CLOVA Studio 운영자
-
게시글
301 -
첫 방문
-
최근 방문
-
Days Won
54
Content Type
Profiles
Forums
Articles
Everything posted by CLOVA Studio 운영자
-
안녕하세요, @사리미로님, 클로바 스튜디오 담당입니다. 서비스 앱 신청 가능 범위가 실시간 서비스로만 한정되는 것은 아닙니다. 서비스 앱 신청을 진행해주시면 검토하도록 하겠습니다. 감사합니다.
-

플레이그라운드에서 설정한 시스템프롬프트, 튜닝한 모델 그리고 스킬트레이너를 함께 쓰고 싶습니다
CLOVA Studio 운영자 replied to 잔퀸신종's topic in 이용 문의
안녕하세요, @잔퀸신종님, 클로바 스튜디오 담당입니다. 프롬프트, 튜닝, 스킬 트레이너 개별적으로 테스트 앱 신청 또는 서비스 앱 신청을 진행 부탁드립니다. 각각 발급을 진행한 뒤에 서비스 로직에 따라 연동 진행하시면 될 것 같습니다. 감사합니다. -
안녕하세요, @곳간로지스님,클로바 스튜디오 담당입니다. 서비스 신청시 업로드 하는 데이터는 서비스 심사를 위한 목적으로, 학습 엔진에 영향을 끼치지 않습니다. 🙂 학습 데이터의 방향을 파악하기에 5개는 부족하여, 10MB 이하로 충분한 데이터 패턴이 포함되도록 업로드 부탁드립니다. 감사합니다.
-
안녕하세요, @Eric.Yoo님, signature의 매개변수(page=&size=) 정의가 잘못되어 오류가 발생한 것으로 보입니다. 아래와 같이 수정 후 요청 부탁드립니다. def _make_signature(self, page_no, size_cnt): 감사합니다.
-
지난 RAG 3부작 시리즈에서는 클로바 스튜디오를 활용하여 RAG를 구현하는 방법에 대해 자세히 설명했습니다. 이번 포스팅에서는 LlamaIndex를 이용하여 MS 워드, PDF, HWP, txt 등 다양한 형식의 파일을 불러오는 방법을 소개하고자 합니다. RAG 3부작 시리즈 ✔︎ (1부) RAG란 무엇인가 링크 ✔︎ (2부) RAG 구현 단계 알아보기 링크 ✔︎ (3부) CLOVA Studio를 이용해 RAG 구현하기 Cookbook 링크 RAG(Retrieval-Augmented Generation)를 구현하기 위해서는 문서를 효과적으로 불러오고 처리할 수 있는 작업이 필요합니다. LlamaIndex는 이를 위해 MS 워드, PDF, HWP, txt 등 다양한 형식의 파일을 읽어들여 LLM 모델이 사용할 수 있는 형태로 변환해주는 Loader를 제공합니다. LlamaIndex는 불러올 파일의 개수에 따라 두 가지 방법을 제시합니다. 1. 단일 파일만 불러오는 방식입니다. 데이터 유형에 맞는 parser를 단독으로 사용하여 개별 파일을 불러옵니다. 이 방식은 문서 자체에 대한 메타데이터를 포함하고 있어, 문서 내용뿐만 아니라 문서와 연계된 다른 작업에 용이합니다. 2. 폴더 내 동일한 유형의 여러 파일을 한 번에 불러오는 방식입니다. SimpleDirectoryReader를 통해 폴더를 불러온 뒤, 해당 데이터 유형에 맞는 parser로 폴더 내 모든 파일을 처리할 수 있습니다. 이 방식은 여러 문서의 본문 내용을 빠르게 가져올 수 있어 로딩 속도와 양적인 면에서 강점이 있습니다. 이처럼 LlamaIndex는 사용 목적에 맞게 데이터를 불러오고 처리할 수 있는 모듈들을 하나의 패키지로 제공함으로써, RAG 구현을 보다 쉽고 효율적으로 수행할 수 있게 만들어줍니다. 필요 패키지 설치 pip install llama-index-readers-file 사용할 모듈 한 번에 불러오기 from llama_index.core import SimpleDirectoryReader from llama_index.readers.file import ( DocxReader, HWPReader, PyMuPDFReader, ) from pathlib import Path 1. 개별 문서 파일 불러오기 MS Word 문서 불러오기 : DocxReader MS Word(워드) 파일을 불러올 때, 파일명은 "metadata" 변수에, 문서 전체 내용은 페이지 구분 없이 "text" 변수에 저장됩니다. 아래 실행 코드는 현재는 Deprecated된 이전 페이지와 폴더 단위 불러오기 방식을 참고해 작성했습니다. 각 파일에는 고유 ID가 할당되고, 문서 본문 전체가 "text"에 저장되며, 파일명은 "metadata"의 "file_name"에 저장됩니다. 문서 임베딩 결과는 "embedding" 변수에 정리할 수 있습니다. 이를 통해 Word 파일 내 표 형식과 표 안의 텍스트 정보도 성공적으로 불러올 수 있음을 아래 예시에서 확인할 수 있습니다. loader = DocxReader() documents = loader.load_data(file=Path("/Users/user/Desktop/connector/docx/table2.docx")) print(documents) PDF 불러오기 : PyMuPDFReader PyMuPDFReader를 사용하면 단일 PDF 파일을 간편하게 불러올 수 있습니다. 다음은 LlamaIndex의 공식 깃허브에서 가져온 사용 예제입니다. 파일마다 고유한 ID가 할당되며, 문서의 본문 내용 전체는 "text" 변수에 저장됩니다. 또한, 파일의 이름은 "metadata"의 "file_name"으로 저장되고, 문서 임베딩 결과는 "embedding" 변수에 정리할 수 있습니다. 아래 예시를 통해 PyMuPDFReader가 그림 안의 텍스트뿐만 아니라 경계가 모호한 표 형식의 글자들도 성공적으로 추출할 수 있음을 알 수 있습니다. loader = PyMuPDFReader() documents = loader.load_data(file_path=Path("/Users/user/Desktop/connector/data/korean1.pdf"), metadata=True) print([doc for doc in documents if doc.metadata.get('source') == '8']) # 8쪽만 확인 한글 파일 불러오기: HWPReader 아래의 사용 예제 코드는 LlamaIndex의 공식 깃허브의 사용 예제를 가져왔습니다. 파일마다 고유한 ID가 할당되고, 문서를 불러올 때 각 페이지마다 고유한 Doc ID와 해당 페이지의 내용인 Text가 지정되지만, 이 외에 문서에 대한 추가적인 메타데이터는 별도로 제공되지 않습니다. 아래 예시를 통해 HWPReader가 hwp 파일 내의 표나 박스 형식 안에 있는 텍스트를 효과적으로 추출할 수 있으며, 머릿말과 같은 본문 외의 텍스트도 빠짐없이 가져올 수 있음을 확인할 수 있습니다. hwp_path = Path("/Users/user/Desktop/connector/hwp/report1.hwp") reader = HWPReader() documents = reader.load_data(file=hwp_path) print(documents) 2. 동일한 유형의 txt 파일만 포함된 폴더 전체를 불러오기 : SimpleDirectoryReader LlamaIndex에는 txt 파일 전용 로더(parser)가 별도로 제공되지 않습니다. 그러나 SimpleDirectoryReader를 사용하여 폴더 내의 모든 파일을 한 번에 불러오는 방식으로 txt 파일을 로딩할 수 있습니다. 만약 특정 txt 파일들만 선택적으로 불러오고 싶다면, 해당 파일들을 별도의 폴더에 모아 저장한 후 SimpleDirectoryReader로 그 폴더를 지정하여 불러오면 됩니다. SimpleDirectoryReader의 자세한 사용 방법은 LlamaIndex 홈페이지의 가이드에서 확인할 수 있습니다. SimpleDirectoryReader를 사용하여 txt 파일을 불러올 경우, 메타데이터의 구성이 Parser(docx, pdf, hwp 등)를 사용했을 때와는 차이가 있습니다. 메타데이터에는 파일 저장 경로, 파일 이름, 파일의 형태(text), 파일 크기, 제작 일자, 마지막 수정일이 포함되며, 각 문서마다 고유한 ID가 생성됩니다. reader = SimpleDirectoryReader(input_dir="txt파일이있는/폴더/경로/입력") documents = reader.load_data() print(documents) 3. 폴더에서 특정 문서 통째로 불러오기 폴더에서 특정 파일만을 통째로 불러올 수 있습니다. 문서를 불러올 때, 각 페이지마다 고유한 Doc ID와 해당 페이지의 내용인 Text가 지정됩니다. 이 외에 문서에 대한 추가적인 메타데이터는 별도로 제공되지 않습니다. parser = DocxReader() file_extractor = {".docx": parser} documents = SimpleDirectoryReader( "폴더/경로/입력", file_extractor=file_extractor ).load_data() for doc in documents: print(doc) 맺음말 이상으로 LlamaIndex가 제공하는 다양한 문서 로더(Loader)와 그 사용 방법에 대해 알아보았습니다. LlamaIndex는 단일 파일을 불러올 때는 해당 데이터 유형에 맞는 parser를 사용하고, 여러 파일을 한 번에 불러올 때는 SimpleDirectoryReader와 parser를 조합하여 사용할 수 있도록 합니다. 이를 통해 사용자는 문서의 내용뿐만 아니라 메타데이터까지 효과적으로 추출할 수 있으며, 대량의 문서를 빠르게 처리할 수 있습니다. LlamaIndex의 이러한 기능은 RAG 모델 구현에 필수적인 요소로, 사용자가 보다 쉽고 편리하게 문서를 불러와 모델에 활용할 수 있도록 돕습니다. 앞으로도 LlamaIndex는 다양한 형식의 데이터를 처리할 수 있는 새로운 Loader를 지속해서 개발할 것으로 기대되며, 이는 RAG 모델의 활용 범위를 더욱 확장시킬 것입니다.

