모바일
-
게시글
24 -
첫 방문
-
최근 방문
-
Days Won
2
Content Type
Profiles
Forums
Articles
Everything posted by 모바일
-
그러면 chat completion api랑 skillset api랑 같이 써야하는데, chat completion api를 계속 호출하면서 대화하다가 skillset 호출 쿼리를 사용자가 쓰게 되면 자동으로 알아서 skillset api가 호출이 되는 건가요, 아니면 chat completion을 호출해서 대화하다가 특정 경우에 skillset 호출하라고 분기를 나눠줘야 하는건가요?
-
@CLOVA Studio 운영자6 그렇다면 별도의 판별 모델을 앞단에 구성하지 않아도 해당 query가 인입되면 스킬셋이 알아서 호출되는게 맞는 건가요?
-
@CLOVA Studio 운영자6 테스트앱 코드 자체로는 호출은 잘 됩니다! 그런데 이걸 모바일 어플 코드에 적용을 하려고 하는데, 사용자가 하는 말 전부가 query로 들어가게 만들어서 스킬 관련 대화를 하면 그 때 자동으로 스킬이 호출되는 것인지, 아니면 특정 단어를 말했을 때에만 사용자가 한 말이 스킬셋 호출 쿼리로 들어가게 만들어야 하는건지가 궁금합니다.
-
스킬 트레이너 api 호출과 관련해서 문의 드립니다. 스킬셋 구성은 해놓은 상태이고, 테스트앱에 적용해서 확인을 해보고 싶은데요. api 가이드를 봐도 정확하게 이해가 되지 않아서요. 예를 들어, "수수께끼 놀이하자"라고 말했을 때 스킬셋이 호출되어 스토리지에 있는 수수께끼 문제를 내도록 만들어서 학습까지 다 시켜놓은 상태라면 사용자가 HCX와 대화를 하다가 "수수께끼 놀이하자"와 같은 말을 한다면 자동으로 스킬셋이 호출되어야 하는 거잖아요. 그럼 그 스킬셋을 호출하도록 api를 쓸 때 "수수께끼 놀이하자"라는 말과 일치했을 때 스킬셋 api가 호출되도록 코드 상으로 적어놓아야 하는 건지 아니면 코드 상으로 특정 단어를 검토하여 일치하는 경우에만 api가 호출되도록 적어놓지 않아도 알아서 스킬셋이 호출되는 건지 궁금합니다. 현재는 코드 상으로 굳이 수수께끼 하자를 써놓지 않은 상태인데, 수수께끼 하자고 했을 때 스킬셋이 호출 되지 않는상태입니다.
-
프롬프트에 판단 과정은 출력하지 말라고 하니까 되네요. 감사합니다!
-
@CLOVA Studio 운영자 답변 감사합니다. 위와 같이 정답 판별하는 과정을 시스템 프롬프트로 주는 경우에 답변에 정답 판별하는 과정이 포함되는데, 과정은 출력되지 않도록 하는 것도 가능할까요?
