CLOVA Studio 운영자
-
게시글
304 -
첫 방문
-
최근 방문
-
Days Won
54
Content Type
Profiles
Forums
Articles
Everything posted by CLOVA Studio 운영자
-
AI를 비즈니스에 도입한 가상의 스타트업 사례를 통해, HyperCLOVA X가 어떻게 기업의 모습을 변화시킬 수 있는지 살펴보겠습니다. 비즈니스에 AI 도입을 고민 중이신가요? HyperCLOVA X로 지금 바로 시작해보세요!

-
- 1
-

-
- clova studio 활용
- 스킬트레이너
- (and 1 more)
-
@TABA777 님, 추가 코멘트 주신 것에 대하여 답변드립니다. 슬라이딩 윈도우나 요약을 활용한 대화의 경우, 모델의 토큰 한도에 의해 대화의 아주 초기의 맥락은 희석되는 문제가 생길 수 있기 때문에 말을 주고받는 단편적인 대화에 더 적절할 것 같고, 사실이나 정보를 기반으로 한 질의응답 구조의 작업에는 내용의 희석 없이 질문에 대응되는 내용을 전부 보존한채 답변을 할 수 있는 RAG가 더 적절한 방법론일 것입니다. 감사합니다.
-
@TABA777님, 앞서 문의주신 마스킹 관련하여 먼저 답변드립니다. 클로바 스튜디오 정책상 URL로 판단이 되는 경우, 마스킹 처리합니다. 상세 문의가 있으실 경우, 고객문의 창구를 통해 전달주시면 감사하겠습니다.
-
@데니정님, 안녕하세요. 고객 VPC 내에서 CLOVA Studio APIGW API를 호출하면 외부망(인터넷)으로 나가지 않고 NCP 내부 네트워크 내에서 라우팅됩니다. 온프레미스에서 프라이빗한 API 호출을 원하신다면 VPC 내에 프록시 서버를 구성하여 API 호출을 프록시 서버로 전달하고, 프록시에서 APIGW 의 API 를 호출하도록 설정하는 것을 권장드립니다. 추가 문의가 있으실 경우, 고객문의 창구를 통해 전달주시면 감사하겠습니다.
-
안녕하세요, @모바일님, 내 작업 > 튜닝 탭 > 튜닝 상세 페이지에서 공유 버튼을 누르시면, 서비스 앱 신청 화면에서 작업 선택이 가능합니다. 감사합니다.
-
안녕하세요, @TABA777님, 1. 현재 HyperCLOVA X 모델의 Context window는 4096토큰입니다. Input과 Output을 합쳐서 4096 토큰이기 때문에, 한번 호출할 때 체크하는 개념입니다. 4096 토큰이 넘어갈 경우 'Text too long'(40003) 형식의 응답을 내리게 됩니다. 1토큰은 평균적으로 1-2글자이며, 토큰을 초과하는 만큼의 입력을 하지 않는 작업이라면 크게 고려하실 필요는 없을 것입니다. 2. 네, 맞습니다. 4096 토큰을 넘어가면서 긴 대화를 끊김없이 진행할 수 있는 방법입니다. 감사합니다.
-
안녕하세요, @모바일님, Input과 Output을 포함하여 토큰이 계산됩니다. Input은 요청하는 System prompt, User/Assistant message를 말합니다. 1번과 2번의 입력 길이가 다르므로, 토큰 사용량에 차이가 발생할 것입니다. 감사합니다.
-
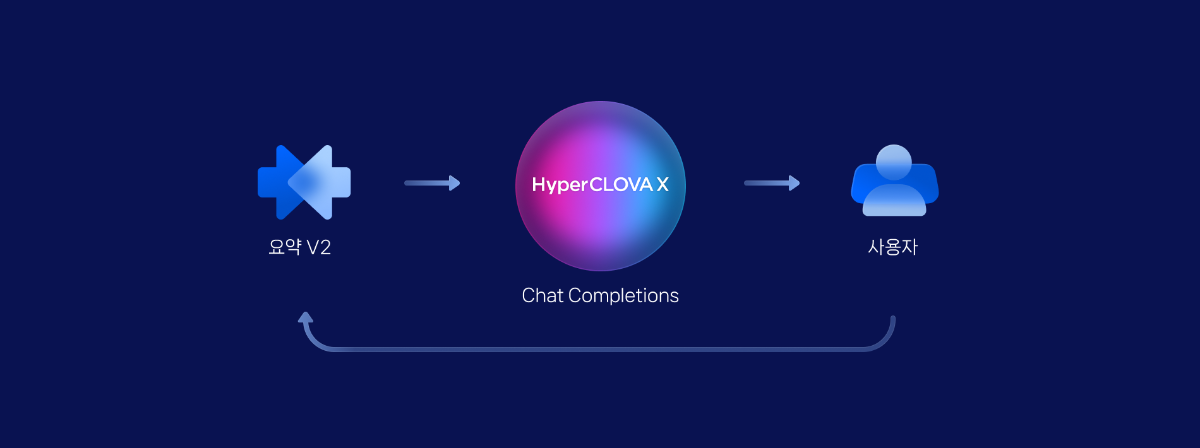
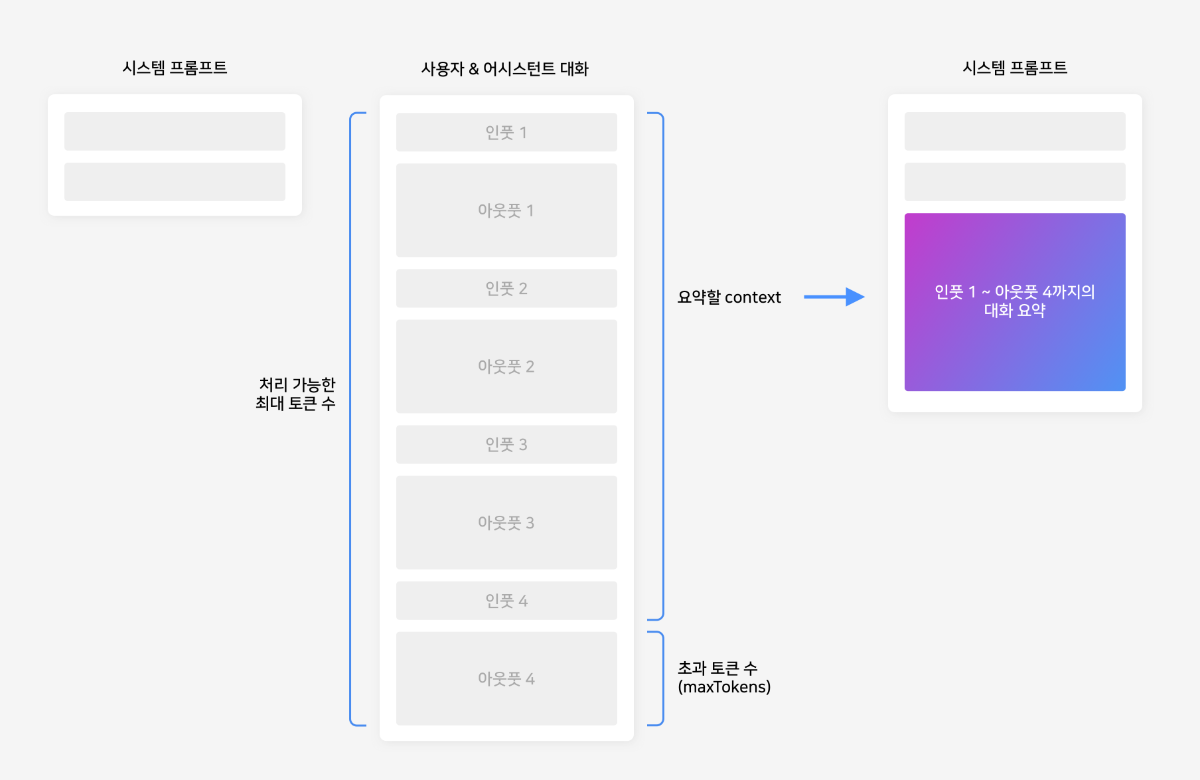
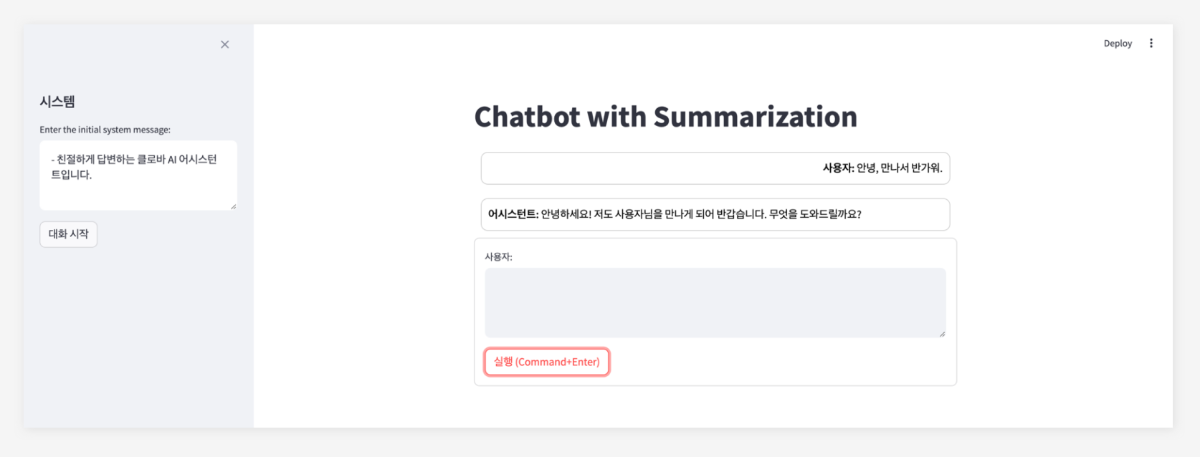
들어가며 CLOVA Studio에서 제공하는 Chat Completions API만을 단독으로 사용하면 최대 4096 토큰까지만 대화를 진행할 수 있어, 맥락 유지에 한계가 있습니다. 하지만 이번 cookbook에서 다룰 요약 API와 Chat Completions API를 함께 활용하면, 이전 대화 내용을 요약해가며 맥락을 보존하기 때문에 훨씬 더 길고 깊이 있는 대화가 가능합니다. 요약 API는 CLOVAStudio에서 제공하는 API로, 많은 양의 텍스트를 효과적으로 요약할 수 있습니다. 작동 원리 사용자와 어시스턴트의 대화는 일정량까지 누적되어 저장됩니다. 이 일정량은 모델이 한 번에 처리할 수 있는 토큰 수에서 Chat Completions의 'maxTokens'을 뺀 값을 기준으로 결정됩니다. 만약 사용자의 요청이 이 기준을 초과할 경우, 요약 API가 자동으로 작동하여 대화를 요약하고, 요약된 내용은 시스템 프롬프트에 포함됩니다. 이후 대화는 다시 기준까지 누적되며 진행되고, 기준을 초과한 사용자의 요청에 대한 어시스턴트의 답변은 요약 이후에 화면에 출력됩니다. 이를 통해 대화의 맥락을 유지하면서도 토큰 제한을 효율적으로 관리할 수 있습니다. 전체 구조 필요한 API들을 별도의 파일로 분리하여 모듈화하였고, 이를 필요에 따라 불러올 수 있도록 구성하였습니다. 관리의 편의성을 위해 요약 API와 Chat Completions API 기능을 각각 별도의 파일로 분리하고, main.py에서 필요한 모듈을 불러와 사용할 수 있도록 구성하였습니다. project-root/ │ ├── clovastudio_executor.py ├── completion_executor.py ├── summary_executor.py └── main.py 각 모듈 설명 1. 상위 클래스 정의 1부에서 정의한 CLOVAStudioExecutor입니다. 여러 API들의 호출에 필요한 공통 기능을 묶어 상위 클래스로 정의한 것으로, 1부에서 소개된 코드와 동일합니다. import json import http.client from http import HTTPStatus class CLOVAStudioExecutor: def __init__(self, host, api_key, api_key_primary_val, request_id): self._host = host self._api_key = api_key self._api_key_primary_val = api_key_primary_val self._request_id = request_id def _send_request(self, completion_request, endpoint): headers = { 'Content-Type': 'application/json; charset=utf-8', 'X-NCP-CLOVASTUDIO-API-KEY': self._api_key, 'X-NCP-APIGW-API-KEY': self._api_key_primary_val, 'X-NCP-CLOVASTUDIO-REQUEST-ID': self._request_id } conn = http.client.HTTPSConnection(self._host) conn.request('POST', endpoint, json.dumps(completion_request), headers) response = conn.getresponse() status = response.status result = json.loads(response.read().decode(encoding='utf-8')) conn.close() return result, status def execute(self, completion_request, endpoint): res, status = self._send_request(completion_request, endpoint) if status == HTTPStatus.OK: return res, status else: error_message = res.get("status", {}).get("message", "Unknown error") if isinstance(res, dict) else "Unknown error" raise ValueError(f"오류 발생: HTTP {status}, 메시지: {error_message}") 2. Chat Completions API Chat Completions API를 정의하는 클래스입니다. 1부와 역시 동일합니다. 전체 프로젝트 폴더 내에 completion_executor.py로 저장합니다. from clovastudio_executor import CLOVAStudioExecutor from http import HTTPStatus import requests class ChatCompletionExecutor(CLOVAStudioExecutor): def __init__(self, host, api_key, api_key_primary_val, request_id): super().__init__(host, api_key, api_key_primary_val, request_id) def execute(self, completion_request, stream=True): headers = { 'X-NCP-CLOVASTUDIO-API-KEY': self._api_key, 'X-NCP-APIGW-API-KEY': self._api_key_primary_val, 'X-NCP-CLOVASTUDIO-REQUEST-ID': self._request_id, 'Content-Type': 'application/json; charset=utf-8', 'Accept': 'text/event-stream' if stream else 'application/json' } with requests.post(self._host + '/testapp/v1/chat-completions/HCX-003', headers=headers, json=completion_request, stream=stream) as r: if stream: if r.status_code == HTTPStatus.OK: response_data = "" for line in r.iter_lines(): if line: decoded_line = line.decode("utf-8") print(decoded_line) response_data += decoded_line + "\n" return response_data else: raise ValueError(f"오류 발생: HTTP {r.status_code}, 메시지: {r.text}") else: if r.status_code == HTTPStatus.OK: return r.json() else: raise ValueError(f"오류 발생: HTTP {r.status_code}, 메시지: {r.text}") 3. 