CLOVA Studio 운영자5
-
게시글
6 -
첫 방문
-
최근 방문
-
Days Won
1
CLOVA Studio 운영자5's Achievements
")





-
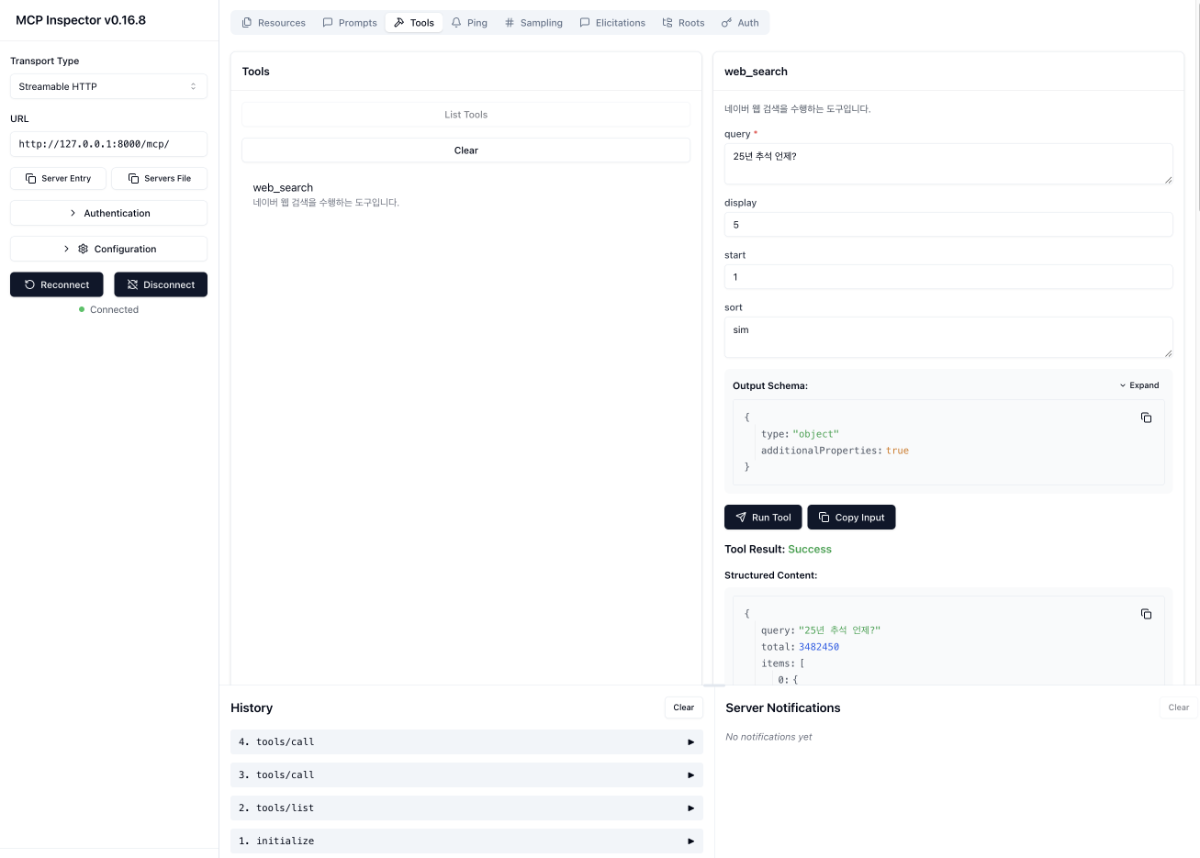
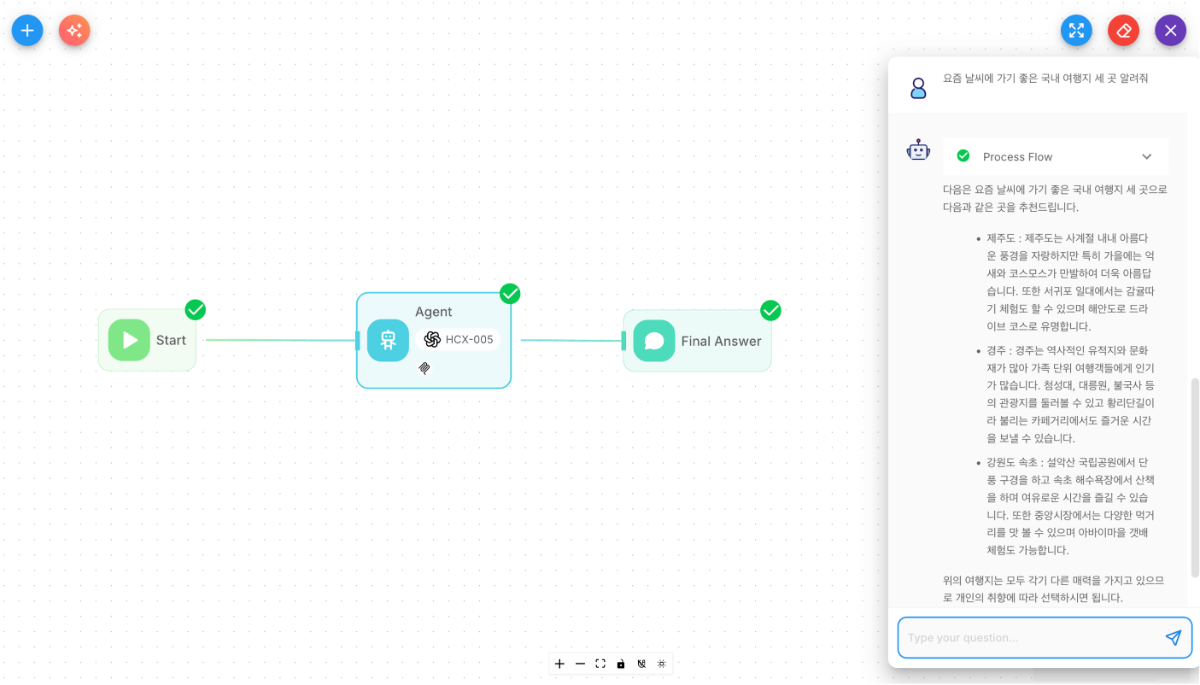
들어가며 실제 서비스 운영 단계에서 MCP 서버를 안정적으로 관리하고, 다양한 환경에서 효율적으로 확장할 수 있는 방법을 이해하는 것이 중요합니다. 또한 CLOVA Studio 모델을 기반으로 손쉽게 MCP 연동 프로토타입을 구현하는 방법도 함께 익혀두면 좋습니다. 마지막 4부에서는 MCP Inspector를 활용한 서버 디버깅, Flowise를 통한 시각적 운영 및 테스트, 그리고 MCP 서버를 작성하는 가이드를 다룹니다. 이러한 실전 팁을 통해 HyperCLOVA X와 MCP를 함께 활용해 더 유연하고 효율적인 서비스 환경을 구축해 볼 수 있습니다. MCP 실전 쿡북 4부작 시리즈 ✔︎ (1부) LangChain에서 네이버 검색 도구 연결하기 링크 ✔︎ (2부) 세션 관리와 컨텍스트 유지 전략 링크 ✔︎ (3부) OAuth 인증이 통합된 MCP 서버 구축하기 링크 ✔︎ (4부) 운영과 확장을 위한 다양한 팁 1. MCP Inspector로 서버 검증하기 MCP Inspector는 Anthropic에서 제공하는 MCP 서버 테스트·디버깅 도구입니다. GUI 환경에서 서버와 연결하여 도구 목록 확인, 도구 호출 테스트, 스트리밍 이벤트 모니터링 등을 쉽게 수행할 수 있습니다. 아래 명령어를 터미널에서 실행하면 브라우저가 자동으로 열립니다. npx @modelcontextprotocol/inspector 브라우저가 열리면 아래 절차에 따라 간단하게 MCP Inspector를 살펴볼 수 있습니다. 서버 연결 (1부) LangChain에서 네이버 검색 도구 연결하기에서 만든 MCP 서버를 연결합니다. 좌측 패널에서 다음의 값을 입력한 후, Connect 버튼을 클릭합니다. Transport Type: Streamable HTTP URL: http://127.0.0.1:8000/mcp/ 도구 목록 확인 상단 메뉴에서 Tools를 선택하고 [List Tools] 버튼을 클릭합니다. 등록된 도구 목록이 표시되며, MCP 서버에 정의된 도구들을 확인할 수 있습니다. 도구 호출 테스트 도구 목록에서 도구를 선택한 후, 우측 입력 영역에 요청 파라미터를 입력하고 실행합니다. 응답이 우측 패널에 실시간으로 표시됩니다. 다음 이미지는 MCP Inspector에서 서버 연결 후 도구 목록을 조회하고, 특정 도구를 실행한 화면 예시입니다. MCP Inspector는 이러한 단순한 호출 테스트 외에도 리소스 조회, 스트리밍 이벤트 모니터링 등의 기능을 지원하므로, MCP 서버를 다양한 방식으로 검증하고 디버깅하는 데 활용할 수 있습니다. 2. Flowise로 노코드 클라이언트 구성하기 Flowise는 MCP 서버와 연결하여 시각적 인터페이스에서 도구를 구성하고 실행할 수 있는 노코드 기반 클라이언트입니다. 기본적으로 MCP 서버와 HTTP 기반으로 통신하며, STDIO로 연결하려면 로컬 환경에 설치된 Flowise로 실행해야 합니다. 또한 Flowise에서는 OpenAI 호환 모델을 연결할 수 있으며, CLOVA Studio의 HCX-005 모델을 이용할 수 있습니다. 단, HCX-007 모델은 현재 일부 파라미터가 호환되지 않아서 연동이 불가능합니다. Flowise 계정 생성 Flowise 예제를 실행하려면 계정 생성이 필요합니다. 다만, Flowise는 필수 구성 요소가 아니며, 선택적으로 활용할 수 있습니다. 클라우드 사용: Flowise에 가입하여 계정을 생성하면 바로 이용할 수 있습니다. 로컬 설치: Node.js 환경에서 다음 명령어로 설치 후 실행할 수 있습니다. 자세한 내용은 Flowise GitHub 문서를 참고해 주세요. npm install -g flowise npx flowise start 워크플로우 생성 절차 다음 절차를 따라서 워크플로우를 생성합니다. Agentflows 시작 Agentflows에서 우측 상단의 [+ Add New] 버튼을 클릭합니다. 노드 추가 좌측 상단의 버튼을 클릭하여 Agent 노드를 드래그하여 추가합니다. 동일한 방법으로 Direct Reply 노드를 드래그하여 추가합니다. 노드 연결 Start, Agent, Direct Reply 순으로 드래그하여 연결합니다. Agent 노드 설정 Agent 노드를 더블 클릭해 노출되는 모달에서 아래 값을 입력합니다. Model: ChatOpenAI Custom ChatOpenAI Custom Parameters Connect Credential: Create New 선택 후 Credential Name을 입력하고 OpenAI API Key에는 CLOVA Studio에서 발급받은 API Key 입력 Model Name: HCX-005 BasePath: https://clovastudio.stream.ntruss.com/v1/openai Messages Message1 Role: System Content: 당신은 친절한 AI 어시스턴트입니다. 사용자의 질문에 대해 신뢰할 수 있는 정보만 근거로 삼아 답변하세요. Message2 Role: User Content: {{question}} Tools Tool: Custom MCP Custom MCP Parameters MCP Server Config: 로컬 환경에서 Flowise를 실행하는 경우에는 아래 값을 입력합니다. 만약 Flowise 클라우드(웹) 환경에서 실행한다면, ngrok 등을 통해 외부 접근이 가능한 URL을 설정해야 합니다. { "url": "http://127.0.0.1:8000/mcp/", "headers": { "Accept": "application/json, text/event-stream", "Content-Type": "application/json" } } Avaliable Actions: 우측의 새로고침 아이콘 클릭한 뒤 도구 선택 Direct Reply 노드 설정 Direct Reply 노드를 더블 클릭해 노출되는 모달에서 아래 값을 입력합니다. {{ agentAgentflow_0 }} 워크플로우 저장 및 실행 우측 상단의 저장 아이콘을 클릭해 워크플로우를 저장합니다. 메시지 아이콘을 클릭해 대화를 실행합니다. 워크플로우 실행 화면 3. MCP 도구 파라미터 설명과 타입 정의하기 파라미터 타입 정의 PEP 484 및 604 타입 힌트로 각 파라미터의 타입을 명시할 수 있습니다. 파이썬 기본 타입부터 일반적인 Pydantic 호환 타입을 대부분 사용할 수 있습니다. from fastmcp import FastMCP from typing import Literal mcp = FastMCP("Example") @mcp.tool def your_tool( param_1: str, # 문자열 param_2: str | int, # 문자열 또는 정수 param_3: Literal["A", "B"], # "A" 또는 "B"만 허용 param_4: list[str] | None # 문자열 리스트 또는 None ) -> dict: # ... return {"ok": True} 필수 및 선택 파라미터 파라미터에 기본값이 없으면 필수(required), 기본값이 있으면 선택(optional) 인자로 스키마에 정의됩니다. LLM이 이 스키마를 참고해 호출 인자를 구성합니다. from fastmcp import FastMCP from typing import Literal mcp = FastMCP("Example") @mcp.tool def your_tool( # 기본값이 없으므로 스키마에서 required로 포함됨(LLM이 반드시 생성해야만 함) param_1: str, # 필수 파라미터: 문자열. 기본값 없음 # 기본값이 있으므로 required 아님. 모든 문자열 또는 정수 허용되며, 미지정 시 "auto" param_2: str | int = "auto", # 선택 파라미터: string | int. 기본값 "auto" # 기본값이 없으므로 스키마에서 required로 포함됨. 값은 "A" 또는 "B" 중 하나만 허용 param_3: Literal["A", "B"], # 필수 파라미터: "A" 또는 "B"만 허용. 기본값 없음 # 기본값이 있으므로 required 아님. 문자열 리스트 또는 None 허용, 미지정 시 None param_4: list[str] | None = None # 선택 파라미터: list[str] 또는 None ) -> dict: # ... return {"ok": True} 파라미터 역할 정의 파라미터별 역할을 정의하기 위해, typing.Annotated를 사용할 수 있습니다. 이후 도구 스키마의 description 필드로 포함되어, LLM이 각 파라미터의 의미를 더 정확히 이해할 수 있도록 돕습니다. from fastmcp import FastMCP from typing import Literal from typing import Annotated mcp = FastMCP("Example") @mcp.tool def your_tool( param_1: Annotated[str, "파라미터 설명 1"], param_2: Annotated[str | int, "파라미터 설명 2"] = "auto", param_3: Annotated[Literal["A", "B"], "파라미터 설명 3"], param_4: Annotated[list[str] | None, "파라미터 설명 4"] = None ) -> dict: # ... return {"ok": True} 특정 파라미터 제외 exclude_args를 사용하면 특정 파라미터를 도구 스키마에서 제외하여 LLM이 해당 값을 생성하지 않도록 할 수 있습니다. 주로 user_id, auth_token처럼 LLM에 노출되면 안되거나, 호출 때마다 서버가 직접 주입해야 하는 값에 사용합니다. from fastmcp import FastMCP from typing import Literal from typing import Annotated mcp = FastMCP("Example") @mcp.tool( name="your_tool", exclude_args=["param1"] ) def your_tool( param_1: Annotated[str, "파라미터 설명 1"], param_2: Annotated[str | int, "파라미터 설명 2"] = "auto", param_3: Annotated[Literal["A", "B"], "파라미터 설명 3"], param_4: Annotated[list[str] | None, "파라미터 설명 4"] = None ) -> dict: # ... return {"ok": True} 4. 개인화 도구 설계하기 (3부) MCP 실전 쿡북: OAuth 인증이 통합된 MCP 서버 구축하기에서 설명한 대로, 사용자가 OAuth 인증을 완료하면 MCP 서버가 액세스 토큰을 안전하게 저장하고, 이후 AI 어시스턴트를 통한 요청이 들어올 때마다 인증 미들웨어가 자동으로 해당 사용자의 토큰을 찾아 제공합니다. 개발자는 복잡한 인증 과정을 신경 쓸 필요 없이 get_access_token()만 호출하면 되며, 이 토큰은 Bearer {token} 형식으로 API 요청에 자동으로 포함됩니다. 파이썬의 contextvars 덕분에 여러 사용자가 동시에 요청해도 토큰이 섞이지 않아 안전합니다. 이 구조를 활용하면 OAuth 토큰을 안전하게 재사용하면서 사용자별 맞춤 기능을 쉽게 추가할 수 있으며, 네이버뿐만 아니라 구글, 카카오, GitHub 등 OAuth를 지원하는 모든 개인화 서비스에 동일한 방식으로 MCP 서버를 구성할 수 있습니다. import os from fastmcp import FastMCP from naver import NaverProvider from dotenv import load_dotenv load_dotenv() # 환경 변수 로드 NAVER_CLIENT_ID = os.getenv("NAVER_CLIENT_ID") NAVER_CLIENT_SECRET = os.getenv("NAVER_CLIENT_SECRET") BASE_URL = os.getenv("BASE_URL") # OAuth Provider 초기화 auth = NaverProvider( client_id=NAVER_CLIENT_ID, client_secret=NAVER_CLIENT_SECRET, base_url=BASE_URL ) # MCP 서버 생성 mcp = FastMCP(name="Naver Calendar MCP", auth=auth) # 도구 정의 @mcp.tool(description="네이버 캘린더에 일정을 추가합니다.") async def create_calendar_schedule( title: str, start_datetime: str, end_datetime: str ) -> dict: from fastmcp.server.dependencies import get_access_token import urllib.request # 1. 액세스 토큰 가져오기 token = get_access_token() access_token = token.token # 2. API 요청 준비 header = "Bearer " + access_token url = "https://openapi.naver.com/calendar/createSchedule.json" # 3. iCalendar 문자열 생성 schedule_ical = f"""BEGIN:VCALENDAR VERSION:2.0 PRODID:Naver Calendar BEGIN:VEVENT DTSTART;TZID=Asia/Seoul:{start_datetime} DTEND;TZID=Asia/Seoul:{end_datetime} SUMMARY:{title} END:VEVENT END:VCALENDAR""" # 4. API 요청 전송 data = f"calendarId=defaultCalendarId&scheduleIcalString={schedule_ical}" request = urllib.request.Request(url, data=data.encode("utf-8")) request.add_header("Authorization", header) try: response = urllib.request.urlopen(request) return { "success": True, "message": "일정이 추가되었습니다." } except Exception as e: return { "success": False, "error": str(e) } # 서버 실행 if __name__ == "__main__": mcp.run(transport="streamable-http", path="/mcp") 마무리 1부(서버·클라이언트 연결), 2부(세션·컨텍스트 관리), 3부(OAuth 2.0 인증 예시)를 바탕으로 4부에서는 MCP 운영 효율을 높이는 여러 방법을 다뤘습니다. MCP의 특성을 명확히 이해하고, 서비스 목적에 맞게 설계·적용한다면, 보다 안정적이고 확장 가능한 MCP 생태계를 구축할 수 있습니다. 이제 CLOVA Studio 모델을 활용해, 직접 자신만의 MCP 서버 연동 워크플로우를 만들어 보시길 바랍니다. 🚀 MCP 실전 쿡북 4부작 시리즈 ✔︎ (1부) LangChain에서 네이버 검색 도구 연결하기 링크 ✔︎ (2부) 세션 관리와 컨텍스트 유지 전략 링크 ✔︎ (3부) OAuth 인증이 통합된 MCP 서버 구축하기 링크 ✔︎ (4부) 운영과 확장을 위한 다양한 팁

-
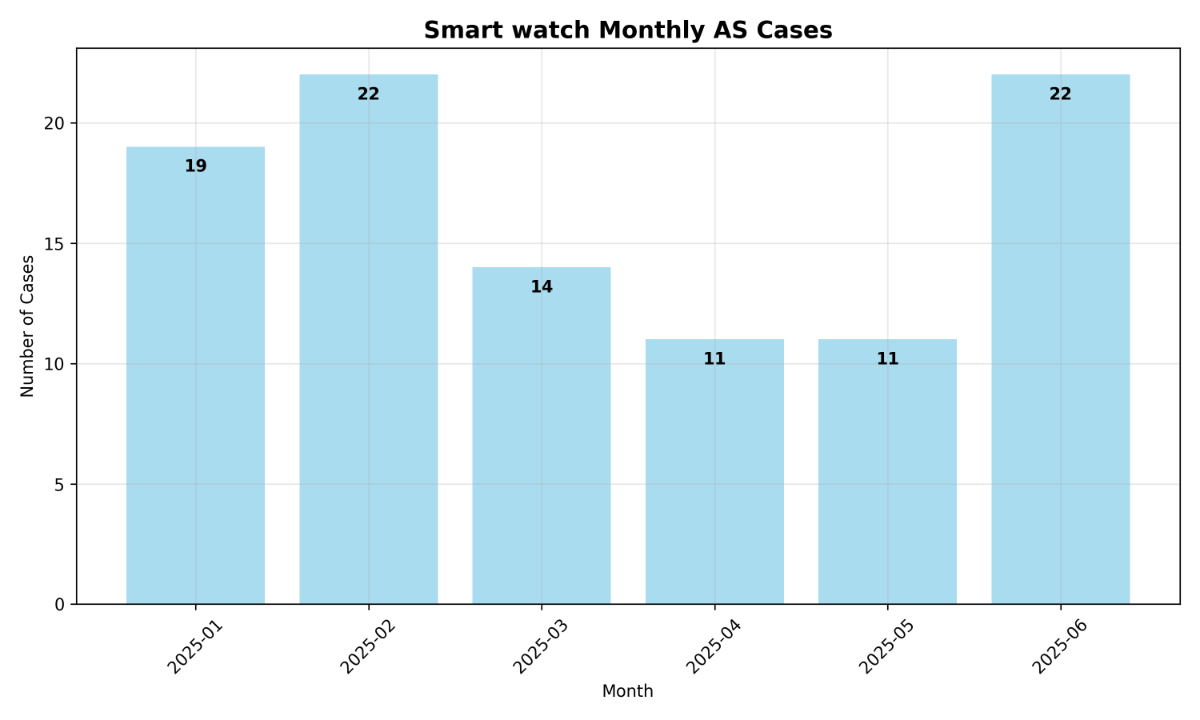
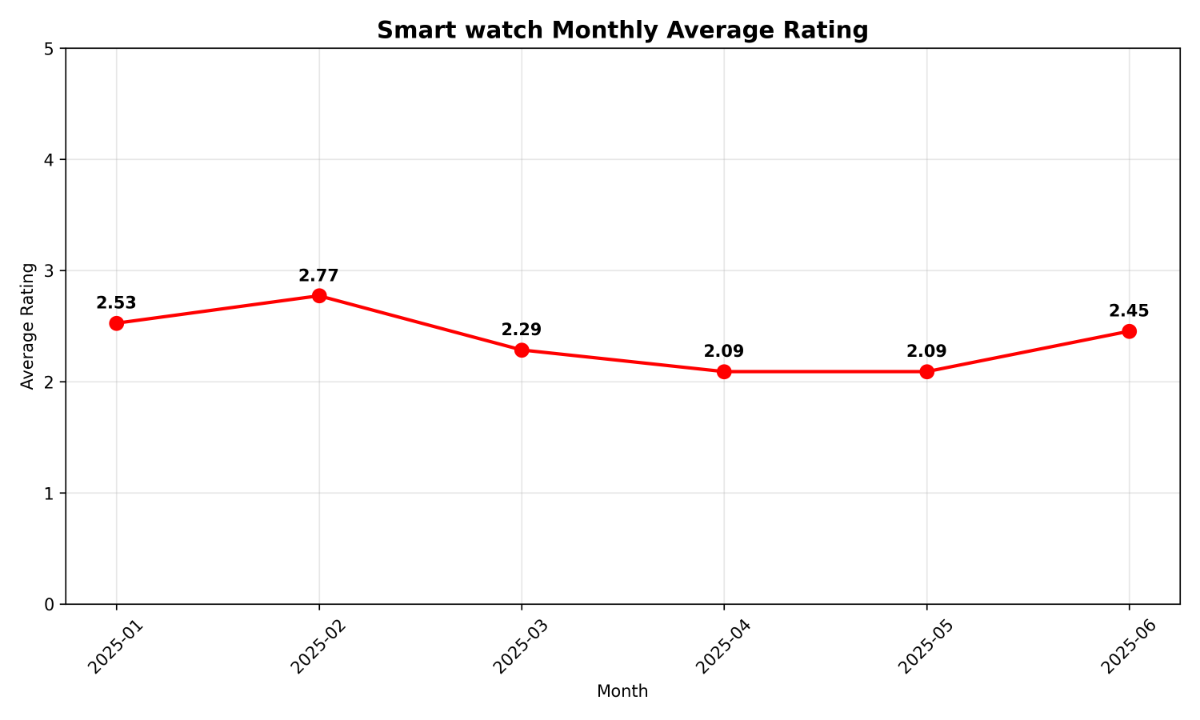
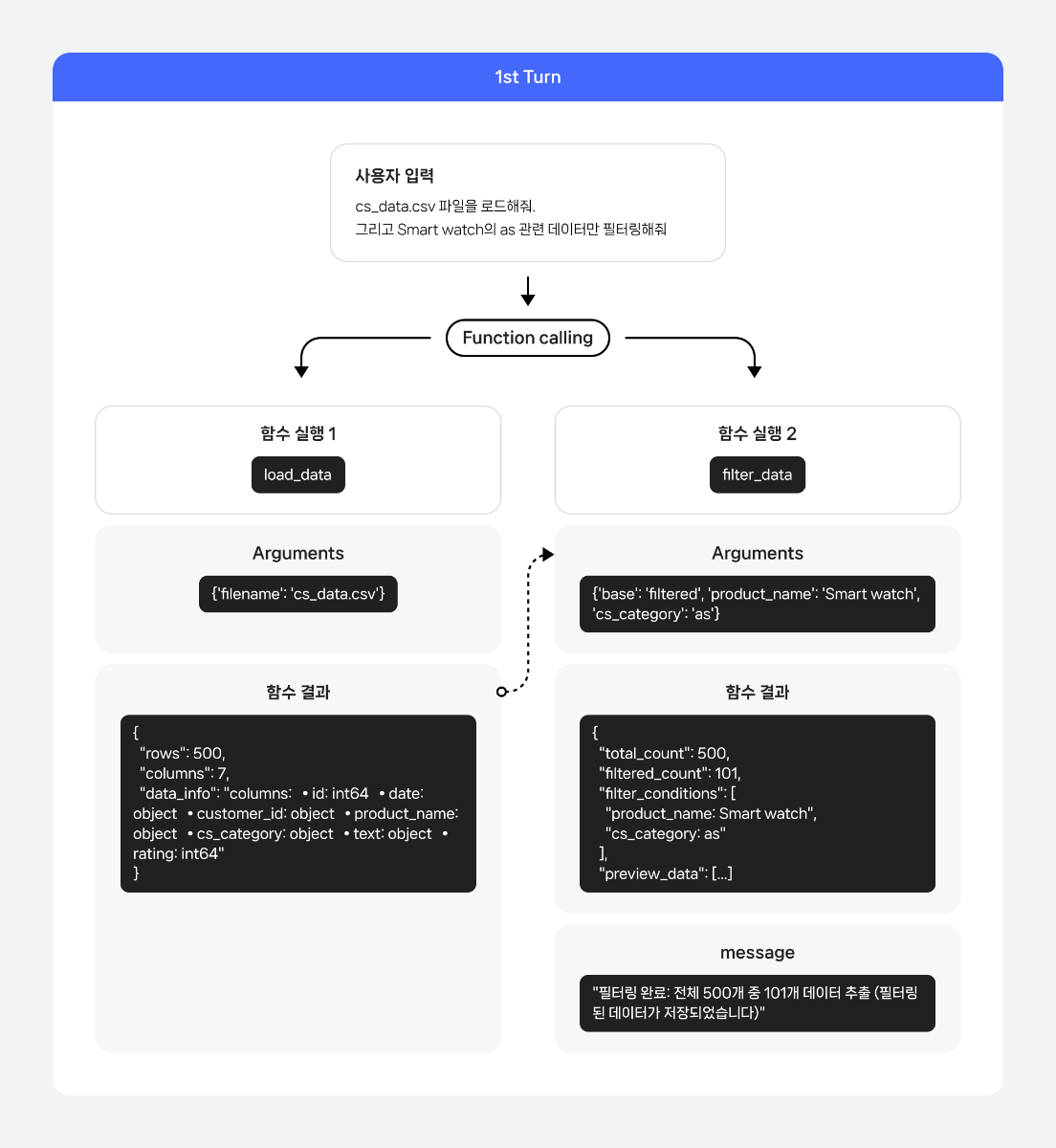
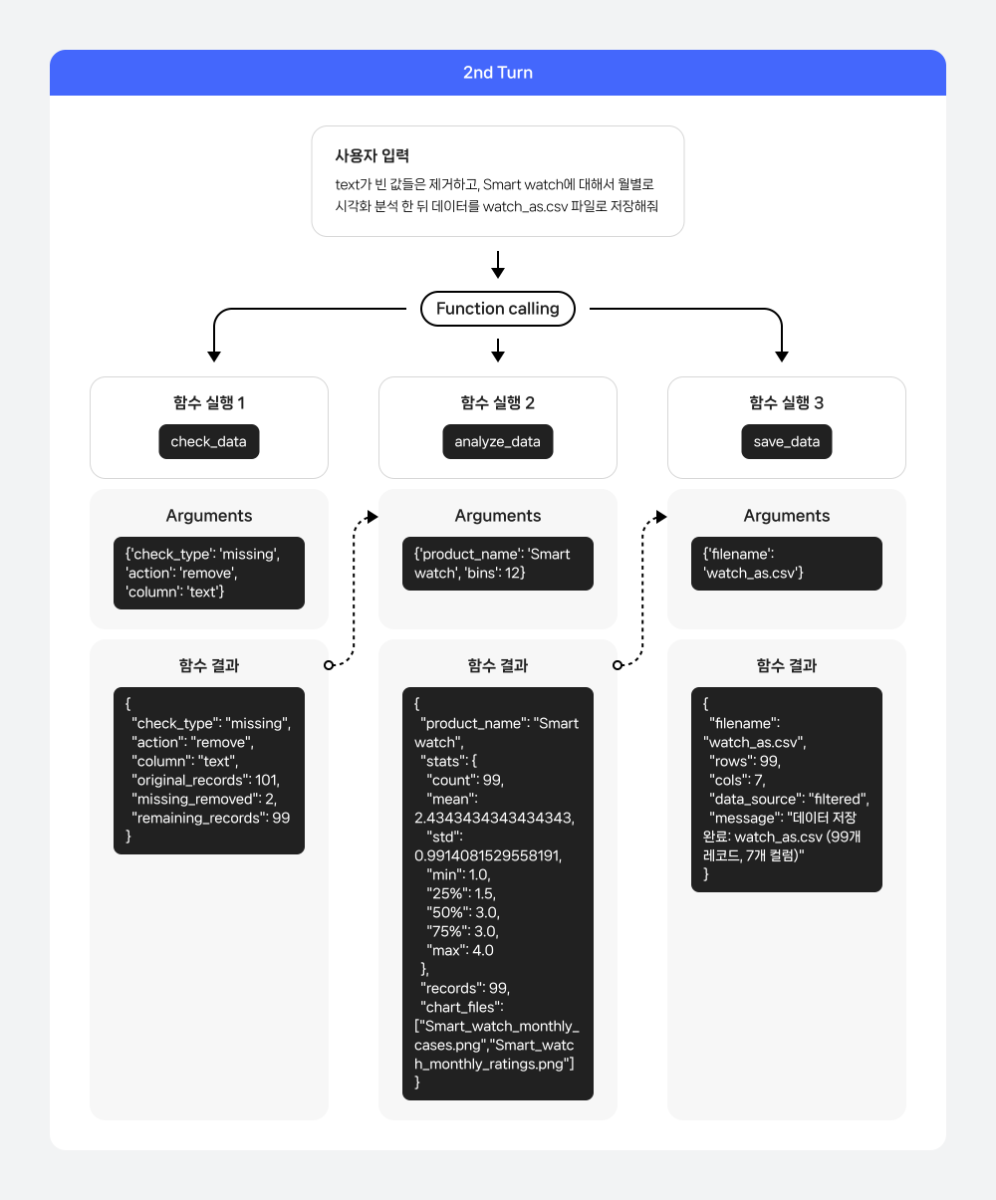
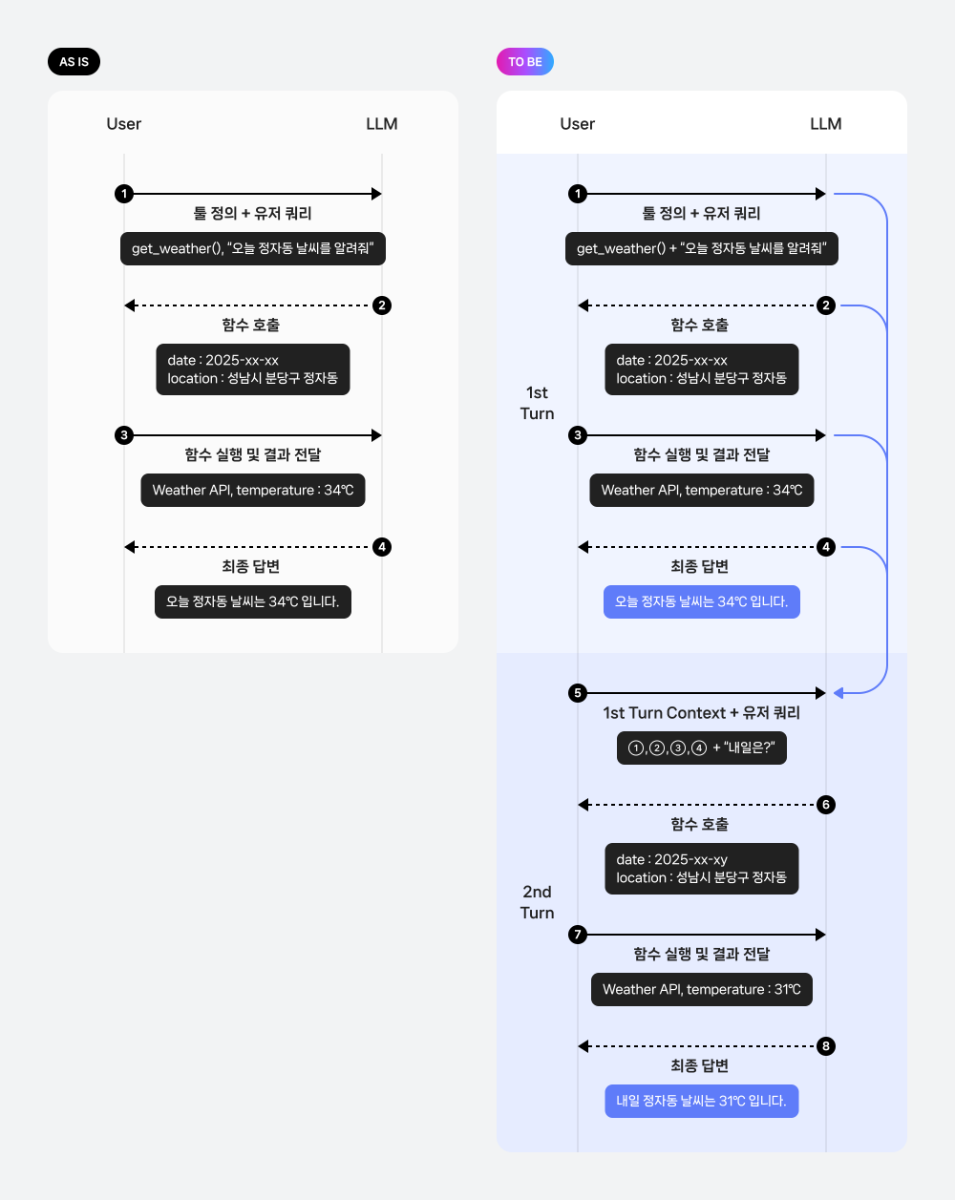
 들어가며 Function calling은 LLM이 사용자의 요청을 처리하기 위해 특정 도구를 직접 호출할 수 있도록 해주는 기능입니다. 이를 활용해 목적에 맞는 도구를 정의하고, 실시간 정보 처리나 외부 데이터 연동, 복잡한 계산 등 기존의 LLM만으로는 해결하기 어려운 작업까지 수행할 수 있습니다. 이번 쿡북에서는 Function calling을 복잡한 멀티 턴 시나리오에 적용하여, 궁극적으로 나만의 데이터 자동 분석 솔루션을 구현하는 방법을 살펴보겠습니다. Function calling의 기본 개념과 활용법에 대한 보다 자세한 내용은 아래 이전 글들을 참고하시기 바랍니다. 당신의 AI에게 행동을 맡겨라: 스킬과 Function Calling Function calling 활용법: LLM으로 실시간 데이터 호출과 액션 수행까지 AI 어시스턴트 제작 레시피: Function calling 활용하기 작동 원리 멀티 턴 최근에는 Function calling이 단일 호출로 끝나는 것이 아니라, 사용자와 LLM간 여러 번의 대화를 주고받으며 복합적인 목표를 달성하는 멀티 턴(multi-turn) 방식이 새로운 트렌드로 자리 잡고 있습니다. 기존의 단일 호출 방식은 "오늘 날씨 어때?"처럼 한 번의 질문에 한 번의 Function calling으로 답을 얻는 간단한 시나리오에 적합합니다. 하지만 실제 사용자의 요청은 "오늘 날씨 알려주고, 비가 오면 우산 챙기라고 알려줘"와 같이 여러 요청이 포함된 멀티 쿼리 형태 혹은 모델의 답변을 보고, 추가적인 호출을 요청하는 멀티 턴 형태의 경우가 대다수입니다. 멀티 턴 방식은 이러한 대화의 맥락을 유지하면서 여러 Function calling을 순차적 또는 병렬적으로 수행할 수 있게 해주며, 이를 통해 더욱 복잡하고 실용적인 작업을 처리할 수 있습니다. 기본 작동 방식: 사용자의 요청을 받은 LLM은 사용 가능한 도구 목록을 확인한 뒤, 어떤 도구를 어떤 파라미터와 함께 사용해야 할지를 판단합니다. 그리고 그 결과를 JSON 형태로 반환합니다. 개발자는 이를 실제 도구 실행에 연결하고, 실행 결과를 다시 LLM에 전달합니다. 멀티 턴 작동 방식: 멀티 턴의 경우 이러한 과정이 한 번의 요청으로 끝나지 않고, 이후 이어지는 사용자 요청에서도 이전 맥락을 참고하여 기능을 수행합니다. 이 과정은 대화가 종료될 때까지 반복됩니다. 함수 실행 자동화 기존의 Function calling 방식은 LLM이 사용자 요청을 분석하여 함수를 호출하고 필요한 파라미터를 담은 JSON 객체를 반환하는 것에 그칩니다. 이 경우, 사용자는 반환된 JSON을 파싱하여 직접 코드를 실행하고, 그 결과를 다시 LLM에게 전달하는 번거로운 과정을 거쳐야 합니다. 이 과정은 다음과 같은 흐름으로 진행됩니다. 사용자 요청 LLM이 함수 및 파라미터 호출 사용자가 직접 해당 함수 코드 실행 결과값 획득 결과값을 LLM에게 다시 전달 LLM이 최종 답변 생성 하지만 이번 쿡북에서 다룰 방식은 이러한 과정을 자동화합니다. 미리 함수 코드를 정의하고, 모델이 함수를 실행할 수 있도록 설계합니다. 따라서 LLM이 함수 호출을 결정하면, 시스템이 사용자의 개입 없이 함수를 실행하고 그 결과를 LLM에게 다시 전달하는 과정을 전부 자동으로 처리합니다. 기존 방식과 비교한 멀티 턴 기반 자동화 파이프라인 구조는 다음과 같습니다. 시나리오 이번 쿡북에서 다룰 시나리오는 주문 상품에 대한 고객 CS 데이터 분석 작업입니다. 시나리오에서는 LLM의 Function calling 기능을 활용하여 복잡하고 반복적인 데이터 분석 작업을 자동화하고, 사용자가 자연어로 던지는 질문에 따라 데이터 분석 시각화 등 다양한 작업 수행 과정을 보여줍니다. 시나리오에서 설계할 도구는 총 5개입니다. LLM은 사용자의 요청을 바탕으로 이 도구들을 적절하게 호출하여 데이터 분석 파이프라인을 구축합니다. load_data: 분석할 CSV 파일을 불러오는 도구 filter_data: 특정 조건에 맞는 데이터만 추출하는 도구 check_data: 데이터의 품질을 검사하는 도구 analyze_data: 고객 평점을 기준으로 다양한 통계 정보를 계산하는 도구 save_data: 분석이 완료된 데이터를 저장하는 도구 단순히 도구를 한 번 호출하는 것이 아니라, 사용자와의 멀티 턴 대화 과정에서 여러 도구를 순차적으로 호출하며 복합적인 분석 작업을 자동으로 수행하는 과정을 보여주는 데 초점을 맞추고 있습니다. 