-
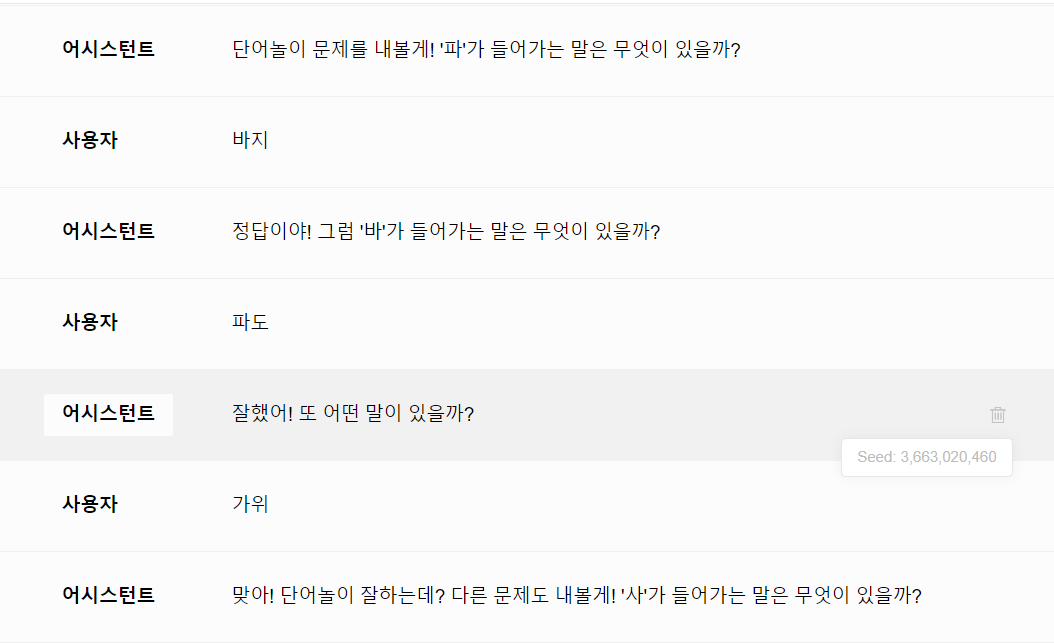
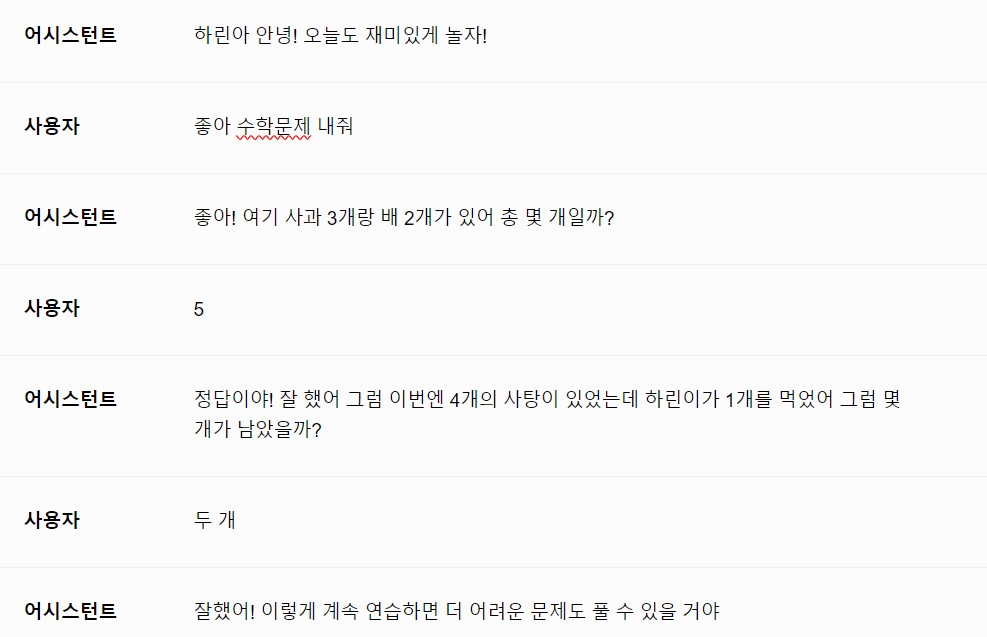
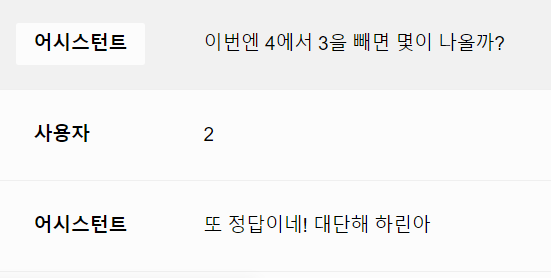
하이퍼클로바가 한글 문제나 수학 문제를 내면, 사용자가 답을 맞히는 대화를 하도록 설계를 하고 있는데요. 사용자가 틀린 답을 말해도 다 정답이라고 하는 경우가 대부분이더라구요. 첨부한 스크린샷의 덧셈문제는 hcx-003 모델과 hcx-dash-001 모델을 사용했고, 단어놀이 문제의 경우는 해당 문제를 내도록 튜닝한 hcx-003 모델을 사용했습니다. 참고로 특정 단어가 포함된 단어를 물어보는 경우, 아래와 같은 내용으로 시스템 프롬프트를 여러 번 작성해보고, 변경도 해가면서 실행을 해보았습니다. <단어놀이 하는 방법> 문제 : '아'가 들어가는 단어는 무엇이 있을까? 1.사용자 : 아이스크림 어시스턴트 : '아이스크림'을 '아', '이', '스', '크', '림'으로 한 글자 씩 나눠서 '아'라는 글자가 있는지 확인을 함. '아' 는 '아'와 같음. '이' 는 '아'와 다름. '스' 는 '아'와 다름. '크' 는 '아'와 다름. '림' 는 '아'와 다름. 따라서 '아'와 같은 단어가 있으므로 정답 2.사용자 : 앙팡 어시스턴트 :'앙'과 '팡'으로 한 글자씩 나눠서 '아'라는 글자와 같은지 다른지 비교. '앙' 은 '아'와 다름. '팡' 은 '아'와 다름. 따라서 '아'와 같은 글자가 없음. 틀린 답. HCX-003 모델의 경우, 오답 판별을 잘하기도 하지만, 여전히 못 하는 경우도 있었습니다. 문제 : "사" 가 들어가는 단어가 무엇이 있을까? <오답을 오답이라고 판단> 1. 글자별로 나누면 '가' , '방' 인데 둘 다 '사'와는 다르네요. 가방이란 단어에는 '사'가 포함되어 있지 않습니다. 2. 빠르게 구분 하겠습니다.'산', '기', '슭' 이며 셋 다 '사'와 상이하므로 산기슭이라는 단어내에는 '사'가 없어요. 3. 