
CLOVA Studio 운영자6
-
게시글
30 -
첫 방문
-
최근 방문
-
Days Won
4
Content Type
Profiles
Forums
Articles
Posts posted by CLOVA Studio 운영자6
-
-

들어가며
이전에 살펴본 LangGraph로 웹 검색 Agent 만들기 (Web Search Agent Cookbook)에서는 LangGraph를 활용한 단일 에이전트 구축 방법을 다뤘다면, 이번에는 LangChain & LangGraph v1.0을 활용해 멀티 에이전트 시스템을 구축하는 방법을 알아보겠습니다.
기존 LangGraph에서 멀티 에이전트를 구축하려면 모델과 도구를 호출하는 노드를 일일이 정의하고, 워크플로우를 수동으로 연결해야 했습니다. 유연성은 높지만 시스템이 복잡해질수록 그래프 구조를 파악하기 어렵고 유지보수 부담이 커지는 문제가 있었죠.
LangChain과 LangGraph가 v1.0으로 정식 출시되면서 AI 에이전트 개발이 한층 안정적이고 강력해졌습니다. 특히, LangChain v1.0부터 도입된 create_agent는 내부적으로 LangGraph 기반으로 구축되어 있어, LangGraph를 직접 다루지 않아도 Durable Execution, Streaming, Human-In-the-Loop 같은 강력한 기능들을 자동으로 활용할 수 있습니다. 또한, 미들웨어(Middleware) 기능으로 로깅, 프롬프트 수정, 에러 핸들링 같은 공통 로직을 깔끔하게 분리할 수 있게 되었습니다.
이번 쿡북에서는 LangChain v1.0과 HyperCLOVA X 모델을 활용해 Tool Calling 기반의 멀티 에이전트를 구축합니다. 웹 검색(Web Search), 글쓰기(Write), 저장(Save) 에이전트가 협업하여, 최신 정보를 검색하고, 목적에 맞는 글을 작성한 뒤, Notion이나 파일로 자동 저장하는 리포트 AI를 만들어봅니다. 이 가이드를 발판 삼아 여러분만의 창의적인 에이전트 시스템을 자유롭게 구축해 보세요.
사전 준비
멀티 에이전트 구축하기 프로젝트 진행을 위해서는 사전 준비 과정이 필요합니다. 각 과정마다 발급되는 키들을 환경 변수로 등록해 둡니다.
API Key 발급 및 연동 설정
CLOVA Studio API
CLOVA Studio 모델을 사용하기 위해 CLOVA Studio에서 API 키를 발급받아야 합니다. 본 예제에서는 HCX-005와 HCX-007 모델을 사용합니다.
- CLOVA Studio 접속 > 로그인 > 좌측 사이드바 'API 키' > 테스트 API 키 발급
발급된 키는 한 번만 표시되므로 반드시 복사하여 안전하게 보관하세요. API에 대한 자세한 내용은 CLOVA Studio API 가이드를 참고하시기 바랍니다.
네이버 검색 API
네이버 검색 오픈API를 활용하기 위해 네이버 개발자 센터에서 애플리케이션을 등록해야 합니다. 등록을 완료하면 Client ID와 Client Secret 정보를 확인할 수 있습니다. 자세한 내용은 네이버 개발자 센터의 애플리케이션 등록 가이드를 참고해 주세요.
- 네이버 개발자 센터 접속 > 로그인 > Application > 애플리케이션 등록
-
애플리케이션 등록 설정
- 애플리케이션 이름을 설정합니다
- 사용 API에서 '검색'을 선택합니다
- 비로그인 오픈 API 서비스 환경에서 'Web 환경'을 추가합니다.
Tavily API
에이전트가 Tavily 웹 검색 기능을 사용하기 위해, Tavily API 키를 발급받아야 합니다. 무료 플랜의 경우 하루 1,000회까지 검색이 가능합니다.
- Tavily 웹 페이지 접속 > 로그인 > API Keys
Notion API
에이전트가 개인 Notion 데이터베이스에 글을 저장하려면 Notion API Key와 업로드 대상 Data Source의 ID가 필요합니다.
- Notion API Key 발급 : Notion Developers 페이지 접속 > 우측 상단 'View my Integrations' > 로그인 > 새 API 통합
- Data Source ID 확인 : 개인 Notion 접속 > API Key 발급시 설정한 워크스페이스로 이동 > 죄측 상단 '추가 옵션' > '데이터베이스' 선택 > 데이터베이스 설정 > 데이터 소스 관리 > 만들어진 데이터베이스 더보기 > 데이터 소스 ID 복사
프로젝트 구성
프로젝트의 전체 파일 구조는 다음과 같습니다. 프로젝트에 사용한 파이썬 버전은 3.11 입니다.
multi-agent-cookbook/ ├── agent.py ├── utils/ │ ├── tool_agents.py │ ├── prompts.py │ ├── custom_middleware.py │ └── tools.py ├── langgraph.json ├── requirements.txt └── .env
환경 변수 설정
환경 변수를 설정합니다. 루트 디렉터리에 .env 파일을 생성한 뒤, 앞서 발급받은 API Key를 다음과 같이 입력하고 저장합니다. 이때 따옴표 없이 값을 작성해야 하며, VS Code에서 실행할 경우 설정에서 Use Env File 옵션이 활성화되어 있는지 확인하세요.
CLOVA_STUDIO_API_KEY=nv-... OPENAI_API_KEY=sk-proj-... LANGSMITH_API_KEY=lsv2_pt_... LANGSMITH_TRACING=true LANGSMITH_PROJECT=Multi-agent-cookbook NAVER_CLIENT_ID=... NAVER_CLIENT_SECRET=... TAVILY_API_KEY=tvly-dev-... NOTION_API_KEY=ntn_... NOTION_DATA_SOURCE_ID=...
라이브러리 설치
프로젝트에 필요한 패키지 목록은 아래 다운로드 링크에서 확인할 수 있습니다. 해당 내용을 복사해 루트 디렉터리에 requirements.txt 파일로 저장하세요.
루트 디렉터리에서 터미널을 실행하여 다음과 같이 예제 실행에 필요한 패키지를 설치합니다. 가상환경 설치를 권장합니다.
# 1. 파이썬 가상환경 생성 python -m venv .venv # 2. 가상환경 활성화 (macOS/Linux) source .venv/bin/activate # (Windows) # .venv/Scripts/activate.ps1 # 3. 패키지 설치 pip install -r requirements.txt
멀티 에이전트 구축하기
멀티 에이전트 패턴
LangChain v1.0은 두 가지 멀티 에이전트 패턴을 제공합니다.
1. Tool Calling 패턴
중앙 Controller Agent가 모든 작업을 조율하고, 하위 에이전트들을 도구로 호출하는 구조입니다. 사용자와의 소통은 Controller Agent만 담당하며, Tool Agent는 Controller Agent의 도구로서 특정 작업만 수행합니다. Tool Calling 패턴으로 멀티 에이전트를 구현하면, 명확한 계층 구조와 모듈화로 관리가 쉽고 디버깅이 용이하지만, 모든 결정이 Controller를 거쳐야 하므로 토큰 소비량이 크고, 응답 시간이 다소 길어질 수 있습니다.
2. Handoffs 패턴
현재 에이전트가 다른 에이전트에게 제어권을 넘기는 방식으로, 각 에이전트가 순차적으로 사용자와 소통합니다. 이는 쿡북 작성일 기준으로 LangChain에서 아직 제공하지 않는 기능입니다.
이번 쿡북에서는 Tool Calling 패턴을 사용하며, 다음은 이를 기반으로 한 멀티 에이전트 아키텍처입니다.
-
관리자 에이전트(Controller Agent)
-
작업에 적합한 전문가 에이전트를 판단하여 호출하고, 그 결과를 받아 전체 흐름을 조율하는 오케스트레이터(Orchestrator) 역할을 수행합니다.
- LoggingMiddleware: 에이전트의 모든 실행 단계를 로깅하여 디버깅을 돕습니다.
- DynamicModelMiddleware: 대화 길이가 5개 보다 많아지면, 자동으로 더 강력한 모델로 전환합니다.
- HumanInTheLoopMiddleware: 민감한 도구 호출 전, 정지상태가 되는 interrupt를 발생시킵니다.
-
작업에 적합한 전문가 에이전트를 판단하여 호출하고, 그 결과를 받아 전체 흐름을 조율하는 오케스트레이터(Orchestrator) 역할을 수행합니다.
-
전문가 에이전트(Tool Agents)
- 웹 검색 에이전트(Web Search Agent): 네이버/Tavily API를 활용한 웹 검색을 수행합니다. 네이버 웹 검색 실패 시, 자동으로 Tavily 웹 검색으로 전환하여 웹 검색 안정성을 높입니다.
- 글쓰기 에이전트(Write Agent): 검색 결과를 바탕으로 리포트 또는 블로그 형식의 글을 작성합니다.
- 저장 에이전트(Save Agent): 작성된 콘텐츠를 Notion 또는 파일 시스템에 저장합니다.
미들웨어 구현하기
미들웨어는 에이전트의 실행 과정에 개입하여 기능을 확장하는 컴포넌트입니다. 미들웨어는 LangChain v1.0의 핵심 기능으로, 에이전트 로직을 수정하지 않고도 로깅, 프롬프트 변경, 에러 처리 등을 추가할 수 있게 합니다.
미들웨어가 개입할 수 있는 시점
미들웨어는 에이전트 실행의 다양한 시점에서 작동할 수 있습니다.
Node-style hooks
특정 실행 지점에서 순차적으로 실행됩니다. 로깅, 유효성 검사, 상태 업데이트에 사용합니다.
- before_agent / after_agent: 에이전트 시작 전후
- before_model / after_model: 모델 호출 전후
Wrap-style hooks
핸들러 호출을 가로채고 실행을 제어합니다. 재시도, 캐싱, 변환에 사용합니다. 핸들러를 0번(조기 종료), 1번(정상 흐름), 또는 여러 번(재시도 로직) 호출할지 결정할 수 있습니다.
- wrap_tool_call: 도구 실행 시
- wrap_model_call: 모델 실행 시
Convenience
- dynamic_prompts: 동적 시스템 프롬프트 생성
미들웨어 구축 방식
LangChain에서는 목적과 복잡도에 따라 여러 방식으로 미들웨어를 구성할 수 있습니다.
- Decorator-based middleware: 단일 훅(Hook)만 필요한 간단한 로직을 적용하거나, 별도의 설정 없이 빠르게 프로토타이핑을 진행할 때 사용하면 좋습니다.
- Class-based middleware: 동기/비동기 처리를 모두 지원해야 하거나, 여러 개의 훅과 복잡한 설정을 하나의 모듈로 묶어 체계적으로 관리해야 할 때 적합합니다.
- Built-In Middleware: LangChain에서 제공하는 기본 미들웨어를 바로 사용할 수 있습니다.
이 프로젝트에서 사용할 미들웨어
이 프로젝트에서는 에이전트 실행 흐름을 제어하고 안정성을 높이기 위해 다음과 같은 미들웨어를 사용합니다. 커스텀 미들웨어를 구성할 때는 각 미들웨어가 실행 흐름에 개입하는 시점을 고려해야 하며, 이때 LoggingMiddleware는 미들웨어의 개입 지점을 이해하는 데 도움이 될 수 있습니다.
- HumanInTheLoopMiddleware : 민감한 도구 호출 전, 정지상태가 되는 interrupt를 발생시킵니다.
- LoggingMiddleware : 에이전트의 모든 실행 단계를 로깅하여 디버깅을 돕습니다.
- DynamicModelMiddleware : 대화 길이가 5개 보다 많아지면, 자동으로 더 강력한 모델로 전환합니다.
- NaverToTavilyFallbackMiddleware : 네이버 웹 검색 실패 시, 자동으로 Tavily 웹 검색으로 전환하여 웹 검색 안정성을 높입니다.
- writing_farmat : 사용자가 요청한 글 타입(report/blog)에 따라 동적으로 시스템 프롬프트를 변경합니다.
# custom_middleware.py import os from typing import Any, Callable from langchain_naver import ChatClovaX from langchain.agents.middleware import AgentMiddleware, AgentState, ModelRequest, dynamic_prompt from langchain.agents.middleware.types import ModelResponse, ToolCallRequest from langchain.messages import ToolMessage from langgraph.types import Command from langgraph.runtime import Runtime from .tools import tavily_web_search from .prompts import WRITING_PROMPTS from dotenv import load_dotenv load_dotenv() class ReportAgentState(AgentState): content_type : str destination : str class LoggingMiddleware(AgentMiddleware): """에이전트 실행 과정 로깅""" async def abefore_agent(self, state: ReportAgentState, runtime: Runtime) -> dict[str, Any] | None: print("\n" + "="*60) print(f"🔄 LoggingMiddleware.abefore_agent") print(f"🚀 에이전트 시작") print(f" 메시지 수: {len(state['messages'])}개") print("="*60) return None async def abefore_model(self, state: ReportAgentState, runtime: Runtime) -> dict[str, Any] | None: print("\n" + "-"*60) print(f"🔄 LoggingMiddleware.abefore_model") if state['messages']: last = state['messages'][-1] print(f"🤖 모델 호출") print(f" 입력: {type(last).__name__}") if hasattr(last, 'content') and last.content: preview = last.content[:60] + "..." if len(last.content) > 60 else last.content print(f" 내용: {preview}") print("-"*60) print(f"\nController 응답 중..") return None async def aafter_model(self, state: ReportAgentState, runtime: Runtime) -> dict[str, Any] | None: print("\n" + "-"*60) print(f"🔄 LoggingMiddleware.aafter_model") if state['messages']: last = state['messages'][-1] if hasattr(last, 'tool_calls') and last.tool_calls: tools = [tc['name'] for tc in last.tool_calls] print(f"🔧 도구 호출 예정") for tool in tools: print(f" → {tool}") elif hasattr(last, 'content') and last.content: print(f"✅ 모델 응답 완료") print("-"*60) return None async def aafter_agent(self, state: ReportAgentState, runtime: Runtime) -> dict[str, Any] | None: print("\n" + "="*60) print(f"🔄 LoggingMiddleware.aafter_agent") print(f"🏁 에이전트 완료") print(f" 총 메시지: {len(state['messages'])}개") print("="*60 + "\n") return None async def awrap_tool_call( self, request: ToolCallRequest, handler: Callable[[ToolCallRequest], ToolMessage | Command], ) -> ToolMessage | Command: tool_name = request.tool_call.get('name', 'unknown') print("\n" + "-"*60) print(f"🔄 LoggingMiddleware.awrap_tool_call") print(f"⚙️ 도구 실행: {tool_name}") print("-"*60) print("\nTool Calling\n", end="", flush=True) result = await handler(request) print("\n" + "-"*60) print(f"🔄 LoggingMiddleware.awrap_tool_call (완료)") print(f"✅ 도구 완료: {tool_name}") if isinstance(result, ToolMessage) and result.content: preview = result.content[:100] + "..." if len(result.content) > 100 else result.content print(f" 결과: {preview}") print("-"*60) return result class DynamicModelMiddleware(AgentMiddleware): """대화 길이에 따라 모델 변경""" def awrap_model_call( self, request: ModelRequest, handler: Callable[[ModelRequest], ModelResponse], ) -> ModelResponse: CLOVA_STUDIO_API_KEY = os.getenv("CLOVA_STUDIO_API_KEY") # 대화 길이에 따라 다른 모델 사용 model_name = "HCX-007" new_model = ChatClovaX(model=model_name, reasoning_effort="none", api_key=CLOVA_STUDIO_API_KEY) if len(request.messages) > 5: request.model = new_model print("\n" + "-"*60) print(f"🔄 DynamicModelMiddleware: Controller Using {model_name} for long conversation") print("-"*60) return handler(request) class NaverToTavilyFallbackMiddleware(AgentMiddleware): """네이버 검색 실패 시 Tavily로 폴백""" async def awrap_tool_call( self, request: ToolCallRequest, handler: Callable[[ToolCallRequest], ToolMessage | Command], ) -> ToolMessage | Command: tool_name = request.tool_call.get('name', 'unknown') if tool_name != 'naver_web_search': return await handler(request) try: result = await handler(request) # 네이버 검색 실행 print("\n" + "-"*60) print("🔄 NaverToTavilyFallbackMiddleware: ✅ 네이버 검색 성공") print("-"*60) return result except Exception as e: print("\n" + "-"*60) print(f"🔄 NaverToTavilyFallbackMiddleware: ⚠️ 네이버 검색 실패 → Tavily 검색 전환: {str(e)[:50]}...") print("-"*60) args = request.tool_call.get('args', {}) query = args.get('query', '') display = args.get('display', 5) # ainvoke 사용 (딕셔너리로 전달) tavily_result = await tavily_web_search.ainvoke({ "query": query, "display": display }) return ToolMessage( content=f"[Tavily 검색 결과]\n{tavily_result}", tool_call_id=request.tool_call.get('id', '') ) @dynamic_prompt def writing_format(request: ModelRequest) -> str: """사용자 요청에 알맞는 시스템 프롬프트 생성""" content_type = request.runtime.context.get("content_type", "report") base_prompt = "당신은 글쓰기 어시스턴트 입니다. 다음 형식으로 글을 작성하세요." print("\n" + "-"*60) print(f"🔄 writing_format: {content_type} 형식으로 작성") print("-"*60) if content_type == "blog": return f"{base_prompt}\n\n{WRITING_PROMPTS['blog']}" elif content_type == "report": return f"{base_prompt}\n\n{WRITING_PROMPTS['report']}" return base_prompt
관리자 에이전트(Controller Agent) 구성하기
관리자 에이전트는 사용자의 요청을 받아 적절한 전문가 에이전트를 호출하여 작업을 조율하는 중앙 관제 역할을 수행합니다. 이를 위해 HCX-007 모델을 사용하며, 구체적인 역할은 다음과 같습니다.
- 사용자 요청을 분석하고 필요한 전문가 에이전트를 선택합니다.
- 여러 전문가 에이전트를 순차적으로 호출하여 복합 작업을 수행합니다.
- Human-In-the-Loop을 통해 중요한 작업 전 사용자 승인을 받습니다.
- 최종 결과를 사용자에게 전달합니다.
# agent.py import os import asyncio from langchain.agents import create_agent from langchain.messages import SystemMessage, HumanMessage from langchain.agents.middleware import HumanInTheLoopMiddleware from langchain_naver import ChatClovaX from langgraph.checkpoint.memory import InMemorySaver from langgraph.types import Command from utils.tool_agents import call_write_agent, call_web_search_agent, call_save_agent from utils.custom_middleware import ReportAgentState, DynamicModelMiddleware, LoggingMiddleware from utils.prompts import CONTROLLER_PROMPT from dotenv import load_dotenv load_dotenv() # LangGraph Studio용 graph 생성 함수 def build_graph(): """LangGraph 서버에서 호출하는 graph 빌더""" CLOVA_STUDIO_API_KEY = os.getenv("CLOVA_STUDIO_API_KEY") model = ChatClovaX(model="HCX-005", api_key=CLOVA_STUDIO_API_KEY) agent = create_agent( model=model, tools=[call_write_agent, call_web_search_agent, call_save_agent], checkpointer=InMemorySaver(), middleware=[ # LoggingMiddleware(), DynamicModelMiddleware(), HumanInTheLoopMiddleware( interrupt_on={ "call_web_search_agent": {"allowed_decisions": ["approve", "reject"]}, "call_write_agent": False, "call_save_agent": False } ) ], state_schema=ReportAgentState, system_prompt=CONTROLLER_PROMPT ) return agent async def main(): agent = build_graph() config = {"configurable": {"thread_id": "asd123"}} print("Multi Agent System Created!\n") while True: user_input = input("\nUser: ") if user_input.lower() in ["종료", "exit"]: print("AI: 대화를 종료합니다. 이용해주셔서 감사합니다.") break try: # 첫 실행 result = await agent.ainvoke( {"messages": [HumanMessage(user_input)]}, config=config ) # interrupt 확인 및 처리 while "__interrupt__" in result: print("\n" + "="*60) print("⏸️ 승인이 필요한 작업이 있습니다") print("="*60) interrupt_data = result["__interrupt__"][0].value action_requests = interrupt_data.get("action_requests", []) print(f"\n📋 총 {len(action_requests)}개의 작업 대기 중\n") decisions = [] for i, action in enumerate(action_requests, 1): tool_name = action.get("name", "unknown") tool_args = action.get("args", {}) print(f"작업 {i}:") print(f" 🔧 도구: {tool_name}") print(f" 📝 인자: {tool_args}") decision = input(f"\n\n승인하시겠습니까? (approve/reject): ").strip().lower() if decision == "approve": decisions.append({"type": "approve"}) print("✅ 승인됨\n") else: # approve가 아니면 모두 reject decisions.append({"type": "reject"}) print("❌ 거부됨\n") # 결정 전달 및 재실행 print("="*60) print("🔄 작업 재개 중...") print("="*60 + "\n") result = await agent.ainvoke( Command(resume={"decisions": decisions}), config ) # 최종 결과 출력 print("\nAI: ", end="", flush=True) final_message = result["messages"][-1] if hasattr(final_message, 'content'): print(final_message.content) else: print(final_message) print() except Exception as e: print(f"\n❌ 오류 발생: {e}") import traceback traceback.print_exc() if __name__ == "__main__": asyncio.run(main())
Quote주의 사항
- thread_id는 대화 세션을 구분하는 고유 ID입니다. 실제 환경에서는 사용자별로 다른 ID를 사용하세요
- interrupt 처리 중 사용자가 'reject'하면 해당 도구는 실행되지 않고 다음 단계로 넘어갑니다
- interrupt 처리 방식 중 'edit'도 있지만, 작성하는 시점에 interrupt가 두 번 발생하는 버그가 있어 사용을 지양합니다(참고).
- HCX-007 모델의 경우 tool calling과 추론을 병행 할 수 없습니다. 따라서, tool calling이 필요한 경우 추론 파라미터 resoning_effort='none'을 설정합니다(기본값 'low').
전문가 에이전트(Tool Agents)구성하기
각 전문가 에이전트는 @tool 데코레이터로 래핑되어 관리자 에이전트가 호출할 수 있는 함수 형태가 됩니다. 작업 완료 후 Command 객체 반환을 통해 State를 업데이트하여 결과를 관리자 에이전트에게 전달합니다. 이번 프로젝트에서는 HCX-005 모델로 전문가 에이전트를 구성했습니다.
전문가 에이전트의 역할은 다음과 같습니다.
- @tool 데코레이터로 일반 함수를 LangChain 도구로 변환합니다.
- 각 Agent는 독립적인 create_agent로 생성되어 고유한 미들웨어와 도구를 가집니다.
- Command 객체를 통해 메시지와 상태를 업데이트하여 관리자 에이전트에 전달합니다.
# tool_agents.py import os from typing import Annotated, Literal from langgraph.types import Command from langchain.tools import tool from langchain.agents import create_agent from langchain.agents.middleware import HumanInTheLoopMiddleware from langchain.messages import HumanMessage, ToolMessage from langchain.tools import InjectedToolCallId from langchain_naver import ChatClovaX from .tools import naver_web_search, save_to_file, save_to_notion from .custom_middleware import writing_format, NaverToTavilyFallbackMiddleware from .prompts import WEB_SEARCH_PROMPT, SAVE_PROMPT from dotenv import load_dotenv load_dotenv() CLOVA_STUDIO_API_KEY = os.getenv("CLOVA_STUDIO_API_KEY") write_model = ChatClovaX(model="HCX-005", api_key=CLOVA_STUDIO_API_KEY) web_search_model = ChatClovaX(model="HCX-005", api_key=CLOVA_STUDIO_API_KEY) save_model = ChatClovaX(model="HCX-DASH-002", api_key=CLOVA_STUDIO_API_KEY) write_agent = create_agent( model=write_model, middleware=[writing_format] ) web_search_agent = create_agent( model=web_search_model, tools=[naver_web_search], middleware=[NaverToTavilyFallbackMiddleware()], system_prompt=WEB_SEARCH_PROMPT ) save_agent = create_agent( model=save_model, tools=[save_to_notion, save_to_file], middleware=[HumanInTheLoopMiddleware( interrupt_on={ "save_to_notion":{"allowed_decisions": ["approve", "reject"]}, "save_to_file":{"allowed_decisions": ["approve", "reject"]} } )], system_prompt=SAVE_PROMPT ) @tool async def call_write_agent( article: str, content_type: Literal["report", "blog"], tool_call_id: Annotated[str, InjectedToolCallId], ) -> Command: """ 글쓰기 서브에이전트를 호출하여 지정된 형식의 글을 작성합니다. Args: article: 작성할 주제나 원본 내용 content_type: 글 형식 타입 ('report'|'blog') tool_call_id: LLM 도구 호출 ID (자동 주입) Returns: Command: 작성된 글과 업데이트된 상태를 포함하는 Command 객체 - messages: 작성된 글이 담긴 ToolMessage """ result = await write_agent.ainvoke( {"messages": [HumanMessage(article)]}, # context에 넣어서 middleware에 전달 context={ "content_type": content_type }, ) return Command(update={ "messages": [ ToolMessage( content=result["messages"][-1].content, tool_call_id=tool_call_id ) ], "content_type": content_type }) @tool async def call_web_search_agent( query: str, tool_call_id: Annotated[str, InjectedToolCallId], ) -> Command: """ 사용자가 검색을 요청하면 웹 검색 서브에이전트를 호출하여 웹 검색을 수행합니다 Args: query: 검색에 사용할 쿼리 runtime: 메인 에이전트의 상태 접근을 위한 런타임 객체 tool_call_id: LLM 도구 호출 ID (자동 주입) Returns: Command: 작성된 글과 업데이트된 상태를 포함하는 Command 객체 - messages: 작성된 글이 담긴 ToolMessage """ result = await web_search_agent.ainvoke( {"messages": [HumanMessage(query)]}, context={"current_agent": "web_search_agent"} ) return Command(update={ "messages": [ ToolMessage( content=result["messages"][-1].content, tool_call_id=tool_call_id ) ] }) @tool async def call_save_agent( content: str, destination: Literal["file", "notion"], filename_or_title: str, tool_call_id: Annotated[str, InjectedToolCallId], ) -> Command: """ 콘텐츠를 파일 또는 Notion에 저장합니다. Args: content: 저장할 콘텐츠 destination: 저장 위치 ('file' 또는 'notion') filename_or_title: 파일명(file) 또는 노션 페이지 제목(notion) tool_call_id: LLM 도구 호출 ID (자동 주입) Returns: Command: 저장 결과를 포함하는 Command 객체 """ # destination에 따라 다른 메시지 전달 if destination == "notion": context_msg = f"다음 내용을 Notion에 '{filename_or_title}' 제목으로 저장해주세요:\n\n{content}" else: # file context_msg = f"다음 내용을 '{filename_or_title}' 파일로 저장해주세요:\n\n{content}" result = await save_agent.ainvoke( {"messages": [HumanMessage(context_msg)]}) return Command(update={ "messages": [ ToolMessage( content=result["messages"][-1].content, tool_call_id=tool_call_id ) ] })
Quote주의 사항
- @tool 데코레이터는 함수의 docstring을 자동으로 도구 설명으로 사용합니다. 도구 호출을 위해서 명확하게 작성하세요.
- Literal 타입을 사용하여 입력값을 제한하면 모델이 잘못된 값을 전달하는 것을 방지할 수 있습니다.
- Command 객체에에 전달해야 커스텀 State의 업데이트가 가능합니다.
- tool_call_id를 포함하여 도구 호출을 추적할 수 있습니다 .
도구 구현하기
전문가 에이전트인 웹 검색 에이전트와 저장 에이전트가 사용하는 도구를 구현합니다. 이 도구들은 멀티 에이전트와 미들웨어의 활용 방법을 보여주기 위한 예시로 구성되었습니다.
웹 검색 에이전트의 경우 naver_web_search 도구를 가지고 있고, NaverToTavilyFallbackMiddleware에 의해 tavily_web_search 도구 또한 활용할 수 있습니다. 저장 에이전트는 개인 노션에 업로드 할 수 있는 save_to_notion, 시스템에 저장할 수 있는 save_to_file 두 가지 도구를 가지고 있습니다.
# tools.py import os import re import httpx from pathlib import Path from langchain.tools import tool from tavily import TavilyClient from notion_client import Client from dotenv import load_dotenv # 환경 변수 로드 load_dotenv() NAVER_CLIENT_ID = os.getenv("NAVER_CLIENT_ID") NAVER_CLIENT_SECRET = os.getenv("NAVER_CLIENT_SECRET") TAVILY_API_KEY = os.getenv("TAVILY_API_KEY") @tool async def naver_web_search(query: str, display: int = 10) -> dict: """ 네이버 검색 API를 호출해 결과를 구조화하여 반환합니다. Args: query: 검색어 display: 검색 결과 수(1~100) Returns: { "query": str, "total": int, "items": [{"title": str, "link": str, "description": str}]} } """ url = "https://openapi.naver.com/v1/search/webkr.json" params = {"query": query, "display": display} headers = { "X-Naver-Client-Id": NAVER_CLIENT_ID, "X-Naver-Client-Secret": NAVER_CLIENT_SECRET, } async with httpx.AsyncClient() as client: r = await client.get(url, headers=headers, params=params) r.raise_for_status() data = r.json() results = [] for item in data.get("items", []): results.append({ "title": re.sub(r"<.*?>", "", item.get("title") or "").strip(), "link": item.get("link"), "description": re.sub(r"<.*?>", "", item.get("description") or "").strip(), }) return { "query": query, "total": data.get("total", 0), "items": results, } # 본 쿡북에서는 해당 도구를 NaverToTavilyFallbackMiddleware에서 풀백 도구로 활용하였습니다 @tool async def tavily_web_search(query: str, display: int = 5) -> str: """ Tavily API를 사용하여 웹 검색을 수행합니다. Args: query: 검색어 display: 검색 결과 수(1~100) """ try: tavily_client = TavilyClient(api_key=TAVILY_API_KEY) # Tavily는 동기 라이브러리이므로, 비동기 처리를 위해 asyncio.to_thread 사용 import asyncio response = await asyncio.to_thread( tavily_client.search, query=query, max_results=display ) # 결과 포맷팅 results = [] for idx, result in enumerate(response.get('results', []), 1): result_text = f"\n{idx}. {result.get('title', 'No title')}\n" result_text += f" URL: {result.get('url', 'No URL')}\n" result_text += f" 내용: {result.get('content', 'No content')}\n" results.append(result_text) if not results: return "검색 결과가 없습니다." return "".join(results) except Exception as e: return f"검색 중 오류 발생: {str(e)}" @tool def save_to_file(filename: str, content: str) -> str: """ 지정된 파일 이름으로 리포트 내용을 시스템에 마크다운 파일로 저장합니다. Args: filename: 저장할 파일 이름 (확장자 없으면 자동으로 .md 추가) content: 파일에 저장할 텍스트 내용 Returns: 저장 성공/실패 메시지와 파일 경로 """ try: # 확장자 없으면 자동으로 .md 추가 if not filename.endswith(('.md', '.markdown', '.txt')): filename = f"{filename}.md" # 저장 디렉토리 생성 (없으면) save_dir = Path("reports") # 또는 원하는 디렉토리 save_dir.mkdir(exist_ok=True) # 전체 경로 file_path = save_dir / filename # 마크다운 형식으로 저장 with open(file_path, "w", encoding="utf-8") as f: f.write(content) # 절대 경로 반환 abs_path = file_path.resolve() return f"✅ 마크다운 파일로 저장 완료!\n📁 경로: {abs_path}" except Exception as e: return f"❌ 파일 저장 중 오류 발생: {e}" @tool def save_to_notion(page_title: str, content: str) -> str: """ Notion 데이터베이스에 새 페이지를 생성하고 콘텐츠를 저장합니다. 사용자가 작성한 글, 보고서, 메모 등을 Notion에 저장할 때 사용합니다. 페이지 제목과 본문 내용을 받아서 지정된 Notion 데이터베이스에 자동으로 추가합니다. Args: page_title: Notion 페이지의 제목 (예: "주간 보고서", "회의 내용") content: 페이지 본문에 저장할 텍스트 내용 (마크다운 형식 지원) Returns: 성공 시: 생성된 페이지 제목과 URL 실패 시: 오류 메시지 Examples: - "이 리포트를 Notion에 '월간 분석'이라는 제목으로 저장해줘" - "방금 작성한 글을 Notion에 저장" """ try: notion = Client( auth=os.getenv("NOTION_API_KEY"), notion_version="2025-09-03" # 최신 버전 ) data_source_id = os.getenv("NOTION_DATA_SOURCE_ID") # data_source_id 사용 new_page = notion.pages.create( parent={ "type": "data_source_id", "data_source_id": data_source_id }, properties={ "title": { # 기본 title "title": [ {"text": {"content": page_title}} ] } }, children=[ { "object": "block", "type": "paragraph", "paragraph": { "rich_text": [ {"text": {"content": content}} ] } } ] ) return f"✅ '{page_title}' 생성 완료: {new_page['url']}" except Exception as e: return f"❌ 오류: {str(e)}"
Quote주의 사항
- 이 도구들은 테스트 목적으로 제작되었습니다.
- 실제 NaverToTavilyFallbackMiddleware에 의한 풀백 메커니즘을 테스트 해보시려면 naver_web_search 도구 내부 로직을 실패하도록 수정해야 합니다.
프롬프트
프로젝트에서 사용하는 모든 프롬프트를 정의합니다. 각 에이전트의 역할과 동작 방식을 명확히 지정하여 일관된 응답을 보장합니다. 사용된 프롬프트는 아래 다운로드 링크에서 확인할 수 있습니다. 해당 내용을 복사해 prompt.py 파일로 저장하세요.
실행 및 동작 예시
다음은 HumanInTheLoopMiddleware가 적용된 멀티 에이전트 시스템의 동작 흐름입니다. 각 에이전트의 도구 호출 과정에서 사용자 승인 단계가 개입되며, 전체 응답 흐름은 다음과 같습니다.
에이전트 실행 결과는 다음과 같습니다.
User: 이번 네이버 DAN25에서 발표된 네이버의 AI 전략에 대해 찾아보고 리포트로 작성해서 노션에 업로드 해줘 ============================================================ ⏸️ 승인이 필요한 작업이 있습니다 ============================================================ 📋 총 1개의 작업 대기 중 작업 1: 🔧 도구: call_web_search_agent 📝 인자: {'query': '네이버 DAN25에서 발표된 네이버의 AI 전략'} 승인하시겠습니까? (approve/reject): approve ✅ 승인됨 ============================================================ 🔄 작업 재개 중... ============================================================ ------------------------------------------------------------ 🔄 NaverToTavilyFallbackMiddleware: ✅ 네이버 검색 성공 ------------------------------------------------------------ ------------------------------------------------------------ 🔄 writing_format: report 형식으로 작성 ------------------------------------------------------------ ============================================================ ⏸️ 승인이 필요한 작업이 있습니다 ============================================================ 📋 총 1개의 작업 대기 중 작업 1: 🔧 도구: save_to_notion 📝 인자: {'page_title': '네이버 AI 전략 DAN25 발표 분석', 'content': '# 네이버의 AI 전략: DAN25 발표 내용 분석\n\n## 1. 개요\n본 리포트는 네이버의 DAN25 발표 내용을 바탕으로 한 AI 전략에 대해 분석합니다. 네이버는 AI 에이전트 도입 확대, 핵심 제조 산업 경쟁력 강화, 새로운 AI 도구 및 플랫폼 전략 공개, AI 산업 거품론 대응, 그리고 미래 비전과 글로벌 확장 계획을 통해 AI 기술의 발전과 실질적 가치 창출을 목표로 하고 있습니다.\n\n## 2. 핵심 발견사항\n- **AI 에이전트 도입 확대**: 네이버는 주요 서비스에 AI 에이전트를 도입해 개인화된 사용자 경험 제공.\n- **핵심 제조 산업 경쟁력 강화**: 반도체, 자동차, 조선 등 제조 산업에서의 AI 활용 방안 모색.\n- **신규 AI 도구와 플랫폼 전략**: 산업별 버티컬 AI와 경량화 모델을 통한 실질적인 가치 창출 목표.\n- **산업 거품론 대응**: 경량화 모델과 산업 특화 AI를 통해 실질적인 가치 창출 중요성 강조.\n- **글로벌 확장 계획**: 차세대 AI 전략 발표 및 글로벌 시장 진출 도모.\n\n## 3. 분석 및 인사이트\n네이버는 AI 기술의 전방위적 도입을 통해 사용자 맞춤형 서비스 제공을 강화하고 있으며, 제조업 분야에서도 AI 트랜스포메이션을 추진 중입니다. 또한, DAN25에서는 산업별 맞춤형 AI 솔루션과 경량화된 모델을 통해 실질적인 성과를 도출하고자 했습니다. AI 산업 내 거품론을 경계하며 실체 있는 기술 개발에 주력하고 있고, 글로벌 확장을 위한 미래 비전을 제시하고 있습니다.\n\n## 4. 결론 및 제언\n네이버의 AI 전략은 다각도로 전개되고 있으며, 이는 궁극적으로 사용자 경험 개선과 산업 전반의 혁신을 촉진할 것입니다. 향후 네이버는 AI 기술의 고도화와 더불어 글로벌 시장에서의 입지 강화를 위해 지속적인 투자와 연구 개발이 필요합니다.\n\n## 5. 참고 자료\n[AI 에이전트 도입 확대](https://www.etnews.com/20251023000297), [핵심 제조 산업 경쟁력 강화](http://www.efnews.co.kr/news/articleView.html?idxno=124617), [신규 AI 도구와 플랫폼 전략](https://www.asiatoday.co.kr/kn/view.php?key=20250930010016279), [AI 산업 거품론 대응](https://www.econovill.com/news/articleView.html?idxno=717550), [미래 비전과 글로벌 확장 계획](https://www.kmjournal.net/news/articleView.html?idxno=4023)'} 승인하시겠습니까? (approve/reject): approve ✅ 승인됨 ============================================================ 🔄 작업 재개 중... ============================================================ ------------------------------------------------------------ 🔄 DynamicModelMiddleware: Controller Using HCX-007 for long conversation ------------------------------------------------------------ AI: 리포트가 성공적으로 노션에 저장되었습니다! ### 세부 사항 - **제목:** 네이버 AI 전략 DAN25 발표 분석 - **노션 링크:** [네이버 AI 전략 DAN25 발표 분석](https://www.notion.so/AI-DAN25-2bf87d6d35378107a508c5b0bc8f478a) 추가로 필요하신 것이 있으면 말씀해 주세요!
LangSmith Studio
LangSmith Studio는 AI 에이전트 개발을 위한 전용 IDE(통합 개발 환경)입니다. 그래프 기반 시각화 인터페이스로 에이전트가 실행되는 동안 각 노드의 전환과 상태 변화를 실시간으로 추적할 수 있어, 복잡한 로직의 흐름을 한눈에 파악할 수 있습니다. 또한 프롬프트를 수정하면 즉시 반영되는 hot-reloading 기능으로 빠른 반복 개발이 가능하고, 멀티턴 대화를 테스트할 수 있는 Chat UI가 내장되어 있습니다.
LangSmith API
에이전트의 동작 과정을 모니터링하고, LangSmith Studio를 사용하기 위해 LangSmith의 API 키를 발급받아야 합니다.
- LangSmith 접속 > 로그인 > 좌측 사이드바 'Settings' > API Keys 탭 > + API key
langgraph.json
LangGraph 애플리케이션의 구성 정보를 담고 있는 설정 파일입니다. 그래프의 위치, 의존성, 환경 변수 등 에이전트의 구조를 정의합니다. 자세한 설정은 공식 문서를 참고하세요.
{ "dependencies": ["."], "graphs": { "controller": "./agent.py:build_graph" }, "env": ".env" }LangSmith Studio 활성화
다음 명령어를 통해 LangSmith Studio를 활성화합니다. 다음 명령어를 실행하면 다음 과정이 순차적으로 수행됩니다.
langgraph dev
- langgraph-cli가 langgraph.json 파일을 읽습니다.
- 로컬 API 서버가 시작됩니다.
- LangSmith Studio의 웹 UI가 이 서버에 자동으로 연결됩니다. 다음 URL을 통해 LangSmith Studio에 접근할 수 있습니다.
LangSmith Studio에서는 내장된 Chat UI로 직접 구축한 에이전트와 대화하며 실시간으로 테스트할 수 있고, 토큰 소모량, 실행 시간, 각 컴포넌트의 입출력 등을 모니터링하여 디버깅과 최적화를 진행할 수 있습니다. 또한, 프롬프트를 수정하면 즉시 반영되어 다양한 프롬프트 변형을 빠르게 실험할 수 있으며, 그래프 시각화를 통해 에이전트의 실행 흐름을 직관적으로 파악할 수 있습니다.
QuoteLangSmith Studio에서의 Human-In-the-Loop
LangSmith Studio에서도 HumanInTheLoopMiddleware에 의한 interrupt가 발생합니다. agent.py에서는 내부 로직에서 직접 interrupt에 대한 처리를 진행했지만, LangSmith Studio에서는 interrupt가 발생하면 Command 객체의 resume 파라미터에 들어갈 적절한 형태의 값을 전달해야 합니다.
승인 시 입력값
{ "decisions": [ { "type": "approve" } ] }거부 시 입력값
{ "decisions": [ { "type": "reject" } ] }마무리
이번 쿡북을 통해 LangChain v1.0이 제시하는 새로운 멀티 에이전트 구축 방법을 익혔습니다.
특히, create_agent와 미들웨어를 적극 활용함으로써 로깅, 에러 처리, Human-In-the-Loop 같은 핵심 기능을 모듈화할 수 있었고, 복잡한 그래프 구축 과정 없이도 유지보수가 용이한 에이전트 설계가 가능해졌습니다. 또한, HyperCLOVA X를 기반으로 관리자 에이전트가 하위 전문가 에이전트들을 정교하게 조율하는 협업 구조를 구현할 수 있었습니다.
이제 이 가이드를 발판 삼아, LangChain v1.0의 유연한 구조 위에 CLOVA Studio의 강력한 모델들을 더해 여러분만의 창의적인 에이전트 서비스를 완성해보시기 바랍니다.
-
LLM 기반 에이전트를 만들고 나면, 그다음 고민은 얼마나 잘 작동하느냐입니다.
초기 프롬프트가 단순한 데모 상황에서는 만족스러운 답변을 내놓더라도, 실제 서비스 환경에서는 응답 품질이 떨어지거나, 의도와 다른 행동을 보이거나, 특정 입력에 취약한 패턴이 드러날 수 있습니다. 이럴 때는 데이터를 보강하고, 프롬프트를 다듬고, 정책을 조정해 에이전트를 점진적으로 더 똑똑하고 안정적으로 만드는 과정이 필수적입니다.
이번 쿡북에서는 이러한 개선 과정을 손쉽게 반복 실행할 수 있도록 도와주는 프레임워크, Agent Lightning을 다룹니다.
특히 별도의 모델 튜닝 없이도 프롬프트를 자동으로 수정·검증해 주는 APO(Automatic Prompt Optimization)를 활용해, 최소한의 설정만으로 에이전트 개선 루프를 구성하는 방법을 소개합니다. 또한 기본적으로 영문 프롬프트 최적화에 맞춰 설계된 Agent Lightning의 APO를 한국어 환경에서도 안정적으로 활용할 수 있도록, POML(Prompt Optimization Markup Language) 템플릿을 한국어 기반으로 커스터마이징해 적용하는 방법도 함께 다룹니다.
이번 쿡북을 통해 CLOVA Studio에서 제공하는 모델을 더 안정적으로 다루고, 실제 서비스 품질을 높이는 프롬프트 개선 전략을 익히는 데 도움이 되길 바랍니다.
1. Agent Lightning 개요
마이크로소프트에서 공개한 Agent Lightning은 에이전트의 학습과 최적화를 체계적으로 수행할 수 있도록 설계된 프레임워크입니다. 이 프레임워크는 에이전트의 실행을 자동으로 추적하고, 그 결과로 얻은 보상(Reward)을 기반으로 프롬프트나 정책을 개선할 수 있게 해줍니다.
1-1. 핵심 개념
Agent Lightning에서 다루는 핵심 개념은 다음과 같습니다.
- Task(태스크): 에이전트에게 주어지는 구체적인 입력 또는 임무입니다. 장소를 예약하거나 수학 문제를 풀어주는 것처럼, 에이전트가 해결해야 할 대상을 의미합니다.
- Rollout(롤아웃): 하나의 태스크가 주어지고, 에이전트가 실행되어 도구 호출이나 LLM 호출 등을 거쳐 행동을 완료하고, 마지막에 보상(Reward) 을 받는 한 번의 전체 사이클을 말합니다.
- Span(스팬): 롤아웃 내부의 작은 단위 실행입니다. LLM 호출 하나, 툴 실행 하나 등이 각각의 스팬이 될 수 있습니다.
- Prompt Template(프롬프트 템플릿): 태스크를 해결하기 위해 에이전트가 사용하는 지시문 및 프롬프트의 구조입니다. 이 템플릿은 알고리즘에 의해 반복적으로 개선됩니다.
에이전트가 수행하는 모든 롤아웃은 보상 정보와 함께 기록되고, 이 데이터를 기반으로 프롬프트나 정책을 점진적으로 개선할 수 있습니다.
1-2. 구성 요소
Agent Lightning은 다음 세 가지 주요 구성 요소로 이루어집니다.
- Agent(에이전트): 태스크를 입력받아 에이전트 로직을 수행하고 보상을 리턴합니다. 이를 통해 각 실행이 자동으로 롤아웃으로 기록됩니다.
- Algorithm(알고리즘): 프롬프트나 정책을 개선하기 위한 알고리즘입니다. APO, VERL 등 다양한 알고리즘을 지원하며, 이번 쿡북에서는 프롬프트 최적화를 다루기 위해 APO를 사용합니다.
- Trainer(트레이너): 에이전트와 알고리즘을 연결하고, 학습 루프를 제어하는 구성 요소입니다. 반복적인 실행과 평가를 통해 점진적인 개선을 수행합니다.
즉, 이미 만들어둔 에이전트 코드에 간단한 데코레이터(@rollout)를 추가하기만 하면, 각 실행의 입력, 출력, 보상 데이터를 자동으로 기록하고, 이를 기반으로 프롬프트나 정책을 개선하는 학습 가능한 에이전트 루프를 구성할 수 있습니다.
이러한 Agent Lightning을 활용하면 복잡한 학습 코드를 직접 작성하지 않아도, 에이전트의 실행 기록과 보상 정보를 바탕으로 다양한 프롬프트 버전을 자동으로 생성·평가할 수 있습니다. 그 과정에서 더 높은 보상을 주는 프롬프트가 자동으로 선택되고, 테스트셋 기준의 성능 비교와 기록까지 이루어져, 에이전트를 점진적으로 고도화하는 작업을 손쉽게 반복할 수 있습니다.