요약 API 요약 API를 정의하는 클래스입니다. 전체 프로젝트 폴더 내에 summary_executor.py로 저장합니다. from clovastudio_executor import CLOVAStudioExecutor from http import HTTPStatus class SummarizationExecutor(CLOVAStudioExecutor): def execute(self, completion_request): endpoint = '/testapp/v1/api-tools/summarization/v2/{테스트앱 식별자}' res, status = super().execute(completion_request, endpoint) if status == HTTPStatus.OK and "result" in res: return res["result"]["text"] else: error_message = res.get("status", {}).get("message", "Unknown error") if isinstance(res, dict) else "Unknown error" raise ValueError(f"오류 발생: HTTP {status}, 메시지: {error_message}") 4. main.py 앞서 정의한 3개의 모듈을 활용하여 토큰 한도를 초과하는 대화를 가능하게 하는 로직이 담긴 main 파일입니다. 아래는 main.py의 전체 코드이며, 각 부분에 대한 자세한 설명을 이어서 하겠습니다. import json from completion_executor import ChatCompletionExecutor from summary_executor import SummarizationExecutor # 세션 state 정의 session_state = { "preset_messages": [], "total_tokens": 0, "chat_log": [], "started": False, "summary_messages": [], "last_user_input": "", "last_response": "", "last_user_message": {}, "last_assistant_message": {}, "previous_messages": [], "system_message_changed": False, "system_message": "" } def log_preset_messages(): print("preset_messages:", json.dumps(session_state['preset_messages'], ensure_ascii=False, indent=2)) print("system_message:", session_state['system_message']) print("total_tokens:", session_state['total_tokens']) def summarize_and_reset(summarization_executor): text_to_summarize = " ".join([msg.get('content', '') for msg in session_state['preset_messages'][1:] if msg['role'] != 'system']) # 첫 system 메시지 제외 print(f"Text to summarize: {text_to_summarize}") summary_request_data = { "texts": [text_to_summarize], "autoSentenceSplitter": True, "segCount": -1, "segMaxSize": 1000, "segMinSize": 300, "includeAiFilters": False } summary_response = summarization_executor.execute(summary_request_data) print(f"Summary response: {summary_response}") if summary_response and isinstance(summary_response, str): summary_text = summary_response session_state['summary_messages'].append({"role": "system", "content": summary_text}) session_state['preset_messages'] = [{"role": "system", "content": session_state['system_message']}, {"role": "system", "content": summary_text}] session_state['preset_messages'].append(session_state.get('last_user_message', {})) session_state['preset_messages'].append(session_state.get('last_assistant_message', {})) session_state['total_tokens'] = len(summary_text.split()) + \ len(session_state.get('last_user_message', {}).get('content', '').split()) + \ len(session_state.get('last_assistant_message', {}).get('content', '').split()) log_preset_messages() def parse_stream_response(response): input_length = 0 output_length = 0 content_parts = [] for line in response.splitlines(): if line.startswith('data:'): data = json.loads(line[5:]) if 'message' in data and 'content' in data['message']: content_parts.append(data['message']['content']) if 'inputLength' in data: input_length = data['inputLength'] if 'outputLength' in data: output_length = data['outputLength'] content = content_parts[-1] return { 'inputLength': input_length, 'outputLength': output_length, 'content': content } def parse_non_stream_response(response): result = response.get('result', {}) message = result.get('message', {}) content = message.get('content', '') input_length = result.get('inputLength', 0) output_length = result.get('outputLength', 0) return { 'inputLength': input_length, 'outputLength': output_length, 'content': content } def main(): system_message = input("Enter the initial system message (예시: 친절하게 답변하는 클로바 AI 어시스턴트입니다.): ") session_state['system_message'] = system_message session_state['system_message_changed'] = True session_state['started'] = True if session_state['system_message_changed']: session_state['preset_messages'] = [msg for msg in session_state['preset_messages'] if msg['role'] != 'system'] session_state['preset_messages'].insert(0, {"role": "system", "content": session_state['system_message']}) session_state['system_message_changed'] = False if session_state['started']: completion_executor = ChatCompletionExecutor( host='https://clovastudio.stream.ntruss.com', api_key='<api_key>', api_key_primary_val='<api_key_primary_val>', request_id='<request_id>' ) summarization_executor = SummarizationExecutor( host='clovastudio.apigw.ntruss.com', api_key='<api_key>', api_key_primary_val='<api_key_primary_val>', request_id='<request_id>' ) while