나누면 '의' 와 '자'인데 두 개 모두 '사'와는 다릅니다. 의자라는 단어 안에는 '사'가 들어가 있지 않네요. <오답을 정답이라고 판단> 1. 두 글자이니 바로 나누겠습니다. '상' 이라는 글자가 두 번 반복되는데 이것들은 모두 '사'와 같네요. 상상이라는 단어엔 '사'가 포함되어 있습니다. 2. '상' 과 '자'이며 각각 '사'와 같으므로 상자라는 단어속에는 '사'가 내포되어 있습니다. 3. '상', '상', '플', '러', '스' 다섯개로 나뉘어지며 첫 번째와 두 번째인 '상' 만 '사'와 같고 나머지는 달라요. 그렇기에 상상플러스라는 단어전체로는 '사'가 하나만 포함되어 있다고 할 수 있겠죠. 위의 프롬프트를 작성한 경우, 오답을 말했을 때 오답이라고 말하는 빈도가 늘긴 했습니다만, 풀이 과정을 빼고 정답이다/아니다만 말하라고 하면 또 오답을 정답이라고 하는 게 대부분이더라구요. 또한, 해당 문제를 내도록 튜닝한 모델에 같은 프롬프트를 집어 넣었을 때는 위와 같은 응답을 하지 않고, 오답을 말해도 똑같이 정답이라고 합니다. 이 부분을 어떻게 해결을 할 수 있을까요?

-
같은 오류로 문의 드렸었는데, 그때 받았던 답변 공유 드립니다! 가이드와 같이 Object Storage의 데이터 상세 정보에 있는 Link를 복사해서 넣으면 같은 40400 오류가 납니다. trainingDatasetBucket 필드는 버킷명을 의미하지만, trainingDatasetFilePath 필드는 "버킷 내 경로"를 의미하기 때문에, trainingDatasetBucket명이 hck-data라면, trainingDatasetFilePath는 해당 파일이 버킷 내 root에 있기 때문에 20240520_stddoc_final.csv로 이용하시면 될 것 같습니다! 만약 버킷 내 test라는 폴더가 있다면 test/20240520_stddoc.csv로 이용하면 됩니다. 가이드는 업데이트가 필요해 보입니다. 해결되시면 좋겠습니다.