구체적인 CS 데이터 분석 시나리오 파이프라인은 다음과 같습니다. 분석 데이터 분석할 데이터는 구매한 제품에 대한 고객 문의 내용이 담긴 CSV 파일입니다. 이 데이터는 다음과 같은 정보를 포함하고 있습니다. id: 고유 식별자 date: 문의 작성 날짜 customer_id: 고객 ID product_name: 상품명 cs_category: CS 유형 (예: as, payment , exchange, delivery, return) text: 고객의 구체적인 문의 내용 rating: 서비스 만족도 평점 (1~5점) 시나리오 구현 1. 환경 설정 API 토큰 발급은 CLOVA Studio API 가이드를 참조하세요. 2. 파일 생성 생성할 파일 구성은 다음과 같습니다. cookbook/ ├── main.py # 멀티 턴 대화 시나리오 실행 스크립트입니다. ├── fc_core.py # 핵심 함수들이 모인 모듈입니다. function_call()로 load_data/filter_data/analyze_data/check_data/save_data 함수들을 제공합니다. ├── config.py # API 설정과 함수 실행 우선순위를 정의합니다. ├── tool_schema.py # AI가 사용할 도구들의 스키마를 정의합니다. 2.1 config.py config.py는 CLOVA Studio API 연결과 함수 실행 우선순위를 정의하는 설정 파일입니다. 이 파일은 전체 시스템의 핵심 설정을 중앙 집중식으로 관리하여 유지보수성을 높입니다. 실제 사용을 위해서는 본인의 CLOVA Studio API 키를 입력해야 합니다. API_KEY = "YOUR_API_KEY" API_URL = "https://clovastudio.stream.ntruss.com/testapp/v3/chat-completions/HCX-DASH-002" def get_headers() -> dict: return { "Content-Type": "application/json", "Authorization": API_KEY, } # 함수 실행 우선 순위 정의 FUNCTION_PRIORITY = { "load_data": 0, "filter_data": 1, "check_data": 2, "analyze_data": 3, "save_data": 4, } 2.2 tool_schema.py tool_schema.py 는 LLM이 사용할 수 있는 도구의 스키마를 정의하는 파일입니다. LLM이 어떤 함수를 호출할 수 있고 각 함수가 어떤 파라미터를 받는지 명시합니다. 정의할 함수 정보는 다음과 같습니다. load_data: CSV 파일을 로드하는 기본 함수입니다. 'filename'은 필수 파라미터이며, 같은 폴더 내에 해당 이름을 가진 파일이 존재해야 합니다. filter_data: 다양한 조건으로 데이터를 필터링하는 함수입니다. 'base' 파라미터로 필터 적용 대상을 선택할 수 있으며, 각 파라미터들은 해당 열에 명시된 값들을 제공합니다. check_data: 데이터 품질을 검사하고 정리하는 함수입니다. 'check_type'과 'action'은 필수 파라미터로, 검사 유형과 수행할 작업을 지정합니다. analyze_data: 특정 제품의 평점 통계를 분석하고 월별 시각화 차트를 생성하는 분석 함수입니다. 'product_name'은 필수 파라미터이며, 'bins'는 시각화 도구의 구간 수를 지정합니다. save_data: 필터링된 데이터를 CSV 파일로 저장하는 함수입니다. 'filename'은 저장할 파일의 이름을 지정하는 필수 파라미터입니다. def get_tools() -> list: return [ { "type": "function", "function": { "description": "CSV 파일을 로드하고 데이터 정보를 제공합니다.", "name": "load_data", "parameters": { "properties": { "filename": { "type": "string", "description": "업로드할 CSV 파일명 (예: 'data.csv', 'sales.csv')", } }, "required": ["filename"], "type": "object", }, }, }, { "type": "function", "function": { "description": "사용자가 특정 조건의 데이터를 요청할 때 호출합니다.", "name": "filter_data", "parameters": { "properties": { "base": { "type": "string", "enum": ["filtered", "all"], "description": "필터 적용 대상. 'filtered'는 이전 필터링 결과에 추가 필터를 적용하고, 'all'은 전체 데이터에서 새로 필터링합니다. 기본값은 'filtered'입니다.", }, "product_name": {"type": "string"}, "cs_category": { "enum": [ "as", "payment", "exchange", "delivery", "return", ], "type": "string", }, "date_range": {"type": "string"}, "rating_threshold": {"type": "integer"}, "customer_id": {"type": "string"}, }, "required": [], "type": "object", }, }, }, { "type": "function", "function": { "description": "특정 product의 rating 기술통계와 월별 시각화 차트를 생성합니다.", "name": "analyze_data", "parameters": { "properties": { "product_name": {"type": "string"}, "bins": { "type": "integer", "description": "rating 히스토그램 구간 수 (기본값: 12)", }, }, "required": ["product_name"], "type": "object", }, }, }, { "type": "function", "function": { "description": "사용자가 데이터 품질 검사나 정리를 요청할 때 호출합니다.", "name": "check_data", "parameters": { "properties": { "check_type": { "description": "검사 유형 (duplicates: 중복, missing: 결측값)", "enum": ["duplicates", "missing"], "type": "string", }, "action": { "description": "수행할 작업 (check: 확인만, remove: 제거)", "enum": ["check", "remove"], "type": "string", }, "column": { "description": "검사할 컬럼명 (없으면 전체)", "type": "string", }, }, "required": ["check_type", "action"], "type": "object", }, }, }, { "type": "function", "function": { "description": "사용자가 특정 파일명으로 데이터를 저장하라고 요청할 때 호출합니다. 필터링된 데이터를 CSV 형식으로 저장합니다.", "name": "save_data", "parameters": { "properties": { "filename": { "description": "저장할 CSV 파일명 (예: 'result.csv')", "type": "string", }, }, "required": ["filename"], "type": "object", }, }, }, ] 2.3. fc_core.py fc_core.py는 멀티 턴, Function calling, 함수 실행 자동화 등 전체 시스템의 핵심 기능을 담당하는 파일입니다. 이 파일은 크게 멀티 턴 대화를 위한 컨텍스트 관리, Function calling 처리, 그리고 실행 함수 구현 세 부분으로 나뉩니다. 2.3.1. 멀티 턴 정보 전달 멀티 턴 대화에서 이전 턴의 정보를 다음 턴에 전달하기 위한 컨텍스트 관리 함수들입니다. build_summary 함수는 현재 대화 상태를 요약하여 문자열로 반환합니다. 데이터 로드 정보, 최근 필터링 결과, 데이터 검사 결과 등 함수 실행 결과를 포함하여 LLM이 이전 턴의 작업 내용을 이해할 수 있도록 도와줍니다. append_context 함수는 앞서 생성된 컨텍스트 요약을 메시지 히스토리에 추가합니다. 이 함수는 다음 턴 시작 전에 호출되어 LLM에게 이전 턴의 작업 결과를 전달합니다. import json import os from typing import Any, Dict, List import pandas as pd import numpy as np import requests import matplotlib matplotlib.use('Agg') import matplotlib.pyplot as plt from config import get_headers, API_URL, FUNCTION_PRIORITY current_df = None # load_data로 불러온 원본 데이터를 의미합니다. filtered_df = None # 다른 함수 실행으로 인해 필터링된 데이터를 의미합니다. conversation_state = { "data_loaded": False, "filename": None, "rows": 0, "columns": 0, "last_filter": None, } def build_summary() -> str: parts: List[str] = [] if conversation_state.get("data_loaded"): parts.append( f"데이터 로드됨(file={conversation_state.get('filename')}, rows={conversation_state.get('rows')}, cols={conversation_state.get('columns')})" ) lf = conversation_state.get("last_filter") if lf: conds = ", ".join(lf.get("conditions", [])) if lf.get("conditions") else "-" parts.append( f"최근 필터(count={lf.get('filtered_count')}/{lf.get('total_count')}, conds={conds})" ) lc = conversation_state.get("last_check") if lc: check_type = lc.get("type", "") action = lc.get("action", "") column = lc.get("column", "") removed = lc.get("removed", 0) remaining = lc.get("remaining", 0) if check_type == "missing": parts.append(f"결측값 제거({column}: {removed}개 제거, {remaining}개 남음)") elif check_type == "duplicates": parts.append(f"중복 제거({column}: {removed}개 제거, {remaining}개 남음)") return "[context] " + " | ".join(parts) if parts else "" def append_context(messages: List[Dict[str, Any]]) -> None: summary = build_summary() if summary: messages.append({"role": "assistant", "content": summary}) 2.3.2. Function calling 처리 LLM이 사용자 쿼리를 바탕으로 정의된 도구를 호출하는 Function calling 과정을 설계합니다. execute_function 함수는 LLM이 요청한 함수를 실행하는 역할을 합니다. 함수 이름과 파라미터를 받아서 해당하는 실제 함수를 호출하고 결과를 반환합니다. function_call 함수는 멀티 턴 대화의 함수 호출 과정을 보여주는 핵심 함수입니다. 첫 번째 호출을 통해 message와 tool_schema를 LLM에게 전송합니다. LLM이 요청 함수들을 우선순위에 따라 실행합니다. 함수 실행 결과를 LLM에게 전달하여 최종 응답을 생성합니다. 새로운 메시지와 이전 컨텍스트를 포함하여 두 번째 턴을 실행합니다. 1-3 과정을 반복하여 최종 응답을 생성합니다. def execute_function(func_name: str, args: Dict[str, Any]) -> Dict[str, Any]: if func_name == "load_data": return load_data_file(args.get("filename")) if func_name == "filter_data": return filter_data_func(args) if func_name == "analyze_data": return analyze_data_func(args) if func_name == "check_data": return check_data_func(args) if func_name == "save_data": return save_data_func(args) return {"error": f"알 수 없는 함수: {func_name}"} def function_call(messages: List[Dict[str, Any]]) -> Dict[str, Any] | None: from tool_schema import get_tools payload = {"messages": messages, "tools": get_tools(), "toolChoice": "auto"} # 요청 페이로드 생성 try: response = requests.post(API_URL, headers=get_headers(), json=payload, timeout=30) # Tool call 요청 전송 if response.status_code != 200: return None # 응답 코드가 200이 아닌 경우 오류 반환 result = response.json() # 응답 결과 파싱 message = ( result.get("result", {}).get("message", {}) if "result" in result else (result.get("choices", [{}])[0].get("message", {})) ) if not message: return result tool_calls_raw = message.get("toolCalls", message.get("tool_calls", [])) # Tool call 목록 추출 if not tool_calls_raw: return {"message": message} tool_calls = sorted( tool_calls_raw, key=lambda c: FUNCTION_PRIORITY.get(c.get("function", {}).get("name", ""), 99), ) # 우선순위에 따라 정렬 tool_messages: List[Dict[str, Any]] = [] for i, call in enumerate(tool_calls): func_name = call["function"]["name"] args_str = call["function"]["arguments"] call_id = call.get("id", f"call_{i}") # 실행 로그: 어떤 함수가 어떤 arguments로 호출되는지 출력 print(f"\n 함수 실행 {i+1}: {func_name}") print(f"Arguments: {args_str}") try: args = json.loads(args_str) if isinstance(args_str, str) else args_str function_result = execute_function(func_name, args) # 함수 실행 print("함수 결과:") print(json.dumps(function_result, ensure_ascii=False, indent=2)) tool_messages.append( { "role": "tool", "content": json.dumps(function_result, ensure_ascii=False), "tool_call_id": call_id, } ) except Exception: tool_messages.append( { "role": "tool", "content": json.dumps({"error": "함수 실행 실패"}, ensure_ascii=False), "tool_call_id": call_id, } ) # 두 번째 호출 messages.extend(tool_messages) # 원본 메시지에 tool 실행 결과 추가 second_payload = {"messages": messages, "tools": get_tools(), "toolChoice": "auto"} # 두 번째 호출 페이로드 생성 second_response = requests.post( API_URL, headers=get_headers(), json=second_payload, timeout=30 ) # 두 번째 호출 요청 전송 if second_response.status_code != 200: return {"message": message, "has_tool_calls": True} second_result = second_response.json() # 두 번째 호출 결과 파싱 second_message = ( second_result.get("result", {}).get("message", {}) if "result" in second_result else (second_result.get("choices", [{}])[0].get("message", {})) ) return {"message": second_message} if second_message else {"message": message, "has_tool_calls": True} except Exception: return None 2.3.3. 실행 함수 구현 실제 데이터 처리를 담당하는 도구 함수들을 구현합니다. 각 함수는 LLM이 요청하는 구체적인 작업을 직접 수행합니다. load_data_file 함수는 CSV 파일을 읽어서 current_df에 저장하고, 데이터의 기본 정보를 반환합니다. 파일 존재 여부를 확인하고, 컬럼명과 데이터 타입 정보를 생성하여 사용자가 데이터 구조를 파악할 수 있도록 도와줍니다. filter_data_func 함수는 다양한 조건으로 데이터를 필터링합니다. 제품명, 카테고리, 평점, 고객 ID, 날짜 범위 등 다양한 조건을 적용할 수 있습니다. 필터링 결과는 filtered_df에 저장되고, 상위 3개 레코드를 미리보기로 제공합니다. check_data_func 함수는 데이터 품질을 검사하고 정리합니다. 중복 데이터와 결측값을 검사하거나 제거할 수 있으며, 특정 컬럼에 대해서만 작업을 수행할 수도 있습니다. analyze_data_func 함수는 특정 제품의 평점 통계를 분석하고 월별 시각화 차트를 생성합니다. 평점에 대한 기술통계(평균, 표준편차, 최소값, 최대값 등)를 계산하고, 월별 건수와 월별 평균 평점을 시각화한 두 개의 차트 파일을 생성합니다. save_data_func 함수는 필터링된 데이터를 CSV 파일로 저장합니다. 