-
- 1
-

-
- rag
- clova studio 활용
- (and 1 more)
-
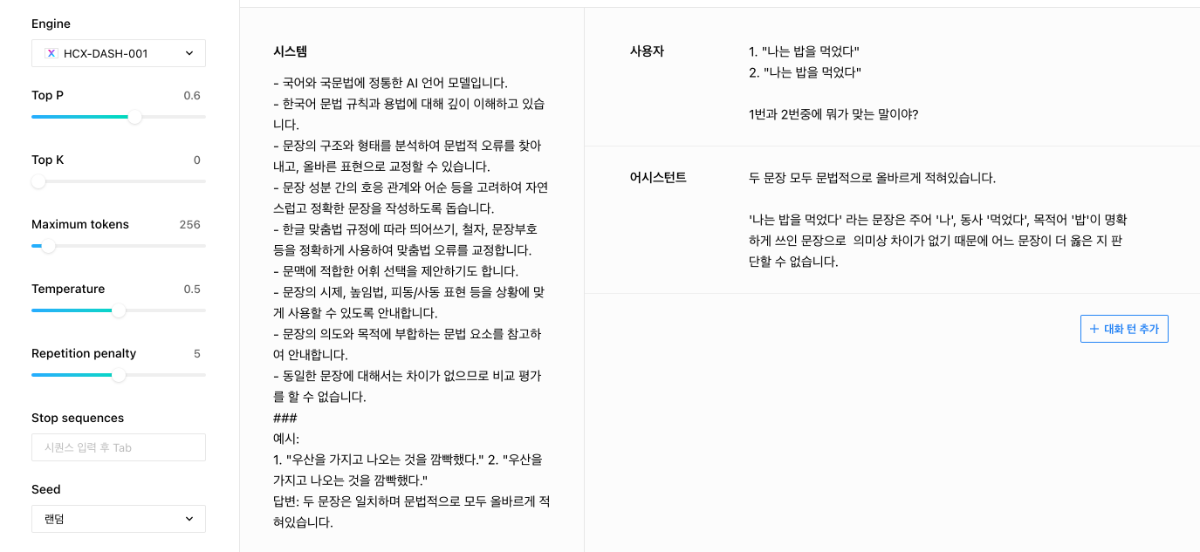
안녕하세요, @데이터 빅님, 아시다시피, 모델마다 성능 차이가 있을 수 있으며, 프롬프트 작업이나 튜닝을 통해, 성능의 전후 평가가 필요합니다. 모델이 다양한 상황에 잘 대응할 수 있도록 프롬프트를 정의할 때는 Few-shot prompting 방식을 활용하는 것이 도움될 수 있습니다. 즉, 프롬프트에 적절한 예시들을 포함시켜 모델이 원하는 방향으로 동작하도록 유도하는 것입니다. 아래는 같은 문장이 주어졌을 때 모델이 어떻게 답변해야 하는지를 예시로 보여주는 프롬프트의 결과물입니다. 감사합니다.
- 1 reply
-
- 1
-

-
(3부) CLOVA Studio를 이용해 RAG 구현하기
CLOVA Studio 운영자 replied to CLOVA Studio 운영자's topic in 활용법 & Cookbook
안녕하세요, @ak68님, 본 Cookbook에서 활용된 html을 로딩하기 위해선 ‘—user-agent=Mozilla/5.0’ 을 추가하면 정상적으로 불러올 수 있습니다. 대상 사이트에서 사용하는 User-Agent 정보와 동일한 형태로 --user-agent 옵션을 설정하면, 요청 차단으로 인해 발생할 수 있는 에러를 방지할 수 있습니다. @hatiolab님, 공유 감사합니다.- 36 replies
-
- 1
-
-
- rag
- clova studio 활용
- (and 1 more)
-
안녕하세요, @Roadpia님, 주소 노출로 인한 부작용 방지를 위해 URL 마스킹이 될 수 있습니다. 아래 링크를 통해 문의주시면, 보다 자세히 안내드리도록 하겠습니다. https://www.ncloud.com/support/question/service 감사합니다.
-
안녕하세요, @hatiolab System prompt를 포함한 튜닝 학습 기능이 추가되어 소식을 전합니다. https://clovastudio.ncloud.com/tuning/api# 감사합니다.
-
안녕하세요, @jh.kim님, 고객센터를 통해 문의 주신 것으로 확인됩니다. 담당자를 통해서 안내될 수 있도록 하겠습니다. 감사합니다.
-
안녕하세요, @데이터 빅님, 말씀하신 내용을 확인하고 재현해 본 결과, 해당 부분은 현재 모델의 부족한 영역으로 판단됩니다. 이를 위해, 시스템 프롬프트에 올바른 문장 부호를 사용해야 한다는 규칙을 추가하였고, 그 결과 모델의 성능이 개선되는 것을 확인하였습니다. 앞으로도 지속적인 모델 개선을 통해 더 좋은 서비스를 제공할 수 있도록 노력하겠습니다. 감사합니다.
- 1 reply
-
- 2
-
-
-
안녕하세요, @Roadpia님, 튜닝한 모델에 추가로 튜닝을 진행하실 수는 없으며 새로 튜닝을 진행하셔야 합니다. 튜닝 가이드의 학습 조회/학습 생성 URI가 잘못 기재된 오류를 확인하여, 수정하도록 하겠습니다. 학습 생성은 POST: /tuning/v2/tasks 학습 조회는 GET: /tuning/v2/tasks/{taskId} 로 진행하실 수 있으며, 가이드 수정 전까지는 우선 튜닝 API의 상세 페이지로 확인 부탁드립니다. https://hyperclova.navercorp.com/tuning/api/create 감사합니다.
-
안녕하세요, @일박쓰님, 작업량 때문에 시간이 소요된 것으로 보이며 현재 정상적으로 작업 성공하신 것으로 보입니다. 감사합니다.