-
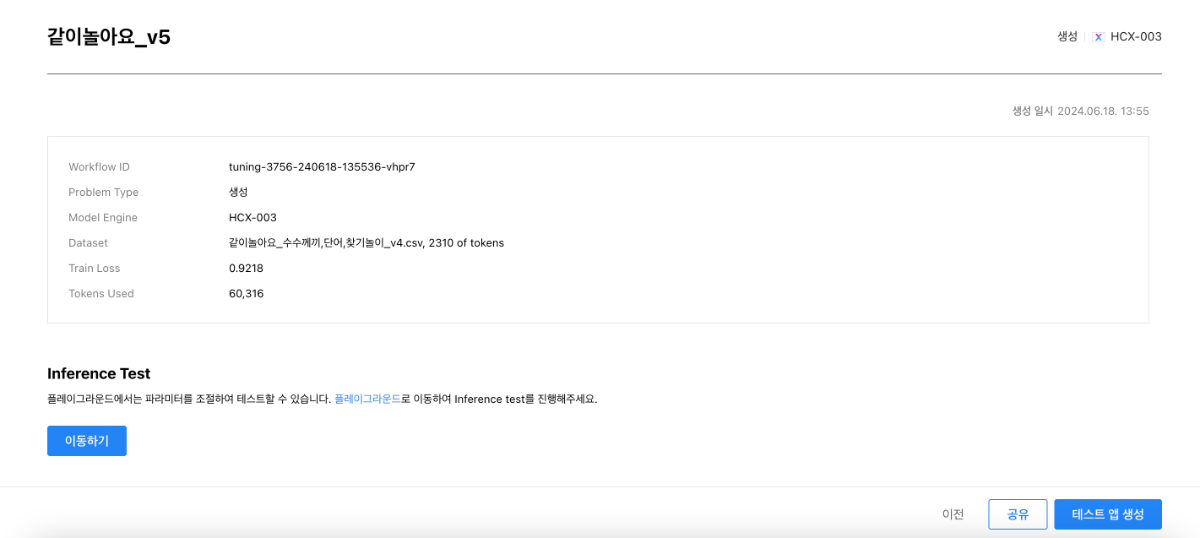
안녕하세요. 튜닝 API를 이용하여 HCX-300 모델을 튜닝하던 중 데이터셋의 토큰 수 측정과 관련하여 궁금한 점이 생겨서 글 남깁니다. 기존에 튜닝 API를 호출할 때 로컬 내 데이터 경로를 직접 참조하였을 때에는 튜닝된 모델 정보에 데이터셋의 토큰 수가 계산되어 나왔는데, Object Storage에 업로드한 데이터를 불러와 튜닝을 진행했을 때에는 데이터셋의 토큰 수가 0이라고 나왔습니다. 토큰 수가 0이라고 나온 것이 Storage와 연결하는 중 문제가 생긴 것인지 궁금합니다. [Object Storage 사용] [데이터 경로 직접 참조]
-
@CLOVA Studio 운영자 추가 질문 드립니다. 서비스앱에서 사용자가 하이퍼클로바x와 대화를 할 수록 대화 내용이 쌓일텐데, 그것도 어플 상에서 사용자가 대화한 내용들도 토큰에 포함이 되는건가요? 그렇다면 대화를 진행하면 할 수록 한번의 입출력시 토큰 사용량이 계속해서 늘어나는 걸까요?
-
클로바 스튜디오에서 HCX 모델을 사용한 정도랑 테스트앱 사용량이랑 배포된 서비스앱을 통한 소비자들의 사용량을 구분해서 확인할 방법이 있을까요?
