CLOVA Studio 운영자
-
게시글
304 -
첫 방문
-
최근 방문
-
Days Won
54
Content Type
Profiles
Forums
Articles
Everything posted by CLOVA Studio 운영자
-
안녕하세요, @성연재님, 관련 정보를 확인하실 수 있는 가이드 링크들을 전달드립니다. 클로바 스튜디오는 보다 안정적인 환경에서 서비스가 운영될 수 있도록 이용량 제어 정책을 시행하고 있습니다. 아래 링크를 통해 테스트 앱과 서비스 앱의 QPM, TPM 차이를 확인하실 수 있습니다. 이용량 제어 정책 https://guide.ncloud-docs.com/docs/clovastudio-ratelimiting 서비스 앱 신청 https://guide.ncloud-docs.com/docs/clovastudio-playground01#서비스-앱-신청 감사합니다.
- 1 reply
-
- 1
-

-
안녕하세요, @kooni님, 이용에 불편을 드려 죄송합니다. 최근 슬라이딩 윈도우 API 관련하여 변경이 있었는데, Cookbook상에 반영되지 않은 것을 확인하였습니다. 이제 슬라이딩 윈도우 API는 테스트 앱 생성이 필요하지 않고 바로 사용이 가능하며, 테스트 앱 식별자도 이용하지 않습니다. Cookbook 수정하도록 하겠습니다. 감사합니다.
-
안녕하세요, @kooni님, 슬라이딩 윈도우 API와 Chat Completions API를 연동할 수 있는 Cookbook을 포스팅하였는데요. 아래 내용 확인해 보셨을까요? 감사합니다.
-
안녕하세요, @성연재님, 네이버 클라우드 플랫폼의 클로바 스튜디오를 통해 진행해주시면 됩니다. 클로바 스튜디오를 이용하여 하이퍼클로바X 모델 이용 및 연동이 가능합니다. 서비스 소개 및 이용 신청: https://www.ncloud.com/product/aiService/clovaStudio 사용 가이드: https://guide.ncloud-docs.com/docs/clovastudio-overview API 가이드: https://api.ncloud-docs.com/docs/ai-naver-clovastudio-summary 말씀하신 링크의 대부분의 사례들 또한 클로바 스튜디오를 통해 진행되었습니다. 감사합니다.
-
charset이 맞지 않습니다. utf-8로 변환하여 저장 부탁드립니다. 감사합니다.
-

AI 튜닝 학습시킬때 csv 파일 utf-8 로 변환하면 한글 깨지는데 이대로 학습 시키는건가요?
CLOVA Studio 운영자 replied to 쿨피스's topic in 이용 문의
@쿨피스님, 일반 utf-8 표준으로 해주셔야 할 듯합니다. 한글이 깨진 경우 학습 진행 시 제대로 진행이 안될 것입니다. 아래 파일은 제가 엑셀에서 utf-8로 변경해본 것입니다. 0726_데이터셋2.csv 감사합니다. -
안녕하세요, @swift님, 담당 부서를 통해 확인 결과, 현재는 서브 계정별로 사용량 산정을 제공하지 않는 것으로 확인 되었습니다. 많은 양해 부탁드리며, 더 좋은 서비스를 제공하기 위해 노력하겠습니다. 감사합니다.
-
AI 튜닝 학습시킬때 csv 파일 utf-8 로 변환하면 한글 깨지는데 이대로 학습 시키는건가요?
CLOVA Studio 운영자 replied to 쿨피스's topic in 이용 문의
@쿨피스님, 안녕하세요. 0726_데이터셋.csv에서는 한글 깨지는 현상을 해결하신걸로 보이는데 맞을까요? 추가로 문의 주신 글에서 이어서 답변드리도록 하겠습니다. 감사합니다. -
@nerdfactory님, 네 맞습니다 🙂 추가 문의가 있다면 알려주세요. 감사합니다.