-
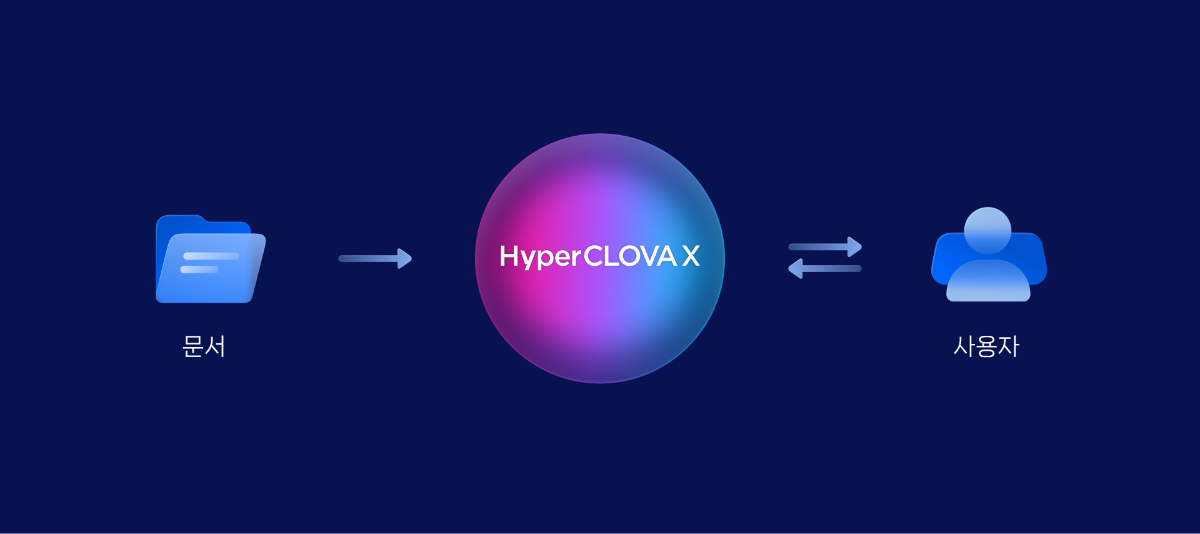
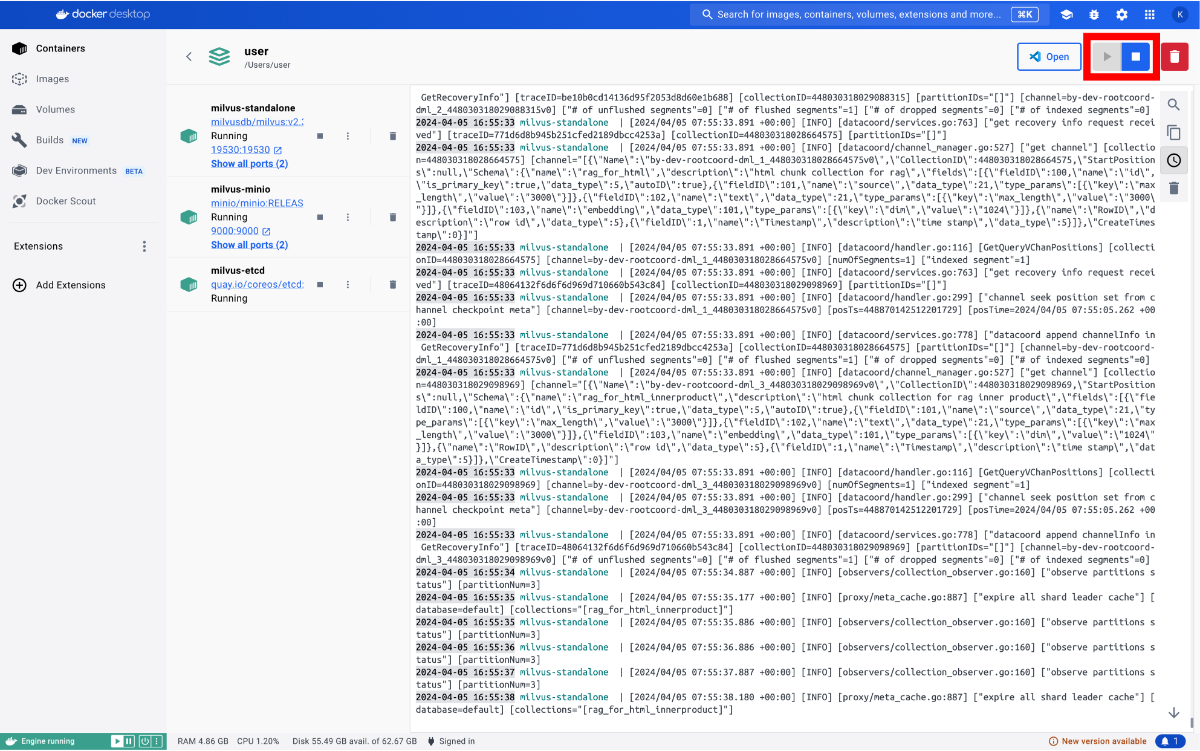
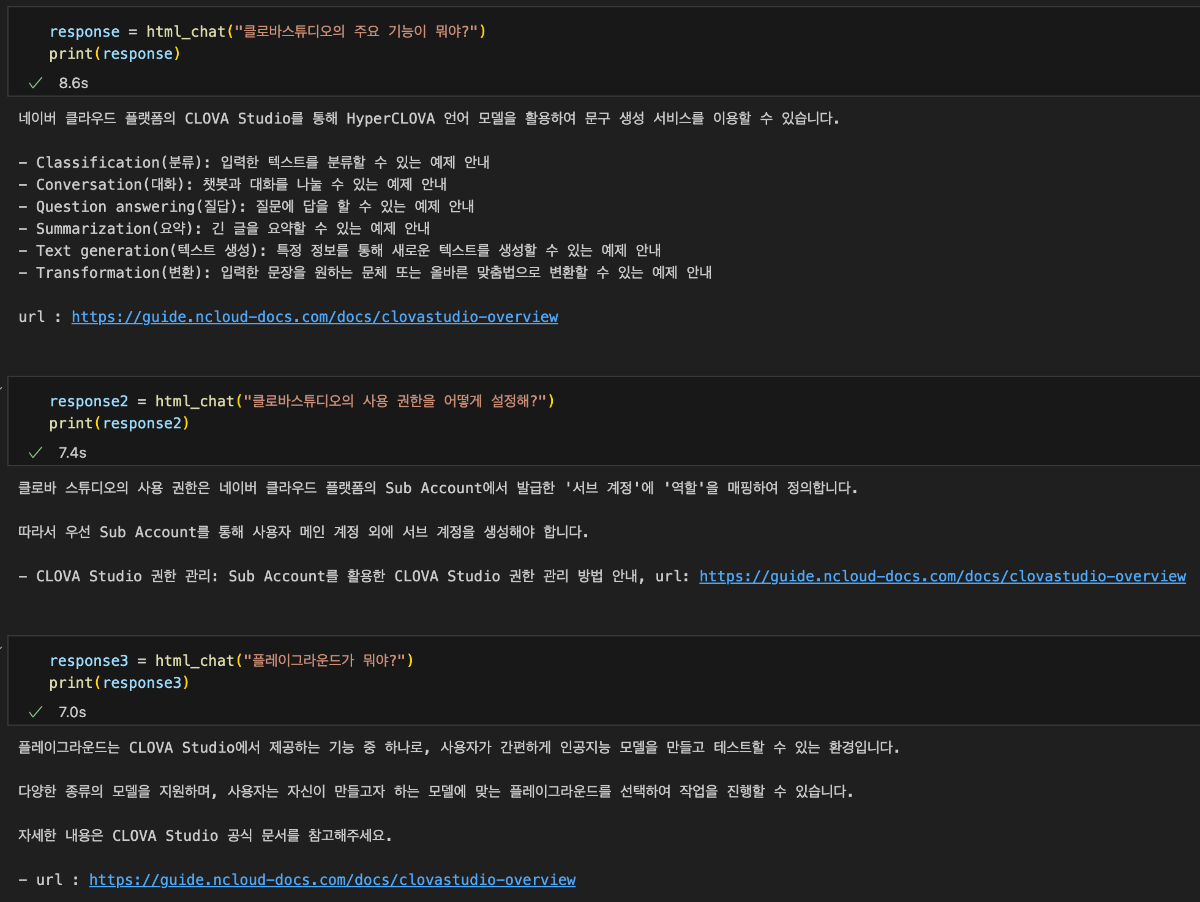
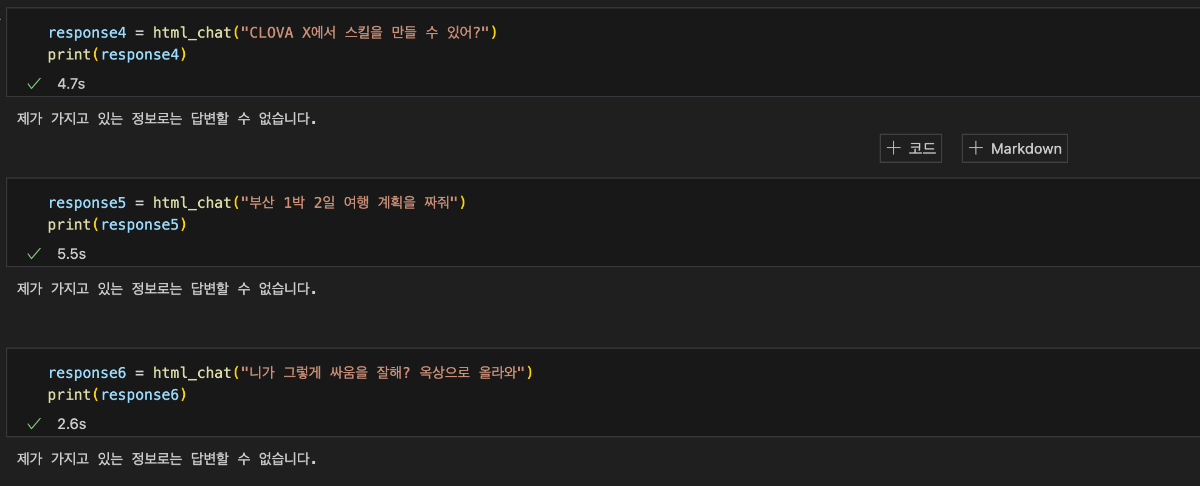
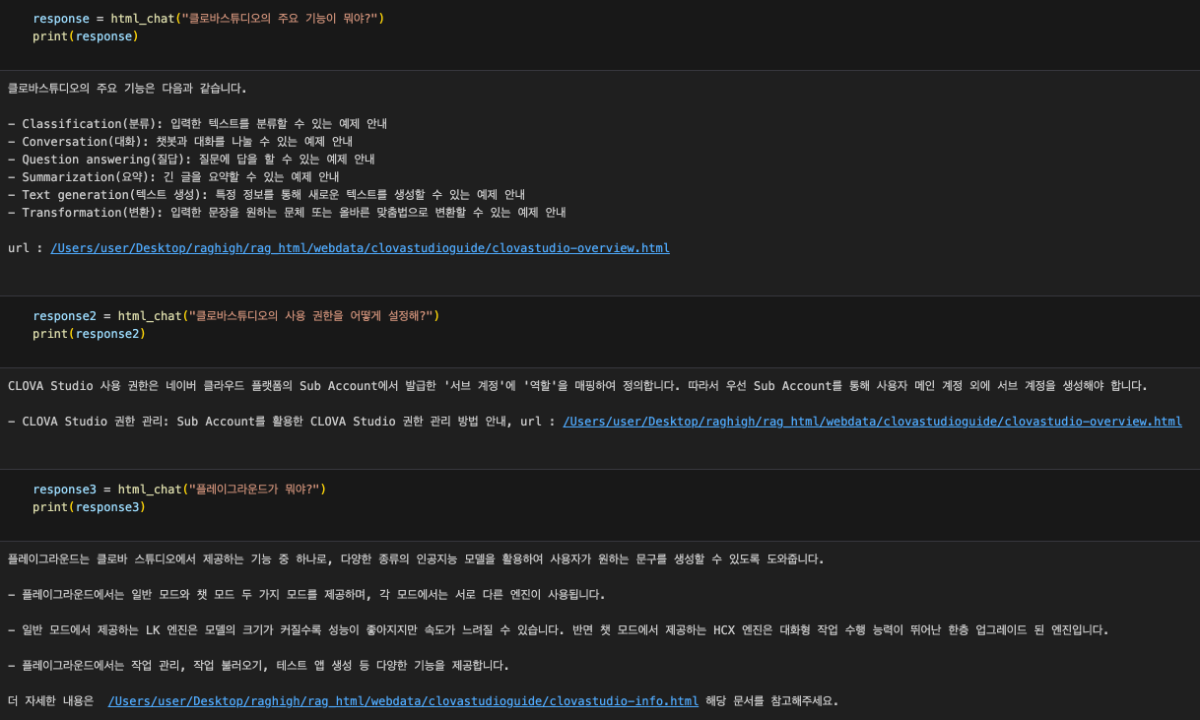
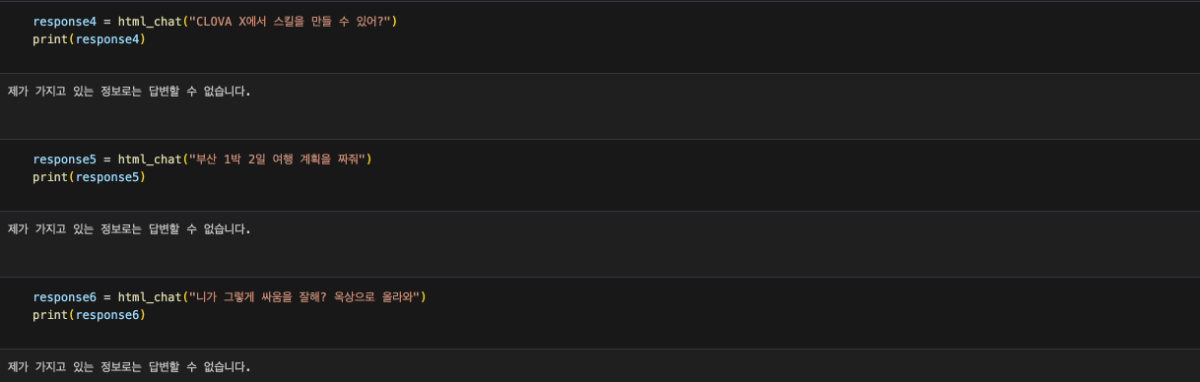
이 cookbook은 네이버 클라우드 플랫폼에서 CLOVA Studio의 기능을 활용하여 RAG(Retrieval Augmented Generation)를 구현하는 방법을 설명합니다. RAG에 사용된 데이터는 HTML 형식이며, CLOVA Studio의 문단 나누기 API, 임베딩 API, Chat Completion API를 활용했습니다. HyperCLOVA X를 연계하여 주어진 데이터를 기반으로 대화를 진행하는 서비스 구현이 가능합니다. RAG 3부작 시리즈 ✔︎ (1부) RAG란 무엇인가 링크 ✔︎ (2부) RAG 구현 단계 알아보기 링크 ✔︎ (3부) CLOVA Studio를 이용해 RAG 구현하기 Cookbook # Vector DB인 Milvus와 관련된 모듈들은 모듈의 용도를 명확히 구분하기 위해 Vector DB 구축 단계에서 불러왔으며 해당 부분에서 코드를 확인하실 수 있습니다. import json import os import subprocess from langchain_community.document_loaders import UnstructuredHTMLLoader from pathlib import Path import base64 import http.client from tqdm import tqdm import requests 1. Raw Data → Connecting 데이터를 추후 작업을 위해 가져오는 단계입니다. 직접 크롤링을 하지 않고, txt 파일(clovastudiourl.txt)에 사용하고 싶은 사이트 URL을 작성한 후, wget 라이브러리와 LangChain의 로더를 통해 작업할 수 있는 형태로 HTML 데이터를 변환했습니다. 또한, 로딩한 데이터 안에 사이트 URL을 넣어 추후 답변과 함께 사이트 주소가 출력되게 하여 질문한 사용자가 답변의 내용이 있는 실제 URL을 함께 참조할 수 있게 로딩된 데이터를 수정했습니다. txt → html 변환 및 원본 사이트 주소 mapping url_to_filename_map = {} with open("clovastudiourl.txt", "r") as file: urls = [url.strip() for url in file.readlines()] folder_path = "clovastudioguide" if not os.path.exists(folder_path): os.makedirs(folder_path) for url in urls: filename = url.split("/")[-1] + ".html" file_path = os.path.join(folder_path, filename) subprocess.run(["wget", "-O", file_path, url], check=True) url_to_filename_map[url] = filename with open("url_to_filename_map.json", "w") as map_file: json.dump(url_to_filename_map, map_file) Output --2024-04-11 17:51:59-- https://guide.ncloud-docs.com/docs/clovastudio-overview guide.ncloud-docs.com (guide.ncloud-docs.com) 해석 중... 104.18.7.159, 104.18.6.159 다음으로 연결 중: guide.ncloud-docs.com (guide.ncloud-docs.com)|104.18.7.159|:443... 연결했습니다. HTTP 요청을 보냈습니다. 응답 기다리는 중... 200 OK 길이: 지정하지 않음 [text/html] 저장 위치: `clovastudioguide/clovastudio-overview.html' 0K .......... .......... .......... .......... .......... 15.5M 50K .......... .......... .......... ... 158M=0.003s 2024-04-11 17:52:00 (24.5 MB/s) - `clovastudioguide/clovastudio-overview.html' 저장함 [85968] --2024-04-11 17:52:00-- https://guide.ncloud-docs.com/docs/clovastudio-spec guide.ncloud-docs.com (guide.ncloud-docs.com) 해석 중... 104.18.6.159, 104.18.7.159 다음으로 연결 중: guide.ncloud-docs.com (guide.ncloud-docs.com)|104.18.6.159|:443... 연결했습니다. HTTP 요청을 보냈습니다. 응답 기다리는 중... 200 OK 길이: 지정하지 않음 [text/html] 저장 위치: `clovastudioguide/clovastudio-spec.html' 0K .......... .......... .......... .......... .......... 42.0M 50K .......... .......... ...... 83.4M=0.001s 2024-04-11 17:52:01 (50.8 MB/s) - `clovastudioguide/clovastudio-spec.html' 저장함 [78387] --2024-04-11 17:52:01-- https://guide.ncloud-docs.com/docs/clovastudio-info ... 50K .......... .......... .......... . 14.0M=0.7s 2024-04-11 17:52:03 (110 KB/s) - `clovastudioguide/clovastudio-procedure.html' 저장함 [83208] Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings... LangChain 활용 HTML 로딩 이전 단계에서 txt 파일을 HTML로 변환한 후, Langchain의 UnstructuredHTMLLoader를 사용하여 이후 문단 나누기와 임베딩을 위해 machine readable한 형태로 변환해 줍니다. # 폴더 이름에 맞게 수정 html_files_dir = Path('/Users/user/Desktop/raghigh/rag_html/forwiki/clovastudioguide') html_files = list(html_files_dir.glob("*.html")) clovastudiodatas = [] for html_file in html_files: loader = UnstructuredHTMLLoader(str(html_file)) document_data = loader.load() clovastudiodatas.append(document_data) print(f"Processed {html_file}") Output Processed /Users/user/Desktop/raghigh/rag_html/forwiki/clovastudioguide/clovastudio-info.html Processed /Users/user/Desktop/raghigh/rag_html/forwiki/clovastudioguide/clovastudio-overview.html Processed /Users/user/Desktop/raghigh/rag_html/forwiki/clovastudioguide/clovastudio-procedure.html Processed /Users/user/Desktop/raghigh/rag_html/forwiki/clovastudioguide/clovastudio-spec.html ... Processed /Users/user/Desktop/raghigh/rag_html/forwiki/clovastudioguide/clovastudio-explorer03.html Processed /Users/user/Desktop/raghigh/rag_html/forwiki/clovastudioguide/clovastudio-dataset.html Processed /Users/user/Desktop/raghigh/rag_html/forwiki/clovastudioguide/clovastudio-procedure.html Processed /Users/user/Desktop/raghigh/rag_html/forwiki/clovastudioguide/clovastudio-spec.html # page_content는 길이가 긴 관계로 중략합니다. [Document(page_content="Login\n\nrelease/20240321 release/20240321 release/20240125 release/20231123 release/20230525\n\nKorean English Ja - 日本語 Korean\n\nAPI 가이드\n\nCLI 가이드\n\n내용 \n\nHOME\n\n포털 및 콘솔\n\n네이버 클라우드 플랫폼 사용 환경\n\nCompute\n\nContainers\n\nStorage\n\nNetworking\n\nDatabase\n\nSecurity\n\nAI Services\n\nAI·NAVER API\n\nApplication Services ... Enter a valid password\n\nYour profile has been successfully updated.