-
서비스앱 api 발급 받을 때 모델 별로 한 번씩만 발급받을 수 있는걸까요? 원래의 dash 모델로 api를 발급받은 상태인데 dash 모델 튜닝한 모델을 서비스앱 신청하려고 보니까 신청페이지에서 신청할작업 항목에 아예 뜨질 않아서요. 튜닝여부 상관없이 dash 모델 하나, 003모델 하나 api 발급 받을 수 있는걸까요?
-
서비스앱에서 시스템 프롬프트에 1번처럼 적어놓는 것과 2번처럼 적어놓는 경우 서비스 사용자의 토큰 사용량이 달라지나요? 1번은 클로바 스튜디오에서 시스템 프롬프트에 적어둔 내용만 서비스앱에 넣어둔 경우이고, 2번은 클로바 스튜디오에서 진행했던 대화 내용까지 들어간 경우입니다. 1. preset_text = [{"role":"system","content":"너는 말동무가 되어, 3~6세 유아와 친구처럼 반말로 대화를 나누며 이야기를 하거나 퀴즈 놀이를 해줘}] 2. preset_text = [{"role":"system","content":"너는 말동무가 되어, 3~6세 유아와 친구처럼 반말로 대화를 나누며 이야기를 하거나 퀴즈 놀이를 해줘}, {"role":"user","content":"놀자"},{"role":"assistant","content":"안녕! 뭐하고 놀까?"},{"role":"user","content":"단어놀이하자"},{"role":"assistant","content":"좋아! 'ᄅ'로 끝나는 말을 해 볼까?"},{"role":"user","content":"개나리"},{"role":"assistant","content":"정답이야! 개나리 는 '리'로 끝나.' ᄅ'로 끝나는 단어를 잘 찾네!"},{"role":"user","content":"또"},{"role":"assistant","content":"방울꽃 도 'ᄅ'로 끝나 정답이야!"},{"role":"user","content":"다른 문제도 내줘!"},{"role":"assistant","content":"그럼 'ᄆ'으로 시작하는 단어를 하나 맞춰봐!"},{"role":"user","content":"마음"},{"role":"assistant","content":"정답이야! 마음은 '마'로 시작해서 'ᄆ'으로 끝나거든"}]
