 끝나면 학생들은 자유를 얻지만, 교사에게는 또 다른 업무가 시작됩니다. 특히 수학이나 과학 과목처럼 풀이 과정이 중요한 시험지의 경우, 단순 정답 확인을 넘어 학생의 사고 흐름을 면밀히 검토해야 합니다. 이 과정에서 다양한 글씨체와 표기법 해석, 장시간 집중력 유지의 어려움, 그리고 휴먼 에러로 인한 채점 오류 가능성 등 여러 과제에 직면하게 됩니다. 비전 모델이 이러한 문제들에 실질적인 해결책을 제공합니다.
손글씨 시험지를 이미지로 업로드하면, 비전 언어 모델이 학생의 손글씨를 정확히 인식하고, 대규모 언어 모델이 모범 답안과 비교 분석하여 자동 채점을 완료합니다. 이러한 시스템은 교사의 시간을 절약할 뿐만 아니라, 일관된 평가 기준을 적용해 채점의 공정성과 정확성을 높여줍니다. 이는 교육 현장에서 실질적인 문제를 해결하는 AI 기술의 대표적인 적용 사례가 될 수 있을 것입니다.
시험지 이미지와 정답 이미지를 함께 입력하고 "채점해줘"라고 요청하면 복잡한 개발 과정 없이도 깔끔하게 채점된 결과를 즉시 확인할 수 있어 교육 현장의 실용성이 높습니다. 이 채점 자동화 기술은 칠판 필기 자동 요약, 스마트 학원 시스템, 교사용 학생 관리 리포트 생성, 손글씨 메모 정리 등 다양한 교육 분야로 확장 가능합니다.
7. 비전 모델이 열어가는 제품 마케팅의 새로운 가능성
언어 모델은 마케팅 문구 생성에 혁신적인 변화를 가져왔지만, 제품을 정확히 묘사하기 위해서는 여전히 상세한 설명이 필요했습니다. 제품의 특성, 디자인, 색상, 질감 등을 글로 표현해야만 적절한 마케팅 문구를 얻을 수 있었습니다. 이 과정은 시간이 많이 소요되고 때로는 핵심 특징을 놓치기도 했습니다. 그러나 이제 비전 모델의 등장으로 이러한 한계를 극복할 수 있게 되었습니다.
제품 사진 하나만 업로드하면 비전 모델이 시각적 요소를 분석하고, 제품의 특징을 정확히 파악하여 매력적인 마케팅 문구를 자동으로 생성합니다. 이미지에서 직접 정보를 추출하는 능력 덕분에 마케팅 작업 흐름이 획기적으로 간소화될 것입니다. 이 기술은 단순한 시간 절약을 넘어 제품의 시각적 특성 색상의 미묘한 차이 디자인의 특별한 요소 사용 환경 등을 기반으로 더욱 정확하고 매력적인 카피를 생성합니다.
이 외에도 썸네일 기반 쇼츠 제목 추천, 이메일 제목과 푸시 메시지 자동화, 릴스 스크립트 자동 생성 등으로 다양하게 활용할 수 있어 단시간에 저비용으로 고품질 마케팅 컨텐츠를 생성할 수 있습니다.
마치며
과거에는 불가능하거나 여러 단계를 거쳐야 했던 일들이 많았습니다. 복잡한 문서 구조, 이미지 속 정보, 손글씨, 차트와 같은 비정형 데이터는 자동화의 사각지대에 머물러 있었습니다. 그러나 이제 HCX-005를 통해 이러한 한계가 점차 사라질 것으로 기대됩니다. 더 단순화된 방식으로, 더 빠르고 정확하게, 그리고 무엇보다 현실적인 비용과 품질로 이전에는 시도조차 어려웠던 작업들이 가능해졌습니다.
비전 모델의 등장으로 업무 자동화는 단순 반복 작업을 넘어 이해, 판단, 생성이 필요한 고차원적 영역까지 확장되었습니다. 이는 단순히 기존 기능을 대체하는 도구가 아니라, 산업 전반의 업무 방식을 근본적으로 재정의하고 새로운 가치 창출의 토대가 됩니다. 교육, 마케팅, 행정, 제조, 금융 등 비정형 데이터가 존재하는 다양한 분야에서 이러한 기술의 활용 가능성이 점차 현실화되고 있습니다. 복잡했던 일은 이제 더 이상 복잡하지 않으며, 어렵던 자동화는 누구나 활용할 수 있는 기술이 되었습니다. 비전 모델, HCX-005와 함께 여러분의 비즈니스를 마음껏 성장시켜보세요.
-
 1
1
-
 1
1
-
-
안녕하세요, @HongSamToneGold님,
요청하신 내용을 확인해 보니,
max_tokens로 요청을 주신 것으로 보입니다.해당 파라미터명은 지원되지 않기 때문에, 기본값인 100으로 요청이 처리된 것으로 확인됩니다.
가이드 문서에 안내된 것처럼
maxTokens로 요청해 주셔야 하며, 필요에 따라 해당 값을 조정해 주시면 됩니다.가이드: https://api.ncloud-docs.com/docs/clovastudio-chatcompletions
확인 부탁드립니다.
감사합니다.
-
안녕하세요, @봄애나 님,
고객센터를 통해서 문의 접수해주신 것으로 알고 있습니다.
만약 그렇지 않다면, 보다 정확한 내용 파악을 위해 https://www.ncloud.com/support/question/service 에서 이용 문의를 접수 부탁드립니다.
감사합니다.
-
안녕하세요, @intube님,
클로바 스튜디오에 많은 관심을 가져주셔서 감사합니다.
이미지를 이해하는 비전 모델과 관련 신규 기능 출시를 준비 중에 있습니다.
빠른 시일 내에 업데이트 소식을 전해드릴 수 있도록 하겠습니다.
감사합니다.
-
안녕하세요, @SiSAFER님,
대화 내용을 기억하는 구현 방법에는 여러 가지가 있겠지만,
가장 간단하게 시도할 수 있는 방법은 시스템 프롬프트에 관련 정보와 지시 사항을 명확히 작성하는 것입니다.이때, 주어진 지시 사항을 최대한 벗어나지 않도록 Repetition penalty를 1.2 정도로 설정하는 것을 권장합니다. (단, 작업에 따라 다소 조정될 수 있습니다.)
감사합니다.
-
안녕하세요, @tunib님,
플래이그라운드에서 수행한 작업을 저장한 뒤, 테스트 앱 버튼을 누른 후 테스트 앱을 생성을 하면,
서비스앱 신청 현황 페이지의 '신청할 작업'에서 작업이 보여지게 됩니다.
확인 부탁드립니다.
감사합니다.
-
튜닝한 모델에 대해서
in 이용 문의
-
이용 요금 관련 문의
in 이용 문의
안녕하세요, @todayssky님,
테스트 앱을 이용하시는 경우에도 이용 요금이 부과됩니다. (이용 요금 확인)
Cost Explorer에서는 해당 상품의 집계 기준에 따라 요금이 표시될 수 있습니다.
보다 자세한 사항은 이용 문의를 통해 문의해 주세요.
테스트 앱의 API Key는 만료 기한이 없습니다.
감사합니다.
-
안녕하세요, @insighter님,
서비스 앱 심사는 1-3주 가량 소요될 수 있습니다. (가이드)
서비스 앱 승인 이후에 API 이용하실때 필요하신 형태로 파라미터 조정을 하셔도 무방합니다.
감사합니다.
-
-
안녕하세요, @dogfootruler님,
아래 이용문의 링크를 통해 문의 남겨주시면, 자세히 안내해 드리도록 하겠습니다.
https://www.ncloud.com/support/question/service
감사합니다.
-
안녕하세요, @ITIMES님,
클로바 스튜디오의 플레이그라운드에서 몇 줄의 프롬프트 입력만으로도 감정 분석을 수행할 수 있는 기능을 구현할 수 있습니다.
플레이그라운드를 통한 대체 기능 구현 방법
- 네이버 클라우드 플랫폼 콘솔에서 Services > AI Services > CLOVA Studio 메뉴를 차례대로 클릭해 주십시오.
- My Product 메뉴를 클릭한 후 [CLOVA Studio 바로가기] 버튼을 클릭해 주십시오.
- 플레이그라운드 메뉴를 클릭해 주십시오.
- 화면 왼쪽의 시스템 영역에 모델이 수행할 작업에 대한 구체적인 지시문 또는 예제를 입력해주십시오.
- [실행] 버튼을 클릭해 주십시오.
CLOVA Studio의 원활한 이용을 위해 사용 가이드 안내를 안내드립니다.
감사합니다.
-
안녕하세요, 클로바 스튜디오 담당입니다.
언어 모델의 특성상 최신 정보나 날짜를 직접 알 수는 없습니다.
날짜의 경우에는 프롬프트에 {날짜} 정보를 동적으로 설정하는 방법을 사용할 수 있습니다.
다만, 이 방법으로도 실제로 외부의 최신 정보를 가져오는 것은 불가능하므로, 해당 필요가 있다면 스킬 트레이너를 고려해볼 수 있습니다.
스킬 트레이너는 언어 모델을 외부 API와 연동하여 학습시키는 기능입니다.
https://guide.ncloud-docs.com/docs/clovastudio-skilltrainer
감사합니다.
-
안녕하세요, @morm님,
1. 네, 개인 프로젝트의 용도로도 이용하실 수 있으며, 필요에 따라 서비스 앱 신청을 진행해주시면 됩니다.
- 서비스앱 신청: https://guide.ncloud-docs.com/docs/clovastudio-playground01#서비스앱신청
- 이용량 제어 정책: https://guide.ncloud-docs.com/docs/clovastudio-ratelimiting
2. 서비스 이용약관에 기재되어 있는데요. '서비스 약관 10조 1항: 서비스 관련 정보 및 자료는 회사의 서비스 품질 및 기능 개선을 위해 사용할 수 있습니다.'를 참고하시면 될 것 같습니다.
감사합니다.
-
본 Cookbook은 기존 🦜🔗 랭체인(Langchain)으로 Naive RAG 구현하기 cookbook에서 한 단계 더 나아가, 다양한 CLOVA Studio API와 오픈소스 도구들을 활용해 고급 검색 및 생성 기능을 구현하는 방법을 소개합니다
주요 컴포넌트로는 LangChain과 연동되는 bge-m3 기반의 임베딩 v2 API와 Chat Completions API를 중심으로, 토큰 계산기, 문단 나누기 API, 요약 v2 API가 포함되며, 성능 향상을 위해 reranking, summarization, multi-query 등의 고급 모듈들이 추가되었습니다.
전체 파이프라인은 데이터 전처리부터 시작하여 문단 분할, 임베딩 생성, 벡터 DB 구축, 고도화된 검색 로직 구현, 그리고 HyperCLOVA X를 통한 최종 응답 생성까지 체계적으로 구성되어 있습니다. 각 모듈은 독립적으로 설계되어 있어 사용자의 필요에 따라 유연하게 조합할 수 있으며, 이를 통해 더욱 정확하고 맥락에 맞는 응답을 생성할 수 있는 Advanced RAG 시스템을 구축할 수 있습니다.
- NCP 가이드: https://guide.ncloud-docs.com/docs/clovastudio-dev-langchain
-
LangChain 공식 문서: https://python.langchain.com/docs/integrations/providers/naver/
버전 정보
아래 예제 코드는 Python 3.12.4에서 실행 확인하였으며, 최소 Python3.9를 필요로 합니다.
langchain-community >= 0.3.4부터 langchain_community 안에 ChatClovaX, ClovaXEmbeddings가 포함되었습니다.
아래 파일을 참고해 필요한 모듈을 모두 설치해줍니다.
requirements.txt1. 사전 준비
1) Langchain 패키지 설치
아래 파일을 참고해 필요한 모듈을 모두 설치해줍니다.
pip install langchainpip install langchain-community~=0.3.42) 코드에 공통적으로 들어가는 필요 모듈 import
importjsonimportosimportsubprocessfromlangchain_community.document_loadersimportUnstructuredHTMLLoaderfrompathlibimportPathimporthttp.clientfromhttpimportHTTPStatusfromtqdmimporttqdmimporttimeimportosimportgetpassimportuuidfromuuidimportuuid43) API Key 및 테스트앱 발급
CLOVA Studio에서 문단 나누기, 임베딩V2, 요약 테스트앱을 미리 발급받습니다. 서비스 앱을 이용하고자 할 경우 사전 설정이 아니라 개별 모듈 정의 시마다 해당 API Key를 입력해야합니다. 따라서 각 모듈 호출 시 필요한 API Key와 App ID를 환경 변수로 미리 저장해두는 것이 좋습니다.
Quote# API 키와 Gateway API 키를 넣습니다.os.environ["NCP_CLOVASTUDIO_API_KEY"]=getpass.getpass("NCP CLOVA Studio API Key: ")os.environ["NCP_APIGW_API_KEY"]=getpass.getpass("NCP API Gateway API Key: ")NCP CLOVA Studio API Key: ········ NCP API Gateway API Key: ········
# 문단나누기 테스트앱의 앱 ID를 넣습니다.os.environ["NCP_CLOVASTUDIO_APP_ID_SEGMENTATION"]=input("NCP CLOVA Studio Segmentation App ID: ")NCP CLOVA Studio Segmentation App ID: <your Segmentation App ID>
# 임베딩 테스트앱의 앱 ID를 넣습니다.os.environ["NCP_CLOVASTUDIO_APP_ID"]=input("NCP CLOVA Studio App ID: ")NCP CLOVA Studio App ID: <your App ID>
# 요약 테스트앱의 앱 ID를 넣습니다.os.environ["NCP_CLOVASTUDIO_APP_ID_SUMMARIZATION"]=input("NCP CLOVA Studio Summarization App ID: ")NCP CLOVA Studio App ID: <your Summarization App ID>
2. 상위 클래스 정의
"CLOVAStudioExecutor"라는 상위 클래스로 각 API의 공통 양식을 묶고, 각 API의 부가적인 로직을 하위 클래스로 추가 정의합니다. 임베딩 V2와 Chat Completions는 랭체인 패키지에서 바로 불러와 클래스 설정이 필요 없습니다. 아래의 두 코드를 실행한 이후에는 모든 코드에서 별도의 클래스 선언 없이, main 코드만 실행하면 됩니다. 또한, CLOVA Studio API들의 기존 파이썬 스펙에서의 클래스 이름을 API의 성질에 맞게 변경했으며, 대응하는 클래스의 이름은 주석으로 확인 가능합니다.
CLOVAStudioExecutor
QuoteimportbackoffclassRateLimitException(Exception):passclassCLOVAStudioExecutor:def__init__(self, host):self._host=hostself._api_key=os.environ.get("NCP_CLOVASTUDIO_API_KEY")self._api_key_primary_val=os.environ.get("NCP_APIGW_API_KEY")self._request_id=str(uuid.uuid4())# Validate required environment variablesifnotself._api_key:raiseValueError("NCP_CLOVASTUDIO_API_KEY environment variable is not set")ifnotself._api_key_primary_val:raiseValueError("NCP_APIGW_API_KEY environment variable is not set")def_send_request(self, completion_request, endpoint):headers={'Content-Type':'application/json; charset=utf-8','X-NCP-CLOVASTUDIO-API-KEY':self._api_key,'X-NCP-APIGW-API-KEY':self._api_key_primary_val,'X-NCP-CLOVASTUDIO-REQUEST-ID':self._request_id}conn=http.client.HTTPSConnection(self._host)conn.request('POST', endpoint, json.dumps(completion_request), headers)response=conn.getresponse()status=response.statusresult=json.loads(response.read().decode(encoding='utf-8'))conn.close()returnresult, status@backoff.on_exception(backoff.expo, RateLimitException, max_tries=5, max_time=120, base=10)defexecute(self, completion_request, endpoint):res, status=self._send_request(completion_request, endpoint)ifstatus==HTTPStatus.OK:returnres, statuselifstatus==HTTPStatus.TOO_MANY_REQUESTS:raiseRateLimitExceptionelse:raiseException(f"API Error: {res}, {status}")개별 클래스 추가 정의
QuoteclassSegmentationExecutor(CLOVAStudioExecutor):def__init__(self, host):super().__init__(host)self.app_id=os.environ.get("NCP_CLOVASTUDIO_APP_ID_SEGMENTATION")ifnotself.app_id:raiseValueError("NCP_CLOVASTUDIO_APP_ID_SEGMENTATION environment variable is not set")defexecute(self, completion_request):endpoint=f'/testapp/v1/api-tools/segmentation/{self.app_id}'res, status=super().execute(completion_request, endpoint)ifstatus==HTTPStatus.OKand"result"inres:returnres["result"]["topicSeg"]else:error_message=res.get("status", {}).get("message","Unknown error")ifisinstance(res,dict)else"Unknown error"raiseValueError(f"오류 발생: HTTP {status}, 메시지: {error_message}")classSummarizationExecutor(CLOVAStudioExecutor):def__init__(self, host):super().__init__(host)self.app_id=os.environ.get("NCP_CLOVASTUDIO_APP_ID_SUMMARIZATION")ifnotself.app_id:raiseValueError("NCP_CLOVASTUDIO_APP_ID_SUMMARIZATION environment variable is not set")defexecute(self, completion_request):endpoint=f'/testapp/v1/api-tools/summarization/v2/{self.app_id}'res, status=super().execute(completion_request, endpoint)ifstatus==HTTPStatus.OKand"result"inres:returnres["result"]["text"]else:error_message=res.get("status", {}).get("message","Unknown error")ifisinstance(res,dict)else"Unknown error"raiseValueError(f"오류 발생: HTTP {status}, 메시지: {error_message}")classEmbeddingTokenizerExecutor(CLOVAStudioExecutor):defexecute(self, completion_request):endpoint='/v1/api-tools/embedding/v2/tokenize'res, status=super().execute(completion_request, endpoint)ifstatus==HTTPStatus.OKand"result"inres:returnres["result"]["numTokens"]else:error_message=res.get("status", {}).get("message","Unknown error")ifisinstance(res,dict)else"Unknown error"raiseValueError(f"오류 발생: HTTP {status}, 메시지: {error_message}")
3. Raw Data → Connecting🦜🔗 랭체인(Langchain)으로 Naive RAG 구현하기 cookbook에서 거쳤던 동일한 과정으로, 아래와 같이 진행됩니다.
1. txt 파일에 데이터로 활용할 사이트 주소 작성
2. txt 파일 내 URL을 HTML로 변환
3. mapping 정보가 담긴 json 파일 생성
4. LangChain Document Loader를 활용한 로딩
5. json 파일을 통해 실제 URL로 교체
보다 다양한 데이터를 활용하기 위해 파일에 포함된 가이드 문서를 전체 범위로 넓혔으며, 변경된 txt 파일과 전체 코드는 다음과 같습니다.1) txt → html 변환 및 원본 사이트 주소 mapping
files_path=os.getcwd()url_to_filename_map={}# ipynb 파일 위치에 files 폴더를 만들어 관련 파일을 일괄 관리합니다.# 위에서 다운받은 clovastudiourl.txt 파일 역시 해당 폴더 안에 위치시켜주세요.folder_path="files"ifnotos.path.exists(folder_path):os.makedirs(folder_path)withopen(f"{folder_path}/clovastudiourl.txt","r") asfile:urls=[url.strip()forurlinfile.readlines()]forurlinurls:filename=url.split("/")[-1]+".html"file_path=os.path.join(folder_path+'/clovastudio-guide', filename)subprocess.run(["wget","--user-agent=RAGCookbook-Crawler/1.0","-O", file_path, url], check=True)url_to_filename_map[url]=filenamewithopen(f"{folder_path}/url_to_filename_map.json","w") as map_file:json.dump(url_to_filename_map, map_file)--2024-11-01 00:00:00-- https://guide.ncloud-docs.com/docs/clovastudio-overview guide.ncloud-docs.com (guide.ncloud-docs.com) 해석 중... xxx.xx.x.xxx, xxx.xx.x.xxx 다음으로 연결 중: guide.ncloud-docs.com (guide.ncloud-docs.com)|xxx.xx.x.xxx|:xxx... 연결했습니다. HTTP 요청을 보냈습니다. 응답 기다리는 중... 200 OK 길이: 지정하지 않음 [text/html] 저장 위치: `clovastudio-guide/clovastudio-overview.html' 0K .......... .......... .......... .......... .......... 40.8M 50K .......... .......... .......... . 106M=0.001s (이하 중략)
2) LangChain 활용 HTML 로딩# 폴더 이름에 맞게 수정html_files_dir=Path(f'{folder_path}/clovastudio-guide')html_files=list(html_files_dir.glob("*.html"))clovastudiodatas=[]forhtml_fileinhtml_files:loader=UnstructuredHTMLLoader(str(html_file))document_data=loader.load()clovastudiodatas.append(document_data)print(f"Processed {html_file}")Processed .../clovastudio-guide/clovastudio-info.html (이하 중략)
3. Json 파일 적용, 실제 URL로 대체 및 후처리
withopen("url_to_filename_map.json","r") as map_file:url_to_filename_map=json.load(map_file)filename_to_url_map={v: kfork, vinurl_to_filename_map.items()}# clovastudiodatas 리스트의 각 Document 객체의 'source' 수정fordoc_listinclovastudiodatas:fordocindoc_list:extracted_filename=doc.metadata["source"].split("/")[-1]ifextracted_filenameinfilename_to_url_map:doc.metadata["source"]=filename_to_url_map[extracted_filename]else:print(f"Warning: {extracted_filename}에 해당하는 URL을 찾을 수 없습니다.")clovastudiodatas_flattened = [item for sublist in clovastudiodatas for item in sublist]
4. Chunking
임베딩 모델이 처리할 수 있는 적당한 크기로 raw data를 나누기 위해 CLOVA Studio의 문단 나누기 API를 활용했습니다. 이 API를 이용하면 문장들 간의 의미 유사도에 기반하여 최적의 청크(chunk) 개수로 문단을 나누고, 추가로 후처리(postProcess=True)를 통해 사용자가 원하는 1개 청크 크기(글자 수)를 설정하여 문단을 나눌 수 있습니다. 자세한 내용은 문단 나누기 API 관련 문서를 참고해주세요. (사용 가이드, API 가이드)
segmentation_executor=SegmentationExecutor(host='clovastudio.apigw.ntruss.com')chunked_html=[]# 문단으로 나눈 결과와 페이지 번호를 저장할 리스트forhtmldataintqdm(clovastudiodatas_flattened):request_data={"text": htmldata.page_content,"alpha":-100,"segCnt":-1,"postProcess":True,"postProcessMaxSize":1000,"postProcessMinSize":300}response_data=segmentation_executor.execute(request_data)forparagraphinresponse_data:chunked_document={"source": htmldata.metadata['source'],# 문단의 주소"text": paragraph# 문단의 텍스트}chunked_html.append(chunked_document)foriteminchunked_html:item['text']="".join(item['text'])print(len(chunked_html))chunked_html[50]
chunked_html[50]{'source': 'https://guide.ncloud-docs.com/docs/clovastudio-skillset', 'text': '스킬셋: 스킬셋 이름.영문자, 한글, 숫자, 공백을 허용하며...'}
- 본 cookbook에서는 alpha와 SegCnt 모두 모델이 알아서 최적값으로 결정하도록 했습니다. 후처리 모듈인 postProcess를 활용했고, postProcessMaxSize와 postProcessMinSize 모두 기본값인 1000자와 300자가 임베딩 v2 API의 처리 한도 내에 들어올 수 있기 때문에 별도로 변경하지 않았습니다.
- 문단 나누기를 진행할 전체 텍스트의 내용, 기호, 언어등에 따라 약간의 차이는 있을 수 있지만, 모델이 의미 기반으로 문단 나누기를 진행하는 만큼 처리 한도를 초과할 만큼의 큰 chunk를 생성하는 경우는 매우 드뭅니다.
5. Vector DB
1) 리스트 형식의 documents로 만들기
임베딩 처리를 위해 앞서 만든 청크를 Document 객체들의 리스트 형식의 documents로 변환합니다.
fromlangchain_core.documentsimportDocumentdocuments=[]forindex, iteminenumerate(chunked_html):doc=Document(page_content=str(item['text']),metadata={"source": item['metadata']},id=str(uuid4()))documents.append(doc)아래 코드를 통해 변환된 documents의 구조를 확인할 수 있습니다.
# documents 구조 체크fori, docinenumerate(documents):print(f"Document {i}:")print(f" Page Content: {doc.page_content[:100]}...")# 첫 100자만 출력print(f" Metadata: {doc.metadata}")print(f" Page Content Type: {type(doc.page_content)}")print(f" Metadata Type: {type(doc.metadata)}")print("-"*40)Document 0: Page Content: 스킬셋: 스킬셋 이름.영문자, 한글, 숫자, 공백을 허용하며 30자 이내로 입력스킬셋 설명: 해당 스킬셋이 제공할 기능에 대한 설명.1,000자 이내로 입력서비스 분야: 생성할 스... Metadata: {'source': 'https://guide.ncloud-docs.com/docs/clovastudio-skillset'} Page Content Type: <class 'str'> Metadata Type: <class 'dict'> ---------------------------------------- ...(이하 중략)
2) Chroma에 임베딩 값 저장하기본 예제에선 Chroma를 사용합니다. Chroma는 오픈소스 Vector DB이며, 클라우드를 사용하지않고 클라이언트용으로 사용하면 Apache 2.0 라이센스에 무료로 이용할 수 있습니다. 본 예제에서는 chroma를 활용해 컬렉션을 생성하고, 컬렉션에 앞서 만든 문서를 추가해보겠습니다.
hnsw:space의 값을 설정함으로써 임베딩 공간의 거리 방법을 사용자 정의할 수 있습니다. 임베딩에 사용할 모델은 유사도 판단을 위해 벡터의 cosine 거리 단위로 사용하므로, 컬렉션 또한 매개변수를 "cosine"으로 설정해주었습니다.*매개변수는 ip, cosine, l2(기본값) 중에 선택할 수 있습니다.
또한, 임베딩 클래스에 오류가 발생시 멈추게끔 하는 로직을 일부 추가해, 다량의 데이터를 처리할 때 오류 발생시 재실행의 부담을 줄였으며, 이에 따라 전체 문서를 처리하는데 약 4~5분 정도 소요될 수 있습니다. LangChain 공식 문서에서 Chroma를 활용하는 자세한 내용을 확인할 수 있습니다.
- 벡터 DB는 문서의 의미를 담은 임베딩 데이터를 저장하고 유사도 검색을 수행하는 데이터베이스입니다. LangChain과 함께 사용할 수 있는 벡터 DB는 본 예제에서 사용한 Chroma 이외에도 Pinecone, FAISS, Milvus Lite 등 다양한 옵션이 있으며, 개발 환경(로컬/클라우드)과 목적(확장성/관리 용이성)에 따라 적절한 선택이 필요합니다. Langchain 공식 문서를 참고해 사용 목적에 맞는 VectorDB를 선택하세요. (링크)
importchromadbfromlangchain_chromaimportChroma# 임베딩 모델 정의clovax_embeddings=ClovaXEmbeddings(model='bge-m3')# 로컬 클라이언트 경로 지정client=chromadb.PersistentClient(path="./chroma_langchain_db")#저장할 로컬 경로# Chroma 컬렉션 생성chroma_collection=client.get_or_create_collection(name="clovastudiodatas_docs",#collection이 바뀔때마다 이름도 꼭 변경해줘야 합니다.metadata={"hnsw:space":"cosine"}#사용하는 임베딩 모델에 따라 ‘l2’, 'ip', ‘cosine’ 중에 사용)# Chroma 벡터 저장소 생성vectorstore=Chroma(client=client,collection_name="clovastudiodatas_docs",embedding_function=clovax_embeddings)# tqdm으로 for 루프 감싸기fordocintqdm(documents, desc="Adding documents", total=len(documents)):embeddings=clovax_embeddings.embed_documents([doc.page_content])[0]# 문서 추가chroma_collection.add(ids=[str(uuid.uuid4())],# 고유한 ID 생성documents=[doc.page_content],embeddings=[embeddings],metadatas=[doc.metadata])time.sleep(1)# 이용량 제어를 고려한 1초 이상의 딜레이, 필요에 따라 조정 가능print("All documents have been added to the vectorstore.")Adding documents: 100%|██████████| 238/238 [04:55<00:00, 1.24s/it]All documents have been added to the vectorstore.