파일 확장자가 .csv가 아닌 경우 자동으로 추가하며, 저장된 파일의 정보와 함께 완료 메시지를 반환합니다. # 함수 정의 def load_data_file(filename: str) -> Dict[str, Any]: global current_df try: current_dir = os.getcwd() file_path = os.path.join(current_dir, filename) if not os.path.exists(file_path): return {"error": "파일을 찾을 수 없습니다"} current_df = pd.read_csv(file_path) # 컬럼명과 타입 정보 생성 df_info = f"columns:\n" for i, col in enumerate(current_df.columns): dtype = str(current_df[col].dtype) df_info += f" • {col}: {dtype}" if i < len(current_df.columns) - 1: df_info += "\n" conversation_state.update( { "data_loaded": True, "filename": file_path, "rows": int(len(current_df)), "columns": int(len(current_df.columns)), } ) return { "success": True, "filename": file_path, "rows": int(len(current_df)), "columns": int(len(current_df.columns)), "data_info": df_info, } except Exception: return {"error": "CSV 읽기 실패"} def filter_data_func(args: Dict[str, Any]) -> Dict[str, Any]: global current_df, filtered_df try: if current_df is None: return {"error": "먼저 load_data로 데이터를 로드해주세요."} base_target = args.get("base", "filtered") if base_target == "filtered" and filtered_df is not None and len(filtered_df) > 0: df = filtered_df.copy() else: df = current_df.copy() # 필터 적용 filtered = df.copy() conditions: list[str] = [] if "product_name" in args: filtered = filtered[filtered["product_name"] == args["product_name"]] conditions.append(f"product_name: {args['product_name']}") if "cs_category" in args: filtered = filtered[filtered["cs_category"] == args["cs_category"]] conditions.append(f"cs_category: {args['cs_category']}") if "rating_threshold" in args: filtered = filtered[filtered["rating"] >= args["rating_threshold"]] conditions.append(f"rating >= {args['rating_threshold']}") if "customer_id" in args: filtered = filtered[filtered["customer_id"] == args["customer_id"]] conditions.append(f"customer_id: {args['customer_id']}") if "date_range" in args: date_range = args["date_range"] if "1월" in date_range and "2월" in date_range and "date" in filtered.columns: filtered = filtered[filtered["date"].astype(str).str.contains("2025-01|2025-02")] conditions.append("date_range: 1-2월") filtered_df = filtered # 필터된 데이터 미리보기 (처음 3개만 노출) preview_data = [] if len(filtered_df) > 0: # 미리보기 컬럼 구성 preview_cols = ["id", "date", "product_name", "cs_category", "text", "rating"] available_cols = [col for col in preview_cols if col in filtered_df.columns] preview_data = filtered_df[available_cols].head(3).to_dict('records') conversation_state.update( { "last_filter": { "filtered_count": int(len(filtered_df)), "total_count": int(len(df)), "conditions": conditions, "base": base_target, } } ) return { "success": True, "total_count": int(len(df)), "filtered_count": int(len(filtered_df)), "filter_conditions": conditions, "preview_data": preview_data, "message": f"필터링 완료: 전체 {len(df)}개 중 {len(filtered_df)}개 데이터 추출 (필터링된 데이터가 저장되었습니다)", } except Exception: return {"error": "필터링 실패"} def check_data_func(args: Dict[str, Any]) -> Dict[str, Any]: global current_df, filtered_df try: if current_df is None: return {"error": "먼저 load_data로 데이터를 로드해주세요."} # 항상 필터링된 데이터 기준으로 수행. 없으면 오류 반환 if filtered_df is None or len(filtered_df) == 0: return {"error": "필터링된 데이터가 없습니다. 먼저 filter_data를 수행하세요."} df = filtered_df check_type = args.get("check_type", "duplicates") action = args.get("action", "check") column = args.get("column") if check_type == "duplicates": if column: duplicates_count = df[column].duplicated().sum() else: duplicates_count = df.duplicated().sum() if action == "check": result = { "success": True, "check_type": "duplicates", "action": "check", "column": column, "duplicates_found": int(duplicates_count), "total_records": int(len(df)), } return result else: df_clean = df.drop_duplicates(subset=[column]) if column else df.drop_duplicates() # 필터링된 데이터 갱신 filtered_df = df_clean conversation_state.update( { "last_check": { "type": "duplicates", "action": "remove", "column": column, "removed": int(duplicates_count), "remaining": int(len(df_clean)), } } ) return { "success": True, "check_type": "duplicates", "action": "remove", "column": column, "original_records": int(len(df)), "duplicates_removed": int(duplicates_count), "remaining_records": int(len(df_clean)), } if check_type == "missing": if column: # NaN과 빈 문자열 모두 결측치로 처리 missing_count = df[column].isna().sum() + (df[column] == '').sum() else: # 모든 컬럼에서 NaN 또는 빈 문자열이 있는 행 찾기 missing_mask = df.isna().any(axis=1) | (df == '').any(axis=1) missing_count = missing_mask.sum() if action == "check": return { "success": True, "check_type": "missing", "action": "check", "column": column, "missing_found": int(missing_count), "total_records": int(len(df)), } else: if column: # 특정 컬럼에서 NaN과 빈 문자열 제거 df_clean = df[~(df[column].isna() | (df[column] == ''))] else: # 모든 컬럼에서 NaN 또는 빈 문자열이 있는 행 제거 df_clean = df[~(df.isna().any(axis=1) | (df == '').any(axis=1))] # 필터링된 데이터 갱신 filtered_df = df_clean conversation_state.update( { "last_check": { "type": "missing", "action": "remove", "column": column, "removed": int(missing_count), "remaining": int(len(df_clean)), } } ) return { "success": True, "check_type": "missing", "action": "remove", "column": column, "original_records": int(len(df)), "missing_removed": int(missing_count), "remaining_records": int(len(df_clean)), } return {"error": "지원하지 않는 check_type 입니다."} except Exception: return {"error": "데이터 검사 실패"} def analyze_data_func(args: Dict[str, Any]) -> Dict[str, Any]: global current_df, filtered_df try: if current_df is None: return {"error": "먼저 load_data로 데이터를 로드해주세요."} base_df = filtered_df if (filtered_df is not None and len(filtered_df) > 0) else current_df df = base_df product_name = args.get("product_name") if not product_name: return {"error": "product_name 파라미터가 필요합니다."} if "rating" not in df.columns: return {"error": "rating 컬럼이 없습니다."} df_product = df[df["product_name"] == product_name] if len(df_product) == 0: return {"error": f"해당 product 데이터 없음: {product_name}"} desc = df_product["rating"].describe() stats = { "count": int(desc.get("count", 0)), "mean": float(desc.get("mean", 0)) if not pd.isna(desc.get("mean", None)) else 0.0, "std": float(desc.get("std", 0)) if not pd.isna(desc.get("std", None)) else 0.0, "min": float(desc.get("min", 0)) if not pd.isna(desc.get("min", None)) else 0.0, "25%": float(desc.get("25%", 0)) if not pd.isna(desc.get("25%", None)) else 0.0, "50%": float(desc.get("50%", 0)) if not pd.isna(desc.get("50%", None)) else 0.0, "75%": float(desc.get("75%", 0)) if not pd.isna(desc.get("75%", None)) else 0.0, "max": float(desc.get("max", 0)) if not pd.isna(desc.get("max", None)) else 0.0, } # 월별 시각화 데이터 기반 차트 생성 chart_files = [] if "date" in df_product.columns: try: df_product["date"] = pd.to_datetime(df_product["date"]) df_product["month"] = df_product["date"].dt.strftime("%Y-%m") monthly_counts = df_product["month"].value_counts().sort_index() monthly_ratings = df_product.groupby("month")["rating"].mean() # 차트 1: 월별 건수 plt.figure(figsize=(10, 6)) bars = plt.bar(monthly_counts.index, monthly_counts.values, color='skyblue', alpha=0.7) plt.title(f'{product_name} Monthly AS Cases', fontsize=14, fontweight='bold') plt.xlabel('Month') plt.ylabel('Number of Cases') plt.xticks(rotation=45) plt.grid(True, alpha=0.3) y_max = max(monthly_counts.values) if len(monthly_counts) > 0 else 0 offset = max(0.02 * y_max, 0.5) for bar, count in zip(bars, monthly_counts.values): y = max(bar.get_height() - offset, bar.get_height() * 0.5) plt.text( bar.get_x() + bar.get_width() / 2, y, str(count), ha='center', va='top', fontweight='bold' ) plt.tight_layout(pad=1.2) chart_filename_1 = f"{product_name.replace(' ', '_')}_monthly_cases.png" plt.savefig(chart_filename_1, dpi=300) plt.close() # 차트 2: 월별 평균 평점 plt.figure(figsize=(10, 6)) plt.plot(monthly_ratings.index, monthly_ratings.values, marker='o', linewidth=2, markersize=8, color='red') plt.title(f'{product_name} Monthly Average Rating', fontsize=14, fontweight='bold') plt.xlabel('Month') plt.ylabel('Average Rating') plt.xticks(rotation=45) plt.grid(True, alpha=0.3) plt.ylim(0, 5) for x, y in zip(monthly_ratings.index, monthly_ratings.values): plt.text(x, y + 0.1, f'{y:.2f}', ha='center', va='bottom', fontweight='bold') plt.tight_layout(pad=1.2) chart_filename_2 = f"{product_name.replace(' ', '_')}_monthly_ratings.png" plt.savefig(chart_filename_2, dpi=300) plt.close() chart_files = [chart_filename_1, chart_filename_2] except Exception: chart_files = [] return { "success": True, "product_name": product_name, "stats": stats, "records": int(len(df_product)), "chart_files": chart_files, } except Exception: return {"error": "분석 실패"} def save_data_func(args: Dict[str, Any]) -> Dict[str, Any]: global filtered_df try: if filtered_df is None or len(filtered_df) == 0: return {"error": "저장할 데이터가 없습니다. 먼저 filter_data로 데이터를 준비하세요."} filename = args.get("filename") if not filename: return {"error": "filename 파라미터가 필요합니다."} base, ext = os.path.splitext(filename) if ext.lower() != ".csv": filename = f"{base}.csv" filtered_df.to_csv(filename, index=False, encoding="utf-8") return { "success": True, "filename": filename, "rows": int(len(filtered_df)), "cols": int(len(filtered_df.columns)), "data_source": "filtered", "message": f"데이터 저장 완료: {filename} ({len(filtered_df)}개 레코드, {len(filtered_df.columns)}개 컬럼)", } except Exception: return {"error": "저장 실패"} 2.4. main.py main.py는 멀티 턴 대화 시나리오를 실행하는 메인 파일입니다. 시나리오에 맞는 쿼리와 프롬프트를 입력하여 데이터 분석 작업 수행 예시를 제공합니다. from typing import List, Dict, Any from fc_core import function_call, append_context def multiturn_calling() -> None: # 멀티 턴 대화 시나리오 실행 # 시스템 프롬프트 설정 messages: List[Dict[str, Any]] = [ { "role": "system", "content": "당신은 상품 주문에 대한 고객 CS 데이터를 분석하는 AI 어시스턴트입니다. 함수를 호출해서 CSV 파일을 불러오고, 데이터를 필터링하고, 데이터를 검사하고 분석한 뒤 결과를 바탕으로 사용자에게 도움이 되는 답변을 제공하세요. 일반적인 답변은 하지 말고, 항상 적절한 함수를 선택해서 호출해야 합니다. 사용자가 여러 작업을 요청하면 필요한 모든 함수를 호출하세요.", } ] # 1st Turn: CSV 로드 + Smart watch as 필터링 # - 컨텍스트 요약은 턴2에서만 추가하여 중복/과다 메시지 방지 print("\n🔄 턴 1") # 유저 쿼리 작성 user_query_1 = ( "cs_data.csv 파일을 로드해줘. 