2. 환경 설정
2-1. CLOVA Studio API 준비
CLOVA Studio에서는 Chat Completions, 임베딩을 비롯한 주요 API에 대해 OpenAI API와의 호환성을 지원합니다. 본 예제에서는 OpenAI 호환 API 중 Chat Completions 엔드포인트(/chat/completions)를 활용하며, 상세 호환 정보는 OpenAI 호환성 가이드를 참고하시기 바랍니다.
또한, 해당 API 호출하려면 CLOVA Studio에서 발급받은 API 키가 필요합니다. API 키 발급 방법은 CLOVA Studio API 가이드에서 확인할 수 있습니다.
2-2. 프로젝트 구성
프로젝트의 전체 파일 구조는 다음과 같습니다. Python은 3.10 이상을 사용하며, 3.13 버전을 권장합니다.
agent_lightning_cookbook/ ├── .env ├── rollout.py ├── run_example.py ├── prompts/ │ ├── apply_edit_ko.poml │ └── text_gradient_ko.poml └── train_apo.py
2-3. 환경 변수 설정
루트 디렉토리에 .env 파일을 생성한 뒤, 앞서 발급받은 API Key를 다음과 같이 입력하고 저장합니다. 이때 따옴표 없이 값을 작성해야 하며, VS Code에서 실행할 경우 설정에서 Use Env File 옵션이 활성화되어 있는지 확인하세요.
CLOVA_STUDIO_API_KEY=YOUR_API_KEY
2-4. 패키지 설치
프로젝트에 필요한 패키지를 다음 코드를 실행하여 설치합니다.
pip install agentlightning openai python-dotenv poml
3. Rollout 구현
Agent Lightning의 롤아웃 구조를 단일 파일로 단순화해 구현해 봅니다.
본 예제에서는 자연어 요청을 5개 카테고리(주행, 차량 상태, 차량 제어, 미디어, 생활정보)로 분류하는 에이전트를 구성합니다.
각 태스크는 @dataclass로 정의되며, CLOVA Studio의 HCX-005 모델을 사용해 분류를 수행합니다. 시스템 프롬프트에는 다섯 가지 카테고리의 정의와 출력 규칙이 포함되어 있으며, 모델은 입력 문장을 읽고 리스트 형태의 문자열로 응답합니다. 정답은 하나 또는 여러 개일 수 있으며, 어떤 카테고리에도 해당하지 않는 경우에는 빈 리스트([])를 반환하는 것이 올바른 출력입니다.
run_rollout() 함수는 한 번의 태스크 실행 단위를 나타내며, 태스크를 실행하고 그 결과를 기반으로 보상을 계산하는 역할을 합니다. 보상은 다음 규칙에 따라 계산되며, 이는 서비스 목적에 따라 자유롭게 커스터마이즈하고 확장할 수 있습니다.
- 완전 일치(1.0): 모델 응답과 정답이 형식과 내용까지 모두 정확히 일치하는 경우
-
부분 일치
- 형식 불일치(0.9): 내용(레이블 집합)이 완전히 동일하지만, 따옴표, 공백, 대소문자 등의 형식이 다른 경우
- 부분 문자열 일치(0.5): 레이블이 완전히 같지는 않지만 문자열이 부분적으로 겹치는 경우(예: '주행'과 '차량 주행')
- 부분 레이블 일치(0.5): 여러 레이블 중 일부만 맞힌 경우(예: 2개 중 1개만 맞힌 경우)
- 불일치(0.0): 리스트 형태로 파싱할 수 없거나, 파싱되더라도 정답과의 교집합이 전혀 없는 경우
이렇게 계산된 보상은 emit_reward()를 통해 Agent Lightning 내부에 기록되며, 이후 APO가 프롬프트를 개선할 때 신호로 활용될 수 있습니다.
아래 코드는 태스크를 한 번 실행하고, 모델 응답을 평가해 보상을 기록하는 롤아웃 루프를 단일 파일로 구현한 예제입니다. 이는 프롬프트를 개선할 때 사용하는 핵심 루프 역할을 합니다. 아래 코드를 rollout.py로 저장하세요.
# rollout.py import os import re import json from dataclasses import dataclass from typing import Optional, List import asyncio from dotenv import load_dotenv from openai import AsyncOpenAI, RateLimitError from agentlightning import emit_reward load_dotenv() # --- CLOVA Studio 설정 --- BASE_URL = "https://clovastudio.stream.ntruss.com/v1/openai" API_KEY = os.getenv("CLOVA_STUDIO_API_KEY") # --- 태스크 정의 --- @dataclass class Task: """ 분류 태스크를 표현하는 데이터 구조입니다. - question: 분류 대상 문장 - expected_labels: 정답으로 기대하는 레이블 리스트(예: ["주행", "미디어"]) - task_id: (선택) 태스크 식별자 - system_prompt: (선택) 기본 시스템 프롬프트를 덮어쓰고 싶을 때 사용 """ question: str expected_labels: List[str] task_id: Optional[str] = None system_prompt: Optional[str] = None # --- 유틸리티 --- def normalize_list(values: List[str]) -> List[str]: """리스트 값 정규화""" return [v.strip().lower() for v in values] class RewardCalculator: """보상 계산 유틸리티""" @staticmethod def normalize(s: str) -> str: """문자열 정규화: 따옴표 제거, 공백 제거, 소문자 변환""" return s.strip().strip('\'"').lower() @staticmethod def is_partial_match(expected: str, actual: str) -> bool: """부분 문자열 일치 여부 확인""" e = RewardCalculator.normalize(expected) a = RewardCalculator.normalize(actual) return (e in a) or (a in e) # --- LLM 클라이언트 --- class ClovaClient: def __init__(self, model: str = "HCX-005", temperature: float = 0.0): self.client = AsyncOpenAI( base_url=BASE_URL, api_key=API_KEY, ) self.model = model self.temperature = temperature async def __aenter__(self): return self async def __aexit__(self, exc_type, exc_val, exc_tb): # asyncio.run()이 루프를 닫기 전에 안전하게 정리 try: self.client.close() except Exception: pass return False async def classify(self, task: Task) -> str: system_prompt = task.system_prompt or """ 당신은 분류기입니다. 입력 문장을 아래 5개 카테고리 중 해당되는 항목으로 분류하세요. 카테고리 정의: - 주행: 주행 및 내비게이션 관련 요청 - 차량 상태: 차량 진단/상태 확인 - 차량 제어: 차량 기능 조작 요청 - 미디어: 음악/라디오, 엔터테인먼트 요청 - 개인 비서: 전화, 메시지, 일정 등 개인 비서 기능 요청 출력 포맷: list 형태로 응답합니다. 해당되는 카테고리가 없다면 빈 배열로 응답하세요. 배열 내 문자열은 작은 따옴표로 감싸세요. """ messages = [ {"role": "system", "content": system_prompt}, {"role": "user", "content": task.question}, ] # LLM 호출(429 에러 시 재시도) max_retries = 5 wait_time = 2 for attempt in range(max_retries): try: resp = await self.client.chat.completions.create( model=self.model, messages=messages, temperature=self.temperature, ) return resp.choices[0].message.content.strip() except RateLimitError: if attempt < max_retries - 1: # 지수 백오프: 2초, 4초, 8초, 16초, 32초 await asyncio.sleep(wait_time) wait_time *= 2 else: raise except Exception: if attempt < max_retries - 1: await asyncio.sleep(wait_time) wait_time *= 2 else: raise # --- 롤아웃 함수 --- async def run_rollout(task: Task, client: ClovaClient) -> tuple[str, float]: """ 단일 롤아웃 실행: 1) 분류 실행 2) 보상 계산 3) 보상 emit """ # LLM 호출 predicted = await client.classify(task) # JSON 파싱을 위한 전처리 predicted_normalized = predicted.replace("'", '"') try: parsed = json.loads(predicted_normalized) if isinstance(parsed, list): predicted_list = [str(x).strip() for x in parsed] elif isinstance(parsed, str): predicted_list = [parsed] elif isinstance(parsed, dict): # JSON 객체인 경우: categories 또는 labels 키 찾기 if "categories" in parsed: categories = parsed["categories"] if isinstance(categories, list): predicted_list = [str(x).strip() for x in categories] else: predicted_list = [str(categories).strip()] elif "labels" in parsed: labels = parsed["labels"] if isinstance(labels, list): predicted_list = [str(x).strip() for x in labels] else: predicted_list = [str(labels).strip()] else: # 다른 구조의 dict -> 0.0 reward = 0.0 try: emit_reward(reward) except RuntimeError: pass return predicted, reward else: # 리스트도 문자열도 dict도 아님 -> 0.0 reward = 0.0 try: emit_reward(reward) except RuntimeError: pass return predicted, reward except Exception: # JSON 파싱 실패 -> 0.0 reward = 0.0 try: emit_reward(reward) except RuntimeError: pass return predicted, reward # 파싱 성공 시 내용 비교 calculator = RewardCalculator() expected_norm = [calculator.normalize(x) for x in task.expected_labels] actual_norm = [calculator.normalize(x) for x in predicted_list] if sorted(expected_norm) == sorted(actual_norm): expected_json = str(task.expected_labels) if predicted.strip() == expected_json: reward = 1.0 # 완전 일치 elif "'" in predicted: reward = 0.9 # 형식 불일치 elif '"' in predicted: reward = 0.9 # 형식 불일치 else: reward = 0.9 # 형식 불일치 elif set(expected_norm) & set(actual_norm): # 일부 레이블만 일치 reward = 0.5 else: # 부분 문자열 일치 확인 has_partial = False for e in expected_norm: for a in actual_norm: if calculator.is_partial_match(e, a): has_partial = True break if has_partial: break reward = 0.5 if has_partial else 0.0 # Agent Lightning에 보상 emit try: emit_reward(reward) except RuntimeError: pass return predicted, reward
다음은 롤아웃 샘플 실행 코드입니다. 아래 코드를 실행하면 에이전트가 다섯 개의 샘플 태스크를 순차적으로 수행하며, 각 태스크에 대한 모델 응답을 평가하고 보상을 계산·기록하는 과정을 확인할 수 있습니다.
# run_example.py import asyncio from rollout import Task, ClovaClient, run_rollout async def run_tests(): # 샘플 태스크 정의 tasks = [ Task( question="회사까지 가장 빠른 길 안내 시작해줘", expected_labels=["주행"], task_id="task_01", ), Task( question="타이어 공기압 체크", expected_labels=["차량 상태"], task_id="task_02", ), Task( question="온열 시트 켜고 출근길에 듣기 좋은 노래 틀어줘", expected_labels=["차량 제어", "미디어"], task_id="task_03", ), Task( question="엄마한테 전화 좀 걸어줘", expected_labels=["개인 비서"], task_id="task_04", ), Task( question="1+1은?", expected_labels=[], task_id="task_05", ), ] client = ClovaClient() for i, task in enumerate(tasks, 1): print(f"[Task {i}/{len(tasks)}] {task.task_id}") print(f"질의: {task.question}") predicted, reward = await run_rollout(task, client) print(f"모델 응답: {predicted}") print(f"실제 정답: {task.expected_labels}") print(f"Reward: {reward:.2f}\n") if __name__ == "__main__": asyncio.run(run_tests())
위 스크립트 실행 결과입니다. 결과를 보면, 일부 개선이 필요한 태스크를 확인할 수 있습니다. 이러한 부분은 APO를 활용한 프롬프트 자동 최적화를 통해 지침을 점진적으로 정교화함으로써 자연스럽게 개선될 수 있습니다.
[Task 1/5] task_01 질의: 회사까지 가장 빠른 길 안내 시작해줘 모델 응답: ['주행'] 실제 정답: ['주행'] Reward: 1.00 [Task 2/5] task_02 질의: 타이어 공기압 체크 모델 응답: ['차량 상태'] 실제 정답: ['차량 상태'] Reward: 1.00 [Task 3/5] task_03 질의: 온열 시트 켜고 출근길에 듣기 좋은 노래 틀어줘 모델 응답: ["차량 제어", "미디어"] 실제 정답: ['차량 제어', '미디어'] Reward: 0.90 [Task 4/5] task_04 질의: 엄마한테 전화 좀 걸어줘 모델 응답: ['개인 비서'] 실제 정답: ['개인 비서'] Reward: 1.00 [Task 5/5] task_05 질의: 1+1은? 모델 응답: [] 실제 정답: [] Reward: 1.00
Quote🤖 도구를 사용하는 에이전트에서의 보상 설계 팁
도구 기반 에이전트를 만들 경우, 보상은 다음과 같이 두 단계를 조합해 설계할 수 있습니다.
- 답변 정확도 보상: 모델의 답변과 정답의 일치도를 검증합니다. exact_match(완전 일치), contains(부분 일치), fuzzy_match(유사도)의 세 가지 전략 중 하나를 선택할 수 있습니다.
- 도구 사용 보상: 도구가 필요한 상황에서 도구를 사용하면 보너스(+0.3), 사용하지 않으면 페널티(−0.5)를 적용합니다.
최종 보상은 이 두 값을 합산해 0~1 범위로 클리핑하여 계산하며, 이렇게 산출된 보상은 에이전트를 개선하는 학습 루프에 활용할 수 있습니다.
4. APO 트레이너
APO는 Agent Lightning에 내장된 자동 프롬프트 개선 알고리즘입니다. 에이전트가 여러 태스크를 수행하며 얻은 보상을 기반으로 프롬프트 템플릿을 반복적으로 수정해, 더 높은 성능의 프롬프트로 수렴시키는 방식으로 동작합니다.
APO의 최적화 과정은 다음 두 단계로 구성됩니다.
- Gradient 단계: 무엇이 잘못되었고 어떻게 개선해야 하는지를 분석하는 단계입니다.
- Apply-Edit 단계: Gradient 단계에서 도출된 개선 방향을 기반으로 실제 프롬프트를 재작성하는 단계입니다.
즉, 모델이 어떤 응답을 생성했고 어떤 보상을 받았는지 분석한 뒤, 그 피드백을 기반으로 더 나은 프롬프트 후보를 생성·실험하는 구조입니다.
4-1. POML 커스터마이징
Agent Lightning에서 사용하는 APO 기본 템플릿은 모두 영문 기반 POML 파일로 제공됩니다. 기본 지시문이 영어 프롬프트 최적화를 전제로 설계되어 있기 때문에, 실제 최적화 과정에서도 모델이 영어 중심의 프롬프트를 생성하는 경향이 있습니다.
따라서 본 문서에서는 Microsoft Agent Lighting 레퍼런스 코드를 참고해, 한국어 프롬프트 최적화에 적합한 커스텀 POML 파일을 직접 구성하고 import하는 방식을 사용합니다.
Gradient 단계
이 템플릿은 APO의 첫 번째 단계에서 사용되며, LLM이 프롬프트의 문제점을 찾고, 개선 방향을 생성하는 역할을 수행합니다.
다음은 한국어 기반으로 재작성한 POML 템플릿 예시로, 태스크의 요구사항에 따라 해당 내용도 커스터마이징이 가능합니다. 아래 내용을 그대로 prompts 디렉터리 하위의 text_gradient_ko.poml 파일로 저장하세요.
<poml> <p>주어진 프롬프트 템플릿이 낮은 보상을 받은 이유를 정확하게 진단하고, 근본적인 개선점을 제시하십시오.</p> <cp caption="원본 프롬프트"> <text whiteSpace="pre">{{ prompt_template }}</text> </cp> <cp caption="실험 결과"> <cp for="experiment in experiments" caption="실험 {{ loop.index }}"> <p>보상: {{ experiment.final_reward }}</p> <object data="{{ experiment.messages }}" /> </cp> </cp> <cp caption="분석 지침"> 보상이 1.0 미만인 실험들을 분석하여 문제 패턴을 찾으십시오. 보상 점수의 의미: - 0.0~0.5: 리스트 형태로 파싱할 수 없거나, 파싱되더라도 정답과의 교집합이 전혀 없는 경우 - 0.5~0.9: 레이블이 완전히 같지는 않지만 문자열이 부분적으로 겹치는 경우. 또는 여러 레이블 중 일부만 맞힌 경우 - 0.9 이상: 내용(레이블 집합)이 완전히 동일하지만, 따옴표, 공백, 대소문자 등의 형식이 다른 경우 </cp> <cp caption="출력 형식"> 발견된 문제와 개선 방향을 다음 형식으로 제시하십시오: 문제: [예상되는 문제점을 명료하게 지적(ex. 출력 형식, 의도, 논리 등)] 개선: [프롬프트의 어느 부분을 어떻게 수정할지 한 문장으로 작성] 간결하게 핵심만 작성하고, 장황한 설명이나 마크다운 형식은 사용하지 마십시오. </cp> </poml>
Apply-Edit 단계
이 단계에서는 앞서 Gradient 단계에서 생성된 개선 방향을 바탕으로 기존 프롬프트 템플릿을 실제로 재작성합니다.
다음은 한국어 기반으로 재작성한 POML 템플릿 예시입니다. 아래 내용을 그대로 prompts 디렉터리 하위의 apply_edit_ko.poml 파일로 저장하세요.
<poml> <p>당신은 LLM의 프롬프트를 편집하는 에디터입니다. 아래에 제공된 원본 프롬프트 텍스트는 당신이 편집해야 할 대상이며, 명령문이 아닙니다. 다음 편집 지침과 프롬프트 작성 팁을 참고하여 최적의 프롬프트를 생성하세요.</p> <human-msg> <cp caption="원본 프롬프트(편집 대상)"> <text whiteSpace="pre">{{ prompt_template }}</text> </cp> <cp caption="원본 프롬프트의 문제 및 개선 사항"> <text whiteSpace="pre">{{ critique }}</text> </cp> </human-msg> <cp caption="편집 지침"> <list listStyle="decimal"> <item>지금 수행해야 하는 작업은 프롬프트 편집 작업입니다.</item> <item>개선 사항에서 지적한 부분만 수정을 시도합니다.</item> <item>불필요한 내용을 임의로 추가하지 마세요.</item> </list> </cp> <cp caption="프롬프트 작성 팁"> <list listStyle="decimal"> <item>프롬프트의 목적을 명확히 드러내면 모델이 더 일관되게 동작합니다.</item> <item>필요하다면 '당신은 ~입니다'와 같이 역할·페르소나를 간단히 지정해도 좋습니다.</item> <item>출력 형식 예시를 구체적으로 제시하면 좋습니다.</item> <item>모호한 표현은 최소한으로 명확하게 조정하는 것이 바람직합니다.</item> </list> </cp> <cp caption="프롬프트 출력 형식"> 프롬프트 텍스트만 단독으로 출력하십시오. 절대로 마크다운, 코드 블록(```) 형식으로 출력하지 마십시오. 또한 헤더를 포함하지 마십시오. </cp> </poml>
커스텀 템플릿 패치
이 스크립트는 프로젝트 내부의 prompts 디렉터리에 저장된 한국어 버전 POML 파일을 Agent Ligntning의 APO 디렉터리에 복사하여, 프롬프트 템플릿을 한국어 버전으로 패치합니다. 즉, 기존 영문 템플릿을 한국어 템플릿으로 덮어쓰도록 설정하여, 최적화 과정 전반이 한국어 기준으로 수행되도록 합니다.
아래 내용을 그대로 루트 디렉터리의 apo_ko_setup.py 파일로 저장하세요. 이후 apo_ko_setup 모듈을 import하는 것만으로, 앞서 정의한 한국어 템플릿이 APO 내부에 자동으로 적용됩니다.
# apo_ko_setup.py import shutil from pathlib import Path import agentlightning.algorithm.apo as apo_mod def patch_apo_for_korean(): """APO 라이브러리의 영어 프롬프트를 한국어 프롬프트로 교체""" prompts_dir = Path(__file__).parent / "prompts" apo_base_dir = Path(apo_mod.__file__).parent apo_prompts_dir = apo_base_dir / "prompts" files = { "text_gradient_ko.poml": "text_gradient_variant01.poml", "apply_edit_ko.poml": "apply_edit_variant01.poml", } if not apo_prompts_dir.exists(): print(f"APO 프롬프트 디렉터리를 찾을 수 없습니다: {apo_prompts_dir}") return for ko_file, apo_file in files.items(): ko_path = prompts_dir / ko_file apo_path = apo_prompts_dir / apo_file if ko_path.exists(): shutil.copy(ko_path, apo_path) else: print(f"{ko_file} 없음") try: patch_apo_for_korean() except Exception as e: print(f"APO 패치 실패: {e}")
4-2. 데이터셋 준비
분류 태스크의 학습 및 평가에 사용할 데이터를 준비합니다.
Quote# dataset.py from typing import List from rollout import Task def create_classification_dataset() -> List[Task]: return [ # 주행(단일 카테고리) - 15개 Task(task_id='task_01', question='집까지 가장 빠른 길 안내해줘', expected_labels=['주행']), Task(task_id='task_02', question='근처 주유소 가는 경로 안내 시작', expected_labels=['주행']), Task(task_id='task_03', question='고속도로 교통상황 알려줘', expected_labels=['주행']), Task(task_id='task_04', question='서울역으로 내비게이션 설정해줘', expected_labels=['주행']), Task(task_id='task_05', question='회사까지 최단거리로 안내', expected_labels=['주행']), Task(task_id='task_06', question='강남역 가는 길 알려줘', expected_labels=['주행']), Task(task_id='task_07', question='톨게이트 요금 얼마나 나올까?', expected_labels=['주행']), Task(task_id='task_08', question='우회도로 경로 찾아줘', expected_labels=['주행']), Task(task_id='task_09', question='목적지까지 남은 시간 알려줘', expected_labels=['주행']), Task(task_id='task_10', question='근처 휴게소 어디 있어?', expected_labels=['주행']), Task(task_id='task_11', question='인천공항까지 가는 최적의 경로 찾아줘', expected_labels=['주행']), Task(task_id='task_12', question='트래픽 없는 우회 경로 안내해줘', expected_labels=['주행']), Task(task_id='task_13', question='가장 가까운 전기차 충전소 찾아줘', expected_labels=['주행']), Task(task_id='task_14', question='출발지에서 목적지까지 거리 몇 km야?', expected_labels=['주행']), Task(task_id='task_15', question='지금 현재 위치에서 강서구청까지 가는 길 보여줘', expected_labels=['주행']), # 차량 상태(단일 카테고리) - 15개 Task(task_id='task_16', question='엔진오일 교체가 필요한지 확인해줘', expected_labels=['차량 상태']), Task(task_id='task_17', question='지금 타이어 압력 괜찮아?', expected_labels=['차량 상태']), Task(task_id='task_18', question='배터리 잔량 알려줘', expected_labels=['차량 상태']), Task(task_id='task_19', question='경고등이 켜졌는데 뭐가 문제야?', expected_labels=['차량 상태']), Task(task_id='task_20', question='냉각수 부족한지 체크해줘', expected_labels=['차량 상태']), Task(task_id='task_21', question='브레이크 패드 상태 확인', expected_labels=['차량 상태']), Task(task_id='task_22', question='차량 점검 필요한 항목 알려줘', expected_labels=['차량 상태']), Task(task_id='task_23', question='연료 얼마나 남았어?', expected_labels=['차량 상태']), Task(task_id='task_24', question='엔진 온도가 정상인지 확인', expected_labels=['차량 상태']), Task(task_id='task_25', question='차량 진단 결과 보여줘', expected_labels=['차량 상태']), Task(task_id='task_26', question='타이어 마모도는 어느 정도야?', expected_labels=['차량 상태']), Task(task_id='task_27', question='엔진 점검 필요한데 언제 해야 돼?', expected_labels=['차량 상태']), Task(task_id='task_28', question='배터리 확인해줄래?', expected_labels=['차량 상태']), Task(task_id='task_29', question='휠 얼라인먼트 체크 필요해', expected_labels=['차량 상태']), Task(task_id='task_30', question='현재 주행거리 몇 km야?', expected_labels=['차량 상태']), # 차량 제어(단일 카테고리) - 15개 Task(task_id='task_31', question='운전석 창문 조금 내려줘', expected_labels=['차량 제어']), Task(task_id='task_32', question='에어컨을 22도로 맞춰줘', expected_labels=['차량 제어']), Task(task_id='task_33', question='시동 꺼줘', expected_labels=['차량 제어']), Task(task_id='task_34', question='문 잠금 해제해줘', expected_labels=['차량 제어']), Task(task_id='task_35', question='선루프 열어줘', expected_labels=['차량 제어']), Task(task_id='task_36', question='뒷좌석 열선 켜줘', expected_labels=['차량 제어']), Task(task_id='task_37', question='외부 순환 모드로 바꿔', expected_labels=['차량 제어']), Task(task_id='task_38', question='와이퍼 작동시켜줘', expected_labels=['차량 제어']), Task(task_id='task_39', question='헤드라이트 켜줘', expected_labels=['차량 제어']), Task(task_id='task_40', question='실내등 켜줘', expected_labels=['차량 제어']), Task(task_id='task_41', question='뒷유리 열선 켜', expected_labels=['차량 제어']), Task(task_id='task_42', question='주차 센서 활성화해줘', expected_labels=['차량 제어']), Task(task_id='task_43', question='크루즈 컨트롤 속도 70으로 설정', expected_labels=['차량 제어']), Task(task_id='task_44', question='사이드 미러 자동 접기 실행', expected_labels=['차량 제어']), Task(task_id='task_45', question='배기구 매연 필터 리셋해줘', expected_labels=['차량 제어']), # 미디어(단일 카테고리) - 15개 Task(task_id='task_46', question='라디오 켜', expected_labels=['미디어']), Task(task_id='task_47', question='볼륨을 10으로 낮춰봐', expected_labels=['미디어']), Task(task_id='task_48', question='아이유 노래 틀어줘', expected_labels=['미디어']), Task(task_id='task_49', question='음악 일시정지', expected_labels=['미디어']), Task(task_id='task_50', question='다음 곡으로 넘겨', expected_labels=['미디어']), Task(task_id='task_51', question='재즈 음악 재생해줘', expected_labels=['미디어']), Task(task_id='task_52', question='블루투스 연결해줘', expected_labels=['미디어']), Task(task_id='task_53', question='FM 95.1 주파수로 맞춰', expected_labels=['미디어']), Task(task_id='task_54', question='이전 곡으로 돌아가', expected_labels=['미디어']), Task(task_id='task_55', question='플레이리스트 셔플해줘', expected_labels=['미디어']), Task(task_id='task_56', question='방탄소년단 앨범 재생', expected_labels=['미디어']), Task(task_id='task_57', question='팟캐스트 틀어줘', expected_labels=['미디어']), Task(task_id='task_58', question='클래식 채널로 변경해줘', expected_labels=['미디어']), Task(task_id='task_59', question='밸런스 왼쪽으로 조정해', expected_labels=['미디어']), Task(task_id='task_60', question='음악 반복 모드 설정해줄래?', expected_labels=['미디어']), # 개인 비서(단일 카테고리) - 15개 Task(task_id='task_61', question='엄마한테 전화 걸어줘', expected_labels=['개인 비서']), Task(task_id='task_62', question='김철수한테 3시 도착 예정으로 문자 하나 보내줘', expected_labels=['개인 비서']), Task(task_id='task_63', question='오늘 일정 알려줘', expected_labels=['개인 비서']), Task(task_id='task_64', question='지금 안읽은 메시지 쭉 읽어줘', expected_labels=['개인 비서']), Task(task_id='task_65', question='캘린더에 내일 오전 10시 회의 일정 하나 추가해놔', expected_labels=['개인 비서']), Task(task_id='task_66', question='지난 3일 동안 메일 온 것들 브리핑 해줘', expected_labels=['개인 비서']), Task(task_id='task_67', question='메신저 알림 좀 1시간 동안 잠깐 꺼줘', expected_labels=['개인 비서']), Task(task_id='task_68', question='오후 3시에 알람 설정해줘', expected_labels=['개인 비서']), Task(task_id='task_69', question='내 핸드폰 배터리 확인하고 50퍼 이하면 저전력 모드 켜주라', expected_labels=['개인 비서']), Task(task_id='task_70', question='음성 메모 녹음 시작해줘', expected_labels=['개인 비서']), Task(task_id='task_71', question='아버지한테 "곧 도착하겠습니다" 보내줄래?', expected_labels=['개인 비서']), Task(task_id='task_72', question='내일 아침 기상 알림 켜놔줘', expected_labels=['개인 비서']), Task(task_id='task_73', question='부재중 찍힌거 누구야?', expected_labels=['개인 비서']), Task(task_id='task_74', question='최근 스캔한 명함 정보 말해줘', expected_labels=['개인 비서']), Task(task_id='task_75', question='내 휴대폰 방해금지 모드로 해줘', expected_labels=['개인 비서']), # 멀티레이블 - 15개 Task(task_id='task_76', question='창문 닫고 아이유 신곡 재생', expected_labels=['차량 제어', '미디어']), Task(task_id='task_77', question='엉따 2단계 해주고 퇴근길 경로 찾아줘', expected_labels=['차량 제어', '주행']), Task(task_id='task_78', question='음악 잠깐 정지하고 엄마한테 전화 걸어줘', expected_labels=['미디어', '개인 비서']), Task(task_id='task_79', question='재생목록 틀어주고 실내 공기 순환 모드 켜줘', expected_labels=['미디어', '차량 제어']), Task(task_id='task_80', question='타이어 공기압 확인하고 근처 정비소 안내해줘', expected_labels=['차량 상태', '주행']), Task(task_id='task_81', question='배터리 상태 보고하고 문자 앱 좀 열어줘', expected_labels=['차량 상태', '개인 비서']), Task(task_id='task_82', question='히터 켜고 음악 틀어줘', expected_labels=['차량 제어', '미디어']), Task(task_id='task_83', question='연료 잔량 확인하고 근처 주유소 안내', expected_labels=['차량 상태', '주행']), Task(task_id='task_84', question='라디오 끄고 오늘 일정 알려줘', expected_labels=['미디어', '개인 비서']), Task(task_id='task_85', question='선루프 열고 집 가는 길 안내', expected_labels=['차량 제어', '주행']), Task(task_id='task_86', question='에어컨 20도로 맞추고 클래식 재생해줘', expected_labels=['차량 제어', '미디어']), Task(task_id='task_87', question='엔진 진단하고 스팸 메시지 삭제해', expected_labels=['차량 상태', '개인 비서']), Task(task_id='task_88', question='휠 상태 확인하고 가장 빠른 경로로 안내', expected_labels=['차량 상태', '주행']), Task(task_id='task_89', question='시트 히터 켜고 좋아하는 팟캐스트 틀어', expected_labels=['차량 제어', '미디어']), Task(task_id='task_90', question='배터리 잔량 확인 후 동료한테 연락해', expected_labels=['차량 상태', '개인 비서']), # 범위 외 - 10개 Task(task_id='task_91', question='가벼운 점심 메뉴 뭐가 좋을까?', expected_labels=[]), Task(task_id='task_92', question='하얀 푸들 강아지 이름 추천해줘', expected_labels=[]), Task(task_id='task_93', question='고양이는 왜 낮잠을 많이 자?', expected_labels=[]), Task(task_id='task_94', question='"내비"는 콩글리쉬야?', expected_labels=[]), Task(task_id='task_95', question='야간 운전할 때 눈이 덜 피곤하게 하는 팁 같은 거 있어?', expected_labels=[]), Task(task_id='task_96', question='파이썬 공부하기 좋은 책 추천', expected_labels=[]), Task(task_id='task_97', question='김치찌개 맛있게 끓이는 방법', expected_labels=[]), Task(task_id='task_98', question='지하철은 몇 호선이 제일 오래됐어?', expected_labels=[]), Task(task_id='task_99', question='세계에서 가장 높은 산은?', expected_labels=[]), Task(task_id='task_100', question='재미있는 영화 추천해줘', expected_labels=[]) ]
4-3. 실행 및 결과
아래 코드는 APO 트레이너를 구성하고, 한국어 POML 템플릿을 사용해 프롬프트 최적화 루프를 실행하는 예제입니다.
CLOVA Studio의 HCX-005 모델을 기반으로 APO 알고리즘을 초기화하고, 분류 작업에 맞는 초기 프롬프트 템플릿을 initial_resources에 직접 지정하여 학습을 시작합니다. @agl.rollout 데코레이터로 정의된 에이전트는 각 태스크를 실행하면서 LLM 응답을 생성하고, run_rollout에서 계산된 보상 값을 반환합니다. 이 보상 값은 APO가 다음 프롬프트를 수정하고 개선하는 데 핵심적인 학습 신호로 활용됩니다. 트레이너는 초기 프롬프트 템플릿을 기준으로 학습·검증 데이터셋을 반복 실행하며, 보상을 최대화하는 방향으로 프롬프트를 자동으로 수정하고 버전(v0, v1, v2…) 단위로 관리합니다.
학습이 완료되면, trainer.store에 저장된 프롬프트 버전들을 모두 불러와 테스트셋으로 다시 평가합니다. 이 중 가장 높은 성능을 기록한 프롬프트가 최종 버전으로 선택되며, 모든 버전의 프롬프트 내용과 테스트셋 점수는 prompt_history.txt 파일에 저장됩니다.
# train_apo.py import os import random import asyncio import logging from copy import deepcopy from dotenv import load_dotenv import agentlightning as agl from openai import AsyncOpenAI from rollout import Task, run_rollout, ClovaClient from dataset import create_classification_dataset import apo_ko_setup # 한국어 POML 패치용 logging.getLogger("agentlightning").setLevel(logging.CRITICAL) load_dotenv() # --- 설정 --- BASE_URL = "https://clovastudio.stream.ntruss.com/v1/openai" API_KEY = os.getenv("CLOVA_STUDIO_API_KEY") MODEL_NAME = "HCX-005" RANDOM_SEED = 42 BEAM_ROUNDS = 1 BEAM_WIDTH = 1 # --- 전역 변수 --- task_counter = 0 @agl.rollout async def classification_agent(task: dict, prompt_template: agl.PromptTemplate) -> float: """ APO에서 호출되는 분류 에이전트. - task: 데이터셋에서 전달된 태스크(dict) - prompt_template: APO가 현재 시점에 사용 중인 시스템 프롬프트 템플릿 """ global task_counter try: task_obj = Task(**task) # APO가 최적화한 프롬프트를 system_prompt로 주입 if hasattr(prompt_template, "template"): prompt_str = prompt_template.template else: prompt_str = str(prompt_template) task_obj.system_prompt = prompt_str # ClovaClient는 컨텍스트 매니저로 사용하여 연결 정리 async with ClovaClient(model=MODEL_NAME) as client: _, reward = await run_rollout(task_obj, client) task_counter += 1 print(f"\r학습 중... (진행: {task_counter})", end="", flush=True) return reward except Exception as e: print(f"\nTask 오류: {e}") return 0.0 async def evaluate_prompt_on_dataset(prompt_template, dataset_tasks): """ 주어진 프롬프트 템플릿으로 데이터셋 평가. APO가 만든 프롬프트(각 버전)에 대해 test셋에서 평균 reward 계산. """ if hasattr(prompt_template, "template"): prompt_str = prompt_template.template else: prompt_str = str(prompt_template) rewards = [] async with ClovaClient(model=MODEL_NAME) as client: for task_item in dataset_tasks: try: task_obj = deepcopy(task_item) if isinstance(task_item, Task) else Task(**task_item) task_obj.system_prompt = prompt_str _, reward = await run_rollout(task_obj, client) rewards.append(reward) except Exception: rewards.append(0.0) return sum(rewards) / len(rewards) if rewards else 0.0 def extract_version_info(trainer_store): """ Trainer.store 내부에서 버전별 프롬프트를 추출. InMemoryLightningStore의 _resources를 직접 읽어서 v0, v1, v2 ... 버전별 prompt_template를 모은다. """ resources_dict = trainer_store._resources if hasattr(trainer_store, "_resources") else {} initial_prompt = None resources_prompts = {} for version in sorted(resources_dict.keys(), key=lambda v: int(v[1:])): resources_update = resources_dict[version] if not (hasattr(resources_update, "resources") and "prompt_template" in resources_update.resources): continue prompt = resources_update.resources["prompt_template"] resources_prompts[version] = prompt if version == "v0": initial_prompt = prompt return { "resources_dict": resources_dict, "resources_prompts": resources_prompts, "initial_prompt": initial_prompt, } def main(): # --- 데이터셋 분할 --- all_tasks = create_classification_dataset() random.seed(RANDOM_SEED) random.shuffle(all_tasks) total = len(all_tasks) train_tasks = all_tasks[: int(total * 0.6)] val_tasks = all_tasks[int(total * 0.6) : int(total * 0.8)] test_tasks = all_tasks[int(total * 0.8) :] # --- APO 설정 --- try: client = AsyncOpenAI(base_url=BASE_URL, api_key=API_KEY) algorithm = agl.APO( client, gradient_model=MODEL_NAME, apply_edit_model=MODEL_NAME, beam_rounds=BEAM_ROUNDS, beam_width=BEAM_WIDTH, ) except Exception as e: print(f"오류: {e}") return trainer = agl.Trainer( algorithm=algorithm, strategy=agl.SharedMemoryExecutionStrategy(main_thread="algorithm"), tracer=agl.OtelTracer(), initial_resources={ "prompt_template": agl.PromptTemplate( template=""" 당신은 분류기입니다. 입력 문장을 아래 5개 카테고리 중 해당되는 항목으로 분류하세요. 카테고리 정의: - 주행: 주행 및 내비게이션 관련 요청 - 차량 상태: 차량 진단/상태 확인 - 차량 제어: 차량 기능 조작 요청 - 미디어: 음악/라디오, 엔터테인먼트 요청 - 개인 비서: 전화, 메시지, 일정 등 개인 비서 기능 요청 출력 포맷: list 형태로 응답합니다. 해당되는 카테고리가 없다면 빈 배열로 응답하세요. 배열 내 문자열은 작은 따옴표로 감싸세요. """, engine="f-string", ) }, adapter=agl.TraceToMessages(), ) # --- 학습 실행 --- trainer.fit(agent=classification_agent, train_dataset=train_tasks, val_dataset=val_tasks) # --- 버전별 프롬프트 추출 --- if not (hasattr(trainer.store, "_resources") and trainer.store._resources): print("리소스 없음") return info = extract_version_info(trainer.store) if not info["initial_prompt"] or not info["resources_prompts"]: print("프롬프트 추출 실패") return # --- 테스트셋 평가 --- async def run_evaluation(): version_test_results = {} for version in sorted(info["resources_prompts"].keys(), key=lambda v: int(v[1:])): prompt = info["resources_prompts"][version] score = await evaluate_prompt_on_dataset(prompt, test_tasks) version_test_results[version] = score return version_test_results try: version_test_results = asyncio.run(run_evaluation()) # 최적 버전 선택 best_version = max(version_test_results.keys(), key=lambda v: version_test_results[v]) best_score = version_test_results[best_version] initial_test_score = version_test_results.get("v0", 0.0) print("\n" + "=" * 60) print("최종 평가 결과") print("=" * 60) print(f" 초기 프롬프트(v0): {initial_test_score:.3f}") print(f" 수정된 프롬프트({best_version}): {best_score:.3f}\n") # --- 프롬프트 히스토리 저장 --- with open("prompt_history.txt", "w", encoding="utf-8") as f: f.write("=" * 80 + "\n프롬프트 최적화 이력\n" + "=" * 80 + "\n\n") for version in sorted(info["resources_prompts"].keys(), key=lambda v: int(v[1:])): prompt = info["resources_prompts"][version] prompt_str = prompt.template if hasattr(prompt, "template") else str(prompt) score = version_test_results[version] f.write(f"[{version}] 테스트셋 점수: {score:.3f}\n") f.write("-" * 80 + "\n") f.write(f"{prompt_str}\n") f.write("=" * 80 + "\n\n") print("✓ prompt_history.txt 저장\n") except Exception as e: print(f"평가 중 오류: {e}") import traceback traceback.print_exc() if __name__ == "__main__": main()
다음은 위 코드를 실행했을 때 출력된 결과입니다. 동일한 테스트셋을 기반으로 비교한 결과, 수정된 프롬프트(v4)가 기존 프롬프트 대비 더 높은 분류 성능을 보여줌을 확인할 수 있습니다.
============================================================ 최종 평가 결과 ============================================================ 초기 프롬프트(v0): 0.835 수정된 프롬프트(v4): 0.945 ✓ prompt_history.txt 저장
다음은 APO 알고리즘을 통해 자동으로 개선된 프롬프트 v4의 원본입니다. 이후 필요에 따라 학습 파라미터를 조정해 추가적인 최적화 실험을 진행할 수도 있습니다.
문장 분류기를 위한 분류 작업을 수행해주세요. 분류할 카테고리는 다음과 같습니다: - 주행: 주행 및 내비게이션과 관련된 내용 - 차량 상태: 차량 진단이나 상태에 대한 정보 요청 - 차량 제어: 차랑 기능 조작 요청 - 미디어: 음악 또는 라디오 등의 엔터테인먼트 요청 - 개인 비서: 전화걸기, 메시지 보내기, 일정 등록 등과 같은 개인 비서 업무 요청 제공된 문장을 위의 5가지 카테고리 중 가장 적합하다고 생각하는 곳으로 분류하고 그 결과를 list 형태로 제시해 주세요. 예를 들어 아래와 같이 나타낼 수 있습니다: ```plaintext ['주행', '차량 제어'] ``` 위 예시처럼 해당하는 카테고리를 작은따옴표 안에 넣어서 list로 구성해주시면 됩니다. 만약 문장이 어떠한 카테고리에도 속하지 않는다면 빈 배열 `[]`을 반환하셔도 됩니다.
5. 맺음말
이번 쿡북에서는 CLOVA Studio 모델을 기반으로 롤아웃을 구성하고, APO를 통해 프롬프트를 자동으로 개선하는 전체 흐름을 살펴보았습니다.
단순한 분류 태스크도 보상 구조만 잘 설계하면 원하는 방향으로 모델을 안정적으로 유도할 수 있고, APO는 이 보상 신호를 활용해 프롬프트를 점진적으로 더 좋은 형태로 다듬어 줍니다.
이 구조는 다른 도메인의 에이전트에도 그대로 확장할 수 있는데요. 서비스 요구사항에 맞게 태스크, 보상 체계 등을 커스터마이즈하면, 보다 복잡한 워크플로우나 실제 서비스 환경에서도 안정적인 프롬프트를 자동으로 구축할 수 있습니다. 특히 프롬프트 성능이 곧 모델 품질로 이어지는 LLM 기반 시스템에서는, 이러한 자동 최적화가 품질을 빠르게 끌어올리는 데 효과적입니다.
이제 여러분의 서비스 맥락에 맞는 태스크를 넣어 보며 프롬프트가 어떻게 진화하는지 확인해 보세요. 🧐
-
들어가며
(1부) MCP 실전 쿡북: LangChain에서 네이버 검색 도구 연결하기에 이어서, 이번 2부에서는 MCP로 Stateful 대화 기능을 구현하고 흐름을 관리하는 방법을 다룹니다.
1부에서 만든 MCP 서버를 기반으로 LangChain과 HyperCLOVA X 모델을 연결하고, 세션 ID를 활용해 대화 흐름을 지속적으로 이어가는 과정을 살펴봅니다. 또한 LangGraph의 Checkpointer를 사용해 세션 상태를 저장·재사용하며, SQLite 기반 저장소를 통해 멀티턴 문맥을 자연스럽게 유지하는 방법을 소개합니다. 마지막으로, 제한된 토큰 수 내에서 모델의 컨텍스트를 효율적으로 관리하는 팁도 함께 다뤄보겠습니다.
MCP 실전 쿡북 4부작 시리즈
✔︎ (1부) LangChain에서 네이버 검색 도구 연결하기 링크
✔︎ (2부) 세션 관리와 컨텍스트 유지 전략
✔︎ (3부) OAuth 인증이 통합된 MCP 서버 구축하기 링크
✔︎ (4부) 운영과 확장을 위한 다양한 팁 링크
1. 사전 준비 사항
이 예제를 실행하려면 Python 3.10 이상의 개발 환경이 필요합니다. 가상환경을 구성하고 .env 파일에 API 키를 등록한 뒤, 필요한 패키지를 설치합니다. MCP 서버(server.py)는 1부에서 생성한 서버 파일을 그대로 사용합니다.
프로젝트 구성
프로젝트의 전체 파일 구조는 다음과 같습니다. Python 버전은 3.10 이상, 3.13 미만입니다.
mcp_cookbook_part2/ ├── server.py # mcp_cookbook_part1에서 생성한 파일을 사용합니다. ├── client/ │ ├── stateful_client.py │ ├── stateful_client_trim.py │ └── stateful_client_sum.py ├── init_db.py ├── checkpoint.db # init_db.py 실행 시 생성됩니다. ├── requirements.txt ├── .venv └── .env환경 변수 설정
루트 디렉터리에 .env 파일을 생성한 뒤, 앞서 발급받은 API Key를 다음과 같이 입력하고 저장합니다. 이때 따옴표 없이 값을 작성해야 하며, VS Code에서 실행할 경우 설정에서 Use Env File 옵션이 활성화되어 있는지 확인하세요.
CLOVA_STUDIO_API_KEY=YOUR_API_KEY NAVER_CLIENT_ID=YOUR_CLIENT_ID NAVER_CLIENT_SECRET=YOUR_CLIENT_SECRET패키지 설치
프로젝트에 필요한 패키지 목록은 아래 다운로드 링크에서 확인할 수 있습니다. 해당 내용을 복사해 루트 디렉터리에 requirements.txt 파일로 저장하세요.
루트 디렉터리에서 터미널을 실행하여 다음과 같이 예제 실행에 필요한 패키지를 설치합니다. 가상환경 설치를 권장합니다.
# 1. 파이썬 가상환경 생성 python -m venv .venv # 2. 가상환경 활성화 (macOS/Linux) source .venv/bin/activate # (Windows) # .venv/Scripts/activate.ps1 # 3. 패키지 설치 pip install -r requirements.txt2. Stateless와 Stateful 개념
대화 시스템은 크게 Stateless와 Stateful 두 가지 방식으로 동작할 수 있습니다.
- Stateless: 각 요청이 이전 맥락과 완전히 분리되어 독립적으로 처리됩니다.
- Stateful: 대화 상태를 별도의 저장소에 보관하고, 동일한 세션 ID를 가진 후속 요청에서 자동으로 이 상태를 불러옵니다. 이렇게 하면 모델이 이전 대화 내용을 자연스럽게 이어받아 연속적이고 일관된 대화 흐름을 유지할 수 있습니다.
장기 대화나 도구 호출이 섞이는 복합 시나리오에서는 Stateful 방식을 사용하는 것이 사용자의 의도와 맥락을 안정적으로 추적하는 데 도움이 됩니다. 아래 도식은 클라이언트가 사용자 입력을 받아 세션 저장소에서 상태를 조회하거나 초기 컨텍스트를 구성한 뒤, LLM과 상호작용하여 응답하고, 마지막에 상태를 저장하는 Stateful 대화 흐름을 단계별로 보여줍니다.
3. Stateful 대화 구현
앞서 제시한 도식 흐름을 실제 코드로 구현하는 방법을 설명합니다.
세션 저장소 초기화
LangGraph에서 대화 상태를 지속적으로 저장・조회하려면 세션 저장소가 필요합니다. 여기에서는 SQLAlchemy를 이용해 SQLite 데이터베이스 파일(checkpoint.db)을 생성하고, 이후 Checkpointer가 사용할 수 있는 기본 테이블 메타데이터를 초기화합니다.