6. Retrieval → HyperCLOVA X (naive)
랭체인에서 ChatClovaX를 불러와 최종적인 답변을 생성하는 단계입니다. 우선 Advanced RAG 방법론과의 비교를 위해 아래와 같이 Naive RAG 체인을 구성해보았습니다.
사용자의 질문 임베딩 → Vector DB 내에서 유사도 높은 데이터 검색 → HyperCLOVA X에게 전달("context") → 최종적인 답변 생성
이와 같은 기본적인 RAG의 답변 생성 로직을 사전에 정의함으로서 Advanced RAG 방법론을 위한 Retrieval 전/후에 여러 기능 및 모듈을 연결해볼 수 있습니다. (Retrieval 전/후에 연결할 수 있는 부가적인 기능들은 아래의 Advanced module 파트에서 담았습니다.)
1) 답변 생성 Retrieval 정의 및 Chain 구현답변 생성 함수에 사용된 프롬프트는 다음과 같습니다.
# 답변 생성 함수 프롬프트 전문
당신은 질문-답변(Question-Answering)을 수행하는 친절한 AI 어시스턴트입니다.
당신의 임무는 원래 가지고 있는 지식은 모두 배제하고, 주어진 문맥(context) 만을 참고하여 주어진 질문(question) 에 답하는 것입니다.
검색된 다음 문맥(context) 만을 사용하여 질문(question) 에 답하세요.
만약, 주어진 문맥(context) 에서 답을 찾을 수 없다면, 답을 모른다면 `주어진 정보에서 질문에 대한 정보를 찾을 수 없습니다` 라고 답하세요.fromlangchain.chainsimportcreate_retrieval_chainfromlangchain.chains.combine_documentsimportcreate_stuff_documents_chainfromlangchain_core.promptsimportChatPromptTemplatefromlangchain_community.chat_modelsimportChatClovaX# retrieverretriever=vectorstore.as_retriever(kwargs={"k":3})# chat모델 정의chat=ChatClovaX(model="HCX-003",temperature=0.2)# ChatPromptTemplate 사용system_prompt=("""당신은 질문-답변(Question-Answering)을 수행하는 친절한 AI 어시스턴트입니다. 당신의 임무는 원래 가지고 있는 지식은 모두 배제하고, 주어진 문맥(context) 만을 참고하여 주어진 질문(question) 에 답하는 것입니다.검색된 다음 문맥(context) 만을 사용하여 질문(question) 에 답하세요. 만약, 주어진 문맥(context) 에서 답을 찾을 수 없다면, 답을 모른다면 `주어진 정보에서 질문에 대한 정보를 찾을 수 없습니다` 라고 답하세요.""""\n\n""{context}")prompt=ChatPromptTemplate.from_messages([("system", system_prompt),("human","{input}"),])# Built-in chainsquestion_answer_chain=create_stuff_documents_chain(chat, prompt)rag_chain=create_retrieval_chain(retriever, question_answer_chain)result=rag_chain.invoke({"input":"클로바 스튜디오에서 어떤 모델 엔진을 쓸 수 있나요?"})print("질문:")print(result['input'])print("\n답변:")print(result['answer'])print("\n참조 문서 URL:")unique_urls=set(doc.metadata['source']fordocinresult['context'])forurlinunique_urls:print(url)질문: 클로바 스튜디오에서 어떤 모델 엔진을 쓸 수 있나요? 답변: 클로바 스튜디오에서는 한국어 엔진인 LK-B, LK-D2, 그리고 HyperCLOVA X 엔진인 HCX-003, HCX-DASH-001을 사용할 수 있습니다. 참조 문서 URL: https://guide.ncloud-docs.com/docs/clovastudio-info
7. Advanced module
다음은 Naive RAG와 Advanced RAG의 주요 차별점이 될 수 있는, RAG의 검색 및 답변 정확도를 높이기 위한 몇 가지 방법들입니다. 데이터의 양이 많고 질문이 복잡하거나 모호할수록 retrieval(검색) 전후에 부가적인 기능들을 추가하여 RAG의 완성도를 높일 필요가 있습니다. 이러한 필요성에 따라 관련 방법론들이 활발히 연구되고 있으며, CLOVA Studio가 제공하는 기능들 또는 오픈소스를 통해 연계할 수 있는 대표적인 예시들을 아래에 소개했습니다.
1) Reranking
Reranking은 사용자 질문에 대한 검색 결과(reference)의 유사도 순위를 재조정하는 과정입니다. 이는 Vector DB에 저장된 벡터들의 맥락 보존 정도와 검색 성능을 보완하는 추가적인 안전 장치 역할을 합니다. 본 cookbook에선 한국어를 지원하는 reranking 모델 중 무료로 사용할 수 있는 버전인 bge-m3 multilingual reranker를 사용합니다.
Bge-m3 multilingual reranker
CLOVA Studio의 임베딩 v2 모델의 기반인 bge-m3의 reranker입니다. 이 모델은 HuggingFace 허브에서 제공되며, LangChain
HuggingFaceCrossEncoder클래스를 통해 쉽게 사용할 수 있습니다. LLM 기반이 아닌 bge-m3 embedding 기반의 Reranking을 사용할 경우, rate limit의 제한이 없습니다.아래 코드에서는 학습 데이터셋 업로드를 다루고 있는 문서와 함께 관련 있는 쿼리, 관련이 없는 쿼리에 대해 reranker로 매긴 점수(유사도)를 비교해보면 연관성이 있는 쿼리에서 더 높은 점수를 출력하는 것을 확인할 수 있습니다. 점수가 높을수록 두 텍스트가 의미적으로 더 관련이 있다는 것을 나타냅니다.fromlangchain_community.cross_encodersimportHuggingFaceCrossEncoder# reranker 정의reranker=HuggingFaceCrossEncoder(model_name='BAAI/bge-reranker-v2-m3',)# 실행 예시score_similar=reranker.score([chunked_html[50]['text'],'학습을 위한 데이터셋 업로드 방법'])score_different=reranker.score([chunked_html[50]['text'],'오늘 점심 메뉴'])print(score_similar, score_different)# 유사도 점수 추출0.82105595 0.13086149
- HuggingFaceCrossEncoder는 HuggingFace의 cross encoder 모델들을 사용할 수 있게 해주는 랭체인의 래퍼 클래스입니다. 이 클래스를 통해 문서 쌍의 유사도를 계산할 수 있습니다.
-
model_name으로 'BAAI/bge-reranker-v2-m3'를 지정했는데, 이는 BAAI에서 제공하는 reranking 전용 모델입니다. 기본값인 'BAAI/bge-reranker-base'보다 더 큰 모델을 사용하여 성능이 더 좋은 것으로 알려져 있습니다.
이 함수는 Retrieval 결과인 "context"를 추가로 reranking한 후, HyperCLOVA X에 전달하여 답변을 생성하는 전체 과정을 구현합니다. 기존의 답변 생성 함수인 html_chat_naive에 bge-m3 reranker를 통합한 구조로, 검색 결과의 정확도를 높이고 더 관련성 있는 정보를 기반으로 답변을 생성합니다.
fromlangchain.chainsimportcreate_retrieval_chainfromlangchain.chains.combine_documentsimportcreate_stuff_documents_chainfromlangchain_core.promptsimportChatPromptTemplatefromlangchain_community.chat_modelsimportChatClovaXdefhtml_chat(query:str):"""RAG 검색 및 응답 생성 함수"""globalreferencereference=[]# 초기 검색 수행docs_with_scores=vectorstore.similarity_search_with_score(query,k=10)# Reranking 및 점수 저장 (중복 제거 포함)unique_docs=set()reranked_docs=[]fordoc, vector_scoreindocs_with_scores:ifdoc.page_contentnotinunique_docs:rerank_score=reranker.score([query, doc.page_content])reranked_docs.append({'document': doc,'vector_score': vector_score,'rerank_score': rerank_score})unique_docs.add(doc.page_content)# Rerank 점수로 정렬하고 상위 3개 선택top_docs=sorted(reranked_docs, key=lambdax: x['rerank_score'], reverse=True)[:3]# Reference 정보 저장reference.extend([{'distance':1-item['vector_score'],'relevance_score': item['rerank_score'],'source': item['document'].metadata['source'],'text': item['document'].page_content}foritemintop_docs])# RAG Chain 설정 및 실행# chat모델 정의llm=ChatClovaX(model="HCX-003",max_tokens=200)# ChatPromptTemplate 사용system_prompt=("""당신은 질문-답변(Question-Answering)을 수행하는 친절한 AI 어시스턴트입니다. 당신의 임무는 원래 가지고있는 지식은 모두 배제하고, 주어진 문맥(context) 에서 주어진 질문(question) 에 답하는 것입니다.검색된 다음 문맥(context) 을 사용하여 질문(question) 에 답하세요. 만약, 주어진 문맥(context) 에서 답을 찾을 수 없다면, 답을 모른다면 `주어진 정보에서 질문에 대한 정보를 찾을 수 없습니다` 라고 답하세요.""""\n\n""{context}")prompt=ChatPromptTemplate.from_messages([("system", system_prompt),("human","{input}"),])chain=create_stuff_documents_chain(llm, prompt)# 최종 응답 생성result=chain.invoke({"input": query,"context": [item['document']foritemintop_docs]})returnresult# 직접 result 반환답변을 생성할 때마다 reference에 참고한 문서, 문서의 링크, 유사도 점수, 거리가 함께 저장됩니다. 아래 코드를 통해 reference에 저장된 정보를 확인할 수 있습니다.
response=html_chat("Maximum tokens 파라미터는 몇으로 설정하는 게 좋을까? 최대값으로 설정했을 떄 무슨 문제가 있을 수 있지?")print(response,"\n")print("-"*10+"Reference"+"-"*10)# reference 확인forrefinreference:print(f"Source: {ref['source']}")print(f"Distance: {ref['distance']}")print(f"Relevance Score: {ref['relevance_score']}")print(f"Content: {ref['text'][:200]}...")# 처음 200자만 출력Maximum tokens는 결괏값을 생성할 때 사용할 최대 토큰 수입니다. 프롬프트와 결괏값을 포함하여 일반 모드에서 제공하는 언어 모델인 경우에는 최대 2048 토큰까지, 챗 모드에서 제공하는 HyperCLOVA X 언어 모델인 경우에는 최대 4096 토큰까지 허용됩니다. 일반적으로 Maximum tokens는 300~500을 권장하며 작업에 따라 달라질 수 있습니다. 그러나 이 값을 최대값으로 설정하면 여러 가지 문제가 발생할 수 있습니다. * **예상치 못한 과금**: 너무 길게 설정되면 그만큼 많은 자원이 소모되어 예상보다 많은 비용이 발생할 수 있습니다. * **처리 시간 증가**: 길어질수록 계산해야 하는 데이터 양이 많아지기 때문에 응답 속도가 느려질 수 있습니다. * **요청 미처리**: 이용량 제어 정책의 TPM 최대 이용량 초과로 이어질 수 있어 이로인한 요청 미처리가 더욱 빈번하게 발생할 수 있습니다. ----------Reference---------- Source: https://guide.ncloud-docs.com/docs/clovastudio-info Distance: 0.6760624051094055 Relevance Score: 0.9393323659896851 Content: Top KTop K는 자연어 처리 모델이 예측한 토큰의 선택 확률 분포에서 확률 값이 가장 높은 K개 중에서 하나를 선택할 때 사용하는 기준 값입니다.Top K는 특수한 경우가 아니라면 0으로 설정하는 것을 권장합니다.<예시> Top K=5인 경우, 가장 확률 값이 높은 5개의 토큰 중에서 하나의 토큰이 선택됩니다.이때, 가장 확률 값이 높은 토큰이 선택될... Source: https://guide.ncloud-docs.com/docs/clovastudio-info Distance: 0.6855939626693726 Relevance Score: 0.9207711219787598 Content: Maximum tokens가 실제 필요한 결괏값 토큰 수 대비 과도하게 설정될 경우, 불필요한 출력 길이로 인해 예상치 못한 과금이 발생하거나 처리 시간이 길어질 수 있습니다.... Source: https://guide.ncloud-docs.com/docs/clovastudio-info Distance: 0.6923664808273315 Relevance Score: 0.7897565960884094 Content: Maximum tokensMaximum tokens는 결괏값을 생성할 때 사용할 최대 토큰 수입니다.토큰 수를 높게 설정할 수록 긴 결괏값을 출력합니다....
- 기존 retrieval 과정에서는 사용자 질문과 관련도가 높은 10개의 chunk를 추출했습니다. 이후 reranking을 통해 이 중 relevance_score가 가장 높은 상위 3개의 chunk만을 선별하여 HyperCLOVA X에 전달합니다.
- 실행 화면 속 "reference"에서 relevance_score를 확인할 수 있습니다.
2) Summarization
요약은 retrieval 결과인 reference들의 내용을 압축하여 LLM이 근거 데이터를 쉽게 참고할 수 있게 돕습니다. 이는 Multi-query로 생성된 여러 질문들의 reference나 원본 질문만으로 구성된 naive RAG에서도 유용하며, 질문에 대한 근거의 맥락을 강화합니다. Reference가 복잡하거나 그 수가 많을 때, 요약을 통해 압축된 맥락을 전달하거나 부족한 설명을 보충할 수 있습니다. CLOVA Studio는 두 가지 요약 API를 제공하여 목적에 맞게 선택해 RAG의 정확도를 높일 수 있습니다. 이 cookbook에서는 긴 문장 요약에 강점이 있는 요약 v2 API를 활용했습니다.
요약 V2 함수 정의
이 코드는 주어진 쿼리로 검색된 결과물들의 참조 텍스트를 각각 요약하는 함수입니다. 중복된 텍스트는 건너뛰고, 각 텍스트는 설정된 크기로 분할되어 요약되며, 요약 실패 시 에러 처리를 하고 5초 후 다음 작업을 진행합니다. 이 함수는 단독으로 실행하지 않고, 뒤에 설명할 Multi-query 기능과 함께 실행할 예정입니다. 요약 v2 실행 결과, reference의 'text'를 요약한 내용을 'summary' 객체에 저장하고 final_references에 추가합니다.
defsummarize_each_ref(self, realquery):combined_results=self.retrieval(realquery)final_references=[]seen_texts=set()# 중복을 확인하기 위한 집합forresultincombined_results:forreferenceinresult['references']:ifreference['text']notinseen_texts:seen_texts.add(reference['text'])try:summary_request={"texts": [reference['text']],"autoSentenceSplitter":True,"segCount":-1,"segMaxSize":200,"segMinSize":50,"includeAiFilters":False}summarized_text=self.summarization_executor.execute(summary_request)ifsummarized_textisNoneor'Error'insummarized_text:raiseValueError("요약 실패")final_references.append({'query': result['query'],'text': reference['text'],'summary': summarized_text,'source': reference['source']})exceptException as e:print(f"요약 에러: {reference['text']}, 오류: {str(e)}")time.sleep(5)returnfinal_references- summarize_each_ref() 함수는 단독으로 실행되는 것이 아닌 다음 목차에서 설명될 Multi-query를 연계해서 만든 Multiquery(mq) 클래스에 속한 함수입니다. 따라서 아래의 실행 결과도 클래스에 속한 함수의 실행 결과이며 예제 코드의 들여쓰기도 클래스 내부에 있기 때문에 존재하는 것입니다.
- "summarization_executor"는 아래 목차의 Multiquery(mq)클래스에 정의되어 있습니다. 요약 v2 API의 파라미터 설정은 클로바스튜디오 내 익스플로러에 상세히 기재되어 있습니다.
3) Multi-Query
Multi-query는 사용자의 원래 질문 의미를 유지하면서 유사한 질문들을 생성하고, 각 질문에 대해 병렬적으로 retrieval을 수행합니다. 이후 모든 유사 query의 retrieval 결과를 종합하여 LLM에 전달하고, 원본 질문에 답변하도록 합니다. 이 방법은 데이터양이 방대하거나 질문이 복잡하고 모호한 경우, 단일 질문만으로는 사용자의 의도에 맞는 retrieval이 어려울 때 정확도를 높이기 위한 맥락 강화 기법입니다.
이번 cookbook에서는 비용 효율적이고 적절한 성능을 보장하는 HCX-DASH-001 모델을 Chat Completion API를 통해 multi-query 생성기로 활용하며, Langchain의 MultiQueryRetriever 컴포넌트를 활용해 구현합니다. MultiQuery Retriever는 사용자의 하나의 질문을 LLM이 여러 관점의 질문들로 자동 확장해주는 도구입니다. 각각의 확장된 질문에 대해 문서를 검색하고 그 결과들을 합쳐서, 더 포괄적이고 정확한 답변을 제공할 수 있게 해줍니다.Multi Query Retriever 정의
생성하고 싶은 질문의 개수는 프롬프트를 자유롭게 구성해 사용자가 직접 정할 수 있습니다. 본 예제에서는 system 프롬프트로 AI에게 paraphrasing 지침을 주고 다섯가지 버전의 질문을 생성하도록 했습니다. 또한 응답에서 각 질문을 리스트로 변환하기 쉽도록 줄바꿈으로 구분하도록 합니다.
Multiquery 생성 시스템 프롬프트 전문
주어진 사용자 질문의 다섯 가지 버전을 생성하는 AI입니다.
사용자의 질문을 paraphrasing해서 질문의 의도와 의미가 동일한 새로운 질문을 만들어냅니다.
질문 속 핵심 단어는 유지하고 조사나 수식어와 같은 부가적인 표현을 paraphrasing합니다.
응답은 새 줄로 구분된 값의 목록이어야 합니다(예: 'foo\nbar\nbaz\n'). #사용자 질문: {question}fromlangchain_core.runnablesimportRunnablePassthroughfromlangchain_core.promptsimportPromptTemplatefromlangchain_core.output_parsersimportStrOutputParser# 프롬프트 템플릿prompt=PromptTemplate.from_template("""주어진 사용자 질문의 다섯 가지 버전을 생성하는 AI입니다.사용자의 질문을 paraphrasing해서 질문의 의도와 의미가 동일한 새로운 질문을 만들어냅니다.질문 속 핵심 단어는 유지하고 조사나 수식어와 같은 부가적인 표현을 paraphrasing합니다.응답은 새 줄로 구분된 값의 목록이어야 합니다(예: 'foo\nbar\nbaz\n').#사용자 질문:{question}""")# chat 모델llm=ChatClovaX(model="HCX-DASH-001")# LLMChaincustom_multiquery_chain=({"question": RunnablePassthrough()} | prompt | llm | StrOutputParser())# 질문question="토큰이 뭔가요?"# 체인을 실행하여 생성된 다중 쿼리를 확인합니다.multi_queries=custom_multiquery_chain.invoke(question)# 파싱을 위한 처리queries_list=multi_queries.strip().split('\n')# 숫자와 점, 공백 제거queries_list=[q.split('. ',1)[1]if'. 'inqelseqforqinqueries_list]print(queries_list)위 코드를 실행하면, 아래와 같이 5개의 다른 질문을 리스트 형식으로 출력해 볼 수 있습니다.
['토큰이란 무엇인가요?', '용어로서의 토큰에 대해 알려주세요.', '토큰이라는 개념에 대해 설명해주세요.', '토큰 정의에 대해 알고 싶습니다.', '토큰의 뜻이 궁금합니다.']
Multiquery 클래스 정의
Multi-query module을 기반으로 생성된 여러 질문에 대한 retrieval 결과를 요약 v2나 reranker와 연계할 수 있도록 모든 모듈을 하나의 클래스에 통합했습니다.
이를 통해 필요한 module들을 선택적으로 조합하여 RAG를 구성할 수 있습니다. 클래스 내 주요 함수는 다음과 같습니다.-
multiquery_generator(): HCX-DASH-001을 활용해 원본 질문과 유사한 질문 생성 -
retrieval(): html_chat_raw를 기반으로 여러 유사 질문에 대해 개별 검색 수행 -
rerank_diff(): bge-m3 기반 reranker를 사용해 retrieval 결과 재정렬 -
summarize_each_ref(): 요약 v2 API를 사용해 reference 요약 -
answer(): Chat Completion API를 활용해 여러 모듈의 결과를 참고하여 최종 답변 생성
fromlangchain_core.runnablesimportRunnablePassthroughfromlangchain_core.promptsimportPromptTemplate, ChatPromptTemplatefromlangchain_core.output_parsersimportStrOutputParserfromlangchain.chainsimportcreate_retrieval_chainfromlangchain.chains.combine_documentsimportcreate_stuff_documents_chainfromlangchain_community.chat_modelsimportChatClovaXfromlangchain_core.documentsimportDocumentimporttimefromtypingimportList,Dict,Any, OptionalclassMultiqueryRetrieval:def__init__(self,vectorstore,reranker,summarization_executor,multiquery_model:str="HCX-DASH-001",answer_model:str="HCX-003") :self.vectorstore=vectorstoreself.reranker=rerankerself.summarization_executor=summarization_executorself.multiquery_model=multiquery_modelself.answer_model=answer_modeldefmultiquery_generator(self, question:str)->List[str]:"""원본 질문으로부터 다중 쿼리를 생성합니다."""prompt=PromptTemplate.from_template("""주어진 사용자 질문의 세가지 버전을 생성하는 AI입니다.사용자의 질문을 paraphrasing해서 질문의 의도와 의미가 동일한 새로운 질문을 만들어냅니다.질문 속 핵심 단어는 유지하고 조사나 수식어와 같은 부가적인 표현을 paraphrasing합니다.응답은 새 줄로 구분된 값의 목록이어야 합니다(예: 'foo\\nbar\\nbaz\\n').#사용자 질문:{question}""")llm=ChatClovaX(model=self.multiquery_model)# LLMChain 생성custom_multiquery_chain=({"question": RunnablePassthrough()} | prompt | llm | StrOutputParser())# 체인 실행multi_queries=custom_multiquery_chain.invoke(question)# 결과 파싱queries_list=multi_queries.strip().split('\n')# 숫자와 점, 공백 제거queries_list=[q.split('. ',1)[1]if'. 'inqelseqforqinqueries_list]returnqueries_listdefhtml_chat_raw(self, realquery:str, k:int=10) :"""단일 쿼리에 대한 검색을 수행합니다."""# 초기 검색 수행docs_with_scores=self.vectorstore.similarity_search_with_score(realquery,k=k)# Reranking 및 점수 저장reranked_docs=[]fordoc, vector_scoreindocs_with_scores:rerank_score=self.reranker.score([realquery, doc.page_content])reranked_docs.append({'document': doc,'vector_score': vector_score,'rerank_score': rerank_score})# Rerank 점수로 정렬하고 상위 3개 선택top_docs=sorted(reranked_docs, key=lambdax: x['rerank_score'], reverse=True)[:3]# Reference 정보 반환references=[{'distance':1-item['vector_score'],'relevance_score': item['rerank_score'],'source': item['document'].metadata['source'],'text': item['document'].page_content}foritemintop_docs]returnreferencesdefretrieval(self, realquery:str)->List[Dict]:"""각 쿼리에 대한 검색을 수행합니다."""similar_queries=self.multiquery_generator(realquery)all_results=[]forqueryinsimilar_queries:references=self.html_chat_raw(query)all_results.append({'query': query,'references': references})returnall_resultsdefrerank_diff(self, realquery:str, combined_results:List[Dict])->List[Dict]:"""중복을 제거하는 reranking을 수행합니다."""all_references=[]forresultincombined_results:all_references.extend(result['references'])forreferenceinall_references:score=self.reranker.score([realquery, reference['text']])reference['relevance_score']=scoresorted_references=sorted(all_references,key=lambdax: x['relevance_score'],reverse=True)final_references=[]added_texts=set()forreferenceinsorted_references:ifreference['text']notinadded_texts:final_references.append(reference)added_texts.add(reference['text'])iflen(final_references)==3:breakreturnfinal_referencesdefsummarize_each_ref(self, realquery:str)->List[Dict]:"""중복이 제거된 참조 문서들을 요약합니다."""combined_results=self.retrieval(realquery)final_references=[]seen_texts=set()forresultincombined_results:forreferenceinresult['references']:ifreference['text']notinseen_texts:seen_texts.add(reference['text'])try:# API 스펙에 맞게 요청 데이터 구성summary_request={"texts": [reference['text']],# texts는 배열이어야 함"autoSentenceSplitter":True,"segCount":-1}summarized_text=self.summarization_executor.execute(summary_request)ifsummarized_textisNone:raiseValueError("요약 실패")final_references.append({'query': result['query'],'text': reference['text'],'summary': summarized_text,'source': reference['source']})exceptException as e:print(f"요약 에러: {reference['text']}, 오류: {str(e)}")time.sleep(5)returnfinal_referencesdefanswer(self, realquery:str, final_references:List[Dict])->str:"""최종 답변을 생성합니다."""# chat 모델 정의llm=ChatClovaX(model=self.answer_model)# ChatPromptTemplate 사용system_prompt="""당신은 질문-답변(Question-Answering)을 수행하는 친절한 AI 어시스턴트입니다.당신의 임무는 원래 가지고있는 지식은 모두 배제하고, 주어진 문맥(context)에서 주어진 질문(question)에 답하는 것입니다.검색된 다음 문맥(context)을 사용하여 질문(question)에 답하세요.만약, 주어진 문맥(context)에서 답을 찾을 수 없다면, '주어진 정보에서 질문에 대한 정보를 찾을 수 없습니다'라고 답하세요.\n\n{context}"""prompt=ChatPromptTemplate.from_messages([("system", system_prompt),("human","{input}")])# Chain 생성chain=create_stuff_documents_chain(llm, prompt)# Document 객체 생성을 위한 컨텍스트 준비context_docs=[Document(page_content=ref.get('summary', ref['text']),metadata={'source': ref['source']})forrefinfinal_references]# 최종 응답 생성result=chain.invoke({"input": realquery,"context": context_docs})returnresult['answer']ifisinstance(result,dict)elseresult8. Module 실행 예시
앞서 Multiquery 클래스를 통해 정의한 유사 질문 생성, 요약, reranking 모듈들을 엮어서 어떻게 활용할 수 있는지 예시를 통해 살펴보겠습니다.