그리고 Smart watch의 as 관련 데이터만 필터링해줘" ) print(f" User: {user_query_1}") print("-" * 60) messages.append({"role": "user", "content": user_query_1}) result_1 = function_call(messages) # 1차 호출 + 도구 실행 + 2차 호출로 응답 생성까지 수행 # 어시스턴트 자연어 응답은 메시지 히스토리에 추가하지 않음(Tool 결과만으로 충분) print("✅ 턴 1 완료") print('-'*60) # 2nd Turn: 이전 필터링된 Smart watch 데이터를 분석 + 결측값 제거 + CSV 저장 # filtered_df 기준으로 연속적으로 함수가 수행되는지 확인 print("\n🔄 턴 2") # 2번째 유저 쿼리 작성 user_query_2 = ( "text가 빈 값들은 제거하고 월별로 시각화 분석 한 뒤 데이터를 watch_as.csv 파일로 저장해줘." ) print(f" User: {user_query_2}") print('-'*60) append_context(messages) # 1턴 결과를 요약해 모델에 1회만 전달 messages.append({"role": "user", "content": user_query_2}) result_2 = function_call(messages) # 어시스턴트 자연어 응답은 메시지 히스토리에 추가하지 않음 print("✅ 턴 2 완료") def main() -> None: # 멀티 턴 예시를 실행 multiturn_calling() if __name__ == "__main__": main() 3. 파일 실행 앞서 구현한 파일들을 저장한채로 main.py 파일을 실행한 결과는 다음과 같습니다. 🔄 턴 1 User: cs_data.csv 파일을 로드해줘. 그리고 Smart watch의 as 관련 데이터만 필터링해줘 ------------------------------------------------------------ 함수 실행 1: load_data Arguments: {'filename': 'cs_data.csv'} 함수 결과: { "success": true, "filename": "/Users/user/fc/cs_data.csv", "rows": 500, "columns": 7, "data_info": "columns:\n • id: int64\n • date: object\n • customer_id: object\n • product_name: object\n • cs_category: object\n • text: object\n • rating: int64" } 함수 실행 2: filter_data Arguments: {'product_name': 'Smart watch', 'cs_category': 'as'} 함수 결과: { "success": true, "total_count": 500, "filtered_count": 101, "filter_conditions": [ "product_name: Smart watch", "cs_category: as" ], "preview_data": [ { "id": 5, "date": "2025-01-03", "product_name": "Smart watch", "cs_category": "as", "text": "터치가 안 되는데 수리 가능한가요", "rating": 3 }, { "id": 6, "date": "2025-01-03", "product_name": "Smart watch", "cs_category": "as", "text": NaN, "rating": 3 }, { "id": 10, "date": "2025-01-04", "product_name": "Smart watch", "cs_category": "as", "text": "지문인식이 안 되는데 AS 가능한가요", "rating": 3 } ], "message": "필터링 완료: 전체 500개 중 101개 데이터 추출 (필터링된 데이터가 저장되었습니다)" } ✅ 턴 1 완료 ------------------------------------------------------------ 🔄 턴 2 User: text가 빈 값들은 제거하고 Smart watch에 대해서 월별로 시각화 분석 한 뒤 데이터를 watch_as.csv 파일로 저장해줘. ------------------------------------------------------------ 함수 실행 1: check_data Arguments: {'check_type': 'missing', 'action': 'remove', 'column': 'text'} 함수 결과: { "success": true, "check_type": "missing", "action": "remove", "column": "text", "original_records": 101, "missing_removed": 2, "remaining_records": 99 } 함수 실행 2: analyze_data Arguments: {'product_name': 'Smart watch', 'bins': 12} 함수 결과: { "success": true, "product_name": "Smart watch", "stats": { "count": 99, "mean": 2.4343434343434343, "std": 0.9914081529558191, "min": 1.0, "25%": 1.5, "50%": 3.0, "75%": 3.0, "max": 4.0 }, "records": 99, "chart_files": [ "Smart watch_cases.png", "Smart watch_monthly_ratings.png" ] } 함수 실행 3: save_data Arguments: {'filename': 'watch_as.csv'} 함수 결과: { "success": true, "filename": "watch_as.csv", "rows": 99, "cols": 7, "data_source": "filtered", "message": "데이터 저장 완료: watch_as.csv (99개 레코드, 7개 컬럼)" } ✅ 턴 2 완료 결과 데이터 및 시각화 이미지 watch_as.csv 마무리 이번 쿡북에서는 LLM의 핵심 기능인 Function calling 기반 멀티 턴 자동화를 살펴보았습니다. 시나리오에서는 기본적인 데이터 분석 도구를 사용했지만, 시각화, 감성 분석, 요약 등 다양한 함수를 추가해 더 풍부한 분석을 할 수 있습니다. 예제에서는 원할한 이해를 위해 한 번의 함수 실행으로 멀티 턴을 구현했지만, 실제 환경에서는 단계별 입력을 받아 결과를 확인하고 다음 작업을 결정할 수 있습니다. 이를 통해 필요에 따라 턴을 추가·수정하며 유연한 분석이 가능합니다. 이 쿡북을 통해 Function Calling 역량을 높이고, 자신만의 자동화 솔루션을 구축해 보세요! 🚀
들어가며 Function calling은 LLM이 사용자의 요청을 처리하기 위해 특정 도구를 직접 호출할 수 있도록 해주는 기능입니다. 이를 활용해 목적에 맞는 도구를 정의하고, 실시간 정보 처리나 외부 데이터 연동, 복잡한 계산 등 기존의 LLM만으로는 해결하기 어려운 작업까지 수행할 수 있습니다. 이번 쿡북에서는 Function calling을 복잡한 멀티 턴 시나리오에 적용하여, 궁극적으로 나만의 데이터 자동 분석 솔루션을 구현하는 방법을 살펴보겠습니다. Function calling의 기본 개념과 활용법에 대한 보다 자세한 내용은 아래 이전 글들을 참고하시기 바랍니다. 당신의 AI에게 행동을 맡겨라: 스킬과 Function Calling Function calling 활용법: LLM으로 실시간 데이터 호출과 액션 수행까지 AI 어시스턴트 제작 레시피: Function calling 활용하기 작동 원리 멀티 턴 최근에는 Function calling이 단일 호출로 끝나는 것이 아니라, 사용자와 LLM간 여러 번의 대화를 주고받으며 복합적인 목표를 달성하는 멀티 턴(multi-turn) 방식이 새로운 트렌드로 자리 잡고 있습니다. 기존의 단일 호출 방식은 "오늘 날씨 어때?"처럼 한 번의 질문에 한 번의 Function calling으로 답을 얻는 간단한 시나리오에 적합합니다. 하지만 실제 사용자의 요청은 "오늘 날씨 알려주고, 비가 오면 우산 챙기라고 알려줘"와 같이 여러 요청이 포함된 멀티 쿼리 형태 혹은 모델의 답변을 보고, 추가적인 호출을 요청하는 멀티 턴 형태의 경우가 대다수입니다. 멀티 턴 방식은 이러한 대화의 맥락을 유지하면서 여러 Function calling을 순차적 또는 병렬적으로 수행할 수 있게 해주며, 이를 통해 더욱 복잡하고 실용적인 작업을 처리할 수 있습니다. 기본 작동 방식: 사용자의 요청을 받은 LLM은 사용 가능한 도구 목록을 확인한 뒤, 어떤 도구를 어떤 파라미터와 함께 사용해야 할지를 판단합니다. 그리고 그 결과를 JSON 형태로 반환합니다. 개발자는 이를 실제 도구 실행에 연결하고, 실행 결과를 다시 LLM에 전달합니다. 멀티 턴 작동 방식: 멀티 턴의 경우 이러한 과정이 한 번의 요청으로 끝나지 않고, 이후 이어지는 사용자 요청에서도 이전 맥락을 참고하여 기능을 수행합니다. 이 과정은 대화가 종료될 때까지 반복됩니다. 함수 실행 자동화 기존의 Function calling 방식은 LLM이 사용자 요청을 분석하여 함수를 호출하고 필요한 파라미터를 담은 JSON 객체를 반환하는 것에 그칩니다. 이 경우, 사용자는 반환된 JSON을 파싱하여 직접 코드를 실행하고, 그 결과를 다시 LLM에게 전달하는 번거로운 과정을 거쳐야 합니다. 이 과정은 다음과 같은 흐름으로 진행됩니다. 사용자 요청 LLM이 함수 및 파라미터 호출 사용자가 직접 해당 함수 코드 실행 결과값 획득 결과값을 LLM에게 다시 전달 LLM이 최종 답변 생성 하지만 이번 쿡북에서 다룰 방식은 이러한 과정을 자동화합니다. 미리 함수 코드를 정의하고, 모델이 함수를 실행할 수 있도록 설계합니다. 따라서 LLM이 함수 호출을 결정하면, 시스템이 사용자의 개입 없이 함수를 실행하고 그 결과를 LLM에게 다시 전달하는 과정을 전부 자동으로 처리합니다. 기존 방식과 비교한 멀티 턴 기반 자동화 파이프라인 구조는 다음과 같습니다. 시나리오 이번 쿡북에서 다룰 시나리오는 주문 상품에 대한 고객 CS 데이터 분석 작업입니다. 시나리오에서는 LLM의 Function calling 기능을 활용하여 복잡하고 반복적인 데이터 분석 작업을 자동화하고, 사용자가 자연어로 던지는 질문에 따라 데이터 분석 시각화 등 다양한 작업 수행 과정을 보여줍니다. 시나리오에서 설계할 도구는 총 5개입니다. LLM은 사용자의 요청을 바탕으로 이 도구들을 적절하게 호출하여 데이터 분석 파이프라인을 구축합니다. load_data: 분석할 CSV 파일을 불러오는 도구 filter_data: 특정 조건에 맞는 데이터만 추출하는 도구 check_data: 데이터의 품질을 검사하는 도구 analyze_data: 고객 평점을 기준으로 다양한 통계 정보를 계산하는 도구 save_data: 분석이 완료된 데이터를 저장하는 도구 단순히 도구를 한 번 호출하는 것이 아니라, 사용자와의 멀티 턴 대화 과정에서 여러 도구를 순차적으로 호출하며 복합적인 분석 작업을 자동으로 수행하는 과정을 보여주는 데 초점을 맞추고 있습니다. 구체적인 CS 데이터 분석 시나리오 파이프라인은 다음과 같습니다. 분석 데이터 분석할 데이터는 구매한 제품에 대한 고객 문의 내용이 담긴 CSV 파일입니다. 이 데이터는 다음과 같은 정보를 포함하고 있습니다. id: 고유 식별자 date: 문의 작성 날짜 customer_id: 고객 ID product_name: 상품명 cs_category: CS 유형 (예: as, payment , exchange, delivery, return) text: 고객의 구체적인 문의 내용 rating: 서비스 만족도 평점 (1~5점) 시나리오 구현 1. 환경 설정 API 토큰 발급은 CLOVA Studio API 가이드를 참조하세요. 2. 파일 생성 생성할 파일 구성은 다음과 같습니다. cookbook/ ├── main.py # 멀티 턴 대화 시나리오 실행 스크립트입니다. ├── fc_core.py # 핵심 함수들이 모인 모듈입니다. function_call()로 load_data/filter_data/analyze_data/check_data/save_data 함수들을 제공합니다. ├── config.py # API 설정과 함수 실행 우선순위를 정의합니다. ├── tool_schema.py # AI가 사용할 도구들의 스키마를 정의합니다. 2.1 config.py config.py는 CLOVA Studio API 연결과 함수 실행 우선순위를 정의하는 설정 파일입니다. 이 파일은 전체 시스템의 핵심 설정을 중앙 집중식으로 관리하여 유지보수성을 높입니다. 실제 사용을 위해서는 본인의 CLOVA Studio API 키를 입력해야 합니다. API_KEY = "YOUR_API_KEY" API_URL = "https://clovastudio.stream.ntruss.com/testapp/v3/chat-completions/HCX-DASH-002" def get_headers() -> dict: return { "Content-Type": "application/json", "Authorization": API_KEY, } # 함수 실행 우선 순위 정의 FUNCTION_PRIORITY = { "load_data": 0, "filter_data": 1, "check_data": 2, "analyze_data": 3, "save_data": 4, } 2.2 tool_schema.py tool_schema.py 는 LLM이 사용할 수 있는 도구의 스키마를 정의하는 파일입니다. LLM이 어떤 함수를 호출할 수 있고 각 함수가 어떤 파라미터를 받는지 명시합니다. 정의할 함수 정보는 다음과 같습니다. load_data: CSV 파일을 로드하는 기본 함수입니다. 'filename'은 필수 파라미터이며, 같은 폴더 내에 해당 이름을 가진 파일이 존재해야 합니다. filter_data: 다양한 조건으로 데이터를 필터링하는 함수입니다. 'base' 파라미터로 필터 적용 대상을 선택할 수 있으며, 각 파라미터들은 해당 열에 명시된 값들을 제공합니다. check_data: 데이터 품질을 검사하고 정리하는 함수입니다. 'check_type'과 'action'은 필수 파라미터로, 검사 유형과 수행할 작업을 지정합니다. analyze_data: 특정 제품의 평점 통계를 분석하고 월별 시각화 차트를 생성하는 분석 함수입니다. 'product_name'은 필수 파라미터이며, 'bins'는 시각화 도구의 구간 수를 지정합니다. save_data: 필터링된 데이터를 CSV 파일로 저장하는 함수입니다. 'filename'은 저장할 파일의 이름을 지정하는 필수 파라미터입니다. def get_tools() -> list: return [ { "type": "function", "function": { "description": "CSV 파일을 로드하고 데이터 정보를 제공합니다.", "name": "load_data", "parameters": { "properties": { "filename": { "type": "string", "description": "업로드할 CSV 파일명 (예: 'data.csv', 'sales.csv')", } }, "required": ["filename"], "type": "object", }, }, }, { "type": "function", "function": { "description": "사용자가 특정 조건의 데이터를 요청할 때 호출합니다.", "name": "filter_data", "parameters": { "properties": { "base": { "type": "string", "enum": ["filtered", "all"], "description": "필터 적용 대상. 'filtered'는 이전 필터링 결과에 추가 필터를 적용하고, 'all'은 전체 데이터에서 새로 필터링합니다. 기본값은 'filtered'입니다.", }, "product_name": {"type": "string"}, "cs_category": { "enum": [ "as", "payment", "exchange", "delivery", "return", ], "type": "string", }, "date_range": {"type": "string"}, "rating_threshold": {"type": "integer"}, "customer_id": {"type": "string"}, }, "required": [], "type": "object", }, }, }, { "type": "function", "function": { "description": "특정 product의 rating 기술통계와 월별 시각화 차트를 생성합니다.", "name": "analyze_data", "parameters": { "properties": { "product_name": {"type": "string"}, "bins": { "type": "integer", "description": "rating 히스토그램 구간 수 (기본값: 12)", }, }, "required": ["product_name"], "type": "object", }, }, }, { "type": "function", "function": { "description": "사용자가 데이터 품질 검사나 정리를 요청할 때 호출합니다.", "name": "check_data", "parameters": { "properties": { "check_type": { "description": "검사 유형 (duplicates: 중복, missing: 결측값)", "enum": ["duplicates", "missing"], "type": "string", }, "action": { "description": "수행할 작업 (check: 확인만, remove: 제거)", "enum": ["check", "remove"], "type": "string", }, "column": { "description": "검사할 컬럼명 (없으면 전체)", "type": "string", }, }, "required": ["check_type", "action"], "type": "object", }, }, }, { "type": "function", "function": { "description": "사용자가 특정 파일명으로 데이터를 저장하라고 요청할 때 호출합니다. 필터링된 데이터를 CSV 형식으로 저장합니다.", "name": "save_data", "parameters": { "properties": { "filename": { "description": "저장할 CSV 파일명 (예: 'result.csv')", "type": "string", }, }, "required": ["filename"], "type": "object", }, }, }, ] 2.3. fc_core.py fc_core.py는 멀티 턴, Function calling, 함수 실행 자동화 등 전체 시스템의 핵심 기능을 담당하는 파일입니다. 이 파일은 크게 멀티 턴 대화를 위한 컨텍스트 관리, Function calling 처리, 그리고 실행 함수 구현 세 부분으로 나뉩니다. 2.3.1. 멀티 턴 정보 전달 멀티 턴 대화에서 이전 턴의 정보를 다음 턴에 전달하기 위한 컨텍스트 관리 함수들입니다. build_summary 함수는 현재 대화 상태를 요약하여 문자열로 반환합니다. 데이터 로드 정보, 최근 필터링 결과, 데이터 검사 결과 등 함수 실행 결과를 포함하여 LLM이 이전 턴의 작업 내용을 이해할 수 있도록 도와줍니다. append_context 함수는 앞서 생성된 컨텍스트 요약을 메시지 히스토리에 추가합니다. 