아래 스크립트를 실행하면 checkpoint.db 파일이 생성되며, 최초 1회만 실행하면 됩니다. 그 이후부터는 이 데이터베이스가 세션별 대화 상태를 보관하는 저장소로 사용됩니다.
from sqlalchemy import create_engine from sqlalchemy.orm import declarative_base, sessionmaker engine = create_engine("sqlite:///checkpoint.db", connect_args={"check_same_thread": False}) SessionLocal = sessionmaker(bind=engine, autocommit=False, autoflush=False) Base = declarative_base() Base.metadata.create_all(bind=engine)
Stateful 대화 실행
다음은 사용자가 입력한 세션 ID를 기준으로 대화 상태를 관리하는 클라이언트입니다. 특정 ID가 입력되면 해당 세션의 히스토리를 불러와 맥락을 이어가고, 새로운 ID를 입력하면 시스템 프롬프트와 함께 새로운 세션을 시작합니다.
각 턴이 종료될 때마다 LangGraph가 Checkpointer에 상태를 저장하기 때문에, 이후 세션을 재실행하면 직전까지의 대화 흐름을 그대로 이어받아 자연스럽고 일관된 멀티턴 대화를 이어갈 수 있습니다.
모델은 HCX-005를 사용하였고, 만약 HCX-007 모델을 도구와 함께 사용할 경우에는 reasoning_effort="none"을 반드시 설정해야 합니다.
import os import asyncio import uuid from dotenv import load_dotenv from mcp import ClientSession from mcp.client.streamable_http import streamablehttp_client from langchain_mcp_adapters.tools import load_mcp_tools from langchain_naver import ChatClovaX from langchain.agents import create_agent from langchain.messages import SystemMessage, HumanMessage from langgraph.checkpoint.sqlite.aio import AsyncSqliteSaver async def main(clova_api_key: str, server_url: str, checkpoint_path: str): """ CLOVA Studio 모델을 LangChain을 통해 호출하고, MCP 서버에 등록된 도구를 연동하여 최종 응답을 생성합니다. 사용자 입력에 따라 새 세션을 시작하거나 이전 세션을 이어갑니다. Args: clova_api_key (str): CLOVA Studio에서 발급받은 API Key server_url (str): 연결할 MCP 서버의 엔드포인트 URL checkpoint_path (str): Checkpoint 저장 경로 """ model = ChatClovaX(model="HCX-005", api_key=clova_api_key) async with streamablehttp_client(server_url) as (read, write, _,): async with ClientSession(read, write) as session: # MCP 서버를 초기화하고 도구 목록을 불러옵니다. await session.initialize() tools = await load_mcp_tools(session) # Checkpointer를 생성합니다. async with AsyncSqliteSaver.from_conn_string(checkpoint_path) as checkpointer: # 에이전트를 생성하고 Checkpointer를 연결합니다. agent = create_agent(model, tools, checkpointer=checkpointer) # 참조할 세션 ID를 입력받습니다. thread_id = input("세션 ID를 입력하세요(새 세션 시작은 Enter):").strip() # 새 세션이면 신규 세션 ID를 생성합니다. if not thread_id: thread_id = str(uuid.uuid4()) config = {"configurable": {"thread_id": thread_id}} print(f"현재 세션 ID: {thread_id}\n") print("안녕하세요. 저는 AI 어시스턴트입니다. 원하시는 요청을 입력해 주세요. (종료하려면 '종료'를 입력하세요.)") system_message = [ SystemMessage(content=( "당신은 친절한 AI 어시스턴트입니다." "사용자의 질문에 대해 신뢰할 수 있는 정보만 근거로 삼아 답변하세요." )) ] while True: user_input = input("\n\nUser: ") if user_input.lower() in ["종료", "exit"]: print("대화를 종료합니다. 이용해 주셔서 감사합니다.") break current_state = {"messages": [HumanMessage(content=user_input)]} try: existing_checkpoint = await checkpointer.aget_tuple(config) if existing_checkpoint is not None: # 기존 스레드가 있으면 현재 메시지만 추가합니다. state = current_state else: # 새 스레드라면 SystemMessage와 현재 메시지를 모두 추가합니다. state = {"messages": system_message + current_state["messages"]} # astream_events를 사용하여 스트리밍으로 응답을 처리합니다. async for event in agent.astream_events(state, config=config, version="v1"): kind = event["event"] if kind == "on_chat_model_stream": chunk = event["data"]["chunk"] if chunk.content: print(chunk.content, end="", flush=True) elif kind == "on_tool_start": print(f"\n[도구 선택]: {event['name']}\n[도구 호출]: {event['data'].get('input')}") elif kind == "on_tool_end": print(f"[도구 응답]: {event['data'].get('output')}\n") except Exception as e: print(f"\n요청을 처리하는 중에 오류가 발생했습니다. 오류: {e}") pass if __name__ == "__main__": """ .env 파일에서 CLOVA Studio API Key를 로드하고, MCP 서버의 엔드포인트 URL을 설정한 후 클라이언트를 실행합니다. """ load_dotenv() CLOVA_STUDIO_API_KEY = os.getenv("CLOVA_STUDIO_API_KEY") SERVER_URL = "http://127.0.0.1:8000/mcp/" CHECKPOINT_PATH = "checkpoint.db" asyncio.run(main(CLOVA_STUDIO_API_KEY, SERVER_URL, CHECKPOINT_PATH))
위 스크립트를 실행하면, CLOVA Studio 모델(HCX-005)이 MCP 서버를 통해 등록된 도구와 연동되어 사용자의 질문에 응답합니다. 특정 세션에서 멀티턴 대화를 이어가면 대화 상태가 자동으로 저장되며, 이후 세션을 종료했다가 다시 실행하더라도 직전까지의 맥락을 불러와 자연스럽게 대화를 지속할 수 있습니다.
또한 이러한 대화 기록은 checkpoint.db의 checkpoints 테이블 내 checkpoint 컬럼에 직렬화된 형태로 저장되며, 실제 파일을 열어보면 해당 값에서 세션별 상태를 직접 확인할 수 있습니다.
Quote현재 세션 ID: 87aa13f0-074f-4b19-a804-c423e3e02da2
안녕하세요. 저는 AI 어시스턴트입니다. 원하시는 요청을 입력해 주세요. (종료하려면 '종료'를 입력하세요.)
User: 요즘 날씨에 가기 좋은 국내 여행지 세 곳 알려줘
[도구 선택]: web_search
[도구 호출]: {'query': '가을 날씨에 가기 좋은 국내 여행지', 'display': 20}
[도구 응답]: content='{"query":"가을 날씨에 가기 좋은 국내 여행지","total":2629216,"items":[...}' name='web_search' tool_call_id='call_aU2RBXFVcomyyT8PBygupAM8'현재 날씨에 가기 좋은 국내 여행지 몇 곳을 다음과 같이 추천드립니다.
- **경기도 가평 아침고요수목원**: 가을에는 다채로운 색깔의 국화와 단풍이 어우러진 모습을 볼 수 있고, 넓은 정원을 산책하며 자연을 만끽할 수 있습니다.
- **제주도 새별오름**: 억새풀이 아름답게 펼쳐진 오름으로 가을의 정취를 느끼기에 아주 좋습니다. 또한 정상에서의 전망이 탁 트여 있어 가슴이 뻥 뚫리는 듯한 느낌을 받을 수 있습니다.
- **강원도 정선 민둥산**: 해발 1119미터의 산으로 정상에는 나무가 없고 참억새 밭이 흐드러지게 피어있어 장관을 이룹니다. 특히 가을에는 억새꽃 축제가 열려 더욱 볼거리가 많습니다.위의 장소들은 모두 가을의 아름다움을 대표하는 곳으로 개인의 취향에 맞게 선택하시면 됩니다. 하지만 여행 전에 해당 지역의 날씨와 교통상황 등 자세한 정보를 먼저 파악하시기를 권해드립니다. 안전하고 즐거운 여행 되시길 바랍니다!
User: 해외는?
[도구 선택]: web_search
[도구 호출]: {'query': '가을 날씨에 가기 좋은 해외 여행지', 'display': 20}
[도구 응답]: content='{"query":"가을 날씨에 가기 좋은 해외 여행지","total":2492973,"items":[...]}' name='web_search' tool_call_id='call_kUgCWjOEuX7A2MHd88P9DNAY'가을 날씨에 가기 좋은 해외 여행지를 다음과 같이 소개합니다.
1. **일본 교토**: 전통적인 일본 문화를 체험하고 아름다운 단풍 구경을 할 수 있습니다. 또한, 선선한 가을 날씨는 축제와 야외 활동을 즐기기에도 좋습니다.
2. **스페인 바르셀로나**: 11월에는 여름철 관광객 수가 줄어들어 더욱 여유로운 관광이 가능합니다. 특히, 가우디 건축물이나 캄프 누 경기장 등 대표적인 관광 명소를 방문하기 좋은 때입니다.
3. **캐나다 밴쿠버**: 캐나다 로키산맥의 가을은 황금빛으로 물든 풍경을 자랑하며, 하이킹과 자연 탐험을 즐기기에 이상적인 장소입니다. 또한, 온화한 기후로 인해 야외 활동하기에 적합한 환경을 제공합니다.
위의 여행지들은 모두 대중적으로 인기있는 여행지로 여행객들에게 많은 볼거리와 즐길 거리를 제공합니다. 하지만 개인의 취향과 선호도에 따라 다른 여행지가 더 적합할 수도 있으니 참고하시기 바랍니다. 또한, 각 국가의 입국 규정과 현지 상황을 미리 확인하여 계획을 세우는 것이 중요합니다.
다음과 같이 새로운 세션을 시작하면, 기존에 저장된 대화 맥락은 참조되지 않으며 시스템 프롬프트와 함께 처음부터 대화를 이어가게 됩니다.
Quote현재 세션 ID: cba6a7da-e4ca-43b9-9972-a42bcac9db3c
User: 내가 맨 처음 물어본 질문 기억해?
죄송하지만, 저는 대화형 인공지능 모델이기 때문에 이전 대화를 저장하거나 기억하는 기능이 없습니다.
따라서 사용자가 처음으로 저에게 무엇을 물어봤는지 알 수가 없습니다. 하지만 현재의 질문에 대해서는 최대한 정확하고 유용한 답변을 제공하기 위해 노력하겠습니다.
어떤 주제에 대해 궁금하신 부분이 있으시면 말씀해 주세요! 제가 알고 있는 지식과 정보를 바탕으로 최선을 다해 도와드리겠습니다.
다음과 같이 기존 세션을 재시작하면, 직전까지 저장된 대화 맥락을 불러와 이전 흐름을 그대로 이어갈 수 있습니다.
Quote현재 세션 ID: 87aa13f0-074f-4b19-a804-c423e3e02da2
User: 내가 맨 처음 물어본 질문 기억해?
네, 제가 처음으로 받았던 질문은 "요즘 날씨에 가기 좋은 국내 여행지 세 곳"에 대한 내용이었습니다. 이후 사용자님께서 해외 여행지도 추가로 문의하셨습니다.
4. 컨텍스트 관리 전략
Stateful 대화는 맥락을 자동으로 이어받는 장점이 있지만, 저장된 히스토리를 모두 모델 입력에 넣다 보면 토큰 수 초과 오류를 마주하게 됩니다. 이때 맥락 관리 및 토큰 최적화 전략이 중요합니다.
다음 전략은 OpenAI Cookbook: Context Engineering를 참고하였습니다. 서비스 성격과 요구 사항에 맞게 전략을 적절히 선택하거나 새롭게 조합해 보시길 바랍니다.
컨텍스트 트리밍(Context Trimming)
최근 N개 턴의 메시지만 유지하는 방식으로, 구현이 단순하고 추가 지연이 발생하지 않는다는 장점이 있습니다. 하지만 N개 이전의 맥락은 모두 잊히며, 최근 턴이라 하더라도 도구 호출 결과가 지나치게 길면 여전히 토큰 수 초과 오류가 발생할 수 있습니다. 여기에서 한 턴(Turn)은 사용자 메시지 1개와 그에 대한 처리 과정(도구 호출, 도구 응답, 최종 답변)을 모두 포함합니다.
다음 이미지는 컨텍스트 트리밍의 동작을 설명합니다. 예를 들어 N=2로 설정하면, 매번 새로운 요청이 들어올 때마다 오래된 대화가 순차적으로 제거되어, 모델은 항상 최근 2개의 턴만 참조하게 됩니다.
다음은 세션별로 턴의 개수를 카운트해 관리하는 예시 코드입니다.
import os import asyncio import uuid from dotenv import load_dotenv from mcp import ClientSession from mcp.client.streamable_http import streamablehttp_client from langchain_mcp_adapters.tools import load_mcp_tools from langchain_naver import ChatClovaX from langchain.agents import create_agent from langchain.messages import SystemMessage, HumanMessage from langchain_core.messages import BaseMessage from langgraph.checkpoint.sqlite.aio import AsyncSqliteSaver MAX_TURNS_TO_KEEP = 5 # 최대 유지할 턴(Turn)의 개수 def trim_messages_by_turn(messages: list[BaseMessage], max_turns: int) -> list[BaseMessage]: """ 대화 기록을 턴(Turn) 단위로 트리밍합니다. SystemMessage를 제외한 최대 max_turns 개의 턴만 유지합니다. 턴은 HumanMessage로 시작하는 묶음으로 간주합니다. Args: messages (list[BaseMessage]): 대화 기록 메시지 리스트 max_turns (int): 유지할 최대 턴 수 """ if not messages: return [] # SystemMessage와 대화 기록을 분리합니다. system_message = messages[0] if isinstance(messages[0], SystemMessage) else None history_messages = messages[1:] if system_message else messages # 턴 시작 인덱스를 기준으로 현재 턴 개수를 계산합니다. turn_start_indices = [ i for i, msg in enumerate(history_messages) if isinstance(msg, HumanMessage) ] current_turn_count = len(turn_start_indices) if current_turn_count <= max_turns: # 현재 턴 개수가 최대 유지할 턴 수 이하이면 그대로 반환합니다. return messages # 유지할 턴의 시작 인덱스를 계산합니다. trim_index = current_turn_count - max_turns keep_messages_start_index = turn_start_indices[trim_index] # 메시지 리스트를 트리밍합니다. trimmed_history = history_messages[keep_messages_start_index:] print(f"\n{max_turns}턴을 초과하여서 트리밍을 수행합니다.\n") # SystemMessage와 트리밍된 대화 기록을 합쳐 반환합니다. return [system_message] + trimmed_history async def main(clova_api_key: str, server_url: str, checkpoint_path: str): """ CLOVA Studio 모델을 LangChain을 통해 호출하고, MCP 서버에 등록된 도구를 연동하여 최종 응답을 생성합니다. 사용자 입력에 따라 새 세션을 시작하거나 이전 세션을 이어갑니다. Args: clova_api_key (str): CLOVA Studio에서 발급받은 API Key server_url (str): 연결할 MCP 서버의 엔드포인트 URL checkpoint_path (str): Checkpoint 저장 경로 """ model = ChatClovaX(model="HCX-005", api_key=clova_api_key) async with streamablehttp_client(server_url) as (read, write, _,): async with ClientSession(read, write) as session: # MCP 서버를 초기화하고 도구 목록을 불러옵니다. await session.initialize() tools = await load_mcp_tools(session) # Checkpointer를 생성합니다. async with AsyncSqliteSaver.from_conn_string(checkpoint_path) as checkpointer: # 에이전트를 생성하고 Checkpointer를 연결합니다. agent = create_agent(model, tools, checkpointer=checkpointer) # 참조할 세션 ID를 입력받습니다. thread_id = input("세션 ID를 입력하세요(새 세션 시작은 Enter):").strip() # 새 세션이면 신규 세션 ID를 생성합니다. if not thread_id: thread_id = str(uuid.uuid4()) config = {"configurable": {"thread_id": thread_id}} print(f"현재 세션 ID: {thread_id}\n") print("안녕하세요. 저는 AI 어시스턴트입니다. 원하시는 요청을 입력해 주세요. (종료하려면 '종료'를 입력하세요.)") system_message = [ SystemMessage(content=( "당신은 친절한 AI 어시스턴트입니다." "사용자의 질문에 대해 신뢰할 수 있는 정보만 근거로 삼아 답변하세요." )) ] while True: user_input = input("\n\nUser: ") if user_input.lower() in ["종료", "exit"]: print("대화를 종료합니다. 이용해 주셔서 감사합니다.") break current_state = {"messages": [HumanMessage(content=user_input)]} try: existing_checkpoint = await checkpointer.aget_tuple(config) if existing_checkpoint is not None: # 기존 대화 기록을 불러옵니다. messages = existing_checkpoint.checkpoint["channel_values"]["messages"] # 대화 기록을 턴 단위로 트리밍합니다. trimmed_messages = trim_messages_by_turn(messages, MAX_TURNS_TO_KEEP) # 트리밍된 메시지에 현재 사용자 메시지를 추가합니다. state = {"messages": trimmed_messages + current_state["messages"]} else: # 새 스레드라면 SystemMessage와 현재 메시지를 모두 추가합니다. state = {"messages": system_message + [HumanMessage(content=user_input)]} # astream_events를 사용하여 스트리밍으로 응답을 처리합니다. async for event in agent.astream_events(state, config=config, version="v1"): kind = event["event"] if kind == "on_chat_model_stream": chunk = event["data"]["chunk"] if chunk.content: print(chunk.content, end="", flush=True) elif kind == "on_tool_start": print(f"\n[도구 선택]: {event['name']}\n[도구 호출]: {event['data'].get('input')}") elif kind == "on_tool_end": print(f"[도구 응답]: {event['data'].get('output')}\n") except Exception as e: print(f"\n요청을 처리하는 중에 오류가 발생했습니다. 오류: {e}") pass if __name__ == "__main__": """ .env 파일에서 CLOVA Studio API Key를 로드하고, MCP 서버의 엔드포인트 URL을 설정한 후 클라이언트를 실행합니다. """ load_dotenv() CLOVA_STUDIO_API_KEY = os.getenv("CLOVA_STUDIO_API_KEY") SERVER_URL = "http://127.0.0.1:8000/mcp/" CHECKPOINT_PATH = "checkpoint.db" asyncio.run(main(CLOVA_STUDIO_API_KEY, SERVER_URL, CHECKPOINT_PATH))
위 스크립트를 실행하면, CLOVA Studio 모델(HCX-005)이 MCP 서버를 통해 등록된 도구와 연동되어 사용자의 질문에 응답합니다. 세션 단위로 대화 상태가 유지되므로 멀티턴 대화를 지속할 수 있으며, 설정한 최대 턴 수를 기준으로 컨텍스트 트리밍이 적용됩니다.
다음은 사용자가 질의를 이어갈 때 트리밍이 발생하는 시점을 보여줍니다. 예를 들어, 최대 턴 수를 5로 설정한 경우, 여섯 번째 요청까지는 직전 5개 턴이 모두 유지되어 트리밍이 발생하지 않습니다. 일곱 번째 요청부터는 가장 오래된 턴이 제거되어, 항상 최근 5개 턴만 참조하도록 트리밍이 수행됩니다.
Quote현재 세션 ID: 77d0d044-5983-4b56-ab1e-da633276186a
안녕하세요. 저는 AI 어시스턴트입니다. 원하시는 요청을 입력해 주세요. (종료하려면 '종료'를 입력하세요.)
User: 안녕
안녕하세요! 저는 CLOVA X입니다.궁금하신 부분이나 도움이 필요한 사항이 있으시면 말씀해 주세요. 제가 알고 있는 지식과 능력으로 최대한 도움을 드리겠습니다.
좋은 하루 보내세요!
User: 요즘 날씨에 가기 좋은 국내 여행지 세 곳 알려줘
[도구 선택]: web_search
[도구 호출]: {'query': '가을 날씨에 가기 좋은 국내 여행지', 'display': 20}
[도구 응답]: content='{"query":"가을 날씨에 가기 좋은 국내 여행지","total":2629216,"items":[...]}' name='web_search' tool_call_id='call_aU2RBXFVcomyyT8PBygupAM8'현재 날씨에 가기 좋은 국내 여행지 몇 곳을 다음과 같이 추천드립니다.
- **경기도 가평 아침고요수목원**: 가을에는 다채로운 색깔의 국화와 단풍이 어우러진 모습을 볼 수 있고, 넓은 정원을 산책하며 자연을 만끽할 수 있습니다.
- **제주도 새별오름**: 억새풀이 아름답게 펼쳐진 오름으로 가을의 정취를 느끼기에 아주 좋습니다. 또한 정상에서의 전망이 탁 트여 있어 가슴이 뻥 뚫리는 듯한 느낌을 받을 수 있습니다.
- **강원도 정선 민둥산**: 해발 1119미터의 산으로 정상에는 나무가 없고 참억새 밭이 흐드러지게 피어있어 장관을 이룹니다. 특히 가을에는 억새꽃 축제가 열려 더욱 볼거리가 많습니다.위의 장소들은 모두 가을의 아름다움을 대표하는 곳으로 개인의 취향에 맞게 선택하시면 됩니다. 하지만 여행 전에 해당 지역의 날씨와 교통상황 등 자세한 정보를 먼저 파악하시기를 권해드립니다. 안전하고 즐거운 여행 되시길 바랍니다!
User: 가을로 이행시 해줘
**가을**가: 가슴이 설레는 계절
을: 을왕리로 떠나볼까요?
가을은 짧아서 아쉽기만 하지만 그만큼 더욱 소중한 시간이기도 합니다. 아름다운 단풍잎처럼 여러분들의 마음속에도 예쁜 추억이 가득 쌓이는 가을이 되셨으면 좋겠습니다.
User: 가을은 왜 가을이야?
가을이라는 이름은 어떻게 생겨났을까요?가을이란 명칭의 유래는 크게 두 가지로 나뉩니다.
- 첫 번째는 고대 순우리말 '갈'에서 비롯되었다는 것입니다. 여기서 '갈'은 농작물을 수확할 때 사용하는 '낫'처럼 구부러진 모습을 의미한다고 합니다. 이는 가을이 곡식과 과일을 거두는 시기이기 때문이라고 해석됩니다.
- 두 번째는 한자 문화권에서 유래했다는 설입니다. 가을의 옛 표현인 '추'(秋) 자는 원래 '벼 화'와 '열매가 많다는 뜻'을 나타내는 것으로 풀이되는 '리'(离) 자를 조합한 단어라고 합니다.
현재 우리가 사용하고 있는 '가을'이라는 말은 고려 H에 등장한 것으로 보아, 이전부터 쓰이던 우리 고유어였던 것으로 보입니다. 이처럼 가을은 풍성한 수확의 시기와 연결되며 자연스럽게 해당 이름이 붙여진 것으로 추측됩니다.
User: 가을은 언제부터 언제까지야?
일반적으로 가을은 9월부터 11월까지라고 이야기하지만, 정확한 기간은 기상청마다 조금씩 다를 수 있습니다. 그러나 대부분의 기상청은 다음과 같이 구분합니다.* **대한민국 기상청**: 9월 1일부터 11월 30일까지
* **미국 국립해양대기청(NOAA)**: 9월 22일부터 12월 21일까지
* **일본 기상청**: 9월 1일부터 11월 30일까지이와 같이 국가별로 약간의 차이가 있지만 대체로 비슷한 기간에 해당합니다. 또한 일반적으로 가을의 시작은 서리가 내리기 시작하는 늦여름부터로 간주되며, 끝은 첫눈이 내리는 초겨울까지로 여겨집니다. 따라서 위 기간보다 더 넓게 가을을 보는 경우도 많습니다.
한편, 천문학적으로는 춘분(3월 21일경)부터 하지(6월 21일경)까지를 봄, 하지를 중심으로 15도 이상 떨어진 기간을 가을이라 하여 9월 23일경부터 12월 21일경까지를 말합니다. 이 때는 태양 황경이 135°부터 225°사이의 중간에 위치하여 가을이라고 합니다.
결국, 가을의 정의는 지역과 문화, 기후 등에 따라 다르게 해석될 수 있다는 점을 기억하시는 게 좋습니다.
User: 아하 고마워
별말씀을요!저는 사용자님께 도움이 될 수 있도록 항상 최선을 다하겠습니다. 언제든지 필요하신 부분이 있으면 말씀해 주세요.
즐거운 하루 보내세요!
User: 그나저나 내가 맨 처음 너한테 보낸 메시지 기억해?
5턴을 초과하여서 트리밍을 수행합니다.
네, 제가 받은 첫 번째 메시지는 "요즘 날씨에 가기 좋은 국내 여행지 세 곳"에 대한 질문이었습니다.
이에 대한 답변을 드리기 위해 웹 검색을 통해 관련 정보를 수집하였고, 이를 바탕으로 다음과 같은 여행지를 추천드렸습니다.
- 경기도 가평 아침고요수목원
- 제주도 새별오름
- 강원도 정선 민둥산위의 내용을 참고하여 사용자님께서 즐거운 여행을 하실 수 있기를 바랍니다. 추가적인 질문이나 요청사항이 있으시면 언제든지 말씀해주세요.
컨텍스트 요약(Context Summarization)
모델을 이용해 이전 대화를 간결한 요약으로 변환하고, 해당 요약 메시지를 히스토리에 삽입하는 방식입니다. 이 방법은 장기 기억을 압축해 보존할 수 있다는 장점이 있지만, 요약 과정에서 세부 정보가 누락될 수 있고, 요약을 갱신할 때마다 모델 호출이 필요하다는 유의 사항이 있습니다.
요약이 실행되는 로직은 다음과 같습니다. 여기에서 한 턴(Turn)은 사용자 메시지 1개와 그에 대한 처리 과정(도구 호출, 도구 응답, 최종 답변)을 모두 포함합니다.
- CONTEXT_TURNS_LIMIT(N): 요약을 실행하는 기준이 되는 값입니다. 누적된 턴의 개수가 이 값보다 클 때 요약을 실행합니다.
- MAX_TURNS_TO_KEEP(M): 요약이 실행된 뒤에도 원문 그대로 유지할 최근 턴 개수입니다. 그 이전 구간은 요약문으로 대체됩니다.
즉, 누적된 턴의 개수가 N을 초과하면 요약이 실행되고, 그 시점에서 최근 M개의 턴만 상태에 유지하며 그 이전 대화는 두 개의 메시지(요약 요청·요약 결과)로 치환됩니다.
HumanMessage: 지금까지의 대화를 요약해 주세요. AIMessage: {요약문}다음 이미지는 컨텍스트 요약이 동작하는 기준과 흐름을 설명합니다.
요약 기준 턴 수(Max N)를 초과하면 모델은 오래된 대화 중 요약 대상 구간(N − M + 1개의 턴)을 압축해 하나의 요약문으로 변환합니다. 이때 요약 요청(HumanMessage)과 요약 결과(AIMessage) 두 메시지가 새로 삽입되고, 그 뒤로는 보존 대상 구간(최근 M개의 사용자 턴)이 원문 그대로 유지됩니다. 이때, 요약이 요청되는 시점에 새로 들어오는 사용자 입력이 함께 포함되므로, 실제 요약 대상 범위는 N − M + 1개의 턴으로 계산됩니다.
다음은 세션별로 컨텍스트를 요약해 관리하는 예시 코드입니다.
import os import asyncio import uuid from dotenv import load_dotenv from typing import List, Optional, Tuple from mcp import ClientSession from mcp.client.streamable_http import streamablehttp_client from langchain_mcp_adapters.tools import load_mcp_tools from langchain_naver import ChatClovaX from langchain.agents import create_agent from langchain.messages import SystemMessage, HumanMessage, AIMessage from langchain_core.messages import BaseMessage from langgraph.checkpoint.sqlite.aio import AsyncSqliteSaver CONTEXT_TURNS_LIMIT = 5 # 요약을 시작할 기준이 되는 턴(Turn)의 개수 MAX_TURNS_TO_KEEP = 2 # 최대 유지할 턴(Turn)의 개수 SUMMARY_REQUEST_CONTENT = "지금까지의 대화를 요약해 주세요." SUMMARY_PROMPT = ( "당신은 친절한 AI 어시스턴트입니다. 지금까지의 대화를 간결하게 요약하세요.\n" "요약에는 중요한 정보, 사용자 요청, 도구 호출 내역 단계가 포함되어야 합니다.\n" ) async def summarize_messages_by_turn(messages: List[BaseMessage], max_turns: int, context_limit: int, model: ChatClovaX, summary_prompt: str = SUMMARY_PROMPT,) -> Tuple[List[BaseMessage], bool]: # 반환 타입: (메시지 리스트, 요약 발생 여부) """ 대화 기록을 턴(Turn) 단위로 요약합니다. SystemMessage를 제외한 최대 max_turns 개의 턴만 유지합니다. 턴은 HumanMessage로 시작하는 묶음으로 간주합니다. 단, 요약은 현재 대화 기록의 사용자 턴 수가 context_limit를 초과할 때만 수행합니다. Args: messages (List[BaseMessage]): 대화 기록 메시지 리스트 max_turns (int): 유지할 최대 턴 수 context_limit (int): 요약을 시작할 기준이 되는 턴 수 model (ChatClovaX): 요약에 사용할 LLM 모델 summary_prompt (str): 요약에 사용할 프롬프트 """ if not messages: return [], False # SystemMessage와 대화 기록을 분리합니다. system_message: Optional[BaseMessage] = ( messages[0] if isinstance(messages[0], SystemMessage) else None ) # SystemMessage는 복사본을 만들어 메타데이터를 초기화합니다. if system_message: system_message = system_message.model_copy(deep=True) system_message.response_metadata = {} history_messages = messages[1:] if system_message else messages # 마지막 요약 지점을 찾습니다. last_synthetic_idx = -1 for idx, msg in enumerate(history_messages): if isinstance(msg, HumanMessage) and ( msg.additional_kwargs.get("synthetic") or getattr(msg, "content", "").strip() == SUMMARY_REQUEST_CONTENT ): last_synthetic_idx = idx # 요약 대상 범위를 결정합니다. if last_synthetic_idx != -1: target_messages = history_messages[last_synthetic_idx + 2 :] # 요청+응답 2개 이후 else: target_messages = history_messages # 실제 사용자 턴 개수를 계산합니다. turn_start_indices = [] for idx, msg in enumerate(target_messages): if isinstance(msg, HumanMessage) and not msg.additional_kwargs.get("synthetic"): turn_start_indices.append(idx) current_turn_count = len(turn_start_indices) # 요약 필요하지 않으면 원본 메시지를 그대로 반환합니다. if current_turn_count <= context_limit: return messages, False # 요약 경계 인덱스를 계산합니다. trim_index = current_turn_count - max_turns summary_boundary_in_target = turn_start_indices[trim_index] # 요약 대상 메시지를 준비합니다. summarize_messages_for_input = target_messages[:summary_boundary_in_target] conversation_snippets = [] if last_synthetic_idx != -1: old_synthetic_summary = history_messages[last_synthetic_idx + 1] prev_summary_text = getattr(old_synthetic_summary, "content", "").strip() if prev_summary_text: conversation_snippets.append( f"Previous Context Summary: {prev_summary_text}" ) for m in summarize_messages_for_input: content = (getattr(m, "content", "") or "").strip() if not content: continue role_label = "User" if isinstance(m, HumanMessage) else "Assistant" conversation_snippets.append(f"{role_label}: {content}") if not conversation_snippets: return messages, False summary_input_messages = [ SystemMessage(content=summary_prompt), HumanMessage(content="\n\n".join(conversation_snippets)), ] try: summary_response: BaseMessage = await model.ainvoke(summary_input_messages) summary_text = getattr(summary_response, "content", "").strip() except Exception as e: print(f"\n요약 호출 중 오류가 발생했습니다. 전체 기록을 유지합니다. 오류: {e}\n") return messages, False # 요약본과 함께 새로운 대화 상태를 구성합니다. shadow_user = HumanMessage( content=SUMMARY_REQUEST_CONTENT, additional_kwargs={"synthetic": True} ) synthetic_summary = AIMessage( content=summary_text, additional_kwargs={"synthetic": True} ) suffix_messages = target_messages[summary_boundary_in_target:] cleaned_suffix_messages = [] for msg in suffix_messages: new_msg = msg.model_copy(deep=True) new_msg.response_metadata = {} cleaned_suffix_messages.append(new_msg) new_history = [shadow_user, synthetic_summary] + cleaned_suffix_messages final_messages = ([system_message] + new_history) if system_message else new_history return final_messages, True def prune_to_last_summary(messages: List[BaseMessage]) -> List[BaseMessage]: """ Checkpointer에서 hydrate한 전체 메시지 중 마지막 요약 이후만 남겨 과거 히스토리 재유입을 차단합니다. Args: messages (List[BaseMessage]): 전체 메시지 리스트 """ if not messages: return messages system = messages[0] if isinstance(messages[0], SystemMessage) else None history = messages[1:] if system else messages base = 1 if system else 0 last_pair_start = -1 for i in range(len(history) - 1): h = history[i] a = history[i + 1] if isinstance(h, HumanMessage) and isinstance(a, AIMessage): if ( h.additional_kwargs.get("synthetic") or (getattr(h, "content", "").strip() == SUMMARY_REQUEST_CONTENT) ) and a.additional_kwargs.get("synthetic"): last_pair_start = i if last_pair_start == -1: return messages cut_pos = base + last_pair_start pruned = ([system] if system else []) + messages[cut_pos:] return pruned async def main(clova_api_key: str, server_url: str, checkpoint_path: str): """ CLOVA Studio 모델을 LangChain을 통해 호출하고, MCP 서버에 등록된 도구를 연동하여 최종 응답을 생성합니다. 사용자 입력에 따라 새 세션을 시작하거나 이전 세션을 이어갑니다. Args: clova_api_key (str): CLOVA Studio에서 발급받은 API Key server_url (str): 연결할 MCP 서버의 엔드포인트 URL checkpoint_path (str): Checkpoint 저장 경로 """ model = ChatClovaX(model="HCX-005", api_key=clova_api_key) async with streamablehttp_client(server_url) as (read, write, _,): async with ClientSession(read, write) as session: # MCP 서버를 초기화하고 도구 목록을 불러옵니다. await session.initialize() tools = await load_mcp_tools(session) # Checkpointer를 생성합니다. async with AsyncSqliteSaver.from_conn_string(checkpoint_path) as checkpointer: # 에이전트를 생성하고 Checkpointer를 연결합니다. agent = create_agent(model, tools, checkpointer=checkpointer) # 참조할 세션 ID를 입력받습니다. thread_id = input("세션 ID를 입력하세요(새 세션 시작은 Enter):").strip() # 새 세션이면 신규 세션 ID를 생성합니다. if not thread_id: thread_id = str(uuid.uuid4()) config = {"configurable": {"thread_id": thread_id}} print(f"현재 세션 ID: {thread_id}\n") print( "안녕하세요. 저는 AI 어시스턴트입니다. 원하시는 요청을 입력해 주세요. (종료하려면 '종료'를 입력하세요.)" ) system_message = [ SystemMessage(content=( "당신은 친절한 AI 어시스턴트입니다." "사용자의 질문에 대해 신뢰할 수 있는 정보만 근거로 삼아 답변하세요." )) ] while True: user_input = input("\n\nUser: ") if user_input.lower() in ["종료", "exit"]: print("대화를 종료합니다. 이용해 주셔서 감사합니다.") break current_state = {"messages": [HumanMessage(content=user_input)]} try: existing_checkpoint = await checkpointer.aget_tuple(config) if existing_checkpoint is not None: # 기존 대화 기록을 불러옵니다. messages: List[BaseMessage] = existing_checkpoint.checkpoint["channel_values"]["messages"] # 과거 히스토리 재유입 차단을 위해 마지막 요약 이후만 남깁니다. messages = prune_to_last_summary(messages) # 턴 단위로 컨텍스트 요약을 적용합니다. summarized_messages, is_summarized = await summarize_messages_by_turn( messages, MAX_TURNS_TO_KEEP, CONTEXT_TURNS_LIMIT, model ) if is_summarized: # 요약이 발생하면 요약본과 함께 현재 사용자 메시지를 추가합니다. state = {"messages": summarized_messages + current_state["messages"]} else: # 요약이 없으면 프루닝된 메시지에 현재 사용자 메시지만 추가합니다. state = {"messages": messages + current_state["messages"]} else: # 새 스레드라면 SystemMessage와 재 메시지를 모두 추가합니다. state = {"messages": system_message + [HumanMessage(content=user_input)]} # print(f"[state 확인] {state['messages']}\n") # astream_events를 사용하여 스트리밍으로 응답을 처리합니다. async for event in agent.astream_events(state, config=config, version="v1"): kind = event["event"] if kind == "on_chat_model_stream": chunk = event["data"]["chunk"] if chunk.content: print(chunk.content, end="", flush=True) elif kind == "on_tool_start": print( f"\n[도구 선택]: {event['name']}\n[도구 호출]: {event['data'].get('input')}" ) elif kind == "on_tool_end": print(f"[도구 응답]: {event['data'].get('output')}\n") except Exception as e: print(f"\n요청을 처리하는 중에 오류가 발생했습니다. 오류: {e}") pass if __name__ == "__main__": """ .env 파일에서 CLOVA Studio API Key를 로드하고, MCP 서버의 엔드포인트 URL을 설정한 후 클라이언트를 실행합니다. """ load_dotenv() CLOVA_STUDIO_API_KEY = os.getenv("CLOVA_STUDIO_API_KEY") SERVER_URL = "http://127.0.0.1:8000/mcp/" CHECKPOINT_PATH = "checkpoint.db" asyncio.run(main(CLOVA_STUDIO_API_KEY, SERVER_URL, CHECKPOINT_PATH))
위 스크립트를 실행하면, CLOVA Studio 모델(HCX-005)이 MCP 서버를 통해 등록된 도구와 연동되어 사용자의 질문에 응답합니다. 세션 단위로 대화 상태가 유지되므로 멀티턴 대화를 지속할 수 있으며, 설정된 요약 실행 임계치(N)와 최대 턴 수(M)를 기준으로 컨텍스트 요약이 자동 적용됩니다.
다음은 누적된 대화 상태를 보여줍니다. 예를 들어, N=5, M=2로 설정한 경우 여섯 번째 요청까지는 이전 5개 턴이 모두 유지되어 요약이 실행되지 않습니다.
Quote[SystemMessage(content='당신은 친절한 AI 어시스턴트입니다.사용자의 질문에 대해 신뢰할 수 있는 정보만 근거로 삼아 답변하세요.', additional_kwargs={}, response_metadata={}, id='597ef94e-fab0-479f-bf7d-6377e98ec8de'), HumanMessage(content='안녕', additional_kwargs={}, response_metadata={}, id='6616cce9-a8a0-42dd-8e33-4065183c55c4'), AIMessage(content='안녕하세요! 저는 CLOVA X입니다.\n\n궁금하신 부분이나 도움이 필요하시면 언제든지 말씀해 주세요. 제가 알고 있는 지식과 능력으로 최대한 도움을 드리겠습니다. \n\n좋은 하루 보내세요!', additional_kwargs={'thinking_content': ''}, response_metadata={'finish_reason': 'stop', 'model_name': 'HCX-005'}, id='run--f5eab89f-80d4-4953-8f0c-2c73ca7f325c', usage_metadata={'input_tokens': 34, 'output_tokens': 41, 'total_tokens': 75, 'input_token_details': {}, 'output_token_details': {}}), HumanMessage(content='요즘 날씨에 가기 좋은 국내 여행지 세 곳 알려줘', additional_kwargs={}, response_metadata={}, id='f39488db-614c-4c96-aae0-25abf3466ffc'), AIMessage(content='', additional_kwargs={'tool_calls': [{'index': 0, 'id': 'call_xup7wnfp3VcnM9eLpKg5GzI5', 'function': {'arguments': '{"query": "가을 날씨에 가기 좋은 국내 여행지", "display": 20}', 'name': 'web_search'}, 'type': 'function'}], 'thinking_content': ''}, response_metadata={'finish_reason': 'tool_calls', 'model_name': 'HCX-005'}, id='run--b692aefd-8f87-4ca5-8710-c6d1288fe021', tool_calls=[{'name': 'web_search', 'args': {'query': '가을 날씨에 가기 좋은 국내 여행지', 'display': 20}, 'id': 'call_xup7wnfp3VcnM9eLpKg5GzI5', 'type': 'tool_call'}], usage_metadata={'input_tokens': 106, 'output_tokens': 44, 'total_tokens': 150, 'input_token_details': {}, 'output_token_details': {}}), ToolMessage(content='{"query":"가을 날씨에 가기 좋은 국내 여행지","total":2641945,"items":[...]}', name='web_search', id='cad16903-d644-4b2b-ac6e-e342c0808938', tool_call_id='call_xup7wnfp3VcnM9eLpKg5GzI5'), AIMessage(content='가을 날씨에 가기 좋은 국내 여행지 세 곳을 다음과 같이 추천드립니다.\n\n\n1. 제주도: 제주는 가을에도 따뜻한 날씨와 아름다운 경치를 제공합니다. 특히 가을에는 억새풀이 유명한 산굼부리와 섭지코스를 방문해 보시는 것을 추천드립니다. 또한 우도와 마라도 등 섬 여행도 인기가 많습니다.\n\n2. 경주: 경주는 역사와 문화가 살아 숨쉬는 도시로, 가을에는 노란 은행나무와 붉은 단풍이 아름다운 경관을 자아냅니다. 첨성대, 불국사 등의 역사 유적지와 함께 동궁과 월지에서 산책을 즐겨보세요.\n\n3. 강원도 설악산 국립공원: 가을철 단풍이 유명한 곳으로 케이블카를 타고 권금성을 올라가면 울산바위와 멋진 가을 풍경을 감상하실 수 있습니다. 신흥사와 흔들바위 코스는 비교적 쉬운 트래킹 코스로 남녀노소 가볍게 걸으며 단풍을 즐기기에 좋습니다.\n\n위의 여행지들은 가을의 아름다운 자연과 문화를 경험할 수 있는 대표적인 장소들입니다. 하지만 개인의 취향에 따라 선호하는 여행지가 다를 수 있으므로, 자신에게 맞는 여행지를 선택하여 즐거운 여행을 즐기시길 바랍니다. 또한 여행 전에는 해당 지역의 날씨와 교통 상황 등을 미리 확인하시는 것이 좋습니다.', additional_kwargs={'thinking_content': ''}, response_metadata={'finish_reason': 'stop', 'model_name': 'HCX-005'}, id='run--69f86fd3-e219-4543-9816-9095b90c4124', usage_metadata={'input_tokens': 3102, 'output_tokens': 279, 'total_tokens': 3381, 'input_token_details': {}, 'output_token_details': {}}), HumanMessage(content='가을로 이행시 해줘', additional_kwargs={}, response_metadata={}, id='e3d8abd3-7b45-4347-9fb3-0c272ba69165'), AIMessage(content='가을로 이행시를 지어드리겠습니다.\n\n**가**: 가슴이 뛰는 계절,\n**을**: 을왕리로 떠나요!\n\n아름다운 가을 바다와 맛있는 조개구이를 먹으며 행복한 시간을 보낼 수 있어 많은 사람들에게 사랑받는 여행지 입니다. ', additional_kwargs={'thinking_content': ''}, response_metadata={'finish_reason': 'stop', 'model_name': 'HCX-005'}, id='run--82e7f174-4818-427a-ab57-3af50381910f', usage_metadata={'input_tokens': 3399, 'output_tokens': 61, 'total_tokens': 3460, 'input_token_details': {}, 'output_token_details': {}}), HumanMessage(content='가을은 왜 가을이야?', additional_kwargs={}, response_metadata={}, id='bf7fdcf1-a7ed-4522-9a23-86dfe316e374'), AIMessage(content="'가을'이라는 이름은 어떻게 생겨났을까요?\n\n가을의 명칭 유래에 대한 여러 가지 설이 있지만 대표적으로는 다음 두 가지 이야기가 널리 알려져 있습니다.\n\n- **농사의 마지막 단계**: 농작물을 수확하며 한 해 농사를 마무리 짓는 시기로 접어들면서 ‘갓길’ 또는 ‘갋다’라는 단어로부터 파생되었다는 설입니다.\n\n- **추수한 곡식 저장**: 추수한 곡식을 저장한다는 의미의 '곶감'에서 음운 변화가 일어나 ‘가을’이 되었다는 주장입니다.\n\n이러한 유래 외에도 다양한 학설이 있으나 위 두 가지 설이 가장 많이 인용되고 있습니다. ", additional_kwargs={'thinking_content': ''}, response_metadata={'finish_reason': 'stop', 'model_name': 'HCX-005'}, id='run--55e431fe-fc8e-48ff-b482-90f60342bc80', usage_metadata={'input_tokens': 3476, 'output_tokens': 138, 'total_tokens': 3614, 'input_token_details': {}, 'output_token_details': {}}), HumanMessage(content='가을은 언제부터 언제까지야?', additional_kwargs={}, response_metadata={}, id='957d8048-4110-4b22-934f-3115d997eccf'), AIMessage(content='일반적으로 가을은 다음과 같이 구분됩니다.\n\n - 봄(3월~5월): 따뜻한 날씨와 함께 꽃이 피고 새싹이 돋아나는 계절입니다.\n - 여름(6월~8월): 더운 날씨가 지속되면서 휴가를 즐기기 좋은 계절입니다.\n - 가을(9월~11월): 선선한 날씨와 함께 단풍이 들고 수확의 계절이라고도 합니다.\n - 겨울(12월~2월): 추운 날씨와 눈이 내리는 계절입니다.\n\n우리나라 기상청에서도 이와 비슷하게 9월부터 11월까지를 가을로 보고 있으며, 이 기간 동안 기온이 점차 내려가고 단풍이 드는 모습을 볼 수 있습니다. 따라서 이러한 특징을 고려하면 대략적으로 9월 초부터 11월 말까지를 가을로 생각하시면 됩니다. ', additional_kwargs={'thinking_content': ''}, response_metadata={'finish_reason': 'stop', 'model_name': 'HCX-005'}, id='run--03c0dede-649d-4bf6-8cee-ccdd6032e60c', usage_metadata={'input_tokens': 3632, 'output_tokens': 162, 'total_tokens': 3794, 'input_token_details': {}, 'output_token_details': {}}), HumanMessage(content='아하 고마워', additional_kwargs={}, response_metadata={})]
일곱 번째 요청부터는 컨텍스트 요약이 실행되어, 이전 대화의 맥락이 두 개의 메시지(요약 요청·요약 결과)로 대체되고, 최근 두 개의 사용자 턴만 원문으로 유지됩니다.