1) Multi-query 생성 → bge-m3 reranker → 답변
- retrieval()을 통해 realquery에 대한 유사 질문들을 생성하고 이에 대한 개별 retrieval을 진행
- 각 유사 질문에 대한 reference를 realquery에 대해 bge-m3 기반 reranking 진행
-
최종적으로 답변 생성
# 초기화mq=MultiqueryRetrieval(vectorstore=vectorstore,reranker=HuggingFaceCrossEncoder(model_name='BAAI/bge-reranker-v2-m3'),summarization_executor=SummarizationExecutor(host='clovastudio.apigw.ntruss.com'))# 실행query="클로바 스튜디오와 랭체인을 연동하여 사용할 수 있나요?"combined_results=mq.retrieval(query)final_references=mq.rerank_diff(query, combined_results)final_answer=mq.answer(query, final_references)print(final_answer)print("-"*10+"Reference"+"-"*10)forreferenceinfinal_references:print(f"Source: {reference['source']}")print(f"Content: {reference['text']}")네, CLOVA Studio의 HyperCLOVA X 모델과 임베딩 도구를 손쉽게 연동하여 사용하기 위해 LangChain을 활용할 수 있습니다. LangChain은 언어 모델 기반 애플리케이션 개발을 지원하는 오픈소스 프레임워크로, HyperCLOVA X를 포함한 여러 언어 모델과 벡터 데이터베이스, 검색 엔진 등의 여러 도구를 사슬(Chain)처럼 엮어 연결할 수 있어 기능 간 연결 및 통합 개발 과정을 간소화할 수 있습니다.
Quote----------Reference----------Source: https://guide.ncloud-docs.com/docs/clovastudio-dev-langchainContent: LangChain 연동인쇄공유PDF기사 요약이 요약이 도움이 되었나요?의견을 보내 주셔서 감사합니다.Classic/VPC 환경에서 이용 가능합니다.CLOVA Studio의 HyperCLOVA X 모델과 임베딩 도구를 손쉽게 연동하여 사용하기 위해 LangChain을 활용할 수 있습니다.LangChain은 언어 모델 기반 애플리케이션 개발을 지원하는 오픈소스 프레임워크입니다.HyperCLOVA X를 포함한 여러 언어 모델과 벡터 데이터베이스, 검색 엔진 등의 여러 도구를 사슬(Chain)처럼 엮어 연결할 수 있어 기능 간 연결 및 통합 개발 과정을 간소화할 수 있습니다.따라서 CLOVA Studio를 서드 파티 모델 및 도구와 함께 이용할 경우, LangChain을 연동하여 좀 더 간편한 애플리케이션 개발이 가능합니다.LangChain 연동 가이드에서는 LangChain 설치 방법과 CLOVA Studio 연동 설정 방법을 설명합니다.또한 LangChain을 통해 CLOVA Studio의 HyperCLOVA X 모델과 임베딩 도구를 이용하는 예제 코드를 제공하여 실제 개발에 참고할 수 있도록 안내합니다.참고LangChain은 Python 또는 JavaScript 및 TypeScript 언어로 구현되어 있습니다.CLOVA Studio에서는 Python 기반의 LangChain을 지원하며, 이 가이드 역시 Python을 기준으로 설명합니다.LangChain은 LangChain Inc.의 상표입니다.상표의 권리는 LangChain Inc.에 있습니다.네이버클라우드는 이 가이드에서 참조 목적으로만 사용하며, 이는 LangChain과 네이버클라우드 간 후원, 보증, 제휴를 의미하지 않습니다.LangChain은 오픈 소스 소프트웨어로서 네이버클라우드는 LangChain의 품질, 성능을 보증하거나 책임지지 않습니다.LangChain에 대한 자세한 설명은 공식 문서를 참조해 주십시오.LangChain 설치 및 확인Source: https://guide.ncloud-docs.com/docs/clovastudio-dev-langchainContent: CLOVA Studio에 연동하여 LangChain을 사용하려면 버전3.9이상의 Python 설치가 필요합니다.Python 설치를 완료한 후에는 다음 명령어를 사용하여 LangChain을 설치한 후 연동에 필요한 langchain-community 패키지를 설치해 주십시오.pip install langchain # install LangChainpip install langchain-community # install langchain-communitypackage설치되어 있는 LangChain이 CLOVA Studio와 연동 가능한 버전인지 확인하려면 다음 명령어를 사용해 주십시오.pip show langchain-community버전 확인 결과 langchain-community 패키지 버전이0.3.3이하인 경우에는 다음과 같이 연동 가능한 LangChain 버전을 명시하여 설치하는 것이 필요할 수 있습니다.pip install langchain-community~=0.3.4연동 범위 확인LangChain을 통해 이용 가능한 CLOVA Studio의 기능은 다음과 같습니다.CLOVA Studio 플레이그라운드 메뉴의 챗 모드 모델모델: 기본 모델(<예시> HCX-003), 기본 모델을 튜닝한 모델연관 API: Chat Completions연동 예제: HyperCLOVA X 모델 이용Source: https://guide.ncloud-docs.com/docs/clovastudio-dev-langchainContent: single_vector = embeddings.embed_query(query)embed_documentstext1 ="CLOVA Studio는 HyperCLOVA X 언어 모델을 활용하여 AI 서비스를 손쉽게 만들 수 있는 개발 도구입니다."text2 ="LangChain은 언어 모델 기반 애플리케이션 개발을 지원하는 오픈소스 프레임워크입니다."document = [text1, text2]multiple_vector = embeddings.embed_documents(document)참고LangChain을 통해 CLOVA Studio의 임베딩(임베딩 v2) 도구를 이용하는 방법에 대한 자세한 설명은 공식 문서를 참조해 주십시오.(이하 중략)
2) Multi-query 생성 → 요약 → 답변- summarize_each_ref()를 통해 realquery에 대한 유사 질문들을 생성, 개별 retrieval 진행 후 각 retrieval 내용 요약
- 'summary'가 추가된 final_references를 바탕으로 답변 생성
# 초기화mq=MultiqueryRetrieval(vectorstore=vectorstore,reranker=HuggingFaceCrossEncoder(model_name='BAAI/bge-reranker-v2-m3'),summarization_executor=SummarizationExecutor(host='clovastudio.apigw.ntruss.com'))# 실행query="클로바 스튜디오와 랭체인을 연동하여 사용할 수 있나요?"combined_results=mq.retrieval(query)final_references=mq.rerank_diff(query, combined_results)final_answer=mq.answer(query, final_references)print(final_answer)print("-"*10+"Reference"+"-"*10)forreferenceinfinal_references:print(f"Source: {reference['source']}")print(f"Content: {reference['text']}")네, CLOVA Studio의 HyperCLOVA X 모델과 임베딩 도구를 손쉽게 연동하여 사용하기 위해 LangChain을 활용할 수 있습니다. LangChain은 언어 모델 기반 애플리케이션 개발을 지원하는 오픈소스 프레임워크로, CLOVA Studio를 서드 파티 모델 및 도구와 함께 이용 할 경우 LangChain을 연동하여 좀 더 간편한 애플리케이션 개발이 가능합니다.
Quote----------Reference----------Source: https://guide.ncloud-docs.com/docs/clovastudio-dev-langchainContent: LangChain 연동인쇄공유PDF기사 요약이 요약이 도움이 되었나요?의견을 보내 주셔서 감사합니다.Classic/VPC 환경에서 이용 가능합니다.CLOVA Studio의 HyperCLOVA X 모델과 임베딩 도구를 손쉽게 연동하여 사용하기 위해 LangChain을 활용할 수 있습니다.LangChain은 언어 모델 기반 애플리케이션 개발을 지원하는 오픈소스 프레임워크입니다.HyperCLOVA X를 포함한 여러 언어 모델과 벡터 데이터베이스, 검색 엔진 등의 여러 도구를 사슬(Chain)처럼 엮어 연결할 수 있어 기능 간 연결 및 통합 개발 과정을 간소화할 수 있습니다.따라서 CLOVA Studio를 서드 파티 모델 및 도구와 함께 이용할 경우, LangChain을 연동하여 좀 더 간편한 애플리케이션 개발이 가능합니다.LangChain 연동 가이드에서는 LangChain 설치 방법과 CLOVA Studio 연동 설정 방법을 설명합니다.또한 LangChain을 통해 CLOVA Studio의 HyperCLOVA X 모델과 임베딩 도구를 이용하는 예제 코드를 제공하여 실제 개발에 참고할 수 있도록 안내합니다.참고LangChain은 Python 또는 JavaScript 및 TypeScript 언어로 구현되어 있습니다.CLOVA Studio에서는 Python 기반의 LangChain을 지원하며, 이 가이드 역시 Python을 기준으로 설명합니다.LangChain은 LangChain Inc.의 상표입니다.상표의 권리는 LangChain Inc.에 있습니다.네이버클라우드는 이 가이드에서 참조 목적으로만 사용하며, 이는 LangChain과 네이버클라우드 간 후원, 보증, 제휴를 의미하지 않습니다.LangChain은 오픈 소스 소프트웨어로서 네이버클라우드는 LangChain의 품질, 성능을 보증하거나 책임지지 않습니다.LangChain에 대한 자세한 설명은 공식 문서를 참조해 주십시오.LangChain 설치 및 확인Source: https://guide.ncloud-docs.com/docs/clovastudio-dev-langchainContent: CLOVA Studio에 연동하여 LangChain을 사용하려면 버전3.9이상의 Python 설치가 필요합니다.Python 설치를 완료한 후에는 다음 명령어를 사용하여 LangChain을 설치한 후 연동에 필요한 langchain-community 패키지를 설치해 주십시오.pip install langchain # install LangChainpip install langchain-community # install langchain-communitypackage설치되어 있는 LangChain이 CLOVA Studio와 연동 가능한 버전인지 확인하려면 다음 명령어를 사용해 주십시오.pip show langchain-community버전 확인 결과 langchain-community 패키지 버전이0.3.3이하인 경우에는 다음과 같이 연동 가능한 LangChain 버전을 명시하여 설치하는 것이 필요할 수 있습니다.pip install langchain-community~=0.3.4연동 범위 확인LangChain을 통해 이용 가능한 CLOVA Studio의 기능은 다음과 같습니다.CLOVA Studio 플레이그라운드 메뉴의 챗 모드 모델모델: 기본 모델(<예시> HCX-003), 기본 모델을 튜닝한 모델연관 API: Chat Completions연동 예제: HyperCLOVA X 모델 이용Source: https://guide.ncloud-docs.com/docs/clovastudio-dev-langchainContent: single_vector = embeddings.embed_query(query)embed_documentstext1 ="CLOVA Studio는 HyperCLOVA X 언어 모델을 활용하여 AI 서비스를 손쉽게 만들 수 있는 개발 도구입니다."text2 ="LangChain은 언어 모델 기반 애플리케이션 개발을 지원하는 오픈소스 프레임워크입니다."document = [text1, text2]multiple_vector = embeddings.embed_documents(document)참고LangChain을 통해 CLOVA Studio의 임베딩(임베딩 v2) 도구를 이용하는 방법에 대한 자세한 설명은 공식 문서를 참조해 주십시오.(이하 중략)9. 맺음말
기존의 cookbook이 CLOVA Studio를 활용한 기본적인 naive RAG 구현에 초점을 맞췄다면, 이번 cookbook은 CLOVA Studio의 신규 API들과 오픈소스를 이용한 Advanced RAG 구현법을 안내합니다. 각 API로 개발된 기능들을 모듈화하여 필요에 따라 선별적으로 활용함으로써, 용도에 부합하는 효과적인 RAG 시스템을 구성할 수 있습니다. 본 cookbook에서는 기초적인 모듈들만 다루었지만, RAG의 성능을 끌어올리기 위한 보다 복잡하고 다채로운 방법론들이 활발히 연구되고 있다는 점을 참고해 주시기 바랍니다.
- NCP 가이드: https://guide.ncloud-docs.com/docs/clovastudio-dev-langchain
- LangChain 공식 문서: https://python.langchain.com/docs/integrations/providers/naver/
-
1
-
파인 튜닝은 언제 활용하는가?
프롬프트 엔지니어링은 AI 모델의 성능을 향상시키는 효과적인 방법이지만, 그 한계에 도달할 때가 있습니다. 이때 유용한 대안이 바로 튜닝입니다. 튜닝은 프롬프트 엔지니어링만으로는 성능 향상이 어려운 정체 구간에서 추가적인 성능 개선을 가능하게 합니다.
튜닝의 장점 중 하나는 사용자가 보유한 고유 데이터를 활용하여 특정 작업에 특화된 모델을 만들 수 있다는 것입니다. 예를 들어, 고객의 문의를 분류하는 작업에서 100건의 테스트셋으로 프롬프트 최적화를 수행했지만, 정답률이 73%에 머물러 있었습니다. 또한, AI의 출력이 불필요한 문장이나 부가적인 설명을 포함하는 경우가 여전히 존재했습니다. 이러한 상황에서 파인튜닝은 모델의 성능을 향상시키고, 출력의 일관성을 개선하는 데 효과적인 방법입니다.
튜닝 전 오답 예시
UserCompletion실제 정답이전에 계정 만들었다가 지우고 다시 네이버 밴드 새로 계정 만들려고 하는데, 계정 만들고 지웠다가 다시 가입이 안되나요? 정답은 '네이버밴드 오류해결'입니다. 네이버밴드 계정
이러한 상황에서, 고객 문의 분류 작업을 예로 들어 튜닝을 통한 성능 향상 방법을 살펴보겠습니다. 우리의 목표는 카테고리 분류의 정확도를 높이고, AI가 '카테고리명'만을 출력하도록 만드는 것입니다. 이를 위해 다음과 같은 단계로 튜닝을 진행해 보겠습니다.Step 1. 데이터셋 준비
튜닝을 효과적으로 수행하기 위해서는 충분한 양의 고품질 데이터가 필요합니다. 하이퍼클로바X의 경우, 일반적으로 400개 이상의 데이터셋이 권장됩니다. 이는 작업의 성격과 도메인(예: 의료, 법률, 경제, 마케팅 등)에 따라 다소 차이가 있을 수 있습니다.
HCX-003 모델 인퍼런스 시 결과가 잘 나오지 않던 항목을
400개 이상의 데이터셋으로 튜닝했을 때 오류 발생 확률이 크게 감소하는 것을 확인했습니다. (작업에 따라 달라질 수 있습니다.)1. 학습시킬 데이터 수집하기
튜닝 학습을 시작하기 전, 다양한 고객 문의와 그에 맞는 카테고리 분류 데이터를 모아야 합니다. 이때 데이터 전처리가 중요한데, 이는 오타 수정, 표기 교정, 데이터 정제 및 구조화 등을 포함하는 작업입니다. 효과적인 학습 시스템 구축을 위해 필수적인 단계로, 전처리가 필요한 데이터 예시를 들면 다음과 같습니다.
데이터 전처리 과정에서는 잘못된 카테고리로 라벨링된 데이터를 올바른 카테고리로 수정하고, 의도와 의미를 판별하기 어려운 데이터는 제거하는 것이 좋습니다. 모델의 성능 향상을 위해 특수 문자와 이모티콘 제거, 축약어 및 인터넷 용어의 표준어 처리 등의 추가적인 전처리 작업도 고려할 수 있습니다.
전처리 유형text잘못된 completion올바른 completion잘못된 라벨링 네이버 드라이브 사용 금액 알려주세요. 네이버플러스멤버십 오류 해결 MYBOX 가격 전처리 유형text판별불가 ㅇㅋㄷㅋ111 판별불가 !!bjaowjd@@ 위와 같이 의도와 의미를 판별하기 어려운 데이터는 제거해주어야합니다. 그 외에도 모델의 성능을 높이기 위해, 특수 문자 및 이모티콘 제거, 축약어 및 인터넷 용어 표준어 처리 등의 작업도 고려할 수 있을 것입니다.
이러한 전처리 과정을 거쳐, 네이버 고객센터의 고객 문의 데이터를 기반으로 1000개의 학습 데이터셋을 구성했습니다. 이 데이터셋은 다음과 같은 구조를 가집니다.
- Text 열: 다양한 고객 문의 예제를 포함합니다. MYBOX, 네이버플러스멤버십, 네이버 밴드 등 15개의 카테고리에 걸쳐 실제 사용자의 문의를 반영하기 위해 비문도 포함될 수 있습니다.
- Completion 열: 각 고객 문의에 대한 정확한 카테고리 분류를 포함합니다. 분류 태스크의 성공을 위해 이 부분의 정확성은 매우 중요합니다.
이렇게 구성된 데이터셋의 예시는 다음과 같습니다.
C_IDT_IDTextCompletion1 0 네이버플러스멤버십 한달에 내는 요금이 얼마고 멤버십은 따로 어플 설치해서 이용하는건가요? 네이버플러스멤버십 가격 2 0 핸드폰 해킹 당해서 드라이브에 사진 백업해두려고 하는데 앱을 깔아야지 백업 가능한가요?
백업하는 법 좀 알려주세요MYBOX 보안 및 해킹 3 0 네이버 밴드 계정을 찾을려면 어케해야되나요 네이버밴드 계정 4 0 최근에 멤버십이 7월26일에 4900원이 결제 된다는데 이거 무슨 소리이죠?
네이버플러스멤버십 결제 학습 데이터는 양보다도 질이 중요합니다. 수집한 데이터의 정답(completion)이 올바르게 부여되어있는지 사전에 꼼꼼히 체크하면 도움이 됩니다.
2. 데이터셋 파일 만들기- 파일 형식 : .json 혹은 .csv 파일로 준비해주세요.
- System_Prompt(선택) : 시스템 프롬프트를 함께 학습시킨다면, 가장 첫 열에 추가해야 합니다. 저희는 최적화한 시스템 프롬프트를 함께 데이터셋에 추가해 학습시켜보았습니다.
- C_ID : 한 개가 대화 데이터 한 건을 의미하며, 0부터 시작해 하나씩 늘어납니다.
- T_ID : User & Assistant의 발화 페어 한 건을 의미하며, 0부터 시작해 하나씩 늘어납니다. 저희의 경우, '분류' 태스크이기 때문에 여러 대화 턴 예제는 필요 없습니다. User와 Assistant의 발화 페어가 필요하지 않으므로, T_ID는 모두 0으로 설정해 데이터셋을 만들었습니다.
System_PromptC_IDT_IDTextCompletion<system prompt가 있는 경우 삽입> 0 0 네이버플러스멤버십 한달에 내는 요금이 얼마고 멤버십은 따로 어플 설치해서 이용하는건가요? 네이버플러스멤버십 가격 <system prompt가 있는 경우 삽입> 1 0 핸드폰 해킹 당해서 드라이브에 사진 백업해두려고 하는데 앱을 깔아야지 백업 가능한가요? 백업하는 법 좀 알려주세요 MYBOX 보안 및 해킹 <system prompt가 있는 경우 삽입>
2 0 네이버 밴드 계정을 찾을려면 어케해야되나요 네이버밴드 계정 <system prompt가 있는 경우 삽입> 3 0 최근에 멤버십이 7월26일에 4900원이 결제 된다는데 이거 무슨 소리이죠? 네이버플러스멤버십 결제 데이터셋에 대한 자세한 설명은 데이터셋 준비 가이드를 참고해보세요.
Step 2. AI 모델 튜닝하기
1. 하이퍼파라미터 설정하기
- epochs : 전체 데이터셋을 반복 학습하는 횟수를 지정합니다. 예를 들어, 4에서 8로 증가시키면 모델의 학습량이 늘어나 loss가 감소할 수 있습니다. 하지만, 과도한 epochs 설정은 과적합(overfitting)을 유발할 수 있으므로 주의해야 합니다. 고객 문의 분류 작업의 경우, 8 epochs가 적절합니다.
- model : 튜닝에 사용할 모델을 선택합니다. 분류 작업에는 HCX-DASH-001 모델이 적합합니다.
- tasktype : 작업 유형을 지정합니다. 분류 작업이므로 classification을 선택합니다.
2. 학습생성API 코드 작성 후 실행하기
아래와 같이 python 코드를 작성했습니다. 여러분도 태스크 작업에 따라 적절하게 파라미터를 수정해 코드를 작성해보세요.
학습 생성 코드 보기
# -*- coding: utf-8 -*-importbase64importhashlibimporthmacimportrequestsimporttimeclassCreateTaskExecutor:def__init__(self, host, uri, method, iam_access_key, secret_key, request_id):self._host=hostself._uri=uriself._method=methodself._api_gw_time=str(int(time.time()*1000))self._iam_access_key=iam_access_keyself._secret_key=secret_keyself._request_id=request_iddef_make_signature(self) :secret_key=bytes(self._secret_key,'UTF-8')message=self._method+" "+self._uri+"\n"+self._api_gw_time+"\n"+self._iam_access_keymessage=bytes(message,'UTF-8')signing_key=base64.b64encode(hmac.new(secret_key, message, digestmod=hashlib.sha256).digest())returnsigning_keydef_send_request(self, create_request):headers={'X-NCP-APIGW-TIMESTAMP':self._api_gw_time,'X-NCP-IAM-ACCESS-KEY':self._iam_access_key,'X-NCP-APIGW-SIGNATURE-V2':self._make_signature(),'X-NCP-CLOVASTUDIO-REQUEST-ID':self._request_id}result=requests.post(self._host+self._uri, json=create_request, headers=headers).json()returnresultdefexecute(self, create_request):res=self._send_request(create_request)if'status'inresandres['status']['code']=='20000':returnres['result']else:returnresif__name__=='__main__':create_task_executor=CreateTaskExecutor(uri='/tuning/v2/tasks',method='POST',iam_access_key='<your_iam_access_key>',secret_key='<your_secret_key>',request_id='<unique_request_id>')request_data={'name':'example_tuning_task','model':'HCX-003','taskType':'CLASSIFICATION','trainEpochs':8,'learningRate':1e-5,'trainingDatasetBucket':'bucket_name','trainingDatasetFilePath':'path/to/dataset/file.json','trainingDatasetAccessKey':'<dataset_access_key>','trainingDatasetSecretKey':'<dataset_secret_key>'}response=create_task_executor.execute(request_data)print(request_data)print(response)튜닝 API 사용은 학습 생성 가이드를 참고해보세요.
3. 튜닝 완료된 모델 확인하기
'클로바 스튜디오 > 내 작업 > 튜닝' 경로에서 아래 이미지와 같이 튜닝 모델의 작업 상태와 예상 소요 시간을 확인할 수 있습니다.
'튜닝 완료된 작업 선택> 코드 보기' 경로에서 아래 이미지와 같이 튜닝한 모델의 task id를 확인하세요.
Step 3. 결과 인퍼런스하기
1. 플레이그라운드에서 인퍼런스하기
① 엔진을 튜닝한 모델로 선택
'플레이그라운드 > 불러오기'를 통해 튜닝한 모델을 선택합니다.② 테스트셋 데이터 중 하나를 입력
테스트셋 데이터 중, 튜닝하기 전에 계속 오류를 냈던 예제 하나를 선택해서 인퍼런스 테스트를 해보았습니다.
'MYBOX'를 고객이 '네이버 드라이브'로 말하는 바람에, 분류에 어려움을 겪었던 케이스입니다.③ 결과 확인
결과를 확인하니 분류 작업을 잘 수행했고, 결과물 형식도 원하는 형식으로 나오네요!User 네이버 드라이브에 사진을 모두 삭제하고 휴지통까지 삭제하였습니다다시 복구하고 싶은데 가능한가요?가능하다면 방법을 알고 싶습니다. Assistant MYBOX 데이터 관리
2. Chat Completion API로 테스트셋 인퍼런스하기
이제 테스트셋 100건에 대해 모두 인퍼런스해보겠습니다.
① 테스트셋 준비하기
튜닝이 잘 되었는지 확인하기 위해선 테스트할 데이터를 수집해야 합니다. 주의할 점은, 이 데이터가 튜닝할 때 사용한 데이터셋과 달라야 한다는 것입니다.
저희는 아래와 같이 평가 데이터 100개를 준비하여 평가를 진행했습니다.
② 인퍼런스 코드 실행하기
아래는 테스트셋 엑셀 파일로 대량의 테스트셋을 인퍼런스 돌리는 코드입니다. API key, 테스트셋 파일 경로, 완료 후 저장할 파일 경로, 튜닝한 모델의 task id를 변경해 코드를 실행해보세요.Chat Completion 인퍼런스 코드 보기
importrequestsimportpandas as pdimporttime# API Key 정보 설정CLOVA_API_KEY='{CLOVA Studio API Key}'# CLOVA Studio API KeyAPIGW_API_KEY='{API Gateway API Key}'# API Gateway API KeyREQUEST_ID='{Request ID}'# Unique request identifierMODEL_PARAMETERS={"topP":0.8,"topK":0,"maxTokens":256,"temperature":0.5,"repeatPenalty":5.0,"includeAiFilters":True,"stopBefore": [],}INPUT_FILENAME="{테스트셋 파일 경로}"# .xlsx 파일OUTPUT_FILENAME="{인퍼런스 완료 후 저장할 파일 경로}"# .xlsx 파일defsend_requests(system:str, user:str) :url="https://clovastudio.stream.ntruss.com/v2/tasks/{taskId}/chat-completions"# taskId는 사용자의 작업 ID로 대체headers={"X-NCP-CLOVASTUDIO-API-KEY": CLOVA_API_KEY,"X-NCP-APIGW-API-KEY": APIGW_API_KEY,"X-NCP-CLOVASTUDIO-REQUEST-ID": REQUEST_ID,"Content-Type":"application/json","Accept":"application/json",}body=MODEL_PARAMETERS.copy()body["messages"]=[{"role":"system","content": system},{"role":"user","content": user},]response=requests.post(url=url, json=body, headers=headers)result=response.json()if"result"inresult:print(result["result"])returnresult["result"]["message"]else:print("Error:", result)return{"role":"error","content":"Error in API response"}if__name__=='__main__':# Input 데이터 읽기df=pd.read_excel(INPUT_FILENAME)results_role=[]results_content=[]foriindf.itertuples():# 시스템 메시지와 사용자 메시지를 입력으로 전달result=send_requests(i.system, i.user)results_role.append(result['role'])results_content.append(result['content'])# 결과를 DataFrame에 추가df.insert(2,"role", results_role,True)df.insert(3,"content", results_content,True)# 결과를 엑셀 파일로 저장df.to_excel(OUTPUT_FILENAME, index=False)Step 4. 평가하기
1. 정량 평가
평가 데이터의 정답과 모델 답변을 비교하면서, 맞으면 match 열에 1, 틀리면 0으로 점수를 매겨서 정확도를 계산합니다.
평가셋 100의 정답과 각 모델 답변이 일치하는 지에 대한 점수를 매긴 후, HCX-DASH-001과 HCX-003모델 각각의 학습 전후를 비교해보겠습니다.
튜닝 후, HCX-DASH-001과 HCX-003 모델 모두 성능이 크게 향상되었습니다. HCX-DASH-001의 경우, 초기 성능은 73점이었지만, 파인튜닝 후 97점으로 향상되었습니다. 반면, HCX-003 모델은 초기 성능이 83점이었지만, 파인튜닝 후 95점으로 개선되었습니다. 초기에는 더 큰 모델인 HCX-003이 HCX-DASH-001보다 높은 성능을 보였지만, 양질의 데이터로 학습된 후에는 더 작은 모델인 HCX-DASH-001이 HCX-003과 비슷하거나 더 나은 성능을 보였습니다. 이는 효과적인 파인튜닝이 모델 크기의 차이를 상쇄하고, 때로는 더 작은 모델이 특정 작업에 더 잘 최적화될 수 있음을 보여줍니다.
충분한 데이터를 가지고 있고 과금에 대한 고민이 있으시다면 작은 모델인 HCX-DASH-001로도 충분한 성능 개선을 기대해볼 수 있다는 점을 참고해주세요.