이 함수는 다음 턴 시작 전에 호출되어 LLM에게 이전 턴의 작업 결과를 전달합니다. import json import os from typing import Any, Dict, List import pandas as pd import numpy as np import requests import matplotlib matplotlib.use('Agg') import matplotlib.pyplot as plt from config import get_headers, API_URL, FUNCTION_PRIORITY current_df = None # load_data로 불러온 원본 데이터를 의미합니다. filtered_df = None # 다른 함수 실행으로 인해 필터링된 데이터를 의미합니다. conversation_state = { "data_loaded": False, "filename": None, "rows": 0, "columns": 0, "last_filter": None, } def build_summary() -> str: parts: List[str] = [] if conversation_state.get("data_loaded"): parts.append( f"데이터 로드됨(file={conversation_state.get('filename')}, rows={conversation_state.get('rows')}, cols={conversation_state.get('columns')})" ) lf = conversation_state.get("last_filter") if lf: conds = ", ".join(lf.get("conditions", [])) if lf.get("conditions") else "-" parts.append( f"최근 필터(count={lf.get('filtered_count')}/{lf.get('total_count')}, conds={conds})" ) lc = conversation_state.get("last_check") if lc: check_type = lc.get("type", "") action = lc.get("action", "") column = lc.get("column", "") removed = lc.get("removed", 0) remaining = lc.get("remaining", 0) if check_type == "missing": parts.append(f"결측값 제거({column}: {removed}개 제거, {remaining}개 남음)") elif check_type == "duplicates": parts.append(f"중복 제거({column}: {removed}개 제거, {remaining}개 남음)") return "[context] " + " | ".join(parts) if parts else "" def append_context(messages: List[Dict[str, Any]]) -> None: summary = build_summary() if summary: messages.append({"role": "assistant", "content": summary}) 2.3.2. Function calling 처리 LLM이 사용자 쿼리를 바탕으로 정의된 도구를 호출하는 Function calling 과정을 설계합니다. execute_function 함수는 LLM이 요청한 함수를 실행하는 역할을 합니다. 함수 이름과 파라미터를 받아서 해당하는 실제 함수를 호출하고 결과를 반환합니다. function_call 함수는 멀티 턴 대화의 함수 호출 과정을 보여주는 핵심 함수입니다. 첫 번째 호출을 통해 message와 tool_schema를 LLM에게 전송합니다. LLM이 요청 함수들을 우선순위에 따라 실행합니다. 함수 실행 결과를 LLM에게 전달하여 최종 응답을 생성합니다. 새로운 메시지와 이전 컨텍스트를 포함하여 두 번째 턴을 실행합니다. 1-3 과정을 반복하여 최종 응답을 생성합니다. def execute_function(func_name: str, args: Dict[str, Any]) -> Dict[str, Any]: if func_name == "load_data": return load_data_file(args.get("filename")) if func_name == "filter_data": return filter_data_func(args) if func_name == "analyze_data": return analyze_data_func(args) if func_name == "check_data": return check_data_func(args) if func_name == "save_data": return save_data_func(args) return {"error": f"알 수 없는 함수: {func_name}"} def function_call(messages: List[Dict[str, Any]]) -> Dict[str, Any] | None: from tool_schema import get_tools payload = {"messages": messages, "tools": get_tools(), "toolChoice": "auto"} # 요청 페이로드 생성 try: response = requests.post(API_URL, headers=get_headers(), json=payload, timeout=30) # Tool call 요청 전송 if response.status_code != 200: return None # 응답 코드가 200이 아닌 경우 오류 반환 result = response.json() # 응답 결과 파싱 message = ( result.get("result", {}).get("message", {}) if "result" in result else (result.get("choices", [{}])[0].get("message", {})) ) if not message: return result tool_calls_raw = message.get("toolCalls", message.get("tool_calls", [])) # Tool call 목록 추출 if not tool_calls_raw: return {"message": message} tool_calls = sorted( tool_calls_raw, key=lambda c: FUNCTION_PRIORITY.get(c.get("function", {}).get("name", ""), 99), ) # 우선순위에 따라 정렬 tool_messages: List[Dict[str, Any]] = [] for i, call in enumerate(tool_calls): func_name = call["function"]["name"] args_str = call["function"]["arguments"] call_id = call.get("id", f"call_{i}") # 실행 로그: 어떤 함수가 어떤 arguments로 호출되는지 출력 print(f"\n 함수 실행 {i+1}: {func_name}") print(f"Arguments: {args_str}") try: args = json.loads(args_str) if isinstance(args_str, str) else args_str function_result = execute_function(func_name, args) # 함수 실행 print("함수 결과:") print(json.dumps(function_result, ensure_ascii=False, indent=2)) tool_messages.append( { "role": "tool", "content": json.dumps(function_result, ensure_ascii=False), "tool_call_id": call_id, } ) except Exception: tool_messages.append( { "role": "tool", "content": json.dumps({"error": "함수 실행 실패"}, ensure_ascii=False), "tool_call_id": call_id, } ) # 두 번째 호출 messages.extend(tool_messages) # 원본 메시지에 tool 실행 결과 추가 second_payload = {"messages": messages, "tools": get_tools(), "toolChoice": "auto"} # 두 번째 호출 페이로드 생성 second_response = requests.post( API_URL, headers=get_headers(), json=second_payload, timeout=30 ) # 두 번째 호출 요청 전송 if second_response.status_code != 200: return {"message": message, "has_tool_calls": True} second_result = second_response.json() # 두 번째 호출 결과 파싱 second_message = ( second_result.get("result", {}).get("message", {}) if "result" in second_result else (second_result.get("choices", [{}])[0].get("message", {})) ) return {"message": second_message} if second_message else {"message": message, "has_tool_calls": True} except Exception: return None 2.3.3. 실행 함수 구현 실제 데이터 처리를 담당하는 도구 함수들을 구현합니다. 각 함수는 LLM이 요청하는 구체적인 작업을 직접 수행합니다. load_data_file 함수는 CSV 파일을 읽어서 current_df에 저장하고, 데이터의 기본 정보를 반환합니다. 파일 존재 여부를 확인하고, 컬럼명과 데이터 타입 정보를 생성하여 사용자가 데이터 구조를 파악할 수 있도록 도와줍니다. filter_data_func 함수는 다양한 조건으로 데이터를 필터링합니다. 제품명, 카테고리, 평점, 고객 ID, 날짜 범위 등 다양한 조건을 적용할 수 있습니다. 필터링 결과는 filtered_df에 저장되고, 상위 3개 레코드를 미리보기로 제공합니다. check_data_func 함수는 데이터 품질을 검사하고 정리합니다. 중복 데이터와 결측값을 검사하거나 제거할 수 있으며, 특정 컬럼에 대해서만 작업을 수행할 수도 있습니다. analyze_data_func 함수는 특정 제품의 평점 통계를 분석하고 월별 시각화 차트를 생성합니다. 평점에 대한 기술통계(평균, 표준편차, 최소값, 최대값 등)를 계산하고, 월별 건수와 월별 평균 평점을 시각화한 두 개의 차트 파일을 생성합니다. save_data_func 함수는 필터링된 데이터를 CSV 파일로 저장합니다. 파일 확장자가 .csv가 아닌 경우 자동으로 추가하며, 저장된 파일의 정보와 함께 완료 메시지를 반환합니다. # 함수 정의 def load_data_file(filename: str) -> Dict[str, Any]: global current_df try: current_dir = os.getcwd() file_path = os.path.join(current_dir, filename) if not os.path.exists(file_path): return {"error": "파일을 찾을 수 없습니다"} current_df = pd.read_csv(file_path) # 컬럼명과 타입 정보 생성 df_info = f"columns:\n" for i, col in enumerate(current_df.columns): dtype = str(current_df[col].dtype) df_info += f" • {col}: {dtype}" if i < len(current_df.columns) - 1: df_info += "\n" conversation_state.update( { "data_loaded": True, "filename": file_path, "rows": int(len(current_df)), "columns": int(len(current_df.columns)), } ) return { "success": True, "filename": file_path, "rows": int(len(current_df)), "columns": int(len(current_df.columns)), "data_info": df_info, } except Exception: return {"error": "CSV 읽기 실패"} def filter_data_func(args: Dict[str, Any]) -> Dict[str, Any]: global current_df, filtered_df try: if current_df is None: return {"error": "먼저 load_data로 데이터를 로드해주세요."} base_target = args.get("base", "filtered") if base_target == "filtered" and filtered_df is not None and len(filtered_df) > 0: df = filtered_df.copy() else: df = current_df.copy() # 필터 적용 filtered = df.copy() conditions: list[str] = [] if "product_name" in args: filtered = filtered[filtered["product_name"] == args["product_name"]] conditions.append(f"product_name: {args['product_name']}") if "cs_category" in args: filtered = filtered[filtered["cs_category"] == args["cs_category"]] conditions.append(f"cs_category: {args['cs_category']}") if "rating_threshold" in args: filtered = filtered[filtered["rating"] >= args["rating_threshold"]] conditions.append(f"rating >= {args['rating_threshold']}") if "customer_id" in args: filtered = filtered[filtered["customer_id"] == args["customer_id"]] conditions.append(f"customer_id: {args['customer_id']}") if "date_range" in args: date_range = args["date_range"] if "1월" in date_range and "2월" in date_range and "date" in filtered.columns: filtered = filtered[filtered["date"].astype(str).str.contains("2025-01|2025-02")] conditions.append("date_range: 1-2월") filtered_df = filtered # 필터된 데이터 미리보기 (처음 3개만 노출) preview_data = [] if len(filtered_df) > 0: # 미리보기 컬럼 구성 preview_cols = ["id", "date", "product_name", "cs_category", "text", "rating"] available_cols = [col for col in preview_cols if col in filtered_df.columns] preview_data = filtered_df[available_cols].head(3).to_dict('records') conversation_state.update( { "last_filter": { "filtered_count": int(len(filtered_df)), "total_count": int(len(df)), "conditions": conditions, "base": base_target, } } ) return { "success": True, "total_count": int(len(df)), "filtered_count": int(len(filtered_df)), "filter_conditions": conditions, "preview_data": preview_data, "message": f"필터링 완료: 전체 {len(df)}개 중 {len(filtered_df)}개 데이터 추출 (필터링된 데이터가 저장되었습니다)", } except Exception: return {"error": "필터링 실패"} def check_data_func(args: Dict[str, Any]) -> Dict[str, Any]: global current_df, filtered_df try: if current_df is None: return {"error": "먼저 load_data로 데이터를 로드해주세요."} # 항상 필터링된 데이터 기준으로 수행. 없으면 오류 반환 if filtered_df is None or len(filtered_df) == 0: return {"error": "필터링된 데이터가 없습니다. 먼저 filter_data를 수행하세요."} df = filtered_df check_type = args.get("check_type", "duplicates") action = args.get("action", "check") column = args.get("column") if check_type == "duplicates": if column: duplicates_count = df[column].duplicated().sum() else: duplicates_count = df.duplicated().sum() if action == "check": result = { "success": True, "check_type": "duplicates", "action": "check", "column": column, "duplicates_found": int(duplicates_count), "total_records": int(len(df)), } return result else: df_clean = df.drop_duplicates(subset=[column]) if column else df.drop_duplicates() # 필터링된 데이터 갱신 filtered_df = df_clean conversation_state.update( { "last_check": { "type": "duplicates", "action": "remove", "column": column, "removed": int(duplicates_count), "remaining": int(len(df_clean)), } } ) return { "success": True, "check_type": "duplicates", "action": "remove", "column": column, "original_records": int(len(df)), "duplicates_removed": int(duplicates_count), "remaining_records": int(len(df_clean)), } if check_type == "missing": if column: # NaN과 빈 문자열 모두 결측치로 처리 missing_count = df[column].isna().sum() + (df[column] == '').sum() else: # 모든 컬럼에서 NaN 또는 빈 문자열이 있는 행 찾기 missing_mask = df.isna().any(axis=1) | (df == '').any(axis=1) missing_count = missing_mask.sum() if action == "check": return { "success": True, "check_type": "missing", "action": "check", "column": column, "missing_found": int(missing_count), "total_records": int(len(df)), } else: if column: # 특정 컬럼에서 NaN과 빈 문자열 제거 df_clean = df[~(df[column].isna() | (df[column] == ''))] else: # 모든 컬럼에서 NaN 또는 빈 문자열이 있는 행 제거 df_clean = df[~(df.isna().any(axis=1) | (df == '').any(axis=1))] # 필터링된 데이터 갱신 filtered_df = df_clean conversation_state.update( { "last_check": { "type": "missing", "action": "remove", "column": column, "removed": int(missing_count), "remaining": int(len(df_clean)), } } ) return { "success": True, "check_type": "missing", "action": "remove", "column": column, "original_records": int(len(df)), "missing_removed": int(missing_count), "remaining_records": int(len(df_clean)), } return {"error": "지원하지 않는 check_type 입니다."