CLOVA Studio 운영자
-
게시글
304 -
첫 방문
-
최근 방문
-
Days Won
54
Content Type
Profiles
Forums
Articles
Everything posted by CLOVA Studio 운영자
-
안녕하세요, @hatiolab님, 튜닝 학습시에도 System prompt를 포함하여 학습이 가능하도록 곧 반영될 예정입니다. 해당 기능을 토대로 보다 정확한 답변을 얻을 수 있지 않을까 생각이 됩니다. 학습해야할 지식이 아주 많을 경우에는 RAG 구축을 이용하시는 것이 효과적일 수 있습니다. RAG 구축의 경우, 클로바 스튜디오를 통해 구현할 수 있는 Cookbook을 조만간 업데이트 드릴 예정이니, 참고하셔도 좋을 것 같습니다. 감사합니다. @TABA님, 답변 감사드립니다.
-
네, 공유 감사합니다. 이용하시다가 문의사항이 있으시면 또 알려주세요. 감사합니다.
-
@DevLee님, 아래 링크를 통해 요청하신 정보나 작업 링크(공유 비밀번호 포함)대해서 자세히 안내주시면, 보다 자세히 살펴보도록 하겠습니다. https://www.ncloud.com/support/question/service 감사합니다.
-
@DevLee님, MaxTokens를 어떻게 설정하셨는지 알 수 있을까요? MaxTokens 설정값으로 인해 문장 출력이 잘리는 것으로 보이며, MaxTokens의 설정을 조금 더 늘린 후 실행을 하시면 될 듯 합니다. 감사합니다.
-
@DevLee님, 네 맞습니다. 클로바 스튜디오의 플레이그라운드를 통해 HCX 모델을 이용하는 것과 Chat Completions API를 통해 HCX 모델을 이용하는 것과 동일합니다. 다만, LLM 특성상 요청마다 출력 결과가 달라질 수 있는 점을 말씀드립니다. 감사합니다.
-
안녕하세요, @DevLee님, 클로바 스튜디오 담당입니다. 토큰 단위로 스트리밍 되는 것이 아니라, 출력 결과를 바로 받는 방법을 문의하신 것으로 이해했습니다. Header의 text/event-stream을 N으로 요청하시면, 토큰 스트리밍이 아닌 형태로 응답 결과를 받을 수 있습니다. 가이드: https://api.ncloud-docs.com/docs/clovastudio-sendchatcompletionsbymodelname 추가 문의가 있으실 경우 언제든지 알려주세요. 감사합니다.
-
안녕하세요, @beans님, 클로바 스튜디오를 이용해주셔서 감사합니다. 현재 API를 통한 중단은 지원하지 않으며, 웹을 통해서만 중단이 가능합니다. 인증 오류는 코드 에러로 보입니다. 코드를 보니 requests.get() 이 아니라 requests.delete() 를 호출하셔야 할 것 같습니다. 감사합니다.
- 1 reply
-
- 1
-

-
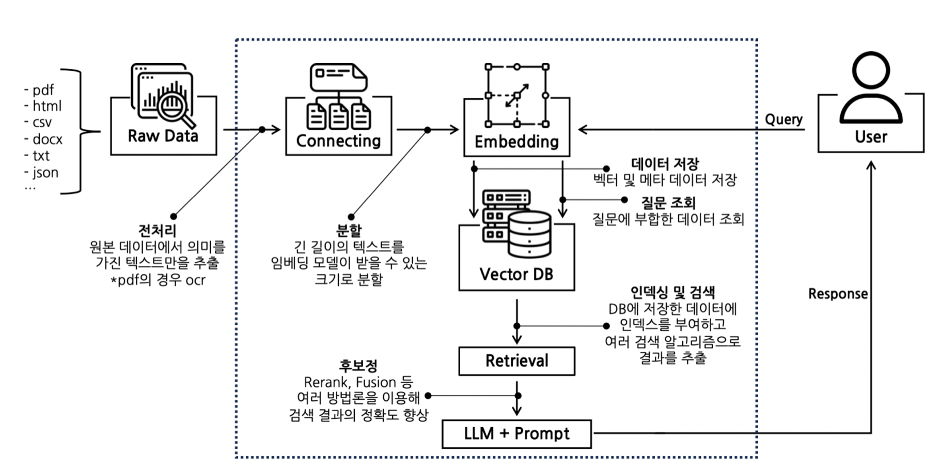
이번 포스팅은 'RAG(Retrieval-Augmented Generation)'을 주제로 한 시리즈의 첫 번째 글입니다. 총 3부로 구성된 이 시리즈에서는 RAG가 등장하게 된 배경과 RAG의 개념에 대해 자세히 알아보고자 합니다. RAG 3부작 시리즈 ✔︎ (1부) RAG란 무엇인가 ✔︎ (2부) RAG 구현 단계 알아보기 링크 ✔︎ (3부) CLOVA Studio를 이용해 RAG 구현하기 Cookbook 링크 LLM의 등장과 한계 대규모 언어 모델(LLM)의 등장은 인간만이 가능하다고 여겨졌던 많은 분야에서 인공지능의 잠재력을 보여주었습니다. 방대한 양의 데이터를 기반으로 학습한 LLM은 인간 수준의 텍스트를 생성하고, 다양한 질문에 답변을 제공하며, 나아가 창의성이 요구되는 예술 분야에서도 두각을 나타내고 있습니다. 