2. 정성 평가
이전에 오답으로 나왔던 같은 고객 문의에 대해 어떻게 답변하는지 확인해보았습니다. 튜닝 전과 달리, 원하는 형식대로 '카테고리명'만 출력했고, 카테고리 분류도 잘한 것을 확인할 수 있었습니다.
user튜닝 전 Completion튜닝 후 Completion정답이전에 계정 만들었다가 지우고 다시 네이버 밴드 새로 계정 만들려고 하는데, 계정 만들고 지웠다가 다시 가입이 안되나요? 정답은 '네이버밴드 오류해결'입니다. 네이버밴드 계정 네이버밴드 계정 튜닝은 AI 모델을 사용자와 과제에 맞게 최적화 시킬 수 있는 방법입니다. 이는 정체된 성능을 한 단계 끌어올리고, 원하는 형식으로 결과를 일관되게 출력하는 데 매우 효과적입니다. 앞서 설명드린 단계와 사례를 참고하여, 여러분의 프로젝트에서도 튜닝을 적극 활용해 보세요. 적절한 데이터셋 구성과 체계적인 프로세스를 통해 최고의 결과를 도출할 수 있을 것입니다. 더 나은 성능과 높은 정확도를 향한 튜닝 여정, 지금 바로 시작해 보세요! 🚀
-
@eytg8e님, """당신은 ~~하는 ~입니다. 등의 내용""" 이 부분이 올바른 json 포맷이 아닙니다.
json 의 문자열 내 double quote를 사용하고자 하는 경우 적절한 escape 처리를 해야 할 것 같습니다.
감사합니다.
-
 1
1
-
-
들어가며
최근 Anthropic의 Claude와 OpenAI의 기능으로 공개된 Prompt Generator가 주목받고 있습니다. 이 기능들이 의미하는 바는 무엇일까요? 프롬프트 엔지니어링은 그동안 LLM을 효과적으로 활용하기 위한 핵심 기술로 인식되어 왔습니다. 이를 위해 다양한 노하우와 방법론이 공유되고, 그 중요성이 지속적으로 강조되어 왔습니다. 이러한 상황에서 Prompt Generator 기능이 본격적으로 등장했다는 것은, 프롬프트 엔지니어링 분야가 한 단계 더 발전할 수 있는 계기가 마련되었다는 것을 의미합니다.
수작업 프롬프트를 대체할 프레임워크
DSPy는 언어 모델 기반 애플리케이션 개발을 위한 파이썬 프레임워크로, 복잡한 프롬프트 엔지니어링 없이도 프로그래밍 중심의 접근 방식을 제공합니다. DSPy 논문1)과 DSPy 문서 에서 소개된 바와 같이, DSPy는 수행할 작업과 최적화할 지표를 정의하여 모델의 동작을 제어하고, 다양한 내장 모듈(CoT, self-reflection 등)을 통해 복잡한 파이프라인을 구성할 수 있습니다. 또한, 자동으로 프롬프트나 모델 가중치를 조정해 성능을 향상시킬 수 있습니다. DSPy는 수행할 작업과 최적화할 지표를 정의하여 모델의 동작을 손쉽게 제어할 수 있으며, CoT, self-reflection 등 다양한 내장 모듈을 통해 복잡한 파이프라인을 간편하게 구성할 수 있습니다. 또한, 자동으로 프롬프트나 모델 가중치를 조정하여 성능을 향상시키는 기능도 갖추고 있습니다.
1) Khattab, Omar, et al. 2023. "DSPY: Compiling Declarative Language Model Calls into Self-Improving Pipelines. Stanford University, UC Berkeley, and collaborators. https://arxiv.org/pdf/2310.03714
2) Stanford NLP. DSPY. GitHub repository, https://github.com/stanfordnlp/dspyDSPy의 구조적 접근
DSPy는 Signature를 활용하여 입출력 정의를 명확히 하고, 이를 Chain-of-Thought와 같은 모듈을 통해 실행합니다. Signature는 복잡한 모델 로직을 간단하게 정의할 수 있도록 도와주며, 작업의 명확성을 높이는 데 큰 역할을 합니다. Signature를 통해 각 단계의 역할을 명확히 구분하고, 이를 여러 모듈과 쉽게 연계할 수 있어 파이프라인 구축이 더욱 효율적입니다. 프로그래밍 중심의 접근 방식은 LLM 기반 애플리케이션의 구현 접근성을 높이고, 반복적인 프롬프트 작성의 부담을 줄여줍니다.
또한, LlamaIndex와 같은 프레임워크에서는 PromptTemplate 클래스를 사용해 구조화된 형식을 제공합니다. LlamaIndex 코드를 통해 일관되고 최적화된 출력을 보장하여 개발자들의 시간을 절약하고 오류 발생 가능성을 줄일 수 있습니다. PromptTemplate은 복잡한 입력 조건을 간단하게 정의하고, 다양한 시나리오에서 재사용 가능하도록 만들어 줍니다. 이를 통해 반복적인 프롬프트 작성의 부담이 줄어들고, LLM의 일관된 성능을 유지할 수 있습니다.
‘Automatic Prompt Optimization…’ 논문3)에서는 Gradient Descent와 Beam Search를 활용해 프롬프트 성능을 31%까지 향상시킨 사례를 소개합니다. 이처럼 자동화된 프롬프트 최적화는 수작업보다 더 좋은 결과를 가져올 수 있으며, 전반적으로 서비스 성능을 상향 평준화하는 데 기여할 수 있습니다.
3) Pryzant, Reid, Dan Iter, Jerry Li, Yin Tat Lee, Chenguang Zhu, and Michael Zeng. 2023. "Automatic Prompt Optimization with 'Gradient Descent' and Beam Search." October 19, Microsoft Azure AI. https://arxiv.org/pdf/2305.03495
Anthropic과 OpenAI가 Prompt Generator 기능을 제공하기 시작한 것은 LLM 활용 서비스 전체의 성능을 높여준다는 점에서 큰 의미가 있습니다. 앞으로 이러한 기능들이 DSPy와 결합된다면 더욱 강력한 애플리케이션 개발 프레임워크로 발전할 가능성이 높습니다. 결합을 통해 개발자들은 복잡한 LLM 작업을 간단한 코드 조각으로 표현할 수 있을 뿐만 아니라, 그 과정에서 모델의 성능도 자동으로 최적화할 수 있게 됩니다. 이는 LLM 기술의 보편화와 더불어 그 활용성을 극대화하는 방향으로 나아가는 것이며, 점차 많은 기업과 개발자들이 이러한 흐름을 따르게 될 것이죠.
- 프롬프트 엔지니어링 작업 시간 단축
- 프롬프트의 성능 최적화
- 전반적인 애플리케이션 성능의 향상
하이퍼클로바X로 실험하기
현재 클로바 스튜디오에서는 Prompt Generator 기능을 제공하고 있지 않지만, 이와 유사한 방식으로 자체 실험을 진행해 보았습니다. 사용자 요청과 구조화된 출력 데이터를 약 100개 제작하여 실험해 본 결과, HyperCLOVA X 모델로도 충분히 구조화된 응답을 생성할 수 있다는 가능성을 확인했습니다.
실험 과정에서는 수행할 작업을 명확히 설명하는 '지시문', 단계별 작업을 설명하는 '단계', 원하는 출력의 형식과 스타일을 명시한 '출력 형식', 그리고 참고할 만한 '예시'를 활용했습니다. 예를 들어, 고객 리뷰에 대한 답변을 자동으로 생성하는 경우, 단순한 요청 대신 구체적인 지시문과 예시를 통해 구조화된 출력을 얻어냈습니다.
- 지시문 : 수행할 작업을 명확히 설명
- 단계 : 단계별 작업을 설명
- 출력 형식 : 원하는 출력의 형식과 스타일을 명시
- 예시 : 참고할 만한 예시
고객 리뷰에 답변을 추가하는 서비스를 구현한다고 가정했을 때, "고객 리뷰에 답변을 추가합니다. 예제의 어투를 참고합니다. 이모티콘을 포함하세요."와 같은 두서없는 요청을 구조화하여, 구체적인 지시문과 예제를 포함한 형식으로 출력할 수 있습니다.
마치며
이와 같은 접근 방식은 LLM을 보다 효율적으로 활용할 수 있는 가능성을 열어주며, 향후 클로바 스튜디오의 에이전트 구현에도 적용할 수 있을 것입니다. 클로바 스튜디오는 앞으로도 에이전트 구현을 위한 다양한 기능을 제공할 예정이니 많은 관심과 기대 부탁드립니다.
-
1
-
본 가이드는 클로바 스튜디오(CLOVA Studio)와 랭체인(Langchain)을 이용해 RAG(Retrieval Augmented Generation; 검색 증강 생성) 시스템을 만드는 방법을 설명합니다.
- NCP 가이드: https://guide.ncloud-docs.com/docs/clovastudio-dev-langchain
- LangChain 공식 문서: https://python.langchain.com/docs/integrations/providers/naver/
RAG는 AI가 주어진 정보를 바탕으로 더 정확하고 관련성 높은 답변을 생성하도록 돕는 기술입니다. 이 예제에서 우리는 HTML 형식의 데이터(클로바 스튜디오 가이드)를 기반으로 질문에 대한 답변을 출력하는 RAG 시스템을 랭체인을 활용해 구현해보겠습니다. 구현하고자 하는 RAG 시스템의 구조도는 아래와 같습니다.
클로바 스튜디오의 HyperCLOVA X 모델 (챗 모드), 임베딩 API, 문단 나누기 API를 사용하며, 랭체인을 통해 아래와 같은 단계로 진행해 간단한 RAG 시스템을 구현해보겠습니다.
버전 정보
아래 예제 코드는 Python 3.12.4에서 실행 확인하였으며, 최소 Python3.9를 필요로 합니다.
아래 파일을 참고해 필요한 모듈을 모두 설치해줍니다.
requirements.txt1. 사전 준비
1) Langchain 패키지 설치
langchain-community >= 0.3.4부터 langchain_community 안에 ChatClovaX, ClovaXEmbeddings가 포함되었습니다. 랭체인은 아래 명령문을 통해 설치할 수 있습니다.
pip install langchainpip install langchain-community~=0.3.42) 참조할 문서 (HTML 데이터) 준비
본 예제에서는 네이버클라우드플랫폼(NCP)의 클로바 스튜디오 사용 가이드중 CLOVA Studio 개념, CLOVA Studio 시나리오 페이지를 HTML 데이터로 활용합니다. 참고할 웹사이트의 링크를 아래와 같이 txt 파일로 준비했으며, 해당 내용은 필요한 데이터에 맞게 수정되어도 무방합니다.
- (주의) txt파일을 작성할 때는 한 줄에 하나의 URL을 작성해야 합니다. 즉, 각 URL은 줄바꿈으로 구분되어야 합니다.
https://guide.ncloud-docs.com/docs/clovastudio-info https://guide.ncloud-docs.com/docs/clovastudio-procedure
3) 코드에 공통적으로 들어가는 필요 모듈 import
importjsonimportgetpassimportosfromtqdmimporttqdmimportrequestsimporttimeimportuuidfromuuidimportuuid4frompathlibimportPath4) 테스트앱 및 API키 미리 발급 받기
각 모듈 호출시 필요한 테스트앱 및 API키를 미리 발급받고 환경 변수로 저장해두세요.
Quote키 값 가져오는 방법 (클로바 스튜디오 앱 신청 현황 페이지)
1.API키, Gateway키 설정하기
테스트 앱을 이용하는 경우, API키와 Gateway키는 계정당 발급되기 때문에 어떤 테스트앱으로 발급받아도 키 값이 동일합니다.
본 예제에선 테스트 앱을 사용하므로 API 키와 Gateway 키를 사전 발급받아 정의해두고, 각 모듈 호출시 불러오겠습니다.단, 앱의 API Key/API GW Key가 전부 동일한 건 테스트앱만 해당됩니다. 서비스 앱을 이용하고자 할 경우 사전 설정이 아니라 개별 모듈 정의 시마다 해당 API Key를 입력해야합니다.
-
NCP_CLOVASTUDIO_API_KEY
-
NCP_APIGW_API_KEY
2.문단나누기 테스트 앱 발급받고, app_id 값을 설정하기
(ClovaStudio > 익스플로러 > 문단 나누기 > 테스트앱 발급)-
NCP_CLOVASTUDIO_APP_ID_SEGMENTATION
3. 임베딩V2 테스트앱 발급받고, app_id 값을 설정하기
(ClovaStudio > 익스플로러 > 임베딩V2 > 테스트앱 발급)
*임베딩 모델 emb,sts를 쓰는경우 V1으로 발급 받아야합니다.- NCP_CLOVASTUDIO_APP_ID
# API 키와 Gateway API 키를 넣습니다.os.environ["NCP_CLOVASTUDIO_API_KEY"]=getpass.getpass("NCP CLOVA Studio API Key: ")os.environ["NCP_APIGW_API_KEY"]=getpass.getpass("NCP API Gateway API Key: ")NCP CLOVA Studio API Key: ········ NCP API Gateway API Key: ········
# 문단나누기 테스트앱의 앱 ID를 넣습니다.os.environ["NCP_CLOVASTUDIO_APP_ID_SEGMENTATION"]=input("NCP CLOVA Studio Segmentation App ID: ")NCP CLOVA Studio Segmentation App ID: <your Segmentation App ID>
# 임베딩 테스트앱의 앱 ID를 넣습니다.os.environ["NCP_CLOVASTUDIO_APP_ID"]=input("NCP CLOVA Studio App ID: ")NCP CLOVA Studio App ID: <your App ID>
2. LoadRAG의 첫번째 작업은 추후 LLM이 응답의 문맥으로 사용할 때 RAG 시스템이 참고할 HTML 데이터를 준비하는 단계입니다. txt 파일(clovastudiourl.txt)에 사용하고 싶은 사이트 URL을 작성한 후, wget 라이브러리와 LangChain의 Document Loader 컴포넌트를 활용하여 HTML 데이터를 작업에 편한 형태로 변환했습니다. 또한, 로딩한 데이터 안에 사이트 URL을 넣어 추후 답변과 함께 사이트 주소가 출력되게 하여 질문한 사용자가 답변의 내용이 있는 실제 URL을 함께 참조할 수 있게 데이터를 수정했습니다.
1) txt → html 변환 및 원본 사이트 주소 mapping
importsubprocessurl_to_filename_map={}withopen("clovastudiourl.txt","r") asfile:urls=[url.strip()forurlinfile.readlines()]folder_path="clovastudioguide"ifnotos.path.exists(folder_path):os.makedirs(folder_path)forurlinurls:filename=url.split("/")[-1]+".html"file_path=os.path.join(folder_path, filename)subprocess.run(["wget","--user-agent=RAGCookbook-Crawler/1.0","-O", file_path, url], check=True)url_to_filename_map[url]=filenamewithopen("url_to_filename_map.json","w") as map_file:json.dump(url_to_filename_map, map_file)#Output --2024-08-26 13:37:02-- https://guide.ncloud-docs.com/docs/clovastudio-info Resolving guide.ncloud-docs.com (guide.ncloud-docs.com)... 104.18.6.159, 104.18.7.159 Connecting to guide.ncloud-docs.com (guide.ncloud-docs.com)|104.18.6.159|:443... connected. HTTP request sent, awaiting response... 200 OK Length: unspecified [text/html] Saving to: ‘clovastudioguide_0822/clovastudio-info.html’ 0K .......... .......... .......... .......... .......... 21.4M 50K .......... .......... .......... .......... 83.3M=0.003s 2024-08-26 13:37:02 (32.1 MB/s) - ‘clovastudioguide_0822/clovastudio-info.html’ saved [92957] --2024-08-26 13:37:02-- https://guide.ncloud-docs.com/docs/clovastudio-procedure Resolving guide.ncloud-docs.com (guide.ncloud-docs.com)... 104.18.6.159, 104.18.7.159 Connecting to guide.ncloud-docs.com (guide.ncloud-docs.com)|104.18.6.159|:443... connected. HTTP request sent, awaiting response... 200 OK Length: unspecified [text/html] Saving to: ‘clovastudioguide_0822/clovastudio-procedure.html’ 0K .......... .......... .......... .......... .......... 18.0M 50K .......... .......... .......... 21.6M=0.004s 2024-08-26 13:37:03 (19.2 MB/s) - ‘clovastudioguide_0822/clovastudio-procedure.html’ saved [82265]
LangChain을 활용해 로딩한 html은, 파일을 저장한 디렉토리의 주소를 metadata의 'source'로 가져오게 됩니다. 추후 답변 제공시, 디렉토리 주소가 아닌 실제 URL을 제공하기 위해, LangChain이 로딩한 데이터를 수정해야합니다. html을 로딩할 때 파일명을 URL로 할 경우, /와 : 기호로 인해 파일명이 깨지게 됩니다. 따라서 원본 URL과 로딩한 HTML 파일을 쌍으로 mapping하고, 이 정보를 json 형식으로 "url_to_filename_map"에 저장합니다. 이후, html 파일의 저장 경로가 담긴 'source'를, 이 json 파일을 참고해 실제 URL로 변환해줍니다. 위 코드는, json 파일을 저장하는 단계까지입니다.
외부 사이트 접근 허용 코드
-
wget 명령어를 통해 HTML 데이터를 로딩하기 전, 해당 웹사이트의 robots.txt를 확인하여 데이터로 활용할 웹페이지의 크롤러 접근 허용 여부를 확인해야합니다. NCP의 클로바스튜디오 사용 가이드의 경우 User-agent: * Allow:/ 로 접근이 가능합니다.
- 일부 사이트는 User-agent를 정의하는 부분을 추가해서 사용해야 웹 서버의 요청 차단이나 에러를 방지할 수 있습니다. 대부분 서버의 --user-agent는 Mozilla/5.0를 따르고 있습니다. 하지만 경우에 따라 불러오고자 하는 사이트의 --user-agent 정보를 직접 찾아서 적어야합니다.
2) LangChain 활용 HTML 로딩2-1) BSHTMLLoader 사용
#!pip install beautifulsoup4 lxml #필요시 beautifulsoup4 설치fromlangchain_community.document_loadersimportBSHTMLLoader# 폴더 이름에 맞게 수정html_files_dir=Path('clovastudioguide')html_files=list(html_files_dir.glob("*.html"))# 모든 문서 데이터를 저장할 리스트 초기화clovastudiodatas=[]# 찾은 HTML 파일들에 대해 처리forhtml_fileinhtml_files:# 각 파일에 대해 BSHTMLLoader 인스턴스 생성loader=BSHTMLLoader(str(html_file))document_data=loader.load()# 로드된 문서 데이터를 리스트에 추가clovastudiodatas.append(document_data)print(f"Processed {html_file}")#Output Processed /Users/user/langchain/libs/community/sample/clovastudioguide/clovastudio-info.html Processed /Users/user/langchain/libs/community/sample/clovastudioguide/clovastudio-procedure.html
2-2) UnstructuredHTMLLoader 사용
이전 단계에서 txt 파일을 HTML로 변환한 후, LangChain의 UnstructuredHTMLLoader를 사용하여 이후 문단 나누기와 임베딩을 위해 machine readable한 형태로 변환해 줍니다.#!pip install unstructured #필요시 unstructured 설치fromlangchain_community.document_loadersimportUnstructuredHTMLLoader# 폴더 이름에 맞게 수정html_files_dir=Path('./clovastudioguide')html_files=list(html_files_dir.glob("*.html"))clovastudiodatas=[]forhtml_fileinhtml_files:loader=UnstructuredHTMLLoader(str(html_file))document_data=loader.load()clovastudiodatas.append(document_data)print(f"Processed {html_file}")#Output Processed /Users/user/langchain/libs/community/sample/clovastudioguide/clovastudio-info.html Processed /Users/user/langchain/libs/community/sample/clovastudioguide/clovastudio-procedure.html
각 HTML에는 page_content에 모든 텍스트가, metadata의 'source'에는 저장 경로가 기록되어 있습니다. 위는, 로딩된 데이터 중 하나인 clovastudio-info.html의 형태입니다. metadata의 'source'에 실제 URL이 아닌 html 파일이 저장된 디렉토리 경로가 담긴 것을 확인할 수 있습니다. Mapping을 통해 이 'source'를 실제 URL로 바꾸는 작업을 다음 단계에 진행하게 됩니다.
3) Mapping 정보를 활용해 'source'를 실제 URL로 대체아래의 output은 앞선 예시인 clovastudio-info.html의 형태입니다. Mapping 정보를 활용해 'source'를 실제 url로 바꾼 것을 확인할 수 있습니다.
withopen("url_to_filename_map.json","r") as map_file:url_to_filename_map=json.load(map_file)filename_to_url_map={v: kfork, vinurl_to_filename_map.items()}# clovastudiodatas 리스트의 각 Document 객체의 'source' 수정fordoc_listinclovastudiodatas:fordocindoc_list:extracted_filename=doc.metadata["source"].split("/")[-1]ifextracted_filenameinfilename_to_url_map:doc.metadata["source"]=filename_to_url_map[extracted_filename]else:print(f"Warning: {extracted_filename}에 해당하는 URL을 찾을 수 없습니다.")print(doc.metadata["source"])#Output https://guide.ncloud-docs.com/docs/clovastudio-procedure
# 이중 리스트를 풀어서 하나의 리스트로 만드는 작업clovastudiodatas_flattened=[itemforsublistinclovastudiodatasforiteminsublist]HTML데이터가 잘 로딩되었는지 결과물을 출력해 확인해봅니다.
# 처음 3개 문서의 URL과 내용 일부 출력fordocinclovastudiodatas_flattened[:2]:print(f"URL: {doc.metadata['source']}")print(f"{doc.page_content[:100]}...")print("-"*50)#Output URL: https://guide.ncloud-docs.com/docs/clovastudio-info Login Korean English Ja - 日本語 Korean API 가이드 (...이하 중략)
3. Chunking
임베딩 모델이 처리할 수 있는 적당한 크기로 raw data를 나누는 것은 매우 중요합니다. 이는 임베딩 모델마다 한 번에 처리할 수 있는 토큰 수의 한계가 있기 때문입니다. CLOVA Studio의 문단 나누기 API를 활용해 앞서 만든 raw data를 나눠보겠습니다. 모델이 직접 문장들간의 의미 유사도를 찾아 최적의 청크(chunk) 개수와 사용자가 원하는 1개 청크 크기(글자 수)를 직접 설정하여 문단을 나눌 수 있습니다. 추가로, 후처리(postProcess = True)를 통해 chunk당 글자 수의 상한선과 하한선을 postProcessMaxSize와 postProcessMinSize로 조절할 수도 있습니다.
importhttp.clientfromhttpimportHTTPStatusclassCLOVAStudioExecutor:def__init__(self, host, request_id=None):self._host=hostself._api_key=os.environ["NCP_CLOVASTUDIO_API_KEY"]self._api_key_primary_val=os.environ["NCP_APIGW_API_KEY"]self._request_id=request_idorstr(uuid.uuid4())def_send_request(self, completion_request, endpoint):headers={'Content-Type':'application/json; charset=utf-8','X-NCP-CLOVASTUDIO-API-KEY':self._api_key,'X-NCP-APIGW-API-KEY':self._api_key_primary_val,'X-NCP-CLOVASTUDIO-REQUEST-ID':self._request_id}conn=http.client.HTTPSConnection(self._host)conn.request('POST', endpoint, json.dumps(completion_request), headers)response=conn.getresponse()status=response.statusresult=json.loads(response.read().decode(encoding='utf-8'))conn.close()returnresult, statusdefexecute(self, completion_request, endpoint):res, status=self._send_request(completion_request, endpoint)ifstatus==HTTPStatus.OK:returnres, statuselse:error_message=res.get("status", {}).get("message","Unknown error")ifisinstance(res,dict)else"Unknown error"raiseValueError(f"오류 발생: HTTP {status}, 메시지: {error_message}")classSegmentationExecutor(CLOVAStudioExecutor):defexecute(self, completion_request):app_id=os.environ["NCP_CLOVASTUDIO_APP_ID_SEGMENTATION"]endpoint=f'/testapp/v1/api-tools/segmentation/{app_id}'res, status=super().execute(completion_request, endpoint)ifstatus==HTTPStatus.OKand"result"inres:returnres["result"]["topicSeg"]else:error_message=res.get("status", {}).get("message","Unknown error")ifisinstance(res,dict)else"Unknown error"raiseValueError(f"오류 발생: HTTP {status}, 메시지: {error_message}")if__name__=="__main__":# 환경 변수가 설정되어 있는지 확인required_env_vars=["NCP_CLOVASTUDIO_API_KEY","NCP_APIGW_API_KEY","NCP_CLOVASTUDIO_APP_ID_SEGMENTATION"]missing_vars=[varforvarinrequired_env_varsifnotos.environ.get(var)]ifmissing_vars:raiseValueError(f"Missing required environment variables: {', '.join(missing_vars)}")segmentation_executor=SegmentationExecutor(host="clovastudio.apigw.ntruss.com")chunked_html=[]forhtmldataintqdm(clovastudiodatas_flattened):try:request_data={"postProcessMaxSize":100,"alpha":-100,"segCnt":-1,"postProcessMinSize":-1,"text": htmldata.page_content,"postProcess":True}response_data=segmentation_executor.execute(request_data)result_data=[' '.join(segment)forsegmentinresponse_data]forparagraphinresult_data:chunked_document={"metadata": htmldata.metadata["source"],"page_content": paragraph}chunked_html.append(chunked_document)exceptException as e:print(f"Error processing data from {htmldata.metadata['source']}: {e}")# 오류 발생 시 현재 반복을 건너뛰고 다음으로 진행continueprint(len(chunked_html))#Output 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:04<00:00, 2.06s/it] 108
위 코드를 실행해 108개의 chunk가 생겼습니다. 샘플 청크를 3개 출력해 결과를 확인해봅시다.
# 청크 분석 및 출력print(f"\n총 청크 수: {len(chunked_html)}")# 샘플 청크 출력print("\n샘플 청크 (처음 3개):")fori, chunkinenumerate(chunked_html[:3], 1):print(f"\n청크 {i}:")print(f"메타데이터: {chunk['metadata']}")print(f"내용: {chunk['page_content']}")print(f"길이: {len(chunk['page_content'])} 문자")#Output 총 청크 수: 108 샘플 청크 (처음 3개): 청크 1: 메타데이터: https://guide.ncloud-docs.com/docs/clovastudio-info 내용: Login Korean English Ja - 日本語 Korean API 가이드 CLI 가이드 내용 x HOME 포털 및 콘솔 네이버 클라우드 플랫폼 사용 환경 Compute Containers Storage Networking Database Security 길이: 145 문자 청크 2: 메타데이터: https://guide.ncloud-docs.com/docs/clovastudio-info 내용: AI Services AI·NAVER API Application Services Big Data & Analytics 길이: 66 문자 청크 3: 메타데이터: https://guide.ncloud-docs.com/docs/clovastudio-info 내용: Blockchain Business Applications Content Delivery Developer Tools Digital Twin Gaming 길이: 85 문자
4. Embedding
임베딩 단계는 앞서 Chunking 단계에서 생성된 chunk들을 기계가 이해할 수 있는 수치적 형태인 벡터 데이터로 변환하는 과정입니다. 문서의 의미를 벡터(숫자의 배열) 형태로 표현함으로써, 유저의 질문에 대해 관련있는 chunk를 검색하여 가져오는 유사도 계산시 활용됩니다.