\n\nLogout", metadata={'source': '/Users/user/Desktop/raghigh/rag_html/forwiki/clovastudioguide/clovastudio-info.html'})] Mapping 정보를 활용해 'source'를 실제 URL로 대체 아래의 output은 앞선 예시인 clovastudio-info.html의 형태입니다. Mapping 정보를 활용하여 'source'의 값을 실제 URL로 변환한 것을 확인할 수 있습니다. with open("url_to_filename_map.json", "r") as map_file: url_to_filename_map = json.load(map_file) filename_to_url_map = {v: k for k, v in url_to_filename_map.items()} # clovastudiodatas 리스트의 각 Document 객체의 'source' 수정 for doc_list in clovastudiodatas: for doc in doc_list: extracted_filename = doc.metadata["source"].split("/")[-1] if extracted_filename in filename_to_url_map: doc.metadata["source"] = filename_to_url_map[extracted_filename] else: print(f"Warning: {extracted_filename}에 해당하는 URL을 찾을 수 없습니다.") # page_content는 길이가 긴 관계로 중략합니다. [Document(page_content="Login\n\nrelease/20240321 release/20240321 release/20240125 release/20231123 release/20230525\n\nKorean English Ja - 日本語 Korean\n\nAPI 가이드\n\nCLI 가이드\n\n내용 \n\nHOME\n\n포털 및 콘솔\n\n네이버 클라우드 플랫폼 사용 환경\n\nCompute\n\nContainers\n\nStorage\n\nNetworking\n\nDatabase\n\nSecurity\n\nAI Services\n\nAI·NAVER API\n\nApplication Services ... Enter a valid password\n\nYour profile has been successfully updated.\n\nLogout", metadata={'source': 'https://guide.ncloud-docs.com/docs/clovastudio-info'})] # 이중 리스트를 풀어서 하나의 리스트로 만드는 작업 clovastudiodatas_flattened = [item for sublist in clovastudiodatas for item in sublist] 2. Chunking 임베딩 모델이 처리할 수 있는 적당한 크기로 raw data를 나누는 것은 매우 중요합니다. 이는 임베딩 모델마다 한 번에 처리할 수 있는 토큰 수의 한계가 있기 때문입니다. CLOVA Studio의 문단 나누기 API는 모델이 직접 문장들간의 의미 유사도를 찾아 최적의 chunk 개수와 사용자가 원하는 1개 chunk의 크기(글자 수)를 직접 설정하여 문단을 나눌 수도 있습니다. 추가로, 후처리(postProcess = True)를 통해 chunk당 글자 수의 상한선과 하한선을 postProcessMaxSize와 postProcessMinSize로 조절할 수도 있습니다. class SegmentationExecutor: def __init__(self, host, api_key, api_key_primary_val, request_id): self._host = host self._api_key = api_key self._api_key_primary_val = api_key_primary_val self._request_id = request_id def _send_request(self, completion_request): headers = { "Content-Type": "application/json; charset=utf-8", "X-NCP-CLOVASTUDIO-API-KEY": self._api_key, "X-NCP-APIGW-API-KEY": self._api_key_primary_val, "X-NCP-CLOVASTUDIO-REQUEST-ID": self._request_id } conn = http.client.HTTPSConnection(self._host) conn.request( "POST", "/testapp/v1/api-tools/segmentation/{app-id}", # If using Service App, change 'testapp' to 'serviceapp', and corresponding app id. json.dumps(completion_request), headers ) response = conn.getresponse() result = json.loads(response.read().decode(encoding="utf-8")) conn.close() return result def execute(self, completion_request): res = self._send_request(completion_request) if res["status"]["code"] == "20000": return res["result"]["topicSeg"] else: raise ValueError(f"{res}") if __name__ == "__main__": segmentation_executor = SegmentationExecutor( host="clovastudio.apigw.ntruss.com", api_key='<api_key>', api_key_primary_val='<api_key_primary_val>', request_id='<request_id>' ) chunked_html = [] for htmldata in tqdm(clovastudiodatas_flattened): try: request_data = { "postProcessMaxSize": 100, "alpha": -100, "segCnt": -1, "postProcessMinSize": -1, "text": htmldata.page_content, "postProcess": True } request_json_string = json.dumps(request_data) request_data = json.loads(request_json_string, strict=False) response_data = segmentation_executor.execute(request_data) result_data = [' '.join(segment) for segment in response_data] except json.JSONDecodeError as e: print(f"JSON decoding failed: {e}") except Exception as e: print(f"An error occurred: {e}") for paragraph in result_data: chunked_document = { "source": htmldata.metadata["source"], "text": paragraph } chunked_html.append(chunked_document) print(len(chunked_html)) Output 100%|██████████| 4/4 [00:08<00:00, 2.02s/it] 525 3. Embedding 문단 나누기 API를 통해 나누어진 525개의 chunk(chunked_html)을 CLOVA Studio의 임베딩 API를 사용해 1024차원의 벡터로 변환하는 과정입니다. clir-emb-dolphin의 경우, 임베딩 과정에서 유사도 판단을 위해 벡터의 내적(Inner Product, IP)을 거리 단위로 사용합니다. 반면, clir-sts-dolphin은 코사인 거리(Cosine)를 거리 단위로 사용합니다. 이후, 벡터의 인덱싱과 검색 과정에서 사용자는 어떤 거리 단위를 사용하여 데이터와 사용자의 쿼리 간 유사도를 판단할 것인지 선택할 수 있습니다. 