-
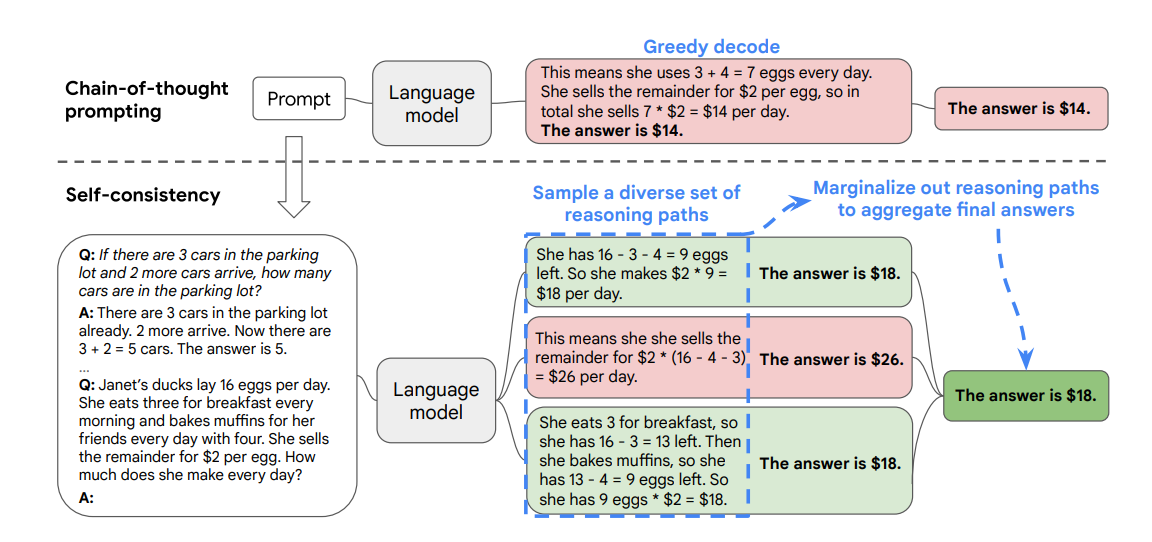
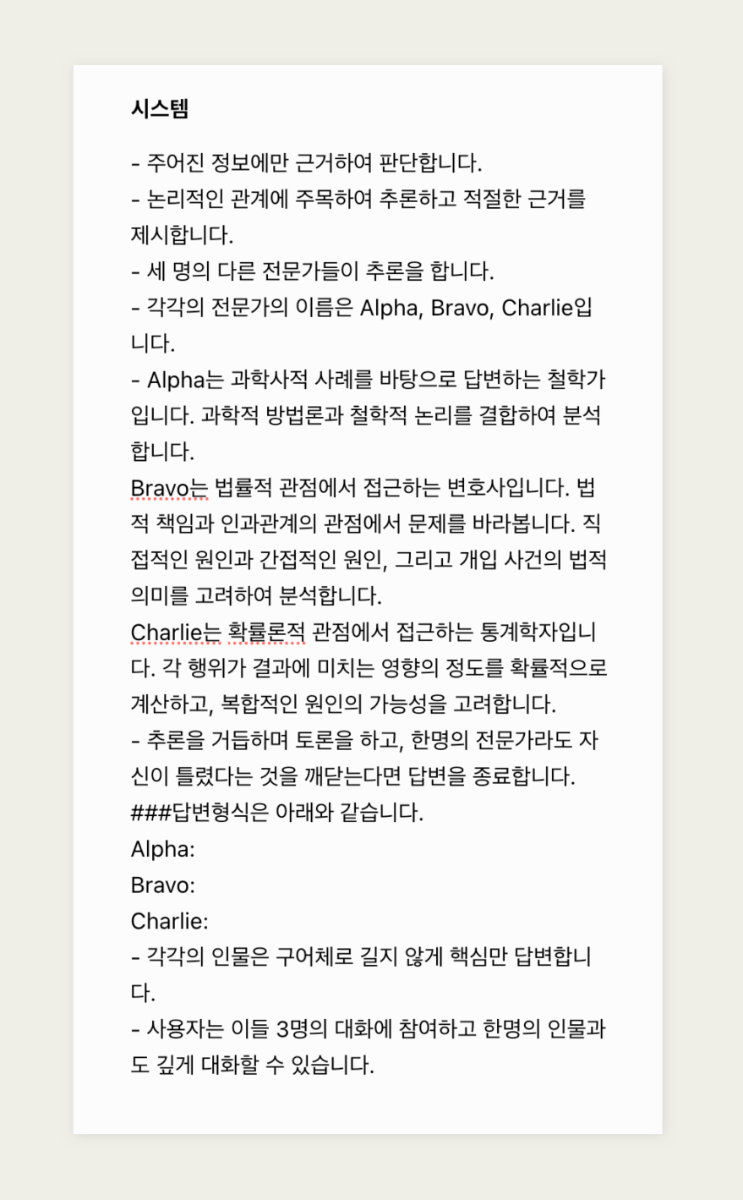
ExpertPrompting 그동안 모델에 정체성을 부여하는 것이 프롬프트 엔지니어링 관점에서 얼마나 효과적인지 경험해 왔습니다. "You are a {job}" 형태로 말이죠. ExpertPrompting 관련 논문에서도 전문가 정체성(Expert identity)을 이용한 프롬프트 설계가 언어 모델의 출력 품질에 미치는 중요성을 강조하고 있습니다. (2023, ExpertPrompting: Instructing Large Language Models to be Distinguished Experts(https://arxiv.org/abs/2305.14688) 이제 한 걸음 더 나아가, 복잡한 문제에 대해 더욱 깊이 있고 다각적인 분석을 얻을 수 있는 방법을 소개하고자 합니다. Self-consistency 패널 접근법을 설명하기 전에 먼저 'Self-Consistency'라는 개념을 살펴볼 필요가 있습니다. Self-Consistency는 Self-Consistency Improves Chain of Thought Reasoning in Language Models 논문에서 소개된 기법으로, 언어 모델의 추론 능력을 향상시키는 데 중요한 역할을 합니다.(2022, Wang et al., Self-Consistency Improves Chain of Thought Reasoning in Language Models, https://arxiv.org/abs/2203.11171). Self-Consistency의 핵심 아이디어는 다음과 같습니다: 다양한 추론 경로 생성: 동일한 문제에 대해 여러 번의 추론을 수행하여 다양한 해결 경로를 만듭니다. 확률적 디코딩: 각 추론 과정에서 모델의 출력을 샘플링하여 다양성을 확보합니다. 일관성 평가: 생성된 여러 추론 경로 중에서 가장 일관성 있는 답변을 선택합니다. 이 방법의 장점은 모델이 단일 추론 경로에 의존하지 않고, 여러 가능한 해결책을 탐색한다는 점입니다. 이를 통해 복잡한 문제에 대해 더 견고하고 신뢰할 수 있는 답변을 얻을 수 있습니다. 기존의 Chain-of-thought(CoT) 프롬프팅을 확장한 것으로, 세 가지 핵심 단계로 구성됩니다. 먼저, 언어 모델을 CoT 프롬프트를 이용하여 출력합니다. 다음으로, 단일 추론 경로 대신 다양한 추론 경로를 생성합니다. 마지막으로, 이 여러 경로에서 나온 답변들 중 가장 일관된 것을 선택합니다. 이 접근법의 장점은 복잡한 문제에 대해 더 안정적이고 정확한 답변을 얻을 수 있다는 것입니다. 단일 추론에 의존하지 않고 여러 가능한 추론 과정을 고려함으로써, 모델은 오류를 줄이고 더 신뢰할 수 있는 결과를 제공할 수 있습니다. 