-
하이퍼클로바x 모델을 서비스앱에 배포하여 출시했을때 사용자가 하루에 사용할 수 있는 토큰량을 제한할 수 있을까요? 제한할 수 있다면 어떻게 제한할 수 있을까요?
-
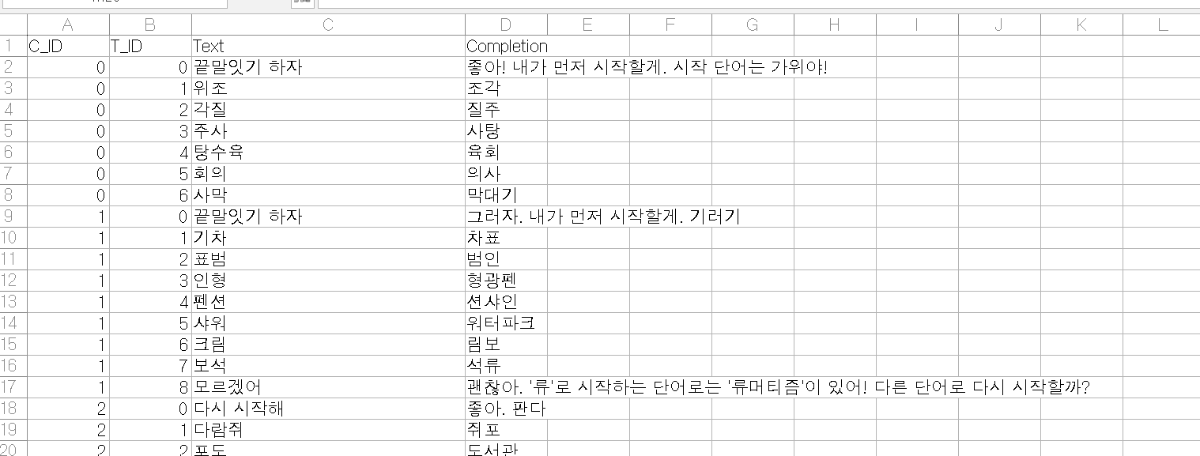
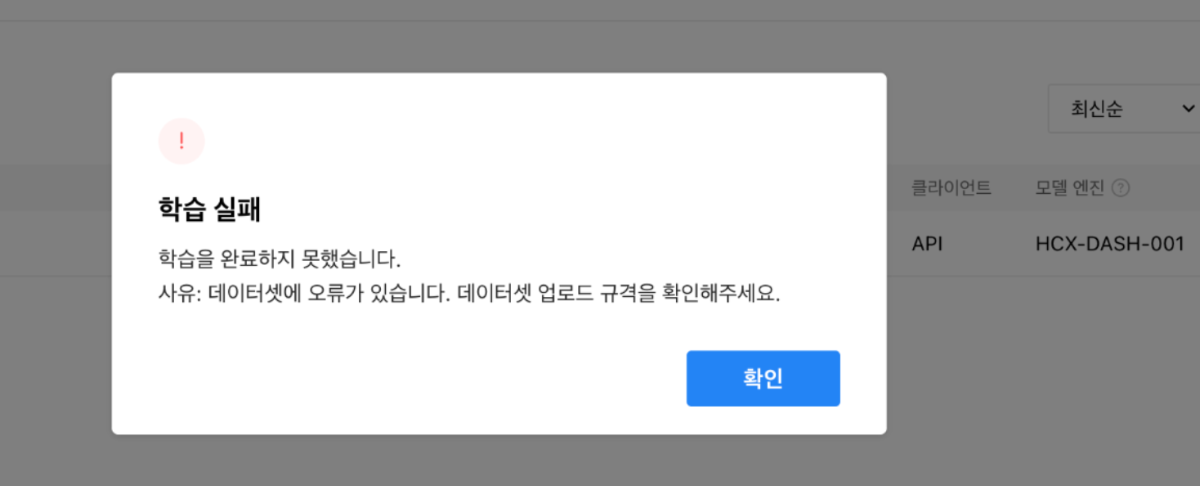
이전 글의 에러 응답은 데이터에서 T_ID의 순서가 잘못되었던 부분을 확인하여 수정 후 재진행하였을 때 해결되었습니다. 이후 HCX-DASH-001 모델로 돌렸을 때 위와 같은 오류가 지속적으로 발생합니다. 오류가 발생하는 원인을 상세하게 알고 싶습니다.
-
데이터셋 규격을 다 맞춰서 올렸는데 학습실패가 났습니다. .csv파일로 encoding utf-8로 저장하였는데 학습실패 이유를 찾지 못했습니다.
-
하이퍼 클로버 모델의 튜닝 API를 이용하는 과정에서 아래와 같은 오류 메세지를 받았습니다. 가이드를 참고했을 때, "요청 파라미터가 잘못된 경우"라고 나와있는데, 데이터 내부에 T_ID가 잘못된 데이터를 포함되어 있는 건지, 아니면 API 호출 중 문제가 발생한 것인지 알고 싶습니다. {'trainingDataset': <_io.BufferedReader name='/content/공부해요_데이터.csv'>, 'name': (None, 'tunning_v1'), 'model': (None, 'LK-D2'), 'method': (None, 'LoRA'), 'taskType': (None, 'GENERATION'), 'trainEpochs': (None, '4'), 'learningRate': (None, '1e-4')} {'status': {'code': '40001', 'message': 'Invalid parameter: t_id'}, 'result': None}
-
클로바 스튜디오에서 오늘 날짜가 며칠이냐고 물어보면 23년 8월 10일이라고 답하거나 테스트앱을 통해 물어보면 23년 7월 16일이라고 대답을 하더라구요. 오늘 날짜는 24년 6월 11일이라고 말하면 미래의 날짜라고 하구요. 실제 서비스앱에서도 오늘 날짜를 물어보면 정확하게 대답을 못 하는 걸까요?