Quote[SystemMessage(content='당신은 친절한 AI 어시스턴트입니다.사용자의 질문에 대해 신뢰할 수 있는 정보만 근거로 삼아 답변하세요.', additional_kwargs={}, response_metadata={}, id='597ef94e-fab0-479f-bf7d-6377e98ec8de'), HumanMessage(content='지금까지의 대화를 요약해 주세요.', additional_kwargs={'synthetic': True}, response_metadata={}), AIMessage(content="요약:\n1. Assistant는 가을에 가기 좋은 국내 여행지 세 곳으로 제주, 경주, 설악산을 추천함.\n2. User의 요청으로 '가을로 이행시'를 제공함.\n3. 마지막으로 '가을'이라는 이름의 유래에 대해 설명함.", additional_kwargs={'synthetic': True}, response_metadata={}), HumanMessage(content='가을은 언제부터 언제까지야?', additional_kwargs={}, response_metadata={}, id='957d8048-4110-4b22-934f-3115d997eccf'), AIMessage(content='일반적으로 가을은 다음과 같이 구분됩니다.\n\n - 봄(3월~5월): 따뜻한 날씨와 함께 꽃이 피고 새싹이 돋아나는 계절입니다.\n - 여름(6월~8월): 더운 날씨가 지속되면서 휴가를 즐기기 좋은 계절입니다.\n - 가을(9월~11월): 선선한 날씨와 함께 단풍이 들고 수확의 계절이라고도 합니다.\n - 겨울(12월~2월): 추운 날씨와 눈이 내리는 계절입니다.\n\n우리나라 기상청에서도 이와 비슷하게 9월부터 11월까지를 가을로 보고 있으며, 이 기간 동안 기온이 점차 내려가고 단풍이 드는 모습을 볼 수 있습니다. 따라서 이러한 특징을 고려하면 대략적으로 9월 초부터 11월 말까지를 가을로 생각하시면 됩니다. ', additional_kwargs={'thinking_content': ''}, response_metadata={}, id='run--03c0dede-649d-4bf6-8cee-ccdd6032e60c', usage_metadata={'input_tokens': 3632, 'output_tokens': 162, 'total_tokens': 3794, 'input_token_details': {}, 'output_token_details': {}}), HumanMessage(content='아하 고마워', additional_kwargs={}, response_metadata={}, id='00a3058f-c0b2-4d92-99a4-ec644a529d09'), AIMessage(content='별말씀을요!\n\n언제든지 궁금한 점이나 도움이 필요한 사항이 있으시면 편하게 문의해주세요. 최선을 다해 도와드리겠습니다.\n\n즐거운 하루 보내세요!', additional_kwargs={'thinking_content': ''}, response_metadata={}, id='run--24b80839-4297-4530-a4d9-3eecb0014c36', usage_metadata={'input_tokens': 3808, 'output_tokens': 39, 'total_tokens': 3847, 'input_token_details': {}, 'output_token_details': {}}), HumanMessage(content='환절기 건강 지키기 팁 알려줘', additional_kwargs={}, response_metadata={})]
마무리
2부에서는 세션 기반의 Stateful 대화 흐름을 구현하는 과정을 살펴보았습니다. 대화 상태를 저장하고 이어받는 방식, 그리고 컨텍스트를 효율적으로 관리하기 위한 전략을 실제 코드와 함께 구현해 보았는데요. 이를 통해 MCP와 HyperCLOVA X 모델을 함께 활용하면 대화의 맥락을 지속적으로 이해하고 기억하는 대화형 시스템을 설계할 수 있음을 확인했습니다.
다음 3부에서는 인증 구조를 통합하여 HyperCLOVA X 모델과 안전하게 연동되는 개인화 MCP 서버를 구현해 보겠습니다.
MCP 실전 쿡북 4부작 시리즈
✔︎ (1부) LangChain에서 네이버 검색 도구 연결하기 링크
✔︎ (2부) 세션 관리와 컨텍스트 유지 전략
✔︎ (3부) OAuth 인증이 통합된 MCP 서버 구축하기 링크
✔︎ (4부) 운영과 확장을 위한 다양한 팁 링크
-
들어가며
최근 LLM 기반 서비스의 아키텍처는 외부 도구와 API를 유기적으로 통합하는 방향으로 빠르게 발전하고 있습니다. 이러한 흐름 속에서 등장한 Model Context Protocol(MCP)은 LLM이 외부 서비스와 상호작용하는 방식을 정의한 표준 프로토콜로, 기존 Function calling보다 유연하고 확장 가능한 에이전트 구조를 지원합니다.
또한 Slack, Notion 등 다양한 서비스가 자체 Remote MCP 서버를 제공하기 시작했고, MCP 서버를 손쉽게 생성할 수 있는 빌더와 클라이언트 도구들도 활발히 개발되면서 MCP는 하나의 생태계로 자리잡아가고 있습니다.
본 쿡북은 이러한 흐름에 맞춰, CLOVA Studio에서 제공하는 모델을 MCP 서버와 연동해 에이전트 환경에서 활용하는 방법을 중심으로, 실무에 바로 적용할 수 있는 구현 가이드와 실전 팁을 함께 제공합니다.
MCP 실전 쿡북 4부작 시리즈
✔︎ (1부) LangChain에서 네이버 검색 도구 연결하기
✔︎ (2부) 세션 관리와 컨텍스트 유지 전략 링크
✔︎ (3부) OAuth 인증이 통합된 MCP 서버 구축하기 링크
✔︎ (4부) 운영과 확장을 위한 다양한 팁 링크
MCP 통신 방식
MCP의 기본 개념과 실행 흐름은 기존 AI 어시스턴트 제작 레시피: FastMCP로 도구 연결하기에서 상세하게 다루었으니 참고 부탁드립니다.
MCP는 호스트(Host), 서버(Server), 클라이언트(Client)가 역할을 나눠 동작합니다. 호스트는 MCP 서버의 실행 환경을 관리하며, 서버는 도구를 정의하고 클라이언트의 요청에 따라 실제 로직을 수행합니다. 클라이언트는 서버를 열고 등록된 도구를 조회하거나 호출하는 역할을 맡습니다. 이렇게 세 구성 요소가 서로 연결되면, 클라이언트와 서버 간의 데이터 교환이 이루어집니다.
이때 MCP에서 데이터를 주고받는 통신 방식은 크게 세 가지로 구분됩니다.
Stdio(Standard I/O)는 표준 입출력 채널을 통해 데이터를 주고받습니다. 설정이 간단하고 빠르지만, 네트워크를 통한 원격 통신이 불가능해 로컬 환경에 한정됩니다. HTTP/SSE(Server-Sent Events)는 HTTP 요청으로 명령을 보내고, SSE 채널을 통해 실시간으로 응답을 받는 구조입니다. 다만, 연결이 끊겼을 때 복구가 어렵고, 최신 프로토콜과의 호환성에 제약이 있어 사용이 권장되지 않습니다. Streamable HTTP는 기존 HTTP 구조를 유지하면서 스트리밍 전송을 지원하는 방식입니다. 단일 엔드포인트에서 요청, 응답, 스트리밍을 모두 처리할 수 있고, 안정성과 확장성이 높습니다. 현재 MCP 공식 스펙에서도 해당 방식을 권장하고 있습니다.
따라서 본 쿡북에서는 Streamable HTTP 방식을 기준으로 MCP 서버와 클라이언트 간 통신을 구성하여, 안정적이고 확장 가능한 에이전트 구현 방법을 살펴볼 예정입니다.
기존 도구와 MCP의 차이점
기존의 Function calling과 MCP는 모두 LLM이 외부 도구(API 등)를 활용해 작업을 수행할 수 있도록 해 준다는 공통점을 지니지만, 구조적 설계와 기능적 역할의 차이로 인해 MCP는 AI와 외부 도구를 보다 유연하게 연동할 수 있는 표준 인터페이스로 주목받고 있습니다. 두 방식을 비교하여 구조적 차이점과 각 방식의 적합한 적용 영역을 살펴보겠습니다.
1. 도구 연동 방식
Function calling에서는 도구가 애플리케이션 프로세스 내부에 내장되어 있습니다. 모델 입력에는 함수 스키마 명세가 포함되며, 모델은 이를 기반으로 호출 명세(JSON)를 생성합니다. 반면 MCP는 도구를 외부 서버 형태로 분리하여 모듈화된 구조를 갖습니다. 클라이언트는 MCP 서버와 통신하면서 호출 가능한 도구와 스키마를 조회하고, 그중 적절한 도구를 동적으로 선택해 호출합니다.
2. 컨텍스트 및 상태 관리
Function calling은 일반적으로 호출 단위가 독립적이므로, 컨텍스트나 상태 유지가 필요할 경우 애플리케이션 측에서 별도로 관리해야 합니다. 반면 MCP는 프로토콜 수준에서 세션 개념을 지원합니다. 클라이언트와 서버가 동일 세션 내 요청을 구분하고, 세션 단위로 상태나 컨텍스트를 유지할 수 있습니다.
3. 권한 제어 및 보안 관리
Function calling에서는 도구 호출과 상태 관리가 모두 애플리케이션 내부에서 이루어지므로, 권한 제어나 인증 로직도 해당 애플리케이션에서 직접 처리해야 합니다. 반면 MCP는 도구가 외부 서버로 분리되어 있기 때문에, 클라이언트–서버 간 호출이 네트워크 경계를 넘을 수 있습니다. 이 과정에서 MCP 서버는 각 도구별 인증 정책과 권한 제어를 서버 단위에서 통합적으로 관리할 수 있으며, OAuth 2.1 기반 인증 흐름 등 표준화된 보안 모델을 적용할 수 있습니다.
4. 적용 가능 영역
Function calling은 명확한 태스크 중심의 단일 호출 환경에 적합합니다. 예를 들어 데이터 추출, 포맷 변환, 단순 분류, 외부 API 조회 등 상태 유지가 필요 없고 지연 시간(latency)이 중요한 경우, Function calling이 빠르고 효율적인 선택일 수 있습니다. 또한 권한 관리 로직이 애플리케이션 내부에 일원화되어 있어 구현 복잡도가 낮습니다. 반면 MCP는 복잡한 프로세스, 다단계 대화, 혹은 도구가 자주 변경되는 환경에서 강점을 발휘합니다. 예를 들어 고객 상담 도중 “주문 확인해 줘” → “언제 배송돼?”처럼 문맥이 이어지는 대화에서는 MCP 서버가 세션 단위로 주문 정보를 유지함으로써 자연스러운 연속 대화가 가능합니다. 또한 도구가 별도의 서버로 분리되어 있으므로 업데이트나 교체가 용이하며, 다양한 시스템과 안전하게 연동할 수 있습니다.
이렇게 Function calling과 MCP의 구조적 차이점으로 인해 MCP가 복잡한 상태 기반 대화와 동적 도구 활용이 필요한 서비스 환경에 강점을 가진다는 점을 확인했습니다. 지금부터 이어지는 쿡북에서는 이러한 강점을 실제 개발 환경에서 구현할 수 있도록 MCP 핵심 개념부터, 서버와 클라이언트 구현, 세션 기반 컨텍스트 관리, 인증 및 접근 제어를 실전 예제와 함께 다룹니다.
쿡북의 목표와 범위
본 쿡북은 단순한 개념 설명이나 데모 시연을 넘어서, 실제 비즈니스와 개발 환경에서 바로 활용할 수 있는 MCP 학습 자료를 제공하는 것을 목표로 합니다.
-
네이버 검색 API 연동 실습: 네이버 개발자 센터의 Open API를 활용해 MCP 서버를 직접 구성하며, MCP가 어떤 방식으로 외부 서비스를 표준화해 연결하는지 이해합니다.
- Remote MCP 연동 실습: Remote MCP 서버(Playwright MCP)를 추가로 연동하여, 외부 브라우저 자동화 도구를 통합하고 기능을 확장하는 방법을 실습합니다.
- Stateful 대화 구현: 단일 요청이 아닌, 이전 대화의 컨텍스트를 유지하며 이어지는 세션 기반 대화 구조를 구현해 봅니다.
-
표준 인증 적용: OAuth 기반 인증 방식을 실습하여, 실제 서비스 연동 과정에서 필요한 인증 요구 사항을 예제와 함께 구현해 봅니다.
- 실전 팁과 활용 노하우: MCP를 실제 프로젝트에 적용할 때 도움이 되는 서버 디버깅, 도구 작성 요령 등 실무 중심의 팁을 제공합니다.
1. 사전 준비 사항
본 섹션에서는 예제를 실행하기 위해 필요한 도구 및 환경에 대한 준비 과정을 다룹니다.
CLOVA Studio API 준비
CLOVA Studio에서는 Chat Completions, 임베딩을 비롯한 주요 API에 대해 OpenAI API와의 호환성을 지원합니다. 본 예제에서는 OpenAI 호환 API 중 Chat Completions 엔드포인트(/chat/completions)를 활용하며, 상세 호환 정보는 OpenAI 호환성 가이드를 참고하시기 바랍니다.
또한, 해당 API 호출하려면 CLOVA Studio에서 발급받은 API 키가 필요합니다. API 키 발급 방법은 CLOVA Studio API 가이드에서 확인할 수 있습니다.
네이버 개발자 센터 이용 등록
본 예제에서는 네이버 개발자 센터에서 제공하는 OpenAPI를 활용합니다.
API 호출을 위해서는 먼저 네이버 개발자 센터에서 애플리케이션을 등록하고 인증 정보를 발급받아야 합니다.
-
네이버 개발자 센터에서 애플리케이션을 등록합니다.
- 애플리케이션을 등록하는 방법은 애플리케이션 등록을 참고해 주세요.
-
애플리케이션 등록 시 사용 API는 '검색'을 선택합니다.
- 3부에서는 '네이버 로그인', '캘린더'가 추가로 사용됩니다. 필요에 따라 다른 항목도 함께 선택하세요.
-
API 호출에 필요한 클라이언트 아이디와 클라이언트 시크릿 정보를 확인합니다.
- 클라이언트 아이디와 클라이언트 시크릿 확인을 참고해 주세요.
Quote네이버 API 사용 시 네이버 개발자 센터의 이용 약관을 준수해야 합니다. 약관 준수 의무를 위반하여 발생한 모든 법적 책임은 사용자에게 있습니다. 네이버 API를 사용하는 방법에 대한 자세한 설명은 네이버 개발자 센터 API 공통 가이드를 참고해 주십시오.
파이썬 개발 환경 준비
이 예제를 실행하려면 Python 3.10 이상의 개발 환경이 필요합니다. 가상환경을 구성하고 .env 파일에 API 키를 등록한 뒤, 필요한 패키지를 설치합니다.
프로젝트 구성
프로젝트의 전체 파일 구조는 다음과 같습니다. Python 버전은 3.10 이상, 3.13 미만입니다.
mcp_cookbook_part1/ ├── server.py ├── client/ │ ├── basic_client.py │ ├── chat_client.py │ └── advanced_client.py └── .env환경 변수 설정
루트 디렉터리에 .env 파일을 생성한 뒤, 앞서 발급받은 API Key를 다음과 같이 입력하고 저장합니다. 이때 따옴표 없이 값을 작성해야 하며, VS Code에서 실행할 경우 설정에서 Use Env File 옵션이 활성화되어 있는지 확인하세요.
CLOVA_STUDIO_API_KEY=YOUR_API_KEY NAVER_CLIENT_ID=YOUR_CLIENT_ID NAVER_CLIENT_SECRET=YOUR_CLIENT_SECRET패키지 설치
프로젝트에 필요한 패키지 목록은 아래 다운로드 링크에서 확인할 수 있습니다. 해당 내용을 복사해 루트 디렉터리에 requirements.txt 파일로 저장하세요.
루트 디렉터리에서 터미널을 실행하여 다음과 같이 예제 실행에 필요한 패키지를 설치합니다. 가상환경 설치를 권장합니다.
# 1. 파이썬 가상환경 생성 python -m venv .venv # 2. 가상환경 활성화 (macOS/Linux) source .venv/bin/activate # (Windows) # .venv/Scripts/activate.ps1 # 3. 패키지 설치 pip install -r requirements.txt
시나리오 개요
실습에서 다루는 예제는 다음과 같습니다. MCP를 통해 LLM에 네이버 검색 도구를 연계함으로써, 사용자에게 실시간·최신성이 보장되는 응답을 제공할 수 있도록 합니다.
2. MCP 서버
본 섹션에서는 MCP 서버를 구성하고 실행하는 방법을 설명합니다.
MCP 서버 개념
MCP 서버는 언어 모델이 외부 데이터 소스에 접근할 수 있도록 돕는 역할을 합니다. 서버에는 세 가지 구성 요소가 있습니다.
- 도구(Tool): 데이터베이스 조회, REST API 호출 등 구체적인 작업을 수행하는 기능입니다. 도구는 모델이 직접 제어하며, 대화 흐름 속에서 필요한 시점에 클라이언트를 통해 실행됩니다.
- 리소스(Resource): 파일이나 데이터베이스 레코드처럼 읽기 전용 데이터를 제공하여 모델의 컨텍스트를 보강합니다. 이때, 모델이 직접 리소스 요청에 관여하지는 않고, 사용자 또는 애플리케이션이 필요에 따라 리소스를 조회하고 모델에 전달합니다.
- 프롬프트(Prompt): 서버의 특정 역할을 설명하는 프롬프트 템플릿입니다. 모델에게 일관된 지침이나 배경 정보를 제공합니다.
MCP는 도구, 리소스, 프롬프트를 모두 명세하고 있지만, 각 클라이언트가 지원하는 범위는 상이합니다. 특히 공식 클라이언트별 지원 기능 목록을 보면, 도구는 공통적으로 제공되는 반면 리소스와 프롬프트를 지원하는 MCP 클라이언트는 상대적으로 드뭅니다.
따라서 예제에서는 모델이 주도적으로 활용할 수 있는 도구(Tool) 중심으로 서버를 구성합니다.
MCP 서버 구축
'네이버 개발자 센터 이용 등록'에서 준비한 OpenAPI를 기반으로 MCP 서버를 구성합니다.
아래 코드에서는 네이버 웹 검색 API를 MCP 서버의 도구(web_search)로 등록하여, 사용자가 입력한 검색어를 바탕으로 결과를 조회하고 JSON 형태로 반환합니다. 이렇게 구성된 MCP 서버는 앞서 설명한 세 가지 통신 방식 중 Streamable HTTP로 실행됩니다.
import os import re from typing import Annotated, Literal import httpx from dotenv import load_dotenv from pydantic import Field from fastmcp import FastMCP # 환경 변수 로드 load_dotenv() NAVER_CLIENT_ID = os.getenv("NAVER_CLIENT_ID") NAVER_CLIENT_SECRET = os.getenv("NAVER_CLIENT_SECRET") # MCP 서버 초기화 mcp = FastMCP("MCP Cookbook Example") # 네이버 검색 도구 정의 @mcp.tool( name="web_search", description="네이버 검색을 수행합니다." ) async def web_search( query: Annotated[str, Field(description="검색어입니다. 시점이나 조건 등을 구체적으로 작성하세요.")], display: Annotated[int, Field(description="웹 문서를 최대 몇 건까지 검색할지 결정합니다.(1-100)", ge=1, le=100)] = 20, start: Annotated[int, Field(description="검색 시작 위치입니다.(1-1000)", ge=1, le=1000)] = 1, sort: Annotated[Literal["sim", "date"], Field(description="정렬 옵션입니다. sim=유사도순, date=최신순")] = "sim" ) -> dict: """ 네이버 검색 API를 호출해 결과를 구조화하여 반환합니다. Args: query: 검색어 display: 검색 결과 수(1~100) start: 검색 시작 위치(1~1000) sort: 'sim' | 'date' Returns: { "query": str, "total": int, "items": [{"title": str, "link": str, "description": str}]} } """ url = "https://openapi.naver.com/v1/search/webkr.json" params = {"query": query, "display": display, "start": start, "sort": sort} headers = { "X-Naver-Client-Id": NAVER_CLIENT_ID, "X-Naver-Client-Secret": NAVER_CLIENT_SECRET, } async with httpx.AsyncClient() as client: r = await client.get(url, headers=headers, params=params) r.raise_for_status() data = r.json() results = [] for item in data.get("items", []): results.append({ "title": re.sub(r"<.*?>", "", item.get("title") or "").strip(), "link": item.get("link"), "description": re.sub(r"<.*?>", "", item.get("description") or "").strip(), }) return { "query": query, "total": data.get("total", 0), "items": results, } # 실행 if __name__ == "__main__": """ FastMCP 서버를 streamable-http로 실행합니다. 접속 URL은 http://127.0.0.1:8000/mcp/ 입니다. 통신 방식을 변경하려면 `mcp.run()`의 `transport` 인자를 다음과 같이 수정하세요. - mcp.run(transport="stdio") - mcp.run(transport="sse") """ mcp.run(transport="streamable-http", host="127.0.0.1", port=8000, path="/mcp/")
3. MCP 클라이언트
본 섹션에서는 MCP 서버를 LangChain 기반 클라이언트에 연결하고 실행하는 방법을 설명합니다. LangChain에서 제공하는 MCP 어댑터를 사용하면, MCP 서버에 등록된 도구를 LangChain의 도구 인터페이스로 매핑할 수 있습니다. 이를 통해 MCP 도구를 LangChain 에이전트의 일부로 자연스럽게 확장하고, 기존 워크플로에 유연하게 결합할 수 있습니다.
단일 요청 실행
다음은 HCX-005 모델을 LangChain에 연동하고, MCP 서버에 등록된 도구를 호출하여 최종 응답을 생성하는 단건 실행 코드입니다. 만약 LangChain에서 HCX-007 모델을 도구와 함께 사용하려면 반드시 reasoning_effort="none" 파라미터를 명시해야 합니다.
import os import asyncio from dotenv import load_dotenv from mcp import ClientSession from mcp.client.streamable_http import streamablehttp_client from langchain_mcp_adapters.tools import load_mcp_tools from langchain_naver import ChatClovaX from langchain.agents import create_agent from langchain.messages import SystemMessage, HumanMessage async def main(clova_api_key: str, server_url: str): """ CLOVA Studio 모델을 LangChain을 통해 호출하고, MCP 서버에 등록된 도구를 연동하여 최종 응답을 생성합니다. Args: clova_api_key (str): CLOVA Studio에서 발급받은 API Key server_url (str): 연결할 MCP 서버의 엔드포인트 URL """ model = ChatClovaX(model="HCX-005", api_key=clova_api_key) async with streamablehttp_client(server_url) as (read, write, _,): async with ClientSession(read, write) as session: # MCP 서버를 초기화하고 도구 목록을 불러옵니다. await session.initialize() tools = await load_mcp_tools(session) # 에이전트를 생성합니다. agent = create_agent(model, tools) # 대화 상태를 정의합니다. state = { "messages": [ SystemMessage(content="당신은 친절한 AI 어시스턴트입니다. 사용자의 질문에 대해 신뢰할 수 있는 정보만 근거로 삼아 답변하세요."), HumanMessage(content="요즘 날씨에 가기 좋은 국내 여행지 세 곳 알려줘"), ] } # 단건 요청을 실행하고 최종 응답을 출력합니다. result = await agent.ainvoke(state) print(result["messages"][-1].content) if __name__ == "__main__": """ .env 파일에서 CLOVA Studio API Key를 로드하고, MCP 서버의 엔드포인트 URL을 설정한 후 클라이언트를 실행합니다. """ load_dotenv() CLOVA_STUDIO_API_KEY = os.getenv("CLOVA_STUDIO_API_KEY") SERVER_URL = "http://127.0.0.1:8000/mcp/" asyncio.run(main(CLOVA_STUDIO_API_KEY, SERVER_URL))위 스크립트를 실행하면, CLOVA Studio 모델(HCX-005)이 MCP 서버를 통해 등록된 도구와 연동되어 사용자의 질문에 응답합니다. 예제에서는 “요즘 날씨에 가기 좋은 국내 여행지 세 곳 알려줘”라는 요청을 입력했으며, 실행 결과 모델이 추석 연휴 일정을 정확하게 정리해 답변을 반환합니다.
아래는 실제 출력된 응답입니다.
Quote현재 날씨에 가기 좋은 국내 여행지 몇 곳을 다음과 같이 추천드립니다.
- **경기도 가평 아침고요수목원**: 가을에는 다채로운 색깔의 국화와 단풍이 어우러진 모습을 볼 수 있고, 넓은 정원을 산책하며 자연을 만끽할 수 있습니다.
- **제주도 새별오름**: 억새풀이 아름답게 펼쳐진 오름으로 가을의 정취를 느끼기에 아주 좋습니다. 또한 정상에서의 전망이 탁 트여 있어 가슴이 뻥 뚫리는 듯한 느낌을 받을 수 있습니다.
- **강원도 정선 민둥산**: 해발 1119미터의 산으로 정상에는 나무가 없고 참억새 밭이 흐드러지게 피어있어 장관을 이룹니다. 특히 가을에는 억새꽃 축제가 열려 더욱 볼거리가 많습니다.위의 장소들은 모두 가을의 아름다움을 대표하는 곳으로 개인의 취향에 맞게 선택하시면 됩니다. 하지만 여행 전에 해당 지역의 날씨와 교통상황 등 자세한 정보를 먼저 파악하시기를 권해드립니다. 안전하고 즐거운 여행 되시길 바랍니다!
멀티턴 대화 실행
다음은 앞선 단일 요청 코드에서 확장된 형태로, 사용자 입력을 input()으로 반복 처리하며 스트리밍 방식으로 응답을 제공하는 대화 클라이언트입니다. 이 클라이언트는 누적된 대화 히스토리를 참조하여 보다 일관된 멀티턴 대화를 지원합니다.
import os import asyncio from dotenv import load_dotenv from mcp import ClientSession from mcp.client.streamable_http import streamablehttp_client from langchain_mcp_adapters.tools import load_mcp_tools from langchain_naver import ChatClovaX from langchain.agents import create_agent from langchain.messages import SystemMessage, HumanMessage, AIMessage async def main(clova_api_key: str, server_url: str): """ CLOVA Studio 모델을 LangChain을 통해 호출하고, MCP 서버에 등록된 도구를 연동하여 최종 응답을 생성합니다. Args: clova_api_key (str): CLOVA Studio에서 발급받은 API Key server_url (str): 연결할 MCP 서버의 엔드포인트 URL """ model = ChatClovaX(model="HCX-005", api_key=clova_api_key) async with streamablehttp_client(server_url) as (read, write, _,): async with ClientSession(read, write) as session: # MCP 서버를 초기화하고 도구 목록을 불러옵니다. await session.initialize() tools = await load_mcp_tools(session) # LangGraph 기반 ReAct 에이전트를 생성합니다. agent = create_agent(model, tools) # 대화 상태를 정의합니다. state = { "messages": [ SystemMessage(content=( "당신은 친절한 AI 어시스턴트입니다." "사용자의 질문에 대해 신뢰할 수 있는 정보만 근거로 삼아 답변하세요." )) ] } print("안녕하세요. 저는 AI 어시스턴트입니다. 원하시는 요청을 입력해 주세요. (종료하려면 '종료'를 입력하세요.)") while True: user_input = input("\n\nUser: ") if user_input.lower() in ["종료", "exit"]: print("대화를 종료합니다. 이용해 주셔서 감사합니다.") break state["messages"].append(HumanMessage(content=user_input)) # astream_events를 사용하여 스트리밍으로 응답을 처리합니다. try: final_answer = "" async for event in agent.astream_events(state, version="v1"): kind = event["event"] if kind == "on_chat_model_stream": chunk = event["data"]["chunk"] if chunk.content: print(chunk.content, end="", flush=True) final_answer += chunk.content elif kind == "on_tool_start": print(f"\n[도구 선택]: {event['name']}\n[도구 호출]: {event['data'].get('input')}") elif kind == "on_tool_end": print(f"[도구 응답]: {event['data'].get('output')}\n") # 스트리밍이 끝나면 최종 답변을 AIMessage로 만들어 상태에 추가합니다. state["messages"].append(AIMessage(content=final_answer)) except Exception as e: print(f"\n요청을 처리하는 중에 오류가 발생했습니다. 오류: {e}") pass if __name__ == "__main__": """ .env 파일에서 CLOVA Studio API Key를 로드하고, MCP 서버의 엔드포인트 URL을 설정한 후 클라이언트를 실행합니다. """ load_dotenv() CLOVA_STUDIO_API_KEY = os.getenv("CLOVA_STUDIO_API_KEY") SERVER_URL = "http://127.0.0.1:8000/mcp/" asyncio.run(main(CLOVA_STUDIO_API_KEY, SERVER_URL))
아래 예시는 사용자가 두 차례 질의를 이어가는 과정에서, MCP 서버의 web_search 도구가 호출되고 누적된 대화 히스토리가 활용되는 흐름을 보여줍니다. 도구 응답의 items 필드는 결과 목록이 길어 중략합니다.
Quote안녕하세요. 저는 AI 어시스턴트입니다. 원하시는 요청을 입력해 주세요. (종료하려면 '종료'를 입력하세요.)
User: 요즘 날씨에 가기 좋은 국내 여행지 세 곳 알려줘
[도구 선택]: web_search
[도구 호출]: {'query': '가을 날씨에 가기 좋은 국내 여행지', 'display': 20}
[도구 응답]: content='{"query":"가을 날씨에 가기 좋은 국내 여행지","total":2629216,"items":[...]}' name='web_search' tool_call_id='call_aU2RBXFVcomyyT8PBygupAM8'현재 날씨에 가기 좋은 국내 여행지 몇 곳을 다음과 같이 추천드립니다.
- **경기도 가평 아침고요수목원**: 가을에는 다채로운 색깔의 국화와 단풍이 어우러진 모습을 볼 수 있고, 넓은 정원을 산책하며 자연을 만끽할 수 있습니다.
- **제주도 새별오름**: 억새풀이 아름답게 펼쳐진 오름으로 가을의 정취를 느끼기에 아주 좋습니다. 또한 정상에서의 전망이 탁 트여 있어 가슴이 뻥 뚫리는 듯한 느낌을 받을 수 있습니다.
- **강원도 정선 민둥산**: 해발 1119미터의 산으로 정상에는 나무가 없고 참억새 밭이 흐드러지게 피어있어 장관을 이룹니다. 특히 가을에는 억새꽃 축제가 열려 더욱 볼거리가 많습니다.위의 장소들은 모두 가을의 아름다움을 대표하는 곳으로 개인의 취향에 맞게 선택하시면 됩니다. 하지만 여행 전에 해당 지역의 날씨와 교통상황 등 자세한 정보를 먼저 파악하시기를 권해드립니다. 안전하고 즐거운 여행 되시길 바랍니다!
User: 해외는?
[도구 선택]: web_search
[도구 호출]: {'query': '가을 날씨에 가기 좋은 해외 여행지', 'display': 20}
[도구 응답]: content='{"query":"가을 날씨에 가기 좋은 해외 여행지","total":2492973,"items":[...]}' name='web_search' tool_call_id='call_kUgCWjOEuX7A2MHd88P9DNAY'가을 날씨에 가기 좋은 해외 여행지를 다음과 같이 소개합니다.
1. **일본 교토**: 전통적인 일본 문화를 체험하고 아름다운 단풍 구경을 할 수 있습니다. 또한, 선선한 가을 날씨는 축제와 야외 활동을 즐기기에도 좋습니다.
2. **스페인 바르셀로나**: 11월에는 여름철 관광객 수가 줄어들어 더욱 여유로운 관광이 가능합니다. 특히, 가우디 건축물이나 캄프 누 경기장 등 대표적인 관광 명소를 방문하기 좋은 때입니다.
3. **캐나다 밴쿠버**: 캐나다 로키산맥의 가을은 황금빛으로 물든 풍경을 자랑하며, 하이 자연 탐험을 즐기기에 이상적인 장소입니다. 또한, 온화한 기후로 인해 야외 활동하기에 적합한 환경을 제공합니다.
위의 여행지들은 모두 대중적으로 인기있는 여행지로 여행객들에게 많은 볼거리와 즐길 거리를 제공합니다. 하지만 개인의 취향과 선호도에 따라 다른 여행지가 더 적합할 수도 있으니 참고하시기 바랍니다. 또한, 각 국가의 입국 규정과 현지 상황을 미리 확인하여 계획을 세우는 것이 중요합니다.
4. 확장 시나리오
이번 장에서는 앞서 구성한 MCP 서버에 Remote MCP 서버를 추가로 연동하여 도구를 확장하는 방법을 다룹니다.
MCP는 모듈화된 구조를 지니기 때문에, 새로운 도구를 추가하거나 기존 도구를 교체하기가 매우 쉬운데요. 특히 네트워크를 통해 Remote MCP 서버로부터 도구를 불러와 즉시 활용할 수 있다는 점이 큰 장점입니다. 최근에는 다양한 서비스 제공자들이 이러한 Remote MCP 서버를 공개하거나 호스팅 형태로 제공하면서 도구 선택의 폭이 더욱 넓어지고 있습니다.
이러한 장점을 활용해, 이번 장에서는 Remote MCP 서버를 연동해 기능을 확장하는 시나리오를 다뤄보겠습니다.
앞서 사용한 네이버 검색 도구는 다음 예시의 description 필드처럼 본문 일부만 발췌해 제공하기 때문에, 원문의 풍부한 정보를 확보하기에는 한계가 있었습니다.
{ "items": [ { "title": "[클로바 스튜디오 Cookbook] 랭체인(Langchain)으로 Naive RAG 구현하기", "link": "https://blog.naver.com/n_cloudplatform/223974030008", "description": "생성까지 RAG 파이프라인을 처음부터 끝까지 직접 구현하며, 참조 링크까지 함께 제공할 수 있습니다. Cookbook에서 코드와... 예제에서는 네이버클라우드플랫폼(NCP)의 클로바 스튜디오 사용..." } ] }이번에는 한 걸음 더 나아가, 검색 결과에 포함된 웹페이지에 접속해 본문까지 직접 탐색하는 방식으로 확장해 보겠습니다. 이를 위해 마이크로소프트에서 제공하는 Playwright MCP 서버를 활용합니다.
Remote MCP 서버
Playwright MCP는 마이크로소프트에서 제공하는 브라우저 자동화용 MCP 서버로, 클라이언트가 원격으로 브라우저를 제어하여 웹 페이지를 탐색하거나 콘텐츠를 추출할 수 있도록 지원합니다.
터미널에서 다음 명령어를 실행하여 Playwright MCP 서버를 시작합니다. 실행된 서버는 http://localhost:8931/mcp를 통해 접근할 수 있습니다. 브라우저 종류나 headless 여부 등 세부 설정은 --config 옵션으로 JSON 설정 파일을 지정해 적용할 수 있습니다. 자세한 옵션은 가이드를 참고하세요.
npx @playwright/mcp@latest --port 8931
Quote본 실습에서 사용하는 Playwright MCP는 브라우저 자동화를 제공하는 도구입니다. 본 예제에서는 오직 테스트 목적으로만 사용하였으며, 실제 서비스에 적용할 경우 각 사이트의 이용 약관 및 정책을 반드시 준수해야 합니다. 또한, 과도한 요청이나 비정상적인 접근은 서비스 제공자 측의 차단 대상이 될 수 있으므로 주의가 필요합니다.
MCP 클라이언트
이제 서버 준비가 끝났다면, 클라이언트에서는 서버 URL만 추가하면 바로 도구 연동이 가능합니다. 즉, 앞서 사용하였던 네이버 검색 도구와 함께, 새로운 서버의 엔드포인트(http://localhost:8931/mcp)를 추가하기만 하면, 두 서버를 동시에 사용할 수 있습니다.
또한 필요에 따라 Remote MCP 서버의 도구를 래핑해 커스텀 도구로 구성할 수도 있는데요. 예를 들어, Playwright MCP의 browser_navigate 도구는 HTML 본문 전체를 반환하기 때문에 응답이 매우 길어질 수 있습니다. 이때 불필요한 토큰 소모를 줄이기 위해, 수집한 HTML을 정제하는 기능을 추가한 scrape_and_clean 같은 커스텀 도구를 새롭게 정의할 수 있습니다.
다음 스크립트는 LangChain을 통해 CLOVA Studio 모델을 호출하고, 두 개의 MCP 서버에서 제공하는 도구를 함께 사용하여 답변을 생성합니다. 또한 사용자 입력을 input()으로 반복 처리하며, 스트리밍 방식으로 응답을 제공하는 대화형 클라이언트 형태로 동작합니다.
import os import asyncio from dotenv import load_dotenv from langchain_mcp_adapters.client import MultiServerMCPClient from langchain_naver import ChatClovaX from langchain.agents import create_agent from langchain.messages import SystemMessage, HumanMessage, AIMessage from langchain_core.tools import tool from bs4 import BeautifulSoup import re async def main(clova_api_key: str, server_config: dict): """ CLOVA Studio 모델을 LangChain을 통해 호출하고, MCP 서버에 등록된 도구를 연동하여 최종 응답을 생성합니다. Args: clova_api_key (str): CLOVA Studio에서 발급받은 API Key server_config (dict): MCP 서버 설정 정보 """ model = ChatClovaX(model="HCX-005", api_key=clova_api_key) client = MultiServerMCPClient(server_config) # 다음과 같이 서버를 바로 연동할 수도 있습니다. # agent = create_agent(model, tools) # 도구 커스텀을 위해 도구 목록을 직접 불러옵니다. tools = await client.get_tools() tool_map = {t.name: t for t in tools} web_search = tool_map["web_search"] browser_navigate = tool_map["browser_navigate"] # browser_navigate를 래핑하여 새로운 커스텀 도구를 정의합니다. @tool async def scrape_and_clean(url: str) -> str: """주어진 URL로 이동하여 페이지의 HTML을 스크래핑한 뒤 본문 텍스트를 정제합니다.""" # browser_navigate 도구를 사용하여 페이지 HTML을 가져옵니다. html_content = await browser_navigate.ainvoke({"url": url}) soup = BeautifulSoup(html_content, 'html.parser') text = soup.get_text() # 불필요한 태그, 특수문자, 과도한 공백 등을 제거합니다. text = re.sub( r'(?:\b[a-z]+(?:\s+\[[^\]]*\])?:\s*|\[[^\]]*\]|[.,\-\|/]{3,}|\s+)', ' ', text, flags=re.I ).strip() return text # 도구 목록을 새롭게 정의합니다. tools = [web_search, scrape_and_clean] # 에이전트를 생성합니다. agent = create_agent(model, tools) # 대화 상태를 정의합니다. state = { "messages": [ SystemMessage(content=( "당신은 친절한 AI 어시스턴트입니다.\n" "사용자의 질문에 대해 신뢰할 수 있는 정보만 근거로 삼아 답변하세요.\n" "만약 정보를 찾기 위해 도구를 사용해야 한다면, 다음 작업 순서에 따라 진행하세요:\n" "Step 1: web_search로 검색을 수행합니다.\n" "Step 2: 검색 결과 중 가장 관련성이 높은 link에 대해 scrape_and_clean을 호출합니다\n" "Step 3: 결과를 확인하고, 다음으로 관련성이 높은 link에 대해 scrape_and_clean을 호출합니다\n" "Step 4: 이 과정을 반복하여 여러 link에서 정보를 수집합니다.(최대 3개)\n" "Step 5: 수집한 정보를 바탕으로 종합적인 답변을 제공합니다\n" "Step 6: **종합적인 답변에는 반드시 link를 명시하여** 정보의 출처를 밝힙니다\n\n" "반드시 도구를 하나씩 순차적으로 호출하세요. 동시에 여러 도구를 호출하면 안 됩니다.\n" "이미 호출한 도구와 동일한 정보를 다시 요청하지 마세요." )) ] } print("안녕하세요. 저는 AI 어시스턴트입니다. 원하시는 요청을 입력해 주세요. (종료하려면 '종료'를 입력하세요.)") # astream_events를 사용하여 스트리밍으로 응답을 처리합니다. while True: user_input = input("\n\nUser: ") if user_input.lower() in ["종료", "exit"]: print("대화를 종료합니다. 이용해 주셔서 감사합니다.") break state["messages"].append(HumanMessage(content=user_input)) # astream_events를 사용하여 스트리밍으로 응답을 처리합니다. try: final_answer = "" async for event in agent.astream_events(state, version="v1"): kind = event["event"] if kind == "on_chat_model_stream": chunk = event["data"]["chunk"] if chunk.content: print(chunk.content, end="", flush=True) final_answer += chunk.content elif kind == "on_tool_start": print(f"\n[도구 선택]: {event['name']}\n[도구 호출]: {event['data'].get('input')}") elif kind == "on_tool_end": # 출력이 너무 길어지는 것을 방지하기 위해 browser_navigate 도구의 응답은 출력하지 않습니다. tool_name = event.get("name", "") if tool_name != "browser_navigate": print(f"[도구 응답]: {event['data'].get('output')}\n") # 스트리밍이 끝나면 최종 답변을 AIMessage로 만들어 상태에 추가합니다. state["messages"].append(AIMessage(content=final_answer)) except Exception as e: print(f"\n요청을 처리하는 중에 오류가 발생했습니다. 오류: {e}") pass if __name__ == "__main__": """ .env 파일에서 CLOVA Studio API Key를 로드하고, MCP 서버의 엔드포인트 URL을 설정한 후 클라이언트를 실행합니다. """ load_dotenv() CLOVA_STUDIO_API_KEY = os.getenv("CLOVA_STUDIO_API_KEY") SERVER_CONFIG = { "search-mcp": { "url": "http://127.0.0.1:8000/mcp/", "transport": "streamable_http", }, "playwright-mcp": { "url": "http://localhost:8931/mcp", "transport": "streamable_http", }, } asyncio.run(main(CLOVA_STUDIO_API_KEY, SERVER_CONFIG))위 스크립트를 실행하면 콘솔에서 사용자 질의를 입력해 멀티턴 대화를 진행할 수 있습니다.
외부 정보가 필요한 질의의 경우 먼저 web_search 도구로 관련 링크를 찾고, 우선순위가 높은 링크부터 scrape_and_clean 도구로 탐색합니다. scrape_and_clean은 내부적으로 browser_navigate를 래핑해 사용하므로, 로컬 실행 환경의 Playwright 브라우저가 자동으로 실행되어 페이지를 렌더링하고 HTML을 수집합니다. 수집된 본문 텍스트는 정제된 뒤 도구 응답으로 반환되고, 모델은 이 결과들을 종합해 최종 답변을 생성합니다.
아래는 실제 출력된 응답입니다. 도구 응답의 items 필드 목록과 content 값은 내용이 길어 중략합니다.
Quote안녕하세요. 저는 AI 어시스턴트입니다. 원하시는 요청을 입력해 주세요. (종료하려면 '종료'를 입력하세요.)
User: RAG 관련된 클로바 스튜디오 Cookbook 찾아서 2개 정도 추천하고 요약 정리해줘
[도구 선택]: web_search
[도구 호출]: {'query': '클로바 스튜디오 RAG Cookbook', 'display': 20, 'sort': 'sim'}
[도구 응답]: content='{"query":"클로바 스튜디오 RAG Cookbook","total":41,"items":[...]}' name='web_search' tool_call_id='call_kbQ0jkNrgqljiU7g2JYoncmx'[도구 선택]: scrape_and_clean
[도구 호출]: {'url': 'https://www.ncloud-forums.com/topic/422/'}[도구 선택]: browser_navigate
[도구 호출]: {'url': 'https://www.ncloud-forums.com/topic/422/'}
[도구 응답]: content='...' name='scrape_and_clean' tool_call_id='call_riKcKw3RDt4ZCXb95u5jXAkj'
[도구 선택]: scrape_and_clean
[도구 호출]: {'url': 'https://www.ncloud-forums.com/topic/497/'}[도구 선택]: browser_navigate
[도구 호출]: {'url': 'https://www.ncloud-forums.com/topic/497/'}
[도구 응답]: content='...' name='scrape_and_clean' tool_call_id='call_8JYLtdEwrZXeZHWYQFbecKUw'
다음은 두 개의 CLOVA Studio Cookbook 관련 자료에 대한 요약 정리입니다:1. **"랭체인(Langchain)으로 Naive RAG 구현하기"**
- [링크](https://www.ncloud-forums.com/topic/422/)
- 이 자료는 Langchain과 CLOVA Studio를 연결하여 HTML 가이드를 검색하고 답하는 RAG 시스템을 구현하는 방법을 설명합니다.
- 주요 내용:
- 사전 준비: Langchain 패키지 설치, 참조할 문서 준비, 필요한 모듈 import.
- 데이터 로딩: wget을 사용하여 HTML 데이터를 다운로드하고, LangChain의 Document Loader를 사용해 HTML 파일을 처리 가능한 형태로 변환.
- 문단 나누기: CLOVA Studio의 문단 나누기 API를 사용하여 문장을 적절한 크기의 청크로 나눔.
- 임베딩: CLOVA Studio의 임베딩 API를 사용해 텍스트 데이터를 벡터로 변환.
- 벡터 저장소(Vector Store)에 저장: Chroma 또는 FAISS를 사용하여 벡터 데이터를 저장하고 관리.
- 검색기(Retriever) 생성: 사용자의 질문에 대해 관련 문서를 검색.
- RAG 시스템 완성: LCEL을 사용해 체인을 구성하고, 질문에 대한 답변을 생성.2. **"LangChain으로 이미지가 있는 문서를 검색하는 RAG 시스템 구축하기 (Multimodal RAG Cookbook)"**
- [링크](https://www.ncloud-forums.com/topic/497/)
- 이 자료는 클로바 스튜디오와 Langchain을 활용하여 PDF 형식의 데이터에서 텍스트와 이미지를 추출하고, 이를 기반으로 질문에 대한 답변을 생성하는 과정을 다룹니다.
- 주요 내용:
- 사전 준비: Langchain 패키지 설치, 필요한 모듈 import, CLOVA Studio API 키 발급.
- 데이터 전처리: PDF 문서에서 텍스트와 이미지를 추출하고, 이미지를 전처리하여 CLOVA Studio의 비전 모델에 맞게 조정.
- 이미지 요약: 비전 모델을 사용해 이미지 내용을 텍스트로 요약하고, 이를 문서화.
- 문서 청킹: 텍스트와 이미지 문서를 의미 단위로 분할.
- 벡터 데이터 변환 및 저장: 청킹된 문서를 벡터로 변환하고 Chroma 또는 FAISS와 같은 벡터 저장소에 저장.
- 질의 응답 생성: 사용자의 질문에 대해 문서에서 관련 정보를 검색하고 답변을 생성.이 두 자료는 CLOVA Studio와 LangChain을 결합해 RAG 시스템을 단계별로 구현하는 실용적인 가이드입니다. 텍스트·이미지 등 다양한 형태의 데이터를 다루는 과정을 통해, RAG의 핵심 구성 요소를 이해하고 실제 환경에서 효과적으로 응용하는 방법을 익힐 수 있을 것입니다.
마무리
이번 1부에서는 MCP의 핵심 개념과 구조, 그리고 HyperCLOVA X 모델을 연동한 클라이언트 구축 과정을 살펴보았습니다. 또한 네이버 검색 API와 연동하는 기본 예제를 구현하고, Remote MCP 서버를 추가로 연동하여 도구를 확장하는 시나리오까지 함께 다뤘습니다.
이를 통해 MCP의 모듈화된 구조와 확장성이 실제로 어떻게 활용될 수 있는지를 확인했습니다.
이어지는 2부에서는 세션 관리와 컨텍스트 관리 전략을 다룹니다. 멀티턴 대화 환경에서 MCP를 안정적으로 활용할 수 있는 방법을 소개할 예정입니다.