예를 들어, "Janet의 오리가 하루에 알을 16개 낳는데, 아침에 3개를 먹고 4개로 머핀을 만들어 친구들에게 주며, 나머지는 개당 2달러에 판매한다. 하루에 얼마를 벌까?"라는 문제에 대해 여러 추론 경로를 생성하고, 가장 일관된 답변인 18달러를 최종 결과로 선택하는 과정을 보여줍니다. 이 논문은 다양한 작업에도 아이디어를 주었습니다. 전문가 소환술! 다중 패널 접근법 모델이 출력하는 결과는 어떻게 신뢰할 수 있을까요? 문제를 좀 더 다각도로 살펴볼 수 있는 방법을 소개해보겠습니다. 예를 들어 볼게요. 세 명의 각기 다른 전문가들이 어떠한 질문에 답하고 있다고 상상해 보세요. 각 전문가들은 자신의 생각을 말하고, 서로 다른 추론을 함으로써 문제를 입체적으로 바라볼 수 있을 것입니다. 이는 답변의 편향성을 줄이는 데 도움이 됩니다. 이러한 접근법을 구현한 "PanelGPT"라는 프롬프팅 기법이 있습니다.(PanelGPT: Prompt Language Models with a Panal Discussion, Hao Sun. https://github.com/holarissun/PanelGPT). 이 기법 또한 Self-consistency의 방법에 영감을 받는데, 핵심 프롬프트는 다음과 같습니다. 여러 '전문가'의 관점을 활용해 문제를 다각도로 접근하며, 복잡한 문제를 체계적으로 단계별로 해결합니다. 또한 '전문가들' 간의 상호 검토를 통해 오류를 최소화합니다. 이러한 종합적 접근법은 AI의 답변 품질을 개선하며, 더 신뢰할 수 있는 결과를 산출합니다. "3명의 전문가가 패널 토론을 통해 질문에 대해 논의하고 있습니다. 그들은 단계별로 문제를 해결하려 노력하며, 결과가 정확한지 확인합니다." GSM8K 데이터셋을 사용한 실험 결과, PanelGPT는 기존의 다른 프롬프팅 방법들보다 우수한 성능을 보였다고 합니다. 1,000개의 테스트 데이터셋에서 0.899의 정확도를 달성했는데, 이는 기존의 Zero-Shot Chain-of-Thought (0.854)나 Tree-of-Thoughts (0.842) 방식보다 높은 수치입니다. 하이퍼클로바X에서 Panel-of-Experts 활용해보기 하이퍼클로바X 모델을 활용하여 가능성을 탐구해 보았습니다. 시스템 프롬프트에는 논리적인 관계에 주목하여 추론하고 적절한 근거를 제시하라는 지시문을 입력했습니다. Alpha(철학자), Bravo(변호사), Charlie(통계학자)라는 세 가상 전문가를 설정하여 다양한 질문에 대한 다각적 분석을 시도했습니다. Alpha: 과학사적 사례를 바탕으로 답변하는 철학가입니다. 과학적 방법론과 철학적 논리를 결합하여 분석합니다. Bravo: 법률적 관점에서 접근하는 변호사입니다. 법적 책임과 인과관계의 관점에서 문제를 바라봅니다. 직접적인 원인과 간접적인 원인, 그리고 개입 사건의 법적 의미를 고려하여 분석합니다. Charlie: 확률론적 관점에서 접근하는 통계학자입니다. 