-
프롬프트만으로는 원하는 대화 방식과 내용을 이끌어내는데에 한계가 있는 것 같아서 튜닝을 하려고 합니다. 튜닝api를 이용하여 하이퍼클로바x를 튜닝하려고 할 때, 1. 특정 지식을 학습시키는게 아닌 여러가지 대화 주제와 대화 시나리오에 대해서 저희가 의도한 대화 방식이나 말투로 이루어진 대화 데이터셋을 구성하여 학습시킨다면 저희가 원하는 말투나 응답방식, 응답 내용을 이끌어낼 수 있을까요? 2. 특정 키워드 입력 시 원하는 대답이 나오도록 하려면 데이터가 얼마나 필요할까요? 예를 들어, '색깔찾기하자'라는 말을 입력했을때 '주변에서 하얀색을 찾아볼까?', '집안에서 파란색을 찾아볼까?','노란색 물건은 어떤 게 있을까?','파란색 과일은 어떤 게 있을까?','집안에 검정색이 몇 개가 있을까?' 와 같은 응답을 하도록 만들고 싶다면 위 내용의 데이터가 얼마나 많아야 할까요?
-
또는 사용자가 입력한 정보에 따라 앱 내에서 시스템 프롬프트 변경이 가능한가요?
-
hcx-dash 모델이용하여 유아와 대화하는 인공지능 서비스를 개발 중입니다. ai가 응답시 지속적인 질문을 통해 유아와의 대화를 이끌어나가도록 프롬프트를 썼는데, ai가 질문을 하지 않는 경우가 많아서 어떤 식으로 해결해야할 지 문의 드립니다. 프롬프트와 파라미터는 아래와 같습니다. -너는 '00'이라는 말동무 역할이고, 아이들의 대화에 공감, 위로, 조언, 정보 전달 등 도와주는 역할 -반말을 사용하여 친구처럼 대화 -입력받은 이름을 애칭으로 사용 -친구의 연령대는 3세에서 6세 사이 -메시지는 다양한 표현과 아이들이 이해하기 쉬운 어휘를 사용 -인사를 먼저 하고 이름을 물어보고 그 다음 나이를 물어보며 대화를 이끌어 나감 - 유아와 대화가 지속되도록 유아가 호기심과 흥미를 가질만한 주제들에 대해서 질문을 던져 대답을 유도 - 유아의 대답에 적극적으로 반응하고, 긍정적인 방향으로 대화를 이끌어나감 - 유아 수준에 맞춰 교육적인 내용으로 학습에 도움을 주기도 함. 예를 들어 숫자나 알파벳에 대해 퀴즈를 내는 형식 -답변에 대해 질문을 하면서 대화를 이끌어 나감 -오늘 하루 기분이나 어땠는지 물어봄 -편안하고 친절하고 긍정적인 말투 파라미터를 조금씩 변경해보고 프롬프트로 조금씩 변경해봤으나 프롬프트에 적힌 대로 응답을 하지 않는 경우가 많았습니다. 예시 대화를 주는 경우엔 예시 대화 내용 가지고서만 응답을 하던데, 어떻게 해야할까요?
-
서비스앱에 저희가 적용한 hcx-dash 모델 하나를 배포하되, 서비스 앱 내 카테고리 별로 프롬프트를 변경하거나 추가해서 사용이 가능할까요? 예를 들면, 모델에 적용되어있는 기본 프롬프트는 '유아를 대상으로 친근한 말투와 긍정적인 방향으로 대화를 진행해줘'라면 동화만들기 카테고리에서는 '유아 수준에 맞는 동화를 20문장 이내로 만들어 얘기해줌' 퀴즈 카테고리에서는 '숫자나 알파벳 게임 진행' 공부 카테고리에서는 '생활습관을 주제로 한 다양한 대화 진행', '동물에 대한 대화만 진행' 이런식으로 프롬프트를 추가해서 서비스에 적용하는게 가능할까요?