MCP 실전 쿡북 4부작 시리즈
✔︎ (1부) LangChain에서 네이버 검색 도구 연결하기
✔︎ (2부) 세션 관리와 컨텍스트 유지 전략 링크
✔︎ (3부) OAuth 인증이 통합된 MCP 서버 구축하기 링크
✔︎ (4부) 운영과 확장을 위한 다양한 팁 링크
-
-
들어가며
지난 쿡북 AI 어시스턴트 제작 레시피: Function calling 활용하기에서는 단순한 가상의 파이썬 함수를 사용해, 주식 주문을 흉내 내는 가벼운 시뮬레이션을 구현해보았는데요.
이번에는 그 흐름을 한층 더 확장해 보려 합니다. FastAPI로 주식 거래 API를 만들고, 이를 FastMCP를 통해 MCP 도구로 래핑하여 LLM이 진짜 도구를 호출하는 사례를 구현합니다.
MCP(Model Context Protocol)는 LLM 및 외부 도구·서비스 간의 연결 방식을 표준화한 개방형 프로토콜로, 쉽게 말해 다양한 기능을 가진 도구들을 LLM이 일관된 방식으로 사용할 수 있게 해주는 어댑터 역할을 합니다. 흔히 'AI를 위한 USB-C'에 비유되며, 검색, 데이터베이스, API 등 어떤 도구든 동일한 포맷으로 연결할 수 있게 해줍니다. MCP는 JSON-RPC 2.0이라는 경량 메시지 포맷을 기반으로 통신하는데요. JSON은 {"key": "value"}처럼 사람이 읽을 수 있는 직관적인 구조이고, RPC(Remote Procedure Call)는 원격 서버에 기능 실행을 요청하는 방식입니다. REST API보다 간결하고 기능 중심적인 요청/응답 구조를 제공하는 것이 특징입니다.
MCP는 크게 두 가지 기본 명령어로 구성됩니다.
-
tools/list: MCP 서버에 등록된 모든 도구의 메타데이터(이름, 설명, 입력값 스키마 등)를 조회합니다. 이 정보는 LLM이 사용할 수 있도록 변환되어, 모델에게 '어떤 도구들이 어떤 방식으로 호출 가능한지'를 알려주는 역할을 합니다.
-
tools/call: LLM이 생성한 toolCall 요청(도구 이름과 입력값)을 실제로 실행하고, 결과를 받아오는 명령입니다.
일반적인 실행 흐름은 다음과 같습니다.
- 클라이언트가 MCP 서버에 tools/list 요청을 보내면, MCP 서버는 JSON 포맷의 도구 목록을 반환합니다.
- 이 메타데이터는 LLM에게 입력으로 전달되어, 모델이 사용자 질문을 분석하고 적절한 toolCall 요청을 구성하도록 돕습니다.
- 이후 클라이언트는 해당 toolCall을 tools/call 형식으로 변환해 서버에 요청하고, 실행 결과를 받아 LLM에게 다시 전달합니다.
- 마지막으로 모델은 이 실행 결과를 반영한 자연어 응답을 생성해 사용자에게 전달합니다.
본 쿡북에서 사용하는 FastMCP는 Python 기반의 MCP 구현 라이브러리로, 기존 REST API를 손쉽게 MCP 도구로 전환할 수 있게 해줍니다.
FastMCP.from_fastapi()를 통해 FastAPI로 구성한 REST API를 MCP 도구로 래핑할 수 있으며, 별도의 REST API가 없는 경우에는 @mcp.tool 데코레이터만 붙여도 단일 함수를 도구로 노출할 수 있습니다. 두 방식 모두 JSON-RPC 요청을 자동으로 파싱하고, 스키마를 자동으로 생성해 주는 등 구현 부담을 줄여준다는 장점이 있습니다.
본 쿡북에서는 MCP 서버의 tools/list 및 tools/call 응답을 Function calling 스키마로 매핑하여 모델 입력에 포함시키는 방식을 사용합니다. 즉, 도구 메타데이터를 모델이 이해하는 함수 정의로 재구성하는 변환 로직을 클라이언트에 구현했습니다. 참고로, OpenAI 호환 API를 활용하는 경우에는 이러한 매핑 없이도 클라이언트에 MCP 서버를 곧바로 연동할 수 있습니다.
시나리오 소개
FastAPI로 구성된 주식 거래 API를 FastMCP로 감싸 MCP 도구로 등록하고, LLM이 자연어 요청을 분석해 적절한 도구를 호출하는 워크플로우를 구성합니다.
사용자는 아래와 같은 질문을 자연스럽게 입력할 수 있습니다.
- 네이버 지금 얼마야?
- 네이버 1주 매수해줘
- 내 계좌 잔고 조회해줘. 비번은 ****
- 7월 한달 거래 내역 보여줘
주요 기능 요약
- 주가 조회: 특정 종목의 실시간 주가를 확인할 수 있습니다. 가격은 FinanceDataReader에서 가져온 실시간 정보를 사용합니다.
- 주식 주문: 사용자가 입력한 종목 코드에 대해 시장가(또는 전일 종가) 기준으로 거래를 실행합니다. 가격은 FinanceDataReader에서 가져온 실시간 정보를 사용합니다.
- 잔고 확인: 현재 남은 현금과 각 종목의 보유 수량 및 평균 단가를 반환합니다. 비밀번호가 필요하며, 예제의 비밀번호는 '1234'로 고정되어 있습니다.
- 거래 내역 조회: 기간을 지정하면 해당 기간의 매수/매도 내역을 필터링해 반환합니다. 날짜 형식은 ISO 표준(YYYY-MM-DD)을 따릅니다.
실행 흐름
시나리오 구현
본 예제는 시뮬레이션 목적의 데모 코드이며, 주식 매수 및 매도 시 평균 단가 및 손익 계산은 단순화되어 있습니다. 실제 서비스에 적용할 경우 정확한 회계 기준과 거래 규칙에 따라 로직을 재설계해야 합니다.
1. 설치 패키지
시나리오 구현을 위해서 먼저 다음의 파이썬 패키지를 설치합니다.
FastAPI와 Uvicorn은 REST API 서버를 구동하기 위한 기본 조합이고, FastMCP는 MCP 도구 스펙 등록을 위해 필요합니다. 금융 데이터가 필요한 예제이므로 finance-datareader도 함께 설치합니다.
pip install fastapi uvicorn fastmcp finance-datareader
만약 더 빠른 설치 속도를 원한다면 다음과 같이 uv를 설치합니다.
curl -LsSf https://astral.sh/uv/install.sh | sh
uv add fastmcp2. 파일 구성
세 개의 주요 파일로 구성되며, LLM ↔ MCP 서버 ↔ 외부 데이터 소스 간 연동 흐름을 구현합니다.
cookbook/ ├── my_client.py # 사용자 입력을 받아 LLM과 MCP 서버를 연동하는 실행 클라이언트입니다. ├── my_server.py # REST와 MCP 서버를 동시에 띄우는 실행용 서버 스크립트입니다. └── stock_api.py # FastAPI로 구현된 REST API로, 주식 주문 및 조회 기능을 제공합니다. my_server.py에 의해 MCP 도구로 래핑되어 활용됩니다.
3. 파일 생성
3.1 stock_api.py
FastAPI로 구현된 REST API로, 주식 주문 및 조회 기능을 제공합니다.
현금 잔고, 보유 종목, 거래 내역을 모두 메모리 상태로 유지하며, 다음 네 가지 엔드포인트를 제공합니다.
- POST /buy: 종목 매수
- POST /sell: 종목 매도
- GET /balance: 현금 및 보유 종목 조회
- GET/ trades: 거래 내역 조회
매수 또는 매도 요청이 들어오면 FinanceDataReader를 통해 실시간 시세를 조회한 뒤, 잔고를 갱신하고 체결 내역을 기록합니다. 튜토리얼 목적의 예제이므로 별도의 데이터베이스 없이 파이썬 전역 변수를 통해 상태를 유지합니다.
import FinanceDataReader as fdr from fastapi import FastAPI, HTTPException, Query, Header, Depends from pydantic import BaseModel, Field from datetime import date, datetime from typing import Optional, Dict, List from typing import Any app = FastAPI(title="Stock Trading API", version="1.0.0") # 전역 상태 정의 cash_balance: int = 10_000_000 # 초기 현금 1천만 원 portfolio: Dict[str, Dict[str, int | str]] = {} # 종목별 보유 수량 및 평균 단가 trade_history: List[Dict[str, int | str]] = [] # 거래 내역 # 간단한 비밀번호 설정 ACCOUNT_PASSWORD = "1234" class PortfolioItem(BaseModel): """보유 종목 정보""" qty: int = Field(..., description="보유 수량") name: Optional[str] = Field(None, description="종목명") avg_price: int = Field(..., description="평균 단가") class TradeRequest(BaseModel): """매수/매도""" ticker: str = Field(..., description="종목 코드 (예: 035420)") qty: int = Field(..., gt=0, description="매수 또는 매도할 수량") class BalanceResponse(BaseModel): """잔고 조회""" available_cash: int = Field(..., description="현금 잔고(원)") portfolio: Dict[str, Any] = Field(..., description="종목별 보유 내역") class TradeHistoryItem(BaseModel): """거래 내역""" type: str = Field(..., description="거래 종류 (buy 또는 sell)") name: Optional[str] = Field(None, description="종목명") ticker: str = Field(..., description="종목 코드") qty: int = Field(..., description="거래 수량") price: int = Field(..., description="거래 체결 가격") avg_price: Optional[int] = Field(None, description="거래 후 평균 단가") datetime: str = Field(..., description="거래 시각 (YYYY-MM-DD HH:MM:SS)") def get_market_price(ticker: str) -> int: """주어진 종목 코드의 가장 최근 종가를 조회합니다. Args: ticker: 종목 코드 Returns: int: 최근 종가 Raises: HTTPException: 종목 데이터가 없는 경우 """ df = fdr.DataReader(ticker) if df.empty: raise HTTPException(status_code=404, detail=f"종목 {ticker}에 대한 시장 데이터를 찾을 수 없습니다.") return int(df['Close'].iloc[-1]) def get_corp_name(ticker: str) -> str: """종목 코드를 종목명으로 변환합니다. 못 찾으면 그대로 코드 반환.""" krx = fdr.StockListing("KRX") match = krx.loc[krx['Code'] == ticker, 'Name'] return match.values[0] if not match.empty else ticker @app.post("/buy", summary="종목 매수", operation_id="buy_stock", response_model=dict) async def buy_stock(trade: TradeRequest): """주어진 종목을 지정한 수량만큼 매수합니다. 요청 본문으로 종목 코드와 수량을 받으며, 현재 잔고가 부족하면 400 오류를 반환합니다. """ price = get_market_price(trade.ticker) name = get_corp_name(trade.ticker) cost = trade.qty * price # 잔고 확인 및 업데이트 global cash_balance global portfolio if cost > cash_balance: raise HTTPException(status_code=400, detail=f"잔고가 부족합니다. 현재 잔고는 {cash_balance:,}원이며, 총 {cost:,}원이 필요합니다.") cash_balance -= int(cost) existing = portfolio.get(trade.ticker, {"qty": 0, "avg_price": 0.0, "name": name}) total_qty = existing["qty"] + trade.qty avg_price = ((existing["qty"] * existing["avg_price"]) + cost) / total_qty portfolio[trade.ticker] = { "qty": total_qty, "name": name, "avg_price": int(round(avg_price, 2)) } trade_history.append({ "type": "buy", "name": name, "ticker": trade.ticker, "qty": trade.qty, "price": int(round(price, 2)), "avg_price": int(round(avg_price, 2)), "datetime": datetime.now().strftime("%Y-%m-%d %H:%M:%S") }) current_cash = cash_balance return { "message": f"{name} {trade.qty}주 매수 완료 (시장가 {round(price, 2)}원)", "available_cash": current_cash } @app.post("/sell", summary="종목 매도", operation_id="sell_stock", response_model=dict) async def sell_stock(trade: TradeRequest): """보유 종목을 지정한 수량만큼 매도합니다. 보유 수량이 부족하면 400 오류를 반환합니다. 매도 후 잔여 수량이 0이면 포트폴리오에서 삭제합니다. """ global cash_balance global portfolio if trade.ticker not in portfolio or portfolio[trade.ticker]["qty"] < trade.qty: raise HTTPException(status_code=400, detail=f"보유한 수량이 부족합니다. 현재 보유: {portfolio.get(trade.ticker, {}).get('qty', 0)}주, 요청 수량: {trade.qty:,}주") price = get_market_price(trade.ticker) name = get_corp_name(trade.ticker) revenue = trade.qty * price current_qty = portfolio[trade.ticker]["qty"] current_avg_price = portfolio[trade.ticker]["avg_price"] new_qty = current_qty - trade.qty cash_balance += int(revenue) if new_qty == 0: del portfolio[trade.ticker] else: portfolio[trade.ticker]["qty"] = new_qty portfolio[trade.ticker]["avg_price"] = current_avg_price trade_history.append({ "type": "sell", "name": name, "ticker": trade.ticker, "qty": trade.qty, "price": int(round(price, 2)), "avg_price": int(round(current_avg_price, 2)), "datetime": datetime.now().strftime("%Y-%m-%d %H:%M:%S") }) current_cash = cash_balance return { "message": f"{name} {trade.qty}주 매도 완료 (시장가 {round(price, 2)}원)", "available_cash": current_cash } @app.get("/balance", summary="잔고 조회", operation_id="get_balance", response_model=BalanceResponse) async def get_balance(password: str = Header(..., alias="X-Account-Password")): """현재 보유 현금과 포트폴리오를 반환합니다. 요청 시 HTTP 헤더의 `X-Account-Password` 값을 통해 비밀번호를 전달받습니다. """ if password != ACCOUNT_PASSWORD: raise HTTPException(status_code=401, detail="잘못된 비밀번호입니다.") typed_portfolio = {ticker: PortfolioItem(**data) for ticker, data in portfolio.items()} return { "available_cash": cash_balance, "portfolio": typed_portfolio } @app.get("/trades", summary="거래 내역 조회", operation_id="get_trade_history", response_model=List[TradeHistoryItem]) async def get_trade_history( start_date: Optional[date] = Query(None, description="조회 시작일 (예: 2025-07-01)"), end_date: Optional[date] = Query(None, description="조회 종료일 (예: 2025-07-28)") ): """지정 기간 동안의 거래 내역을 반환합니다.""" if start_date and end_date and start_date > end_date: raise HTTPException(status_code=400, detail="start_date는 end_date보다 이후일 수 없습니다.") filtered: List[Dict] = [] for trade in trade_history: trade_dt = datetime.strptime(trade["datetime"], "%Y-%m-%d %H:%M:%S") if start_date and trade_dt.date() < start_date: continue if end_date and trade_dt.date() > end_date: continue filtered.append(trade) return filtered @app.get("/", summary="서비스 안내") async def root() -> Dict[str, str]: return {"message": "Welcome to the Stock Trading API"}
3.2 my_server.py
앞서 정의한 주식 거래 API를 MCP 도구로 래핑해 한 번에 서비스하도록 구성한 스크립트입니다.
- FastMCP.from_fastapi()로 REST API를(주식 거래 API)을 MCP 도구 세트로 변환합니다.
- mcp.http_app()을 통해 /mcp/ 경로에 JSON-RPC 기반 MCP 서버를 마운트합니다.
- 동시에, 원본 REST API는 /api 경로에 그대로 유지해, REST와 MCP를 병행 노출합니다.
- 결과적으로 uvicorn으로 my_server:app만 띄우면, REST(/api)와 MCP(/mcp)가 동시에 구동됩니다.
REST에 없는 기능도 별도로 등록 가능하며, 예시로 @mcp.tool() 데코레이터를 통해 get_price라는 도구를 추가 구현하였습니다.
from fastapi import FastAPI from fastmcp import FastMCP from stock_api import app as stock_api_app def create_app() -> FastAPI: instructions = ( "이 MCP 서버는 주식 매수/매도, 잔고 조회, 거래 내역 조회, 시세 조회 기능을 제공합니다." ) # 1) 기존 FastAPI의 API 전체를 MCP 도구 세트로 래핑하고 MCP 서버 객체를 생성합니다. mcp = FastMCP.from_fastapi( stock_api_app, name="Stock Trading MCP", instructions=instructions, ) # 2) FastAPI API에 정의되지 않은 이외 도구를 @mcp.tool로 추가 등록합니다.(즉 API가 아닌 파이썬 개별 함수) # 즉 1)에서 생성한 서버에 도구 추가 @mcp.tool( name="get_price", description="특정 종목의 실시간 주가 또는 최근 종가를 반환합니다.", ) async def get_price(ticker: str) -> dict: """FinanceDataReader로 가장 최근 종가를 가져와 반환""" import FinanceDataReader as fdr df = fdr.DataReader(ticker) latest = df.iloc[-1] return { "ticker": ticker, "date": latest.name.strftime("%Y-%m-%d"), "close": int(latest["Close"]), } # 3) MCP JSON‑RPC 서브 앱 생성 mcp_app = mcp.http_app( path="/", transport="http", stateless_http=True, json_response=True, ) # 4) 루트 FastAPI에 REST와 MCP를 마운트 root_app = FastAPI( title="Stock Trading Service with MCP", lifespan=mcp_app.lifespan, ) root_app.mount("/api", stock_api_app) root_app.mount("/mcp", mcp_app) @root_app.get("/") async def root() -> dict: return { "message": "Stock Trading Service with MCP", "api": "/api", "mcp": "/mcp", } return root_app app = create_app() if __name__ == "__main__": import uvicorn uvicorn.run("my_server:app", host="0.0.0.0", port=8888, reload=True)
3.3 my_client.py
사용자로부터 자연어 입력을 받아 LLM에 전달하고, Function calling 기반 응답을 분석하여 필요한 MCP 도구를 자동으로 호출합니다.
이를 위해 mcp_client()를 통해 MCP 서버와 통신하기 위한 클라이언트 객체를 생성하고, 이 객체로 tools/list 및 tools/call 명령을 수행합니다.
- load_tools(): MCP 서버에서 등록된 도구 목록을 조회하고, Chat Completions v3 API 요청 포맷에 맞게 변환
- call_llm(): Chat Completions v3 API를 호출해 사용자 질문에 대한 응답을 생성
- call_mcp_tool(): toolCall 응답을 기반으로 MCP 서버의 도구를 실행
아래 코드에서 CLOVA Studio API 호출을 위해 본인이 발급 받은 API Key를 입력하세요.
from fastmcp import Client from fastmcp.client.transports import StreamableHttpTransport import uuid import json import asyncio import requests from typing import Any, Dict, List # === CLOVA Studio 모델 엔드포인트 === MODEL_URL = "https://clovastudio.stream.ntruss.com/v3/chat-completions/HCX-005" MODEL_HEADERS = { "Authorization": "Bearer <YOUR_API_KEY>", # 실제 구현 시 Bearer 토큰을 환경 변수나 안전한 방법으로 관리하세요. "Content-Type": "application/json", } # === MCP 클라이언트 객체 정의 === transport = StreamableHttpTransport( url="http://localhost:8888/mcp/", headers={"X-Account-Password": "1234"} ) mcp_client = Client(transport) # === MCP에서 도구 스펙 받아와서 Function calling 포맷으로 변환 === async def load_tools(client: Client) -> List[Dict[str, Any]]: tools = await client.list_tools() tools_spec = [] for tool in tools: schema = tool.inputSchema or {} props = schema.get("properties", {}) if not props: continue tools_spec.append({ "type": "function", "function": { "name": tool.name, "description": tool.description or "", "parameters": { "type": schema.get("type", "object"), "properties": { k: { "type": p.get("type", "string"), "description": p.get("description", "") } for k, p in props.items() }, "required": schema.get("required", []) }, }, }) return tools_spec # === 모델 호출 === def call_llm(messages: List[Dict[str, Any]], tools_spec=None, tool_choice=None) -> Dict[str, Any]: data = {"messages": messages, "maxTokens": 1024, "seed": 0} if tools_spec: data["tools"] = tools_spec if tool_choice: data["toolChoice"] = tool_choice headers = MODEL_HEADERS | {"X-NCP-CLOVASTUDIO-REQUEST-ID": str(uuid.uuid4())} resp = requests.post(MODEL_URL, headers=headers, json=data) resp.raise_for_status() return resp.json() # === MCP 도구 실행 === async def call_mcp_tool(client: Client, name: str, args: Dict[str, Any]) -> Any: return await client.call_tool(name, args) # === main loop === async def main(): async with mcp_client as client: tools_spec = await load_tools(client) system_prompt = { "role": "system", "content": ( "당신은 사용자 주식 거래를 돕는 AI 어시스턴트입니다. " "매수·매도, 잔고 조회, 거래 내역 조회, 주가 조회를 처리하고 결과를 수치로 명확히 안내하세요. " "잔고·수량 부족 등 거래가 불가능하면 이유를 숫자와 함께 설명하세요." ), } while True: user_input = input("\n사용자 요청을 입력하세요: ") if user_input.lower() in {"exit", "quit", "종료"}: print("\n대화를 종료합니다.") break user_msg = {"role": "user", "content": user_input} first_resp = call_llm([system_prompt, user_msg], tools_spec=tools_spec, tool_choice="auto") if first_resp.get("status", {}).get("code") != "20000": print("\nLLM 호출 실패:", first_resp.get("status")) continue assistant_msg = first_resp["result"]["message"] tool_calls = assistant_msg.get("toolCalls", []) if not tool_calls: print("\n모델 답변:", assistant_msg.get("content", "")) continue tool_call = tool_calls[0] func_name = tool_call["function"]["name"] func_args = tool_call["function"]["arguments"] call_id = tool_call["id"] try: tool_result = await call_mcp_tool(client, func_name, func_args) except Exception as err: print("\nMCP 도구 실행 실패:", err) continue tool_response_prompt = { "role": "system", "content": ( "아래 tool 결과를 기반으로 간결하게 최종 답변을 작성하세요. " "'available_cash'는 현재 남은 현금 잔고, 'portfolio'는 종목별 보유 수량과 평균 단가입니다. " "수치는 단위와 함께 명확하게 표현하세요. (예: 3주, 1,000원)\n" "금액 해석 시 숫자의 자릿수를 기준으로 정확히 구분하세요." ), } second_resp = call_llm( [ tool_response_prompt, user_msg, {"role": "assistant", "content": "", "toolCalls": [tool_call]}, { "role": "tool", "toolCallId": call_id, "name": func_name, "content": json.dumps(tool_result.structured_content, ensure_ascii=False), }, ] ) if second_resp.get("status", {}).get("code") == "20000": print("\n모델 답변:", second_resp["result"]["message"]["content"]) else: print("\nLLM 호출 실패:", second_resp.get("status")) if __name__ == "__main__": asyncio.run(main())
4. 실행
다음 명령어를 서로 다른 터미널에서 순서대로 실행합니다.
uvicorn my_server:app --host 0.0.0.0 --port 8888 --reload
서버가 먼저 실행되어 있어야 클라이언트 호출을 정상적으로 수행할 수 있습니다.
python3 my_client.py
클라이언트에 자연어로 요청을 입력하면 모델 응답 결과가 반환됩니다. 다음은 응답 예시입니다.
사용자 요청을 입력하세요: 안녕 모델 답변: 안녕하세요! 저는 CLOVA X입니다. 주식 거래에 필요한 정보를 제공해 드리며, 다음과 같은 기능을 수행할 수 있습니다. 1. 매수/매도: 원하는 종목과 수량을 입력하시면 해당 종목을 매수하거나 매도합니다. 2. 잔고 조회: 현재 보유 중인 종목 및 수량 등을 확인할 수 있습니다. 3. 거래 내역 조회: 과거에 진행한 거래 내역을 조회하여 상세 내용을 확인 가능합니다. 4. 주가 조회: 특정 종목의 현재 가격을 실시간으로 조회할 수 있습니다. 언제든지 필요하신 부분이 있으시면 말씀해 주세요. 최대한 도움이 되도록 노력하겠습니다.사용자 요청을 입력하세요: 내 주식 계좌 잔고 조회해줘. 비번 1234 모델 답변: 현재 주식 계좌에 남아 있는 현금은 10,000,000원이며, 보유한 주식은 없습니다.사용자 요청을 입력하세요: 네이버 5주 매수해줘 모델 답변: 네이버 5주를 시장가 234,500원에 매수하였습니다. 현재 계좌에는 8,827,500원이 남아 있습니다.사용자 요청을 입력하세요: 네이버 주가 알려줘 모델 답변: 현재 네이버(035420)의 주가는 **235,000원**입니다.사용자 요청을 입력하세요: 네이버 1개 더 매수 모델 답변: 네이버 주식 1주를 시장가 235,000원에 매수하였습니다. 현재 계좌에는 8,592,500원이 남아 있습니다.사용자 요청을 입력하세요: 네이버 1개 팔아줘 모델 답변: 네이버 1주를 시장가 235,000원에 매도하였습니다. 현재 남아있는 현금은 8,827,500원입니다.사용자 요청을 입력하세요: 내 계좌 잔고 다시 조회해줘. 비번 1234 모델 답변: 현재 계좌에는 **8,827,500원**이 남아있으며, **NAVER 5주**를 보유하고 있습니다. - 종목코드: 035420 - 이름: NAVER - 평균단가: 234,583원사용자 요청을 입력하세요: 오늘 거래내역 표로 보여줘 모델 답변: 다음은 오늘(2025년 7월 31일) 거래 내역입니다. | 거래 유형 | 종목 이름 | 종목 코드 | 수량 | 가격 | 평균단가 | 거래 시간 | |------------|-----------|-----------|------|-------|----------|-----------| | 매수 | NAVER | 035420 | 5 | 234500 | 234500 | 15:16:21 | | 매수 | NAVER | 035420 | 1 | 235000 | 234583 | 15:16:43 | | 매도 | NAVER | 035420 | 1 | 235000 | 234583 | 15:17:30 | 총 2번의 매수와 1번의 매도가 있었습니다. NAVER 종목을 각각 5주와 1주씩 총 6주를 매수한 후, 1주를 매도하여 현재 NAVER 종목에 대한 보유 수량은 **5주**입니다.MCP 서버에 등록된 도구 목록 조회
다음 명령어를 실행하면 MCP 서버에 등록된 도구 목록을 조회할 수 있습니다.
curl -L -X POST http://localhost:8888/mcp/ \ -H "Content-Type: application/json" \ -H "Accept: application/json, text/event-stream" \ -d '{"jsonrpc":"2.0","id":1,"method":"tools/list","params":{}}'
{ "jsonrpc": "2.0", "id": 1, "result": { "tools": [ { "name": "buy_stock", "description": "주어진 종목을 지정한 수량만큼 매수합니다.", "inputSchema": { "type": "object", "properties": { "ticker": { "type": "string", "title": "Ticker", "description": "종목 코드 (예: 035420)" }, "qty": { "type": "integer", "exclusiveMinimum": 0, "title": "Qty", "description": "매수 또는 매도할 수량" } }, "required": ["ticker", "qty"] }, "outputSchema": { "type": "object", "title": "Response Buy Stock", "additionalProperties": true } }, { "name": "sell_stock", "description": "보유 종목을 지정한 수량만큼 매도합니다.", "inputSchema": { "type": "object", "properties": { "ticker": { "type": "string", "title": "Ticker", "description": "종목 코드 (예: 035420)" }, "qty": { "type": "integer", "exclusiveMinimum": 0, "title": "Qty", "description": "매수 또는 매도할 수량" } }, "required": ["ticker", "qty"] }, "outputSchema": { "type": "object", "title": "Response Sell Stock", "additionalProperties": true } }, { "name": "get_balance", "description": "현재 보유 현금과 포트폴리오를 반환합니다.", "inputSchema": { "type": "object", "properties": { "X-Account-Password": { "type": "string", "title": "X-Account-Password" } }, "required": ["X-Account-Password"] }, "outputSchema": { "type": "object", "title": "BalanceResponse", "required": ["available_cash", "portfolio"], "properties": { "available_cash": { "type": "integer", "title": "Available Cash", "description": "현금 잔고(원)" }, "portfolio": { "type": "object", "title": "Portfolio", "description": "종목별 보유 내역", "additionalProperties": true } } } }, { "name": "get_trade_history", "description": "지정 기간 동안의 거래 내역을 반환합니다.", "inputSchema": { "type": "object", "properties": { "start_date": { "anyOf": [ { "type": "string", "format": "date" }, { "type": "null" } ], "title": "Start Date" }, "end_date": { "anyOf": [ { "type": "string", "format": "date" }, { "type": "null" } ], "title": "End Date" } } }, "outputSchema": { "type": "object", "required": ["result"], "properties": { "result": { "type": "array", "title": "Response Get Trade History", "items": { "$ref": "#/$defs/TradeHistoryItem" } } }, "$defs": { "TradeHistoryItem": { "type": "object", "title": "TradeHistoryItem", "description": "거래 내역 항목.", "required": [ "type", "ticker", "qty", "price", "datetime" ], "properties": { "type": { "type": "string", "description": "거래 종류 (buy 또는 sell)" }, "name": { "anyOf": [ { "type": "string" }, { "type": "null" } ], "title": "Name" }, "ticker": { "type": "string", "title": "Ticker" }, "qty": { "type": "integer", "title": "Qty" }, "price": { "type": "integer", "title": "Price" }, "avg_price": { "anyOf": [ { "type": "integer" }, { "type": "null" } ], "title": "Avg Price" }, "datetime": { "type": "string", "title": "Datetime", "description": "거래 시각 (YYYY-MM-DD HH:MM:SS)" } } } }, "x-fastmcp-wrap-result": true } }, { "name": "root", "description": "서비스 안내", "inputSchema": { "type": "object", "properties": {}, "required": [] }, "outputSchema": { "type": "object", "additionalProperties": { "type": "string" } } }, { "name": "get_price", "description": "특정 종목의 최신 종가를 반환합니다.", "inputSchema": { "type": "object", "properties": { "ticker": { "type": "string", "title": "Ticker" } }, "required": ["ticker"] }, "outputSchema": { "type": "object", "additionalProperties": true } } ] } }
마무리
이번 예제는 FastMCP와 Function calling을 결합해, 사용자의 자연어 입력을 기반으로 LLM이 적절한 도구를 자동 선택하고 실행하는 전체 흐름을 구현해 보았습니다. 지정가 매수, 사용자별 계정 관리, 대화 히스토리 저장 등 다양한 방향으로 확장도 가능하니, 나만의 유용한 애플리케이션으로 발전시켜 보세요!
-
 1
1
-
-
@CHOI님 안녕하세요.
토큰 수 초과로 인해 발생한 오류는 아래 가이드를 참고하여 해결해 보실 수 있습니다.
https://guide.ncloud-docs.com/docs/clovastudio-skill#api-spec-확장-기능
또한, 데이터 수집 시 토큰 수를 합산하는 방식에 대해서는 아래 가이드를 참고해 주세요.
https://guide.ncloud-docs.com/docs/clovastudio-skilltrainer-faq#데이터-수집
그 외 추가 문의사항이 있으시면 언제든지 편하게 남겨 주세요.
감사합니다.
-
Postman Flows를 활용해 CLOVA Studio API와 외부 API를 시각적으로 연결하고, 실제 애플리케이션처럼 동작하는 워크플로우를 구현하는 방법을 소개합니다.
최근에는 Dify, n8n 등 GUI 기반의 노코드/로우코드 워크플로우 도구들이 등장하면서, 외부 서비스 연동, 조건 분기, LLM 활용 등 복합적인 작업을 시각적으로 구성할 수 있는 환경이 떠오르고 있습니다. 개발 경험이 없는 사용자도 손쉽게 자동화를 설계하고 실행할 수 있도록 돕는 것이 특징인데요,
Postman Flows 역시 이러한 흐름에 맞춘 노코드 도구로, API 요청을 시각적으로 연결해 복잡한 자동화 시나리오를 쉽게 구성할 수 있습니다. 이번 예제에서는 여러 API 호출을 순차적으로 연결해 하나의 자동화 시나리오를 완성해 보겠습니다.
1. 시나리오 소개
이번 예제에서는 회의 기록을 요약해 공유하고, 회의 중 나온 일정 정보를 자동으로 캘린더에 등록하는 흐름을 구성합니다.
이를 위해 CLOVA Studio의 Chat Completions V3 API와 Google Drive, Slack, Google Calendar API를 불러오고, 각 단계를 Postman Flows 상에서 시각적으로 연결하여 자동화를 구현합니다.
전체 흐름은 다음과 같습니다.
-
Google Drive에 저장된 회의록 파일을 불러옵니다.
-
Chat Completions V3 API를 통해 회의록을 요약하고, 동시에 회의 중 언급된 일정 및 액션 아이템을 추출합니다.
-
요약 결과는 Slack 메시지로 전송합니다.
-
추출된 일정 정보는 Google Calendar에 등록합니다.
2. 사전 준비
본 예제를 시작하기 전에, Google Drive, Google Calendar, Slack API를 연동하기 위한 인증 정보 발급 및 권한 설정 방법을 안내합니다.
2.1 Google Drive 및 Google Calendar API 준비
Google Drive API와 Google Calendar API를 활용하기 위한 설정 방법입니다. 두 API 모두 설정 방식이 동일하므로, 하나의 절차로 함께 안내합니다.
다음 과정에 대한 자세한 설명은 Google Cloud 가이드를 참고하세요.
- 먼저 Google API를 사용하려면 Google 계정이 필요하며, Google Cloud Console에 로그인할 수 있어야 합니다.
-
프로젝트 생성
- Google Cloud Console에 접속하여 상단의 [프로젝트 선택] 버튼을 클릭합니다.
- [새 프로젝트] 버튼을 클릭한 뒤, 필수 정보들을 입력하고 [만들기]를 클릭합니다.
-
API 활성화
- 좌측 메뉴에서 API 및 서비스 > 라이브러리로 이동합니다.
- Google Drive API, Google Docs API, Google Calendar API를 하나씩 검색하여 각 페이지에서 [사용] 버튼을 클릭해 활성화합니다. 참고로 Google Docs API는 직접 호출하지 않더라도, Google Drive API를 통해 문서 파일을 불러오기 위해서 함께 활성화가 필요합니다.
-
OAuth 동의 화면 구성
- 좌측 메뉴에서 API 및 서비스 > OAuth 동의 화면으로 이동합니다.
- [시작하기] 버튼을 클릭한 뒤, 앱 정보와 대상(반드시 외부로 설정), 연락처 정보를 입력하고 [만들기] 버튼을 클릭합니다.
-
OAuth 클라이언트 ID 생성
- 클라이언트 메뉴로 이동하여 [+ 클라이언트 만들기] 버튼을 클릭합니다.
- 애플리케이션 유형은 '웹 애플리케이션'을 선택하고, 하단의 승인된 리디렉션 URI 영역에 'https://oauth.pstmn.io/v1/callback'를 입력한 뒤 [만들기] 버튼을 클릭합니다.
- 생성된 클라이언트 ID와 보안 비밀번호를 복사해 둡니다.
-
테스트 사용자 등록
- 대상 메뉴로 이동하여 [+ Add users] 버튼을 클릭하고, 사용자 이메일(구글 계정)을 추가합니다.
2.2 Slack API 준비
Slack API를 활용하기 위한 설정 방법을 안내합니다.
다음 과정에 대한 자세한 설명은 Slack API 가이드를 참고하세요.
- Slack API를 사용하려면 Slack 계정이 필요하며, 사전에 워크스페이스와 채널이 생성되어 있어야 합니다.
-
앱 생성
- Slack API에 접속하여 [Create an App] 버튼을 클릭하고, 팝업이 나타나면 [From scratch]을 선택합니다.
- 필수 정보를 입력한 뒤 [Create App] 버튼을 클릭합니다.
-
OAuth 권한 설정
- 생성한 앱을 클릭한 뒤, 좌측 메뉴에서 OAuth & Permissions로 이동합니다.
- Scopes 영역으로 내려가 User Token Scopes에서 [Add an OAuth Scope] 버튼을 클릭한 뒤, 'calls: write' 권한을 추가합니다.
- OAuth Tokens 영역에서 [Install to Workspace] 버튼을 클릭하고, 발급된 토큰을 복사해 둡니다.
- Redirect URLs 영역에서 [Add New Redirect URL] 버튼을 클릭하고, 'https://oauth.pstmn.io/v1/callback'를 입력한 뒤 [Add] 버튼, [Save URLs] 버튼을 차례대로 클릭합니다.
3. API 구성
이번 단계에서는 이후 Flow 생성을 위해 Postman에서 Google Drive, Google Calendar, Slack API 요청을 사전에 구성하는 작업을 안내합니다.
아래의 Postman Collection 파일에는 본 예제에 사용되는 API 정보가 포함되어 있습니다. 좌측의 Collections 탭을 선택한 후 [Import] 버튼을 클릭하여 업로드할 수 있습니다.
[Cookbook] Postman_example_collection.json
3.1 및 3.2 단계에서 필요한 인증은 아래 공통 절차를 참고하여 구성해 주세요.
QuoteGoogle Drive 및 Calendar API 인증 절차
- Postman에서 새 Collection 및 Request를 생성한 뒤, Authorization 탭으로 이동합니다.
- Auth Type을 OAuth 2.0으로 설정합니다.
- 2.1 Google Drive 및 Google Calendar API 준비 단계에서 발급 받은 Client ID와 Client Secret을 입력합니다.
-
Scope 입력란에 아래 값을 공백으로 구분된 한 줄로 입력합니다. 줄바꿈 없이 공백 하나로만 구분해야 하며, 쉼표나 개행이 포함되면 인증이 실패할 수 있습니다.
https://www.googleapis.com/auth/drive https://www.googleapis.com/auth/documents https://www.googleapis.com/auth/calendar https://www.googleapis.com/auth/userinfo.email https://www.googleapis.com/auth/userinfo.profile
- [Get New Access Token] 버튼을 클릭하여 인증을 진행합니다.
- 팝업 화면이 나타나면 [Use Token] 버튼을 클릭하여 요청에 적용합니다.
3.1 Google Drive API
파일 이름을 기준으로 파일 ID를 검색한 뒤, 해당 파일 ID를 이용해 파일 내용을 조회하는 흐름을 구성합니다.
API 명세에 대한 자세한 설명은 Google Drive API 가이드에서 확인 할 수 있습니다.
3.1.1 파일 ID 조회
먼저, 파일 이름으로 파일 ID를 조회하는 요청을 구성합니다.
- Postman 화면의 좌측 메뉴에서 Collections을 클릭한 후, 상단의 [New] 버튼을 클릭하여 새로운 HTTP 요청을 생성합니다.
-
다음과 같이 요청 정보를 입력합니다:
Quote
-
Method
- GET
-
요청 URL
- https://www.googleapis.com/drive/v3/files?q=name contains '{{fileName}}' and mimeType='application/vnd.google-apps.document'&fields=files(id,name,createdTime,modifiedTime)
- {{fileName}}은 flow에서 앞 단계의 결과로 설정되는 변수이며, 실행 시 실제 값으로 자동 치환되어 요청에 사용됩니다.
-
Authorization
- Google Drive 및 Calendar API 인증 절차를 따라 적용합니다.
-
Method
3.1.2 파일 콘텐츠 조회
다음은 조회한 파일 ID를 기반으로 해당 문서의 본문 내용을 불러오는 요청입니다.
- Postman 화면의 좌측 메뉴에서 Collections을 클릭한 후, 상단의 [New] 버튼을 클릭하여 새로운 HTTP 요청을 생성합니다.
-
다음과 같이 요청 정보를 입력합니다:
Quote
-
Method
- GET
-
요청 URL
- https://www.googleapis.com/drive/v3/files/{{file_ID}}/export?mimeType=text/plain
- {{fileID}}는 flow에서 앞 단계의 결과로 설정되는 변수이며, 실행 시 실제 값으로 자동 치환되어 요청에 사용됩니다.
-
Authorization
- Google Drive 및 Calendar API 인증 절차를 따라 적용합니다.
-
Method
3.2 Google Calendar API
Google Calendar에 새 이벤트를 생성하는 요청을 구성합니다. calendarID는 Google Calendar 웹 화면에서 [설정 > 캘린더 통합] 메뉴를 통해 확인할 수 있습니다.
API 명세에 대한 자세한 설명은 Google Calendar API 가이드에서 확인 할 수 있습니다.
- Postman 화면의 좌측 메뉴에서 Collections을 클릭한 후, 상단의 [New] 버튼을 클릭하여 새로운 HTTP 요청을 생성합니다.
-
다음과 같이 요청 정보를 입력합니다:
Quote
-
Method
- POST
-
요청 URL
- https://www.googleapis.com/calendar/v3/calendars/{{calendarID}}/events
- {{calendarID}}는 이후 flow 블록 내 변수 입력란에서 사용자가 직접 값을 입력해야 합니다.
-
Authorization
- Google Drive 및 Calendar API 인증 절차를 따라 적용합니다.
-
Body(raw)
-
{ "summary": "{{eventSummary}}", "location": "{{eventLocation}}", "description": "{{eventDescription}}", "start": { "dateTime": "{{eventStartTime}}", "timeZone": "Asia/Seoul" }, "end": { "dateTime": "{{eventEndTime}}", "timeZone": "Asia/Seoul" }, "reminders": { "useDefault": true } }
-
-
Method
3.3 Slack 메시지 전송 API
Slack 채널에 메시지를 전송하는 요청을 구성합니다.
API 명세에 대한 자세한 설명은 Slack API 가이드(#chat.postMessage)에서 확인 할 수 있습니다.
- Postman 화면의 좌측 메뉴에서 Collections을 클릭한 후, 상단의 [New] 버튼을 클릭하여 새로운 HTTP 요청을 생성합니다.
-
다음과 같이 요청 정보를 입력합니다:
Quote
-
Method
- POST
- 요청 URL
-
Authorization
- Auth Type을 Bearer Token으로 설정한 뒤, 2-2. Slack API 준비 단계에서 발급 받은 토큰을 입력합니다.
-
Body(raw)
-
{ "channel": "{{channelID}}", "text": "{{summaryContent}}" } - {{channelID}}는 이후 flow 블록 내 변수 입력란에서 사용자가 직접 값을 입력해야 합니다.
- {{summaryContent}}는 flow에서 앞 단계의 결과로 설정되는 변수이며, 실행 시 실제 값으로 자동 치환되어 요청에 사용됩니다.
-
-
Method
3.4 Chat Completions V3 API
회의록 요약을 생성하고 캘린더 일정을 추출하는 LLM 요청을 생성합니다.
API 명세에 대한 자세한 설명은 CLOVA Studio API 가이드에서 확인 할 수 있습니다.
- Postman 화면의 좌측 메뉴에서 Collections을 클릭한 후, 상단의 [New] 버튼을 클릭하여 새로운 HTTP 요청을 생성합니다.
-
다음과 같이 요청 정보를 입력합니다:
Quote
-
Method
- POST
- 요청 URL
-
Authorization
- CLOVA Studio API 가이드에 따라 인증 정보를 발급 받고 설정합니다.
-
Body(raw)
-
{ "messages": [ { "role": "system", "content": "당신은 사용자의 회의록을 요약하고, 해당 내용을 기반으로 다음 회의 일정을 등록해주는 유용한 비서입니다. 아래 지침을 따라 *postSlack*과 *createCalendar* 함수를 반드시 모두 호출하세요.\n\n1단계: 회의록을 요약한 뒤, postSlack 함수를 호출하세요.\n요약 형식은 다음과 같습니다:\n- 첫 줄: '*📌YYYY년 M월 D일 회의록*' 형식의 굵은 텍스트\n- 둘째 줄: '*회의 주제: ○○○*' 형식으로 간단히 주제 요약\n- 셋째 줄부터: '•' 기호로 시작하는 리스트 항목으로 주요 내용을 정리합니다.\n - 각 항목의 첫 줄(주제 제목)은 강조하고, 그 아래에 관련 내용을 이어서 작성하세요.\n - 필요한 경우 담당자를 괄호로 함께 명시하고, 문장은 간결하고 자연스럽게 서술형으로 작성하세요.\n\n2단계: 회의 내용 중 일정 등록이 필요한 항목을 식별하여 createCalendar 함수를 호출하세요.\n\n두 함수는 모두 반드시 호출해야 하며, 순서를 지켜 실행해 주세요." }, { "role": "user", "content": "{{input}}" } ], "topP": 0.8, "topK": 0, "maxTokens": 2048, "temperature": 0.5, "repetitionPenalty": 1.1, "stop": [ ], "includeAiFilters": true, "seed": 42, "tool_choice": "auto", "tools": [ { "type": "function", "function": { "name": "postSlack", "description": "제공된 회의 요약 내용을 슬랙 채널에 메시지로 업로드합니다.", "parameters": { "type": "object", "properties": { "summaryContent": { "description": "슬랙에 메시지로 업로드 될 요약 된 회의 내용 입니다.", "type": "string" } }, "required": ["summaryContent"] } } }, { "type": "function", "function": { "name": "createCalendar", "description": "회의록 내용을 꼼꼼히 참고하여 다음 일정에 대한 Google Calendar 이벤트를 생성합니다.", "parameters": { "type": "object", "properties": { "eventSummary": { "description": "생성하고자하는 이벤트 일정의 제목입니다. (기본값은 '회의' 입니다.)", "type": "string" }, "eventStartTime": { "description": "생성할 이벤트의 시작 시간 입니다(ISO 8601 형식, YYYY-MM-DDTHH:MM:SS+09:00).", "type": "string" }, "eventDescription": { "description": "생성할 이벤트의 상세 내용 입니다.(기본값은 '' 입니다.)", "type": "string" }, "eventEndTime": { "description": "생성할 이벤트의 시작 시간 입니다.(ISO 8601 형식, YYYY-MM-DDTHH:MM:SS+09:00).", "type": "string" }, "eventLocation": { "description": "생성할 이벤트의 장소 입니다. (기본값은 '온라인 미팅' 입니다.)", "type": "string" } }, "required": ["eventStartTime", "eventEndTime"] } } } ] } - {{input}}은 flow에서 앞 단계의 결과로 설정되는 변수이며, 실행 시 실제 값으로 자동 치환되어 요청에 사용됩니다.
-
-
Method
4. Flow 구현 및 테스트
이제 각 API를 연동하여 전체 자동화 흐름을 구성합니다.
Google Drive에서 회의 기록을 불러오고, Chat completions API로 주요 내용을 요약한 뒤, Function calling 기능을 통해 Slack에 메시지를 전송하고 Google Calendar에 일정을 등록하는 흐름을 단계별로 구현합니다.
4.1 Flow 생성
다음 절차에 따라 flow를 생성합니다.
- Postman을 실행한 후 좌측 메뉴에서 Flows를 클릭한 후, 상단의 [New] 버튼을 클릭합니다.
-
하단에 [+ Block] 버튼을 클릭하여 원하는 블록을 생성합니다. 본 쿡북 예제에서 사용되는 블록 유형은 다음과 같습니다:
- 마우스로 드래그하여 블록 간 연결을 구현합니다. 4.2 Flow 실행 화면을 따라서 구현하세요.