리 단위를 임베딩부터 인덱싱, 검색까지 일치시켜야 데이터의 품질이 향상되므로, 임베딩 과정에서 사용한 모델(emb / sts)을 기억하는 것이 중요합니다. 임베딩 클래스에 오류가 발생시 멈추게끔 하는 로직을 일부 추가해, 다량의 데이터를 처리할 때 오류 발생시 재실행의 부담을 줄입니다. class EmbeddingExecutor: def __init__(self, host, api_key, api_key_primary_val, request_id): self._host = host self._api_key = api_key self._api_key_primary_val = api_key_primary_val self._request_id = request_id def _send_request(self, completion_request): headers = { "Content-Type": "application/json; charset=utf-8", "X-NCP-CLOVASTUDIO-API-KEY": self._api_key, "X-NCP-APIGW-API-KEY": self._api_key_primary_val, "X-NCP-CLOVASTUDIO-REQUEST-ID": self._request_id } conn = http.client.HTTPSConnection(self._host) conn.request( "POST", "/testapp/v1/api-tools/embedding/clir-emb-dolphin/{app-id (앱 식별자)}", # If using Service App, change 'testapp' to 'serviceapp', and corresponding app id. json.dumps(completion_request), headers ) response = conn.getresponse() result = json.loads(response.read().decode(encoding="utf-8")) conn.close() return result def execute(self, completion_request): res = self._send_request(completion_request) if res["status"]["code"] == "20000": return res["result"]["embedding"] else: error_code = res["status"]["code"] error_message = res.get("status", {}).get("message", "Unknown error") raise ValueError(f"오류 발생: {error_code}: {error_message}") if __name__ == "__main__": embedding_executor = EmbeddingExecutor( host="clovastudio.apigw.ntruss.com", api_key='<api_key>', api_key_primary_val='<api_key_primary_val>', request_id='<request_id>' ) for i, chunked_document in enumerate(tqdm(chunked_html)): try: request_json = { "text": chunked_document['text'] } request_json_string = json.dumps(request_json) request_data = json.loads(request_json_string, strict=False) response_data = embedding_executor.execute(request_data) except ValueError as e: print(f"Embedding API Error. {e}") except Exception as e: print(f"Unexpected error: {e}") chunked_document["embedding"] = response_data Output 100%|██████████| 525/525 [01:04<00:00, 8.08it/s] dimension_set = set() for item in chunked_html: if "embedding" in item: dimension = len(item["embedding"]) dimension_set.add(dimension) print("임베딩된 벡터들의 차원:", dimension_set) Output 임베딩된 벡터들의 차원: {1024} chunked_html[400] Output {'source': 'https://guide.ncloud-docs.com/docs/clovastudio-procedure', 'text': '4. 테스트 앱 생성', 'embedding': [-0.4846521, -0.47464514, -0.47014025, 1.5649279, -0.28591785, 1.0830964, ... -0.09297561, -0.48607916, -0.4411355, -0.86348283, ...]} Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings... 4. Vector DB CLOVA Studio의 임베딩 API를 활용하여 모든 chunked_의 text를 1024차원의 벡터로 변환한 후, 'embedding'이라는 이름의 객체로 chunked_html에 추가해 주었습니다. 이제 이 데이터를 Vector DB에 저장하고, 인덱싱을 하는 단계입니다. Vector DB로는 Milvus를 사용하였으며, 대시보드는 Docker를 사용하여 DB를 켜고(Run) 끄는(Stop) 작업을 수행하였습니다. Milvus Set Up from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility MacOS 환경에서 Docker를 설치한 뒤, 터미널을 사용하여 git clone 명령어로 Milvus Standalone을 설치했습니다. Milvus Standalone 모드는 단일 노드 또는 서버에서 모든 기능을 제공하며, 필요한 모든 컴포넌트가 하나의 인스턴스나 컨테이너 안에서 작동합니다. 이는 주로 소규모 프로젝트나 개발 단계에 이상적입니다. 프로젝트에 파이썬을 사용함에 따라, Milvus를 효과적으로 활용하기 위해 파이썬용 SDK인 Pymilvus를 설치하고 필요한 라이브러리를 가져왔습니다. Collections & ID 생성 connections.connect() fields = [ FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True), FieldSchema(name="source", dtype=DataType.VARCHAR, max_length=3000), FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=9000), FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=1024) ] schema = CollectionSchema(fields, description="컬렉션 설명 적어넣기") collection_name = "컬렉션 이름" collection = Collection(name=collection_name, schema=schema, using='default', shards_num=2) for item in chunked_html: source_list = [item['source']] text_list = [item['text']] embedding_list = [item['embedding']] entities = [ source_list, text_list, embedding_list ] insert_result = collection.insert(entities) print("데이터 Insertion이 완료된 ID:", insert_result.primary_keys) print("데이터 Insertion이 전부 완료되었습니다") Output Data insertion complete. IDs: [448298454101600167, 448298454101600168, 448298454101600173, ..., 448298454101600687, 448298454101600688, 448298454101600689, 448298454101600690, 448298454101600691] Indexing 앞서 임베딩 시 거리 단위를 IP로 설정했기 때문에, 인덱싱에서도 "metric_type"을 "IP"로 설정합니다. 인덱싱 유형은 다양한 알고리즘이 존재하며, 최근에는 HNSW 방식이 많이 활용됩니다. 하지만 선택한 Vector DB가 어떤 인덱싱 유형을 지원하는지 확인해야 합니다. "M"은 각 노드(데이터 포인트)가 유지할 수 있는 최대 엣지(연결)의 수로, 값이 높을수록 검색 정확도는 높아지지만 인덱스 생성 시간과 메모리 사용량도 증가하는 trade-off 관계를 가지고 있습니다. "efConstruction"은 인덱스 구축 시 만들 그래프 구조의 깊이와 너비로, 값이 높을수록 정확도는 올라가지만 인덱스 생성 시간과 메모리 사용량도 증가하는 trade-off 관계를 가지고 있습니다. "M" : 8, "efConstruction" : 200의 설정은 Milvus가 공개한 Milvus 2.2.0의 성능 벤치마크에서 실험 시 설정한 파라미터 값을 가져온 것으로, Cookbook도 Milvus 2.2.x 환경에서 진행되었습니다. 