그러나 LLM이 보편화된 지 약 2년이 지난 지금, 이를 상용화하려는 많은 기업은 오랜 문제에 직면하고 있습니다. 그 문제는 바로 '할루시네이션'입니다. 인공지능 챗봇과의 대화에 큰 기대를 품었던 사용자들은 LLM이 제공하는 부정확하고 불완전한 답변에 실망하곤 합니다. 이는 할루시네이션 문제와 밀접한 관련이 있습니다. 할루시네이션은 단순히 사실이 아닌 내용을 만들어내는 문제를 넘어, LLM이 데이터의 최신성이나 출처의 투명성 확보와 같은 '정보 검색 방식의 질적 전환'에 필수적인 기능을 갖추지 못했음을 시사합니다. 아무리 그럴듯해 보여도 실제로는 도움이 되지 않는 답변으로는 기존의 정보 검색 패러다임을 변화시킬 수 없을 것입니다. *할루시네이션: 편향되거나 불충분한 학습 데이터, 모델의 과적합 등으로 인해 LLM이 부정확한 정보를 생성하는 현상 LLM의 한계를 뛰어넘는 방법: RAG 이러한 LLM의 한계를 극복하기 위해 여러 방법이 제안되고 있습니다. 그중 하나는 Fine tuning으로, 사전 학습 모델(pre-trained model)에 특정 도메인(예: 의료, 법률, 금융)의 데이터를 추가 학습시켜 모델을 최적화하는 방식입니다. 이를 통해 모델은 특정 분야에 대한 전문 지식을 습득하고 정확하고 전문적인 답변을 제공할 수 있습니다. 그러나 Fine tuning은 시간과 비용이 많이 소요되고, 모델의 범용성이 저하될 수 있습니다. 반면 RAG는 외부 지식 소스와 연계하여 모델의 범용성과 적응력을 유지하면서도 정확하고 신뢰할 수 있는 답변을 생성할 수 있습니다. 즉, RAG는 LLM의 한계를 극복하면서도 그 장점을 살릴 수 있는 접근 방식이라고 할 수 있습니다. RAG의 작동 방식은 다음과 같습니다. 사용자가 질문을 입력합니다. RAG는 외부 데이터베이스(예: 웹 문서, 기업 내부 문서)에서 질문과 관련된 정보를 검색합니다. 검색된 정보를 기반으로 LLM이 답변을 생성합니다. RAG는 다음과 같은 장점을 가지고 있습니다. Fine tuning에 비해 시간과 비용이 적게 소요됩니다. 외부 데이터베이스를 활용하기 때문에 별도의 학습 데이터를 준비할 필요가 없습니다. 모델의 일반성을 유지할 수 있습니다. 특정 도메인에 국한되지 않고 다양한 분야에 대한 질문에 답변할 수 있습니다. 답변의 근거를 제시할 수 있습니다. 답변과 함께 정보 출처를 제공하여 답변의 신뢰도를 높일 수 있습니다. 할루시네이션 가능성을 줄일 수 있습니다. 외부 데이터를 기반으로 답변을 생성하기 때문에 모델 자체의 편향이나 오류를 줄일 수 있습니다. 이를 비유하자면, Fine tuning은 언어 모델(A)이 사용자의 질문에 정확히 답하기 위해 특정 도메인 지식을 공부하고 학습하여 암기한 상태로 성장시키는 것이라면, RAG는 언어 모델(A)과 도서관 사서가 협업하는 것과 같습니다. 사용자가 질문을 하면, 사서가 도서관의 책 중에서 그 질문에 대한 정보를 담고 있는 책을 찾아낸 후, 언어 모델(A)이 그 책의 내용을 참고하여 질문에 답변하는 것이라고 볼 수 있습니다. Fine tuning과 RAG는 기술적 차이는 있지만, 모두 LLM의 한계를 극복하고 인공지능 기술의 발전을 이끄는 중요한 방법입니다. 상황에 따라 적합한 방법을 선택하고 활용한다면 LLM의 잠재력을 최대한 발휘할 수 있을 것입니다. RAG 자세히 알아보기 그렇다면 RAG에 대해서 조금 더 자세하게 알아볼까요? RAG의 작동 과정을 단계별로 더욱 자세히 살펴보면 다음과 같습니다. 데이터 임베딩 및 벡터 DB 구축 RAG의 첫 번째 단계는 자체 데이터를 임베딩 모델에 통합하는 것입니다. 