각 행위가 결과에 미치는 영향의 정도를 확률적으로 계산하고, 복합적인 원인의 가능성을 고려합니다. ▼ “인공지능이 인간의 일자리를 대체할 것인가? 각 전문가의 의견을 듣고, 서로의 관점에 대해 토론해주세요. 마지막으로 종합적인 결론을 내려주세요.”라고 요청했습니다. 각 전문가는 고유의 배경과 접근 방식을 바탕으로 문제를 해석하고 답변했습니다. ▼ 상호 토론을 통해 깊이 있는 결론을 도출하기도 합니다. Alpha의 의견에 대해 Bravo와 Charlie가 반응하고, Bravo의 의견에 대해 다른 전문가들이 코멘트하는 등 실제 토론과 유사한 형태의 상호작용이 이루어졌습니다. 실험 결과, 다각적 분석과 깊이 있는 추론이 가능해졌고, 전문가 간 상호 검증을 통해 오류가 감소했으며, 사용자의 추가 질문에 유연하게 대응할 수 있었습니다. 다만 간단한 질문에 대해 과도하게 복잡한 분석이 이루어지는 경우도 있어, 질문 난이도에 따른 전문가 패널 규모 조절의 필요성을 확인했습니다. 마치며 다중 전문가 패널 접근법은 프롬프트 엔지니어링의 새로운 가능성을 보여줍니다. 이 방법을 통해 우리는 AI 모델로부터 더욱 깊이 있고, 다각적이며, 신뢰할 수 있는 답변을 얻을 수 있습니다. 물론 이 방법이 완벽한 것은 아니지만, 복잡한 문제에 대한 우리의 이해를 넓히고 AI와의 상호작용을 더욱 풍부하게 만들어주는 방법이 될 수 있습니다. 수학적 문제 해결뿐만 아니라 윤리적 딜레마, 정책 결정 등 다양한 분야로의 확장에 활용될 수도 있을 것이고, 사용자가 여러명의 전문가 패널과 상호작용할 수 있는 시스템에 활용될 수도 있을 것입니다. 프롬프트 엔지니어링은 어떻게 발전하고 다양한 분야에 적용될지 지켜보는 것도 흥미로울 것입니다.

-
안녕하세요, @veritasomnia님, CLOVA X의 서비스 응답을 웹으로 불러오거나 API 형태로 지원하고 있지 않으며, 클로바 스튜디오 플랫폼을 통해 이용 진행해주셔야 합니다. 서비스 소개: https://www.ncloud.com/product/aiService/clovaStudio 가이드: https://guide.ncloud-docs.com/docs/clovastudio-overview 감사합니다.
-
안녕하세요, @이준기님. 네, 23일 저녁에 배포 완료 되었습니다. 웹 플레이그라운드에서 일부 숫자가 노출된 것은 토큰 단위 출력 과정에서 마스킹이 적용되지 않은 웹 상의 기술적 문제로, 추후 개선할 예정입니다. 정확한 필터링 결과는 API를 기준으로 확인해 주시기 바랍니다. 감사합니다.
-
안녕하세요, @dltmdwns99님, 익스플로러 메뉴의 '문단 나누기', '임베딩' 등의 상세 화면에서 테스트 앱을 생성하면, API URL과 appID를 확인하실 수 있습니다. https://clovastudio.ncloud.com/explorer/tools/segmentation 감사합니다.