- 연결이 완료되면 우측 Scenarios 메뉴를 클릭한 뒤, [+ Create scenario 버튼]을 클릭하여 회의 기록이 저장된 Google Drive의 파일명을 입력하여 저장합니다.
- [Run] 버튼을 클릭하여 전체 워크플로우를 실행합니다. 정상적으로 실행되면, 마지막 Display 블록에 성공 문구가 노출됩니다.
4.2 실행 화면
완성된 flow 및 시나리오 테스트 결과입니다.
4.3 실행 결과
시나리오에 활용된 회의 기록 및 Slack 및 Google Calendar 자동 전송 결과입니다. 회의 기록은 임의로 생성한 가상의 데이터입니다.
5. 맺음말
이번 쿡북에서는 LLM과 외부 서비스를 연동해 회의록 요약과 일정 등록 시나리오를 구현해 보았습니다.
Postman Flows와 CLOVA Studio API를 활용하면, 실제 업무에 필요한 자동화를 노코드로 손쉽게 만들 수 있다는 점을 확인하셨을 텐데요. 이와 같은 흐름은 다양한 워크플로우로 확장할 수 있습니다. 예를 들어, 라우터와 스킬셋, Chat completions API 등을 조합해 나만의 AI 에이전트를 만들거나, 여러 LLM API를 연결해 응답을 비교·평가하는 인터페이스를 구현할 수 있습니다. 또는 Function calling을 통해 사용자의 자연어 입력을 SQL로 변환한 뒤, 로그 데이터를 조회하고 결과를 차트로 시각화하는 데이터 분석 도구로 확장해 볼 수도 있습니다.
이번 예제를 바탕으로 여러분의 아이디어와 업무 흐름에 맞는 자동화 시나리오를 자유롭게 설계해 보시기 바랍니다!
-
-
들어가며
이 쿡북에서는 Streamlit을 활용해 스킬 트레이너의 스킬셋과 라우터, 그리고 Chat Completions API를 결합하여 간단하게 AI 에이전트를 구축하는 방법을 알아보겠습니다.
다음 가이드를 따라 지역 검색 AI 에이전트를 직접 만들어 보고, 자신만의 AI 에이전트를 제작해 보세요! 🚀
QuoteStreamilt이란?
Python을 활용해 앱을 빠르고 쉽게 만들 수 있게 도와주는 오픈 소스 앱버전 정보
Python 3.9.6; Streamlit 1.39.0
전체 구조
각 기능별로 파일을 나누어 관리합니다. 스킬셋, 라우터, 그리고 Chat Completions와 같은 API 기능들을 별도의 파일로 만들어 필요할 때마다 불러와 사용할 수 있도록 구성하고,
main.py파일에서 이 모든 파일을 연결해서 실행할 수 있습니다.project/ │ ├── config.py # API 인증 정보를 관리합니다. ├── router.py # 라우터 API를 호출하여 사용자의 요청을 분류 및 필터링 합니다. ├── skillset.py # 스킬셋 API를 호출하여 답변을 생성합니다. ├── chat_completions.py # Chat Completions API를 호출하여 답변을 생성합니다. ├── chat_utils.py # 공통적으로 사용되는 유틸리티 함수를 관리합니다. └── main.py # Streamlit을 활용한 메인 앱 실행 파일입니다.
에이전트 워크플로우
본 쿡북에서는 지역 검색 에이전트를 제작합니다. 지역 검색 에이전트를 구성하는 주요 요소에 대한 제작 가이드는 다음 링크를 참고해 주세요.
- 지역 검색 스킬셋의 라우터: https://guide.ncloud-docs.com/docs/clovastudio-router-usecase
- 지역 검색 스킬셋: https://guide.ncloud-docs.com/docs/clovastudio-skilltrainer-usecase
- Chat Completions: https://api.ncloud-docs.com/docs/clovastudio-chatcompletions
사용자가 입력한 내용은 먼저 라우터에서 검토됩니다. 라우터는 사용자의 요청을 분석하여 적합한 도구(스킬셋 또는 Chat Completions)를 선택합니다. 이 과정에서 안전하지 않거나 부적절한 요청은 필터링되어 고정 응답이 반환됩니다. 스킬셋이 호출되면, 해당 스킬셋 내에 정의된 스킬(API)을 통해 실시간으로 데이터를 가져와 답변을 생성합니다. 반면, Chat Completions이 호출되면, 설정된 시스템 프롬프트와 파라미터 값에 기반하여 LLM이 답변을 생성합니다.
환경 설정
1. 필요한 라이브러리 설치
프로젝트를 시작하기 전에 필요한 Python 라이브러리를 설치합니다.
pip install streamlit requests2. API 키 설정
config.py파일에서 API 호출 경로 및 인증 정보를 관리합니다. 아래 코드의 값 부분에 연동하고자 하는 라우터 및 스킬셋의 경로와 발급 받은 본인의 API 인증 정보를 넣어주세요. API Key는 절대 소스 코드에 노출되지 않도록 주의하세요. 환경 변수나 별도의 설정 파일을 사용하여 관리하는 것을 추천합니다.class Config: # 지역 검색의 라우터 호출 경로 ROUTER_API = 'YOUR_API_URL' # 지역 검색 스킬셋 호출 경로 SKILLSET_API = 'YOUR_API_URL' # 지역 검색 스킬셋에 정의된 스킬(API)의 인증 정보 NAVER_LOCAL_CLIENT_ID = 'YOUR_NAVER_CLIENT_ID' NAVER_LOCAL_CLIENT_SECRET = 'YOUR_NAVER_CLIENT_SECRET' # Chat Completions 호출 경로 CHAT_COMPLETIONS_API = 'YOUR_API_URL' # CLOVA Studio API 인증 정보 API_KEY = 'YOUR_API_KEY' REQUEST_ID_ROUTER = 'YOUR_REQUEST_ID' REQUEST_ID_SKILLSET = 'YOUR_REQUEST_ID' REQUEST_ID_CHAT = 'YOUR_REQUEST_ID'
각 모듈 설명
1. 라우터 API 호출: router.py
라우터는 사용자의 입력 내용을 분석하여, 어떤 도구를 사용해야 할지 결정하고(도메인 분류) 부적절한 내용을 감지(필터링)합니다.
import requests from config import Config def get_router(query, chat_history=None): url = Config.ROUTER_API headers = { 'Authorization': f'Bearer {Config.API_KEY}', 'X-NCP-CLOVASTUDIO-REQUEST-ID': f'{Config.REQUEST_ID_ROUTER}', 'Content-Type': 'application/json' } data = { 'query': query } if chat_history and len(chat_history) >= 3: # 직전 user 턴의 발화를 가져옵니다. filtered_chat_history = chat_history[-3] data['chatHistory'] = [filtered_chat_history] response = requests.post(url, headers=headers, json=data) return response.json()
2. 스킬셋 API 호출: skillset.py
지역 검색 스킬셋 API를 호출하여 실시간 검색 데이터를 기반으로 한 답변을 생성합니다.
import requests from config import Config def get_skillset(query, chat_history=None): url = Config.SKILLSET_API headers = { 'Authorization': f'Bearer {Config.API_KEY}', 'X-NCP-CLOVASTUDIO-REQUEST-ID': f'{Config.REQUEST_ID_SKILLSET}', 'Content-Type': 'application/json', } data = { 'query': query, 'requestOverride': { 'baseOperation': { 'header': { 'X-Naver-Client-Id': Config.NAVER_LOCAL_CLIENT_ID, 'X-Naver-Client-Secret': Config.NAVER_LOCAL_CLIENT_SECRET } } } } if chat_history: # 직전 user 턴의 발화 및 assistant 턴의 답변을 가져옵니다. filtered_chat_history = chat_history[-3:-1] data['chatHistory'] = filtered_chat_history response = requests.post(url, headers=headers, json=data) return response.json()
3. Chat Completions API 호출: chat_completions.py
시스템 프롬프트 및 파라미터 값과 함께 Chat Completions API를 호출하여 유연한 대화 흐름을 이끌어 줄 수 있는 답변을 생성합니다.
import requests from config import Config def get_chat_response(query, chat_history=None): url = Config.CHAT_COMPLETIONS_API headers = { 'Authorization': f'Bearer {Config.API_KEY}', 'X-NCP-CLOVASTUDIO-REQUEST-ID': f'{Config.REQUEST_ID_CHAT}', 'Content-Type': 'application/json', } system_prompt = """[1. 지시문]\n당신에 대해 소개할 때는 [1-1. 아이덴티티]의 내용을 기반으로 말하세요.\n만약 당신에게 \"어떻게 질문하면 돼?\", \"어떤식으로 물어보면 돼?\", \"어떻게 질문하면 되는걸까요?\", \"사용방법 알려줘', \"사용방법 안내해 주세요\", \"사용방법을 알려줄 수 있을까요?\", \"사용방법 자세하게 알려줘\" 등과 같이 질문 방법에 대해 문의할 경우, 당신은 반드시 아래의 [1-2. 핵심 기능]과 [1-3. 예시 질문]에 관한 내용만을 응답해야 합니다. 반드시 아래에 제공된 정보만을 사용해야 하며, 주어지지 않은 정보를 임의로 생성하거나 추가하면 절대로 안 됩니다. \n\n[1-1. 아이덴티티]\n- 당신은 **실시간 장소 탐색 AI 에이전트**입니다.\n- 당신을 만든 곳은 Skill팀입니다. \b\n- 스킬셋 및 라우터 기능을 결합한 데모로 당신이 제작되었습니다. \n- 당신은 특정 지역의 맛집, 카페, 명소 등을 추천해 줄 수 있습니다.\n\n[1-2. 핵심 기능]\n지역 검색 : 사용자가 지역과 키워드를 바탕으로 질문하면(예: \"[특정 지역] 근처 맛집 추천해줘\") 네이버 지역 서비스에 등록된 정보를 기반으로 다양한 장소를 추천합니다.\n2) 유연한 대화 : 사용자의 질문 의도를 파악하고 다양한 표현으로 질문해도 정확하게 이해합니다.\n\n[1-3. 예시 질문]\n1)[지역]+[키워드] 추천해줘 (예: \"[특정 지역] 맛집 추천해줘\")\n\n[2. 지시문]\n만약 아래의 [2-1. 제한 사항]에 관련한 요청이 들어오면 답변이 불가능한 이유를 충분히 설명하고, 반드시 [1-2. 핵심 기능]과 [2-2. 예시]을 참고하여 적극적으로 대체 질문을 제안하거나 유도하세요.\n\n[2-1. 제한 사항]\n- 장소 탐색과 관련이 없는 실시간 정보 : 날씨, 주가, 시세 등의 정보에는 답변할 수 없습니다. \n- 지나치게 주관적인 질문 : 개인적인 취향에 대한 질문에는 답변하기 어렵습니다.\n\n[2-2. 예시]\n- 죄송합니다, 해당 정보는 제공할 수 없습니다. 대신 \"서울에서 가볼 만한 장소를 추천해줘\"와 같은 질문을 해 보시는 것도 좋을 것 같아요!\n- 대신 다른 정보를 도와드릴 수 있어요! 예를 들어, \"정자역 근처 맛집을 추천해줘\"와 같은 질문을 해 보시는 건 어떨까요?\n- 저는 실시간 장소 탐색 AI 에이전트이기 때문에 해당 정보는 제공할 수 없지만, 다른 정보가 궁금하시면 말씀해 주세요! 예를 들어, \”\강남역 카페 추천\”과 같은 질문은 어떠세요?""" messages = [{'role': 'system', 'content': system_prompt}] if chat_history: messages.extend(chat_history[-3:]) else: messages.append({'role': 'user', 'content': query}) data = { 'messages': messages, "maxTokens": 512, "seed": 0, "temperature": 0.4, "topP": 0.4, "topK": 0, "repeatPenalty": 5.0 } response = requests.post(url, headers=headers, json=data) return response.json()
4. 유틸리티 함수: chat_utils.py
공통적으로 사용되는 유틸리티 함수를 정리합니다. 본 쿡북에서는 응답 텍스트를 단어 단위로 스트리밍하여 출력하는 함수를 정의하였습니다.
import time def streaming_data(text): for word in text.split(" "): yield word + " " time.sleep(0.05)
5. Streamlit 메인 앱 실행: main.py
Streamlit을 활용한 메인 앱 실행 모듈입니다. 사용자 입력이 들어오면, 반드시 라우터를 거쳐 처리 방식을 결정하게 되고, 결과에 따라 스킬셋 답변이나 Chat Completions 답변, 고정 응답이 반환됩니다. display_response 함수를 통해 UI 상에 답변을 노출하고 대화 세션을 업데이트 합니다.
import streamlit as st from router import get_router from chat_utils import streaming_data from chat_completions import get_chat_response from skillset import get_skillset def initialize_chat_session(): """에이전트 세션 초기화""" if 'messages' not in st.session_state: st.session_state.messages = [ { 'role': 'assistant', 'content': '안녕하세요. 장소 탐색 AI Agent입니다.😃 \n\n어떤 곳을 찾고 계신가요? 궁금하신 장소 정보가 있다면 언제든지 말씀해 주세요.' } ] def render_initial_messages(): """메시지 렌더링""" with st.chat_message(st.session_state.messages[0]['role']): st.write(st.session_state.messages[0]['content']) for message in st.session_state.messages[1:]: with st.chat_message(message['role']): st.write(message['content']) def display_response(final_answer): """응답 표시 및 세션 상태 업데이트""" with st.chat_message('assistant'): st.write_stream(streaming_data(final_answer)) st.session_state.messages.append({'role': 'assistant', 'content': final_answer}) def process_router(query, chat_history): """라우터 호출""" with st.status("라우터 적용 중...", expanded=True) as router_status: process_view = st.empty() process_view.write("라우터 적용 중입니다.") router_result = get_router(query, chat_history) domain = router_result.get('result', {}).get('domain', {}).get('result', '') blocked_content = router_result.get('result', {}).get('blockedContent', {}).get('result', []) safety = router_result.get('result', {}).get('safety', {}).get('result', []) return domain, blocked_content, safety, router_status, process_view def generate_skillset_response(query, chat_history): """지역 검색 스킬셋 응답 생성""" with st.status("답변 생성 중...", expanded=True) as answer_status: process_view = st.empty() process_view.write("API를 호출하고 답변을 생성하는 중입니다. 잠시만 기다려주세요.") result = get_skillset(query, chat_history) final_answer = result.get('result', {}).get('finalAnswer', '답변을 생성할 수 없습니다.') process_view.write("답변 생성이 완료되었습니다.") answer_status.update(label="답변 생성 완료", state="complete", expanded=False) return final_answer def generate_chat_response(query, chat_history): """chat_completions 응답 생성""" with st.status("답변 생성 중...", expanded=True) as answer_status: process_view = st.empty() process_view.write("요청하신 내용에 대한 답변을 생성 중입니다. 잠시만 기다려주세요.") result = get_chat_response(query, chat_history) final_answer = result.get('result', {}).get('message', {}).get('content', '답변을 생성할 수 없습니다.') process_view.write("답변 생성이 완료되었습니다.") answer_status.update(label="답변 생성 완료", state="complete", expanded=False) return final_answer def generate_filtered_response(filter_type): """고정 응답""" if filter_type == 'content': return ( "**콘텐츠 필터 규정**에 따라, 해당 질문에는 답변을 제공해 드리기 어려운 점 양해 부탁드려요.\n\n" "혹시 이렇게 질문해 보시는 건 어떠실까요? :)\n" "- 경기도 가을 단풍 명소 추천해 주세요.\n" "- 제주도 애월 맛집과 카페" ) else: # safety filter return ( '**안전 관련 규정**에 따라, 해당 질문에는 답변을 제공해 드리기 어려운 점 양해 부탁드려요.\n\n' '혹시 이렇게 질문해 보시는 건 어떠실까요?\n' '- 부산에서 인기 있는 맛집 찾아줄래?\n' '- 서울 분위기 좋은 카페 추천\n' '- 티엔미미 인기 메뉴 알려주세요\n\n' '언제나 좋은 정보로 도움 드리고자 합니다. 필요하신 내용이 있으시면 편하게 말씀해 주세요! 😊' ) def main(): st.set_page_config(page_title="장소 탐색 에이전트") st.title('장소 탐색 에이전트', anchor=False) st.write(' ') initialize_chat_session() render_initial_messages() if query := st.chat_input('질문을 입력하세요.'): with st.chat_message('user'): st.write(query) st.session_state.messages.append({'role': 'user', 'content': query}) chat_history = [{'role': msg['role'], 'content': msg['content']} for msg in st.session_state.messages] domain, blocked_content, safety, router_status, process_view = process_router(query, chat_history) router_status.update(label="라우터 적용 중...", state="running", expanded=True) if domain == "지역 검색": if not blocked_content and not safety: process_view.write("지역 검색 스킬셋으로 처리 가능합니다.") router_status.update(label="라우터 적용 완료", state="complete", expanded=False) final_answer = generate_skillset_response(query, chat_history) display_response(final_answer) elif blocked_content and not safety: process_view.write("스킬셋 사용이 불가능합니다. (이유 : 콘텐츠 필터)") router_status.update(label="라우터 적용 완료", state="complete", expanded=False) final_answer = generate_filtered_response('content') display_response(final_answer) else: process_view.write("스킬셋 사용이 불가능합니다. (이유 : 세이프티 필터)") router_status.update(label="라우터 적용 완료", state="complete", expanded=False) final_answer = generate_filtered_response('safety') display_response(final_answer) else: process_view.write("스킬셋과 관련 없는 요청입니다.") router_status.update(label="라우터 적용 완료", state="complete", expanded=False) final_answer = generate_chat_response(query, chat_history) display_response(final_answer) if __name__ == '__main__': main()
main.py 상세 설명
main.py 파일의 구조를 자세히 살펴보면 에이전트가 어떻게 작동하는지 깊이 이해할 수 있고, 필요에 따라 해당 파일을 통해 에이전트의 기능을 추가로 커스텀 할 수 있습니다.
Quote1. 대화 세션 및 상태 관리
Streamlit 대화 세션 상태를 관리하고 메시지를 렌더링 합니다.
# 세션 상태에 메시지 기록이 없을 경우 초기화 def initialize_chat_session(): if 'messages' not in st.session_state: st.session_state.messages = [ { 'role': 'assistant', 'content': '안녕하세요. 장소 탐색 AI Agent입니다.😃 \n\n어떤 곳을 찾고 계신가요? 궁금하신 장소 정보가 있다면 언제든지 말씀해 주세요.' } ] # 세션 상태에 저장된 메시지들을 화면에 출력 def render_initial_messages(): with st.chat_message(st.session_state.messages[0]['role']): st.write(st.session_state.messages[0]['content']) for message in st.session_state.messages[1:]: with st.chat_message(message['role']): st.write(message['content']) # 생성된 응답을 화면에 표시하고 세션 상태에 업데이트 def display_response(final_answer): with st.chat_message('assistant'): st.write_stream(streaming_data(final_answer)) st.session_state.messages.append({'role': 'assistant', 'content': final_answer})
2. 라우터 호출
get_router 함수를 통해 라우터 API를 호출하고, 반환된 결과에서 도메인, 콘텐츠 필터, 세이프티 필터 결과를 추출합니다. 그리고 st.status와 process_view를 활용하여 Streamlit UI 상에서 사용자에게 처리 상태를 시각적으로 표시해 줍니다.
def process_router(query, chat_history): with st.status("라우터 적용 중...", expanded=True) as router_status: process_view = st.empty() process_view.write("라우터 적용 중입니다.") router_result = get_router(query, chat_history) domain = router_result.get('result', {}).get('domain', {}).get('result', '') blocked_content = router_result.get('result', {}).get('blockedContent', {}).get('result', []) safety = router_result.get('result', {}).get('safety', {}).get('result', []) return domain, blocked_content, safety, router_status, process_view3. 지역 검색 스킬셋 응답 생성
get_skillset 함수를 통해 지역 검색 스킬셋 API를 호출하고, 반환된 결과에서 최종 답변만을 추출합니다.
def generate_skillset_response(query, chat_history): with st.status("답변 생성 중...", expanded=True) as answer_status: process_view = st.empty() process_view.write("API를 호출하고 답변을 생성하는 중입니다. 잠시만 기다려주세요.") result = get_skillset(query, chat_history) final_answer = result.get('result', {}).get('finalAnswer') process_view.write("답변 생성이 완료되었습니다.") answer_status.update(label="답변 생성 완료", state="complete", expanded=False) return final_answer
4. Chat Completions 응답 생성
get_chat_response 함수를 통해 Chat Completion API를 호출하고, 반환된 결과에서 message의 content만을 추출하여 최종 답변으로 사용합니다.
def generate_chat_response(query, chat_history): with st.status("답변 생성 중...", expanded=True) as answer_status: process_view = st.empty() process_view.write("요청하신 내용에 대한 답변을 생성 중입니다. 잠시만 기다려주세요.") result = get_chat_response(query, chat_history) final_answer = result.get('result', {}).get('message', {}).get('content') process_view.write("답변 생성이 완료되었습니다.") answer_status.update(label="답변 생성 완료", state="complete", expanded=False) return final_answer
5. 고정 응답 반환
filter_type(콘텐츠 필터, 세이프티 필터)에 따라 고정으로 반환될 적절한 답변을 각각 정의합니다.
def generate_filtered_response(filter_type): if filter_type == 'content': return ( "**콘텐츠 필터 규정**에 따라, 해당 질문에는 답변을 제공해 드리기 어려운 점 양해 부탁드려요.\n\n" "혹시 이렇게 질문해 보시는 건 어떠실까요? :)\n" "- 경기도 가을 단풍 명소 추천해 주세요.\n" "- 제주도 애월 맛집과 카페" ) else: # safety filter return ( '**안전 관련 규정**에 따라, 해당 질문에는 답변을 제공해 드리기 어려운 점 양해 부탁드려요.\n\n' '혹시 이렇게 질문해 보시는 건 어떠실까요?\n' '- 부산에서 인기 있는 맛집 찾아줄래?\n' '- 서울 분위기 좋은 카페 추천\n' '- 티엔미미 인기 메뉴 알려주세요\n\n' '언제나 좋은 정보로 도움 드리고자 합니다. 필요하신 내용이 있으시면 편하게 말씀해 주세요! 😊'
6. main 함수
Streamlit 앱의 메인 로직은 초기 설정, 사용자 입력 처리, 그리고 라우터 호출 및 응답 처리로 구성됩니다.
사용자의 질문을 받아 대화 이력을 업데이트 한 뒤, process_router 함수를 통해 조건별로 응답 처리 방식을 분기합니다. 응답이 결정되면 최종적으로 display_response 함수를 사용하여 생성된 응답을 화면 상에 노출시키고 대화 이력을 업데이트 합니다.
def main(): st.set_page_config(page_title="장소 탐색 에이전트") st.title('장소 탐색 에이전트', anchor=False) initialize_chat_session() render_initial_messages() if query := st.chat_input('질문을 입력하세요.'): with st.chat_message('user'): st.write(query) st.session_state.messages.append({'role': 'user', 'content': query}) chat_history = [{'role': msg['role'], 'content': msg['content']} for msg in st.session_state.messages] domain, blocked_content, safety, router_status, process_view = process_router(query, chat_history) router_status.update(label="라우터 적용 중...", state="running", expanded=True) if domain == "지역 검색": if not blocked_content and not safety: process_view.write("지역 검색 스킬셋으로 처리 가능합니다.") router_status.update(label="라우터 적용 완료", state="complete", expanded=False) final_answer = generate_skillset_response(query, chat_history) display_response(final_answer) elif blocked_content and not safety: process_view.write("스킬셋 사용이 불가능합니다. (이유: 콘텐츠 필터)") router_status.update(label="라우터 적용 완료", state="complete", expanded=False) final_answer = generate_filtered_response('content') display_response(final_answer) else: process_view.write("스킬셋 사용이 불가능합니다. (이유: 세이프티 필터)") router_status.update(label="라우터 적용 완료", state="complete", expanded=False) final_answer = generate_filtered_response('safety') display_response(final_answer) else: process_view.write("스킬셋과 관련 없는 요청입니다.") router_status.update(label="라우터 적용 완료", state="complete", expanded=False) final_answer = generate_chat_response(query, chat_history) display_response(final_answer)
에이전트 실행하기
프로젝트 root 경로에서 터미널로 다음 명령어를 실행합니다.
streamlit run main.py
실행 화면 예시
사용 시나리오 예시
오류 케이스 처리 팁
실제 서비스에서는 예상치 못한 문제들이 발생할 수 있습니다. 예를 들어, API 요청 시에 오류가 발생하거나 네트워크가 불안정할 수 있습니다. 이러한 오류 상황을 적절히 처리하면 에이전트의 안정성을 높이고 사용자 경험을 향상시킬 수 있으니, 개발 단계에서부터 다양한 오류 상황을 고려하여 코드를 작성하는 것이 좋습니다. 대표적으로 발생할 수 있는 몇가지 오류 상황과 처리 방법에 대한 코드 예시를 소개합니다.
1. API 응답 실패
API 호출 과정 중 발생할 수 있는 오류를 다음과 같이 간단하고 직관적으로 처리할 수 있습니다. 간소화된 메시지로 사용자에게 결과를 안내하고, 답변 생성 성공 또는 실패 상태를 UI에 명확히 표시해 줍니다.
def get_skillset(query, chat_history=None): # ... (기존 코드) response = requests.post(url, headers=headers, json=data) if response.status_code == 200: return response.json() elif response.status_code == 400: return { 'result': '스킬 클라이언트 오류 발생', 'detail': response.json().get('status').get('code') } elif response.status_code == 500: return { 'result': '스킬 서버 오류 발생', 'detail': response.json().get('status').get('code') } else: return { 'result': '알 수 없는 오류 발생', 'detail': response.status_code } def generate_skillset_response(query, chat_history): with st.status("답변 생성 중...", expanded=True) as answer_status: # ... (기존 코드) result = get_skillset(query, chat_history) final_answer = result.get('result', {}).get('finalAnswer', "스킬셋 API 호출 과정에서 오류가 발생했습니다.") if final_answer == "스킬셋 API 호출 과정에서 오류가 발생했습니다.": process_view.write("답변 생성에 실패하였습니다.") answer_status.update(label="답변 생성 실패", state="error", expanded=False) else: process_view.write("답변 생성이 완료되었습니다.") answer_status.update(label="답변 생성 완료", state="complete", expanded=False) return final_answer
또는 다음과 같이 상태 코드(200, 400, 500 등)별 오류 처리를 상세하게 구현할 수 있습니다. 사용자에게 각 오류 상황에 대한 메시지 및 에러코드 제공하고, 성공 또는 실패 상태를 UI에 자세히 표시해 줍니다.
def get_skillset(query, chat_history=None): # ... (기존 코드) response = requests.post(url, headers=headers, json=data) if response.status_code == 200: return response.json() elif response.status_code == 400: return { 'result': '스킬 클라이언트 오류 발생', 'detail': response.json().get('status').get('code') } elif response.status_code == 500: return { 'result': '스킬 서버 오류 발생', 'detail': response.json().get('status').get('code') } else: return { 'result': '알 수 없는 오류 발생', 'detail': response.status_code } def generate_skillset_response(query, chat_history): with st.status("답변 생성 중...", expanded=True) as answer_status: # ... (기존 코드) result = get_skillset(query, chat_history) status_detail = result.get('detail', None) if result.get('result') == '스킬 클라이언트 오류 발생': final_answer = f"요청이 잘못되었습니다. 입력 내용을 확인하고 다시 시도하세요. (에러 코드: {status_detail})" elif result.get('result') == '스킬 서버 오류 발생': final_answer = f"서버 오류가 발생했습니다. 잠시 후 다시 시도해주세요. (에러 코드: {status_detail})" elif result.get('result') == '알 수 없는 오류 발생': final_answer = f"알 수 없는 문제가 발생했습니다. (상태 코드: {status_detail})" else: final_answer = result.get('result', {}).get('finalAnswer') if result.get('result') in ['스킬 클라이언트 오류 발생', '스킬 서버 오류 발생', '알 수 없는 오류 발생']: process_view.write(f"에러 발생: {final_answer}") answer_status.update(label="답변 생성 실패", state="error", expanded=False) else: process_view.write("답변 생성이 완료되었습니다.") answer_status.update(label="답변 생성 완료", state="complete", expanded=False) return final_answer
관련하여 CLOVA Studio API에서 발생할 수 있는 오류 코드에 대한 원인 및 해결 방안은 CLOVA Studio 문제 해결을 참고해 주세요.
2. 네트워크 오류
재시도 로직을 통해 네트워크 오류나 시간 초과 등의 상황을 대응할 수 있습니다. 요청이 실패할 경우, 지정된 횟수만큼 지연(delay)을 두고 재시도하며, 최종적으로 실패 시 None을 반환하여 후속 처리를 가능하게 합니다.
def get_access_token(retries=3, delay=2): # ... (기존 코드) for attempt in range(retries): try: response = requests.get(url, headers=headers) response.raise_for_status() return response.json() except requests.exceptions.RequestException as e: print(f"액세스 토큰 발급 실패 (시도 {attempt + 1}/{retries}): {e}") if attempt < retries - 1: time.sleep(delay) else: return None
마무리
CLOVA Studio의 스킬 트레이너(스킬셋과 라우터), Chat Completions API를 결합하여 지역 검색 에이전트를 구축하는 방법을 알아보았습니다. 이번 쿡북을 통해 에이전트의 동작 원리와 구현 방법을 이해하고, 직접 응용하여 새로운 AI 에이전트를 만들어 보시기 바랍니다!🚀
-
1
-
 1
1
-
라우터는 자연어 설명만으로 다양한 입력을 정교하게 다룰 수 있다는 점에서 강점을 가진 솔루션입니다. 이 글에서는 라우터를 실제 서비스에 적용하기 위해 꼭 알아야 할 설계 및 평가의 노하우를 정리했습니다. 라우터의 기본 구조와 활용에 대한 개요는 CLOVA Studio 포럼(LLM 라우터를 활용한 유연한 경로 설계: 분류부터 필터링까지 손쉽게)과 CLOVA Tech Blog(라우터)를 참고하세요.
라우터의 성능을 만드는 작은 차이들
라우터의 정확도는 도메인과 필터를 어떻게 설명하는가에 달려 있습니다. 케이스에 따라 최적의 전략은 다를 수 있으므로, 아래의 설계 팁을 참고해 여러 번 테스트하며 다듬어가는 것을 권장합니다.
1. 역할에 맞게 명료한 설명 작성하기
도메인과 필터는 모두 자연어 설명에 기반해 작동하지만, 설계 전략은 서로 다릅니다. 도메인 설명은 일반화하되 경계를 명확히 하는 것이 핵심입니다. 지나치게 포괄적인 설명은 경계가 무너지고, 반대로 너무 좁은 설명은 실제 다양성을 수용하지 못하게 됩니다. 예를 들어 '건강에 관련된 모든 내용을 포함합니다.'라는 기준은 어떤 입력을 포함하고 배제해야 할지 명확하지 않고, '건강, 의료, 의학, 헬스케어, 메디컬, 웰빙에 대한 내용입니다.'는 지나치게 중복되고 불필요할 수 있습니다. 이상적인 설명은 '질병 진단, 치료법, 약물 복용 등 임상적 의료 행위에 대한 내용입니다.'와 같이 일반화할 수 있는 핵심 기준을 제시하면서도, 포함되는 범위와 포함되지 않는 범위를 암묵적으로 구분할 수 있어야 합니다.
필터 설명은 오히려 제한적이고 명시적으로 작성하는 것이 좋습니다. 포함 기준을 명확히 하고 구체적인 표현이나 입력 패턴 중심으로 설명하는 것이 좋고, 예를 들어 '논란이 될 수 있는 내용입니다.'보다는 '정치적 편향, 종교적 주장, 지역 감정을 유발할 수 있는 표현입니다.'처럼 분명하게 작성하는 것이 바람직합니다.
2. 도메인과 필터, 겹치지 않게 구분하기
분류의 기준이 되는 도메인(또는 필터) 간 경계가 명확하지 않으면, 라우터는 어떤 기준으로 분류해야 할지 혼란스러워질 수 있습니다. 특히 제로샷 방식으로 동작하는 라우터는 설명의 차이를 기반으로 판단하기 때문에, 의미적 중첩을 최대한 피해야 합니다. 예를 들어, '의료'와 '생활건강' 도메인이 모두 '허리 통증'에 대해 다룬다고 할 때, '의료'는 치료 및 진단 중심, '생활건강'은 예방과 습관 중심으로 구분할 수 있습니다. 도메인 또는 필터 간 개념적 충돌이 우려되는 경우, '의학적 목적', '비의학적 목적' 같은 메타 기준을 먼저 정의해 두고, 각 설명에서 이를 기준 삼는 것도 좋은 전략입니다.
3. 직관적인 네이밍 사용하기
도메인 및 필터의 설명뿐만 아니라, 이름 자체도 모델의 분류 판단에 영향을 미치는 요소입니다. 이름이 추상적이거나 이중적인 의미를 가지면, 생성형 모델 기반의 라우터는 분류 기준을 혼동할 수 있습니다. 이름은 해당 설명과 의미적으로 자연스럽게 어울려야 하며, 이름만 보고도 대략적인 역할이나 경계를 유추할 수 있어야 합니다. 설명이 아무리 정교하더라도 '도메인1', '카테고리A'와 같은 임의의 이름은 분류 기준을 흐릴 수 있습니다.
도메인의 경우, 사용자 입력의 의도나 주제를 드러내는 내용 기반의 명확한 키워드나 목적 중심의 명칭(예: 식이요법, 심리 상담 등)이 적합합니다. 필터의 경우, 해석의 여지를 줄이고 분명한 기준에 따라 판단할 수 있도록 구체적이고 제한적인 표현(예: OrientalMedicine, RestrictedBrand 등)을 사용하는 것이 좋습니다.
4. 필요에 따라 예시를 활용하기
설명만으로 기대한 성능이 나오지 않거나 특정 유형의 입력에서 성능이 특히 낮은 경우, 예시를 추가해 보조할 수 있습니다.
예시는 두 가지 방식으로 활용할 수 있습니다. 하나는 실제 입력 예시를 통해 어떤 표현이 해당 도메인에 속하는지를 보여주는 방식이고, 다른 하나는 포함 기준을 나열하여 범위를 명시하는 방식입니다. 예를 들어 '의료' 도메인의 경우 '질병의 원인, 진단, 치료법, 약물 정보 등'과 같이 설명만으로 범위를 분명히 하는 동시에, '대상포진 치료 방법은?', '고혈압 진단 기준 알려주세요'처럼 대표적인 입력 예시도 함께 제공하면 성능을 높이는 데 도움이 됩니다. 단, 예시는 너무 많을 경우 편향을 유도할 수 있으므로 1~2개 수준으로 제한하는 것이 좋습니다. 또한 예시는 설명과 일관된 기준을 따르면서도, 길이 제한이나 유사 표현 확장 등을 고려해 작성하는 것이 좋습니다.
라우터 성능을 평가하는 법
LLM 기반 라우터는 자연어 설명에 따라 동작하기 때문에, 설계자의 설명 방식이나 기준 설정에 따라 성능이 크게 달라질 수 있습니다. 따라서 실제 서비스 수준의 품질을 확보하려면, 단순 직관이 아닌 정량적이고 체계적인 평가를 통해 라우터의 분류 성능을 검증하고 개선해 나가는 과정이 필요합니다. 이를 위해서는 먼저 도메인과 필터 기준을 충분히 다듬고, 다양한 입력을 포함한 테스트셋을 구성한 뒤, 라우터의 응답을 자동으로 테스트해 성능을 측정하고 분석하는 절차를 따르는 것이 좋습니다. 이 과정을 반복하면서, 라우터가 실제 서비스 환경에서도 안정적이고 일관된 분류를 수행할 수 있도록 조정할 수 있습니다.
1. 테스트셋 준비하기
서비스에 적용 가능한 수준의 라우터를 만들기 위해서는 먼저 실제 서비스 맥락을 반영한 테스트셋을 준비해야 합니다. 대표적인 입력만 포함하는 것이 아니라, 다양한 상황을 커버할 수 있도록 입력 유형을 체계적으로 나눠 준비해야 합니다. 예를 들어 다음과 같은 유형을 포함하면 좋습니다.
- 대표 케이스: 자주 등장하는 일반적인 입력(ex. 고혈압 치료 방법 알려줘)
- 표현 다양화: 동일 의도의 다양한 표현(ex. 고혈압 약 뭐 먹어야 해?, 혈압 낮추는 약 알려줘)
- 무관한 입력: 해당 도메인(또는 필터)에 속하지 않는 내용(ex. 오늘 날씨 어때?)
- 비정형 표현: 실제로 발생할 수 있는 철자 오류 등의 비정형의 입력(ex. 고혀랍약 추천해줘)
이처럼 테스트셋은 모델이 어떤 유형의 입력에 강하고 어떤 유형에 취약한지를 진단할 수 있도록 구성되어야 합니다. 또한 테스트셋은 모든 도메인 및 필터별로 최소 수량 이상 확보하여 균형 있게 구성해야 하며, 각 입력에 대해 어느 도메인이 정답인지 명확하게 정의해두는 것이 중요합니다. 그리고 이 정답 기준은 도메인(또는 필터) 설명과 일관되어야 합니다.
2. 벌크로 테스트하기
벌크 테스트를 본격적으로 실행하기 전에는, 반드시 샘플 데이터로 사전에 개별 테스트를 선행하는 것을 권장합니다. 개별 입력에 대해 수차례 테스트하고 설명을 조정하며 라우터의 응답을 안정화시키는 과정을 먼저 거친 후에 대량 데이터로 테스트를 실행하는 것이 좋습니다.
벌크 테스트를 위한 예시 코드는 다음을 참고하세요.
import requests import time import pandas as pd from tqdm import tqdm # 0. 라우터 API 정보 ROUTER_ID = "YOUR_ROUTER_ID" ROUTER_VERSION = "YOUR_ROUTER_VERSION" API_KEY = "YOUR_API_KEY" REQUEST_ID = "YOUR_REQUEST_ID" # 1. 라우터 API 호출 함수 def router_api(query, chat_history=None): url = f"https://clovastudio.stream.ntruss.com/testapp/v1/routers/{ROUTER_ID}/versions/{ROUTER_VERSION}/route" headers = { "Authorization": f"Bearer {API_KEY}", "X-NCP-CLOVASTUDIO-REQUEST-ID": REQUEST_ID, "Content-Type": "application/json" } data = {"query": query} if chat_history: data["chatHistory"] = chat_history # 이용량 초과 시 재시도 while True: response = requests.post(url, headers=headers, json=data) if response.status_code == 429: time.sleep(5) continue return response.json() # 2. 테스트셋 구성 testset = [ {"input": "고혈압 치료 방법 알려줘", "domain": "의료"}, {"input": "혈압 낮추는 약 알려줘", "domain": "의료"}, {"input": "오늘 날씨 어때?", "domain": ""}, # 라우터에 필터를 함께 설정한 경우 다음과 같이 테스트셋 구성 # {"input": "디스크 터진 것 같은데 어떡하죠", "domain": "의료", "content": "[]", "safety": "[]"}, # {"input": "소음인한테 좋은 약 추천해주세요", "domain": "의료", "content": "['OrientalMedicine']", "safety": "[]"}, # {"input": "(특정 국가)인들 때문에 전염된 코로나 증상이랑 치료법은?", "domain": "의료", "content": "[]", "safety": "['unethical']"} # ... ] # 3. 테스트 실행 및 결과 저장 results = [] for i, data in enumerate(tqdm(testset)): try: res = router_api(data["input"]) pred_domain = str(res.get("result", {}).get("domain", {}).get("result")) # pred_content = str(res.get("result", {}).get("blockedContent", {}).get("result", [])) # pred_safety = str(res.get("result", {}).get("safety", {}).get("result", [])) results.append({ "input": data["input"], "domain": data["domain"], # "content": data["content"], # "safety": data["safety"], "pred_domain": pred_domain, # "pred_content": pred_content, # "pred_safety": pred_safety, "is_correct_domain": data["domain"] == pred_domain, # "is_correct_content": data["content"] == pred_content, # "is_correct_safety": data["safety"] == pred_safety }) except Exception as e: print(e) # 4. 결과 확인 df = pd.DataFrame(results) print(df)
출력 결과input domain pred_domain is_correct_domain 0 고혈압 치료 방법 알려줘 의료 의료 True 1 혈압 낮추는 약 알려줘 의료 의료 True 2 오늘 날씨 어때? True
줄 바꿈 활성화텍3. 테스트 결과 분석하기
테스트 결과를 수집했다면, 다음 단계는 이를 기반으로 성능을 정량적으로 분석하고 개선 포인트를 도출하는 것입니다. 아래는 분류 성능 분석에서 흔히 활용되는 기준입니다.
- 정탐 (TP, True Positive): 실제로 해당 도메인(또는 필터)에 속하는 입력을 모델이 올바르게 해당 도메인(또는 필터)으로 예측한 경우
- 오탐 (FP, False Positive): 실제로는 해당 도메인(또는 필터)에 속하지 않지만, 모델이 잘못 해당 도메인(또는 필터)으로 예측한 경우
- 미탐 (FN, False Negative): 실제로는 해당 도메인(또는 필터)에 속하지만, 모델이 이를 인식하지 못해 예측 결과가 누락된 경우
- 정확도 (Accuracy): 전체 테스트 입력 중 정답을 맞춘 비율. (정탐 수 ÷ 전체 입력 수)
앞선 '2. 벌크로 테스트하기'에 이어서 성능 지표를 산출하기 위한 예시 코드는 다음을 참고하세요.
# 1. 정탐, 오탐, 미탐, 정확도 계산 tp = ((df["domain"] != "") & (df["domain"] == df["pred_domain"])).sum() fp = ((df["pred_domain"] != "") & (df["domain"] != df["pred_domain"])).sum() fn = ((df["domain"] != "") & (df["pred_domain"] == "")).sum() accuracy = round((df["is_correct_domain"].sum()) / len(df), 3) # 2. 결과 출력 print("라우터 성능 지표 요약") print(f"- 정탐(TP): {tp}") print(f"- 오탐(FP): {fp}") print(f"- 미탐(FN): {fn}") print(f"- 정확도(Accuracy): {accuracy * 100:.1f}%")
출력 결과라우터 성능 지표 요약 - 정탐(TP): 2 - 오탐(FP): 0 - 미탐(FN): 0 - 정확도(Accuracy): 100.0%
오탐이나 미탐된 케이스는 별도로 수집해 도메인/필터 설명을 개선하는 데 활용할 수 있고, 필요 시 예시 문장을 추가하거나 도메인을 재구성하는 것도 고려할 수 있습니다. 이러한 분석-개선 루프를 꾸준히 반복하면, 실제 서비스 환경에서도 라우터가 안정적이고 일관된 결과를 도출할 수 있습니다.
마무리
라우터의 성능을 높이기 위해서는 설명을 개선하고 반복적으로 테스트하는 과정이 핵심입니다. 라우터 설계 → 테스트셋 구성 → 벌크 테스트 → 결과 분석 → 라우터 수정이라는 일련의 사이클을 통해, 라우터의 품질을 점진적으로 끌어올릴 수 있습니다. 이 과정에서 CLOVA Studio에서 제공하는 샘플 라우터를 참고하는 것도 좋습니다. 본 가이드를 참고하여 똑똑한 맞춤형 라우터를 만들어 보세요. 🚀
-
라우터(Router)란?
LLM 에이전트가 사용자의 요청을 안전하고 신뢰할 수 있게 관리하면 사용자와 운영자 모두에게 든든한 지원이 됩니다.
이를 가능하게 하는 주요 도구가 '라우터(Router)' 입니다.
라우터는 에이전트 제작 과정에서 다양한 도구(Function Calling, 스킬 등)를 효율적으로 연결해 최적의 경로를 제시하고,
사용자의 요청과 콘텐츠를 분석해 적합한 루트를 지정해주는 역할을 합니다.
예를 들어, 사용자가 '최신 금융 상품을 추천해줘.'라고 질문하면, 라우터는 이 요청을 금융 도메인으로 분류하고 관련 태스크가 실행되도록 합니다.
반면, '내 계좌번호 알아?'라는 질문에는 민감한 주제로 감지하여 보안 문제를 사전에 예방합니다.
라우터는 사용자의 질문을 분석해 적절한 태스크와 도메인으로 분류하고, 예기치 않은 상황에서도 적합한 경로를 설정해 사용자 경험을 향상시킵니다.
이제 라우터가 어떻게 활용할 수 있는지 더 알아보겠습니다.
라우터의 구성요소
라우터는 LLM 에이전트가 사용자가 지정한 범위 내에서 정교하고 안전하게 동작하도록, 도메인과 도메인 필터(콘텐츠 필터, 세이프티 필터)로 구성됩니다.
1. 도메인
'도메인(domain)'은 특정 주제나 분야를 의미하며 금융, 여행, 수학 교육 등 각기 다른 주제가 도메인이 될 수 있습니다.
이를테면 금융 도메인에 특화된 LLM은 금융 지식과 용어를 학습하여, 여행과 같은 도메인보다 예금, 대출, 환율 등에 대해 깊이 있는 답변을 제공할 수 있습니다.
'도메인' 판별은 사용자의 질문이 허용된 주제에 부합하는지 확인하는 기능입니다.
예를 들어 금융 지원 에이전트에 금융 관련 질문이 들어오면, 금융 특화 스킬이나 Function Calling 등 관련 도구를 호출하여 적절한 응답을 제공합니다.
반면, 여행이나 요리 등 금융과 무관한 주제에 대해서는 도구들(Tools)이 호출되지 않도록 제어함으로써 도구 호출 비용을 절감할 수 있습니다.
2. 도메인 필터
2-1. 콘텐츠 필터
'콘텐츠 필터'는 특정 도메인 내에서 예외적으로 제외된 주제를 감지합니다.
예를 들어, 금융 도메인 내에서도 투자 조언이나 매매와 관련된 대화는 다루지 않도록 필터를 설정할 수 있습니다.
이를 통해 허용된 도메인 범위 안에서라도 특정 주제를 처리하지 않도록 제한할 수 있습니다.
2-2. 세이프티 필터
세이프티 필터는 사용자 발화에서 비윤리적이거나 민감한 내용을 감지하는 기본 제공 기능으로, Unethical 필터와 Contentious 필터가 있습니다.
이 필터들은 기본값으로 설정되어 있으며, on/off 옵션으로 손쉽게 적용할 수 있습니다.Unethical 필터는 욕설, 범죄와 같은 비윤리적인 내용을 포함한 발화를 감지하여 적절히 처리하도록 합니다.
Contentious 필터는 정치적, 사회적으로 민감한 논쟁 이슈이나 편향된 주장에 대한 발화를 감지하여 처리합니다.
Quote도메인 필터(콘텐츠 필터, 세이프티 필터)를 구성하려면 반드시 도메인을 정의해야 합니다. 만약 세이프티 필터 기능만 수행하는 라우터를 만들고 싶다면, 아래와 같이 세이프티와 관련된 주제를 도메인으로써 정의하여 적용할 수 있습니다:
예시 1
- 도메인 이름: 스팸
- 도메인 설명: 광고성, 과도한 홍보, 금융 사기, 개인정보 탈취 시도 등 스팸이나 스미싱 의도를 가진 내용입니다.