True: user_input = input("사용자: ") if user_input.lower() in ['exit', 'quit']: break session_state['last_user_input'] = user_input session_state['last_user_message'] = {"role": "user", "content": user_input} session_state['preset_messages'].append(session_state['last_user_message']) session_state['chat_log'].append(session_state['last_user_message']) request_data = { "messages": session_state['preset_messages'], "maxTokens": 256, "temperature": 0.5, "topK": 0, "topP": 0.6, "repeatPenalty": 1.2, "stopBefore": [], "includeAiFilters": True, "seed": 0, } def execute_request(stream): try: response = completion_executor.execute(request_data, stream=stream) if stream: parsed_response = parse_stream_response(response) else: parsed_response = parse_non_stream_response(response) return parsed_response except Exception as e: print(f"Error occurred: {e}") return None # 여기서 stream 옵션을 True나 False로 설정 response = execute_request(stream=True) if response: response_text = response['content'] input_length = response.get('inputLength', 0) output_length = response.get('outputLength', 0) session_state['last_response'] = response_text session_state['last_assistant_message'] = {"role": "assistant", "content": response_text} session_state['preset_messages'].append(session_state['last_assistant_message']) session_state['chat_log'].append(session_state['last_assistant_message']) session_state['total_tokens'] = input_length + output_length log_preset_messages() token_limit = 4096 - request_data["maxTokens"] # 토큰 한도를 고려하여 설정 if session_state['total_tokens'] > token_limit: print("Token limit exceeded. Starting summarization.") summarize_and_reset(summarization_executor) else: print("Error occurred. Starting summarization.") summarize_and_reset(summarization_executor) session_state['preset_messages'].append(session_state['last_user_message']) if __name__ == "__main__": main() main.py 호출 구조 이제 main.py의 자세한 호출 구조를 설명하겠습니다. ▼ 이 단계에서는 앞서 별도의 Python 파일로 저장한 모듈들을 불러옵니다. 또한, 대화 로그를 관리하고 토큰 수를 계산하기 위한 세션을 정의합니다. 이렇게 필요한 모듈과 세션을 준비함으로써, 원활한 대화 진행과 요약 기능 활용을 위한 기반을 마련하게 됩니다. import json from completion_executor import ChatCompletionExecutor from summary_executor import SummarizationExecutor # 세션 state 정의 session_state = { "preset_messages": [], "total_tokens": 0, "chat_log": [], "started": False, "summary_messages": [], "last_user_input": "", "last_response": "", "last_user_message": {}, "last_assistant_message": {}, "previous_messages": [], "system_message_changed": False, "system_message": "" } ▼ 이 함수는 대화가 진행되는 동안 터미널 상에서 대화 로그가 정상적으로 기록되고, 토큰 수가 올바르게 계산되고 있는지 확인하기 위해 사용됩니다. 이 정보는 사용자의 대화 화면에는 표시되지 않습니다. def log_preset_messages(): print("preset_messages:", json.dumps(session_state['preset_messages'], ensure_ascii=False, indent=2)) print("system_message:", session_state['system_message']) print("total_tokens:", session_state['total_tokens']) ▼ 진행된 대화 내용은 preset_messages 변수에 저장됩니다. 대화 내역이 최대 토큰 수에 도달하면, 이 함수를 통해 preset_message에 저장된 모든 대화 내역을 요약된 내용으로 대체합니다. 요약된 내용은 시스템 프롬프트("role": "system")에 입력되어, 어시스턴트가 이전 대화 맥락을 기억한 채로 사용자와 계속해서 대화를 이어갈 수 있도록 합니다. 이를 통해 대화의 연속성과 일관성을 유지하면서도 토큰 제한을 효과적으로 관리할 수 있습니다. def summarize_and_reset(summarization_executor): text_to_summarize = " ".join([msg.get('content', '') for msg in session_state['preset_messages'][1:] if msg['role'] != 'system']) # 첫 system 메시지 제외 print(f"Text to summarize: {text_to_summarize}") summary_request_data = { "texts": [text_to_summarize], "autoSentenceSplitter": True, "segCount": -1, "segMaxSize": 1000, "segMinSize": 300, "includeAiFilters": False } summary_response = summarization_executor.execute(summary_request_data) print(f"Summary response: {summary_response}") if summary_response and isinstance(summary_response, str): summary_text = summary_response session_state['summary_messages'].append({"role": "system", "content": summary_text}) session_state['preset_messages'] = [{"role": "system", "content": session_state['system_message']}, {"role": "system", "content": summary_text}] session_state['preset_messages'].append(session_state.get('last_user_message', {})) session_state['preset_messages'].append(session_state.get('last_assistant_message', {})) session_state['total_tokens'] = len(summary_text.split()) + \ len(session_state.get('last_user_message', {}).get('content', '').split()) + \ len(session_state.get('last_assistant_message', {}).get('content', '').split()) ▼ 다음은 stream 옵션을 실행했을 때와 실행하지 않았을 때 각각의 요청을 처리하기 위한 함수입니다. 