1) LangChain을 통해 CLOVA Studio Embedding 활용하기1-1) 임베딩 모델 설정하기
문단 나누기 API를 통해 분할된 청크(chunked_html)를 CLOVA Studio의 임베딩 API를 사용해 1024차원 벡터로 변환하는 과정입니다. <1. 사전 준비> 단계에서 발급한 임베딩 V2 테스트앱을 사용했으며, 앞서 저장해둔 API키 및 app id 를 활용합니다. 임베딩 V2는 bge-m3 모델을 사용하며, 이 모델은 임베딩 과정에서 유사도 판단을 위해 코사인 거리(Cosine)를 거리 단위로 사용합니다. 모델을 설정하지 않으면 clir-emb-dolphin 모델이 기본 설정되므로, ClovaXEmbeddings의 모델을 bge-m3로 설정해주어야 합니다.fromlangchain_community.embeddingsimportClovaXEmbeddingsclovax_embeddings=ClovaXEmbeddings(model='bge-m3')# 임베딩 모델을 설정해주세요임베딩 모델은 니즈에 따라 세가지 모델 중, 선택하여 작업을 수행할 수 있습니다. 거리 단위를 임베딩부터 인덱싱, 검색까지 일치시켜야 데이터의 품질이 향상되므로, 임베딩 과정에서 사용한 모델(emb / sts / bge-m3)이 무엇인지 기억하는 것이 중요합니다. (자세한 내용은 클로바 스튜디오 가이드 참고)
도구명모델명최대 토큰 수벡터 차원권장 거리 지표임베딩 clir-emb-dolphin (랭체인 기본설정) 500 토큰 1024 IP (Inner/Dot/Scalar Product; 내적) 임베딩 clir-sts-dolphin 500 토큰 1024 Cosine Similarity (코사인 유사도) 임베딩 v2 bge-m3 8192 토큰 1024 Cosine Similarity (코사인 유사도) 1-2) 임베딩 결과 확인하기
다음 예제 코드는 "클로바 스튜디오"라는 글자에 대해 CLOVA Studio의 임베딩 API를 사용해 임베딩을 생성하는 과정입니다. 임베딩은 텍스트 데이터의 의미를 벡터 공간에서 표현하기 위해 사용됩니다.text="클로바 스튜디오"clovax_embeddings.embed_query(text)결과를 확인해보면 "클로바 스튜디오"라는 텍스트에 대한 임베딩 벡터가 생성됩니다. 이 벡터의 크기는 1024로, 실수 배열의 형태로 표현됩니다.
#Output [-0.13467026, -0.54031295, -0.5842034, 1.6036854, -1.2513447, -0.8417246, -0.51857895, ...생략]
2) 리스트 형식의 documents로 만들기임베딩 처리를 위해 앞서 만든 청크를
Document객체들의 리스트 형식의documents로 변환합니다.fromlangchain_core.documentsimportDocumentdocuments=[]forindex, iteminenumerate(chunked_html):doc=Document(page_content=str(item['page_content']),metadata={"source": item['metadata']},id=str(uuid4()))documents.append(doc)아래 코드를 통해 변환된 documents의 구조를 확인할 수 있습니다.
# documents 구조 체크fori, docinenumerate(documents):print(f"Document {i}:")print(f" Page Content: {doc.page_content[:100]}...")# 첫 100자만 출력print(f" Metadata: {doc.metadata}")print(f" Page Content Type: {type(doc.page_content)}")print(f" Metadata Type: {type(doc.metadata)}")print("-"*40)#Output Document 0: Page Content: CLOVA Studio 개념 Login Korean English Ja - 日本語 Korean API 가이드 CLI 가이드내용 x HOME 포털 및 콘솔 네이버 클라우드 플랫폼 사... Metadata: {'source': 'https://guide.ncloud-docs.com/docs/clovastudio-info', 'title': 'CLOVA Studio 개념'} Page Content Type: <class 'str'> Metadata Type: <class 'dict'> ---------------------------------------- Document 1: Page Content: 의견을 보내 주셔서 감사합니다.Classic/VPC 환경에서 이용 가능합니다.CLOVA Studio를 이용하는 전체 시나리오를 학습하기에 앞서 CLOVA Studio에 대한 몇 가... Metadata: {'source': 'https://guide.ncloud-docs.com/docs/clovastudio-info', 'title': 'CLOVA Studio 개념'} Page Content Type: <class 'str'> Metadata Type: <class 'dict'> ---------------------------------------- ...(이하 중략)
5. Vector store
이 단계는 앞서 임베딩한 결과를 Vector Store에 효율적으로 저장하고 관리하는 단계입니다. 벡터 DB는 벡터 데이터를 저장하고 검색하기 위한 데이터베이스입니다. 이 예제에서는 로컬 환경에서 보다 쉽게 활용할 수 있는 Chroma와 FAISS를 사용했습니다. Langchain의 Vector DB 비교 문서를 보고, 자신의 개발 환경에 맞는 제품을 활용하세요.
1) Vector DB에 저장하기1-1) Chroma 활용
Chroma는 오픈소스 Vector DB이며, 클라우드를 사용하지않고 클라이언트용으로 사용하면 Apache 2.0 라이센스에 무료로 이용할 수 있습니다. 본 예제에서는 chroma를 활용해 컬렉션을 생성하고, 컬렉션에 앞서 만든 문서를 추가해보겠습니다.
hnsw:space의 값을 설정함으로써 임베딩 공간의 거리 방법을 사용자 정의할 수 있습니다. 임베딩에 사용할 모델은 유사도 판단을 위해 벡터의 cosine 거리 단위로 사용하므로, 컬렉션 또한 매개변수를 "cosine"으로 설정해주었습니다.*매개변수는 ip, cosine, l2(기본값) 중에 선택할 수 있습니다.
또한, 임베딩 클래스에 오류가 발생시 멈추게끔 하는 로직을 일부 추가해, 다량의 데이터를 처리할 때 오류 발생시 재실행의 부담을 줄였습니다. LangChain 공식 문서에서 Chroma를 활용하는 자세한 내용을 확인할 수 있습니다.
#chroma 다운받기%pip install-qU"langchain-chroma>=0.1.2"importchromadbfromlangchain_chromaimportChroma# 임베딩 모델 정의clovax_embeddings=ClovaXEmbeddings(model='bge-m3')# 로컬 클라이언트 경로 지정client=chromadb.PersistentClient(path="./chroma_langchain_db")#저장할 로컬 경로# Chroma 컬렉션 생성chroma_collection=client.get_or_create_collection(name="clovastudiodatas_docs",#collection이 바뀔때마다 이름도 꼭 변경해줘야 합니다.metadata={"hnsw:space":"cosine"}#사용하는 임베딩 모델에 따라 ‘l2’, 'ip', ‘cosine’ 중에 사용)# Chroma 벡터 저장소 생성vectorstore=Chroma(client=client,collection_name="clovastudiodatas_docs",embedding_function=clovax_embeddings)# tqdm으로 for 루프 감싸기fordocintqdm(documents, desc="Adding documents", total=len(documents)):embeddings=clovax_embeddings.embed_documents([doc.page_content])[0]# 문서 추가chroma_collection.add(ids=[str(uuid.uuid4())],# 고유한 ID 생성documents=[doc.page_content],embeddings=[embeddings],metadatas=[doc.metadata])time.sleep(1.1)# 이용량 제어를 고려한 1초 이상의 딜레이, 필요에 따라 조정 가능print("All documents have been added to the vectorstore.")#Output Adding documents: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 108/108 [03:17<00:00, 2.46s/it] All documents have been added to the vectorstore.
Quoteemb 모델을 사용하는 경우
필요에 따라 클로바 스튜디오의 임베딩 모델 중clir-emb-dolphin을 사용하고자 하는 경우, 모델에 적합한 거리 지표인 IP(내적)을 사용하기 위해 Chroma 컬렉션 생성 시 설정 역시 'ip'로 변경이 필요하며, 랭체인 연동을 위해 정규화된(normalized) 임베딩 결과를 얻기 위해 아래와 같이 추가적인 조치가 필요합니다.clir-emb-dolphin모델을 사용하는 경우 전체코드
fromlangchain_community.embeddingsimportClovaXEmbeddingsfromlangchain_chromaimportChromaclient=chromadb.PersistentClient(path="./chroma_langchain_db")chroma_collection=client.get_or_create_collection(name="clovastudiodatas_rag_cosine",metadata={"hnsw:space":"ip"}# ip거리로 설정)# IP거리를 사용하는 모델(clir-emb-dolphin)의 임베딩 결과 정규화 필요importnumpy as npclassNormalizedClovaXEmbeddings(ClovaXEmbeddings) :def_embed_text(self, text:str) :# Call the parent class method to get the original embeddingoriginal_embeddings=super()._embed_text(text)# Postprocessing: apply normalization function to each elementtry:normalized_embeddings=list(original_embeddings/np.linalg.norm(original_embeddings))except:raiseValueError(f"normalization failed on text: {text}")returnnormalized_embeddingsasyncdef_aembed_text(self, text:str) :original_embeddings=awaitsuper()._aembed_text(text)try:normalized_embeddings=list(original_embeddings/np.linalg.norm(original_embeddings))except:raiseValueError(f"normalization failed on text: {text}")returnnormalized_embeddingsclova_embeddings=ClovaXEmbeddings(model="clir-emb-dolphin")vectorstore=Chroma(client=client,collection_name="clovastudiodatas_rag_cosine",#collection이 바뀔때마다 이름도 꼭 변경해줘야 합니다.embedding_function=clova_embeddings)# tqdm으로 for 루프 감싸기fordocintqdm(documents, desc="Adding documents", total=len(documents)) :embeddings=clova_embeddings.embed_documents([doc.page_content])[0]# 문서 추가chroma_collection.add(ids=[str(uuid.uuid4())],documents=[doc.page_content],embeddings=[embeddings],metadatas=[doc.metadata])time.sleep(1.4)# 이용량 제어를 고려한 1초 이상의 딜레이, 필요에 따라 조정 가능print("All documents have been added to the vector store.")1-2) FAISS 활용
Facebook AI Similarity Search (Faiss)는 밀집 벡터의 효율적인 유사도 검색과 클러스터링을 위한 라이브러리입니다. 본 예제에서는 FAISS를 활용해 vectorstore를 생성하고, 문서를 추가해보겠습니다. vectorstrore를 생성할 때, 임베딩 차원 크기를 1024차원으로 설정했습니다. 또한, 임베딩 클래스에 오류가 발생시 멈추게끔 하는 로직을 일부 추가해, 다량의 데이터를 처리할 때 오류 발생시 재실행의 부담을 줄였습니다. Langchain 공식 문서에서 FAISS 활용에 대한 더 자세한 내용을 확인 할 수 있습니다.
#FAISS 다운로드%pip install-qU langchain-community faiss-cpuimportfaissfromlangchain_community.vectorstoresimportFAISSfromlangchain_community.docstore.in_memoryimportInMemoryDocstore# 임베딩 모델 정의clovax_embeddings=ClovaXEmbeddings(model='bge-m3')# FAISS 벡터 저장소 생성vectorstore_FAISS=FAISS(embedding_function=clovax_embeddings,index=faiss.IndexFlatIP(1024),# 임베딩 차원 크기docstore=InMemoryDocstore(),index_to_docstore_id={},)# tqdm으로 for 루프 감싸기fordocintqdm(documents, desc="Adding documents", total=len(documents)):embeddings=clovax_embeddings.embed_documents([doc.page_content])[0]# 문서 추가vectorstore_FAISS.add_documents(ids=[str(uuid.uuid4())],# 고유한 ID 생성documents=[doc],# 문자열만 전달embeddings=[embeddings])time.sleep(1.4)# 이용량 제어를 고려한 1초 이상의 딜레이, 필요에 따라 조정 가능print("All documents have been added to the vectorstore.")#Output Adding documents: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 108/108 [03:17<00:00, 2.46s/it] All documents have been added to the vectorstore.
2) 다양한 파라미터를 활용해 Retriever 생성하기검색기(Retriever) 단계는 저장된 벡터 DB에서 사용자의 질문과 관련된 문서를 검색하는 과정입니다.
vectorstore.as_retriever()를 통해 검색기를 생성할 수 있습니다. 이 예제에서는retriever파라미터 설정을 통해 3개의 문서를 참고해 답변을 하도록 해보겠습니다.retriever=vectorstore.as_retriever(kwargs={"k":3})만들고자 하는 RAG 시스템의 목적 및 활용에 맞게 아래의 1~4번의 항목의 다양한 파라미터를 사용해 커스텀해보세요. 파라미터를 다양하게 조절해가며 제품의 목적에 가장 적합한 답변을 하는 방식을 찾아나갈 수 있습니다.
2-1) 유사도 점수 임계값 설정
이 설정은 유사도 점수가 0.5 이상인 문서만 반환합니다. 이를 통해 질문과 관련성이 높은 문서만을 선택적으로 가져올 수 있습니다. 임계값을 높게 설정할수록 더 관련성 높은 문서만 반환되지만, 관련 정보를 놓칠 가능성도 있습니다. 반대로 임계값을 낮추면 더 많은 문서가 반환되지만, 관련성이 떨어지는 문서도 포함될 수 있습니다. Langchain 공식 문서에서 더 자세한 내용을 확인할 수 있습니다.
retriever=db.as_retriever(# 검색 유형을 "유사도 점수 임계값"으로 설정합니다.search_type="similarity_score_threshold",# 검색 인자로 점수 임계값을 0.5로 지정합니다.search_kwargs={"score_threshold":0.5},)유사도 임계값은 0에서 1 사이의 값이어야 합니다. 이는 코사인 거리를 사용하는 `clir-sts-dolphin` 모델과 `bge-m3` 모델을 사용할 때 적합합니다.
IP(Inner Product) 거리를 사용하는 `clir-emb-dolphin` 임베딩 모델의 경우 유사도 점수 범위가 달라 앞서 작성된 코드를 사용해 정규화가 필요합니다.2-2) 반환 문서 수 제한
이 설정은 상위 3개의 가장 관련성 높은 문서만 반환합니다. k 값을 낮게 설정하면 처리 속도가 빨라지고 가장 관련성 높은 문서에 집중할 수 있지만, 중요한 정보를 놓칠 수 있습니다. k 값을 높게 설정하면 더 많은 맥락을 제공할 수 있지만, 처리 시간이 길어지고 관련성이 낮은 정보가 포함될 수 있습니다.
search_kwargs의 k와 kwargs의 k의 차이
- kwargs의 k 값의 의미는 검색기(retriever)가 답변 생성 최종적으로 참조하는 상위 문서의 개수를 의미합니다. 즉, 아래의 예제와 같이 '3'으로 설정한다면 검색하는 문서 중에서 유사도가 높은 상위 3개의 문서를 참조하여 답변을 생성합니다.
- search_kwargs의 k 값의 의미는 검색하는 문서의 개수를 의미합니다. 이전의 kwargs의 k 값은 검색한 문서에서 답변을 할때 참조하는 상위 문서의 수 였다면 search_kwargs의 k는 검색하려는 문서의 개수를 의미합니다.
따라서 search_kwargs의 k값이 kwargs의 k 값보다 적은 수로 설정된다면, 검색하는 문서의 수가 답변 생성 시에 참조하는 문서의 개수보다 적은 개수로 설정된 것으로, search_kwargs의 k값의 수로 문서의 개수가 제한되어 답변됩니다. 예를 들어, search_kwargs의 k 값은 도서관에서 정보를 얻으려고 빌린 전체 책의 권 수가 되고, kwargs의 k 값은 빌린 책 전체에서 실제 정보를 얻은 책의 권수라고 이해할 수 있습니다.
2-3) MMR (Maximum Marginal Relevance) 검색
대부분의 검색 알고리즘은 문서와 쿼리 간의 유사도를 계산하여 가장 높은 점수를 가진 문서들을 순서대로 반환합니다. 이 경우, 내용이 매우 유사하거나 심지어 동일한 문서들이 연속해서 검색 결과에 나타날 수 있습니다.
이 문제점을 MMR(Maximal Marginal Relevance) 방식으로 해결할 수 있습니다. 쿼리에 대한 관련 항목을 검색할 때 검색된 문서의 중복을 피하기 위해 단순히 가장 관련성 높은 항목들만을 검색하는 대신, 이미 선택된 문서들과의 차별성도 고려해 문서를 반환합니다. 따라서, 정보 검색이나 추천 시스템처럼 검색 결과의 다양성이 중요하거나 중복된 정보를 줄이고 싶을 때 이 방식을 사용하면 좋습니다.매개변수(parameters)
- k: 이 매개변수는 최종적으로 반환할 문서의 총 개수입니다. (기본값: 4)
- fetch_k: MMR 알고리즘을 수행할 때 고려할 초기 후보 문서 집합의 크기를 의미합니다. 광범위한 후보군에서 문서를 선택하면 좋을 때 이 값을 높입니다. 반대로, 빠른 응답 시간이 우선적이라면 이 값을 낮출 수 있습니다.(기본값: 20)
- lambda_mult: 쿼리와의 유사성과 선택된 문서 간의 다양성 사이의 균형을 조절하는 변수입니다. 1에 가까울수록 쿼리와의 유사도 점수만 고려하고, 0에 가까워질수록 문서간의 다양성만 고려합니다. (0~1, 기본값: 0.5)
2-4) 메타 데이터 필터링
메타 데이터 필터를 이용하여 특정 키워드가 포함된 메타 데이터만 필터링할 수 있습니다. 앞서 document에 저장할 때, metadata의 title을 함께 저장했습니다. 이를 활용해 문서를 필터링해 가져올 수 있습니다.
# 메타데이터 필터링filtered_retriever=db.as_retriever(search_kwargs={"filter": {'title':'CLOVA Studio 시나리오'}})6. RAG 시스템 완성
1) LCEL을 사용해 Chain 구현하기
LCEL(LangChain Expression Language)은 랭체인에서 코드를 작성하는 새로운 방법입니다. 프롬프트와 LLM 모델을 정의해두고,
|기호로 각 요소를 연결해 한 구성 요소의 출력을 다음 구성 요소의 입력으로 전달할 수 있습니다. 이렇게 Chain을 생성해 복잡한 AI 시스템의 워크플로우를 보다 쉽고 직관적으로 구성할 수 있습니다.1-1) 사용할 LLM 모델 정의
먼저, HyperCLOVA X 모델 (HCX-003) 을 랭체인 Chat model 컴포넌트의 ChatClovaX를 통해 불러와 정의합니다.fromlangchain_community.chat_modelsimportChatClovaXllm=ChatClovaX(model="HCX-003",)1-2) Prompt 정의
PromptTemplate 사용하기
쿼리에 사용할 Prompt는 StringPromptTemplates 혹은 ChatPromptTemplates을 사용해 정의할 수 있습니다. Langchain 공식 문서에서 관련 내용을 확인해보세요.
PromptTemplate은 단일 문자열의 서식을 지정하는 데 사용되며, 일반적으로 간단한 입력에 사용되는 템플릿입니다. PromptTemplate은 Python의 문자열 포맷팅을 사용하여 동적으로 특정한 위치에 입력 값을 포함시킬 수 있어, 다양한 상황에 맞게 프롬프트를 구성할 수 있습니다. 아래 예제처럼 {question}, {context} 와 같은 사용자 입력 및 매개 변수를 언어 모델에 전달하게 할 수 있습니다.fromlangchain_core.promptsimportPromptTemplateprompt1=PromptTemplate.from_template("""당신은 질문-답변(Question-Answering)을 수행하는 친절한 AI 어시스턴트입니다. 당신의 임무는 원래 가지고있는 지식은 모두 배제하고, 주어진 문맥(context) 에서 주어진 질문(question) 에 답하는 것입니다.검색된 다음 문맥(context) 을 사용하여 질문(question) 에 답하세요. 만약, 주어진 문맥(context) 에서 답을 찾을 수 없다면, 답을 모른다면 `주어진 정보에서 질문에 대한 정보를 찾을 수 없습니다` 라고 답하세요.#Question:{question}#Context:{context}#Answer:""")ChatPromptTemplate 사용하기
ChatPromptTemplate 은 대화목록을 프롬프트로 주입하고자 할 때 활용할 수 있습니다. 메시지는 튜플(tuple) 형식으로 구성하며, (role, message) 로 구성하여 리스트로 생성할 수 있습니다.- "system": 시스템 설정 메시지 입니다. 주로 전역설정과 관련된 프롬프트입니다.
- "human" : 사용자 입력 메시지 입니다.
- "ai": AI 의 답변 메시지입니다.
fromlangchain_core.promptsimportChatPromptTemplatesystem_prompt=("""당신은 질문-답변(Question-Answering)을 수행하는 친절한 AI 어시스턴트입니다. 당신의 임무는 원래 가지고있는 지식은 모두 배제하고, 주어진 문맥(context) 에서 주어진 질문(question) 에 답하는 것입니다.검색된 다음 문맥(context) 을 사용하여 질문(question) 에 답하세요. 만약, 주어진 문맥(context) 에서 답을 찾을 수 없다면, 답을 모른다면 `주어진 정보에서 질문에 대한 정보를 찾을 수 없습니다` 라고 답하세요.""""\n\n""{context}")prompt2=ChatPromptTemplate.from_messages([("system", system_prompt),("human","{question}"),])1-3) Chain 생성
앞서 정의한 LLM 모델과 prompt를 LCEL 표기법을 사용해 chain으로 연결합니다. 이때, Langchain의 StrOutputParser도 chain으로 연결해 모델의 출력을 문자열로 변환해보겠습니다. 아래 코드를 실행하면 연결된 chain이 연쇄적으로 실행됩니다. retriever를 통해 관련 문서를 context로 불러오고, context와 question이 프롬프트 템플릿으로 전달되고, llm 모델을 통해 프롬프트가 실행되고, StrOutputParser를 통해 답변만 파싱해 문자열로 출력합니다.fromlangchain_core.runnablesimportRunnablePassthroughfromlangchain_core.output_parsersimportStrOutputParser# 체인을 생성합니다.rag_chain=({"context": retriever,"question": RunnablePassthrough()}| prompt1| llm| StrOutputParser())rag_chain.invoke("토큰이 뭔가요?")#Output 토큰은 자연어 처리를 위해 하나의 단어를 세분화한 단어 조각을 의미합니다. 예를 들어, '맛있어'라는 표현은 각각 '맛'과 '있어'라는 두 개의 토큰으로 나뉠 수 있습니다. 다른 예시로는 '원숭이 엉덩이는 빨개' 라는 문장은 '원숭이', '엉덩이는', '빨개' 와 같은 세 개의 토큰으로 나뉠 수 있습니다.
1-4) 참조 문서 링크와 함께 답변 출력하기
모델이 답변을 생성할 때 참조하는 문서의 출처를 확인하고 싶으시다면 아래의 코드를 참조하세요. RunnablePassthrough.assign()을 사용하여 검색 체인에서 소스 문서를 반환해 참조 문서 링크와 함께 답변을 출력해보겠습니다.frompprintimportpprintfromlangchain_core.runnablesimportRunnablePassthroughfromlangchain.schema.runnableimportRunnableParallelfromlangchain_core.output_parsersimportStrOutputParser# 쿼리 텍스트query_text="max_token을 몇으로 설정해야해?"# 1. 쿼리 임베딩 생성clovax_embeddings=ClovaXEmbeddings(model='bge-m3')query_embedding=clovax_embeddings.embed_query(query_text)# 2. Chroma 컬렉션에 쿼리 실행하여 유사한 문서 검색results=chroma_collection.query(query_embeddings=[query_embedding],n_results=5,include=["embeddings","documents","metadatas","distances"])# 3. 유사도 검색 결과를 사용하여 리트리버 구성similarity_retriever=vectorstore.as_retriever(kwargs={"k":5},search_type="similarity_score_threshold",search_kwargs={"score_threshold":0.1,"k":3})# 4. 검색된 문서를 RAG 체인에 연결하여 답변 생성rag_chain_from_docs=(RunnablePassthrough.assign(context=(lambdax: format_docs(x["context"])))| prompt1| llm| StrOutputParser())defformat_docs(docs):return"\n\n".join(doc.page_contentfordocindocs)rag_chain_with_source=RunnableParallel({"context": similarity_retriever,"question": RunnablePassthrough()}).assign(answer=rag_chain_from_docs)pprint(rag_chain_with_source)Vector DB에 저장한 문서들과 관련있는 질문에 대해서는 모델이 아래와 같이 답변을 잘하는 것을 확인할 수 있습니다.
#Output {'answer': '일반 모드에서 제공하는 언어 모델인 경우에는 최대 2048 토큰까지, 챗 모드에서 제공하는 HyperCLOVA X 언어 ' '모델인 경우에는 최대 4096 토큰까지 허용됩니다. Maximum tokens는 300~500을 권장하며 작업에 따라 ' '달라질 수 있습니다.', 'context': [Document(metadata={'source': 'https://guide.ncloud-docs.com/docs/clovastudio-info'}, page_content='Maximum tokens Maximum tokens는 결괏값을 생성할 때 사용할 최대 토큰 수입니다. 토큰 수를 높게 설정할 수록 긴 결괏값을 출력합니다.'), Document(metadata={'source': 'clovastudioguide_0822/clovastudio-info.html'}, page_content='Maximum tokens Maximum tokens는 결괏값을 생성할 때 사용할 최대 토큰 수입니다. 토큰 수를 높게 설정할 수록 긴 결괏값을 출력합니다.'), Document(metadata={'source': 'clovastudioguide_0822/clovastudio-info.html'}, page_content='프롬프트와 결괏값을 포함하여 일반 모드에서 제공하는 언어 모델인 경우에는 최대 2048 토큰까지, 챗 모드에서 제공하는 HyperCLOVA X 언어 모델인 경우에는 최대 4096 토큰까지 허용됩니다. Maximum tokens는 300~500을 권장하며 작업에 따라 달라질 수 있습니다.')], 'question': 'max_token을 몇으로 설정해야해?'}
위의 결과를 보다 보기 좋게 확인할 수 있습니다.
result=rag_chain_with_source.invoke(query_text)model_answer=result['answer']urls={doc.metadata['source']fordocinresult['context']}print("- 사용자 질문: {0}\n- 모델의 답변: {1}\n- 참조한 문서의 url: {2}".format(query_text, model_answer,list(urls)))#Output - 사용자 질문: max_token을 몇으로 설정해야해? - 모델의 답변: 일반 모드에서 제공하는 언어 모델인 경우에는 최대 2048 토큰까지, 챗 모드에서 제공하는 HyperCLOVA X 언어 모델인 경우에는 최대 4096 토큰까지 허용됩니다. Maximum tokens는 300~500을 권장하며 작업에 따라 달라질 수 있습니다. - 참조한 문서의 url: ['clovastudioguide_0822/clovastudio-info.html', 'https://guide.ncloud-docs.com/docs/clovastudio-info']
아래와 같이 문서와 관련 없는 질문에 대해선 정보를 찾을 수 없다고 답하는 것을 확인할 수 있습니다.
rag_chain_with_source.invoke("오늘 기분이 어때?")#Output {'context': [Document(metadata={'source': 'https://guide.ncloud-docs.com/docs/clovastudio-info'}, page_content='Temperature 값이 높은 경우'), Document(metadata={'source': 'https://guide.ncloud-docs.com/docs/clovastudio-info'}, page_content='Temperature 값이 높은 경우'), Document(metadata={'source': 'https://guide.ncloud-docs.com/docs/clovastudio-procedure'}, page_content='이 문서가 도움이 되었습니까?')], 'question': '오늘 기분이 어때?', 'answer': '주어진 정보에서 질문에 대한 정보를 찾을 수 없습니다.'}
2) Built in chain 활용원하는 경우 LangChain에는 RAG 시스템을 위의 LCEL을 사용하지 않고 함수로도 구현할 수 있습니다.