데이터의 양이 많을수록 인덱싱에 시간이 오래 소요될 수 있습니다. 데이터가 많은 경우, 인덱싱 생성 후 바로 결과를 확인하면 결과를 확인할 수 없으며, 인덱싱은 하나의 객체와 값으로 저장되는 것이 아니기 때문에 아래와 같은 실행 결과로 인덱싱이 완료되었는지 확인할 수 있습니다. index_params = { "metric_type": "IP" "index_type": "HNSW" "params": { "M": 8, "efConstruction": 200 } } collection = Collection("htmlrag_forncp") collection.create_index(field_name="embedding", index_params=index_params) utility.index_building_progress("htmlrag_forncp") print([index.params for index in collection.indexes]) Output [{'metric_type': 'IP', 'index_type': 'HNSW', 'params': {'M': 8, 'efConstruction': 200}}] 재실행시 Milvus 로딩 방법 작업 환경 종료 이후, RAG를 이용해 다시 질의응답을 하려면, Vector DB인 Milvus와 연결 상태여야 합니다. Docker를 Milvus의 대시보드로 사용할 때의 연결 방법은 다음과 같습니다. 질의응답은 html_chat() 함수를 통해 이전과 동일하게 진행할 수 있습니다. 1. Docker를 실행한 후, collections가 저장되어 있는 컨테이너(milvus-standalone)를 실행시켜줍니다. 2. 아래의 코드를 통해 connection을 실행하고, 만든 collection의 이름을 넣어 연결합니다. Milvus 및 Milvus-Standalone의 기본 환경은 host = "localhost", port="19530"입니다. 필요한 모듈과 라이브러리는 Milvus에 데이터를 저장할 때와 동일합니다. connections.connect("default", host="localhost", port="19530") # 불러올 collection 이름을 넣는 곳 collection = Collection("htmlrag_forncp") utility.load_state("htmlrag_forncp") Output <LoadState: Loaded> 5. Retrieval → HyperCLOVA X 사용자의 질문을 임베딩하는 함수와, 임베딩한 사용자의 질문에 대응하는 Vector DB에 저장된 데이터를 검색하는 로직을 구성하는 단계입니다. 검색을 통해 사용자의 질문과 가장 유사한 데이터를 모은 "reference"를 HyperCLOVA X가 참조해 질문에 대한 답변을 생성합니다. Chat Completion API를 생성하여 답변 생성을 위한 LLM을 호출하며, 플레이그라운드와 동일하게 파라미터(Top P, Top K 등)와 시스템 프롬프트를 작성할 수 있습니다. Chat Completion API Chat Completion의 파이썬 스펙은 플레이그라운드의 테스트앱 발급을 통해 확인할 수 있습니다. 기본적으로 Chat Completion API의 실행 결과는, 아래와 같은 stream 형태로 출력됩니다. Chat Completion API의 파이썬 스펙을 약간 변형하여 full-length 최종 답변만을 추출할 수 있습니다. 이를 위해 두 가지 로직을 사용할 수 있는데, 첫째는 Stream 답변 중 가장 긴 길이의 답변을 선택하는 방법이고, 둘째는 제일 마지막 출력 결과인 "[DONE]" 바로 직전의 출력 결과를 선택하는 방법입니다. 각각의 방법에 대한 코드는 아래에서 확인하실 수 있습니다. 1. 가장 긴 길이의 답변을 선택하는 경우 class CompletionExecutor: def __init__(self, host, api_key, api_key_primary_val, request_id): self._host = host self._api_key = api_key self._api_key_primary_val = api_key_primary_val self._request_id = request_id def execute(self, completion_request, response_type="stream"): headers = { "X-NCP-CLOVASTUDIO-API-KEY": self._api_key, "X-NCP-APIGW-API-KEY": self._api_key_primary_val, "X-NCP-CLOVASTUDIO-REQUEST-ID": self._request_id, "Content-Type": "application/json; charset=utf-8", "Accept": "text/event-stream" } final_answer = "" with requests.post( self._host + "/testapp/v1/chat-completions/HCX-003", headers=headers, json=completion_request, stream=True ) as r: if response_type == "stream": longest_line = "" for line in r.iter_lines(): if line: decoded_line = line.decode("utf-8") if decoded_line.startswith("data:"): event_data = json.loads(decoded_line[len("data:"):]) message_content = event_data.get("message", {}).get("content", "") if len(message_content) > len(longest_line): longest_line = message_content final_answer = longest_line elif response_type == "single": final_answer = r.json() # 가정: 단일 응답이 JSON 형태로 반환됨 2. "[DONE]" 바로 직전의 출력 결과를 선택하는 경우 class CompletionExecutor: def __init__(self, host, api_key, api_key_primary_val, request_id): self._host = host self._api_key = api_key self._api_key_primary_val = api_key_primary_val self._request_id = request_id def execute(self, completion_request): headers = { "X-NCP-CLOVASTUDIO-API-KEY": self._api_key, "X-NCP-APIGW-API-KEY": self._api_key_primary_val, "X-NCP-CLOVASTUDIO-REQUEST-ID": self._request_id, "Content-Type": "application/json; charset=utf-8", "Accept": "text/event-stream" } response = requests.post( self._host + "/testapp/v1/chat-completions/HCX-003", headers=headers, json=completion_request, stream=True ) # 스트림에서 마지막 'data:' 라인을 찾기 위한 로직 last_data_content = "" for line in response.iter_lines(): if line: decoded_line = line.decode("utf-8") if '"data":"[DONE]"' in decoded_line: break if decoded_line.startswith("data:"): last_data_content = json.loads(decoded_line[5:])["message"]["content"] return last_data_content 답변 생성 함수 정의 # 사용자의 쿼리를 임베딩하는 함수를 먼저 정의 def query_embed(text: str): request_data = {"text": text} response_data = embedding_executor.execute(request_data) return response_data def html_chat(realquery: str) -> str: # 사용자 쿼리 벡터화 query_vector = query_embed(realquery) collection.load() search_params = {"metric_type": "IP", "params": {"ef": 