토큰 계산 확인을 위해 Chat Completions API의 응답 바디중 inputLength와 outputLength를 추가적으로 가져옵니다. def parse_stream_response(response): input_length = 0 output_length = 0 content_parts = [] for line in response.splitlines(): if line.startswith('data:'): data = json.loads(line[5:]) if 'message' in data and 'content' in data['message']: content_parts.append(data['message']['content']) if 'inputLength' in data: input_length = data['inputLength'] if 'outputLength' in data: output_length = data['outputLength'] content = content_parts[-1] return { 'inputLength': input_length, 'outputLength': output_length, 'content': content } def parse_non_stream_response(response): result = response.get('result', {}) message = result.get('message', {}) content = message.get('content', '') input_length = result.get('inputLength', 0) output_length = result.get('outputLength', 0) return { 'inputLength': input_length, 'outputLength': output_length, 'content': content } ▼ 이 부분은 대화형 애플리케이션의 핵심 로직을 담고 있는 중요한 코드 블록으로, 앞서 소개한 함수들을 포함하여 토큰 수를 계산하고 답변을 출력하며, 최대 토큰 수에 도달했을 때 요약을 수행하는 등의 기능을 수행합니다. def main(): system_message = input("Enter the initial system message (예시: 친절하게 답변하는 클로바 AI 어시스턴트입니다.): ") session_state['system_message'] = system_message session_state['system_message_changed'] = True session_state['started'] = True if session_state['system_message_changed']: session_state['preset_messages'] = [msg for msg in session_state['preset_messages'] if msg['role'] != 'system'] session_state['preset_messages'].insert(0, {"role": "system", "content": session_state['system_message']}) session_state['system_message_changed'] = False if session_state['started']: completion_executor = ChatCompletionExecutor( host='https://clovastudio.stream.ntruss.com', api_key='<api_key>', api_key_primary_val='<api_key_primary_val>', request_id='<request_id>' ) summarization_executor = SummarizationExecutor( host='clovastudio.apigw.ntruss.com', api_key='<api_key>', api_key_primary_val='<api_key_primary_val>', request_id='<request_id>' ) while True: user_input = input("사용자: ") if user_input.lower() in ['exit', 'quit']: break session_state['last_user_input'] = user_input session_state['last_user_message'] = {"role": "user", "content": user_input} session_state['preset_messages'].append(session_state['last_user_message']) session_state['chat_log'].append(session_state['last_user_message']) request_data = { "messages": session_state['preset_messages'], "maxTokens": 256, "temperature": 0.5, "topK": 0, "topP": 0.6, "repeatPenalty": 1.2, "stopBefore": [], "includeAiFilters": True, "seed": 0, } def execute_request(stream): try: response = completion_executor.execute(request_data, stream=stream) if stream: parsed_response = parse_stream_response(response) else: parsed_response = parse_non_stream_response(response) return parsed_response except Exception as e: print(f"Error occurred: {e}") return None # 여기서 stream 옵션을 True나 False로 설정 response = execute_request(stream=True) if response: response_text = response['content'] input_length = response.get('inputLength', 0) output_length = response.get('outputLength', 0) session_state['last_response'] = response_text session_state['last_assistant_message'] = {"role": "assistant", "content": response_text} session_state['preset_messages'].append(session_state['last_assistant_message']) session_state['chat_log'].append(session_state['last_assistant_message']) session_state['total_tokens'] = input_length + output_length log_preset_messages() token_limit = 4096 - request_data["maxTokens"] # 토큰 한도를 고려하여 설정 if session_state['total_tokens'] > token_limit: print("Token limit exceeded. Starting summarization.") summarize_and_reset(summarization_executor) else: print("Error occurred. Starting summarization.") summarize_and_reset(summarization_executor) session_state['preset_messages'].append(session_state['last_user_message']) main 함수를 실행하는 것까지 main.py에 포함됩니다. if __name__ == "__main__": main() 요약 활용 대화 실행 결과 이제 요약 기능을 활용하여 대화 맥락을 유지하는 방법에 대한 실행 결과를 보여드리겠습니다. 대화의 진행 과정을 보다 명확하게 확인할 수 있도록 Streamlit을 사용하여 채팅 화면을 구현했습니다. 앞서 정의한 executor들은 그대로 유지하며, main.py 파일에 아래 제시된 코드를 그대로 저장하면 Streamlit으로 포장된 대화를 실행할 수 있습니다. cd 프로젝트/폴더/경로로/이동 streamlit run main.py Streamlit Code 열어보기 ▼ 대화가 진행되는 동안, 터미널에는 모델이 이후 대화에 참고할 수 있는 정보들이 출력됩니다. 여기에는 이전 대화 내용을 담고 있는 대화 로그(preset_messages), 현재 설정된 시스템 프롬프트(system_message), 그리고 누적된 총 토큰 수(total_tokens)가 포함됩니다. ▼ 대화 내역이 한도를 초과하기 전까지는 'Text to summarize'에 저장되며, 이를 요약한 내용은 'Summary response'로 출력됩니다. 이 요약된 내용은 시스템 프롬프트("role: system")로 사용되어 대화의 맥락을 유지하는 데 활용됩니다. 터미널에서의 가독성을 높이기 위해, 요약이 실행되는 시점(한도 초과 시)에만 누적된 대화 로그를 'Text to summarize'로 표시하고, 요약된 내용이 시스템 프롬프트로 사용된 것은 'preset_messages'를 통해 확인할 수 있도록 구성하였습니다. ▼ 요약이 실행되면 토큰 수도 초기화되어 다시 누적 계산됩니다. 맺음말 본 cookbook에서는 CLOVAStudio의 요약 API를 활용하여 토큰 한도를 넘어서는 대화를 가능하게 하는 방법에 대해 알아보았습니다. 요약 API의 파라미터와 Chat Completions API의 파라미터 설정에 따라 대화 맥락의 보존 정도와 연속 대화 가능 길이가 달라질 수 있습니다. 따라서 대화 서비스의 목적과 특성에 맞게 이러한 파라미터들을 적절히 조정하는 것이 중요합니다. 앞으로도 CLOVA Studio는 다양한 API와 도구를 제공하여, 사용자들이 더욱 풍부하고 인상적인 대화형 AI 서비스를 구현할 수 있도록 지원하겠습니다.