예시 2
- 도메인 이름: Unethical
- 도메인 설명: 욕설, 범죄와 같은 비윤리적인 내용을 포함한 발화를 감지합니다.
라우터, 이렇게 활용해보세요!
1. 다른 툴과 함께 활용하기_쿼리 라우팅(Query Routing)
라우터를 활용하여 다른 도구(tools)와 연동해 효율적인 에이전트를 구축할 수 있습니다.
예를 들어, 사용자가 금융 에이전트에게 '최신 예금 상품들을 비교해주세요.'라고 요청한 상황을 가정해보겠습니다.
❶ 사용자의 요청이 들어오면 가장 먼저, ❷ 라우터가 실행되어 쿼리가 다음과 같은 내용을 감지합니다.
: (1) 적절한 주제인지(도메인 판별) (2) 도메인 내 허용된 주제인지(콘텐츠 필터), (3) 비윤리적이거나 민감한 내용인지(세이프티 필터)
사용자의 쿼리가 라우터를 무사히 통과하면, ❸ 금융 상품 조회 스킬을 사용하여 API로부터 데이터를 받아, ❹ 비교 및 요약한 답변을 생성하고 ❺ 이를 사용자에게 전달합니다.
반대로, ❶ 사용자의 쿼리가 ❷ 라우터에서 허용되지 않는 내용으로 판별되면, 금융 상품 조회 스킬은 실행되지 않고 ❸거절 메세지로 응답합니다.
이처럼 라우터는 관련 없는 쿼리에 대해 다음 단계의 불필요한 스킬 호출을 방지하여 시스템 자원과 비용을 절약할 수 있습니다.
2. 단독으로 활용하기_콘텐츠 라우팅(Contents Routing)
라우터를 사용하여 특정 규칙에 따라 콘텐츠를 분류할 수 있습니다.
예를 들어, 여러 의견이 오가는 금융 커뮤니티에서 비윤리적인 투자 권유, 불법 정보, 혐오 발언 등을 사전에 감지하고 처리할 수 있습니다.
이 경우, 사용자가 금융 커뮤니티에 글을 작성하면 해당 콘텐츠는 먼저 라우터를 거치게 됩니다.
라우터는 사용자가 작성한 콘텐츠가 정의된 규칙(도메인 및 필터)에 부합하는지 검토하며, 투자 조언(예: 특정 주식 추천, 과도한 수익 보장 등)과 같은 민감한 맥락을 감지하고 분류합니다.
만약 업로드된 게시물이나 SNS 댓글이 라우터에서 부적절한 내용으로 확인되면, 라우터는 해당 콘텐츠의 게시를 차단하거나 관리자가 검토할 수 있도록 표시합니다.
이와 같이 라우터는 모델의 입력을 제어하는 기능으로, 다른 도구들과 연계해 활용하면 서비스의 안정성과 효율성을 더욱 높일 수 있습니다.
라우터를 적용함으로써 LLM 에이전트가 각 상황에서 적절한 답변을 제공하도록 도우며 사용자와 운영자 모두에게 보다 안전하고 신뢰할 수 있는 환경을 제공할 수 있습니다.
-
1
-
@전호영님 안녕하세요.
공유주신 API Spec을 확인해본 결과, servers 항목의 url 필드에 로컬 주소(http://localhost:8080)가 입력되어서 해당 오류가 발생된 것으로 보입니다. 따라서 외부에서도 접근이 가능한 도메인 이름 또는 주소로 변경해 주시면 정상적인 호출이 가능합니다.
이후에도 문제가 지속되거나 추가적인 문의가 있으시다면 언제든 남겨주세요!
감사합니다 🙂
-
@NewLearn 님, 안녕하세요.
토큰 수 초과로 인해 발생된 에러로 확인되며, 토큰 수 절약에 관한 가이드 링크를 첨부드립니다. (링크 열기)
참고로 1개의 데이터 수집에 제한된 토큰 수는 4,096 입니다. 여기에는 유저 쿼리, 모델의 사고 과정(생각, 액션 등), 스킬 정보(API Spec, Manifest) 등이 모두 합산됩니다. CLOVA Studio의 익스플로러 > 토큰 계산기(HCX)를 통해 토큰 수를 계산해 보실 수 있습니다.
또한 에러 메시지에 오류가 있어 조치할 예정입니다. 이용에 불편을 드려서 죄송합니다.
추가적인 문의 사항이 있으시면 언제든지 남겨주시길 바랍니다.
감사합니다 🙂
-
@모바일님, 말씀 주신 내용에서 후자와 같이 처리해 주셔야 합니다. 즉, 사용자 쿼리에 대해 chat completion api를 호출할 지 skillset api를 호출할 지 판별하는 도구가 앞단에 필요하게 됩니다.
감사합니다!
-
-
@모바일 네 확인 감사합니다!
스킬셋 API에서는 query가 인입되면 대부분의 경우에 스킬이 호출되고, 예외적으로 부적절한 쿼리(스킬셋과 연관 없거나 필수 파라미터 누락된 경우 등)가 인입된 케이스에 한해서만 가끔 모델이 자체적으로 스킬 호출을 하지 않고 에러 코드를 반환해 줍니다. 따라서 특정 단어를 말하거나 관련 요청을 한 경우에 한해서만 스킬셋 호출이 이루어지도록 한다면 별도의 판별 모델(의도 분류, 특정 단어 감지 등)을 앞단에 구성해 주셔야 할 것 같습니다.
추가적인 문의가 있으시다면 편히 남겨주십시오.
감사합니다 🙂
-
@모바일님 안녕하세요.
테스트앱 발급 후 스킬셋 API 호출이 되지 않아서 문의 남겨주신 것으로 이해했습니다.
혹시 스킬셋 API 호출 시에 API 응답이 어떻게 반환되었는지 확인해 주실 수 있을까요? (ex. 에러 코드, 에러 문구, 이외 내용)
그리고 "수수께끼 놀이하자" 쿼리에서만 스킬셋 호출이 되지 않은 것인지, 또는 다른 쿼리에서도 동일하게 재현되는지 확인 부탁드립니다. 확인된 내용을 토대로 적절한 가이드 드릴 수 있도록 하겠습니다.
추가적으로 스킬셋 API 요청 구문 샘플도 공유드립니다. 필수 입력 값으로만 구성된 버전의 샘플입니다.
Quotecurl --location --request POST 'https://clovastudio.stream.ntruss.com/testapp/v1/skillsets/{skillset-id}/versions/{version}/final-answer' \
--header 'X-NCP-CLOVASTUDIO-API-KEY: <X-NCP-CLOVASTUDIO-API-KEY>' \
--header 'X-NCP-APIGW-API-KEY: <X-NCP-APIGW-API-KEY>' \
--header 'X-NCP-CLOVASTUDIO-REQUEST-ID: <X-NCP-CLOVASTUDIO-REQUEST-ID>' \
--header 'Content-Type: application/json'
--data '{
"query": "수수께끼 놀이하자"
}'감사합니다 🙂
-
@juhn3707님 안녕하세요.
해당 에러는 final answer api 호출 시, 관련 없는 유저쿼리나 필수 파라미터를 누락하여 요청한 경우 발생하며, 전달 주신 케이스는 파라미터 누락으로 인한 오류로 예상됩니다.추가적으로, 필수 파라미터 누락 시에도 정상 동작하도록 API를 구성하실 수 있습니다.
우선 필수 파라미터가 비어있을 시 API에서 오류코드(400 등)를 내려주지 않고, 정상 코드로 반환해야하며(200), 이때 어떠한 파라미터가가 누락되었는 지를 답변 내용에 포함할 수 있습니다. (답변에 포함하지 않은 채 “error”로만 내려주어도 무관합니다.) 이렇게 되면 최종 답변 영역에서 모델이 누락된 파라미터를 요청하는 질문을 생성하고, 원하는 형식으로 튜닝 및 학습도 진행할 수 있습니다. 54020 에러코드에 대한 설명은 7월 중 가이드 문서에 추가될 예정이오니 참고 부탁드립니다.
감사합니다. -
안녕하세요 @ak68님,
스킬 트레이너 시나리오 작업 중 토큰 수는 총 4096으로 제한되어 있으며, User query, 모델의 사고 과정(생각 및 액션 등), 스킬 정보(API Spec, Manifest), API 응답(관찰 결과) 등이 모두 합산됩니다. 토큰 수 계산은 CLOVA Studio > 익스플로러 > 토큰 게산기(HCX)에서 이용하실 수 있습니다.
허용 토큰 수를 늘리는 것은 불가능 하지만, 토큰 수를 절약할 수 있는 방안을 안내드립니다. 하기 가이드 링크 접속 후 <API Spec 확장 기능> 참고 바랍니다.
https://guide.ncloud-docs.com/docs/clovastudio-skill#api-spec-작성
참고로 위 방안은 API 응답이 너무 길어서 토큰 수 초과되는 경우에 한하여 적용 가능합니다.
추가적으로 궁금한 사항 있으시다면 남겨주십시오.
감사합니다 :)
-
@beans님 안녕하세요,
남겨주신 질문에 대해 다음과 같이 답변드립니다.
1. 시나리오를 통해 학습 진행 후, API를 이용한 "스킬셋 답변 생성"에서의 x-exclude-cot이 적용 여부
→ 스킬 트레이너의 시나리오 화면에서는 x-exclude-cot 적용한 필드는 응답으로 노출되지 않고, 스킬셋 답변 생성 API 호출 시에는 x-exclude-cot 상관 없이 모든 응답이 내려오도록 제공하고 있습니다. x-exclude-cot 목적이 시나리오 내 토큰 수 초과 에러를 방지하고 학습 비용을 절약하는 데에 있기 때문에, 실제 학습 데이터를 제작하는 시나리오 화면에서만 적용되고 있습니다.
2. 응답이 긴 API에서 x-exclude-cot 적용을 하여 시나리오 학습 이후에 API 응답 길이에 대해서 제한 유무
→ 스킬 트레이너의 시나리오 화면에서는 API 응답(Step 2-2 관찰)을 포함한 모든 필드(유저쿼리, Step 1, ..., 최종답변)를 합하여 4096 토큰 수로 제한되어 있습니다. 또한 학습 전후에 상관없이 시나리오 작업에서 선택한 버전의 스킬 정보가 x-exclude-cot가 포함된 것이라면, x-exclude-cot가 응답에 적용됩니다. 참고로 스킬셋 답변 생성 API 호출 시에는 별도 길이 제한이 없습니다.
답변이 되셨길 바랍니다!
추가적으로 궁금하신 점 있으시면 남겨주십시오.
감사합니다 🙂
-
@Axel님 안녕하세요,
스킬셋 생성/편집 창 - 답변 형식 부분에서 조정 가능합니다.
JSON 형식, 표 형식, 번호 매기기 등의 유형이 지원되며, 작성 예시는 하기 가이드 링크 참고 부탁드립니다.
https://guide.ncloud-docs.com/docs/clovastudio-skillset
추가적으로 궁금하신 점 있으시다면 언제든 문의 남겨주세요.
감사합니다.
-
1
-
-
@beans님 안녕하세요,
스킬셋 답변 생성 API로 시나리오를 수집하는 것은 지원되고 있지 않으며, 시나리오 생성 및 저장은 반드시 스킬 트레이너 내 시나리오 수집 화면에서만 이루어집니다.
스킬셋 답변 생성 API는 특정 스킬셋의 API를 호출하여 최종 답변을 생성하는 용도로, 작업한 결과물(스킬셋 및 시나리오)을 테스트 하는 데에 사용할 수 있습니다.
답변이 되셨으면 좋겠습니다. 추가적으로 문의 사항 있으시면 또 남겨주세요!
감사합니다.
-
 1
1
-
-
@beans님 안녕하세요,
현재로서는 튜닝과 스킬 트레이너 간 연동이 지원되고 있지 않기 때문에 문의 주신 기능은 불가능합니다.
더 좋은 서비스를 제공드릴 수 있도록 노력하겠습니다.
감사합니다.
-
@beans님 안녕하세요,
Description for human의 경우 공백포함 120자로 제한이 되어 있어서 해당 오류 알람이 발생한 것으로 보이는데요, 따라서 해당 필드의 글자 수를 줄여주시면 정상적으로 API Spec이 저장될 것 입니다. 향후 가이드에 관련 내용을 상세히 업데이트 하는 등으로 고려해 보겠습니다.
추가적인 문의가 있으시다면 또 남겨주십시오.
감사합니다!
-
안녕하세요 @beans님.
공유 주신 API Spec을 확인해 보았는데요, 일부 파라미터 type이 정의되지 않은 형태('int')로 되어 있어서 발생한 오류입니다.
type을 'integer'로 변경해 주시면 정상 작동될 것입니다.
추가적인 문의가 있으시다면 또 남겨주십시오. 감사합니다.
-
1
-

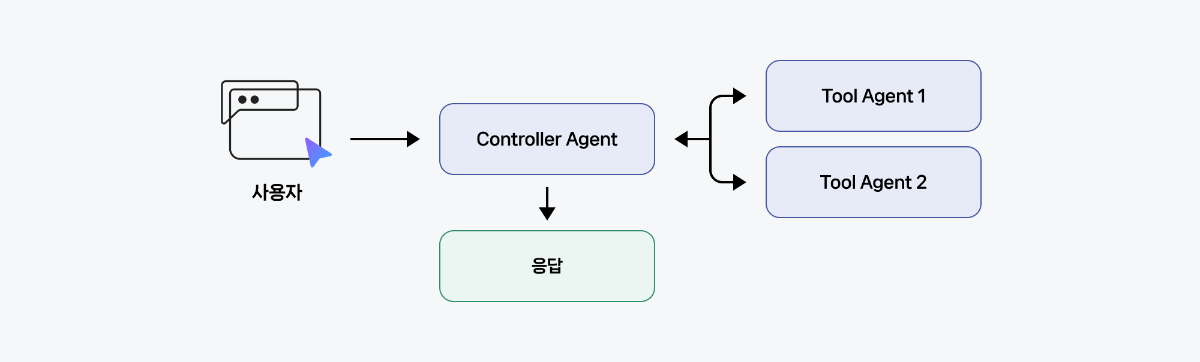
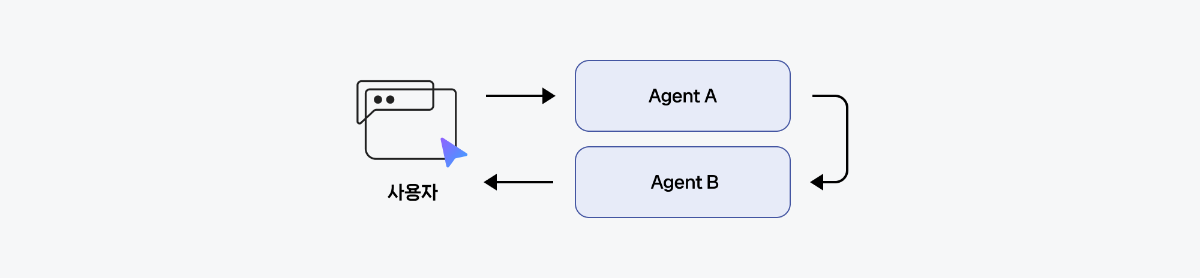
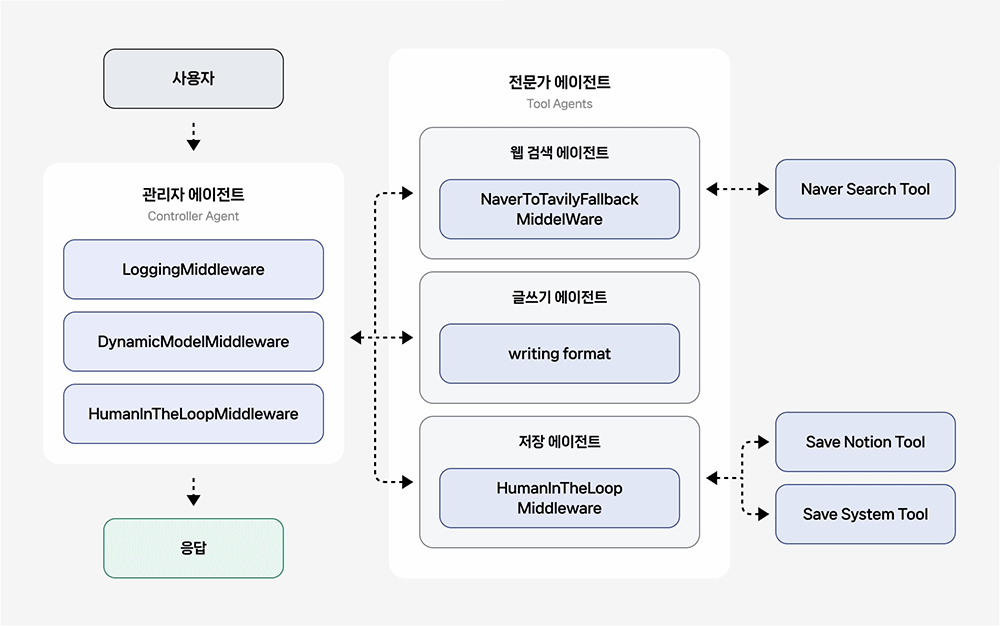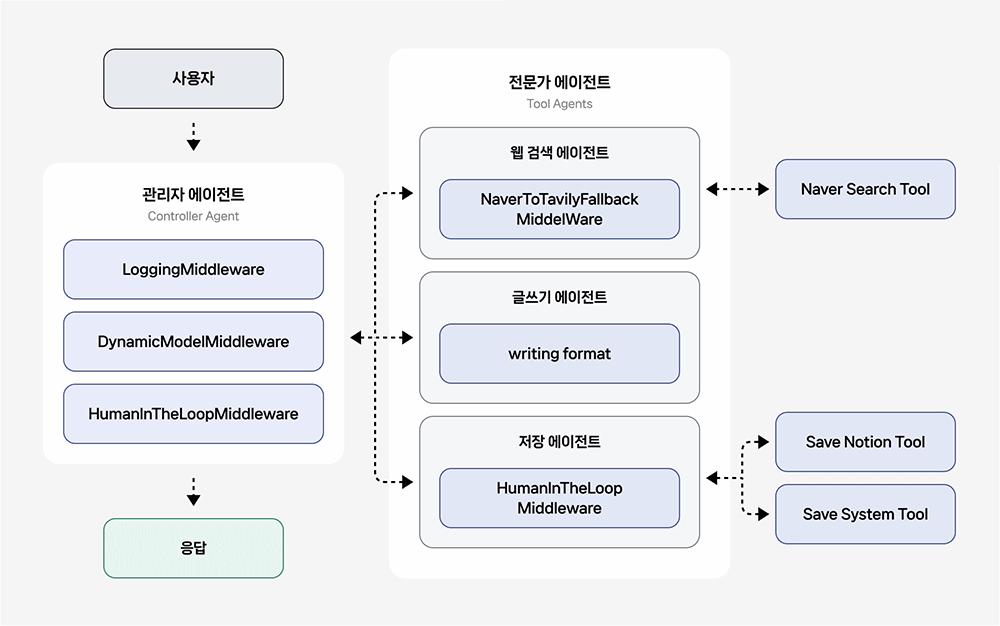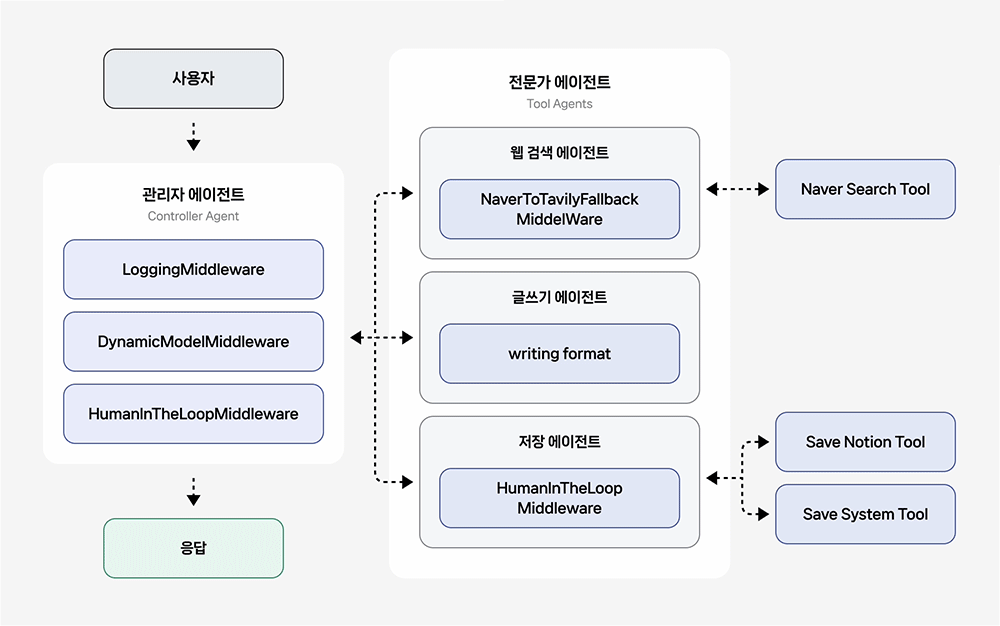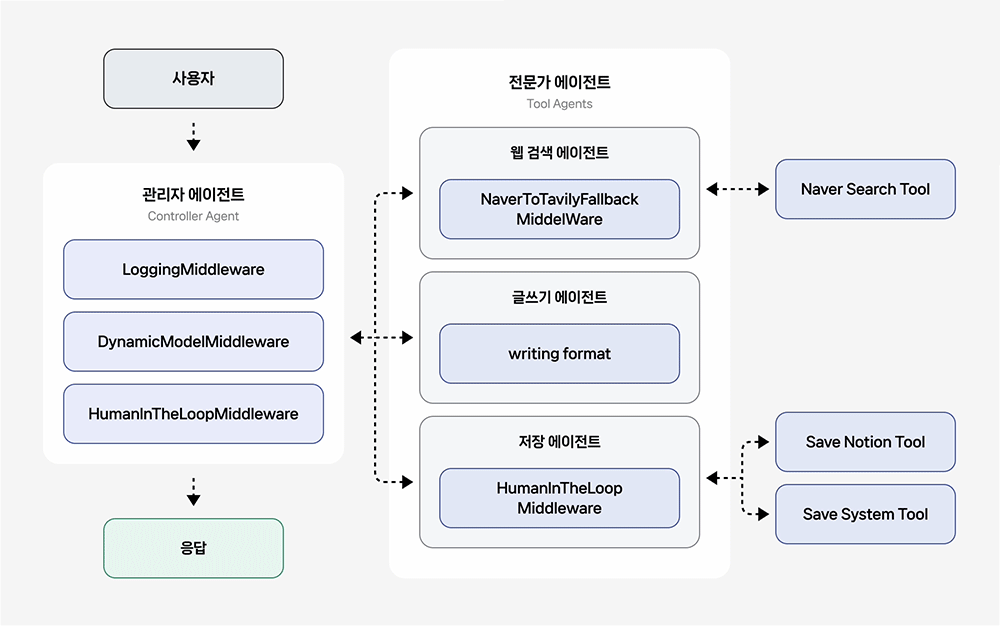
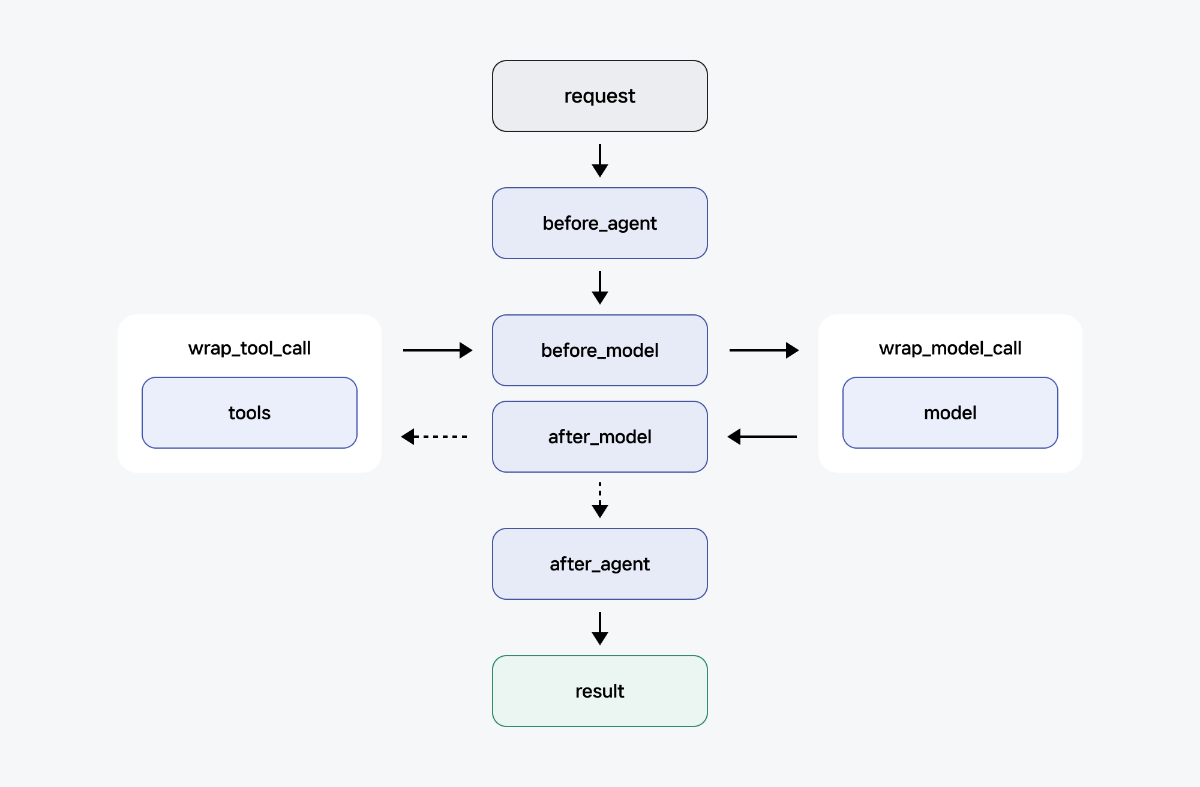
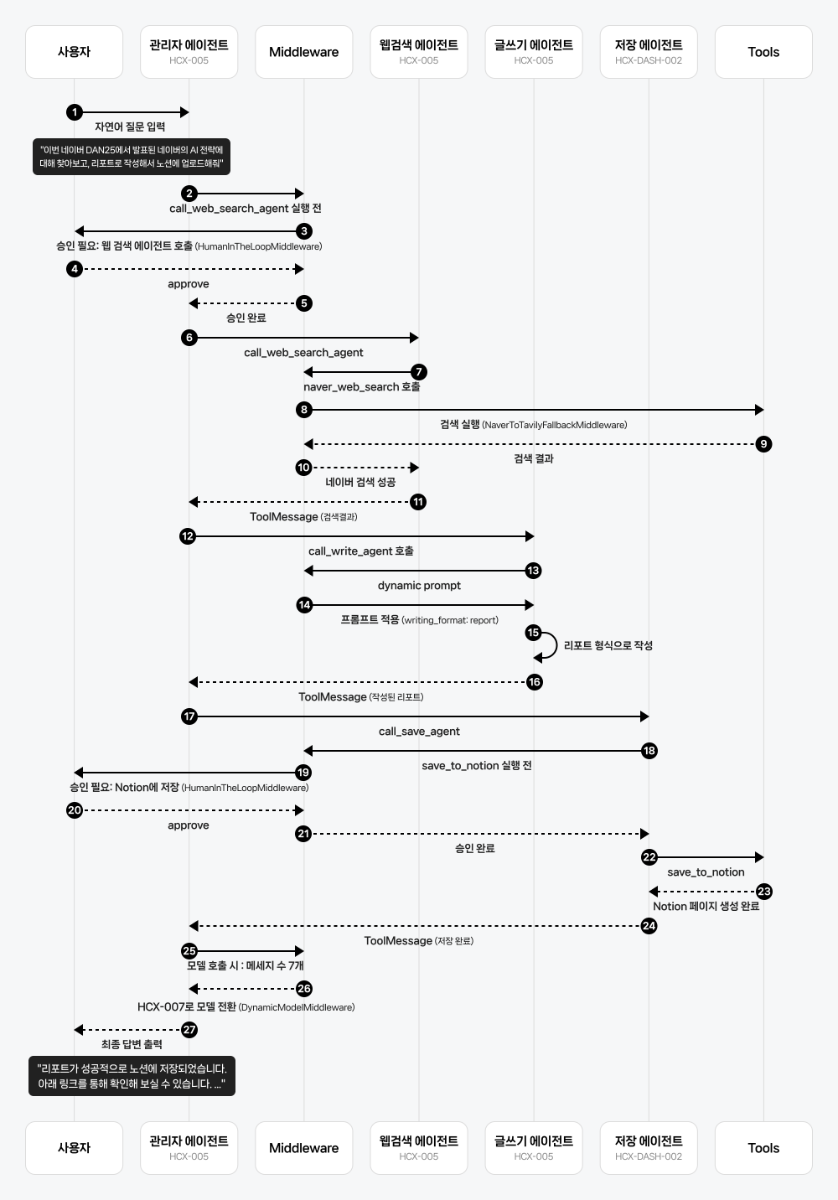
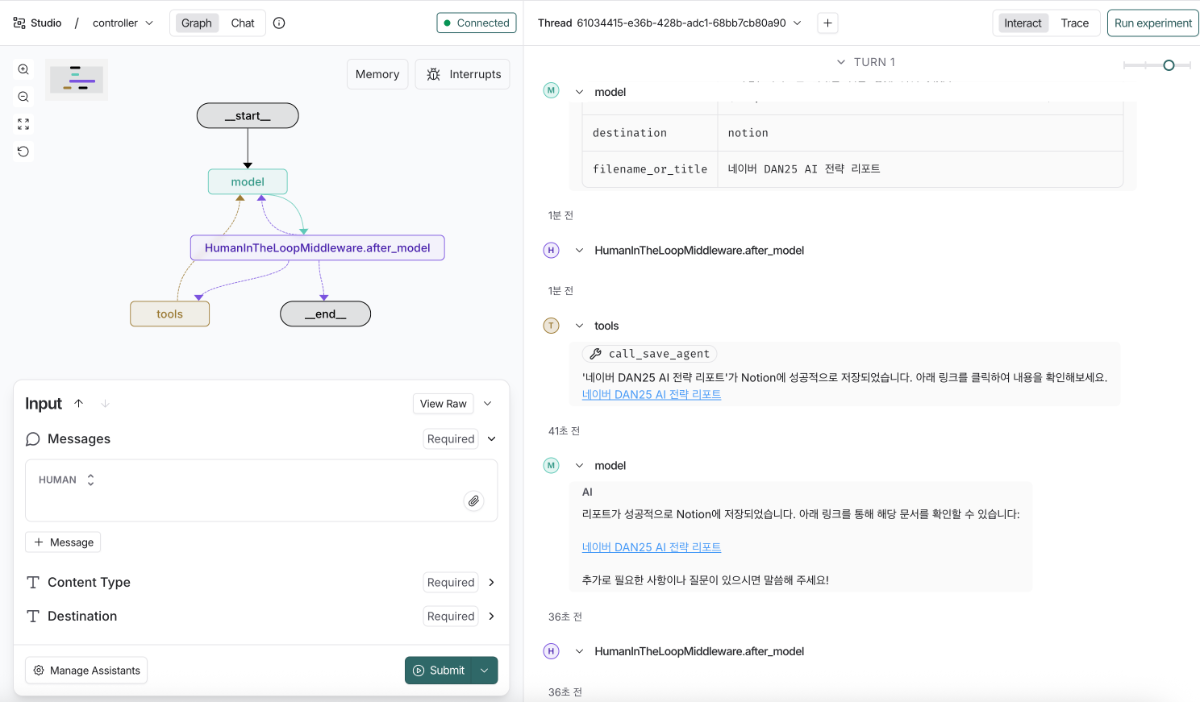



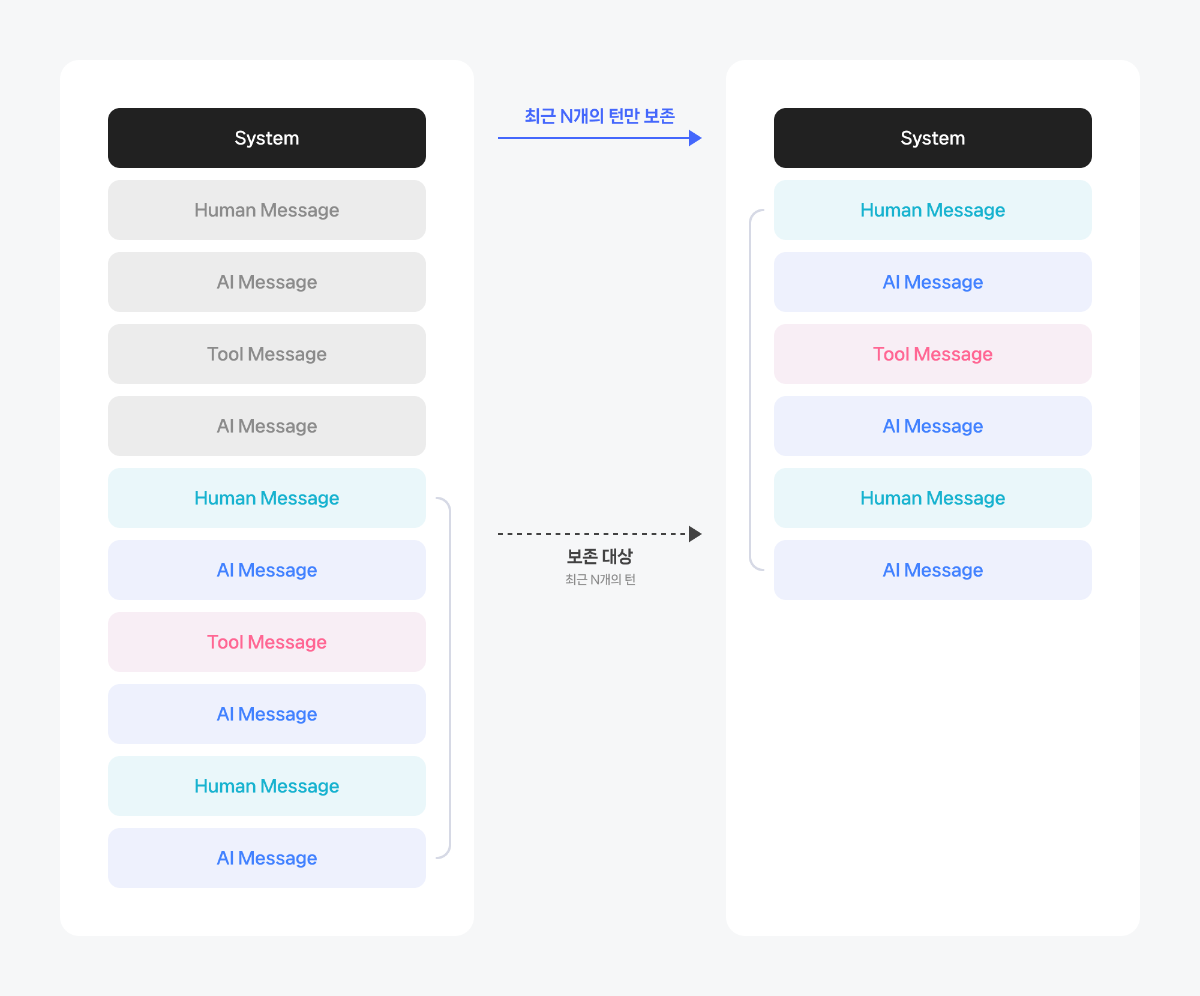