텍스트 데이터를 벡터 형식으로 변환하여 벡터 DB를 구축합니다. 이렇게 벡터화된 정보가 풍부한 데이터베이스는 Retriever(문서 검색기) 부분에서 사용자의 쿼리와 관련된 정보를 찾는 데 활용됩니다. 쿼리 벡터화 및 관련 정보 추출 (증강 단계) 사용자의 질문(쿼리)을 벡터화합니다. 벡터 DB를 대상으로 다양한 검색 기법을 사용하여 소스 정보에서 가장 관련성이 높은 부분 또는 상위 K개의 항목을 추출합니다. 추출된 관련 정보는 쿼리 텍스트와 함께 LLM에 제공됩니다. LLM을 통한 답변 생성 LLM은 쿼리 텍스트와 추출된 관련 정보를 바탕으로 최종 답변을 생성합니다. 이 과정에서 정확한 출처에 기반한 답변이 가능해집니다. 아직 어려우신가요? 좀 더 쉬운 이해를 위해 앞선 도서관과 사서의 비유를 다시 가져와보겠습니다. 벡터 DB 구축: 수많은 책을 보관한 도서관 RAG의 첫 번째 단계는 자체 데이터를 임베딩 모델에 통합하여 벡터 DB를 구축하는 것으로, 이는 마치 사서가 방대한 양의 책을 정리하고 분류하여 도서관에 보관하는 것과 같습니다. 책은 텍스트 정보이며, 임베딩 모델은 책을 벡터라는 숫자 형식으로 변환하는 도구입니다. 벡터화된 정보는 책의 요약본과 같아서 사용자가 책의 내용을 쉽게 이해하고 찾을 수 있도록 도와줍니다. 정보 검색: 사용자에게 딱 맞는 책 추천 사용자가 도서관에 방문하여 질문을 하면, 사서는 사용자의 질문을 이해하고 관련된 책을 찾아주듯이, RAG의 두 번째 단계에서는 사용자의 질문(쿼리)을 벡터화하여 벡터 DB에서 가장 관련성이 높은 정보를 찾아냅니다. 이는 마치 사서가 책의 요약본을 바탕으로 사용자에게 딱 맞는 책을 추천하는 것과 유사합니다. 답변 생성: 사용자를 위한 지식 활용 사서가 추천한 책을 바탕으로 사용자는 새로운 지식을 얻듯이, RAG의 마지막 단계에서 LLM은 벡터 데이터베이스에서 추출된 정보와 사용자의 질문을 기반으로 새로운 답변을 생성합니다.이는 사용자가 책을 읽고 새로운 지식을 얻어 자신의 생각을 바탕으로 새로운 아이디어를 창조하는 것과 같습니다. RAG는 Retrieval(검색), Augmentation(증강), Generation(생성)의 세 단계로 이루어져 있으며, 각 단계가 협력하여 사용자의 질문에 빠르고 정확하게 답변할 수 있도록 돕습니다. 최신 정보 검색, 벡터화, 벡터 유사성 검색을 사용한 정보 증강, 그리고 생성형 AI를 결합함으로써 LLM은 더 최신이고 간결하며 근거에 기반한 결과를 얻을 수 있게 됩니다. RAG 기술은 인공지능 분야에서 새로운 가능성을 제시하는 기술로 평가받고 있습니다. LLM의 한계를 극복하고 더욱 정확하고 신뢰할 수 있는 답변을 생성할 수 있다는 점에서 그 잠재력이 매우 크다고 할 수 있습니다. 지금까지 RAG 기술의 등장 배경과 작동 원리에 대해 알아보았는데요. 다음 편에서는 CLOVA Studio를 통해 RAG 기술을 어떻게 구현할 수 있는지 좀 더 자세히 알아보겠습니다. RAG 3부작 시리즈 ✔︎ (1부) RAG란 무엇인가 ✔︎ (2부) RAG 구현 단계 알아보기 링크 ✔︎ (3부) CLOVA Studio를 이용해 RAG 구현하기 Cookbook 링크

- 3 replies
-
- 1
-
-
- rag
- clova studio 활용
- (and 1 more)
-
안녕하세요, @곳간로지스님, 답변이 늦어져 죄송합니다. 네 말씀대로, '50 MB 이하, API로 학습시 100MB 이하' 파일 용량 제한이 있습니다. https://guide.ncloud-docs.com/docs/clovastudio-dataset 해당 에러 코드와 가이드에 대해선 개선 방안을 내부적으로 논의하겠습니다. 감사합니다.