64}} results = collection.search( data=[query_vector], # 검색할 벡터 데이터 anns_field="embedding", # 검색을 수행할 벡터 필드 지정 param=search_params, limit=10, output_fields=["source", "text"] ) reference = [] for hit in results[0]: distance = hit.distance source = hit.entity.get("source") text = hit.entity.get("text") reference.append({"distance": distance, "source": source, "text": text}) completion_executor = CompletionExecutor( host="https://clovastudio.stream.ntruss.com", api_key='<api_key>', api_key_primary_val='<api_key_primary_val>', request_id='<request_id>' ) preset_texts = [ { "role": "system", "content": "- 너의 역할은 사용자의 질문에 reference를 바탕으로 답변하는거야. \n- 너가 가지고있는 지식은 모두 배제하고, 주어진 reference의 내용만을 바탕으로 답변해야해. \n- 답변의 출처가 되는 html의 내용인 'source'도 답변과 함께 {url:}의 형태로 제공해야해. \n- 만약 사용자의 질문이 reference와 관련이 없다면, {제가 가지고 있는 정보로는 답변할 수 없습니다.}라고만 반드시 말해야해." } ] for ref in reference: preset_texts.append( { "role": "system", "content": f"reference: {ref['text']}, url: {ref['source']}" } ) preset_texts.append({"role": "user", "content": realquery}) request_data = { "messages": preset_texts, "topP": 0.6, "topK": 0, "maxTokens": 1024, "temperature": 0.5, "repeatPenalty": 1.2, "stopBefore": [], "includeAiFilters": False } # LLM 생성 답변 반환 response_data = completion_executor.execute(request_data) return response_data 실행 결과 모음 별도의 패키징 작업 없이, RAG 파이프라인을 사용하여 질문을 하고 HyperCLOVA X로부터 출력된 실행 결과입니다. 정확성을 위해 코드 실행 화면을 그대로 캡쳐해 이미지로 첨부했습니다. 실제 원본 데이터인 NCP의 CLOVA Studio 사용 가이드에 포함된 내용에 대해 정확한 답변을 제공하는 것을 확인할 수 있습니다. 추가로, mapping을 통해 답변의 출처가 되는 데이터의 로컬 디렉토리 경로가 아닌, 접속 가능한 실제 URL로 답변하는 것을 확인할 수 있습니다. 시스템 프롬프트에 입력된 지침에 따라, 참조 자료에서 답변을 찾을 수 없는 질문에 대해서는 시스템이 아는 듯이 답변하지 않는 것을 발견할 수 있습니다. 만약, 이 예제에서 사용하지 않은 다른 CLOVA Studio 사용 가이드 문서가 데이터 소스로 사용되었다면 "CLOVA X에서 스킬을 만들 수 있어?"라는 질문에 답변할 수 있었을 것입니다. 하지만, 데이터 소스로 사용된 NCP의 CLOVA Studio 사용 가이드에는 해당 내용이 포함되어 있지 않아, HyperCLOVA X가 답변을 회피하는 안정적인 결과를 보여주었습니다. 맺음말 이 가이드는 CLOVA Studio의 기능을 이용하여 간략하게 구현한 RAG 파이프라인입니다. 문단 나누기 API, 임베딩 API, Chat Completion API를 통해 HyperCLOVA X를 RAG에서 활용할 수 있습니다. RAG의 전체적인 구조와 흐름에 대해서만 다루었으며, Vector DB에 따라 적용할 수 있는 다양한 post-retrieval 방법론이나 retrieval의 평가에 대해서는 다루지 않았습니다. CLOVA Studio의 다양한 기능이 추가되고 업데이트될 예정이므로, 이를 활용하여 RAG를 더욱 발전시킬 수 있을 것입니다. RAG 3부작 시리즈 ✔︎ (1부) RAG란 무엇인가 링크 ✔︎ (2부) RAG 구현 단계 알아보기 링크 ✔︎ (3부) CLOVA Studio를 이용해 RAG 구현하기 Cookbook
- 36 replies
-
- 2
-
-

-
- rag
- clova studio 활용
- (and 1 more)
-
안녕하세요, @추만득님, 분류 작업의 경우 구체적인 지시문이나 예제를 가지고 프롬프트를 만드신 후 수행이 가능합니다. 참고하실 수 있는 자료를 전달드립니다. 예제 문서: https://guide.ncloud-docs.com/docs/clovastudio-classification 핵심 키워드 추출: https://clovastudio.ncloud.com/playground/yl1cxo6f 감정 분석: https://clovastudio.ncloud.com/playground/1gp812bf 감사합니다.
-
안녕하세요, @comes님, 저희쪽에서 확인했을때 정상적으로 응답되고 있어서, 가이드대로 인증 요청이 되어있는지 확인 부탁드립니다. https://api.ncloud-docs.com/docs/clovastudio-gettask https://guide.ncloud-docs.com/docs/en/apigw-myproducts#error-code 보다 자세한 확인을 위해서는 요청 헤더에 대한 정보가 필요할 것 같아서 아래 링크를 통해 자세히 알려주시면, 답변드릴 수 있도록 하겠습니다. https://www.ncloud.com/support/question/service 감사합니다.
-
@이철희님, 네, 한글 문서의 프롬프트, 영문 문서의 프롬프트처럼 작업을 구분해서 이용하는 것이 성능상 안정적일 수 있을 것 같습니다. 다만 현실적으로 모든 작업들을 이렇게 구분하는 것은 어렵기 때문에, 한글은 한글, 영문은 영문으로 해달라는 형태의 시스템 프롬프트를 추가해보면서 성능 확인이 필요할 것 같습니다. 또는 프롬프트에 간단한 예제를 넣어주는 것도 도움이 될 수 있습니다. 마지막으로 앞서 말씀드린대로, Repetition penalty는 문구를 생성할 때 반복적인 결괏값을 생성하지 않도록 반복되는 토큰에는 감점 요소를 부여하는 값입니다. 따라서 해당 값을 1.2 정도로 낮추면, 최대한 원문에 근접한 언어의 결과를 낼 수 있지 않을까 기대합니다. 그 밖에 부족한 부분들은 지속적으로 모델 개선이 이루어질 수 있도록 관리하겠습니다. 감사합니다.
-
@이철희님, 공유주셔서 감사합니다. 언어를 설정하는 옵션은 없으나, 이러한 문제는 의외로 간단하게 해결할 수 있습니다. 전달해주신 시스템 프롬프트로는 아래와 같이 한국어 키워드가 추출되는 것을 확인했습니다. ▼ 작성하신 시스템 프롬프트에 '영문으로만 출력' 해달라는 지시를 입력해두었습니다. """ ### 지시사항 - 문서에서 핵심 키워드 최대 5개를 추출합니다. - 키워드는 핵심 주제와 상응하는 우선순위로 꼭 json 형식으로 답변합니다. - 각각의 핵심 키워드는 2단어 이하로 조합해서 추출합니다. - 주어진 문서에서 핵심 키워드를 영문으로만 출력합니다. - 한글을 출력하지 않고 절대로 영문으로만 출력합니다. ### 응답형식 {'keywords':['키워드1', '키워드2', '키워드3', '키워드4', '키워드5']} """ ▼ 영문으로 출력되는 것을 확인할 수 있었습니다. 또한 분류와 같은 작업에서 Repetition penalty 값은 1.2로 설정을 추천드립니다. 감사합니다.
-
안녕하세요, @kwak님, 현재는 이전 대화 내용을 기억하기 위한 별도의 기능은 제공하지 않습니다. 이전의 대화를 요약해서 시스템 프롬프트에 넣는 등의 별도의 엔지니어링이 필요할 것으로 보입니다. 감사합니다.
-
안녕하세요, @이철희님, 클로바 스튜디오 많은 관심을 가져주셔서 감사드립니다. 1. 자세한 부분은 작업을 봐야 알 수 있을 것 같으나, 시스템 프롬프트를 통해 json 형태의 스타일에 대한 정의를 구체적으로 추가 하시면 일부 개선이 되지 않을까 생각합니다. 2. 지난주 금요일에 네이버 클라우드 플랫폼 전 범위로 일시적인 에러가 발생하였습니다. 해당 영향으로 보이며, 지속적으로 동일한 이슈가 있으실 경우 고객 센터를 통해 연락 부탁드립니다. 3. 기존 안내된 바와 같이, 지난 3월 CLOVA Studio가 오픈 베타 서비스로 전환됨에 따라 보다 안정적인 환경에서 서비스가 운영될 수 있도록 이용량 제어 정책을 새롭게 적용하였습니다. 관련 상세 내용은 가이드 문서를 참조해주세요. https://guide.ncloud-docs.com/docs/clovastudio-ratelimiting 5. 가이드 보완을 위해 개선 검토하겠습니다. 감사합니다.