} except Exception: return {"error": "데이터 검사 실패"} def analyze_data_func(args: Dict[str, Any]) -> Dict[str, Any]: global current_df, filtered_df try: if current_df is None: return {"error": "먼저 load_data로 데이터를 로드해주세요."} base_df = filtered_df if (filtered_df is not None and len(filtered_df) > 0) else current_df df = base_df product_name = args.get("product_name") if not product_name: return {"error": "product_name 파라미터가 필요합니다."} if "rating" not in df.columns: return {"error": "rating 컬럼이 없습니다."} df_product = df[df["product_name"] == product_name] if len(df_product) == 0: return {"error": f"해당 product 데이터 없음: {product_name}"} desc = df_product["rating"].describe() stats = { "count": int(desc.get("count", 0)), "mean": float(desc.get("mean", 0)) if not pd.isna(desc.get("mean", None)) else 0.0, "std": float(desc.get("std", 0)) if not pd.isna(desc.get("std", None)) else 0.0, "min": float(desc.get("min", 0)) if not pd.isna(desc.get("min", None)) else 0.0, "25%": float(desc.get("25%", 0)) if not pd.isna(desc.get("25%", None)) else 0.0, "50%": float(desc.get("50%", 0)) if not pd.isna(desc.get("50%", None)) else 0.0, "75%": float(desc.get("75%", 0)) if not pd.isna(desc.get("75%", None)) else 0.0, "max": float(desc.get("max", 0)) if not pd.isna(desc.get("max", None)) else 0.0, } # 월별 시각화 데이터 기반 차트 생성 chart_files = [] if "date" in df_product.columns: try: df_product["date"] = pd.to_datetime(df_product["date"]) df_product["month"] = df_product["date"].dt.strftime("%Y-%m") monthly_counts = df_product["month"].value_counts().sort_index() monthly_ratings = df_product.groupby("month")["rating"].mean() # 차트 1: 월별 건수 plt.figure(figsize=(10, 6)) bars = plt.bar(monthly_counts.index, monthly_counts.values, color='skyblue', alpha=0.7) plt.title(f'{product_name} Monthly AS Cases', fontsize=14, fontweight='bold') plt.xlabel('Month') plt.ylabel('Number of Cases') plt.xticks(rotation=45) plt.grid(True, alpha=0.3) y_max = max(monthly_counts.values) if len(monthly_counts) > 0 else 0 offset = max(0.02 * y_max, 0.5) for bar, count in zip(bars, monthly_counts.values): y = max(bar.get_height() - offset, bar.get_height() * 0.5) plt.text( bar.get_x() + bar.get_width() / 2, y, str(count), ha='center', va='top', fontweight='bold' ) plt.tight_layout(pad=1.2) chart_filename_1 = f"{product_name.replace(' ', '_')}_monthly_cases.png" plt.savefig(chart_filename_1, dpi=300) plt.close() # 차트 2: 월별 평균 평점 plt.figure(figsize=(10, 6)) plt.plot(monthly_ratings.index, monthly_ratings.values, marker='o', linewidth=2, markersize=8, color='red') plt.title(f'{product_name} Monthly Average Rating', fontsize=14, fontweight='bold') plt.xlabel('Month') plt.ylabel('Average Rating') plt.xticks(rotation=45) plt.grid(True, alpha=0.3) plt.ylim(0, 5) for x, y in zip(monthly_ratings.index, monthly_ratings.values): plt.text(x, y + 0.1, f'{y:.2f}', ha='center', va='bottom', fontweight='bold') plt.tight_layout(pad=1.2) chart_filename_2 = f"{product_name.replace(' ', '_')}_monthly_ratings.png" plt.savefig(chart_filename_2, dpi=300) plt.close() chart_files = [chart_filename_1, chart_filename_2] except Exception: chart_files = [] return { "success": True, "product_name": product_name, "stats": stats, "records": int(len(df_product)), "chart_files": chart_files, } except Exception: return {"error": "분석 실패"} def save_data_func(args: Dict[str, Any]) -> Dict[str, Any]: global filtered_df try: if filtered_df is None or len(filtered_df) == 0: return {"error": "저장할 데이터가 없습니다. 먼저 filter_data로 데이터를 준비하세요."} filename = args.get("filename") if not filename: return {"error": "filename 파라미터가 필요합니다."} base, ext = os.path.splitext(filename) if ext.lower() != ".csv": filename = f"{base}.csv" filtered_df.to_csv(filename, index=False, encoding="utf-8") return { "success": True, "filename": filename, "rows": int(len(filtered_df)), "cols": int(len(filtered_df.columns)), "data_source": "filtered", "message": f"데이터 저장 완료: {filename} ({len(filtered_df)}개 레코드, {len(filtered_df.columns)}개 컬럼)", } except Exception: return {"error": "저장 실패"} 2.4. main.py main.py는 멀티 턴 대화 시나리오를 실행하는 메인 파일입니다. 시나리오에 맞는 쿼리와 프롬프트를 입력하여 데이터 분석 작업 수행 예시를 제공합니다. from typing import List, Dict, Any from fc_core import function_call, append_context def multiturn_calling() -> None: # 멀티 턴 대화 시나리오 실행 # 시스템 프롬프트 설정 messages: List[Dict[str, Any]] = [ { "role": "system", "content": "당신은 상품 주문에 대한 고객 CS 데이터를 분석하는 AI 어시스턴트입니다. 함수를 호출해서 CSV 파일을 불러오고, 데이터를 필터링하고, 데이터를 검사하고 분석한 뒤 결과를 바탕으로 사용자에게 도움이 되는 답변을 제공하세요. 일반적인 답변은 하지 말고, 항상 적절한 함수를 선택해서 호출해야 합니다. 사용자가 여러 작업을 요청하면 필요한 모든 함수를 호출하세요.", } ] # 1st Turn: CSV 로드 + Smart watch as 필터링 # - 컨텍스트 요약은 턴2에서만 추가하여 중복/과다 메시지 방지 print("\n🔄 턴 1") # 유저 쿼리 작성 user_query_1 = ( "cs_data.csv 파일을 로드해줘. 그리고 Smart watch의 as 관련 데이터만 필터링해줘" ) print(f" User: {user_query_1}") print("-" * 60) messages.append({"role": "user", "content": user_query_1}) result_1 = function_call(messages) # 1차 호출 + 도구 실행 + 2차 호출로 응답 생성까지 수행 # 어시스턴트 자연어 응답은 메시지 히스토리에 추가하지 않음(Tool 결과만으로 충분) print("✅ 턴 1 완료") print('-'*60) # 2nd Turn: 이전 필터링된 Smart watch 데이터를 분석 + 결측값 제거 + CSV 저장 # filtered_df 기준으로 연속적으로 함수가 수행되는지 확인 print("\n🔄 턴 2") # 2번째 유저 쿼리 작성 user_query_2 = ( "text가 빈 값들은 제거하고 월별로 시각화 분석 한 뒤 데이터를 watch_as.csv 파일로 저장해줘." ) print(f" User: {user_query_2}") print('-'*60) append_context(messages) # 1턴 결과를 요약해 모델에 1회만 전달 messages.append({"role": "user", "content": user_query_2}) result_2 = function_call(messages) # 어시스턴트 자연어 응답은 메시지 히스토리에 추가하지 않음 print("✅ 턴 2 완료") def main() -> None: # 멀티 턴 예시를 실행 multiturn_calling() if __name__ == "__main__": main() 3. 파일 실행 앞서 구현한 파일들을 저장한채로 main.py 파일을 실행한 결과는 다음과 같습니다. 🔄 턴 1 User: cs_data.csv 파일을 로드해줘. 그리고 Smart watch의 as 관련 데이터만 필터링해줘 ------------------------------------------------------------ 함수 실행 1: load_data Arguments: {'filename': 'cs_data.csv'} 함수 결과: { "success": true, "filename": "/Users/user/fc/cs_data.csv", "rows": 500, "columns": 7, "data_info": "columns:\n • id: int64\n • date: object\n • customer_id: object\n • product_name: object\n • cs_category: object\n • text: object\n • rating: int64" } 함수 실행 2: filter_data Arguments: {'product_name': 'Smart watch', 'cs_category': 'as'} 함수 결과: { "success": true, "total_count": 500, "filtered_count": 101, "filter_conditions": [ "product_name: Smart watch", "cs_category: as" ], "preview_data": [ { "id": 5, "date": "2025-01-03", "product_name": "Smart watch", "cs_category": "as", "text": "터치가 안 되는데 수리 가능한가요", "rating": 3 }, { "id": 6, "date": "2025-01-03", "product_name": "Smart watch", "cs_category": "as", "text": NaN, "rating": 3 }, { "id": 10, "date": "2025-01-04", "product_name": "Smart watch", "cs_category": "as", "text": "지문인식이 안 되는데 AS 가능한가요", "rating": 3 } ], "message": "필터링 완료: 전체 500개 중 101개 데이터 추출 (필터링된 데이터가 저장되었습니다)" } ✅ 턴 1 완료 ------------------------------------------------------------ 🔄 턴 2 User: text가 빈 값들은 제거하고 Smart watch에 대해서 월별로 시각화 분석 한 뒤 데이터를 watch_as.csv 파일로 저장해줘. ------------------------------------------------------------ 함수 실행 1: check_data Arguments: {'check_type': 'missing', 'action': 'remove', 'column': 'text'} 함수 결과: { "success": true, "check_type": "missing", "action": "remove", "column": "text", "original_records": 101, "missing_removed": 2, "remaining_records": 99 } 함수 실행 2: analyze_data Arguments: {'product_name': 'Smart watch', 'bins': 12} 함수 결과: { "success": true, "product_name": "Smart watch", "stats": { "count": 99, "mean": 2.4343434343434343, "std": 0.9914081529558191, "min": 1.0, "25%": 1.5, "50%": 3.0, "75%": 3.0, "max": 4.0 }, "records": 99, "chart_files": [ "Smart watch_cases.png", "Smart watch_monthly_ratings.png" ] } 함수 실행 3: save_data Arguments: {'filename': 'watch_as.csv'} 함수 결과: { "success": true, "filename": "watch_as.csv", "rows": 99, "cols": 7, "data_source": "filtered", "message": "데이터 저장 완료: watch_as.csv (99개 레코드, 7개 컬럼)" } ✅ 턴 2 완료 결과 데이터 및 시각화 이미지 watch_as.csv 마무리 이번 쿡북에서는 LLM의 핵심 기능인 Function calling 기반 멀티 턴 자동화를 살펴보았습니다. 시나리오에서는 기본적인 데이터 분석 도구를 사용했지만, 시각화, 감성 분석, 요약 등 다양한 함수를 추가해 더 풍부한 분석을 할 수 있습니다. 예제에서는 원할한 이해를 위해 한 번의 함수 실행으로 멀티 턴을 구현했지만, 실제 환경에서는 단계별 입력을 받아 결과를 확인하고 다음 작업을 결정할 수 있습니다. 이를 통해 필요에 따라 턴을 추가·수정하며 유연한 분석이 가능합니다. 이 쿡북을 통해 Function Calling 역량을 높이고, 자신만의 자동화 솔루션을 구축해 보세요! 🚀
-
들어가며 본 쿡북에서는 CLOVA Studio의 Chat Completions v3 API를 활용해, 외부 데이터를 조회하거나 도구를 실행하고 그 결과를 반영해 응답하는 AI 어시스턴트를 구축하는 방법을 소개합니다. Chat Completions v3 API 가이드는 다음 링크를 참고해 주세요. (링크) 작동 원리 본 쿡북에서는 금융 어시스턴트를 제작하는 과정을 예제로 다룹니다. 먼저, 어시스턴트의 작동 원리를 살펴보겠습니다. 사용자가 입력한 내용은 messages와 사전에 정의된 tools(functions) 정보가 함께 Function calling 모델에 전달되어 검토됩니다. Function calling 모델은 적합한 function을 선택하고 arguments 값을 응답하는데, 이 과정에서 사용자 발화가 정의된 tools와 무관하다고 판단이 되면 고정 응답이 반환됩니다. 생성된 Function calling 응답은 사용자가 직접 실행하여 그 결과를 messages에 업데이트한 뒤, 다시 Chat Completions API에 전달합니다. Chat Completions이 호출되면 설정된 시스템 프롬프트와 파라미터 값에 기반하여 LLM이 최종 답변을 생성합니다. 사용 시나리오 다음으로, 금융 어시스턴트의 사용 시나리오를 살펴보겠습니다. 시나리오는 아래와 같이 1) 특정 종목의 주가 정보 2) 주식 주문 3) 환율 계산기 도구와 4) 고정 응답으로 구성됩니다. 다음 가이드를 따라 금융 어시스턴트를 직접 만들어 보고, 자신만의 AI 어시스턴트로 확장해 보세요! 🚀 환경 설정 필요한 라이브러리 설치 및 임포트 FinanceDataReader는 국내 및 해외의 금융 데이터(주가, 지수 등)를 불러올 수 있는 파이썬 오픈소스 라이브러리 입니다. 다음 코드를 실행하여 필요한 라이브러리를 설치하고 임포트 하세요. Chat Completions v3 API 요청 정의 Chat Completions v3 API를 통해 함수 호출(Function calling)과 일반 대화 응답 생성을 모두 처리할 수 있습니다. 요청 본문에 도구 정의(tools)를 함께 전달하면, 사용자의 입력에 따라 필요한 도구가 자동으로 선택되고 실행됩니다. 이때 주식 데이터 조회(get_stock_data), 주식 주문(order_stock), 환율 계산(calculate_currency)의 세 가지 도구를 사용할 수 있으며, "toolChoice": "auto"로 설정하면 도구 선택이 자동으로 이뤄집니다. 반대로, 도구를 포함하지 않은 요청은 일반 LLM 응답 생성으로 처리됩니다. 이 경우 temperature, maxTokens 등의 생성 파라미터를 활용해 응답의 스타일과 길이를 조절할 수 있습니다. 성능과 목적에 따라 적합한 모델(HCX-DASH-002, HCX-005)을 선택하여 활용해 주세요. def chat_completions(messages, tools=None, tool_choice="auto", **generation_params): url = "YOUR_API_URL" # 테스트 앱/서비스 앱을 통해 발급 받은 Chat Completions API 호출 경로를 입력하세요. headers = { "Authorization": "Bearer YOUR_API_KEY", # 본인이 발급 받은 API Key를 입력하세요. "X-NCP-CLOVASTUDIO-REQUEST-ID": "YOUR_REQUEST_ID", # 본인이 발급 받은 API의 요청 ID를 입력하세요. "Content-Type": "application/json" } data = { "messages": messages, "toolChoice": tool_choice if tools else "none", **generation_params } if tools: data["tools"] = tools response = requests.post(url, headers=headers, json=data) return response.json() Tools 정의 도구 호출을 활용하려면, API 요청 본문에 사용할 함수 목록을 tools 필드에 정의해야 합니다. 