-
안녕하세요, @루까까님 혹시 응답 스트림 이용시 API URL을 https://clovastudio.stream.ntruss.com/ 으로 지정해서 요청해보셨을까요? (가이드) 또는 Maximum tokens의 값이 어느 정도로 설정되어 있는지 확인해보셔도 좋을 것 같습니다. 아래 링크를 통해 요청하신 정보에 대해서 자세히 안내주시면, 보다 자세히 살펴보도록 하겠습니다. https://www.ncloud.com/support/question/service 감사합니다.
-
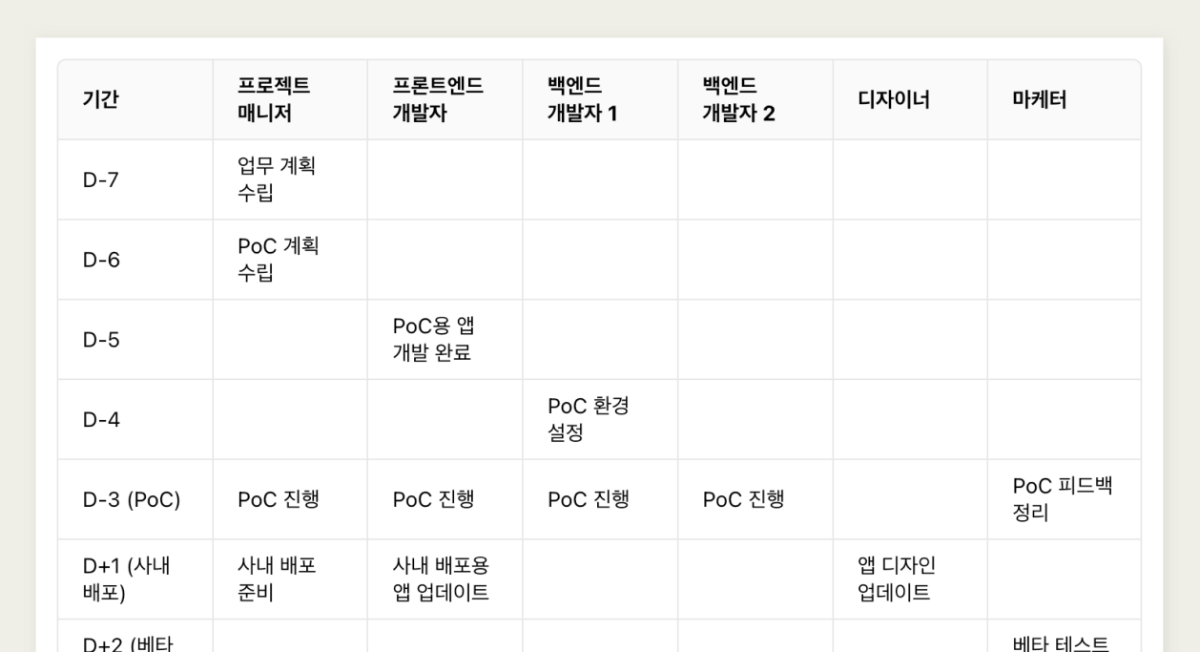
 안녕하세요, 클로바스튜디오 담당입니다! 3월 오픈 베타 전환 이후, 더 많은 사용자 여러분께서 클로바스튜디오를 경험하고 계십니다. 이에 발맞춰 오늘은 몇 가지 새로운 샘플을 선보일게요! 음악의 역사를 랩으로 설명하는 랩퍼 HyperCLOVA X 오늘의 기분에 맞는 칵테일을 추천해 주는 HyperCLOVA X 비슷한 세계관의 책을 추천해 주는 HyperCLOVA X 클릭 한 번으로 Json 양식으로 변환해 주는 HyperCLOVA X ... 상상력을 자극하는 7가지 신규 샘플을 소개합니다! 1. 랩으로 배우는 음악의 역사 플레이그라운드에서 열기 왜 그럴 때 있잖아요, 우리. 어렵고 지루한 내용을 좀 더 쉽고 재미있게 배울 방법은 없을까? 만약 래퍼가 이 따분한 내용을 리드미컬하고 흥미롭게 설명해 준다면 어떨까? (들썩들썩) 그런 상상 한 적 없나요? (...) 먼저 소개할 작업은 음악의 역사를 랩으로 소개하는 작업입니다. 지루할 수 있는 내용을 생동감 있고 리드미컬하게 익힐 수 있는 독창적인 방법이 될 것 같지 않나요? ▼ 특정 장르의 역사를 랩으로 설명해달라는 지시문과 함께, 랩 가사의 [Verse], [Hook]과 같은 구조를 미리 세팅해 두었습니다. ▲ 짜잔, "Jazz의 역사에 대해 설명해줘"라는 요청에 음악의 역사를 랩 가사로 설명해 주고 있습니다. 1절과 2절 그리고 후렴과 같은 곡의 구조를 잘 따르고 있네요. 비트에 맞춰 들리는 이야기, 재미와 흥미 가득한 랩으로, 재즈의 심장 박동을 느껴봐! 재즈의 역사를 느껴봐! 2. AI 바텐더 플레이그라운드에서 열기 오늘 저녁 술 한잔하고 싶은 분들, 이 작업 꼭 해보세요. 날씨와 기분에 어울리는 맞춤형 칵테일을 소개하는 AI 어때요? 오늘 마실만한 칵테일을 추천해줄 수 있는 HyperCLOVA X랍니다. ▼ "너는 숙련된 바텐더야."와 같은 페르소나와 어떤 내용을 담아서 추천해 줬으면 하는지 시스템 프롬프트에 입력했습니다. ▲ 우울한 기분엔 푸른 바다를 연상시키는 상큼한 과일 향의 '블루 하와이'를 추천해 주었네요! 오늘은 너로 정했다! 3. 