-
이번 포스팅은 'RAG(Retrieval-Augmented Generation)'을 주제로 한 3부작 시리즈의 두 번째 글입니다. 1부에서 RAG(Retrieval-Augmented Generation)의 개념과 핵심 구성 요소에 대해 살펴보았다면, 이번 2부에서는 RAG를 실제로 구현하는 과정을 단계별로 상세히 파헤쳐 보겠습니다. 또한, 각 단계에서 CLOVA Studio의 다양한 기능들이 어떻게 활용될 수 있는지 면밀히 분석해 보는 시간을 갖도록 하겠습니다. RAG 3부작 시리즈 ✔︎ (1부) RAG란 무엇인가 링크 ✔︎ (2부) RAG 구현 단계 알아보기 ✔︎ (3부) CLOVA Studio를 이용해 RAG 구현하기 Cookbook 링크 1부에서 소개한 RAG 구조를 자세히 들여다보면, CLOVA Studio는 RAG의 핵심 기능 3가지를 효과적으로 지원하고 있습니다. 첫째, 방대한 텍스트를 적절한 크기로 분할하는 데 사용되는 문단 나누기 API. 둘째, 분할된 데이터와 사용자의 질문을 벡터로 변환할 때 사용되는 임베딩 API. 셋째, 사용자에게 최종 답변을 제공할 때 활용되는 하이퍼클로바X의 Chat Completion API. 이제 RAG의 작동 과정을 살펴보면서, CLOVA Studio의 API들이 어떻게 유기적으로 연계되어 활용될 수 있는지 알아보겠습니다. 1. Raw Data → Connecting 데이터 소스를 가져오는 과정은 RAG 구조를 적용하기 위한 첫 단계입니다. HTML이나 PDF 등 원본 데이터의 형식을 컴퓨터가 처리 가능한 형태로 변환해야 합니다. 이렇게 로딩된 데이터는 문단 나누기 API와 임베딩 API 등을 거쳐 최종적으로 HyperCLOVA X에 전달되어 활용됩니다. 이번 Cookbook에서는 네이버 클라우드 플랫폼의 CLOVA Studio 사용 가이드에 포함된 '개요', '사용 준비', '개념', '시나리오' 4개 페이지의 HTML 형식 데이터를 Raw Data로 사용하였습니다. 그리고 데이터를 효과적으로 연결하고 처리하기 위해 Langchain 라이브러리의 몇 가지 모듈을 활용하였습니다. 이를 통해 원활한 데이터 처리 및 RAG 구조 적용이 가능해졌습니다. 2. Connecting → Embedding 현존하는 모델들은 대용량 데이터를 한 번에 처리하기 어렵기 때문에, 데이터를 모델이 처리 가능한 작은 단위로 나누는 과정이 필요합니다. 이를 일반적으로 Chunking이라고 하며, CLOVA Studio 익스플로러의 문단 나누기 API가 이 기능을 지원합니다. RAG에 활용할 데이터 가져오기에 성공했다면, 문단 나누기 API를 통해 데이터를 적절한 크기로 분할할 수 있습니다. 이 API는 모델이 문장 간 유사도를 파악하여 나누거나, 사용자가 직접 원하는 크기를 설정해서 글을 나눌 수도 있습니다. 문단 나누기 API를 활용하면, 긴 텍스트 데이터를 작은 단위로 효과적으로 분할할 수 있습니다. 이렇게 분할된 데이터는 RAG 구조에서 효율적으로 활용될 수 있습니다. 3. Embedding 임베딩은 자연어를 벡터로 변환하는 과정입니다. RAG(Retrieval-Augmented Generation)에서는 작은 덩어리로 나누어진 데이터와 사용자의 질문을 모두 임베딩해야 하는데, CLOVA Studio의 임베딩 API를 통해 입력한 텍스트를 1024차원의 벡터로 변환할 수 있습니다. 데이터와 질문을 효과적으로 관리하고 검색을 구현하기 위해서는 임베딩이 필수적입니다. CLOVA Studio의 임베딩 API는 RAG 구현에 있어 중요한 역할을 할 것입니다. 4. Vector DB 벡터 DB는 임베딩으로 변환된 벡터를 저장하는 데이터베이스로, 고차원 벡터 데이터를 효율적으로 관리하고 검색하는 데 특화되어 있습니다. 현재 다양한 기업에서 벡터 DB를 지원하고 있어, 사용자는 목적에 맞는 벡터 DB를 선택할 수 있습니다. 벡터 DB에 임베딩된 데이터와 질문을 저장하면 대규모 데이터 세트에서도 유사도 검색을 통해 정확한 결과를 얻을 수 있습니다. 5. Retrieval 이 단계에서는 벡터 데이터베이스(DB)에 저장된 데이터와 사용자의 질문을 매칭하여, 질문에 가장 적합한 데이터를 검색합니다. 검색 로직은 직접 구현하거나, 벡터 DB에서 제공하는 기능을 활용할 수 있습니다. 이렇게 선정된 후보 데이터들은 HyperCLOVA X에 전달되어 최종 답변 생성에 활용됩니다. 6. 하이퍼클로바 X의 답변 HyperCLOVA X는 Retrieval 단계에서 선정된 후보 데이터를 참고하여 사용자에게 제공할 최종 답변을 생성합니다. 이 과정에서 CLOVA Studio의 Chat Completion API가 활용되는데, 이는 RAG 구현에 있어 핵심적인 역할을 합니다. 앞선 과정들을 아무리 잘 구현하더라도 우수한 LLM이 없다면 RAG를 완성할 수 없습니다. CLOVA Studio의 장점 중 하나는 시스템 프롬프트 팔로잉 능력이 뛰어나고 한글 성능이 우수한 HyperCLOVA X 모델을 API로 연결하여 활용할 수 있다는 점입니다. CLOVA Studio의 플레이그라운드에서와 마찬가지로 파라미터를 자유롭게 설정하고 시스템 프롬프트를 원하는 대로 작성함으로써 답변의 품질을 더욱 높일 수 있습니다. 이는 RAG 구현 과정에서 개발자에게 큰 유연성과 편의성을 제공합니다. 이번 예제에서 활용한 시스템 프롬프트는 다음과 같습니다. - 너의 역할은 사용자의 질문에 reference를 바탕으로 답변하는거야. - 너가 가지고있는 지식은 모두 배제하고, 주어진 reference의 내용만을 바탕으로 답변해야해. - 만약 사용자의 질문이 reference와 관련이 없다면, {제가 가지고 있는 정보로는 답변할 수 없습니다.}라고만 반드시 말해야해. 여기서 'reference'는 Retrieval 단계에서 추출한 몇 개의 후보 데이터들을 모아놓은 리스트를 의미합니다. 이제 CLOVA Studio와 함께 활용한 RAG의 작동 방식을 보여드리겠습니다. ▲ CLOVA Studio 사용 가이드 페이지에 수록된 내용을 활용해서 똑똑하게 답변하는 것을 알 수 있습니다. ▼ 반면, 사용 가이드 페이지에 있지 않은 질문들을 했을 때 어떻게 답변하는지 살펴볼까요? CLOVA Studio의 사용 가이드에서 다루지 않은 CLOVA X의 기능에 대해서는 답변할 수 없다고 답변하고 있습니다. 심지어 RAG 구조를 사용하지 않았다면 완벽하게 대답했을 법한 '부산 1박 2일 여행 계획'에 대해서도 응답을 자제하는 태도는 시스템 프롬프트를 충실히 따르는 HyperCLOVA X의 특징을 엿볼 수 있게 해줍니다. CLOVA Studio가 제공하는 다양한 API와 무한한 잠재력을 지닌 HyperCLOVA X를 활용해 RAG를 구현해 보는 것은 매우 흥미로운 도전이 될 것입니다. 3부에서는 CLOVA Studio를 활용한 RAG의 각 단계를 코드와 함께 알아보며, 더욱 구체적으로 살펴보는 시간을 갖겠습니다! RAG 3부작 시리즈 ✔︎ (1부) RAG란 무엇인가 링크 ✔︎ (2부) RAG 구현 단계 알아보기 ✔︎ (3부) CLOVA Studio를 이용해 RAG 구현하기 Cookbook 링크
- 1 reply
-
- 1
-
-
- rag
- clova studio 활용
- (and 1 more)
-
안녕하세요, @Trinity님, 답변이 매우 늦어져 죄송합니다. 크레딧 유형과 기간에 대한 확인이 필요해보여서 아래 링크를 통해 자세히 알려주시면, 답변드릴 수 있도록 하겠습니다. https://www.ncloud.com/support/question/service 감사합니다.
-
안녕하세요, @hatiolab님, 튜닝 학습시에도 System prompt를 포함하여 학습이 가능하도록 곧 반영될 예정입니다. 해당 기능을 토대로 보다 정확한 답변을 얻을 수 있지 않을까 생각이 됩니다. 학습해야할 지식이 아주 많을 경우에는 RAG 구축을 이용하시는 것이 효과적일 수 있습니다. RAG 구축의 경우, 클로바 스튜디오를 통해 구현할 수 있는 Cookbook을 조만간 업데이트 드릴 예정이니, 참고하셔도 좋을 것 같습니다. 감사합니다. @TABA님, 답변 감사드립니다.
-
네, 공유 감사합니다. 이용하시다가 문의사항이 있으시면 또 알려주세요. 감사합니다.
-
@DevLee님, 아래 링크를 통해 요청하신 정보나 작업 링크(공유 비밀번호 포함)대해서 자세히 안내주시면, 보다 자세히 살펴보도록 하겠습니다. https://www.ncloud.com/support/question/service 감사합니다.