아래는 이 예제에서 사용되는 세 가지 함수 정의입니다. get_stock_data: 특정 종목의 주가나 거래량을 조회합니다. order_stock: 주식을 매수하거나 매도할 수 있습니다. 시장가 또는 지정가 주문을 지원합니다. calculate_currency: 특정 금액을 다른 통화로 환산할 수 있습니다. 각 함수는 이름(name), 설명(description), 입력 파라미터(parameters)로 구성되며, 파라미터는 모두 JSON Schema 형식으로 정의됩니다. 이 정의를 통해 LLM은 어떤 도구가 어떤 인자를 필요로 하는지 이해하고, 사용자 입력에 따라 적절히 호출할 수 있게 됩니다. tools = [ { "type": "function", "function": { "name": "get_stock_data", "description": "특정 종목의 현재 혹은 과거 주가와 거래량을 조회할 수 있습니다.", "parameters": { "type": "object", "properties": { "ticker": { "description": "조회할 종목 코드(ticker)입니다. ex. 네이버의 종목코드는 035420", "type": "string" }, "date": { "description": "조회 날짜입니다. (형식: 'YYYY-MM-DD')", "type": "string" }, "result_type": { "description": "조회 유형입니다.", "type": "string", "enum": ["price", "volume"] } }, "required": ["ticker", "date", "result_type"] } } }, { "type": "function", "function": { "name": "order_stock", "description": "시장가/지정가로 주식을 주문할 수 있습니다.", "parameters": { "type": "object", "properties": { "ticker": { "description": "주문할 종목 코드(ticker)입니다. ex. 네이버의 종목코드는 035420", "type": "string" }, "action_type": { "description": "매수/매도를 지정합니다.", "type": "string", "enum": ["매수", "매도"] }, "shares": { "description": "주문 주식 수를 설정합니다.", "type": "integer" }, "order_type": { "description": "주문 유형을 지정합니다.", "type": "string", "enum": ["시장가", "지정가"] }, "order_price": { "description": "지정가일 경우 가격을 설정합니다.", "type": "number" } }, "required": ["ticker", "action_type", "shares", "order_type"] } } }, { "type": "function", "function": { "name": "calculate_currency", "description": "환율 계산을 도와줍니다.", "parameters": { "type": "object", "properties": { "from_currency": { "description": "환전 대상 화폐 종류를 설정합니다.", "type": "string", "enum": ["KRW", "USD", "EUR", "JPY"] }, "to_currency": { "description": "환전하고자 하는 화폐 종류를 설정합니다.", "type": "string", "enum": ["KRW", "USD", "EUR", "JPY"] }, "amount": { "description": "총 환전 대상 금액입니다. (from_currency 기준)", "type": "number" }, "date": { "description": "환율 기준 날짜입니다. (형식: 'YYYY-MM-DD')", "type": "string" } }, "required": ["from_currency", "to_currency", "amount", "date"] } } } ] 사용자 함수 정의 앞서 정의한 세 가지 도구를 처리하는 사용자 정의 함수를 구현합니다. 사용자 함수는 API 뿐만 아니라 데이터베이스, 로컬 또는 클라우드 저장소의 파일 등 다양한 소스 및 기능과 연동하여 활용될 수 있습니다. get_stock_data 파이썬 오픈소스 라이브러리(FinanceDataReader)를 활용해 주식 데이터를 조회하는 함수를 정의합니다. 종목 코드와 날짜를 기반으로, 해당 시점의 주가 또는 거래량 데이터를 반환합니다. 이외 다양한 금융 데이터 소스와 연동하거나, 데이터 처리 로직을 추가해 보다 심화된 결과를 제공할 수 있습니다. def get_stock_data(ticker, date, result_type): stock_data = fdr.DataReader(ticker, date) if stock_data.empty: return [{"name": "get_stock_data", "response": f"{ticker}에 대한 {date} 데이터가 없습니다."}] row = stock_data.iloc[0] if result_type == "price": return [{"name": "get_stock_data", "response": {"date": date, "price": float(row['Close'])}}] elif result_type == "volume": return [{"name": "get_stock_data", "response": {"date": date, "volume": int(row['Volume'])}}] else: return [{"name": "get_stock_data", "response": "잘못된 조회 유형입니다. '가격' 또는 '거래량'만 조회 가능합니다."}] order_stock 주식 주문을 처리하는 함수를 정의합니다. 종목 코드, 주문 유형(매수, 매도) 등을 바탕으로 처리한 결과를 반환합니다. 현재는 예제로서 단순 메시지를 반환하지만, 실제로는 주문 데이터를 DB에 기록하거나 주문 API를 호출하는 방식으로 확장 가능합니다. def order_stock(ticker, action_type, shares, order_type, order_price=None): if order_type == "지정가" and (order_price is None or order_price <= 0): return [{"name": "order_stock", "response": "지정가 주문에는 유효한 가격이 필요합니다."}] # DB 연동하여 확장 가능 return [{"name": "order_stock", "response": f"{ticker} 종목 {shares}주 {order_type}로 '{action_type}' 주문 완료"}] calculate_currency 환율 계산을 수행하는 함수를 정의합니다. 환전할 금액, 통화 종류 등을 입력 받아 계산 결과를 반환합니다. 현재는 예제로서 하드코딩 된 가상의 고정 환율 데이터를 사용하고 있지만, 실제로는 로컬 파일(json, xls, txt 등) 또는 외부 API를 통해 데이터를 읽어오는 방식으로 확장할 수 있습니다. def calculate_currency(from_currency, to_currency, amount, date): exchange_rates = { "KRW": {"USD": 0.0006725, "EUR": 0.0006178, "JPY": 0.09817}, "USD": {"KRW": 1487.07, "EUR": 1.0884, "JPY": 150.99}, "EUR": {"KRW": 1618.79, "USD": 0.9188, "JPY": 138.74}, "JPY": {"KRW": 10.187, "USD": 0.00662, "EUR": 0.00721}, } rate = exchange_rates.get(from_currency, {}).get(to_currency) if not rate: return [{"name": "calculate_currency", "response": "지원되지 않는 통화입니다."}] converted_amount = round(amount * rate, 2) return [{"name": "calculate_currency", "response": f"{converted_amount} {to_currency}"}] 함수 실행 처리 다음으로 정의한 process_tool_calls는 해당 도구에 정의된 함수와 매개변수를 매핑하여 동적으로 실행해 주는 역할을 합니다. 이를 통해 다양한 도구 호출 시 공통 로직을 단순화할 수 있습니다. def process_tool_calls(tool_name, arguments): tool_map = { "get_stock_data": get_stock_data, "order_stock": order_stock, "calculate_currency": calculate_currency } func = tool_map.get(tool_name) # 추출한 매개변수를 키워드 인수로 함수에 전달하여 실행합니다. return func(**arguments) 실행 및 테스트 사용자 요청을 처리하고 최종 응답을 생성하는 전체 실행 과정을 테스트합니다. 사용자 쿼리를 입력하면 적합한 도구를 선택해 실행한 결과를 AI 대화 흐름에 추가하여 응답을 제공합니다. 단, 도구 사용이 불필요하거나 적합한 도구가 없으면 'toolCalls'가 반환되지 않고 'assistant'의 일반 답변이 생성됩니다. 아래 코드는 이러한 상황을 감지하고 이후 처리를 분기하도록 구성되어 있습니다. query = "YOUR_QUERY" messages = [{"role": "user", "content": query}] print(f"User: {query}") # Step 1. 요청 — 입력 및 함수 정의 전달 function_response = chat_completions( messages = messages, tools = tools ) # Step 2. 응답 — 호출할 함수 및 인수 추출 tool_calls = function_response.get("result", {}).get("message", {}).get("toolCalls", []) try: if not tool_calls: # 도구 호출이 없을 경우 final_answer = function_response.get("result").get("message").get("content") print(f"Assistant: {final_answer}") else: # 도구 호출이 있을 경우 messages.append({"role": "assistant", "content": "", "toolCalls": tool_calls}) tool_call = tool_calls[0] print(f"\nAssistant: {tool_call}\n") # Step 3. 함수 실행 — 응답 기반으로 실제 함수 호출 tool_call_id = tool_call["id"] tool_name = tool_call["function"]["name"] arguments = tool_call["function"]["arguments"] results = process_tool_calls(tool_name, arguments) messages.append({"role": "tool", "content": str(results), "toolCallId": tool_call_id}) print(f"Tool: {results}\n") # Step 4. 요청 — 함수 실행 결과 전달 chat_response = chat_completions( messages = messages, seed = 0, topP = 0.8, topK = 0, maxTokens = 1024, temperature = 0.5, repeatPenalty = 1.1, stopBefore = [], includeAiFilters = True ) # Step 5. 응답 — 최종 답변 추출 final_answer = chat_response.get("result").get("message").get("content") print(f'Assistant: {final_answer}') except Exception as e: error_message = f"요청 처리 중 오류가 발생했습니다: {str(e)}" print(f"Assistant: {error_message}") 다음은 위 코드 실행 시 출력 예시입니다. 이 출력은 사용자 요청이 Function calling과 사용자 정의 함수를 거쳐 최종 응답으로 생성되는 단계를 순차적으로 보여줍니다. output sample 1 User: 네이버 그저께 주가 Assistant: {'id': 'call_abA5RsWViXcaCa7FCWg1eoDf', 'type': 'function', 'function': {'name': 'get_stock_data', 'arguments': {'ticker': '035420', 'date': '2025-04-06', 'result_type': 'price'}}} Tool: [{'name': 'get_stock_data', 'response': {'date': '2025-04-06', 'price': np.float64(191800.0)}}] Assistant: 네이버의 그저께 주가는 191,800원이었습니다. output sample 2 User: 엔비디아 10주를 100불에 매도해줘 Assistant: {'id': 'call_Vy7hJQnTicsB1PFa4tscjl0W', 'type': 'function', 'function': {'name': 'order_stock', 'arguments': {'ticker': 'NVDA', 'action_type': '매도', 'shares': 10, 'order_type': '지정가', 'order_price': 100}}} Tool: [{'name': 'order_stock', 'response': "NVDA 종목 10주 지정가로 '매도' 주문 완료"}] Assistant: 사용자님께서 말씀하신 NVDA 종목 10주에 대한 지정가 매도 주문이 완료되었습니다. output sample 3 User: 만원을 달러로 환전하면 얼마인가요 Assistant: {'id': 'call_b7ianfYh9jiEk1csGgWCZKiI', 'type': 'function', 'function': {'name': 'calculate_currency', 'arguments': {'from_currency': 'KRW', 'to_currency': 'USD', 'amount': 10000, 'date': '2025-04-08'}}} Tool: [{'name': 'calculate_currency', 'response': '6.76 USD'}] Assistant: 만 원(10,000 KRW)을 달러로 환전하면 약 6.76 USD입니다. (환율은 2025년 4월 8일 기준입니다.) output sample 4 User: 개나리로 삼행시 지어줘 Assistant: '개': 개성 넘치는 모습으로 우리 곁에 찾아온 봄의 전령사, '나': 나날이 화사하게 피어나는 노란 꽃잎들이 마음을 설레게 하고, '리': 리듬을 타듯 춤추며 흩날리는 모습이 아름다운 개나리여. 봄바람에 살랑살랑 흔들리며 사람들에게 행복을 선사하는 개나리의 아름다움을 시로 표현해 보았습니다. 실전 활용 팁 이 섹션에서는 Function calling에서 복잡한 사용자 요청을 효과적으로 처리하는 방법을 예시와 함께 알아봅니다. 예를 들어, 특정 종목의 주가를 조회하면서 동시에 주식 주문을 처리하는 복잡한 멀티 쿼리 시나리오도 쉽게 해결할 수 있습니다. 1. 병렬 도구 호출: 여러 도구를 동시에 실행하기 여러 도구를 동시에 호출한 뒤, 그 결과를 종합하여 사용자 요청에 응답할 수 있습니다. 복잡한 요청을 단계별로 실행할 때 유용합니다. User: 지금 테슬라 주가 얼마야? 시장가로 20주 매수 주문해줘. Assistant: [{'id': 'call_eeYdvrLHG69sYFJgC95XBjCd', 'type': 'function', 'function': {'name': 'get_stock_data', 'arguments': {'ticker': 'TSLA', 'date': '2025-04-08', 'result_type': 'price'}}}, {'id': 'call_fsVYRYX5hGI9OvzObPe4gxqG', 'type': 'function', 'function': {'name': 'order_stock', 'arguments': {'ticker': 'TSLA', 'action_type': '매수', 'shares': 20, 'order_type': '시장가'}}}] Tool: [{'name': 'get_stock_data', 'response': {'date': '2025-04-08', 'price': 233.2899932861328}}] Tool: [{'name': 'order_stock', 'response': "TSLA 종목 20주 시장가로 '매수' 주문 완료"}] Assistant: 현재(2025년 4월 8일) 테슬라(TSLA)의 주가는 **233.29** 달러입니다. 또한 요청하신 대로 시장가로 20주를 매수하는 주문을 완료했습니다. 추가적인 도움이 필요하시면 말씀해 주세요! 2. 도구 간 의존성 처리: 특정 도구의 출력 결과를 다른 도구의 입력으로 사용하기 한 도구의 출력이 다른 도구의 입력으로 사용되는 경우, 시스템 프롬프트와 큐(queue)를 활용하여 도구 간 의존성을 처리할 수 있습니다. Function calling 호출 시 시스템 프롬프트에 의존성을 "@도구이름.출력키" 형식으로 명시하게끔 하여 각 도구가 필요한 데이터를 다른 도구의 결과에서 자동으로 참조하도록 설정합니다. 그리고 각 도구 호출은 큐로 관리하며, 의존성이 해결된 도구부터 순차적으로 실행해 결과를 축적하고, 의존성이 충족되지 않은 도구는 다시 큐에 삽입해 처리합니다. 결과적으로 모든 호출이 처리된 후 최종 응답을 생성하여 사용자에게 제공합니다. User: 오늘 테슬라 주가 알려주고 한화로 계산하면 얼마인지 계산해줘 Assistant: {'id': 'call_QqLOLiZYwgqG44mXXNP2ktHL', 'type': 'function', 'function': {'name': 'get_stock_data', 'arguments': {'ticker': 'TSLA', 'date': '2025-04-08', 'result_type': 'price'}}} Tool: {'date': '2025-04-08', 'price': 233.2899932861328} Assistant: {'id': 'call_Gc7gkcZUItMKF3n6sw3p6nw3', 'type': 'function', 'function': {'name': 'calculate_currency', 'arguments': {'from_currency': 'USD', 'to_currency': 'KRW', 'amount': 233.2899932861328, 'date': '2025-04-08'}}} Tool: 346487.31 KRW Assistant: 2025년 4월 08일 기준으로 테슬라(TSLA)의 주가는 **233.29 USD**이며, 이를 한화로 환산하면 약 **346,487원**입니다. 마무리 CLOVA Studio의 Chat Completions v3 API를 활용해, 도구(Function)를 호출하고 자연스러운 대화 응답을 생성하는 방법을 살펴보았습니다. 이번 쿡북을 통해 Function calling의 작동 원리를 이해하고, 이를 활용해 자신만의 데이터 소스와 도구를 결합하여 AI 어시스턴트를 제작해 보시길 바랍니다!