클로바 도서관 플레이그라운드에서 열기 이 작업 좋아하실 분들 분명히 있을 거예요. 왜 때로는 어떤 책을 골라야 할지 고민이 될때가 있잖아요. 내가 읽은 책이 있는데, 그 느낌 그대로 이어갈 수 있는 비슷한 책들. ▼ 사용자가 인상깊게 읽은 책, 장르를 입력하면 HyperCLOVA X가 적절한 책을 추천해 줍니다. 단, LLM의 특성상 학습 이후의 데이터에 대한 접근이 어렵다는 한계는 존재합니다. 4. 프로젝트 운영 비서 플레이그라운드에서 열기 자, 이제 업무 생산성과 관련한 작업을 소개할게요. 프로젝트 일정을 계획하는 데 도움을 줄 수 있습니다. ▼ 필요한 개발 일정과, 계획 구성원에 대한 정보를 입력합니다. ▲ 이렇게 기간별 투입 인원과 역할을 마크다운 형식의 표로 만들 수 있습니다. 클로바 스튜디오는 개발 도구이기 때문에, 마크다운을 렌더링 하지 않고, 이런 식으로 모든 형식을 출력합니다. ▼ 마크다운 형식은 이렇게 변환해서 사용할 수 있겠죠. 5. Json 양식 변환기 플레이그라운드에서 열기 데이터 변환 작업은 생산성 향상에 큰 역할을 할 수 있을 것이에요. 예를 들어, 사용자가 입력한 데이터를 Json 형식으로 일괄 변환해 주는 AI 변환기를 만드는 것이죠. ▼ 사용자가 입력하는 데이터를 json 형식으로 일괄 변환해 주는 작업입니다. 시스템 프롬프트에 형식에 대한 설명과 스타일을 미리 정의해두었습니다. 이런 변환기는 향후 단순한 데이터 변환뿐만 아니라 복잡한 변환 작업에도 활용될 수 있을 것입니다. 6. 재밌는 경제 이론 선생님 플레이그라운드에서 열기 HyperCLOVA X는 복잡한 주제를 누구나 이해할 수 있도록 쉽게 설명하는 능력이 뛰어납니다. 예를 들어, 경제 이론과 같은 어려운 학문을 초등학생도 이해할 수 있게 직관적인 비유를 사용해 친근하게 설명해 줄 수 있어요. ▼ 단 몇 줄의 지시문만으로 경제 이론 선생님을 만들었습니다. 이해하기 쉽게 설명해 주는 페르소나를 만들기 위해, "안녕 반가워ᄒᄒ"와 같은 말투를 사용하도록 패턴을 설정했습니다. 그리고 답변 시에는 최소 1개 이상의 실제 사례를 함께 제시하도록 했습니다. 우리 함께 경알못 탈출하자구요! 7. 빈칸 학습지 제작 도우미 플레이그라운드에서 열기 HyperCLOVA X는 학습지 제작에도 도움을 줄 수 있을 것입니다. ▼ 지문에서 빈칸을 만들고, 지문에서 중요한 단어를 뽑아줄 수도 있죠. ▼ 모델의 출력 포맷을 위해 1-shot 형태의 예제를 입력해두었습니다. 이렇게 HyperCLOVA X는 다양한 분야에서 활용될 수 있는 무궁무진한 가능성을 가지고 있습니다. 여러분은 시스템 프롬프트를 어떻게 활용하고 계신가요? 다음에도 유용한 샘플을 소개하겠습니다!