-
create_stuff_documents_chain
검색된 컨텍스트가 프롬프트와 LLM에 공급되는 방법을 지정합니다. 이 경우 프롬프트에 문서의 요약이나 기타 처리 없이 검색된 모든 컨텍스트를 포함합니다. 이 함수를 통해 {input}과 {context}에 내용이 들어가게 됩니다.
입력 키:context,input -
create_retrieval_chain
검색 단계를 추가하고 검색된 문서를 최종 답변과 함께 제공합니다.
입력 키:input
출력: input, context, answer
fromlangchain.chainsimportcreate_retrieval_chainfromlangchain.chains.combine_documentsimportcreate_stuff_documents_chainfromlangchain_core.promptsimportChatPromptTemplatefromlangchain_community.chat_modelsimportChatClovaX# chat모델 정의llm=ChatClovaX(model="HCX-003",)# ChatPromptTemplate 사용system_prompt=("""당신은 질문-답변(Question-Answering)을 수행하는 친절한 AI 어시스턴트입니다. 당신의 임무는 원래 가지고있는 지식은 모두 배제하고, 주어진 문맥(context) 에서 주어진 질문(question) 에 답하는 것입니다.검색된 다음 문맥(context) 을 사용하여 질문(question) 에 답하세요. 만약, 주어진 문맥(context) 에서 답을 찾을 수 없다면, 답을 모른다면 `주어진 정보에서 질문에 대한 정보를 찾을 수 없습니다` 라고 답하세요.""""\n\n""{context}")prompt2=ChatPromptTemplate.from_messages([("system", system_prompt),("human","{input}"),])# Built-in chainsquestion_answer_chain=create_stuff_documents_chain(llm, prompt2)rag_chain=create_retrieval_chain(retriever, question_answer_chain)result=rag_chain.invoke({"input":"토큰이 뭐야?"})print(result)#Output {'input': '토큰이 뭐야?', 'context': [Document(page_content='토큰', metadata={'source': 'https://guide.ncloud-docs.com/docs/clovastudio-info'}), Document(page_content="<예시> '맛있어'라는 표현은 각각 '맛'과 있어'라는 두 개의 토큰으로 나뉠 수 있습니다.", metadata={'source': 'https://guide.ncloud-docs.com/docs/clovastudio-info'}), Document(page_content='Temperature를 낮게 설정하면 후보에 포함된 토큰의 순위는 바뀌지 않지만 확률이 높았던 토큰은 더욱 확률 값이 높아지고 낮았던 토큰은 확률 값이 더욱 낮아집니다. 가장 높은 순위의 토큰이 선택될 가능성이 크기 때문에 정형적인 결괏값을 생성합니다.', metadata={'source': 'https://guide.ncloud-docs.com/docs/clovastudio-info'})], 'answer': '토큰은 문장이나 단어를 구성하는 기본 단위로, 의미를 가지는 최소 단위입니다. 예를 들어, "맛있어"라는 표현은 각각 "맛"과 "있어"라는 두 개의 토큰으로 나뉠 수 있습니다. 또한 인공지능 분야에서는 자연어 처리나 기계학습에서 데이터를 분석하기 위해 토큰화(tokenization) 과정을 거칩니다. 이 때 각 단어나 기호 등을 토큰으로 분리하여 처리합니다.'}
위의 결과를 보다 보기 좋게 확인할 수 있습니다.
print("질문:")print(result['input'])print("\n답변:")print(result['answer'])print("\n참조 문서 URL:")unique_urls=set(doc.metadata['source']fordocinresult['context'])forurlinunique_urls:print(url)#Output 질문: 토큰이 뭐야? 답변: 토큰은 문장이나 단어를 구성하는 기본 단위로, 의미를 가지는 최소 단위입니다. 예를 들어, "맛있어"라는 표현은 각각 "맛"과 "있어"라는 두 개의 토큰으로 나뉠 수 있습니다. 또한 인공지능 분야에서는 자연어 처리나 기계학습에서 데이터를 분석하기 위해 토큰화(tokenization) 과정을 거칩니다. 이 때 각 단어나 기호 등을 토큰으로 분리하여 처리합니다. 참조 문서 URL: https://guide.ncloud-docs.com/docs/clovastudio-info
7. 맺음말
지금까지 NAVER Cloud Platform(NCP)에서 Langchain을 활용하여 RAG 시스템을 구현하는 방법을 살펴보았습니다. 이 가이드에서는 HCX 모델을 활용하여 간단한 RAG 파이프라인을 구축하는 과정을 다뤘습니다. 이 가이드는 RAG의 기본 구조와 흐름에 초점을 맞추었지만, RAG 기술은 계속 발전하고 있습니다. 앞으로 다양한 RAG 시스템 구현에 관한 더 깊이 있는 주제들을 다룰 예정입니다.