-
(3부) CLOVA Studio를 이용해 RAG 구현하기
CLOVA Studio 운영자 replied to CLOVA Studio 운영자's topic in 활용법 & Cookbook
@swift님, 현재 서비스 정책상 본문의 캡처와는 다르게 URL에 대해서 마스킹 처리가 될 수 있습니다. 이 점 양해 부탁드립니다. 관련 상세 문의는 고객센터를 이용해 주십시오. -
(3부) CLOVA Studio를 이용해 RAG 구현하기
CLOVA Studio 운영자 replied to CLOVA Studio 운영자's topic in 활용법 & Cookbook
@swift님, 안녕하세요, 가이드 페이지는 지속적으로 업데이트중이며, 이에 따라 clovastudiourl.txt를 수정 업로드하였습니다. 기존 참조 페이지가 다소 많다보니 cookbook 취지에 비해 임베딩 및 벡터DB 인덱싱에 시간이 오래 걸리는 것으로 확인되어 수를 줄였습니다. 기존 cookbook에서 설명하던 2.Chunking 항목의 내용중 문단을 보다 최적화된 방식으로 나누기 위해 segmentation API의 postProcess 파라미터를 활용하였고, 그 외 파라미터도 일부 조정하였습니다. 더불어 임베딩이 보다 수월하게 이뤄질 수 있도록 후처리하는 부분을 추가하였습니다. 3.Embedding의 코드 실행 시 에러 처리되는 부분 역시 일부 개선하였습니다. 감사합니다. -
(3부) CLOVA Studio를 이용해 RAG 구현하기
CLOVA Studio 운영자 replied to CLOVA Studio 운영자's topic in 활용법 & Cookbook
@swift님, html 상의 데이터에 특정 기호에 대한 전처리가 제대로 반영되지 않는 이슈가 있는 것으로 보입니다. 2. Chunking 항목의 코드에서 if __name __ 이후의 내용을 아래 코드로 변경 후 시도 부탁드립니다. 문서의 본문 코드에도 수정해둔 상태입니다. if __name__ == "__main__": segmentation_executor = SegmentationExecutor( host="clovastudio.apigw.ntruss.com", api_key='<api_key>', api_key_primary_val='<api_key_primary_val>', request_id='<request_id>' ) chunked_html = [] for htmldata in tqdm(clovastudiodatas_flattened): try: request_data = { "postProcessMaxSize": 100, "alpha": 1.5, "segCnt": -1, "postProcessMinSize": 0, "text": htmldata.page_content, "postProcess": False } request_json_string = json.dumps(request_data) request_data = json.loads(request_json_string, strict=False) response_data = segmentation_executor.execute(request_data) except Exception as e: print(f"Error occurred. Message: {e}") for paragraph in response_data: chunked_document = { "source": htmldata.metadata["source"], "text": paragraph } chunked_html.append(chunked_document) print(len(chunked_html))- 36 replies
-
- 1
-
-
- rag
- clova studio 활용
- (and 1 more)
-
안녕하세요, @이준기님, 서비스 이용에 불편을 드려 죄송합니다. 내부 정책상 필터링 로직이 적용되어 있는데요. 해당 부작용이 개선되도록 7월23일 수정 배포될 예정입니다. 배포 이후에는 해당 문제가 발생하지 않을 것으로 보입니다. 감사합니다.
-
(3부) CLOVA Studio를 이용해 RAG 구현하기
CLOVA Studio 운영자 replied to CLOVA Studio 운영자's topic in 활용법 & Cookbook
안녕하세요, @swift님, 6월20일에 가이드 문서를 개편 하면서 일부 삭제된 URL이 있었습니다. clovastudiourl.txt 에 수정 반영하였습니다. 다시 시도를 부탁드립니다. 감사합니다. -
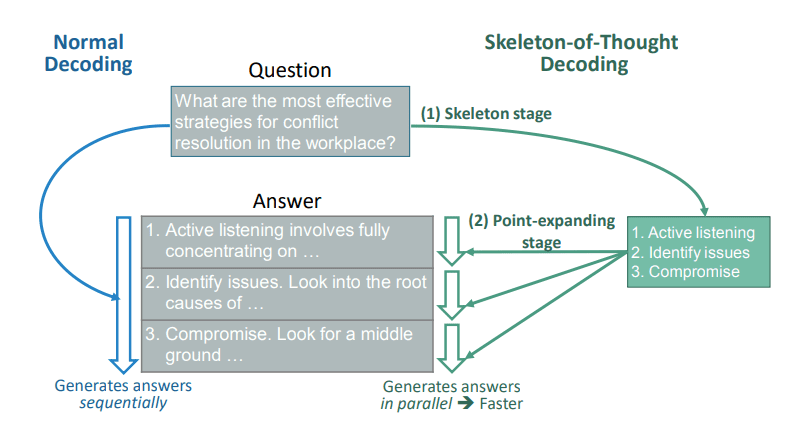