안녕하세요, 클로바스튜디오 담당입니다! 3월 오픈 베타 전환 이후, 더 많은 사용자 여러분께서 클로바스튜디오를 경험하고 계십니다. 이에 발맞춰 오늘은 몇 가지 새로운 샘플을 선보일게요! 음악의 역사를 랩으로 설명하는 랩퍼 HyperCLOVA X 오늘의 기분에 맞는 칵테일을 추천해 주는 HyperCLOVA X 비슷한 세계관의 책을 추천해 주는 HyperCLOVA X 클릭 한 번으로 Json 양식으로 변환해 주는 HyperCLOVA X ... 상상력을 자극하는 7가지 신규 샘플을 소개합니다! 1. 랩으로 배우는 음악의 역사 플레이그라운드에서 열기 왜 그럴 때 있잖아요, 우리. 어렵고 지루한 내용을 좀 더 쉽고 재미있게 배울 방법은 없을까? 만약 래퍼가 이 따분한 내용을 리드미컬하고 흥미롭게 설명해 준다면 어떨까? (들썩들썩) 그런 상상 한 적 없나요? (...) 먼저 소개할 작업은 음악의 역사를 랩으로 소개하는 작업입니다. 지루할 수 있는 내용을 생동감 있고 리드미컬하게 익힐 수 있는 독창적인 방법이 될 것 같지 않나요? ▼ 특정 장르의 역사를 랩으로 설명해달라는 지시문과 함께, 랩 가사의 [Verse], [Hook]과 같은 구조를 미리 세팅해 두었습니다. ▲ 짜잔, "Jazz의 역사에 대해 설명해줘"라는 요청에 음악의 역사를 랩 가사로 설명해 주고 있습니다. 1절과 2절 그리고 후렴과 같은 곡의 구조를 잘 따르고 있네요. 비트에 맞춰 들리는 이야기, 재미와 흥미 가득한 랩으로, 재즈의 심장 박동을 느껴봐! 재즈의 역사를 느껴봐! 2. AI 바텐더 플레이그라운드에서 열기 오늘 저녁 술 한잔하고 싶은 분들, 이 작업 꼭 해보세요. 날씨와 기분에 어울리는 맞춤형 칵테일을 소개하는 AI 어때요? 오늘 마실만한 칵테일을 추천해줄 수 있는 HyperCLOVA X랍니다. ▼ "너는 숙련된 바텐더야."와 같은 페르소나와 어떤 내용을 담아서 추천해 줬으면 하는지 시스템 프롬프트에 입력했습니다. ▲ 우울한 기분엔 푸른 바다를 연상시키는 상큼한 과일 향의 '블루 하와이'를 추천해 주었네요! 오늘은 너로 정했다! 3. 클로바 도서관 플레이그라운드에서 열기 이 작업 좋아하실 분들 분명히 있을 거예요. 왜 때로는 어떤 책을 골라야 할지 고민이 될때가 있잖아요. 내가 읽은 책이 있는데, 그 느낌 그대로 이어갈 수 있는 비슷한 책들. ▼ 사용자가 인상깊게 읽은 책, 장르를 입력하면 HyperCLOVA X가 적절한 책을 추천해 줍니다. 단, LLM의 특성상 학습 이후의 데이터에 대한 접근이 어렵다는 한계는 존재합니다. 4. 프로젝트 운영 비서 플레이그라운드에서 열기 자, 이제 업무 생산성과 관련한 작업을 소개할게요. 프로젝트 일정을 계획하는 데 도움을 줄 수 있습니다. ▼ 필요한 개발 일정과, 계획 구성원에 대한 정보를 입력합니다. ▲ 이렇게 기간별 투입 인원과 역할을 마크다운 형식의 표로 만들 수 있습니다. 클로바 스튜디오는 개발 도구이기 때문에, 마크다운을 렌더링 하지 않고, 이런 식으로 모든 형식을 출력합니다. ▼ 마크다운 형식은 이렇게 변환해서 사용할 수 있겠죠. 5. Json 양식 변환기 플레이그라운드에서 열기 데이터 변환 작업은 생산성 향상에 큰 역할을 할 수 있을 것이에요. 예를 들어, 사용자가 입력한 데이터를 Json 형식으로 일괄 변환해 주는 AI 변환기를 만드는 것이죠. ▼ 사용자가 입력하는 데이터를 json 형식으로 일괄 변환해 주는 작업입니다. 시스템 프롬프트에 형식에 대한 설명과 스타일을 미리 정의해두었습니다. 이런 변환기는 향후 단순한 데이터 변환뿐만 아니라 복잡한 변환 작업에도 활용될 수 있을 것입니다. 6. 재밌는 경제 이론 선생님 플레이그라운드에서 열기 HyperCLOVA X는 복잡한 주제를 누구나 이해할 수 있도록 쉽게 설명하는 능력이 뛰어납니다. 예를 들어, 경제 이론과 같은 어려운 학문을 초등학생도 이해할 수 있게 직관적인 비유를 사용해 친근하게 설명해 줄 수 있어요. ▼ 단 몇 줄의 지시문만으로 경제 이론 선생님을 만들었습니다. 이해하기 쉽게 설명해 주는 페르소나를 만들기 위해, "안녕 반가워ᄒᄒ"와 같은 말투를 사용하도록 패턴을 설정했습니다. 그리고 답변 시에는 최소 1개 이상의 실제 사례를 함께 제시하도록 했습니다. 우리 함께 경알못 탈출하자구요! 7. 빈칸 학습지 제작 도우미 플레이그라운드에서 열기 HyperCLOVA X는 학습지 제작에도 도움을 줄 수 있을 것입니다. ▼ 지문에서 빈칸을 만들고, 지문에서 중요한 단어를 뽑아줄 수도 있죠. ▼ 모델의 출력 포맷을 위해 1-shot 형태의 예제를 입력해두었습니다. 이렇게 HyperCLOVA X는 다양한 분야에서 활용될 수 있는 무궁무진한 가능성을 가지고 있습니다. 여러분은 시스템 프롬프트를 어떻게 활용하고 계신가요? 다음에도 유용한 샘플을 소개하겠습니다!