- NCP 가이드: https://guide.ncloud-docs.com/docs/clovastudio-dev-langchain
- LangChain 공식 문서: https://python.langchain.com/docs/integrations/providers/naver/
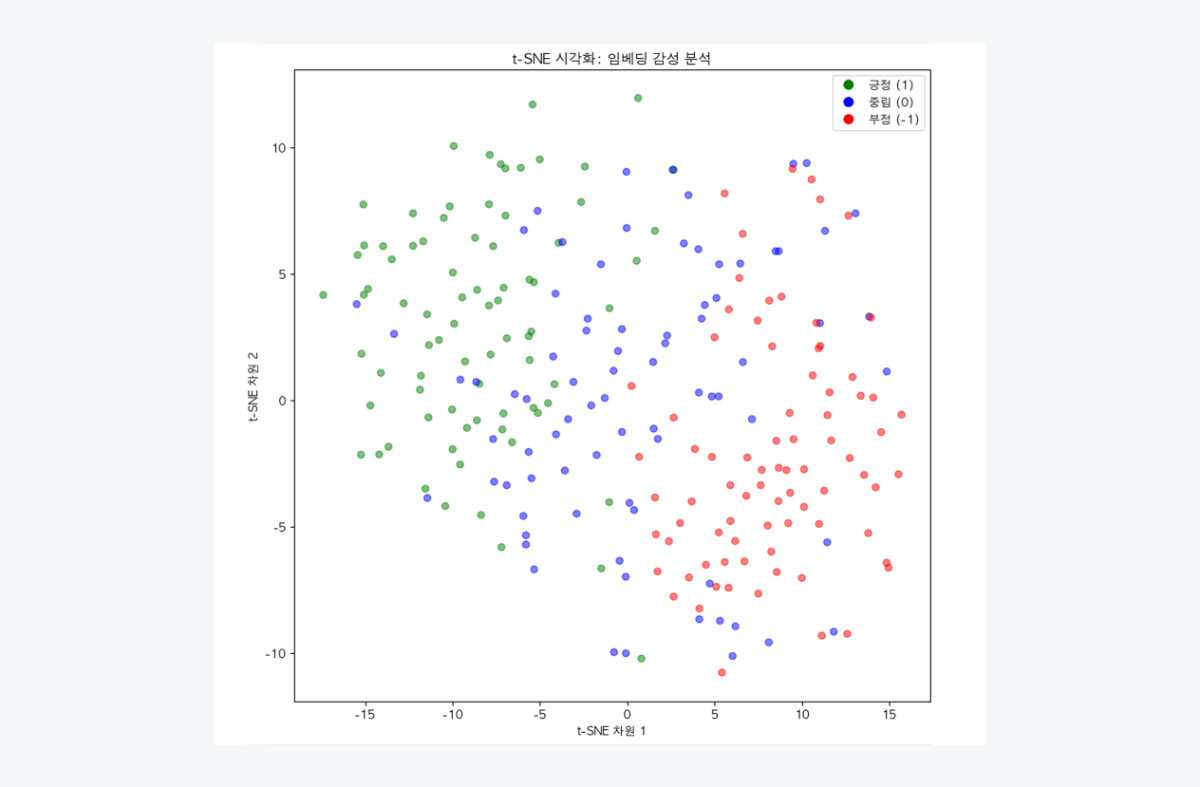
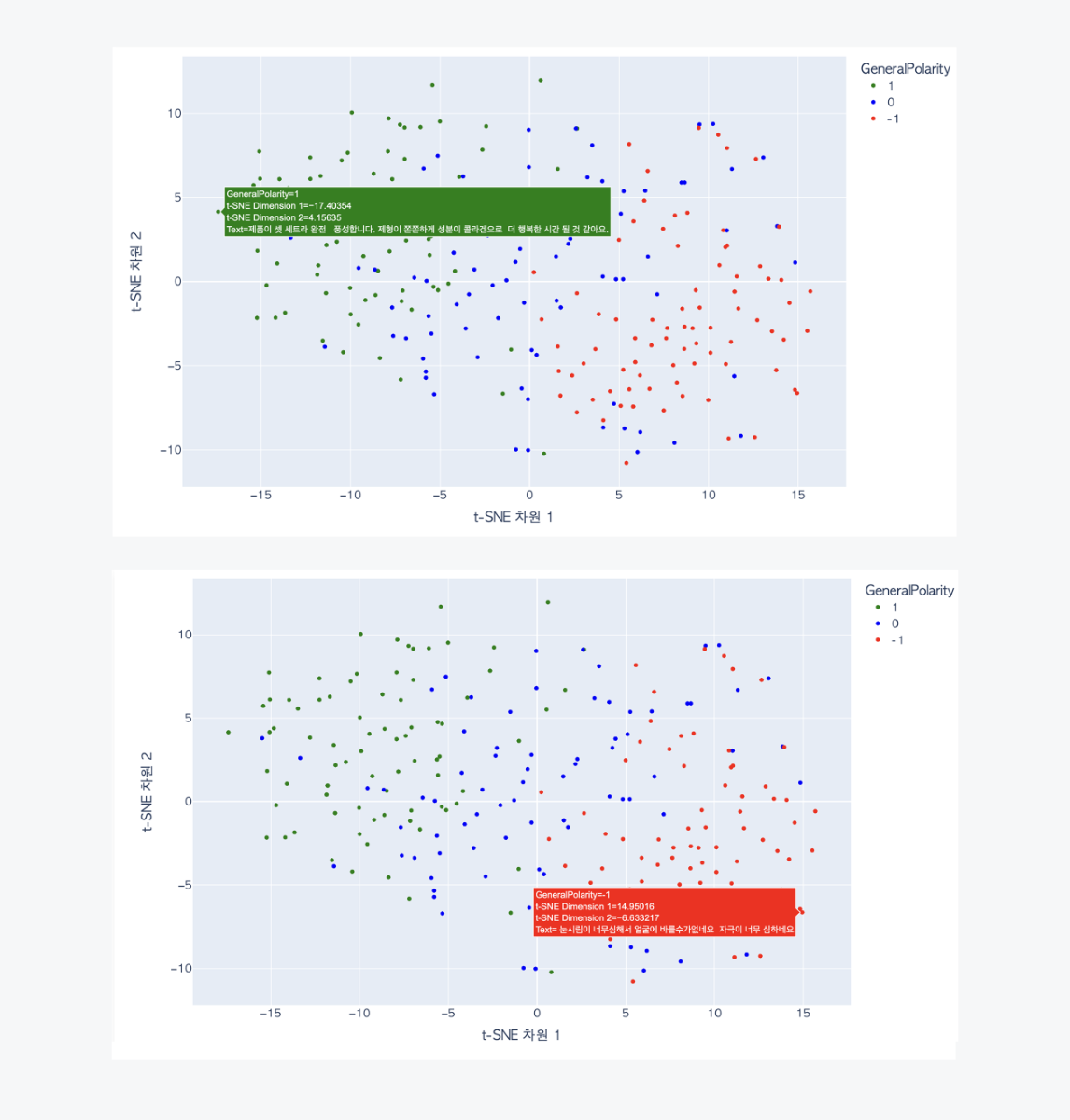
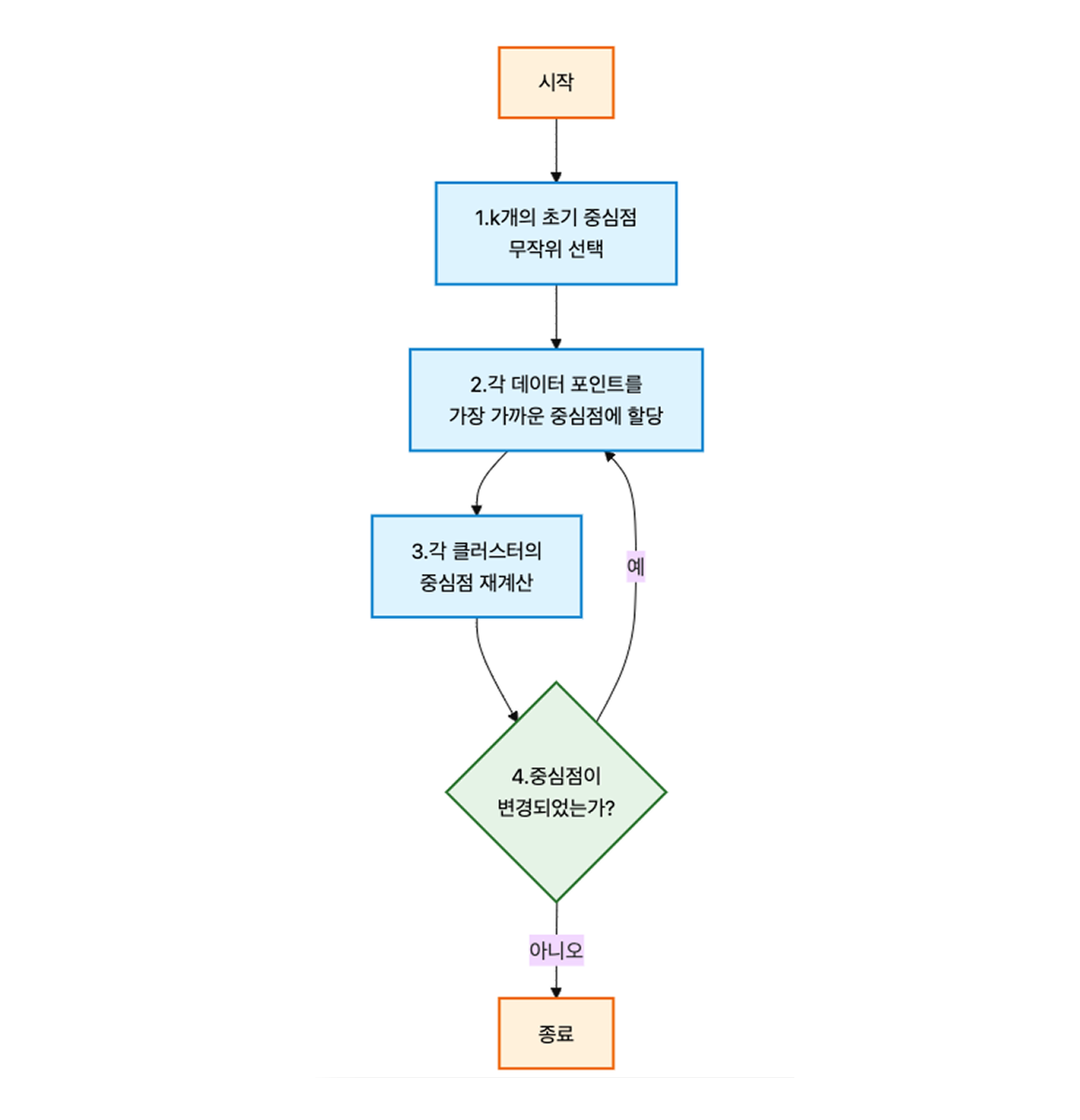


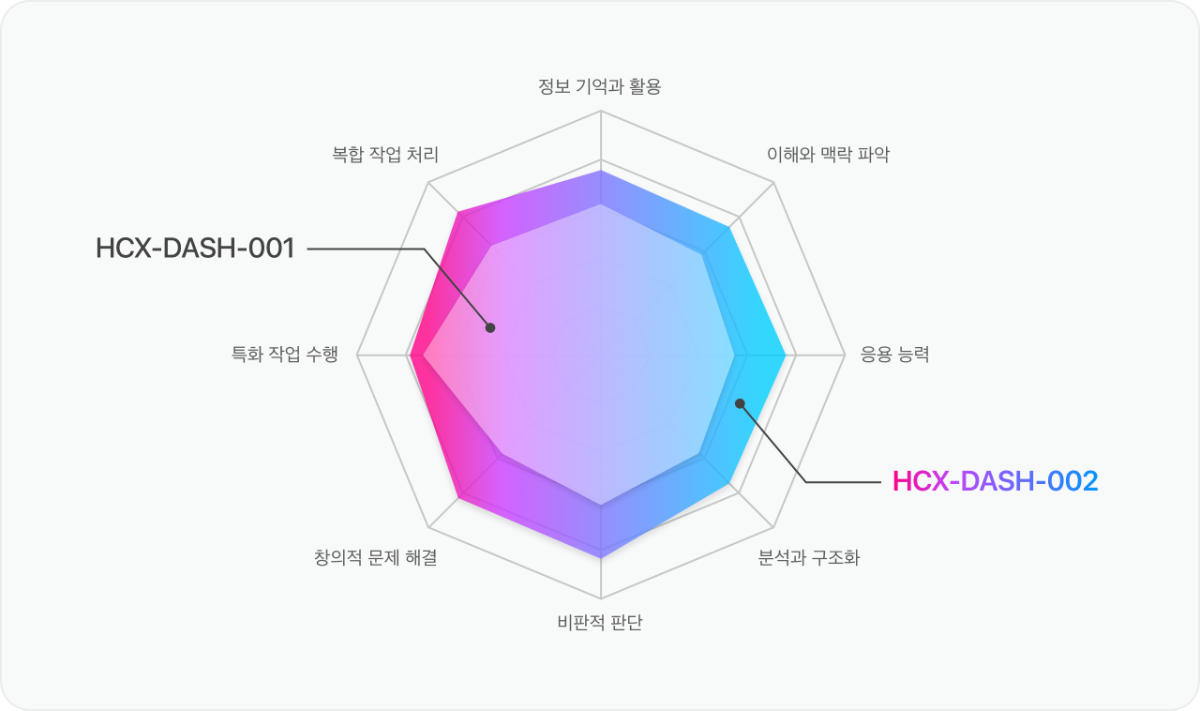
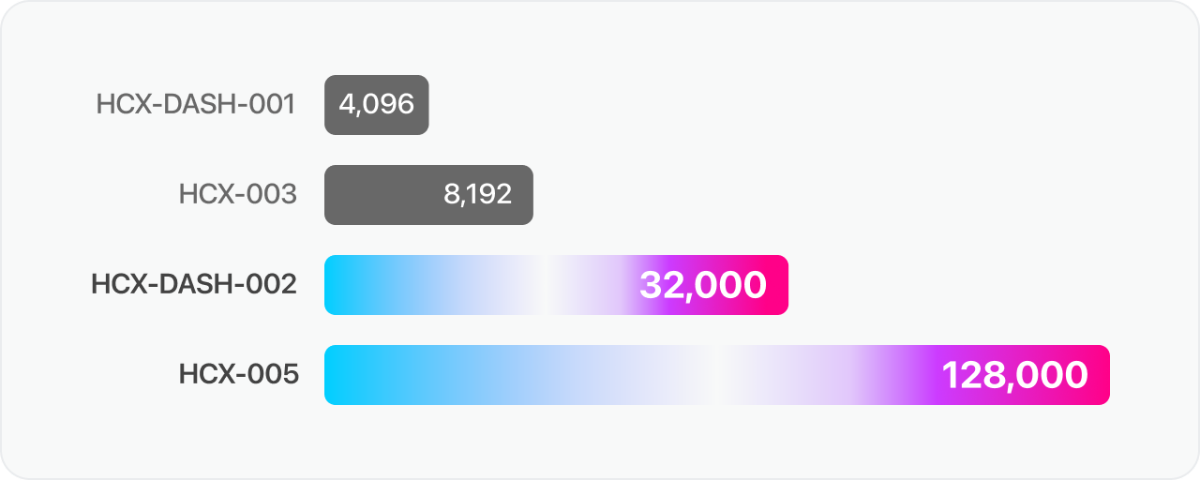

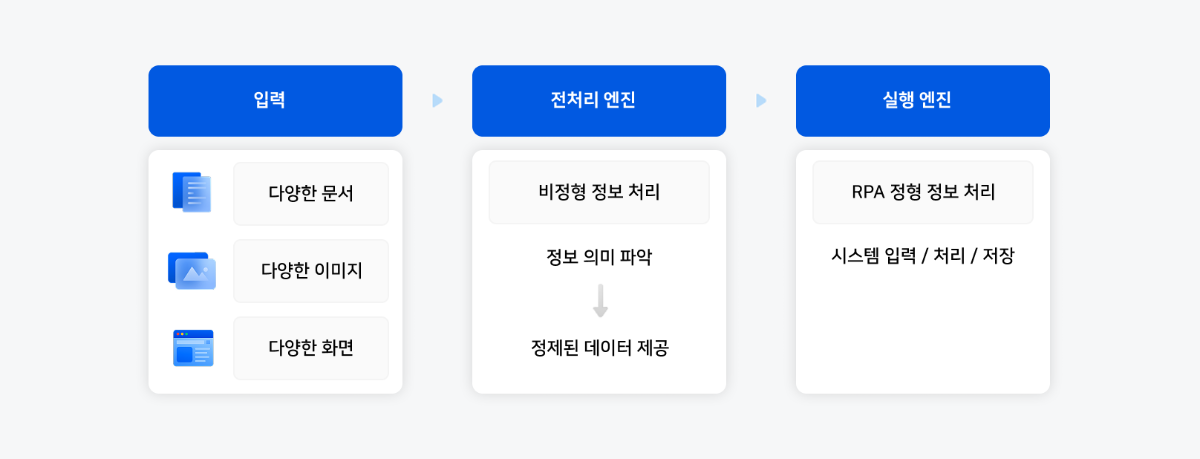
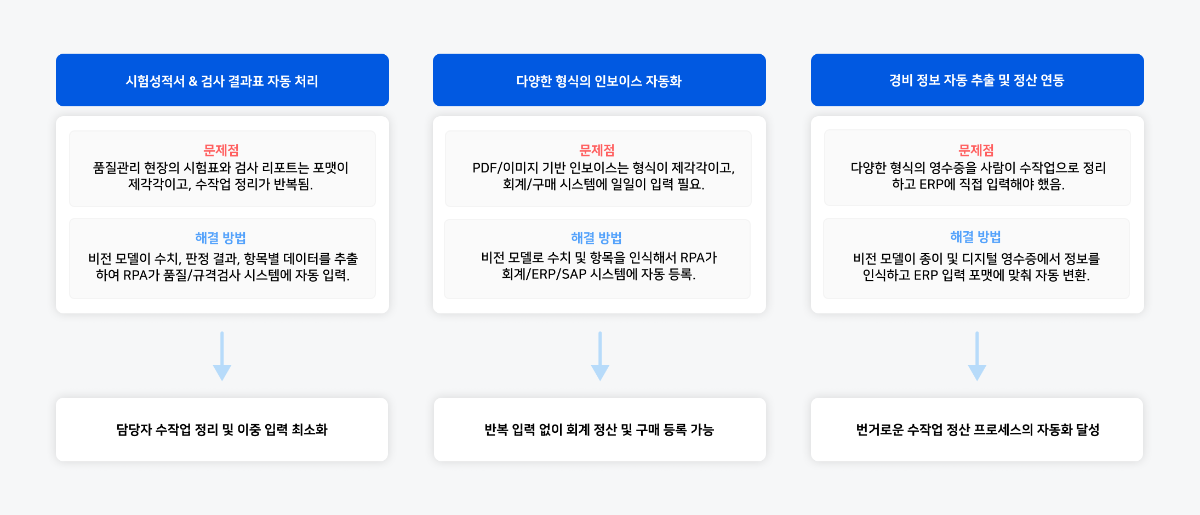

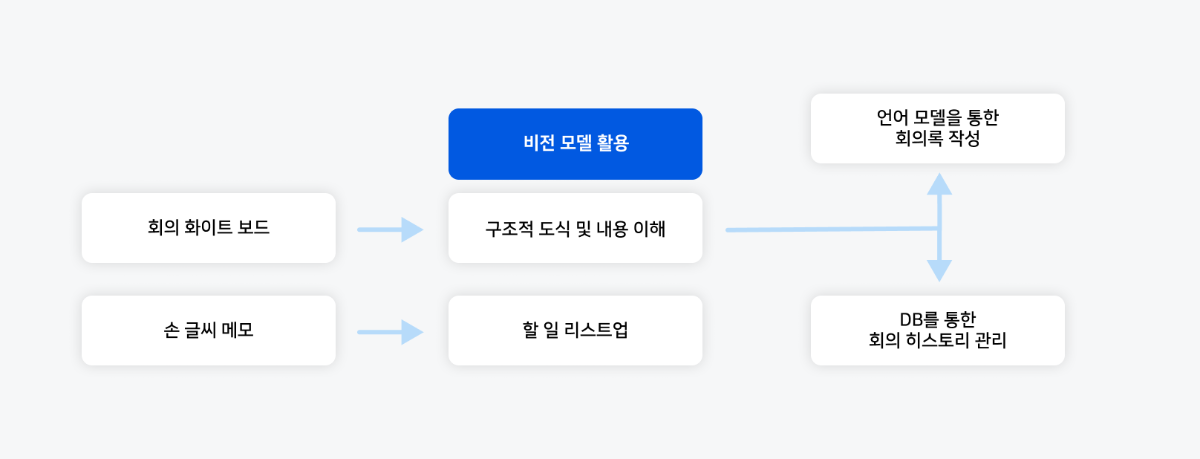
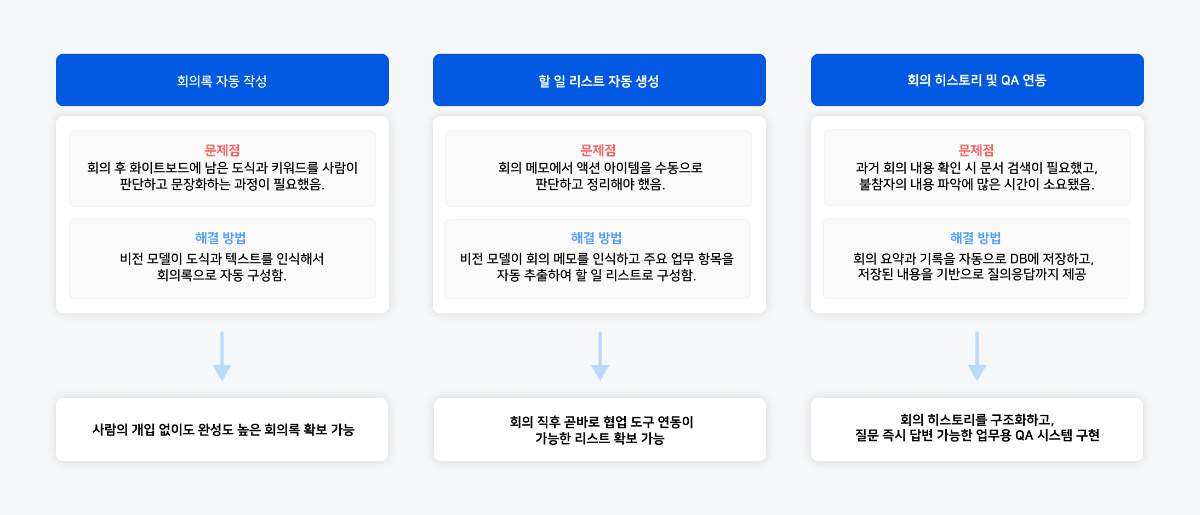

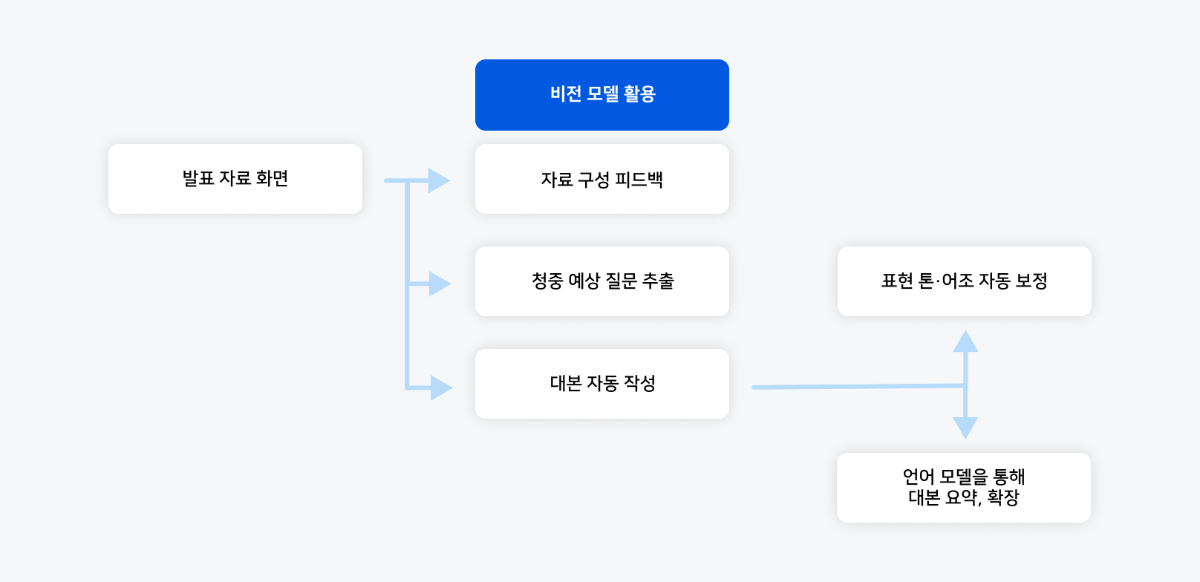
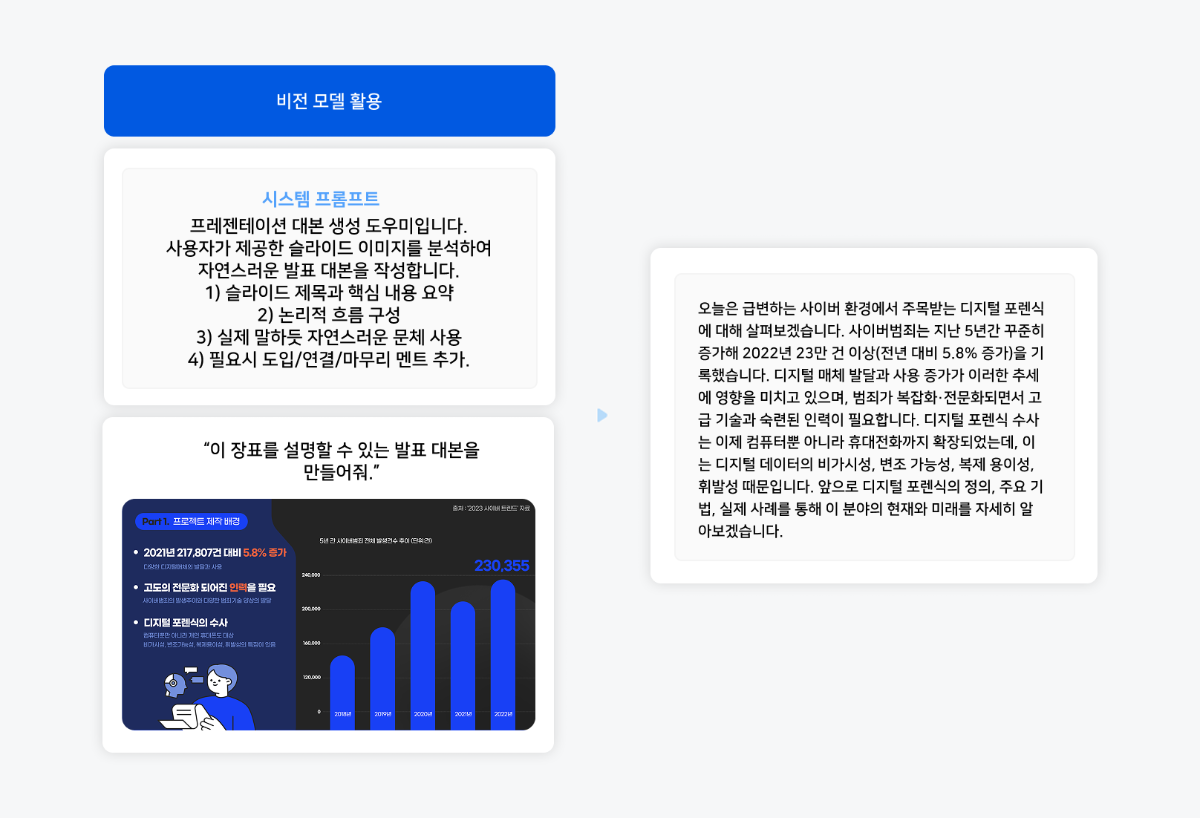

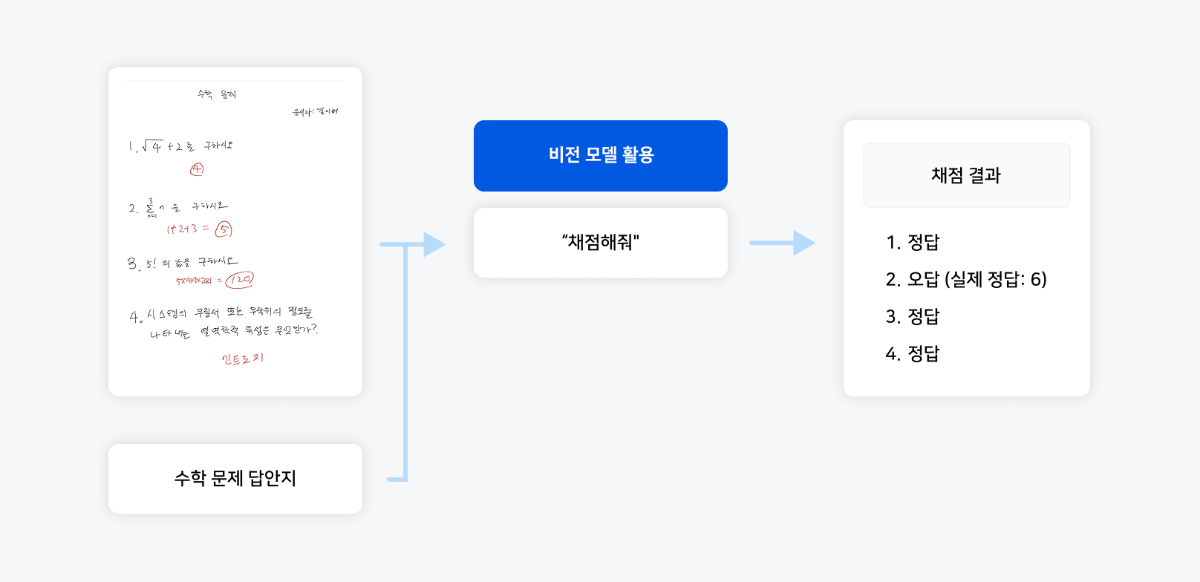
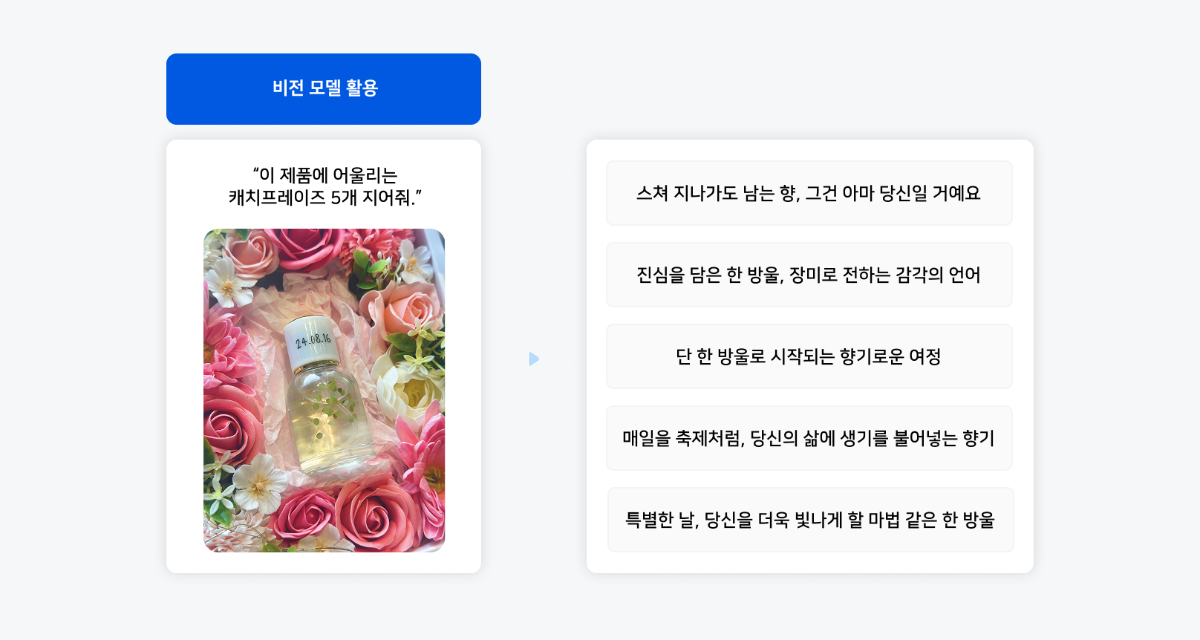



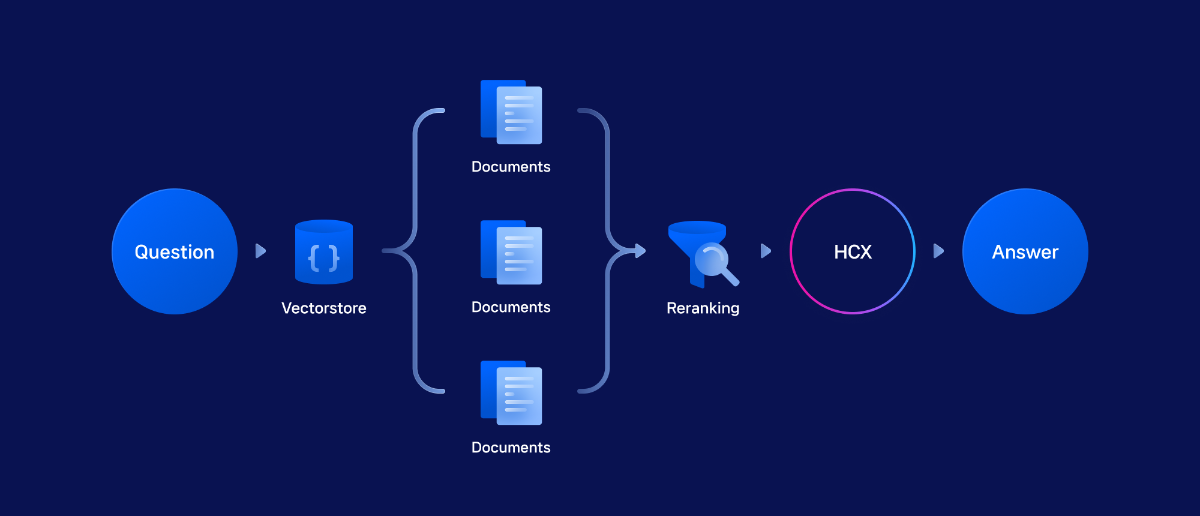
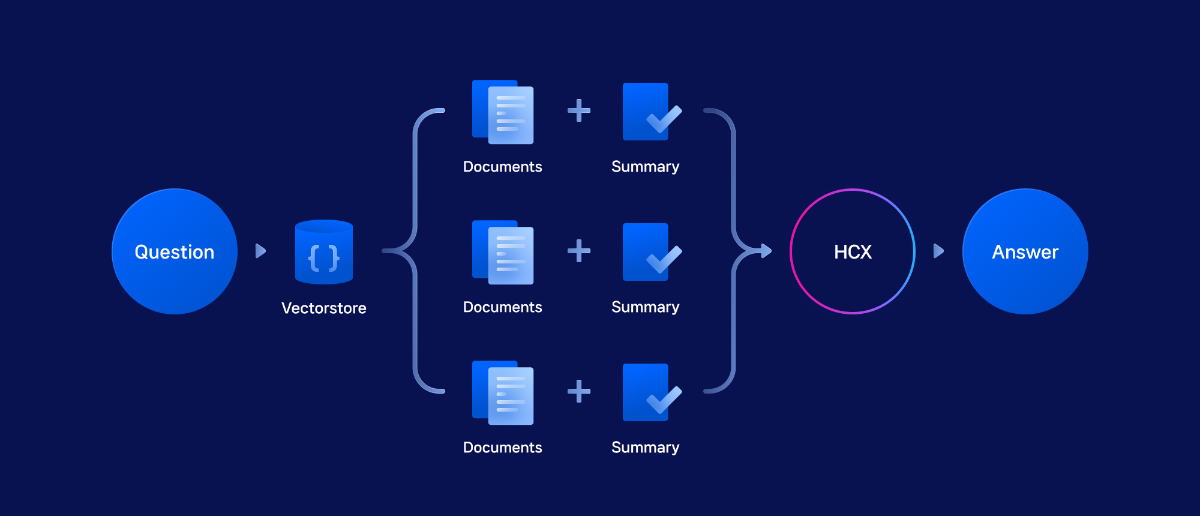

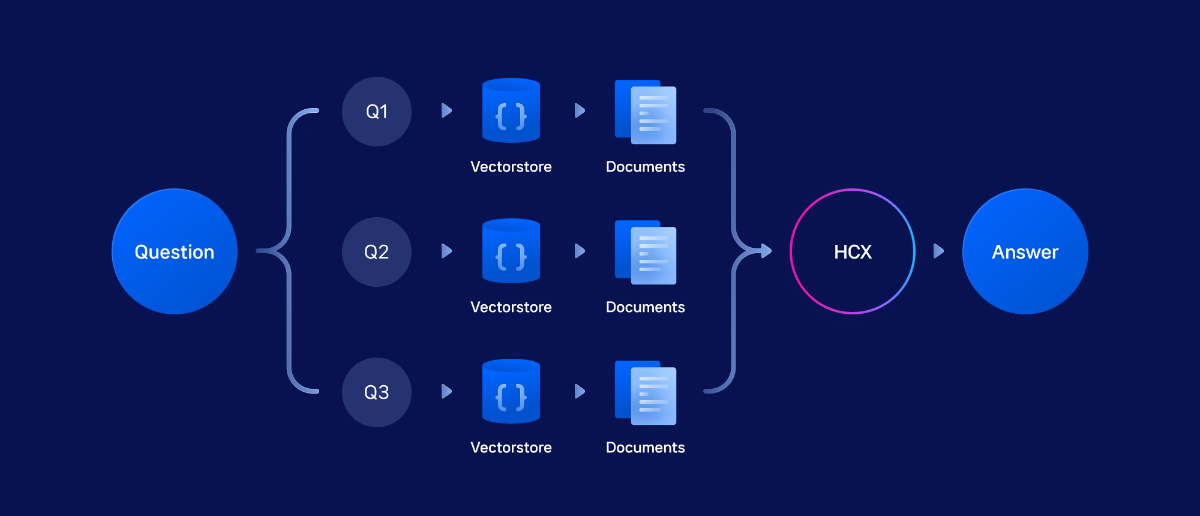

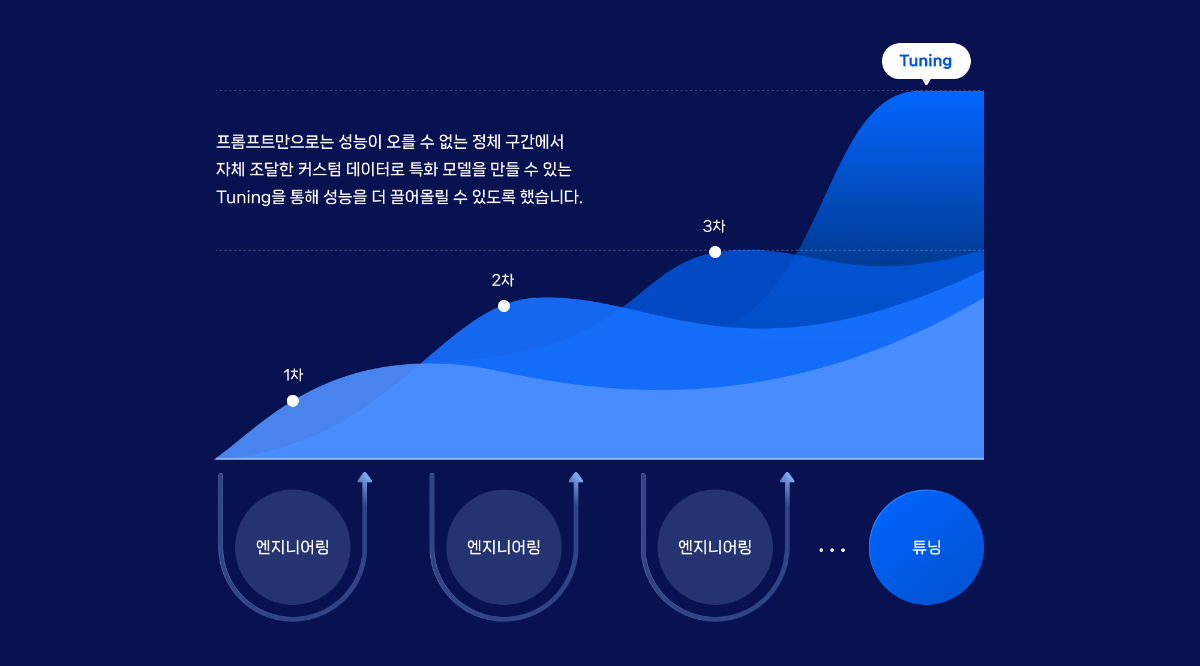
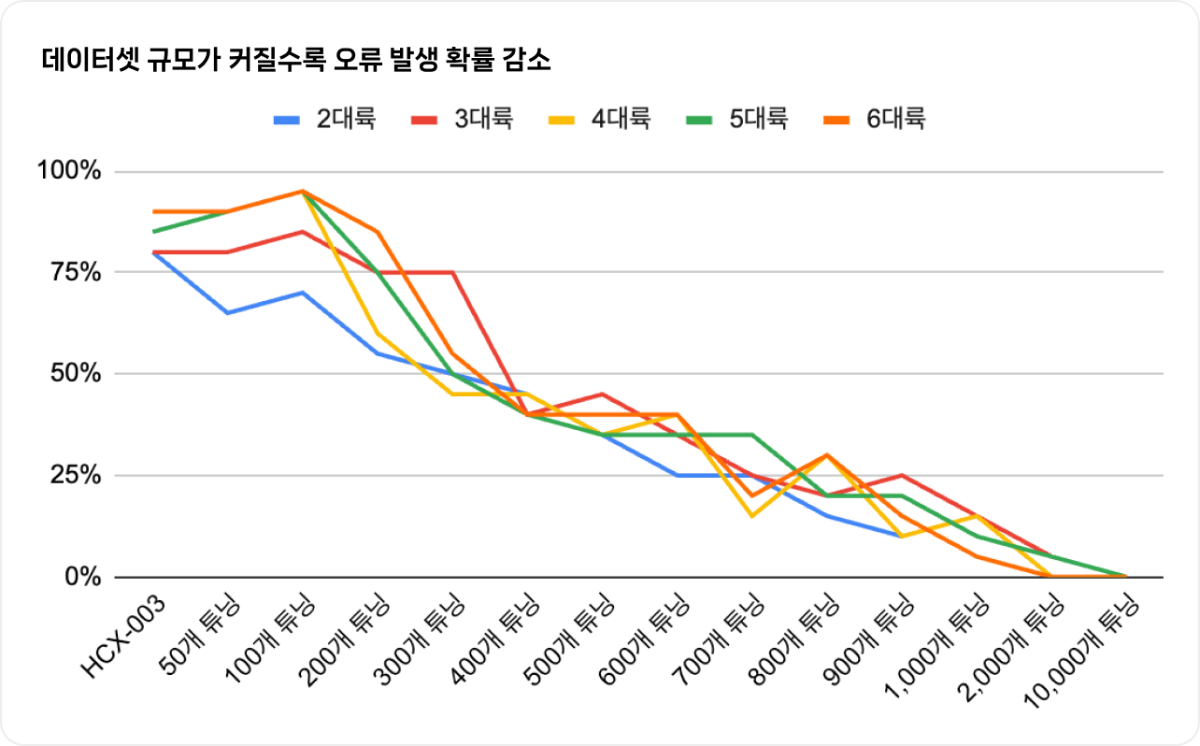
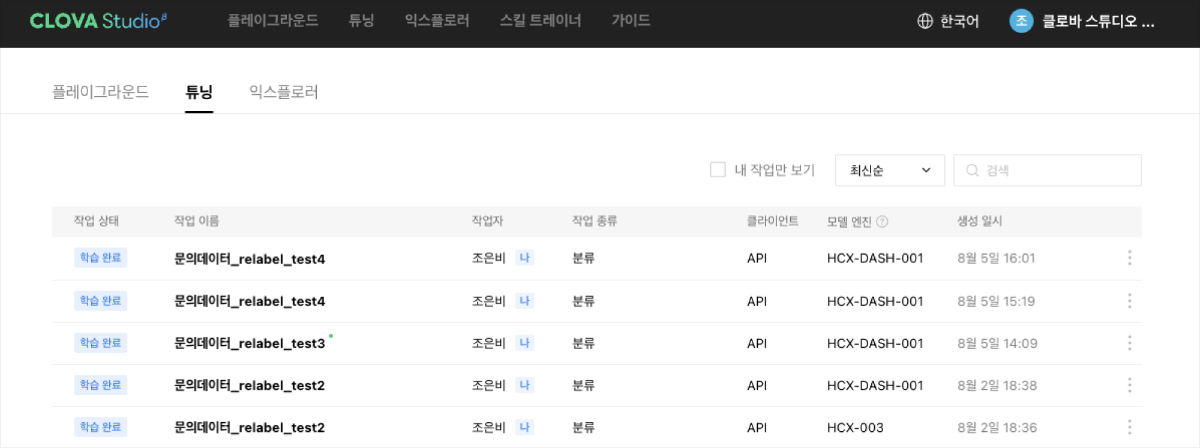
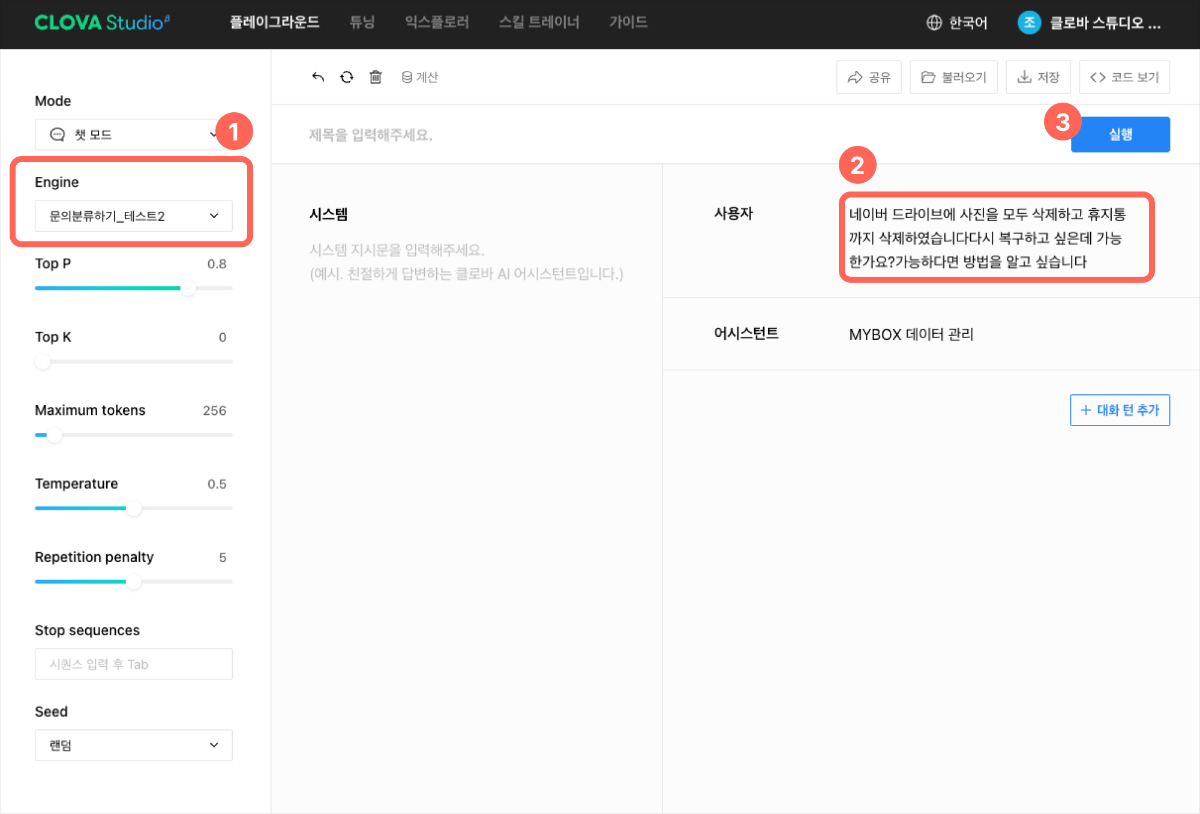
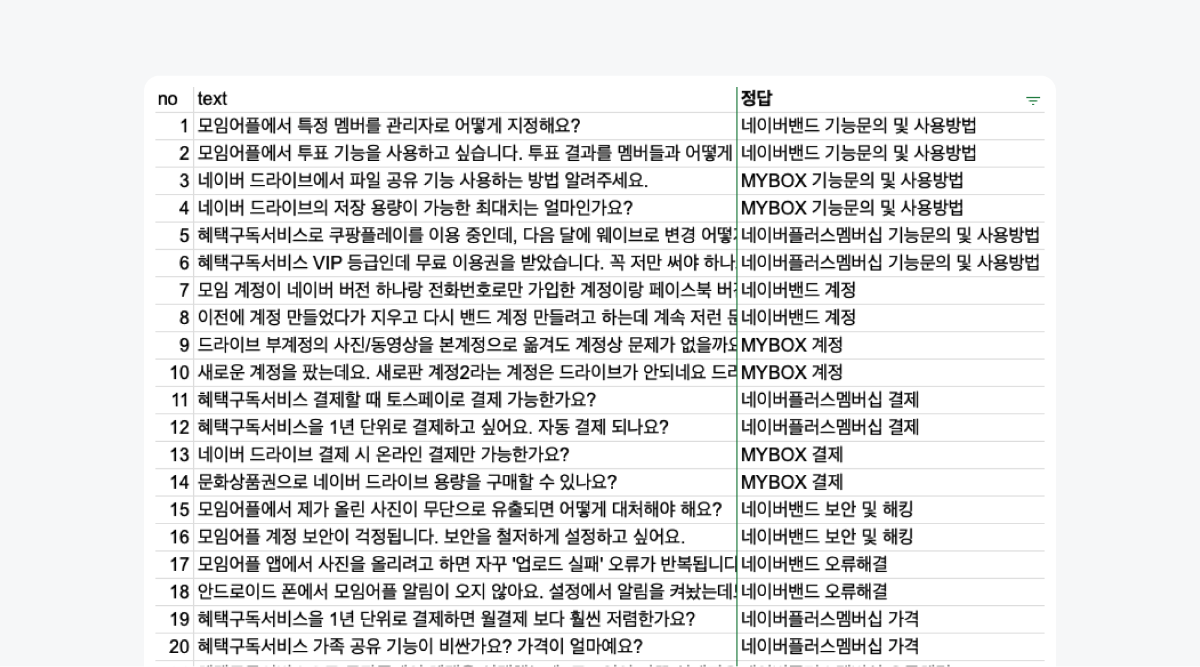

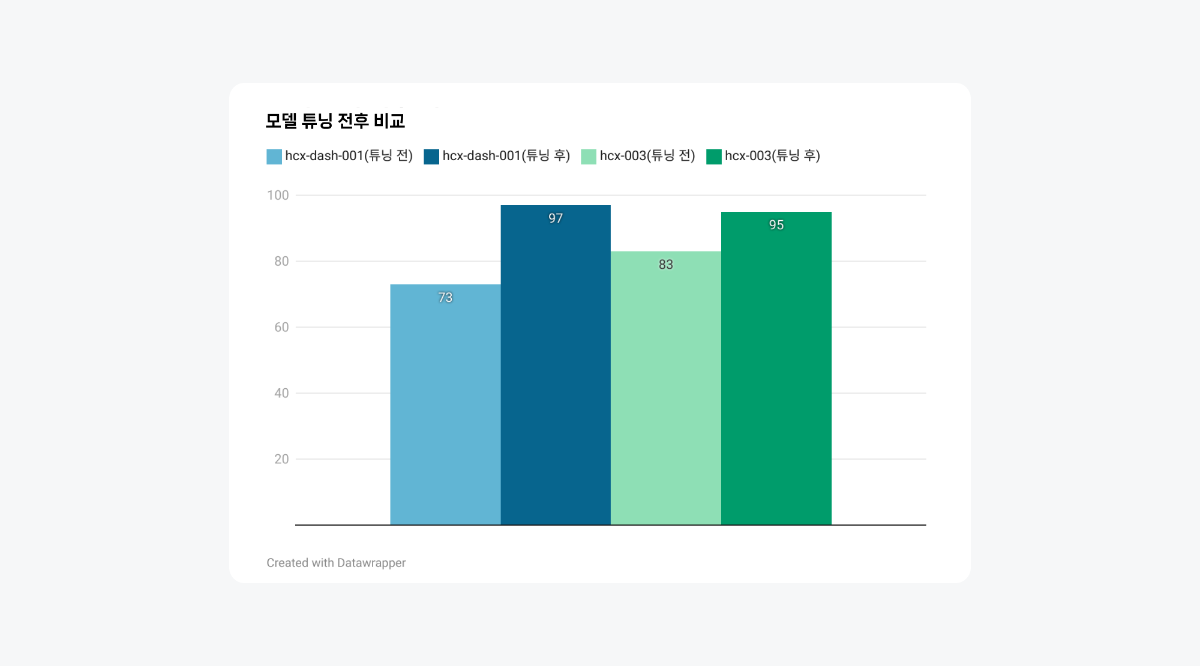


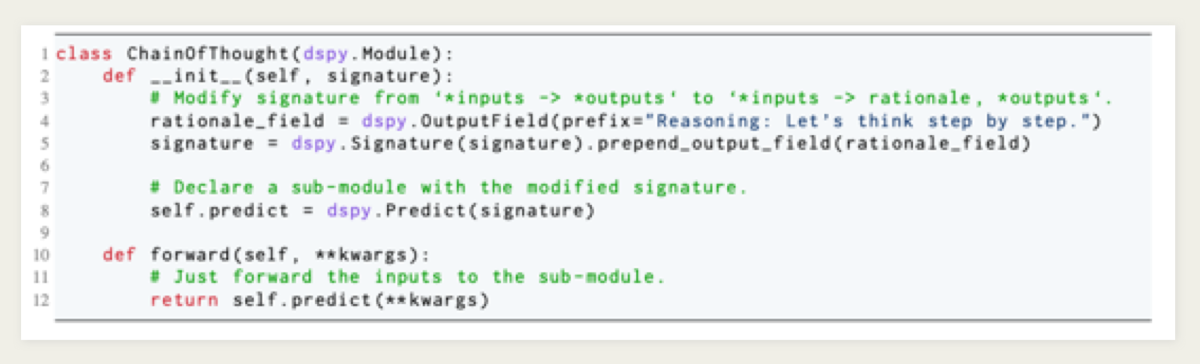



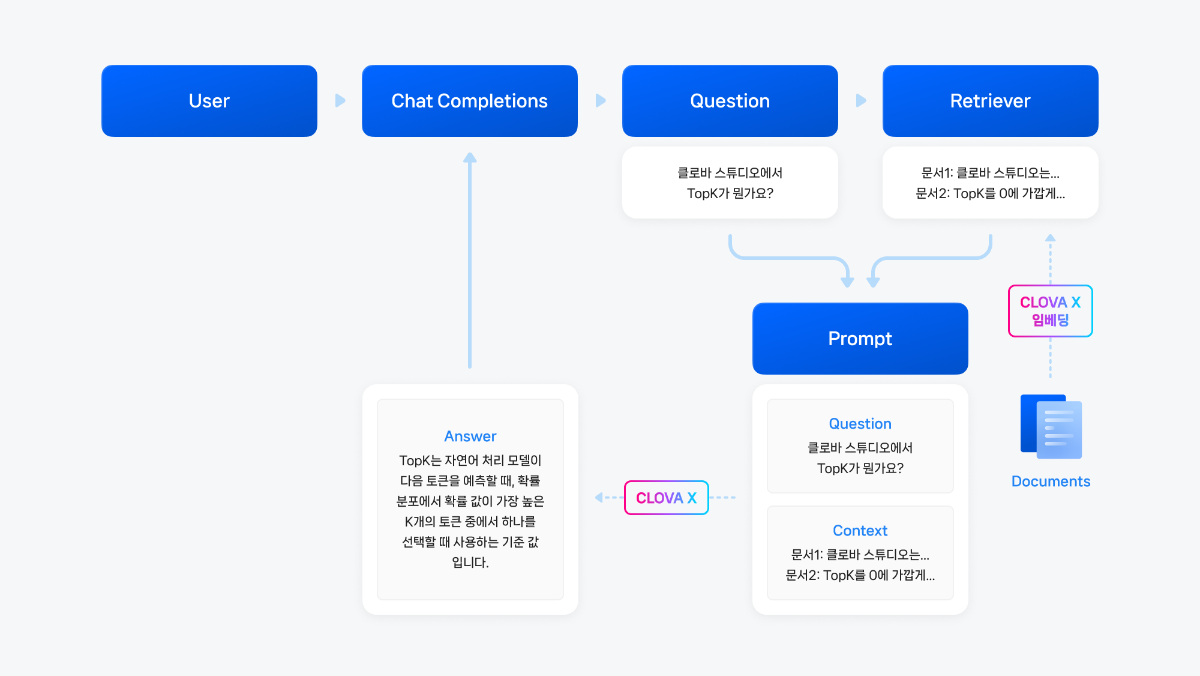
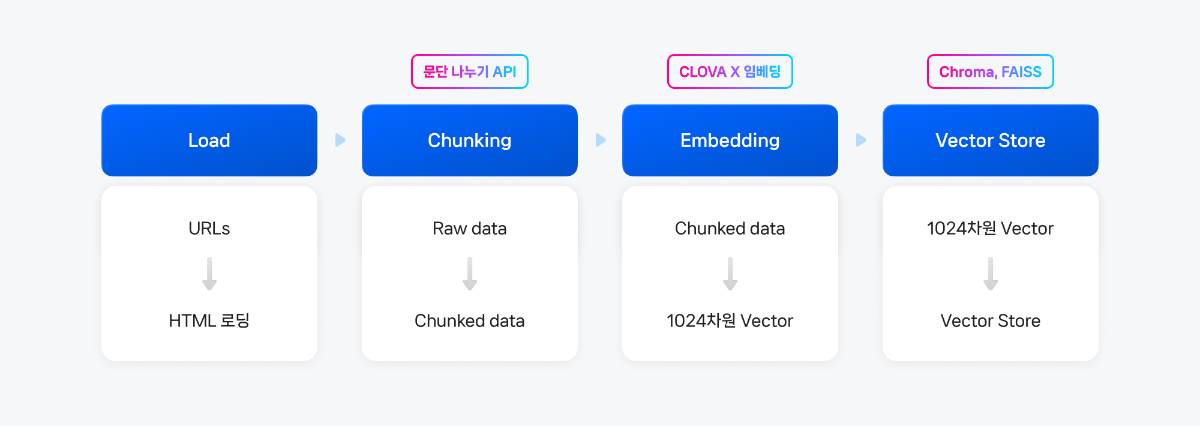
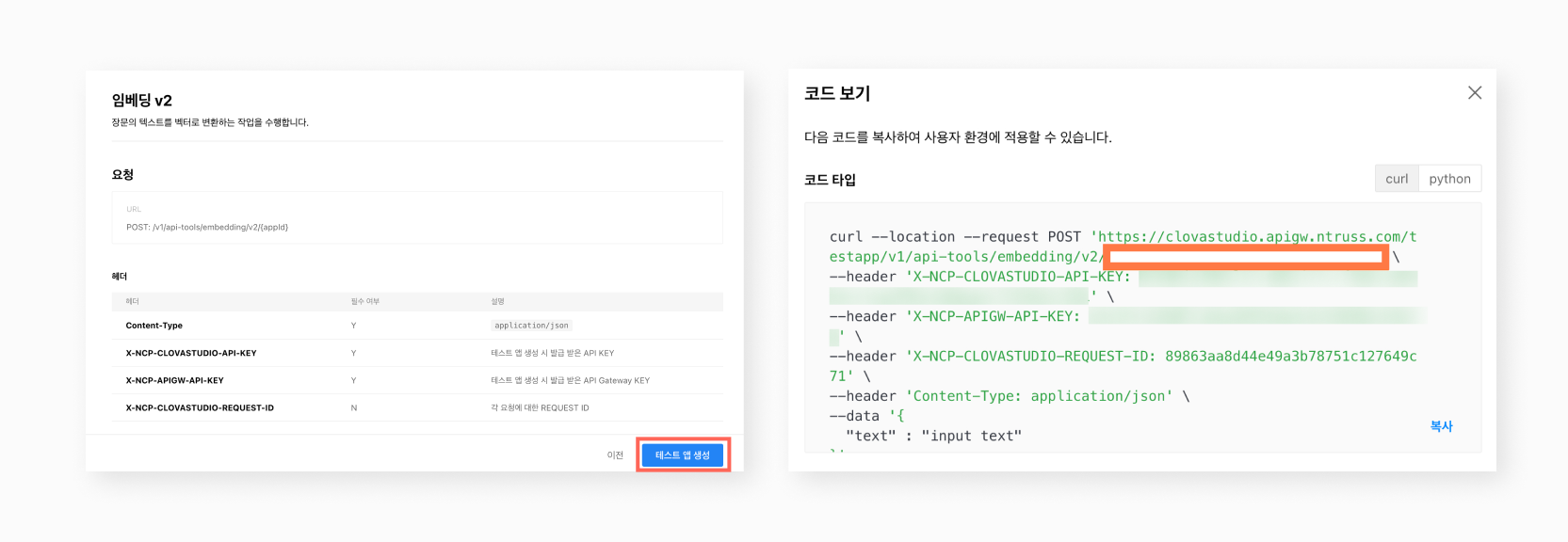
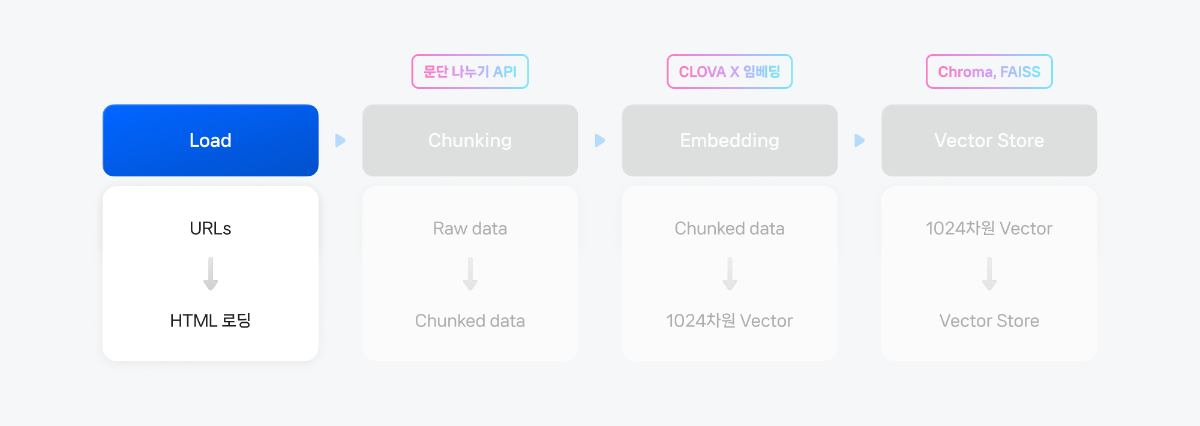
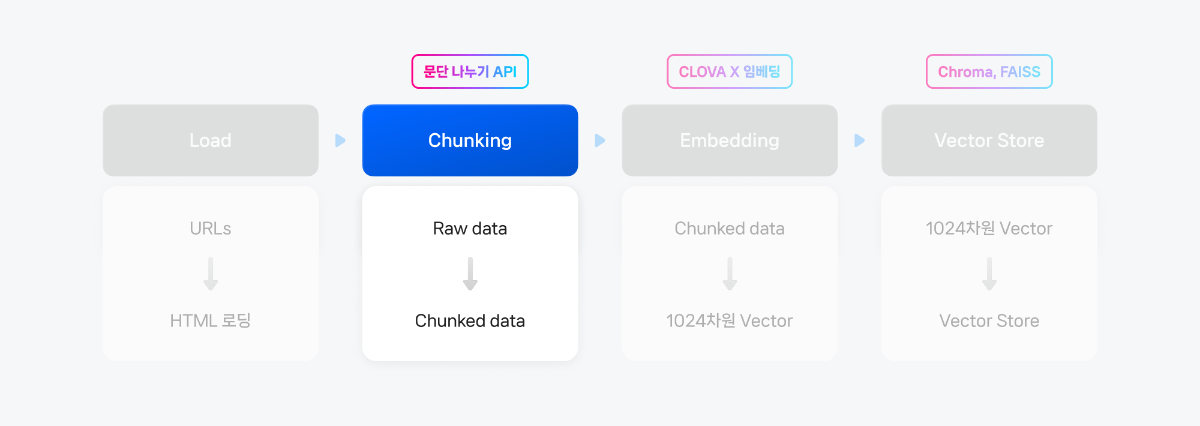
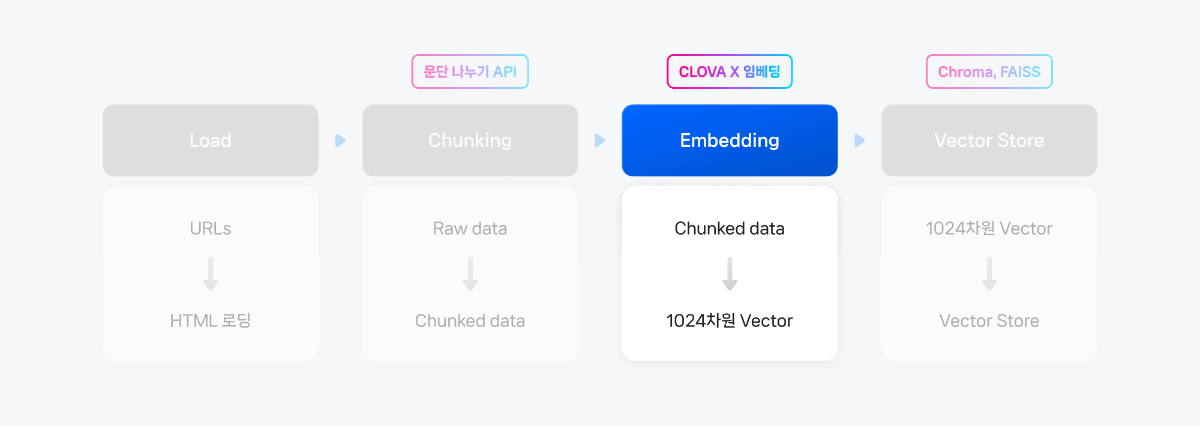
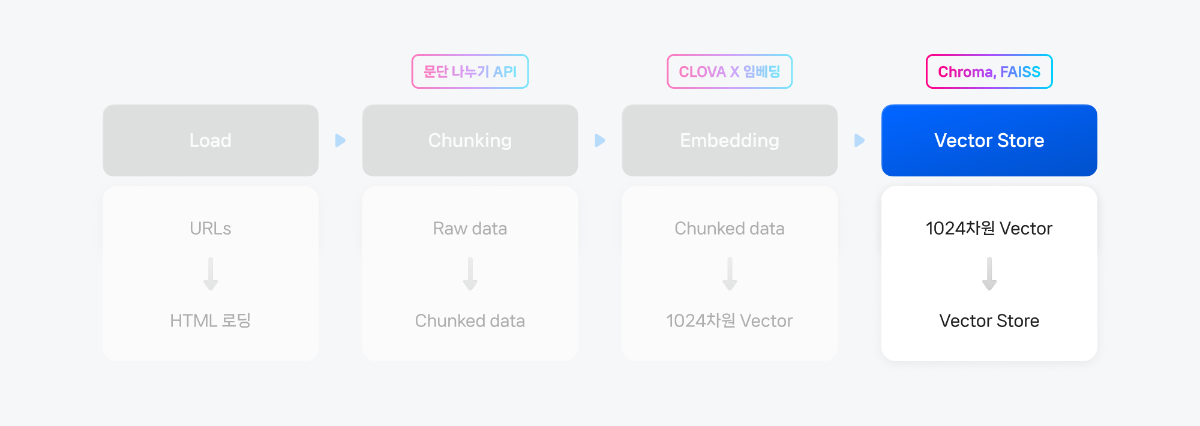
글로벌 AI 생태계와의 연결: CLOVA Studio가 OpenAI 호환 API를 지원하는 이유 (OpenAI compatibility)
in 활용법 & Cookbook
Posted
글로벌 AI 모델 API 생태계와의 연결성
AI 서비스 개발에서 OpenAI API, 특히 Chat Completions API 형식은 사실상 업계 표준으로 자리 잡았습니다. 수많은 오픈소스 프레임워크와 개발 도구들이 OpenAI 호환 API(OpenAI Compatible API)를 기본 인터페이스로 채택하고 있으며, 개발자들 역시 이 환경에 익숙해져 있습니다. CLOVA Studio가 이번에 OpenAI 호환 API를 제공하는 것 역시 이런 흐름을 반영한 결과입니다. OpenAI 중심의 글로벌 AI 생태계와 손쉽게 연결되도록 지원해 HyperCLOVA X 모델을 더 쉽게 쓸 수 있게 하는 것이죠.
실제로 오픈소스 커뮤니티를 살펴보면 LLM 서빙 프레임워크인 vLLM, Ollama, LM Studio 등에서 OpenAI 호환 API를 지원하는 것을 볼 수 있고, AI 어플리케이션 및 에이전트 개발 프레임워크인 LlamaIndex, AutoGen, CrewAI 등은 OpenAI 호환 API가 있는 경우 별도의 연동 구현 없이도 활용이 가능합니다. LangChain이나 LangGraph 역시 마찬가지이지만, 이 경우 최근 출시한 CLOVA Studio 공식 연동 패키지인 langchain-naver 이용을 권장합니다. (링크)
CLOVA Studio가 OpenAI 호환 API를 지원함으로써 사용자들은 이처럼 광범위한 생태계에 곧바로 연결할 수 있습니다. 덕분에 기존 환경을 최대한 유지하면서도 HyperCLOVA X 기반의 AI 서비스와 애플리케이션을 손쉽게 개발할 수 있게 된 것이죠.
개발 편의성: 손쉬운 통합 및 이전 개발
CLOVA Studio의 OpenAI 호환 API를 사용하면 OpenAI가 공식 제공하는 SDK는 물론, 오픈소스 커뮤니티에서 제공하는 다양한 SDK도 그대로 활용할 수 있습니다. OpenAI는 Python, JavaScript, Java, Go, .NET 등 여러 언어용 SDK를 공식 지원하고 있으며, CLOVA Studio 역시 일부 정보만 수정하면 동일한 코드 베이스에서 바로 적용할 수 있습니다. 또한 오픈소스 커뮤니티에는 Kotlin, C++, PHP 등 더 다양한 언어용 SDK도 준비돼 있으니, 필요하다면 지원 언어 및 SDK 목록을 참고해 보시기 바랍니다.