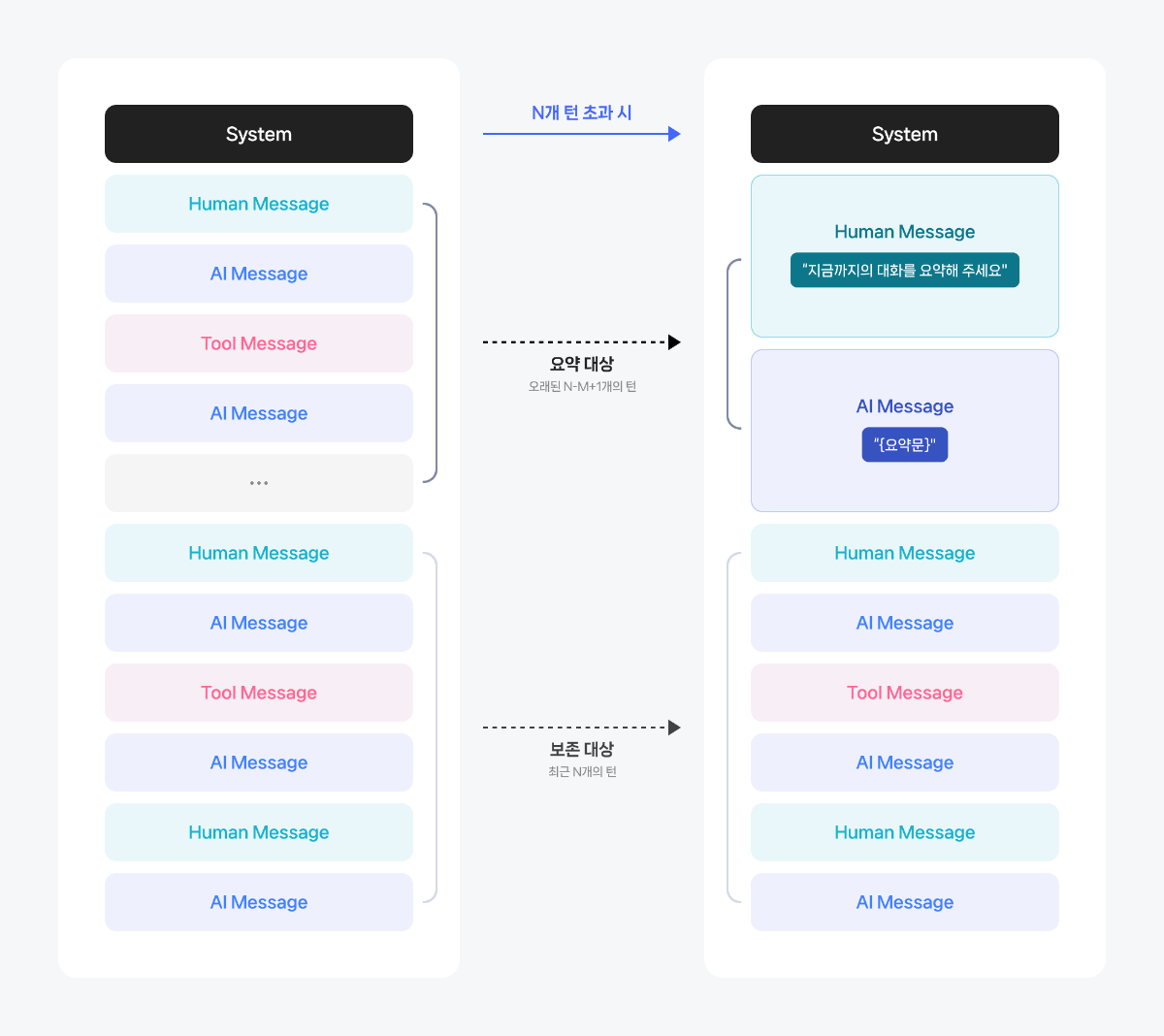

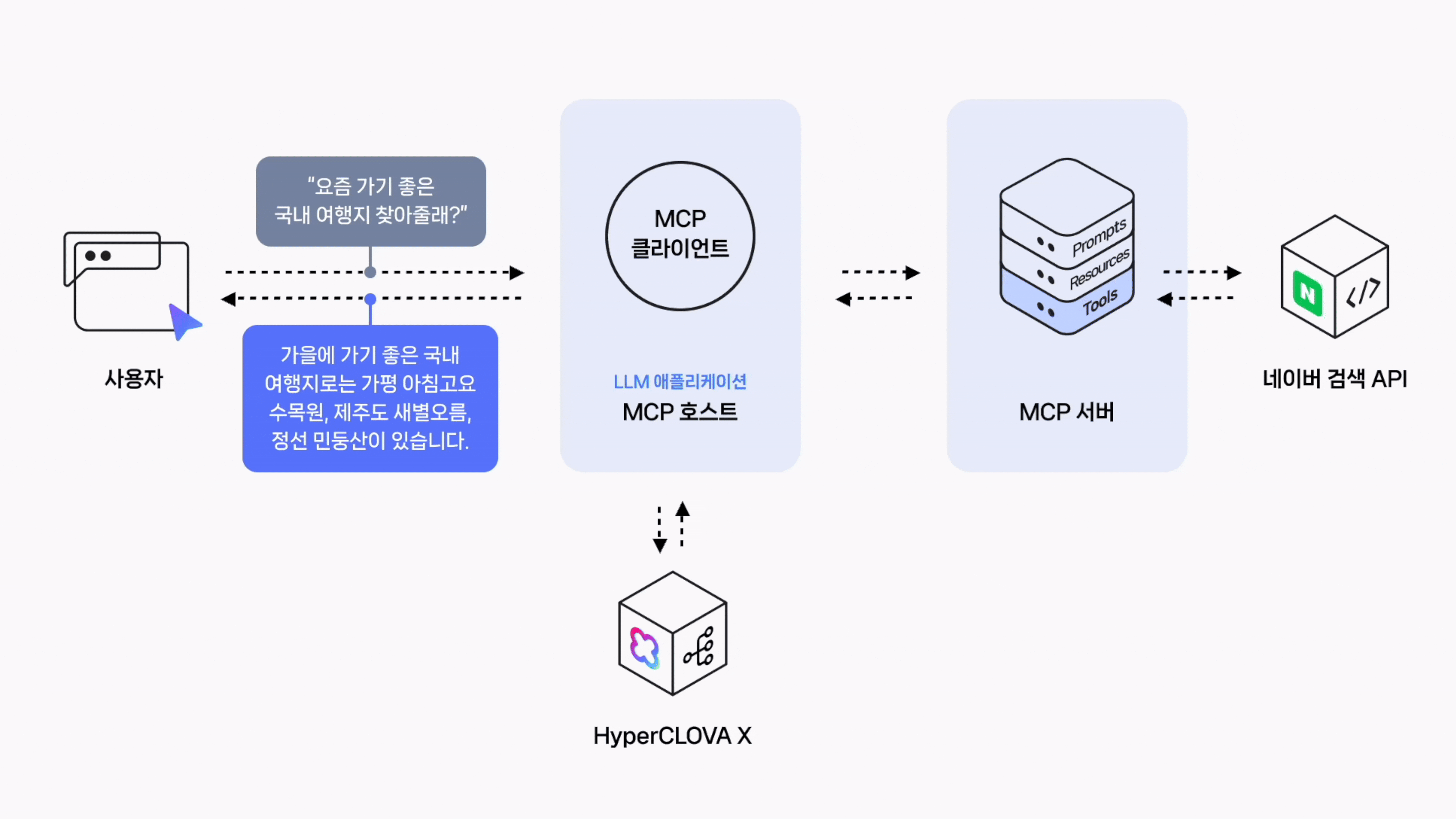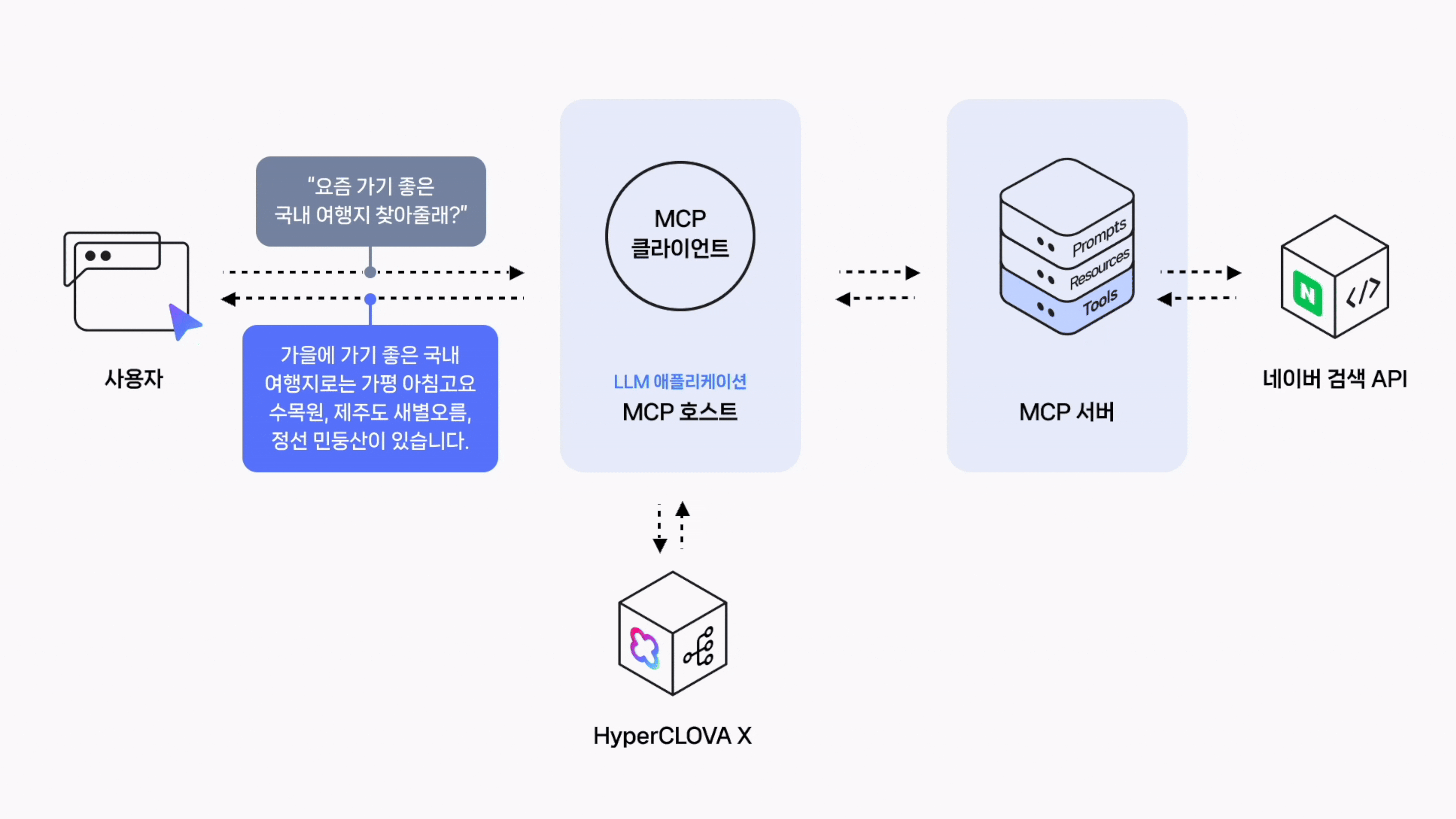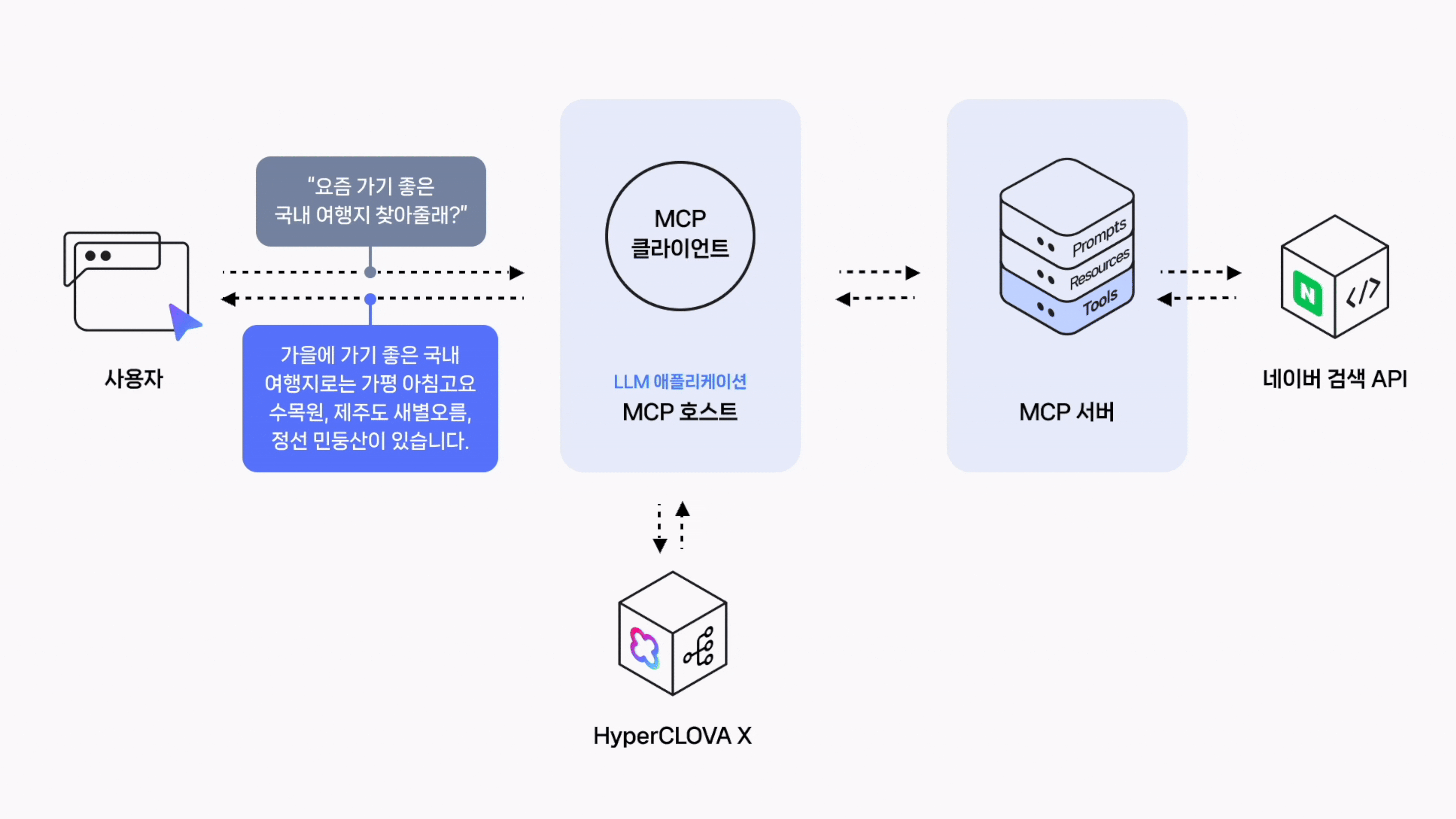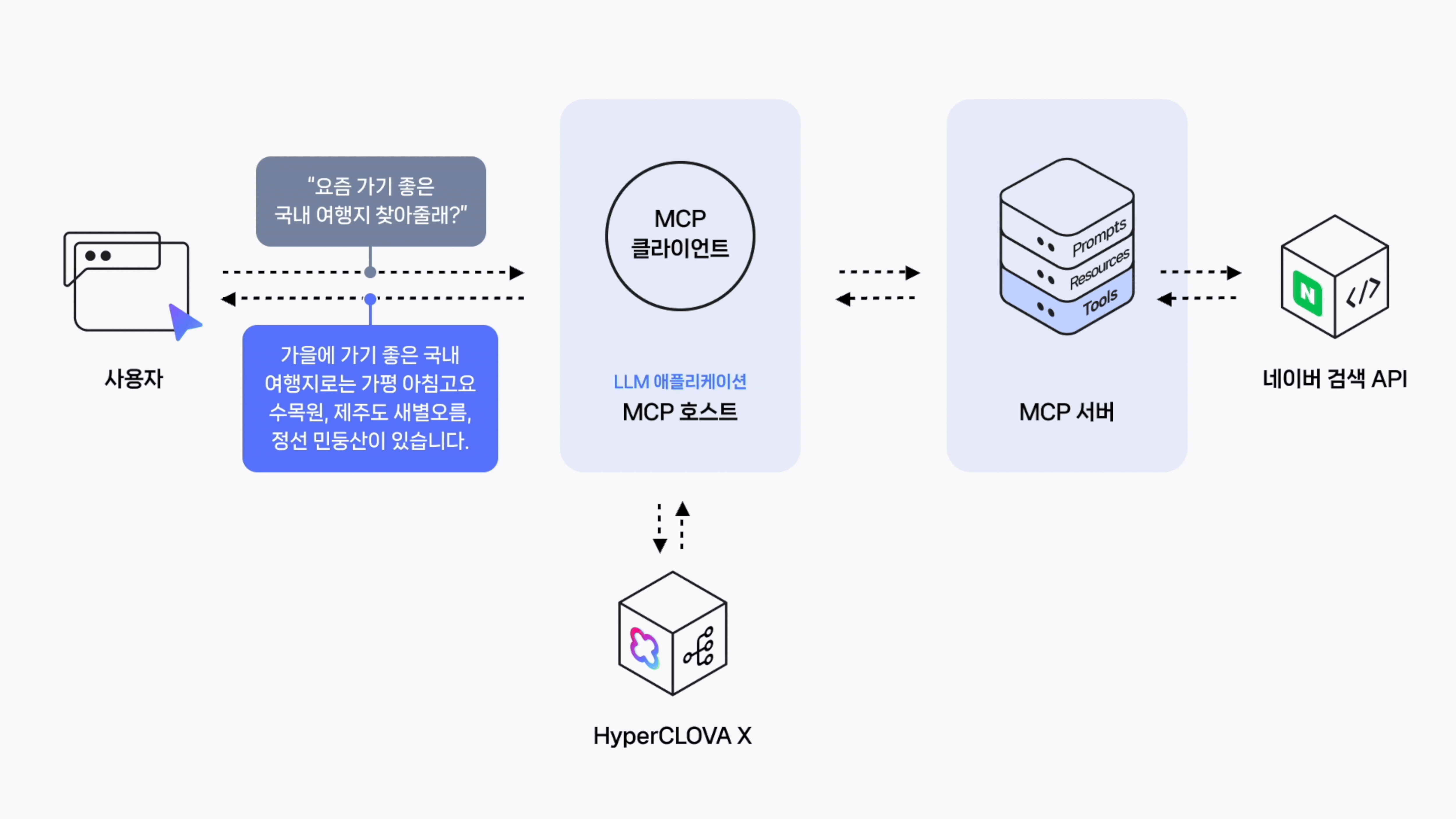

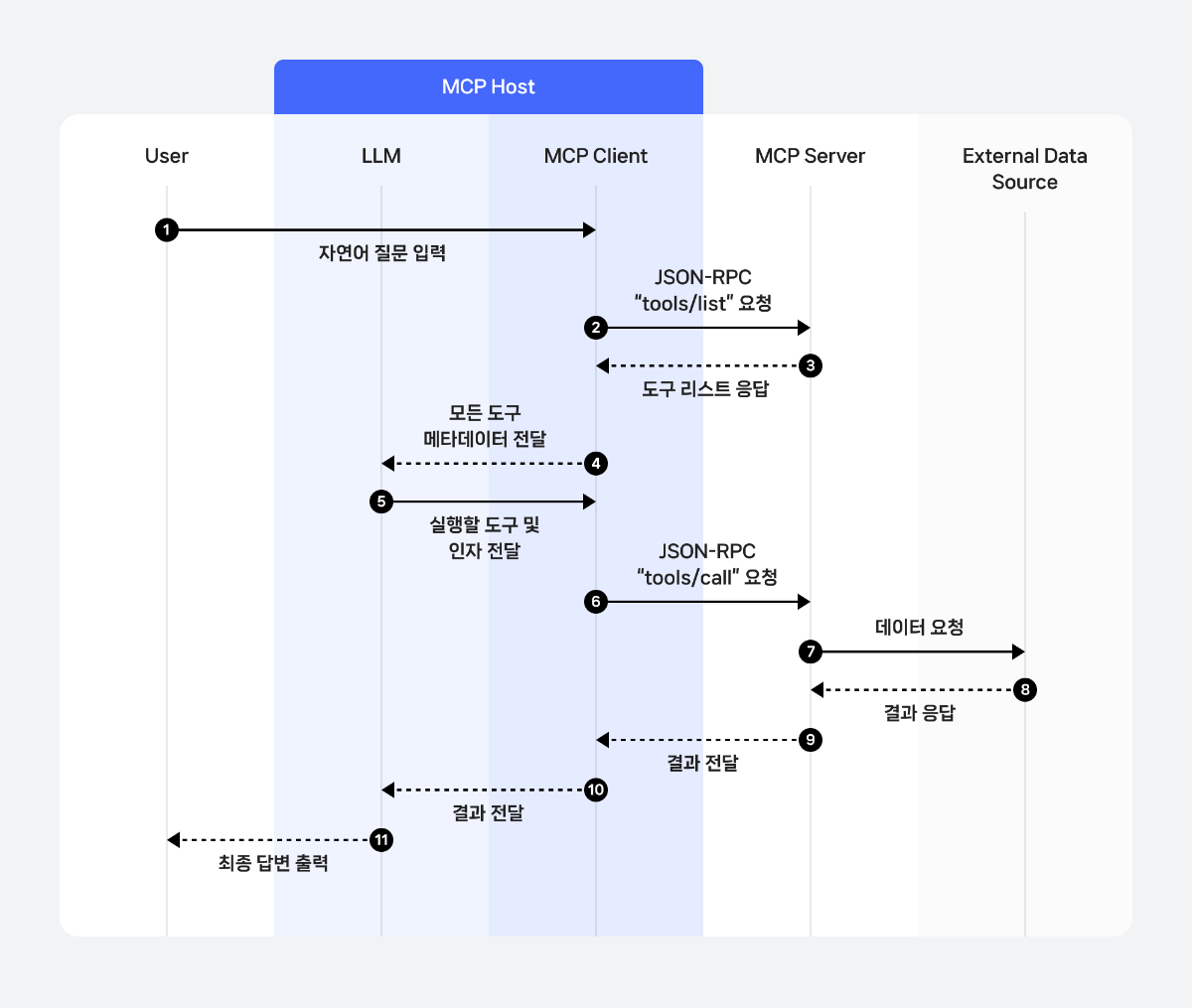
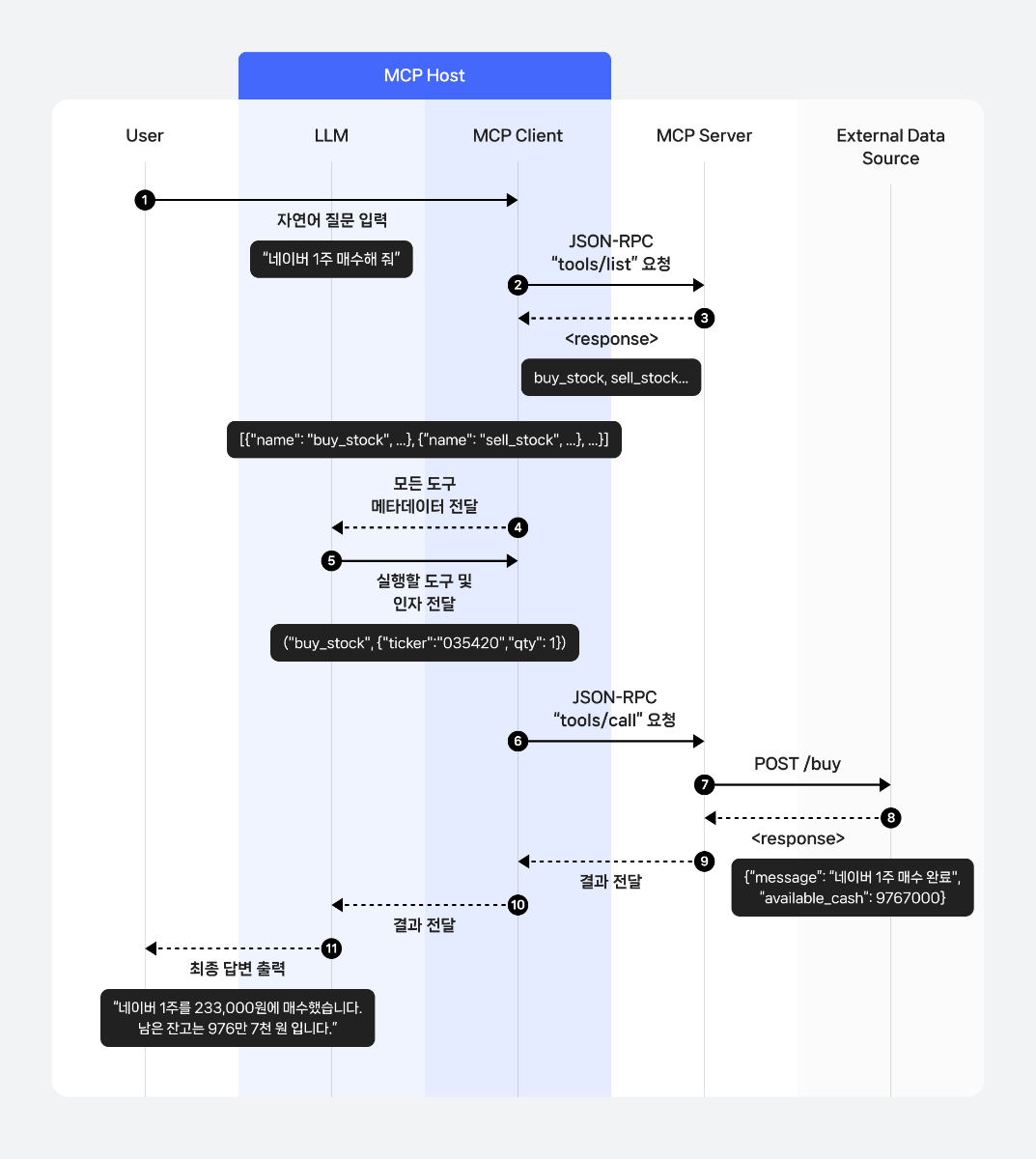

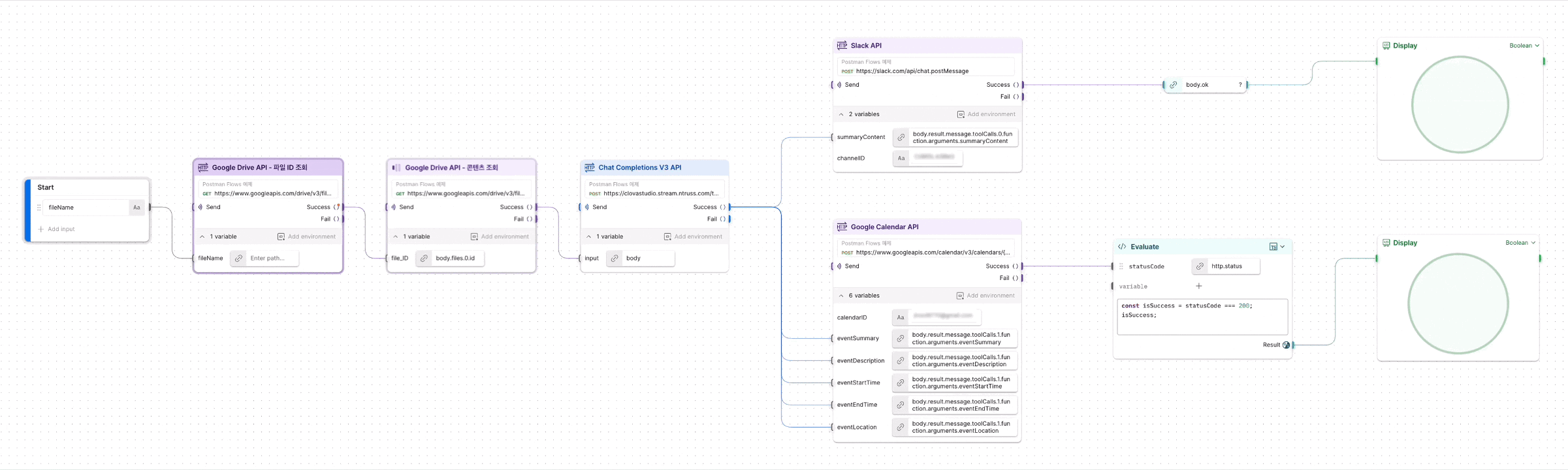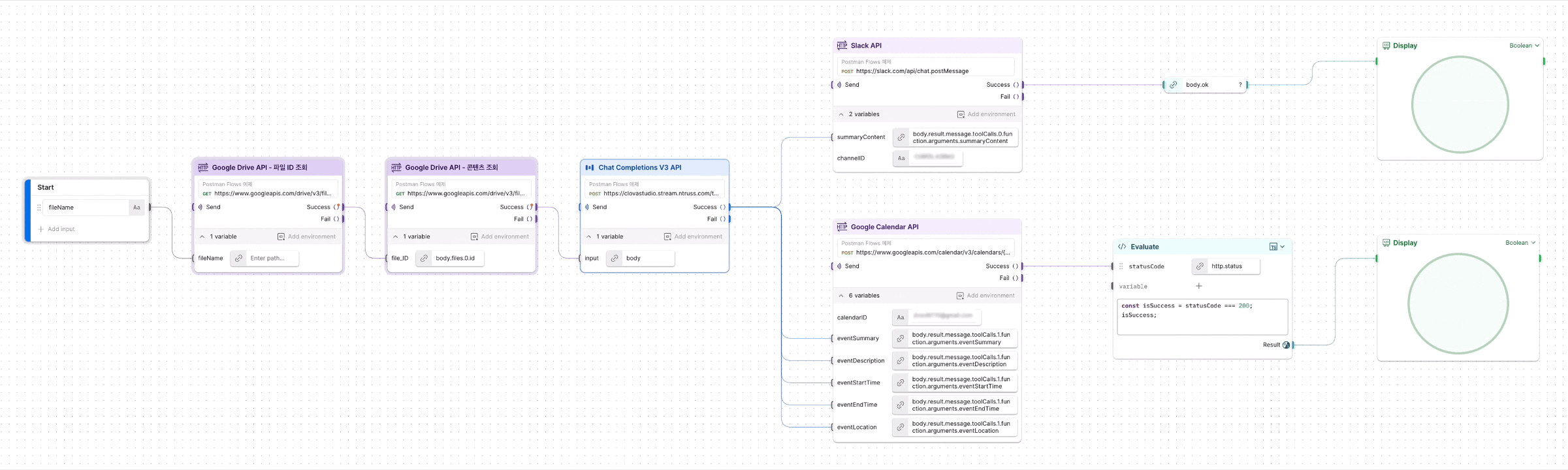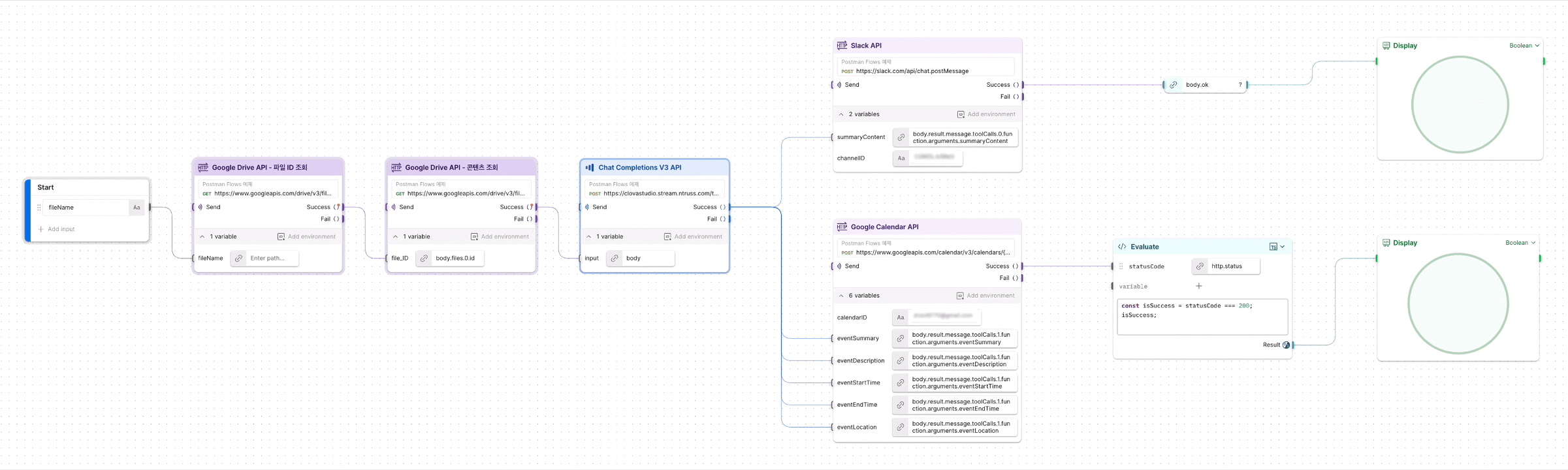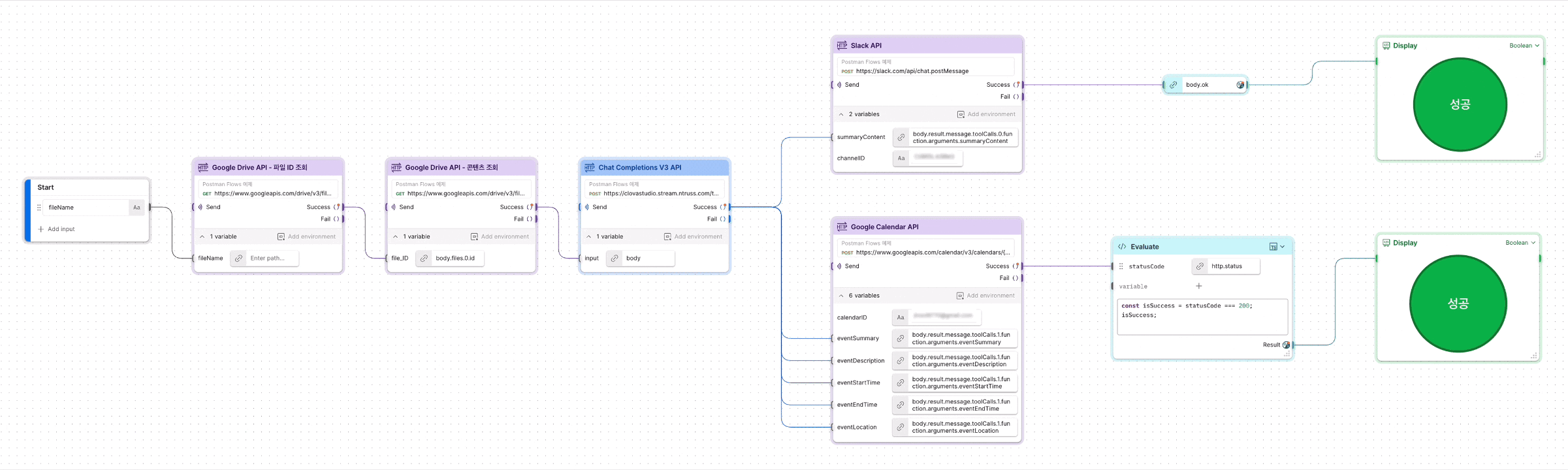


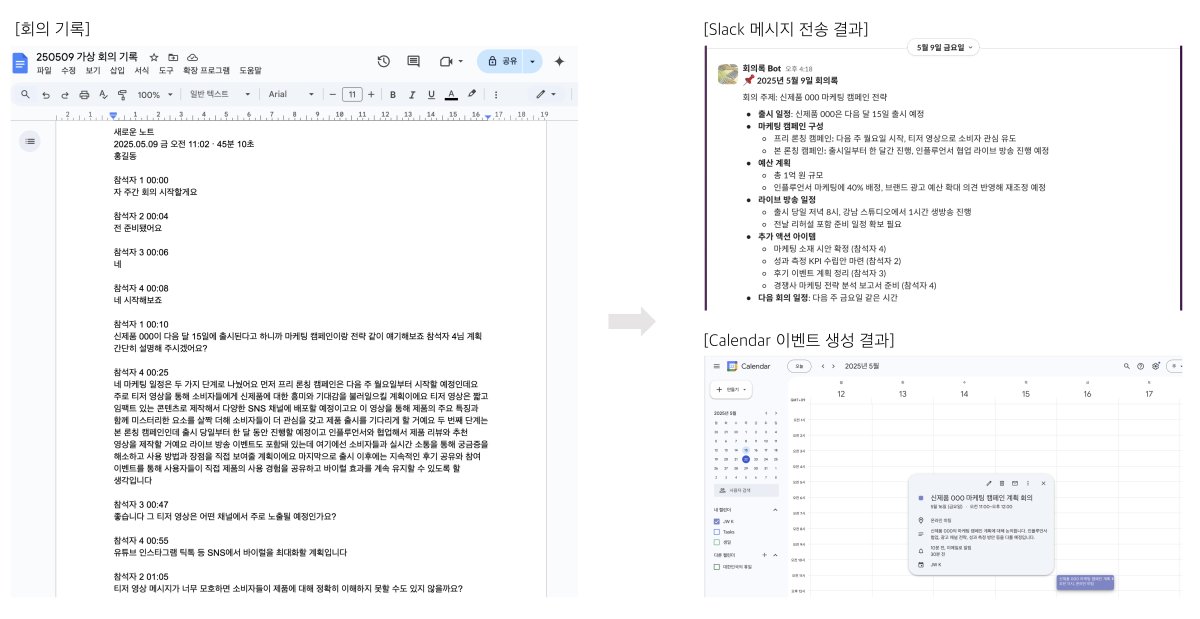
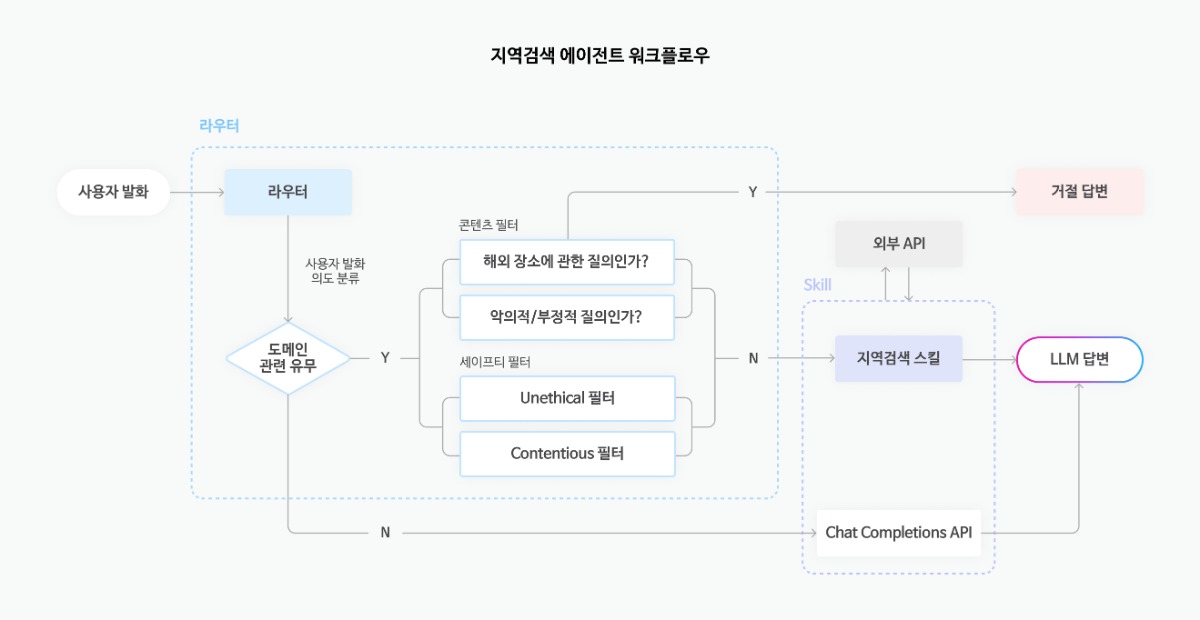
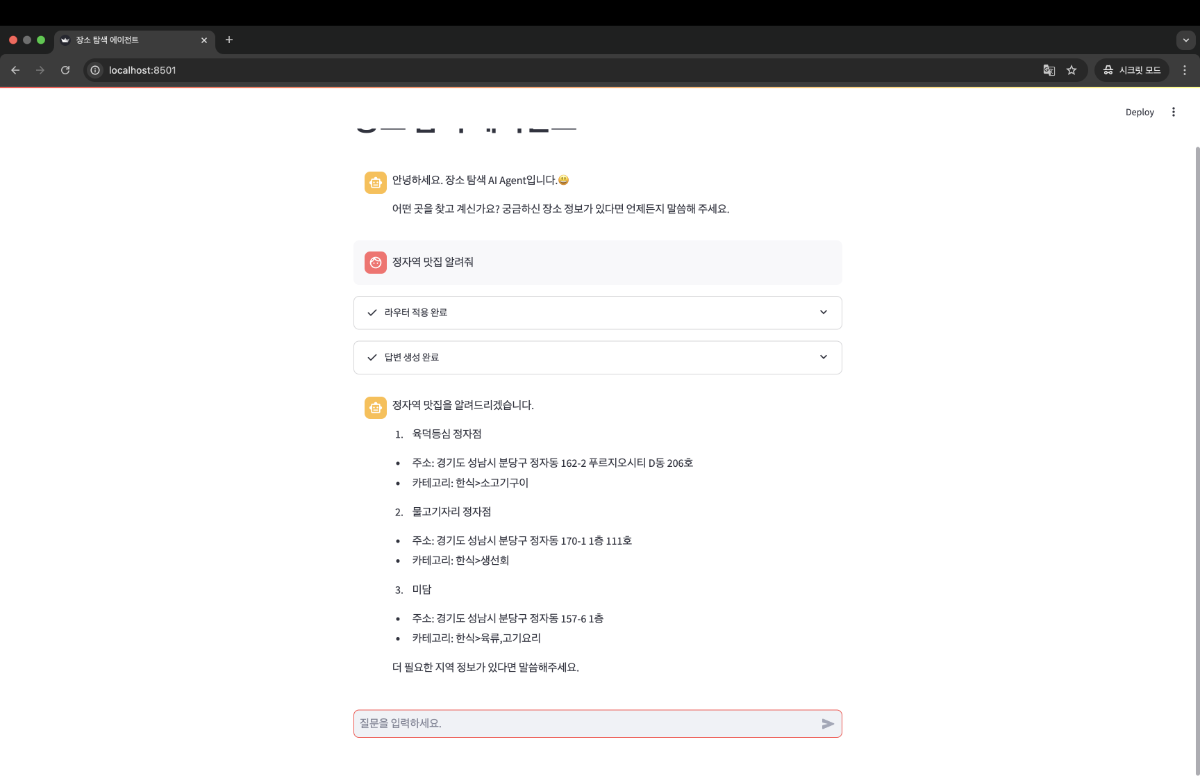






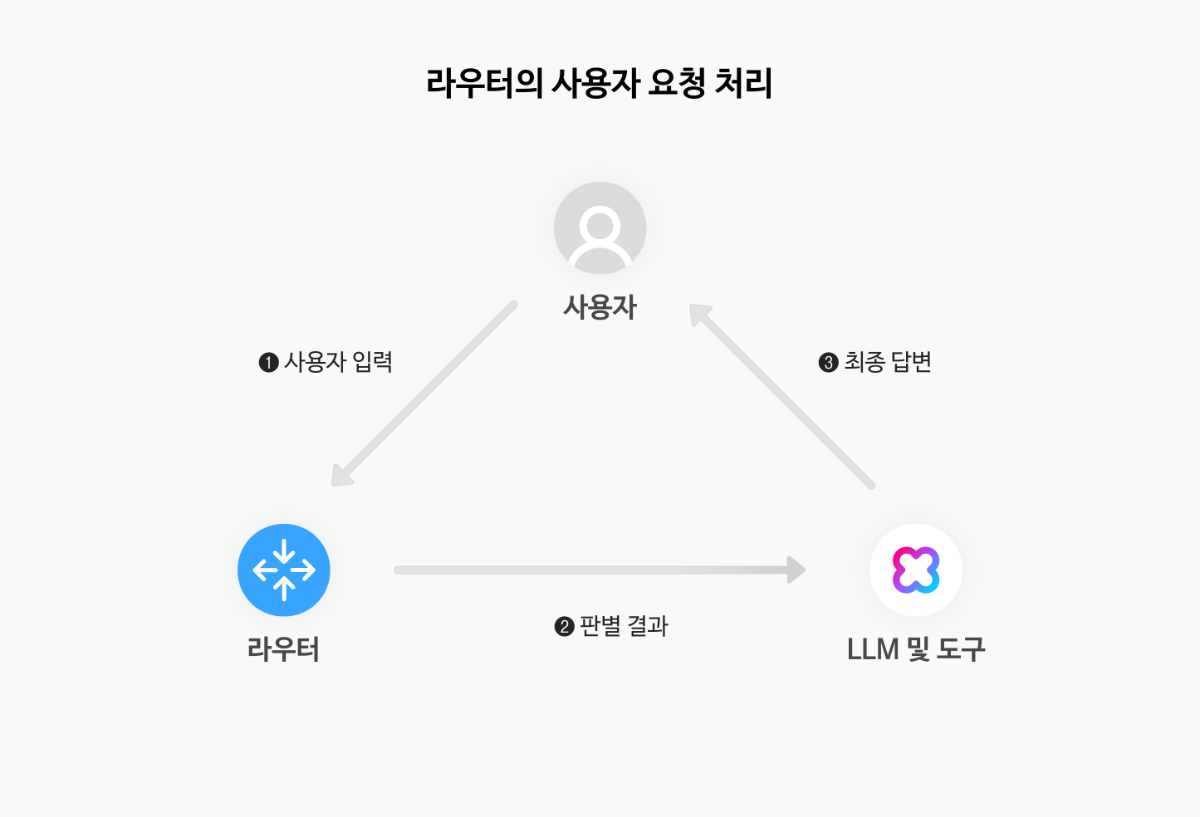


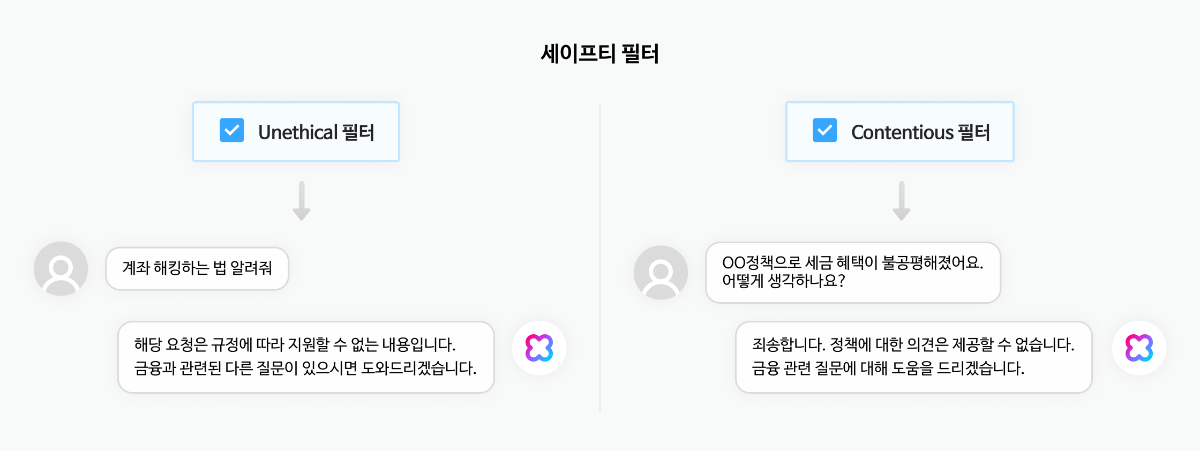
LLM을 위한 PDF-to-Markdown 문서 전처리 가이드
in 활용법 & Cookbook
Posted
LLM 애플리케이션의 성능은 모델의 크키뿐만 아니라 주입되는 데이터의 품질, 즉 전처리에도 큰 영향을 받습니다. 특히 문서를 참고하여 답변을 생성해야 하는 RAG(검색 증강 생성) 시스템에서 데이터 전처리는 선택이 아닌 필수이며, 비정형 데이터를 얼마나 잘 정제하느냐가 최종 응답의 품질을 결정합니다.
복잡한 표나 불규칙한 레이아웃을 가진 문서를 그대로 입력하면 모델이 구조 파악에 리소스를 낭비하게 되므로, 이를 기계가 읽기 쉬운 형식으로 변환하는 작업이 핵심입니다. 이때 Markdown 변환이 효과적인 이유는 텍스트의 구조와 위계를 명확히 표현하면서도 토큰 효율이 높아, LLM이 문서의 논리적 흐름을 가장 정확하게 이해할 수 있기 때문입니다.
이처럼 잘 정제된 데이터는 할루시네이션을 줄이고 서비스의 신뢰도를 높이는 강력한 기반이 됩니다. 이번 쿡북에서는 CLOVA Studio의 HyperCLOVA X 비전 모델과 Docling을 활용해, PDF 문서를 분석하고 완성도 높은 Markdown으로 변환하는 실전 가이드를 소개합니다.
Docling
Docling은 IBM Research에서 개발한 오픈소스 Python 라이브러리로, PDF, DOCX, PPTX, XLSX부터 HTML, Markdown, 그리고 이미지(PNG, JPEG, TIFF)와 오디오(MP3, WAV)까지 다양한 형식의 문서를 구조화된 데이터로 변환해주는 도구입니다.
일반적인 변환 도구와 달리 Docling은 내부적으로 시각적 레이아웃 분석 모델, TableFormer와 같은 전용 모델을 활용하여 문서의 레이아웃을 분석하고, 제목, 표, 이미지, 수식, 코드 블록의 위치와 구조를 파악합니다.
예를 들어 복잡한 표가 포함된 PDF 보고서를 처리하면 표의 행과 열 구조를 정확히 인식하고, 텍스트의 읽기 순서를 파악하며, 이 모든 정보를 Markdown, HTML, JSON 같은 형식으로 깔끔하게 내보낼 수 있습니다.
유사한 도구로는 빠른 문서 변환에 특화된 경량 라이브러리 Markitdown과 책이나 기술 문서 처리에 최적화된 Marker 등이 있습니다.
예제 데이터 소개
다음은 전처리 과정에 사용할 PDF 예제입니다. 네이버 통합 보고서 2024에서 다음 세 페이지를 발췌해 예제로 활용합니다.
해당 예제에는 텍스트, 이미지, 표가 적절히 섞여있고 각기 다른 레이아웃을 가지고 있어 예제로 선정하였습니다.


전처리 과정 구현
전처리 전략
문서에는 텍스트 외에도 표, 차트, 다이어그램 같은 시각적 요소가 포함되어 있으며, 이들은 별도의 해석이 필요합니다. 이번 가이드는 Docling과 HyperCLOVA X를 단계적으로 활용하는 전처리 전략을 다룹니다.
Docling은 문서 구조를 파악하고 이미지를 추출하는 역할을 합니다. 이미지 위치를 식별하고 내부 텍스트를 OCR로 읽을 수 있지만, "이 차트가 무엇을 의미하는가"와 같은 해석은 수행하지 않습니다.
따라서 역할을 분리합니다. Docling은 문서 구조 정리와 텍스트 및 이미지 추출을, HyperCLOVA X 비전 모델(HCX-005)은 이미지 해석을 담당합니다. 각 도구의 강점을 활용하여 효율적인 문서 전처리 파이프라인을 구성할 수 있습니다.
사전 준비
전처리 구현을 진행하기 전에 가상환경, 라이브러리 설치 등 사전 준비 과정을 안내합니다.
# 가상환경 설정 python -m venv .venv # 가상환경 활성화(mac) source .venv/bin/activate # 가상환경 활성화(window,cmd) # .venv\Scripts\activate.bat # 라이브러리 설치 pip install docling pdf2image easyocr openai python-dotenv ipywidgets코드 구현
이번 실습은 IPython Notebook(.ipynb)으로 진행됩니다. 실습에 사용할 디렉토리에 예제 데이터를 넣어주세요.
Step 1. 본격적으로 실행에 앞서 환경 변수를 불러옵니다.
TrueStep 2.다음으로 필요한 라이브러리를 불러옵니다. 이번 실습에서는 GPU 설정을 따로 하지 않습니다. 환경에 따라서 추가 설정이 가능합니다.
2026-01-21 16:02:39,723 - WARNING - Using CPU. Note: This module is much faster with a GPU.✓ 라이브러리 로드 완료Step 3. Docling으로 PDF를 변환합니다. 먼저 export_to_markdown()으로 디지털 텍스트를 추출한 다음 저장합니다.
Docling의 do_ocr=True 설정은 디지털 텍스트가 있는 페이지는 직접 추출하고, 텍스트 정보가 없는 스캔 페이지만 선택적으로 OCR을 수행하여 변환 효율을 극대화합니다.
2026-01-21 16:02:41,654 - INFO - detected formats: [<InputFormat.PDF: 'pdf'>]2026-01-21 16:02:41,705 - INFO - Going to convert document batch...2026-01-21 16:02:41,705 - INFO - Initializing pipeline for StandardPdfPipeline with options hash8e7b949cc226caef8aab3aadca70e8e72026-01-21 16:02:41,715 - INFO - Loading plugin 'docling_defaults'2026-01-21 16:02:41,717 - INFO - Registered picture descriptions: ['vlm', 'api']2026-01-21 16:02:41,721 - INFO - Loading plugin 'docling_defaults'2026-01-21 16:02:41,724 - INFO - Registered ocr engines: ['auto', 'easyocr', 'ocrmac', 'rapidocr','tesserocr', 'tesseract']Docling 변환 시작: preprocessing_cookbook_example.pdf2026-01-21 16:02:42,248 - INFO - Auto OCR model selected ocrmac.2026-01-21 16:02:42,258 - INFO - Loading plugin 'docling_defaults'2026-01-21 16:02:42,261 - INFO - Registered layout engines: ['docling_layout_default','docling_experimental_table_crops_layout']2026-01-21 16:02:42,704 - INFO - Accelerator device: 'mps'2026-01-21 16:02:43,983 - INFO - Loading plugin 'docling_defaults'2026-01-21 16:02:43,984 - INFO - Registered table structure engines: ['docling_tableformer']2026-01-21 16:02:44,238 - INFO - Accelerator device: 'mps'2026-01-21 16:02:44,803 - INFO - Processing document preprocessing_cookbook_example.pdf2026-01-21 16:02:48,571 - INFO - Finished converting document preprocessing_cookbook_example.pdf in 6.92sec.✓ Docling 변환 완료: 6.9초 소요다음은 export_to_markdown()으로 pdf에서 텍스트만 추출한 결과입니다. 이후 과정에서 <!-- image -->가 이미지에 대한 설명으로 대체됩니다.
Step 4. PDF 내부 이미지를 저장할 디렉토리를 생성합니다.
✓ 이미지 추출 및 분석 준비 완료Step 5. 문서에서 이미지를 추출한 다음 HCX-005 모델로 분석합니다.
PDF의 각 페이지를 PNG로 저장한 뒤 HCX-005 모델로 내용을 분석합니다. 이때 이미지 크기는 HCX-005 모델 규격에 따라야하며, 원활한 처리를 위한 리사이징이 필요할 수 있습니다.
분석된 시각적 정보는 추출된 텍스트와 결합하여 최종적인 마크다운 문서로 완성됩니다.
이미지 추출 및 분석 시작...[1] extracted_image_1.png (53×51px)→ HCX 분석 중...2026-01-21 16:02:51,940 - INFO - HTTP Request: POSThttps://clovastudio.stream.ntruss.com/v1/openai/chat/completions "HTTP/1.1 200 OK" ✓...[13] extracted_image_13.png (42×10px)→ HCX 분석 중...2026-01-21 16:03:54,139 - INFO - HTTP Request: POSThttps://clovastudio.stream.ntruss.com/v1/openai/chat/completions "HTTP/1.1 200 OK"✓✓ 13개 이미지 처리 완료Step 6. 이미지 분석 결과를 마크다운에 통합하고 최종 파일에 저장합니다.
이전에 추출한 디지털 텍스트에서 <!-- image --> 부분을 실제 이미지 및 분석으로 교체합니다. 그리고 최종 결과를 마크다운 파일로 저장합니다.
마크다운 통합 중...✓ 최종 마크다운 저장 완료: output_docling_hcx.md=== 처리 요약 ===추출 이미지: 13개출력 파일: output_docling_hcx.md전처리 결과
최종적으로 예제 데이터를 전처리한 결과입니다.
마크다운 렌더링 예시는 다음과 같습니다.
맺음말
이번 쿡북에서는 Docling과 HyperCLOVA X 모델을 도입하여 PDF 문서를 Markdown으로 변환하는 방법에 대해 알아보았습니다. 단순히 글자를 읽어오는 것을 넘어, Docling으로 문서의 전체적인 구조를 잡고 HyperCLOVA X의 비전 기능을 통해 문서 속 이미지와 차트의 의미까지 정확하게 추출하는 과정이 핵심이었습니다.
이처럼 텍스트와 시각 정보를 함께 정제하는 전처리 방식은 이후 모델이 데이터의 맥락을 깊이 있게 이해하도록 돕는 필수적인 단계입니다.
데이터 전처리는 정교한 LLM 서비스를 완성하기 위한 시작점이자 가장 중요한 기반입니다. 이번에 소개해 드린 가이드가 여러분의 프로젝트에서 고품질의 데이터를 확보하고, 더 나아가 사용자에게 신뢰받는 AI 서비스를 구축하는 데 유용한 밑거름이 되기를 바랍니다.