-
안녕하세요. @crizin님, 클로바 스튜디오 담당입니다. 기본적으로 테스트 앱을 통해 클로바 스튜디오를 구현할 수 있지만, 이용량을 늘리기 위해서는 서비스 앱 신청이 필요합니다. 서비스 앱 신청 시에는 서비스 목적을 최대한 구체적으로 작성해 주셔야 하며, 내부 심사를 거쳐 승인 여부를 알려드립니다. 현재 클로바 스튜디오는 오픈 베타 서비스 중이기 때문에, 심사 과정이 있다는 점 참고 부탁드립니다. 더 궁금하신 점이나 도움이 필요한 사항이 있으시면 언제든지 말씀해 주세요. 감사합니다.
-
안녕하세요, @이종필님, 클로바 스튜디오 담당입니다. Chat Completions API로 각 content마다 전달받은 토큰수와 플레이그라운드 상의 토큰수는 동일합니다. 전달해주신 화면을 살펴보면 content 외의 텍스트가 전부 입력 되어있기 때문에, 동일한 값으로 보이지 않는 것인 점 참고 부탁드립니다. 감사합니다.
-
안녕하세요, @mmmm_ssss님, 클로바 스튜디오의 응답 포멧은 SSE (Server Sent Event) 양식을 따르고 있습니다. 이 양식에 따라서 처리를 하는 것을 추천 드립니다. 메시지를 파싱하는 방식은 다양한 방법들이 있는데요. event type 에 따라 다른 메시지 양식을 가질 수 있어 event type 역시 함께 확인하고 활용해 주시면 좋을 것 같습니다. data 처리 시에는 HTML Standard 스펙에 유의하시어 구현 부탁 드립니다. 감사합니다.
-
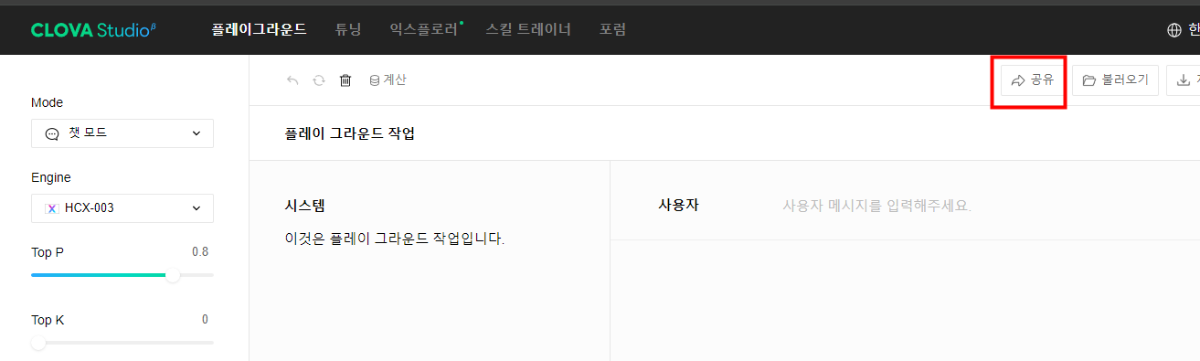
안녕하세요, @김종인님, 플레이그라운드에 우상단 있는 '공유' 버튼을 클릭 하신 후 진행을 부탁드립니다. 감사합니다.