-
- 1
-

-
- agent
- function calling
- (and 1 more)
-
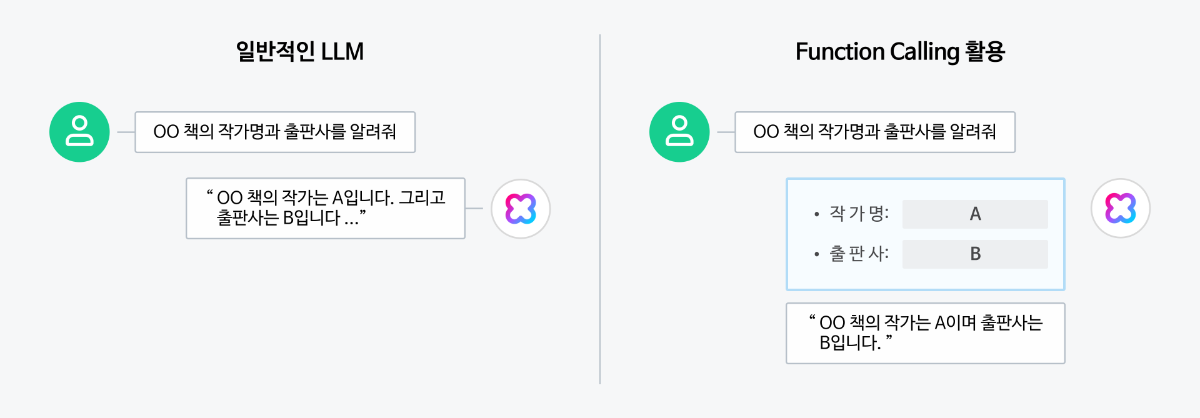
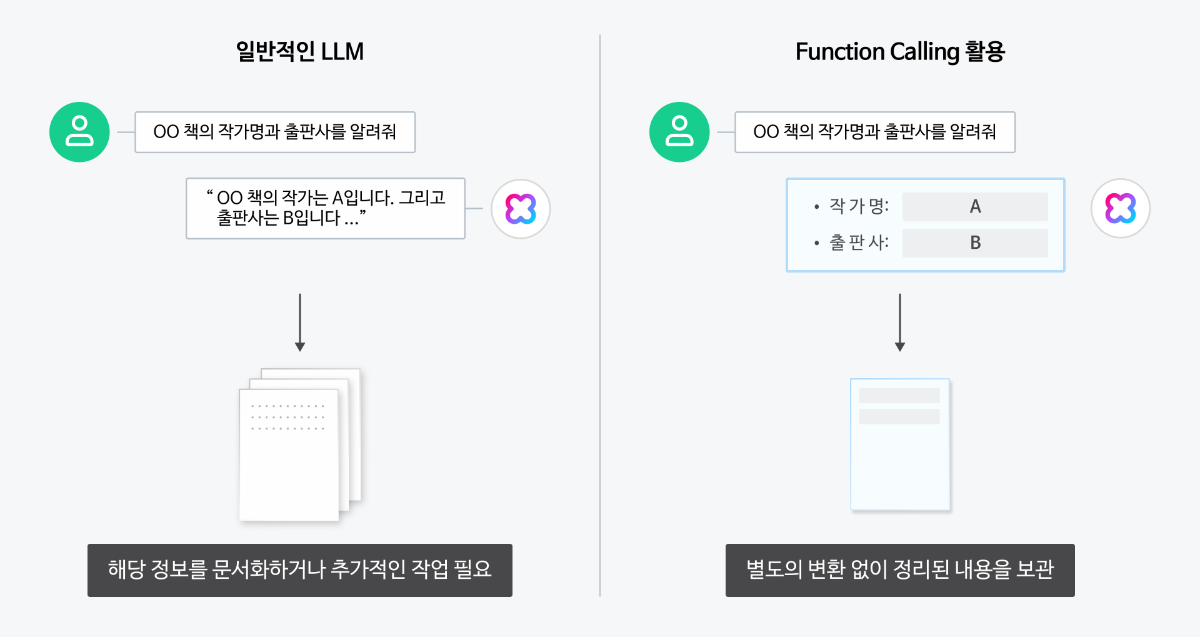
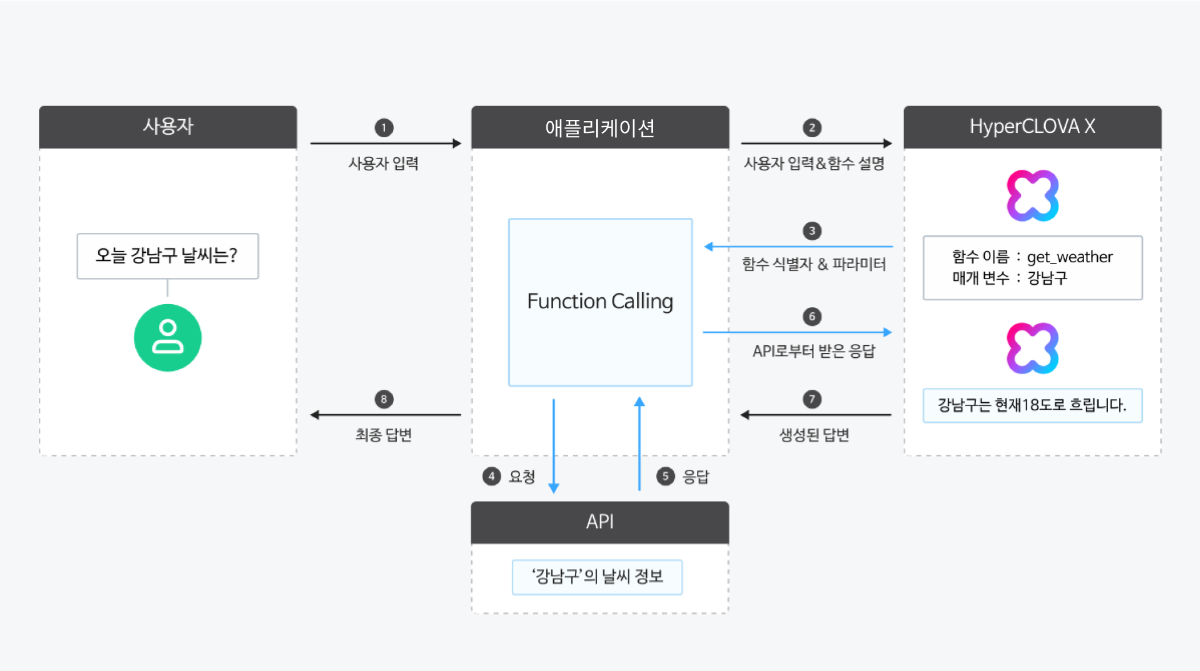
Function calling, 쉽게 알아보기 LLM 에이전트가 우리의 모든 질문에 답변할 수 있다면 얼마나 편리할까요? 하지만 LLM은 미리 학습한 데이터를 기반으로 답변하기 때문에 실시간 정보 제공이나 외부 데이터 활용에 한계가 있습니다. 이러한 문제를 해결하기 위해 등장한 기술이 바로 'Function calling'입니다. 이 기능은 LLM이 외부 도구를 활용해 필요한 정보를 가져올 수 있도록 돕는 역할을 합니다. 모델이 스스로 해결할 수 없는 질문이 있을 때, 외부에서 정보를 받아와 더 정확한 답변을 제공할 수 있습니다. 이처럼 LLM이 외부 시스템이나 API를 사용할 수 있기 때문에, Function calling을 '도구(tool)'라고도 부릅니다. Function calling은 스킬(참고: 스킬 트레이너)과 유사해 보일 수 있지만 차이가 있습니다. 스킬은 트레이너 내에 API를 등록해 모델이 스스로 답변까지 생성해 주는 반면, 이 기능은 개발자가 외부 API를 직접 실행해야 합니다. 또한, Function calling은 API뿐만 아니라 스크립트나 라이브러리 내 함수 호출도 가능하다는 점에서 차이가 존재합니다. Function calling이 무엇인지, 그리고 어떻게 활용할 수 있는지 소개해드리겠습니다. Function calling은 어떻게 작동할까요? Function calling은 LLM(대규모 언어 모델)이 사용자의 질문에 맞춰 미리 정의된 함수를 사용해 필요한 기능을 실행하도록 돕는 방식입니다. 예를 들어, 사용자가 ❶"오늘 강남구 날씨는 어때?"라고 질문하면, ❷모델은 이 질문을 전달 받아 분석해 ❸사전에 정의된 함수 중 get_weather를 사용해야 한다고 판단합니다. 이 과정에서 모델은 "강남구"라는 위치 정보와 "2025-04-17"이라는 날짜를 파라미터로 추출합니다. 여기서 중요한 점은, 모델은 함수를 직접 호출하지 않는다는 것 입니다. 대신, 모델은 사용할 함수를 결정하고 필요한 매개변수를 포함한 데이터를 생성합니다. 즉, 사용자의 요청에 따라 미리 정의된 함수 중 어떤 것을 사용하고 어떤 값을 넣어야 할지 결정하는 역할을 합니다. 이후, ❹외부의 날씨 서비스 API에 연결해 ❺실시간 날씨 데이터를 받아오고, ❻그 정보를 모델에게 전달하면 ❼ 모델이 최종답변을 완성합니다. 이를 통해 ❽"현재 강남구의 온도는 18도 이고, 날씨는 흐립니다." 와 같은 응답을 제공할 수 있습니다. Function calling은 실제로 어떻게 사용하나요? 앞서 설명드린 동작 과정을 바탕으로, "사용자 입력 → 모델이 tool 선택 → 외부 함수 결과 전달 → 최종 응답 생성" 이라는 흐름이 코드에서 어떻게 구현되는지 아래 예시를 참고해주세요. Step 1: 사용자 메시지+함수 정의 전송 사용자 입력과 함께 사용할 수 있는 함수 목록을 모델에 전달합니다. 모델은 이를 바탕으로 어떤 도구(tool)를 사용할지 결정합니다. 응답 결과 Step 2: toolCallId에 대한 함수 결과 전달 모델이 사용자 입력에 대해 get_weather 함수를 호출해야 한다고 판단했습니다. 이제 실제 날씨 API를 호출한 결과를 "role": "tool" 메시지로, toolCallId와 함께 전달합니다. 이때는 함수 정의를 다시 포함하지 않아도 되지만, 이후에 사용자로부터 추가 질문(예: "그럼 부산 날씨는 어때?")이 들어올 가능성이 있다면 해당 함수 정의를 다시 포함해 전달하는 것이 좋습니다. Step 3: 최종 응답 생성 모델은 전달받은 함수 결과를 바탕으로 사용자에게 자연스러운 형태의 최종 응답을 생성합니다. Function calling, 이렇게 사용해보세요! 1. 외부 시스템과 연동된 LLM 에이전트 설계하기 Function calling은 LLM이 외부 데이터를 활용하여 더욱 다양한 기능을 제공할 수 있도록 만들어줍니다. 이를 통해 단순한 질의응답을 넘어 고객의 다양한 요구를 충족시키고 반영할 수 있습니다. Shopping LLM 에이전트에서 특정 상품의 재고를 조회하는 방법 Shopping 에이전트를 제작할 때, 여러 가지 함수들을 사전에 정의합니다. 여기에는 재고 조회, 상품 정보 조회, 결제 처리 등 다양한 함수를 포함할 수 있습니다. 예를 들어, 사용자가 특정 상품의 재고를 물어볼 경우엔 getCount 함수를 사용할 수 있습니다. 이 함수는 특정 상품의 ID와 사용자가 위치한 지역 코드를 기반으로 상품의 재고 수량을 확인할 수 있습니다. Function calling은 먼저 사용자의 쿼리(예: “이 상품 재고 있나요?”)에서 getCount 함수를 선택하고 필요한 파라미터(상품 ID, 지역 코드)를 추출합니다. 이후 함수를 실행한 결과값(예.재고:5권)을 모델에게 전달하면 모델이 최종 답변을 생성하여 사용자에게 응답할 수 있습니다. 2. 작업 자동화를 통해 업무 효율성 증진하기 기존의 작업 자동화 방식은 명확한 룰 베이스에 기반한 반복 업무에 특화되어 있었지만, LLM으로 이러한 한계를 극복할 수 있게 되었습니다. 이때 Function calling은 외부 시스템과 연동을 통해 자동화 영역을 확장하고, 더 많은 작업을 처리하도록 도와줍니다. 매일 아침 최신 기사들의 내용을 요약하여 사내 게시판에 업로드하기 뉴스 API를 통해 최신 뉴스를 수집한 후, LLM 모델을 사용하여 각 기사의 핵심 내용을 요약할 수 있습니다. (참고 : 시간이 부족한 모두를 위한 요약 API, 이렇게 활용하세요) 사내 게시판에 업로드하기 위해 uploadnews 함수를 미리 정의하며, 이 함수는 게시글의 제목과 내용을 입력값으로 받습니다. 이후 Function calling을 사용해, LLM이 요약한 내용에서 제목과 본문을 추출하고 이를 uploadnews 함수에 전달합니다. uploadnews 함수가 실행되면 사내 게시판에 요약된 뉴스들이 게시되고, 이를 확인할 수 있습니다. 3. 필요한 정보 추출하기 Function calling은 일반적인 LLM보다 자연어 문서에서 핵심 정보를 추출하는 작업에 더욱 효과적입니다. 1) 명확하게 정해진 형식(스키마)에 맞춰 핵심 데이터 추출 가능 특정 책에 대한 작가명과 출판사를 추출하는 상황을 가정해봅시다. Function calling을 활용하면, 마치 설문지를 작성하 듯 질문에 맞춰 데이터를 정리된 형식으로 반환하여 이를 바탕으로 답변을 생성합니다. 이처럼 데이터를 구조화된 형식을 정의하면, LLM이 자연어 기반의 문서로부터 필요한 정보를 항목별로 추출할 수 있도록 도와줍니다. 2) JSON 형식의 결과 데이터를 별도의 변환 과정 없이 추가 작업 가능 뉴스 정보 추출이 완료되면, 추출된 정보를 저장하는 추가 작업이 필요합니다. 일반적인 LLM의 답변은 자유로운 형태로 제공되지만, 구체적인 형식이나 구조가 부족해 문서화나 저장을 위해 추가 작업이 필요할 때가 있습니다. 이때 Function calling을 사용하면 추출된 데이터를 JSON 형식으로 바로 응답받을 수 있어 별도의 변환 작업이 필요하지 않습니다. 추출된 데이터를 DB에 저장할 때는 정리된 설문지를 그대로 보관하는 것처럼, JSON 형식으로 받은 데이터를 그대로 전달할 수 있습니다. Function calling 성능 업그레이드 비법 1. 자세한 설명과 함께 직관적인 이름 사용하기 함수 및 매개변수의 이름은 쉽게 알아볼 수 있도록 명확하게 지정하는 것이 중요합니다. 약어나 줄임말은 지양하고, 함수가 언제 호출되어야 하는지 설명을 함께 제공하는 것이 좋습니다. 복잡한 함수의 경우, 각 매개변수가 어떤 역할을 수행하는지 설명해주면 도움이 됩니다. 함수 설명은 최소 3~4문장 이상으로 구성하여, 함수의 사용 시점과 제한 사항 그리고 매개변수가 함수의 동작에 미치는 영향을 포함합니다. 2. 명확한 매개변수 지정하기 직관적인 매개변수의 이름과 함께 설명을 제공합니다. 예를 들어, 날짜 형식을 필요로 하는 매개변수의 경우 YYYY-MM-DD 또는 DD/MM/YY와 같은 형식을 명확히 설명하여 사용자가 올바르게 입력할 수 있도록 합니다. 3. 열거형으로 명확한 매개변수 값 제한하기 가능하다면 매개변수에 열거형(enum)을 사용하여 값을 제한하는 것이 좋습니다. 예를 들어, 티셔츠의 사이즈를 선택할 때 S, M, L과 같은 옵션으로 값을 명확하게 제한하면 모델이 더 정확하게 작동할 수 있습니다. 이를 통해 잘못된 값이나 예상치 못한 값이 반환되는 상황을 줄일 수 있습니다. { "name": "pick_tshirt_size", "description": "사용자가 원하는 티셔츠 사이즈를 선택할 때 사용", "parameters": { "type": "object", "properties": { "size": { "type": "string", "enum": ["s", "m", "l"], "description": "사용자가 선택한 티셔츠 사이즈" } }, "required": ["size"], "additionalProperties": false } } 4. 함수의 개수 최적화하기 한 번에 너무 많은 함수를 사용하지 않도록, 10~20개 내외로 유지하는 것이 좋습니다. 그 이상이 되면 모델이 올바른 함수를 선택하는 데 어려움을 겪을 수 있습니다. 필요한 기능이 많다면, 함수들을 논리적으로 그룹화하거나 여러 도구(tool)로 나누어 사용해보세요. 마무리 CLOVA Studio Chat Completions v3 API의 Function calling의 기능을 알아보고 활용법을 알아보았습니다. 외부 데이터를 가져오고 실제 액션을 수행할 수 있는 Function calling을 어떻게 활용할 수 있을지 고민해보세요.🚀
-
- 2
-
-
- function calling
- tool
- (and 1 more)
-
@MRN님 안녕하세요! 문의주신 내용이 실제 스킬셋 서비스 API 호출이 아닌 스킬 트레이너 내 데이터 수집 페이지에서 "Step2의 결과호출" 부분을 수정하고 싶으신 것으로 이해했는데 맞을까요? Step 2 액션입력 부분의 키워드를 수정하시고 "적용" 버튼을 누르시면 결과 호출을 다시 하실 수 있습니다. 혹시 문의주신 내용과 다르다면 조금 더 구체적인 설명을 부탁드리겠습니다. 감사합니다.
-
안녕하세요. 샘플 스킬셋 호출을 위한 호출옵션 예제 전달드립니다. 발급 받으신 X-Naver-Client-Id 와 X-Naver-Client-Secret을 각 필드에 입력 후, 적용하기 버튼을 누르시고 쿼리를 실행하시면 됩니다. { "baseOperation": { "header": { "X-Naver-Client-Id": "", "X-Naver-Client-Secret": "" }, "query": null, "requestBody": null } } 혹시 다른 궁금하신 점이 있으시다면 말씀주세요. 감사합니다.