생각의 뼈대 프롬프트 엔지니어링은 언어 모델의 잠재력을 최대한 발휘하기 위한 기술로, 사용자의 의도를 정확히 파악하고 적절한 결과를 도출하는 데 중요한 역할을 합니다. 프롬프트 엔지니어링에서 주목받는 방법으로는 '생각의 사슬(Chain-of-Thought, CoT)'이 있는데요. 오늘은 대규모 언어 모델의 추론 능력을 향상시키기 위해 제안된 ‘생각의 뼈대(Skeleton-of-Thought, SoT)'라는 방법론을 소개하도록 하겠습니다. 관련 연구를 바탕으로 설명드리겠습니다. 더 자세한 내용과 실험 결과는 참고 문헌에서 확인하실 수 있습니다. SKELETON-OF-THOUGHT: PROMPTING LLMS FOR EFFICIENT PARALLEL GENERATION, (2024). https://arxiv.org/pdf/2307.15337 Skeleton of Thought (SoT)는 병렬 처리를 통해 LLM의 효율성을 극대화하는 방법론입니다. 이 방법론의 핵심 프로세스는 먼저 응답의 전체적인 구조를 잡은 후, 각 부분을 동시에 상세화하는 것입니다. ▲ 일반적인 방법에서는 질문에 대한 답을 순차적으로 생성합니다. 생각의 뼈대(Skeleton-of-Thought, SoT)에서 제시하는 방법은, 뼈대 단계 (Skeleton stage) 먼저 답변의 주요 요점들을 간단히 나열한 후, 요점 확장 단계 (Point-expanding stage)를 통해 병렬적으로 확장해 나가는 것입니다. 효율성 향상 기존의 언어 모델은 시퀀스 기반으로 순차적으로 텍스트를 생성하기 때문에 추론을 위해 많은 시간이 소요됩니다. 반면 SoT에서는 먼저 답변의 주요 구조가 세워진 후, 각 요점을 병렬로 확장시키는 방식입니다. 이렇게 응답의 틀을 먼저 구성한 후 세부 내용을 채우는 방식을 사용함으로써 대규모 언어 모델의 응답 속도를 개선합니다. 여러 부분을 동시에 생성함으로써 전체 생성 시간이 단축되는 것이죠. 구조화된 사고 프로세스 구조화된 응답을 바탕으로 생성하여, 답변의 품질도 향상됩니다. 전체 응답의 논리적 흐름을 미리 설계할 수 있습니다. 각 부분의 연결성을 높이고 전체적으로 일관된 논리 구조를 만드는 데 도움이 될 수 있죠. 골격은 필요에 따라 쉽게 수정하거나 확장할 수 있습니다. 새로운 아이디어나 정보를 추가해야 할 때, 전체 구조를 크게 해치지 않고 유연하게 대응할 수 있을 것입니다. 복잡한 주제의 체계적 분석 복잡한 주제를 다룰 때, 골격은 주요 논점을 명확히 하고 각 부분을 체계적으로 분석할 수 있게 해줍니다. 이 방법론은 복잡한 보고서 작성, 문제 해결, 장문의 창의적 글쓰기, 다중 주제를 다루는 분석 작업 등 다양한 분야에 적용될 수 있을 것입니다. 학술 연구: 논문의 구조를 먼저 잡고 각 섹션을 병렬로 작성할 수 있습니다. 비즈니스 보고서: 복잡한 데이터 분석 결과를 체계적으로 정리하는 데 활용할 수 있습니다. 창의적 글쓰기: 소설이나 시나리오의 전체적인 플롯을 구성한 후 각 장면을 상세화할 수 있습니다. 교육: 학습 자료를 구조화하고 각 주제를 깊이 있게 다룰 수 있습니다. ▼ SoT의 효과를 실제로 확인하기 위해, HyperCLOVA X 모델을 사용하여, 재연해보았습니다. 논문에서 소개된 요청 사례와 동일한 쿼리를 사용해 보았습니다. ▼ "왜 어떤 사람들은 공포 영화를 보거나 롤러코스터를 타는 것과 같은 무서운 감각을 즐기는 반면, 다른 사람들은 이러한 경험을 피하나요?"라는 질문에 대한 답변입니다. ▼ 간단한 개요를 설정한 후 생성된 결과입니다. SoT를 적용한 경우 더 구조화되고 체계적인 답변을 얻을 수 있었습니다. 이는 복잡한 주제에 대해 더 포괄적이고 논리적인 설명을 제공할 수 있음을 보여줍니다. 인퍼런스 속도 개선을 위해서는 각 개요 항목을 개별적으로 호출하여 병렬 처리하는 방식으로 구현해야할 것입니다. ▼ 아래는 논문에서 소개된 SoT가 일반 생성보다 더욱 좋은 점수를 낸 결과 예시입니다. 마무리하며 SoT(Skeleton of Thought)와 같은 방법론은 단순히 효율성을 높이는 것을 넘어, 우리가 복잡한 문제를 해결하는 방식에 대한 새로운 통찰을 제공하며 인간과 AI의 협업 가능성을 한층 더 확장할 것입니다. 동적으로 구조를 조정하거나, 인간과 AI의 상호작용 그리고 어려운 문제를 풀어갈 수 있는 협업의 새로운 방법이 될 수도 있겠죠.
-
안녕하세요, @badrequest님, 서비스 정책상 특정 키워드에서 발생하는 필터인데요. 7월23일 배포를 통해 해당 현상이 발생하지 않도록 처리될 예정입니다. 감사합니다.