-
안녕하세요, @dokdok.co님, 클로바 스튜디오 담당입니다. 40100 에러는 API Key나 Gateway key가 잘못 입력 되었을 때 발생합니다. 신청된 서비스 앱의 API Key로 입력 되었는지 재확인 부탁드립니다. 지속적으로 문제가 발생할 경우, 아래 링크를 통하여 계정 정보와 함께 접수해주시면 자세히 확인해보도록 하겠습니다. https://www.ncloud.com/support/question/service 감사합니다.
-
네이버 clova에 AI 학습용 데이터의 편향성을 위한 SQuARe, KoSBi 데이터셋에 대한 학습이 적용되어 있나요?
CLOVA Studio 운영자 replied to ultramarin's topic in 이용 문의
안녕하세요, @ultramarin님, 클로바 스튜디오 담당입니다. 서비스 정책상 학습 데이터에 대한 정보 공개가 어렵습니다. 많은 양해 부탁드립니다. 감사합니다. -
안녕하세요, @최창윤님, 클로바 스튜디오 담당입니다. 1. 플레이그라운드에서 작업을 저장하신 후 테스트 앱 발급을 통해 Chat Completions API 등을 이용하실 수 있습니다. API 가이드: https://api.ncloud-docs.com/docs/clovastudio-sendchatcompletionsbymodelname 사용 가이드: https://guide.ncloud-docs.com/docs/clovastudio-info#테스트앱 스킬 트레이너의 경우 HyperCLOVA X가 적절한 서비스 API를 호출할 수 있도록 학습시키는 기능입니다. 2. 스킬 내 모든 필드가 입력되고, API Spec 검증하기까지 완료되어야만 저장 버튼이 활성화됩니다. 이러한 조건이 모두 충족되었는지 한번 더 확인 부탁드립니다. 특히 Schema version 필드가 누락된 경우가 많아서, 해당 필드 입력(v1) 확인 부탁드립니다. 감사합니다.
-
안녕하세요, @CKD님,클로바 스튜디오 담당입니다. 40100 에러는 API Key나 Gateway key가 잘못 입력 되었을 때 발생합니다. 직접 생성된 테스트 앱의 API Key로 입력 되었는지 재확인 부탁드립니다. 지속적으로 문제가 발생할 경우, 아래 링크를 통하여 계정 정보와 함께 접수해주시면 자세히 확인해보도록 하겠습니다. https://www.ncloud.com/support/question/service
-
안녕하세요, @nexusai 님, 말씀주신 오류 발생 시간대 및 전후 시간대 응답을 확인하였으나, 모두 정상 응답으로 보이고 있어서, request ID나 오류가 발생했던 요청 예시를 공유해주실 수 있으실까요? 코멘트로 남기기 어렵다면, 아래 링크를 통해 문의 접수해주셔도 됩니다. https://www.ncloud.com/support/question/service 감사합니다.
-
안녕하세요, @ada.choi님, 클로바 스튜디오에서 제공하는 HyperCLOVA X 모델의 요금표는 아래 링크의 요금 탭에서 확인하실 수 있습니다. https://www.ncloud.com/product/aiService/clovaStudio CLOVA X의 서비스 응답을 웹으로 불러오거나 API 형태로 지원하고 있지 않으며, 클로바 스튜디오 플랫폼을 통해 이용 진행해주셔야 합니다. 감사합니다.
-
안녕하세요. @beans님, 1. 네, 맞습니다. Emb-dolphin 모델은 범용적으로 필요한 여러 분야의 도메인 지식을 처리 가능하도록 학습되었습니다. 2. sts는 Semantic Textual Similarity의 약자입니다. 문장간 유사도를 중점으로 진행하는 모델입니다.
- 1 reply
-
- 1
-
-
네, @hong 님, 현재 History를 관리하는 기능은 제공하지 않고 있습니다. 더 궁금하신 점이나 도움이 필요한 사항이 있으시면 언제든지 말씀해주세요. 감사합니다.
-
안녕하세요, @hong님, 40003 (Text too long) 에러가 발생한 것이 맞을까요? HCX 모델의 경우 인풋과 아웃풋을 포함해 4096 토큰을 넘길 수 없습니다. 플레이그라운드 상단의 '계산' 버튼을 누르면 입력된 텍스트의 토큰을 계산 할 수 있으며, 파라미터에서 Maximum tokens를 높게 설정하셨다면 낮추어 주세요. 그 밖에 다른 문의 사항이 있다면 알려주십시오. 감사합니다.
-
안녕하세요, @곳간로지스님, 답변이 늦어져 죄송합니다. System prompt 열을 활용하여 튜닝을 할 수 있도록, 관련 기능을 검토중에 있습니다. 추후 해당 기능을 이용해서 튜닝을 진행하면 의도하신대로 구현이 가능할 것 같습니다. 현재는 샘플 데이터셋을 제공하지 않는 점 참고 부탁드립니다. 감사합니다.