-
- 1
-
-
- clova studio 활용
- cookbook
- (and 1 more)
-
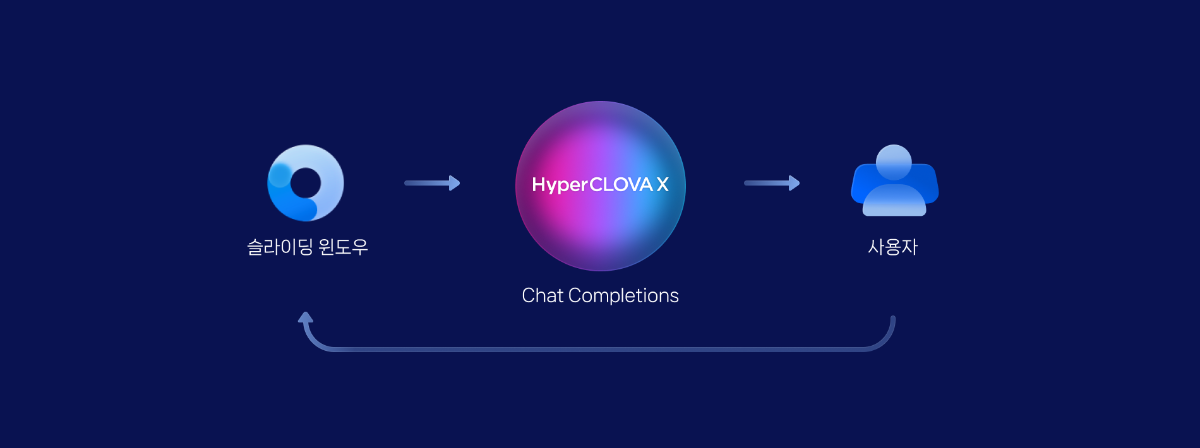
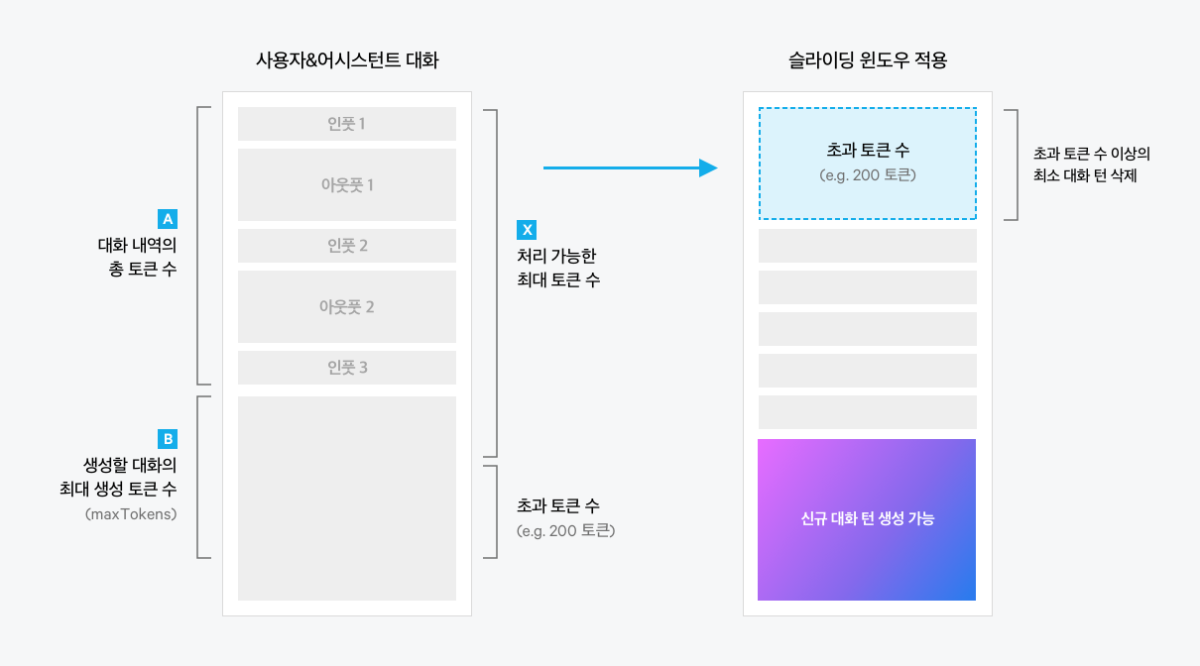
들어가며 CLOVA Studio에서 제공하는 Chat Completions API는 HyperCLOVA X 모델을 기반으로 하며, 사용자의 입력에 따라 자연스러운 대화를 생성할 수 있습니다. 하지만 대화가 길어질수록 모델이 처리할 수 있는 토큰 수(4096) 제한에 부딪혀 대화를 이어갈 수 없는 한계가 있습니다. 이러한 문제를 해결하기 위해 슬라이딩 윈도우 API와 Chat Completion API를 연결하는 방법을 소개하고자 합니다. 이를 통해 대화의 길이에 상관없이 지속적으로 자연스러운 대화를 생성할 수 있게 됩니다. 두 API의 연계를 통해 Context window의 한계를 극복하고, 보다 원활하고 확장성 있는 대화 시스템을 구현할 수 있을 것입니다. 슬라이딩 윈도우 작동 원리 대화 턴에서 입력된 대화 내역의 총 토큰 수Ⓐ와 새롭게 생성할 대화의 최대 토큰 수Ⓑ의 합이 모델이 처리할 수 있는 최대 토큰 수Ⓧ를 초과하면(Ⓐ+Ⓑ > Ⓧ), Chat Completions API는 대화 생성을 중단합니다. 이를 해결하기 위해 슬라이딩 윈도우 API는 초과된 토큰 수(Ⓐ+Ⓑ-Ⓧ)만큼 기존 대화 중 오래된 대화 턴부터 삭제합니다. 대화 턴의 일부만 삭제되지 않도록 대화 턴 단위로 묶어서 삭제합니다. 전체 구조 필요한 API들을 별도의 파일로 분리하여 모듈화하였고, 이를 필요에 따라 불러올 수 있도록 구성하였습니다. 관리의 편의성을 위해 슬라이딩 윈도우 API와 Chat Completions API 기능을 각각 별도의 파일로 분리하고, main.py에서 필요한 모듈을 불러와 사용할 수 있도록 구성하였습니다. 프로젝트 구조 project-root/ │ ├── clovastudio_executor.py ├── sliding_window_executor.py ├── completion_executor.py └── main.py 각 모듈 설명 1. 상위 클래스 정의 CLOVAStudioExecutor는 API 호출에 필요한 공통 기능을 묶어놓은 상위 클래스입니다. 이 클래스는 인증 토큰을 관리하고 API 요청을 처리하는 역할을 합니다. 전체 프로젝트 폴더 내에 clovastudio_executor.py로 저장합니다. clovastudio_executor.py import json import http.client from http import HTTPStatus class CLOVAStudioExecutor: def __init__(self, host, api_key, api_key_primary_val, request_id): self._host = host self._api_key = api_key self._api_key_primary_val = api_key_primary_val self._request_id = request_id def _send_request(self, completion_request, endpoint): headers = { 'Content-Type': 'application/json; charset=utf-8', 'X-NCP-CLOVASTUDIO-API-KEY': self._api_key, 'X-NCP-APIGW-API-KEY': self._api_key_primary_val, 'X-NCP-CLOVASTUDIO-REQUEST-ID': self._request_id } conn = http.client.HTTPSConnection(self._host) conn.request('POST', endpoint, json.dumps(completion_request), headers) response = conn.getresponse() status = response.status result = json.loads(response.read().decode(encoding='utf-8')) conn.close() return result, status def execute(self, completion_request, endpoint): res, status = self._send_request(completion_request, endpoint) if status == HTTPStatus.OK: return res, status else: error_message = res.get("status", {}).get("message", "Unknown error") if isinstance(res, dict) else "Unknown error" raise ValueError(f"오류 발생: HTTP {status}, 메시지: {error_message}") 2. Chat Completions API Chat Completions API를 정의하는 클래스입니다. 전체 프로젝트 폴더 내에 completion_executor.py로 저장합니다. completion_executor.py from clovastudio_executor import CLOVAStudioExecutor from http import HTTPStatus import requests class ChatCompletionExecutor(CLOVAStudioExecutor): def __init__(self, host, api_key, api_key_primary_val, request_id): super().__init__(host, api_key, api_key_primary_val, request_id) def execute(self, completion_request, stream=True): headers = { 'X-NCP-CLOVASTUDIO-API-KEY': self._api_key, 'X-NCP-APIGW-API-KEY': self._api_key_primary_val, 'X-NCP-CLOVASTUDIO-REQUEST-ID': self._request_id, 'Content-Type': 'application/json; charset=utf-8', 'Accept': 'text/event-stream' if stream else 'application/json' } with requests.post(self._host + '/testapp/v1/chat-completions/HCX-003', headers=headers, json=completion_request, stream=stream) as r: if stream: if r.status_code == HTTPStatus.OK: response_data = "" for line in r.iter_lines(): if line: decoded_line = line.decode("utf-8") print(decoded_line) response_data += decoded_line + "\n" return response_data else: raise ValueError(f"오류 발생: HTTP {r.status_code}, 메시지: {r.text}") else: if r.status_code == HTTPStatus.OK: return r.json() else: raise ValueError(f"오류 발생: HTTP {r.status_code}, 메시지: {r.text}") 3. 슬라이딩 윈도우 API 슬라이딩 윈도우 API를 정의하는 클래스입니다. 전체 프로젝트 폴더 내에 sliding_window_executor.py로 저장합니다. sliding_window_executor.py from clovastudio_executor import CLOVAStudioExecutor import json class SlidingWindowExecutor(CLOVAStudioExecutor): def execute(self, completion_request): endpoint = '/v1/api-tools/sliding/chat-messages/HCX-003' try: result, status = super().execute(completion_request, endpoint) if status == 200: # 슬라이딩 윈도우 적용 후 메시지를 반환 return result['result']['messages'] else: error_message = result.get('status', {}).get('message', 'Unknown error') raise ValueError(f"오류 발생: HTTP {status}, 메시지: {error_message}") except Exception as e: print(f"Error in SlidingWindowExecutor: {e}") return 'Error' 4. main.py main.py 파일은 사용자 입력을 받아 슬라이딩 윈도우 API와 Chat Completions API를 순서대로 호출합니다. 