아래를 참고하여 기존 OpenAI SDK 기반의 코드 그대로 API 키, 엔드포인트, 모델명만 변경하여 HyperCLOVA X 모델을 호출해보세요!
python
javascript/typescript
이처럼 CLOVA Studio의 OpenAI 호환 API를 활용하면 해당 API를 기반으로 구축된 서비스에서 최소한의 수정으로 CLOVA Studio의 HyperCLOVA X 모델을 바로 호출할 수 있습니다. 기존 코드 베이스를 거의 그대로 유지할 수 있기 때문에, 새로 개발하거나 전환할 때 개발 부담이 최소화됩니다. 이러한 호환성 덕분에 쿼리별로 모델을 선택하거나 장애 발생 시 다른 LLM으로 우회하는 등 멀티 LLM 기반의 서비스 구조도 쉽게 구현할 수 있습니다. 즉, 단순히 새로운 모델을 쓰는 데 그치지 않고, 운영 환경에서도 탄력적이고 유연한 아키텍처를 구성할 수 있게 됩니다.
지원 범위
CLOVA Studio는 아래와 같이 Chat Completions, 임베딩 등 주요 API에서 OpenAI 호환성을 제공합니다.
/chat/completions (POST)/embeddings (POST)/models (GET)아래는 Chat Completions API의 호환성 표입니다. CLOVA Studio의 OpenAI 호환 Chat Completion API에서 사용 가능한 필드 목록을 확인할 수 있습니다.
(2025년 5월 기준) 앞으로도 새로운 기능이 지속적으로 추가되면서 지원 범위가 확장될 예정이니 참고해 주시기 바랍니다.
modelmessagesstreamtoolstool_choicetemperaturemax_tokens(기본값: 512)max_completion_tokens(기본값: 512)top_pstopseedfrequency_penaltypresence_penaltyresponse_formatstorereasoning_effortmetadatalogit_biaslogprobstop_logprobsnmodalitiespredictionaudioservice_tierstream_optionsparallel_tool_callsusertop_krepeat_penaltyrepetition_penalty비즈니스 관점: 경쟁력 강화와 고객 선택지 확대
CLOVA Studio의 OpenAI 호환 API 지원은 새로운 AI 플랫폼을 검토하거나 기존 서비스를 유지보수하는 경우 실질적인 이점을 제공합니다. 특히 OpenAI API로 이미 구축된 시스템의 경우, API 키와 엔드포인트, 모델명만 변경하면 CLOVA Studio의 HyperCLOVA X 모델로 바로 전환할 수 있어 재개발 비용과 리스크를 크게 줄일 수 있습니다. 새로운 모델을 도입하면서 코드 전체를 뜯어고칠 필요 없이 기존 코드 베이스를 그대로 유지할 수 있다는 점은 실무에서 커다란 장점입니다.
또한 이 호환성 덕분에 멀티 LLM 기반의 서비스도 손쉽게 구성할 수 있습니다. 예를 들어 OpenAI의 모델과 CLOVA Studio의 HyperCLOVA X를 동시에 활용해 쿼리별로 최적의 모델을 선택하거나, 특정 상황에서 자동으로 다른 모델로 우회하는 폴백(fallback) 시나리오를 구현할 수도 있습니다. API 스펙이 동일하기 때문에 로직 상 분기 처리만 추가하면 이런 구조를 빠르게 적용할 수 있고, 한쪽 모델에 문제가 생겼을 때 서비스 연속성을 유지할 수 있다는 점에서 운영 안정성도 크게 향상됩니다.
데이터 프라이버시 이슈나 비용 문제 등으로 OpenAI 모델이 아닌 다른 모델을 고려해야 하는 경우에도 CLOVA Studio는 HyperCLOVA X라는 한국어 특화 모델을 제공하며, OpenAI와 거의 동일한 방식으로 사용할 수 있어 전환 부담이 적습니다. 결과적으로 이 호환성은 단순히 API 연동 편의를 넘어, 전환과 도입 리스크를 낮추고 서비스 구조의 유연성을 확보하며, 장기적인 유지보수 효율성까지 높여주는 실질적인 이점을 제공합니다. 개발팀 입장에서는 더 많은 선택지를 확보하고 상황에 맞게 빠르게 대응할 수 있다는 점이 큰 강점으로 작용할 것입니다.
마치며
이번 OpenAI 호환 API 지원은 결국 더 많은 개발자가 HyperCLOVA X를 손쉽게 활용할 수 있도록 마련됐습니다. 전 세계적으로 통용되는 표준에 맞춰 생태계와의 연결성을 확보하고, 기존 코드를 거의 그대로 활용할 수 있게 하여 개발 편의성을 극대화했습니다. 이를 통해 새로운 AI 플랫폼 도입에 따르는 부담을 낮추고, 서비스 전환이나 멀티 LLM 구성도 훨씬 유연하게 대응할 수 있게 되었습니다. 결국 이 호환성은 개발자의 시간을 아끼고 더 빠르게 실험하고 혁신할 수 있는 환경을 만들어 줍니다. CLOVA Studio는 앞으로도 개방성과 실용성을 바탕으로 개발자와 서비스 운영자 모두에게 매력적인 플랫폼으로 자리 잡아갈 것입니다.
오픈AI 호환성 가이드 링크 : https://api.ncloud-docs.com/docs/clovastudio-openaicompatibility