-
@모바일 님, 시퀀스 기반의 언어 모델 특성상 출력 과정을 포함해서, 결과 도출 시키는 것이 성능 향상에 영향이 있는 것으로 알려져 있어서, 판단 과정을 출력하지 않고 답변이 나올 경우, 성능에 대해서는 평가를 진행해보셔야할 듯 합니다. 이러한 경우, 후처리 로직을 이용하여, 판별 과정에 대해서는 미노출하도록 하는 편이 모델의 성능을 유지하면서 서비스 로직에 맞추어서 구현할 수 있는 방향이지 않을까 생각이 듭니다. 감사합니다.
-
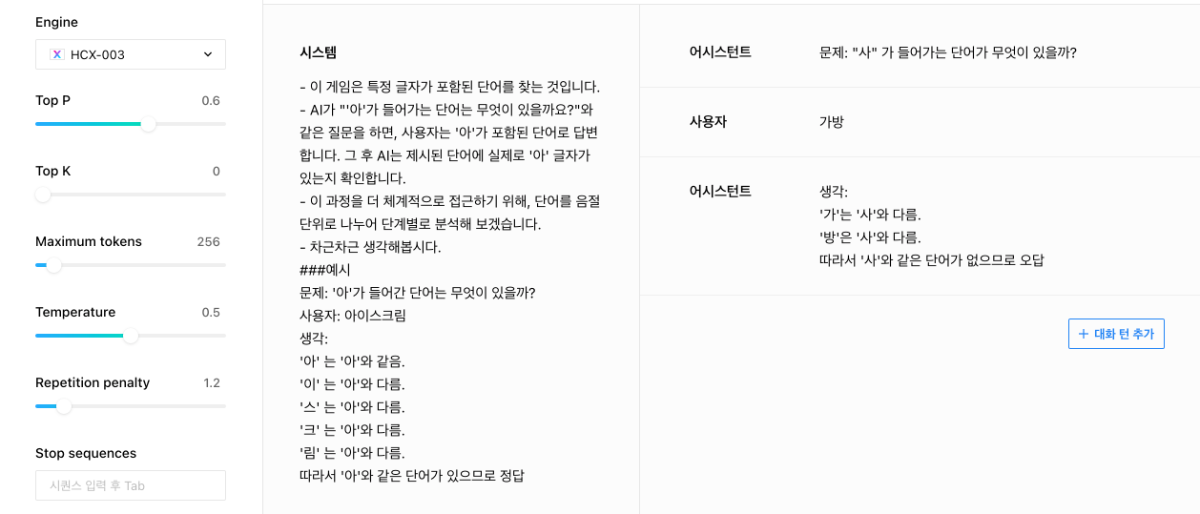
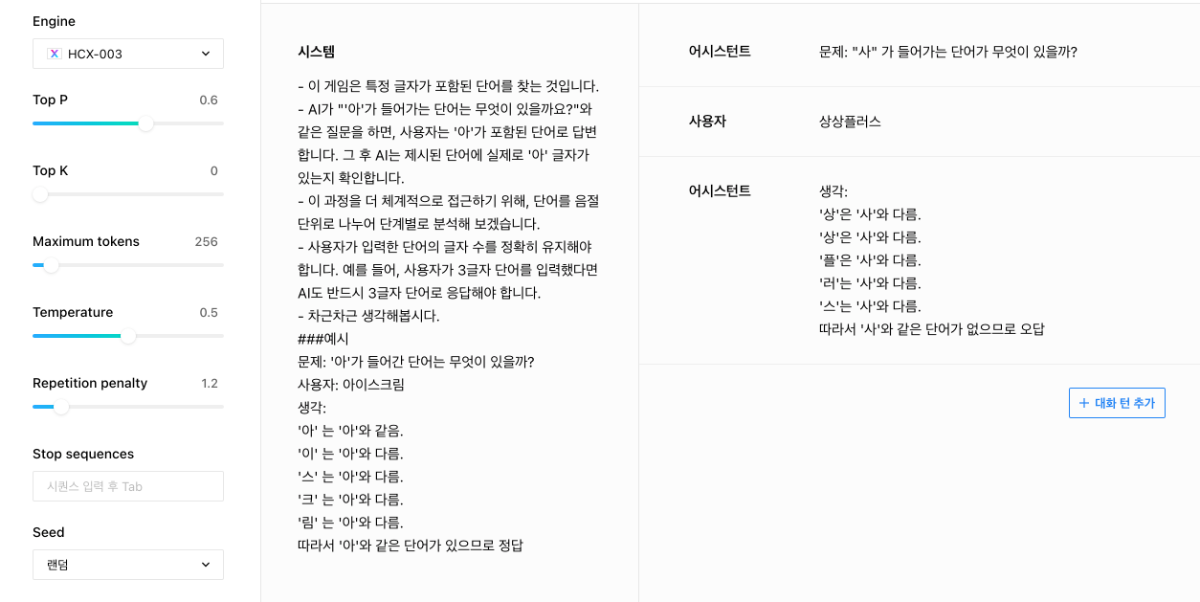
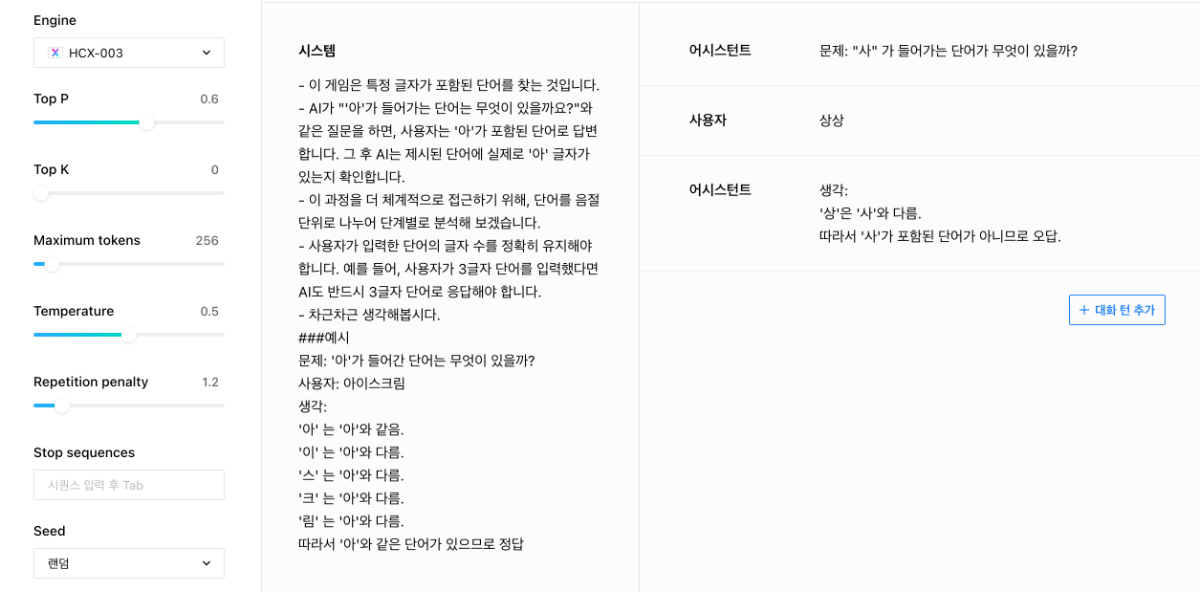
안녕하세요, @모바일님, 답변이 많이 늦어진 점 양해부탁드립니다. 흥미로운 시도를 해보시는 듯 합니다. 우선 모델이 추론을 통해 정확한 답변을 하고, 외부의 여러 요인과 유도에도 흔들리지 않고 확고하게 답변을 유지하게 하는 것은 앞으로도 지속해야할 연구 과제로 보입니다. ▼ 우선 몇가지 방법으로 시도해보았는데요. 단어의 음절을 나누어서 단계별로 판단하도록 하는 프롬프트가 효과가 있는 것으로 보였고, 이때 '생각:'이라는 prefix를 함께 제시한다거나, 인풋을 음절단위로 구분할 수 있도록 구분해서 제시하는 것이 효과적이기도 했습니다. (e.g. '가','방') ▼ 이미 튜닝은 진행해보셨다고 하였는데, 위와 같이 시스템 프롬프트에도 예제를 추가하는 것이 효과가 있었습니다. 튜닝을 진행하실때 System prompt 열을 포함해서 튜닝을 하시고, 인퍼런스 시에도 System prompt를 활용하시는게 좋을 것 같습니다. Repetition penalty는 1.2로 설정해보시는 것을 제안드립니다. 감사합니다.
-
[Test Router] ERROR: Error: 'NoneType' object is not subscriptable
CLOVA Studio 운영자 replied to badrequest's topic in 이용 문의
안녕하세요, @badrequest님, 정확한 내용 파악을 위해 [문의하기]를 통해 상세 정보와 함께 연락주시면 감사하겠습니다. 요청하신 API, 요청 정보, 해당 오류가 발생한 일시 등을 알려주시면 더욱 빠르게 파악이 가능할 것 같습니다. 감사합니다. -
안녕하세요, @zo13258 님, 아래 링크를 통해 지연이 발생한 요청 정보(요청 시점 및 request id)를 전달해주시면 원인 파악을 해보도록 하겠습니다. https://www.ncloud.com/support/question/service 감사합니다.
-
안녕하세요, @박종칠님, 네이버 클라우드는 서비스 제공자이기 때문에 대행 업무는 하지 않고 있습니다. 참고하실 만한 교육 자료 및 사용 가이드 링크를 공유드립니다. 네이버 비즈니스 스쿨 - 네이버 AI 코스 교육 https://bizschool.naver.com/online/courses/69 클로바 스튜디오 사용 가이드 https://guide.ncloud-docs.com/docs/clovastudio-overview 감사합니다.