이를 통해 최대 토큰 수를 초과하지 않도록 오래된 대화를 삭제하여 대화를 지속할 수 있도록 합니다. from completion_executor import ChatCompletionExecutor from sliding_window_executor import SlidingWindowExecutor import json # 스트리밍 응답에서 content 부분만 추출 def parse_stream_response(response): content_parts = [] for line in response.splitlines(): if line.startswith('data:'): data = json.loads(line[5:]) if 'message' in data and 'content' in data['message']: content_parts.append(data['message']['content']) content = content_parts[-1] if content_parts else "" return content.strip() # 논스트리밍 응답에서 content 부분만 추출 def parse_non_stream_response(response): result = response.get('result', {}) message = result.get('message', {}) content = message.get('content', '') return content.strip() def main(): # 초기 시스템 프롬프트 설정 system_prompt = "- HyperCLOVA X는 네이버 클라우드의 하이퍼스케일 AI입니다." messages = [] sliding_window_executor = SlidingWindowExecutor( host='clovastudio.apigw.ntruss.com', api_key = '<api_key>', api_key_primary_val = '<api_key_primary_val>', request_id = '<request_id>' ) completion_executor = ChatCompletionExecutor( host='https://clovastudio.stream.ntruss.com', api_key = '<api_key>', api_key_primary_val = '<api_key_primary_val>', request_id = '<request_id>' ) # stream 옵션에 따라 응답을 토큰 단위(stream=True), 전체(stream=False)로 받을 수 있습니다. stream = True while True: user_input = input("USER: ('exit'으로 종료): ") if user_input.lower() in ['exit', 'quit']: break messages.append({"role": "user", "content": user_input}) request_data = { "messages": [{"role": "system", "content": system_prompt}] + messages, "maxTokens": 100 # 슬라이딩 윈도우에서 사용할 토큰 수 } # SlidingWindowExecutor를 사용하여 조정된 메시지 가져오기 try: adjusted_messages = sliding_window_executor.execute(request_data) if adjusted_messages == 'Error': print("Error adjusting messages with SlidingWindowExecutor") continue except Exception as e: print(f"Error adjusting messages: {e}") continue # Chat Completion 요청 데이터 생성 completion_request_data = { "messages": adjusted_messages, "maxTokens": 100, # Chat Completion에서 사용할 토큰 수 "temperature": 0.5, "topK": 0, "topP": 0.8, "repeatPenalty": 1.2, "stopBefore": [], "includeAiFilters": True, "seed": 0 } try: response = completion_executor.execute(completion_request_data, stream=stream) if stream: response_text = parse_stream_response(response) else: response_text = parse_non_stream_response(response) messages.append({"role": "assistant", "content": response_text}) # 대화 내역 표시 print("\nAdjusted Messages:", adjusted_messages, "\n") print("System Prompt:", system_prompt) print("USER Input:", user_input) print("CLOVA Response:", response_text, "\n") except Exception as e: print(f"Error: {e}") if __name__ == "__main__": main() main.py 호출 구조 이제 main.py의 자세한 호출 구조를 설명하겠습니다. ▼ 다음은 stream 옵션을 실행했을 때와 실행하지 않았을 때 각각의 요청을 처리하기 위한 함수입니다. 모듈 불러오기 from completion_executor import ChatCompletionExecutor from sliding_window_executor import SlidingWindowExecutor import json ▼ 먼저 필요한 모듈을 임포트하는 부분입니다. 'SlidingWindowExecutor'와 'CompletionExecutor' 클래스를 각각의 모듈에서 가져옵니다. 불러온 모듈과 클래스는 이후 코드에서 사용될 것입니다. 작동을 위한 중심 코드 # 스트리밍 응답에서 content 부분만 추출 def parse_stream_response(response): content_parts = [] for line in response.splitlines(): if line.startswith('data:'): data = json.loads(line[5:]) if 'message' in data and 'content' in data['message']: content_parts.append(data['message']['content']) content = content_parts[-1] if content_parts else "" return content.strip() # 논스트리밍 응답에서 content 부분만 추출 def parse_non_stream_response(response): result = response.get('result', {}) message = result.get('message', {}) content = message.get('content', '') return content.strip() ▼ 사용자 입력을 처리하는 과정을 설명해 드리겠습니다. 먼저 시스템 프롬프트를 설정한 후, 사용자로부터 입력을 받습니다. 받은 입력은 messages라는 리스트에 차례로 추가됩니다. 초기 설정 및 사용자 입력 처리 def main(): # 시스템 프롬프트 설정 system_prompt = "- HyperCLOVA X는 네이버 클라우드의 하이퍼스케일 AI입니다." messages = [] sliding_window_executor = SlidingWindowExecutor( host='clovastudio.apigw.ntruss.com', api_key = '<api_key>', api_key_primary_val = '<api_key_primary_val>', request_id = '<request_id>' ) completion_executor = ChatCompletionExecutor( host='https://clovastudio.stream.ntruss.com', api_key = '<api_key>', api_key_primary_val = '<api_key_primary_val>', request_id = '<request_id>' ) # stream 옵션에 따라 응답을 토큰 단위(stream=True), 전체(stream=False)로 받을 수 있습니다. stream = True while True: user_input = input("USER: ('exit'으로 종료): ") if user_input.lower() in ['exit', 'quit']: break messages.append({"role": "user", "content": user_input}) ▼ 사용자의 새로운 입력과 기존 대화 내역을 슬라이딩 윈도우 API에 전달합니다. 이 API는 입력된 데이터의 토큰 수가 최대 허용 개수를 초과하지 않도록 대화 내역을 조정하는 역할을 합니다. 조정된 대화 내역은 'adjusted_messages'라는 변수에 저장되어 이후 처리 과정에서 활용됩니다. 슬라이딩 윈도우 API 호출 # 슬라이딩 윈도우 요청 데이터 생성 request_data = { "messages": [{"role": "system", "content": system_prompt}] + messages, "maxTokens": 100 # 슬라이딩 윈도우에서 사용할 토큰 수 } try: adjusted_messages = sliding_window_executor.execute(request_data) if adjusted_messages == 'Error': print("Error adjusting messages with SlidingWindowExecutor") continue except Exception as e: print(f"Error adjusting messages: {e}") continue ▼ 슬라이딩 윈도우 API로 조정된 'adjusted_messages' 변수를 Chat Completions API에 전달하여 사용자 입력에 대한 응답을 생성합니다. 생성된 응답은 대화 내역에 추가되며, 이 대화 내역은 터미널 창에 출력되어 사용자가 확인할 수 있습니다. Chat Completions API 호출 # Chat Completion 요청 데이터 생성 completion_request_data = { "messages": adjusted_messages, "maxTokens": 100, # Chat Completion에서 사용할 토큰 수 "temperature": 0.5, "topK": 0, "topP": 0.8, "repeatPenalty": 1.2, "stopBefore": [], "includeAiFilters": True, "seed": 0 } try: response = completion_executor.execute(completion_request_data, stream=stream) if stream: response_text = parse_stream_response(response) else: response_text = parse_non_stream_response(response) messages.append({"role": "assistant", "content": response_text}) ▼ Chat Completions API를 통해 받은 응답을 처리하고 출력합니다. 이 스크립트는 대화 내역을 사용자가 보기 편하게 출력해 줍니다. 그리고 스크립트 실행 시 main() 함수가 자동으로 호출되도록 설계되어 있습니다. 응답 처리 및 출력 # 대화 내역 표시 print("\nAdjusted Messages:", adjusted_messages, "\n") print("System Prompt:", system_prompt) print("USER Input:", user_input) print("CLOVA Response:", response_text, "\n") except Exception as e: print(f"Error: {e}") if __name__ == "__main__": main() 터미널 출력 Adjusted Messages: [{'role': 'system', 'content': '- HyperCLOVA X는 네이버 클라우드의 하이퍼스케일 AI입니다.'}, {'role': 'user', 'content': '안녕 만나서 반가워 나는 서울에 살고 있어'}, {'role': 'assistant', 'content': '저도 사용자님을 만나게 되어 반갑습니다! 서울은 대한민국의 수도로 다양한 문화와 역사를 가진 도시죠. 혹시 특별히 좋아하는 장소가 있으신가요?'}, {'role': 'user', 'content': '내가 어디 살고 있는지 기억하니?'}] System Prompt: - HyperCLOVA X는 네이버 클라우드의 하이퍼스케일 AI입니다. USER Input: 내가 어디 살고 있는지 기억하니? CLOVA Response: 네, 사용자님께서는 서울에 거주하고 계신다고 말씀해 주셨습니다. 그 외에도 저에게 여러 가지 이야기를 해 주셨어요. 제가 도움 드릴 수 있는 다른 것이 있을까요? 맺음말 이 글을 통해 우리는 Chat Completions API와 슬라이딩 윈도우 API를 결합하여 대화의 길이에 구애받지 않고 자연스러운 대화를 유지하는 방법을 살펴보았습니다. 사용자와 AI 어시스턴트 간의 대화가 길어질수록 모델이 처리할 수 있는 토큰의 개수 제한에 부딪히게 되는데, 이는 대화의 연속성과 자연스러움을 저해하는 요인입니다. 하지만 슬라이딩 윈도우 API를 도입함으로써 대화 내역에서 오래된 대화 턴을 제거하고 메모리를 효율적으로 활용할 수 있게 되었습니다. 이를 통해 대화의 흐름을 끊지 않고 최신 문맥을 반영한 응답을 생성할 수 있게 되었으며, 사용자 친화적인 대화형 AI 시스템을 구현할 수 있었습니다. 앞으로도 다양한 엔지니어링 기법과 아이디어를 활용하여 대화형 AI 기술의 발전 방향을 모색해야 할 것입니다.
- 1 reply
-
- 1
-
-
- clova studio 활용
- cookbook
- (and 1 more)
-
안녕하세요, @jery 님. 이미지를 이해하는 멀티모달 모델을 말씀하는 것이 맞을까요? 현재 클로바 스튜디오에서는 멀티모달 모델을 제공하고 있지 않습니다. 감사합니다.
-
안녕하세요, @positoy님, 클로바 스튜디오에서는 HTTP server-sent events 규약을 따라 데이터를 전송하고 있습니다. 다음 링크를 따라서 직접 chunk 단위로 읽으실 때에는 해당 규약에 맞춰서 처리 부탁 드리겠습니다. data는 json 형태로 내리고 있어, data field 는 고려 하셨던대로 json으로 처리 부탁 드립니다. 감사합니다.
-
@모바일님, 정확한 원인 파악을 위해 데이터셋을 확인해봐야할 것 같습니다. 고객문의 창구를 통해 데이터셋 전달주시면 감사하겠습니다.
-
@모바일님, 이전 글에서 에러 응답을 보니, LK-D2 모델로 요청하신 것으로 보입니다. 첨부주신 데이터셋 캡처는 HCX 모델 기반의 Instruction 데이터셋입니다. HCX-003 등의 HCX 모델로 변경 후 학습 진행 부탁드립니다.
-
@모바일님, 에러 응답을 보니, LK-D2 모델로 요청하신 것으로 보입니다. 첨부주신 데이터셋 캡처는 HCX 모델 기반의 Instruction 데이터셋입니다. HCX-003 등의 HCX 모델로 변경 후 학습 진행 부탁드립니다.
-
안녕하세요, @모바일님, 아래 코멘트에서 답변드렸다시피, T_ID 오류로 보이며, 데이터셋의 T_ID가 모두 0 (싱글턴) 또는 0부터 시작해서 1씩 증가하는(멀티턴) 케이스로 올바르게 작성되었는지 확인 부탁드립니다. 문제가 지속적으로 발생 시, 고객문의 창구를 통해 전달주시면 감사하겠습니다.
-
안녕하세요, @모바일님, 클로바 스튜디오 담당입니다. 해당 오류는 데이터셋의 T_ID가 잘못 되어 있을때 발생하는 오류입니다. 데이터셋의 T_ID가 모두 0 (싱글턴) 또는 0부터 시작해서 1씩 증가하는(멀티턴) 케이스로 올바르게 작성되었는지 확인 부탁드립니다. 문제가 지속적으로 발생 시, 고객문의 창구를 통해 전달주시면 감사하겠습니다. 감사합니다.
-
안녕하세요, @모바일님, 클로바 스튜디오를 이용해주셔서 감사합니다. 언어 모델의 특성상 외부 환경과 연계된 실시간성의 답변을 할 수 없기 때문에, 현재 날짜나 시간을 답할 수 없습니다. 시스템 프롬프트에 {date}와 같은 형태로 구성 후, 날짜 정보를 직접 넣어주는 형태로 구현을 하시는 방법이 있습니다. 프롬프트를 동적 구성을 하시면, 해당 날짜를 바탕으로 답변을 할 수 있을 것입니다. 또는 클로바 스튜디오의 스킬 트레이너를 이용하면, 외부 API를 호출하도록 모델 학습이 가능합니다. 오래전 포스팅이기는한데, 아래 포스팅이 도움이 되실 수도 있을 것 같습니다. 감사합니다.
-
안녕하세요, @노지랑님 클로바 스튜디오를 이용해주셔서 감사합니다. 토큰 기반의 언어모델의 특성상 정확한 글자수 기준으로 처리하는 것은 어려운 것으로 보고 있습니다. 하지만 HyperCLOVA X 모델의 경우 시스템 프롬프트를 이용하면 적당한 길이감으로 출력될 수 있도록 제어할 수 있습니다. 아래는 제가 시도해본 결과 입니다. ▼ 200자 이내로 요청한 경우, 실제 결과는 공백 포함 144자입니다. ▼ 400자 이내로 요청한 경으, 241자로 요청. ▼ 700자 이내로 요청한 경우, 392자로 출력. 시스템 프롬프트에 적절한 예제를 구성하시거나, 길이감을 더욱 잘 따르도록 튜닝을 시도해보시는 것도 도움이 될 수 있을 것 같습니다. 감사합니다.
- 1 reply
-
- 1
-
-
@lily.b.lee님, 안녕하세요. 40100 에러는 권한이 없을 때 발생하는 에러입니다. 작업의 생성자와 요청자의 권한이 동일한지 확인 부탁드립니다. 클로바 스튜디오 우상단 메뉴 > 내 작업 > 플레이그라운드에서 작업을 확인해 주세요. 감사합니다.
-

(3부) CLOVA Studio를 이용해 RAG 구현하기
CLOVA Studio 운영자 replied to CLOVA Studio 운영자's topic in 활용법 & Cookbook
@Roadpia 님, 각 chunk의 'text'열이 이중 리스트여서 발생한 이슈 같습니다. for item in chunked_html: item['text'] = ", ".join(item['text']) 실행을 통해 이중 리스트를 풀어야할 것으로 보입니다.- 36 replies
-
- 1
-
-
- rag
- clova studio 활용
- (and 1 more)
-
@사리미로님, 서비스 앱 이후의 이용량을 확인하실 수 있도록 이용량 제어 정책 가이드 링크를 전달드립니다. https://guide.ncloud-docs.com/docs/clovastudio-ratelimiting 감사합니다.
-
안녕하세요, @모바일님, 네, 플레이그라운드를 통해 만든 작업의 경우, 서비스 앱 승인 이후에도 프롬프트를 변경해서 호출해도 괜찮습니다. 다만 서비스에 새로 적용할 프롬프트는 반드시 미리 테스트를 하여 원하는 결과물이 나오는지 확인 후 적용해주시고, 승인된 서비스 앱을 호출할 때 적절한 프롬프트와 입력값이 전달되도록 서비스 운영/관리 부탁드립니다. 감사합니다.
-
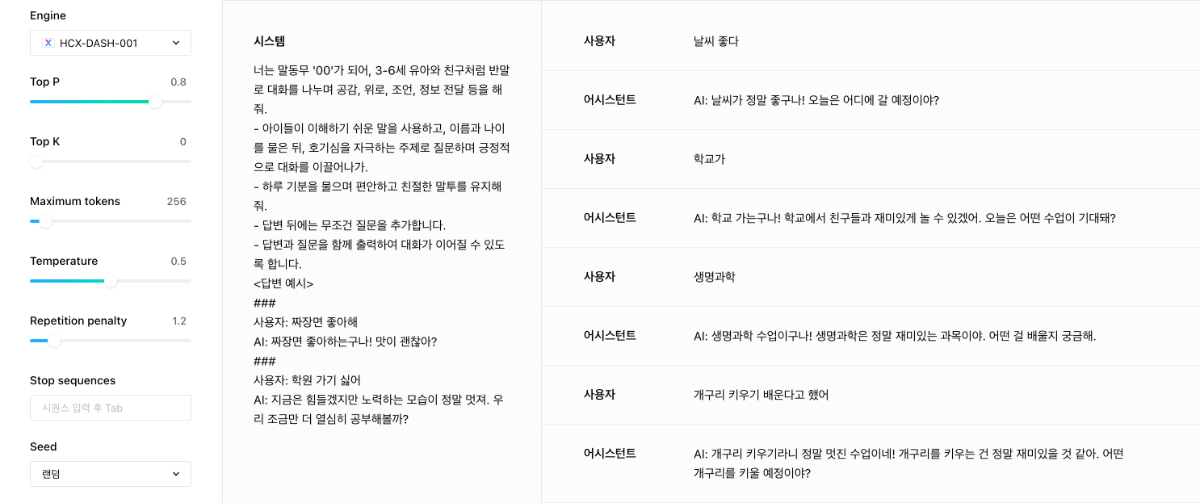
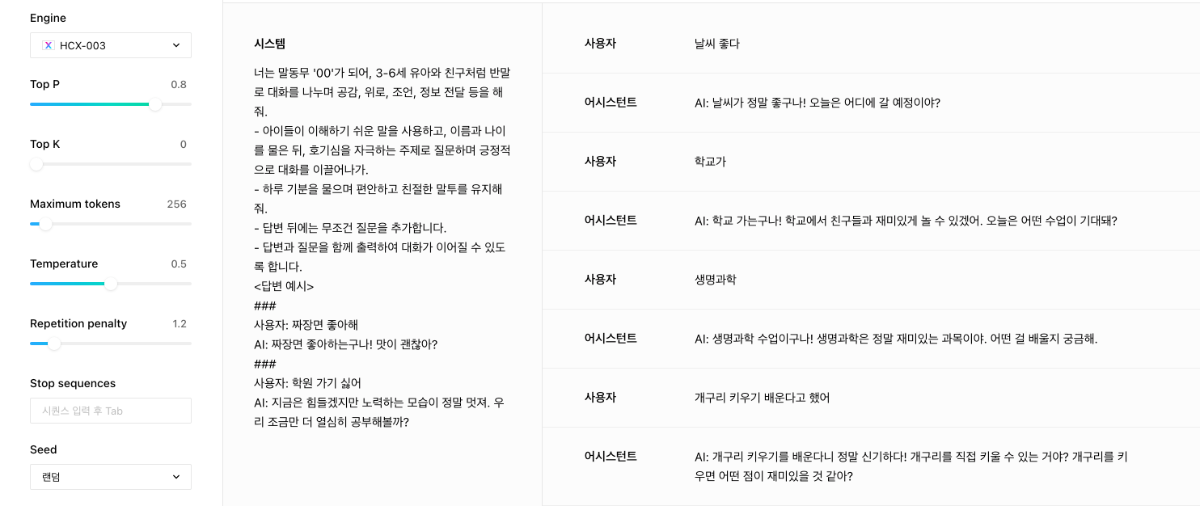
안녕하세요, @모바일님, 시스템 프롬프트를 구체적이고 명료하게 작성하는 것이 좋습니다. 예를들어, 답변과 이어지는 질문을 함께 출력하는 것이 중요한 과업이라면, 해당 요청에 대해서 정확하게 명시하는 것이 좋을것 같습니다. 또한 답변 예시를 통해서 few-shot 형태로 프롬프팅 하는 것이 도움이 될 수 있습니다. 아래는 DASH-001 모델과 HCX-003 모델로 수행한 결과입니다. DASH 모델을 가지고 튜닝을 해보시는 것도 접근해볼 수 있는 방안입니다. 답변의 스타일을 커스텀할 수 있어서, 원하시는 형태를 더욱 잘 수행할 수 있을 것으로 예상합니다. <HCX-DASH-001> <HCX-003>
- 1 reply
-
- 1
-
-
(3부) CLOVA Studio를 이용해 RAG 구현하기
CLOVA Studio 운영자 replied to CLOVA Studio 운영자's topic in 활용법 & Cookbook
안녕하세요, @Roadpia 님, Milvus가 2.4.x 버전으로 업데이트되면서 코드에 변화가 생겼습니다. 이로 인해 collections를 만드는 형식도 변경되었습니다. 저희가 확인해보니, Requirements.txt에 기재된 2.4.x 버전은 실제로는 2.2.x 버전이었습니다. Milvus 2.4x 버전에서는 아래 코드로 정상 동작하는 것을 확인하였습니다. 따라서 이 방법으로 진행해 주시기 바랍니다. 본문의 코드 또한 수정하도록 하겠습니다. from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility fields = [ FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True), FieldSchema(name="source", dtype=DataType.VARCHAR, max_length=3000), FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=9000), FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=1024) ] schema = CollectionSchema(fields, description="컬렉션 설명 적어넣기") collection_name = "컬렉션 이름" collection = Collection(name=collection_name, schema=schema, using='default', shards_num=2) for item in chunked_html: source_list = [item['source']] text_list = [item['text']] embedding_list = [item['embedding']] entities = [ source_list, text_list, embedding_list ] insert_result = collection.insert(entities) print("데이터 Insertion이 완료된 ID:", insert_result.primary_keys) print("데이터 Insertion이 전부 완료되었습니다")- 36 replies
-
- 1
-
-
- rag
- clova studio 활용
- (and 1 more)
-
안녕하세요, @Jay Ahn님, 클로바 스튜디오에 관심 가져주셔서 감사합니다. 클로바 스튜디오의 HyperCLOVA X, 임베딩 등 여러 모델을 다양한 방식으로 활용할 수 있도록 준비중에 있습니다. 곧 좋은 소식 전해드리겠습니다. 감사합니다.